2026 年,41% 的代码提交已经是 AI 辅助生成的——但 AI 生成的代码缺陷率比人类代码高 1.7 倍。代码生成越来越快,但代码审查的产能严重不足,预计 2026 年将出现 40% 的质量缺口。
AI 代码审查不是"要不要做"的问题,而是"怎么做好"的问题。本文将介绍 7 个经过验证的最佳实践,并深入分析为什么 Claude Opus 4.6 和 Sonnet 4.6 是目前最适合代码审查的 AI 模型。
核心价值: 读完本文,你将掌握 AI 代码审查的完整工作流,并了解如何选择最合适的模型来提升团队代码质量。

AI 代码审查的现状:为什么现在必须重视
2026 年代码审查面临的挑战
| 挑战 | 数据 | 影响 |
|---|---|---|
| AI 代码占比激增 | 41% 的提交由 AI 辅助生成 | 审查需求激增 |
| AI 代码缺陷率 | 比人类代码高 1.7 倍 | 需要更严格的审查 |
| 质量缺口 | 预计 2026 年出现 40% | 审查产能跟不上生成速度 |
| 安全风险 | 45% 的 AI 代码引入 OWASP Top 10 漏洞 | 安全审查尤为紧迫 |
| 建议采纳率 | AI 建议仅 16.6%,人类建议 56.5% | AI 审查质量有待提升 |
AI 代码审查 vs 人类代码审查
AI 不是来替代人类审查者的,而是来增强人类的审查能力。使用 AI 代码审查的团队报告:
- 审查时间减少 40-60%
- 缺陷检出率提升——尤其是安全漏洞和边界条件
- 代码风格一致性大幅改善
但 AI 审查也有明确的边界:
- ❌ 无法理解业务截止日期和项目上下文
- ❌ 无法感知遗留系统的历史妥协
- ❌ 无法承担审查的最终责任
- ❌ 无法进行团队知识传承和 mentor
🎯 最佳策略: AI 做第一遍扫描 (风格、bug、安全),人类做最终判断 (架构、意图、风险)。通过 API易 apiyi.com 平台调用 Claude Opus 4.6 或 Sonnet 4.6 的 API,可以快速将 AI 代码审查集成到现有 CI/CD 流程中。
AI 代码审查的 7 个最佳实践
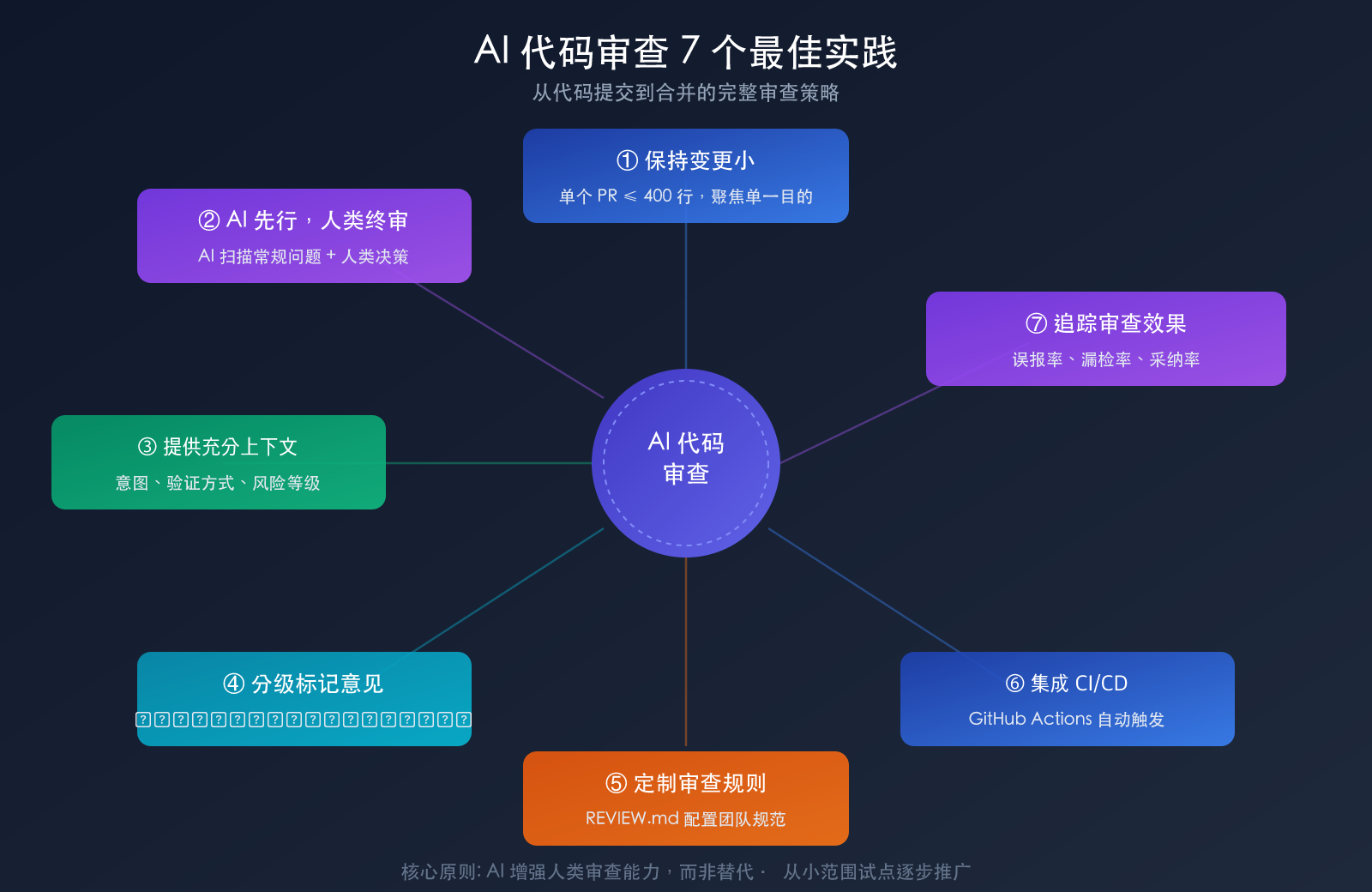
实践一:保持变更小而聚焦
AI 审查者在 diff 超过 1000 行后会显著失去连贯性。即使 Claude Opus 4.6 拥有 100 万 token 的上下文窗口,大型变更的审查质量仍不如小型变更。
具体做法:
- 单个 PR 控制在 200-400 行以内
- 大型重构拆分为多个逻辑独立的 PR
- 每个 PR 只做一件事
实践二:AI 先行,人类终审
最有效的工作流是"双层审查"模式:
代码提交 → AI 自动审查 (第一遍)
↓
标记问题 + 严重级别分类
↓
人类审查者聚焦高风险区域 (终审)
↓
合并或驳回
AI 负责扫描所有常规问题 (风格、命名、死代码、简单 bug),人类聚焦于:
- 架构合理性
- 业务逻辑正确性
- 安全关键决策
- 性能影响评估
实践三:提供充分的上下文
给 AI 审查者的信息越多,审查质量越高。推荐在 PR 描述中包含:
## 变更意图
用 1-2 句话说明"为什么做这个变更"
## 验证方式
- [ ] 单元测试通过
- [ ] 手动测试了 XX 场景
- [ ] 性能无回退
## 风险等级
低/中/高 + 说明
## AI 辅助声明
本次变更中 XX 部分由 AI 生成,请重点审查
## 人工聚焦区域
请重点关注 src/auth/ 目录下的权限逻辑变更
实践四:分级标记审查意见
AI 审查的一个常见问题是"噪音太多"——把风格建议和严重 bug 混在一起,导致开发者忽视重要反馈。
推荐的严重级别标记:
| 标记 | 含义 | 处理方式 |
|---|---|---|
| 🔴 Bug | 合并前必须修复的缺陷 | 阻塞合并 |
| 🟡 Nit | 值得修复但不阻塞的小问题 | 可选修复 |
| 🟣 Pre-existing | 不是本次引入的旧问题 | 记录但不阻塞 |
| 💡 Suggestion | 改进建议 | 讨论后决定 |
Claude Code 的原生代码审查功能已经实现了这套分级系统 (Red/Yellow/Purple)。
实践五:定制审查规则
通用的 AI 审查可能不符合团队规范。通过配置文件定制审查行为:
# REVIEW.md (放在项目根目录)
## 必须检查
- 所有数据库查询必须使用参数化语句
- API 端点必须包含认证中间件
- 所有用户输入必须做校验
## 可以跳过
- CSS 类名的命名风格 (已用 prettier 自动格式化)
- import 排序 (已用 ruff 自动处理)
- 注释语言 (中英文均可)
## 团队约定
- 优先使用组合而非继承
- 错误处理使用 Result 模式
- 日志级别: 业务事件用 INFO,调试用 DEBUG
实践六:集成到 CI/CD 流水线
AI 代码审查应该是自动化的,而非手动触发的。
推荐的集成方式:
# GitHub Actions 示例
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
也可以通过 API 直接调用 Claude 模型进行自定义审查:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """你是资深代码审查专家。
请分析以下代码变更,按严重级别分类:
- 🔴 Bug: 必须修复
- 🟡 Nit: 建议修复
- 💡 Suggestion: 改进建议
每个问题指出具体行号和修复方案。"""},
{"role": "user", "content": f"请审查以下代码变更:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
实践七:追踪审查效果
AI 代码审查不是部署后就不管了。需要持续追踪关键指标:
- 误报率 (False Positive Rate): AI 标记的问题中有多少是真实问题
- 漏检率 (False Negative Rate): 上线后发现的 bug 中有多少 AI 没有发现
- 采纳率: 开发者实际采纳 AI 建议的比例
- 审查时间变化: 人类审查者的平均审查时间是否减少
💡 实施建议: 如果你的团队刚开始尝试 AI 代码审查,建议从非关键路径的 PR 开始试点。通过 API易 apiyi.com 调用 Claude Sonnet 4.6 做初期试验,成本仅为 Opus 的 1/5,审查质量接近 Opus 水平,是性价比最高的起步方案。
为什么推荐 Claude Opus 4.6 和 Sonnet 4.6 做代码审查
在众多 AI 模型中,Claude 4.6 系列在代码审查场景下有着独特的优势。
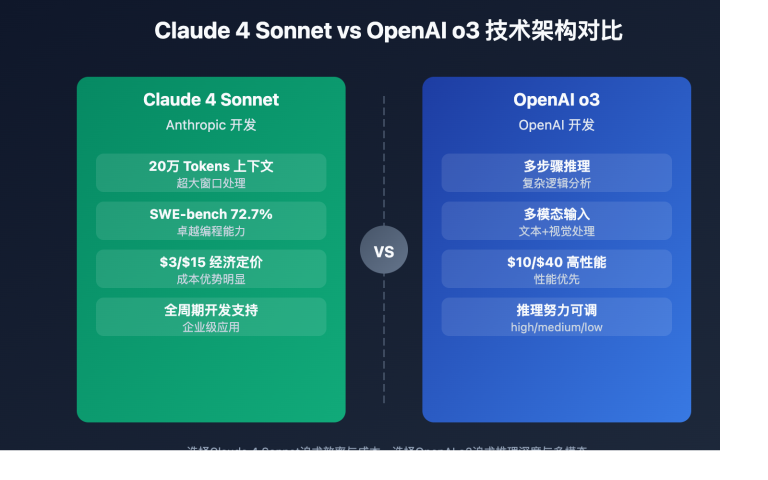
Claude 4.6 模型核心参数对比
| 参数 | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| 模型 ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| 发布时间 | 2026年2月5日 | 2026年2月17日 |
| 上下文窗口 | 100 万 token (beta) | 100 万 token (beta) |
| 最大输出 | 128K token | 64K token |
| SWE-bench Verified | 81.42% | 79.6% |
| 定价 (输入/输出) | $5/$25 每百万 token | $3/$15 每百万 token |
| 适用场景 | 复杂架构审查、安全审计 | 日常 PR 审查、风格检查 |
| API易价格 | 更优惠 | 更优惠 |
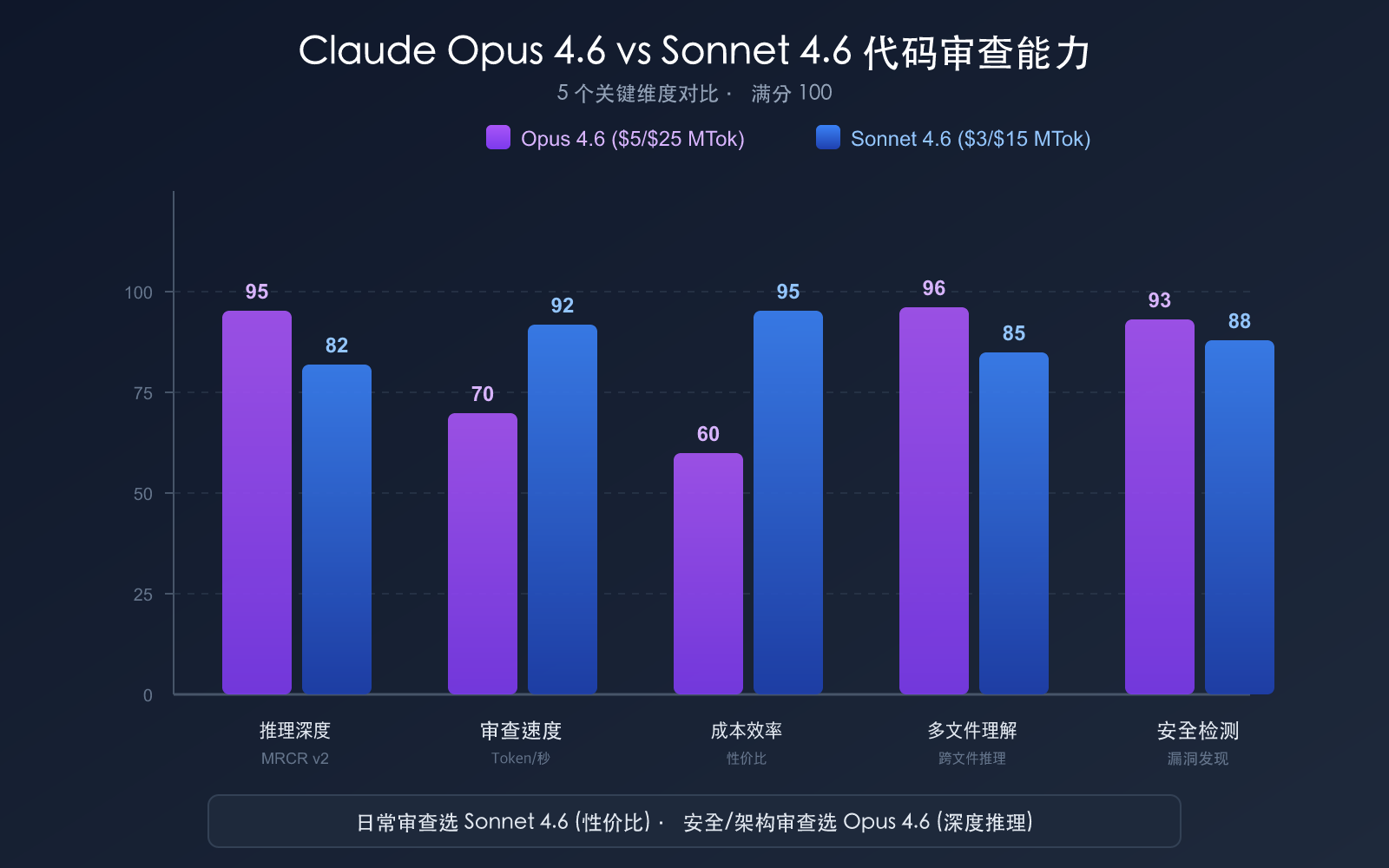
优势一:100 万 token 上下文窗口
这是代码审查场景下最关键的技术优势。
大型项目的一个 PR 可能涉及几十个文件。传统 AI 模型的上下文窗口限制意味着你必须截断代码,导致审查者看不到完整上下文。
Claude 4.6 的 100 万 token 上下文可以一次性容纳:
- 完整的 PR diff (通常几百到几千行)
- 相关文件的全部代码 (import 链、被调用的函数)
- 依赖关系图和类型定义
- 测试文件和配置文件
- 项目的 README 和架构文档
这意味着 AI 可以像资深开发者一样,在理解完整上下文的情况下进行审查。
优势二:顶级的跨文件推理能力
代码审查最有价值的地方不是找语法错误,而是发现跨文件的逻辑问题。
Claude Opus 4.6 在 MRCR v2 (多针多文件检索推理) 测试中得分 76%,而 Sonnet 4.5 仅为 18.5%。这意味着 Opus 4.6 在以下场景表现卓越:
- 检测 A 文件修改了接口,但 B 文件的调用没有同步更新
- 发现数据流从入口到数据库全链路上的校验缺失
- 识别并发场景下的竞态条件
真实案例: 在测试中,Claude Opus 4.6 在一个 2400 行的数据库迁移 PR 中发现了一个竞态条件——只有在迁移中途中断时才会触发的回滚逻辑缺陷。这是自动化测试无法覆盖的场景。
优势三:自适应思考深度
Claude 4.6 引入了 adaptive thinking 模式——AI 会根据问题复杂度自动决定"想多深"。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Review this code change for security issues."},
{"role": "user", "content": diff_content}
],
# Claude 4.6 自适应思考:简单问题快速过,复杂问题深入分析
extra_body={"thinking": {"type": "adaptive"}}
)
- 遇到简单的风格问题 → 快速判断,节省 token
- 遇到复杂的并发或安全问题 → 深入推理,给出详尽分析
优势四:安全漏洞检测远超传统工具
研究表明,Claude 级别的 LLM 在安全代码审查中显著优于传统静态分析工具:
| 对比维度 | Claude (LLM) | CodeQL (传统 SAST) |
|---|---|---|
| 检测漏洞数 | 55 个 | 27 个 |
| 未知漏洞发现 | 4 个零日漏洞 | 0 个 |
| 检测类别 | 注入、认证、数据泄露、加密、逻辑缺陷等 10+ 类 | 基于模式匹配 |
| 语言支持 | 任何编程语言 | 特定语言 |
| 误报过滤 | AI 自动过滤 | 需人工过滤 |
Claude 可以检测的安全漏洞类型:
- SQL/命令/LDAP/XPath/NoSQL 注入
- 认证和授权缺陷
- 硬编码密钥、敏感数据日志
- 弱加密算法、密钥管理不当
- 竞态条件 (TOCTOU)
- 不安全的默认配置、CORS
- 反序列化 RCE、pickle/eval 注入
- XSS (反射型、存储型、DOM 型)
优势五:成本灵活性
Sonnet 4.6 的定价仅为 Opus 4.6 的 1/5,但在 SWE-bench 上仅落后 1-2 个百分点。
推荐的选型策略:
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 日常 PR 审查 | Sonnet 4.6 | 性价比最高,质量接近 Opus |
| 安全关键代码 | Opus 4.6 | 最深推理,不漏过高危问题 |
| 大型重构审查 | Opus 4.6 | 跨文件推理能力最强 |
| 风格和规范检查 | Sonnet 4.6 | 简单任务无需 Opus |
| CI/CD 自动审查 | Sonnet 4.6 | 成本可控,适合每次提交触发 |
🚀 选型建议: Anthropic 官方的建议是"默认使用 Sonnet 4.6,仅在需要最深推理时升级到 Opus 4.6"。在 Claude Code 的内部测试中,开发者对 Sonnet 4.6 的偏好率比上一代 Sonnet 4.5 高 70%,甚至比前旗舰 Opus 4.5 高 59%。通过 API易 apiyi.com 调用两个模型都可以享受更优惠的价格。
完整的 AI 代码审查工作流
工作流总览
开发者提交 PR
↓
AI 自动触发审查 (Sonnet 4.6)
↓
┌─── 低风险变更 ──→ AI 标记 Nit,自动通过
│
├─── 中风险变更 ──→ AI 标记问题,人工快速确认
│
└─── 高风险变更 ──→ 升级到 Opus 4.6 深度审查
↓
安全专家人工终审
↓
合并或驳回
代码示例:搭建自定义 AI 审查系统
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
def get_pr_diff(pr_number):
"""获取 PR 的 diff 内容"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""根据风险级别选择模型进行审查"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"审查以下变更:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# 使用示例
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
查看完整审查 Prompt 模板
REVIEW_PROMPT = """你是一位经验丰富的高级软件工程师,正在进行代码审查。
## 审查重点
1. **逻辑正确性**: 代码是否实现了预期功能?是否有边界条件遗漏?
2. **安全性**: 是否存在注入、XSS、CSRF、硬编码密钥等安全风险?
3. **性能**: 是否有 N+1 查询、不必要的内存分配、阻塞操作?
4. **可维护性**: 命名是否清晰?复杂度是否可控?是否有重复代码?
5. **错误处理**: 异常是否被正确捕获和处理?
6. **并发安全**: 是否存在竞态条件或死锁风险?
## 输出格式
按严重级别分类输出:
### 🔴 必须修复 (Bug/Security)
- [文件名:行号] 问题描述
- 影响: ...
- 建议修复: ...
### 🟡 建议修复 (Nit)
- [文件名:行号] 问题描述
- 建议: ...
### 💡 改进建议 (Suggestion)
- [文件名:行号] 改进点
- 说明: ...
如果代码质量良好且没有发现问题,请明确说明"审查通过,未发现问题"。
不要为了输出而编造不存在的问题。"""
💰 成本优化: 通过 API易 apiyi.com 调用 Claude 4.6 模型进行代码审查,价格比官方更优惠。平台支持 Opus 4.6 和 Sonnet 4.6 的灵活切换,可以根据 PR 的风险等级自动选择最具性价比的模型。
AI 代码审查的局限与注意事项
必须了解的 5 个局限
- 召回率约 50%: LLM 发现的漏洞通常是真实的 (精确率 ~80%),但大约会漏掉一半的现有漏洞
- Prompt 注入风险: AI 审查工具处理不可信 PR 时存在被注入的风险
- 上下文盲区: AI 无法理解项目的商业背景、团队人员能力和历史决策
- 成本累积: 如果对每次提交都触发审查,高频仓库的费用可能较高
- 过度依赖风险: 团队成员可能逐渐放松人工审查的严谨性
规避策略
| 局限 | 规避方案 |
|---|---|
| 漏检率高 | AI 审查 + 人工审查双重保障 |
| Prompt 注入 | 仅审查可信来源的 PR |
| 上下文不足 | 在 REVIEW.md 中提供项目背景 |
| 成本过高 | 日常用 Sonnet 4.6,关键路径用 Opus 4.6 |
| 过度依赖 | 建立"AI 建议 + 人工决策"的制度 |
常见问题
Q1: AI 代码审查可以完全替代人类审查吗?
不能。AI 代码审查是"增强"而非"替代"。AI 擅长发现模式化的问题 (风格、常见 bug、已知漏洞模式),但无法理解业务意图、架构决策背后的权衡和团队协作中的隐性知识。最佳实践是 AI 做第一遍扫描,人类做最终判断。通过 API易 apiyi.com 调用 Claude 4.6 模型可以快速搭建 AI 审查流程,让人类审查者聚焦于更高价值的工作。
Q2: Opus 4.6 和 Sonnet 4.6 选哪个做代码审查?
大多数场景选 Sonnet 4.6。它在 SWE-bench 上仅比 Opus 低 1-2 个百分点,但成本只有 1/5。只有在审查安全关键代码、大型架构重构、需要深度跨文件推理时才需要升级到 Opus 4.6。通过 API易 apiyi.com 可以按需灵活切换两个模型。
Q3: AI 代码审查的成本大约是多少?
Claude Code 原生审查功能平均每次 $15-25,取决于 PR 大小和代码库复杂度。如果通过 API 自建审查系统,成本取决于 token 消耗量。以 Sonnet 4.6 为例,审查一个 500 行的 PR (约 2000 token 输入 + 1000 token 输出) 约 $0.02。通过 API易 apiyi.com 还能享受更优惠的价格。
Q4: 如何评估 AI 代码审查的效果?
建议追踪 4 个核心指标:(1) 误报率——AI 标记的问题中真实问题的比例;(2) 漏检率——上线后发现的 bug 中 AI 未标记的比例;(3) 采纳率——开发者实际采纳 AI 建议的比例;(4) 审查时间变化——人工审查者的平均审查时间是否减少。前两个月建议每周复盘一次。
Q5: 如何快速开始尝试 AI 代码审查?
最简单的方式是三步走:(1) 通过 API易 apiyi.com 注册获取 API Key;(2) 用 Sonnet 4.6 对最近的一个 PR 做一次审查测试;(3) 根据效果决定是否接入 CI/CD 自动化。从非关键路径的代码开始试点,逐步推广到全量。
总结:AI 代码审查是团队效率的倍增器
AI 代码审查不是可选项,而是 2026 年软件开发团队的必备能力。Claude Opus 4.6 和 Sonnet 4.6 凭借 100 万 token 上下文、81%+ 的 SWE-bench 得分、自适应思考和强大的安全检测能力,是目前代码审查场景下的最优选择。
选型建议:
- 日常审查: 默认 Sonnet 4.6,性价比之王
- 安全/架构审查: 升级 Opus 4.6,不妥协的推理深度
推荐通过 API易 apiyi.com 快速接入 Claude 4.6 全系列模型,以最优成本为团队建立 AI 代码审查能力。
参考资料
-
Anthropic 官方: Claude Opus 4.6 和 Sonnet 4.6 发布公告
- 链接:
anthropic.com/news
- 链接:
-
Claude Code 代码审查文档: 原生审查功能使用指南
- 链接:
code.claude.com/docs/en/code-review
- 链接:
-
Claude Code Security Review: 开源安全审查 GitHub Action
- 链接:
github.com/anthropics/claude-code-security-review
- 链接:
-
AI 代码审查最佳实践 2026: 行业综合分析
- 链接:
verdent.ai/guides
- 链接:
-
IRIS 研究论文: LLM 辅助静态分析漏洞检测
- 链接:
arxiv.org
- 链接:
作者: APIYI Team | 探索 AI 赋能软件开发的最佳实践,欢迎访问 API易 apiyi.com 获取 Claude 4.6 全系列模型的 API 接口和技术支持。