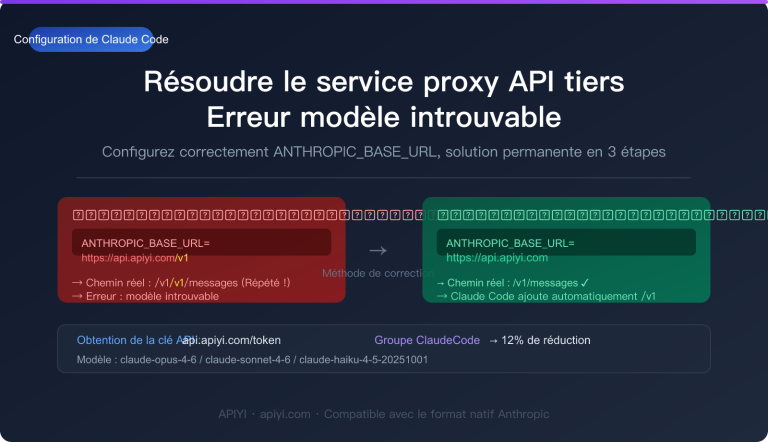
En 2026, 41 % des soumissions de code seront générées avec l'aide de l'IA, mais le taux de défauts du code généré par l'IA est 1,7 fois plus élevé que celui du code écrit par des humains. Si la génération de code s'accélère, la capacité de revue de code, elle, est largement insuffisante, avec un déficit de qualité prévu à 40 % d'ici 2026.
La revue de code par IA n'est plus une question de « si », mais de « comment ». Cet article présente 7 bonnes pratiques éprouvées et analyse en profondeur pourquoi Claude Opus 4.6 et Sonnet 4.6 sont actuellement les modèles d'IA les plus adaptés à la revue de code.
Valeur ajoutée : Après avoir lu cet article, vous maîtriserez le flux de travail complet de la revue de code par IA et saurez choisir le modèle le plus approprié pour améliorer la qualité du code de votre équipe.
État des lieux de la revue de code par IA : pourquoi est-ce devenu indispensable
Les défis de la revue de code en 2026
| Défi | Données | Impact |
|---|---|---|
| Explosion du code généré par IA | 41 % des soumissions assistées par IA | Besoin accru en revue |
| Taux de défauts de l'IA | 1,7 fois supérieur au code humain | Nécessite une revue plus stricte |
| Déficit de qualité | 40 % prévu en 2026 | La capacité de revue ne suit pas la génération |
| Risques de sécurité | 45 % du code IA introduit des vulnérabilités OWASP Top 10 | Revue de sécurité urgente |
| Taux d'adoption des suggestions | IA : 16,6 % vs Humain : 56,5 % | La qualité des suggestions IA doit progresser |
Revue de code par IA vs Revue humaine
L'IA n'est pas là pour remplacer les relecteurs humains, mais pour renforcer leurs capacités. Les équipes utilisant la revue de code par IA rapportent :
- Réduction du temps de revue de 40 à 60 %
- Amélioration du taux de détection des défauts — surtout pour les failles de sécurité et les cas limites
- Amélioration significative de la cohérence du style de code
Cependant, la revue par IA a des limites claires :
- ❌ Incapable de comprendre les délais métier et le contexte du projet
- ❌ Incapable de percevoir les compromis historiques des systèmes existants
- ❌ Ne peut pas assumer la responsabilité finale de la revue
- ❌ Ne peut pas assurer le mentorat ou la transmission des connaissances au sein de l'équipe
🎯 Meilleure stratégie : L'IA effectue une première passe (style, bugs, sécurité), l'humain prend la décision finale (architecture, intention, risques). En utilisant la plateforme APIYI apiyi.com pour invoquer l'API de Claude Opus 4.6 ou Sonnet 4.6, vous pouvez intégrer rapidement la revue de code par IA dans vos flux CI/CD existants.
7 bonnes pratiques pour la revue de code par IA
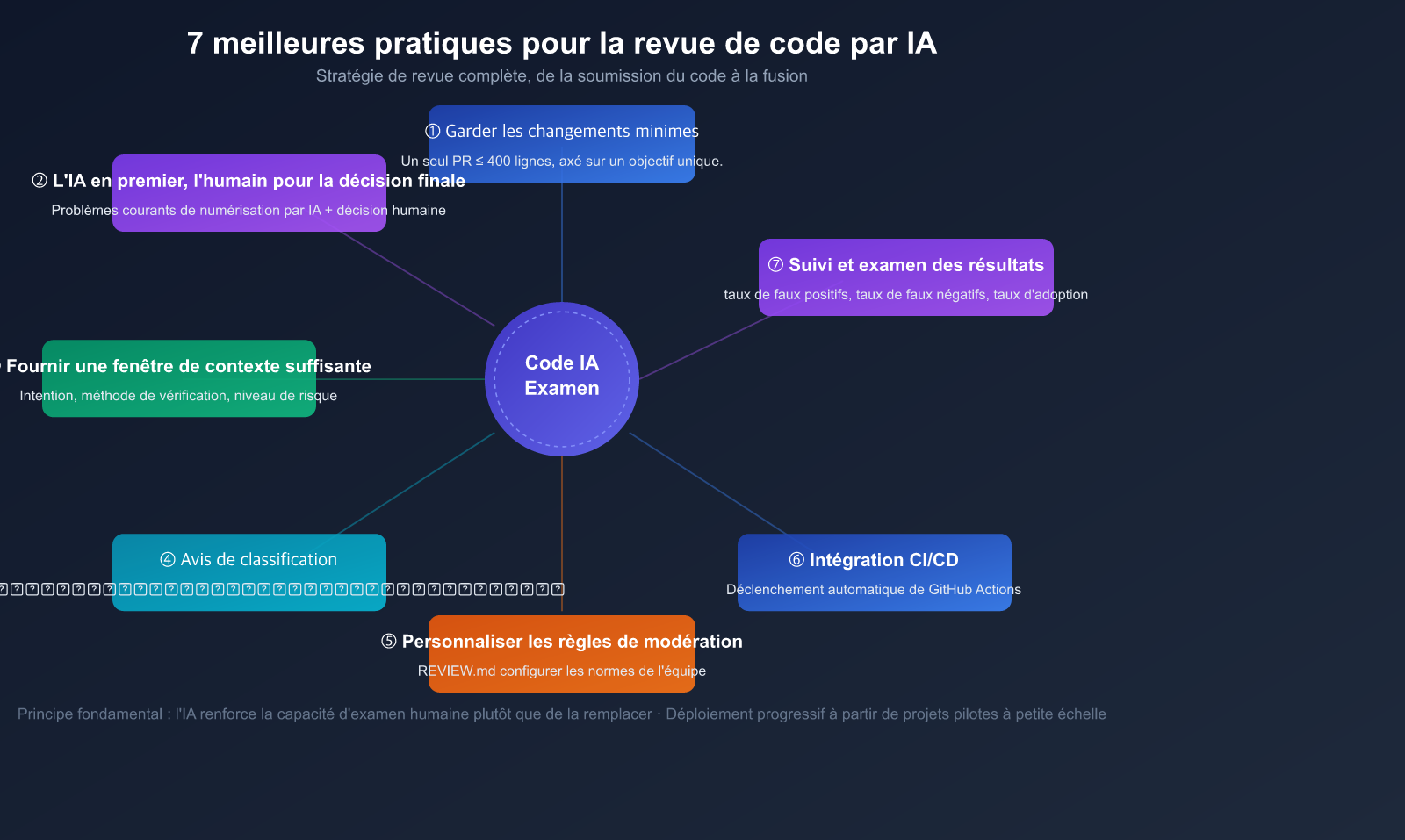
Pratique 1 : Garder les changements petits et ciblés
Un relecteur IA perd significativement en cohérence après plus de 1000 lignes de diff. Même si Claude Opus 4.6 dispose d'une fenêtre de contexte d'un million de jetons, la qualité de la revue sur des changements massifs reste inférieure à celle sur des changements plus restreints.
Méthode concrète :
- Limiter chaque PR à 200-400 lignes.
- Diviser les refactorisations importantes en plusieurs PR logiquement indépendants.
- Chaque PR doit se concentrer sur une seule tâche.
Pratique 2 : IA en premier, humain en dernier
Le flux de travail le plus efficace est le modèle de "revue à deux niveaux" :
Soumission de code → Revue automatique par IA (première passe)
↓
Marquage des problèmes + classification par sévérité
↓
Le relecteur humain se concentre sur les zones à haut risque (décision finale)
↓
Fusion ou rejet
L'IA se charge de scanner tous les problèmes courants (style, nommage, code mort, bugs simples), tandis que l'humain se concentre sur :
- La pertinence de l'architecture
- L'exactitude de la logique métier
- Les décisions critiques de sécurité
- L'évaluation de l'impact sur les performances
Pratique 3 : Fournir un contexte suffisant
Plus vous donnez d'informations à l'IA, meilleure sera la qualité de la revue. Il est recommandé d'inclure dans la description de la PR :
## Objectif du changement
Expliquez brièvement en 1 ou 2 phrases pourquoi cette modification est nécessaire.
## Méthode de vérification
- [ ] Tests unitaires réussis
- [ ] Tests manuels effectués sur le scénario XX
- [ ] Aucune régression de performance constatée
## Niveau de risque
Faible/Moyen/Élevé + Explication
## Déclaration d'assistance IA
Dans le cadre de cette modification, la partie XX a été générée par une IA ; veuillez y accorder une attention particulière lors de votre examen.
## Zone de focus manuel
Veuillez porter une attention particulière aux changements de logique d'autorisation dans le répertoire `src/auth/`.
```markdown
### Pratique 4 : Marquage hiérarchique des commentaires de revue
Un problème courant avec la revue par IA est le "trop-plein de bruit" : mélanger les suggestions de style avec les bugs critiques, ce qui conduit les développeurs à ignorer les retours importants.
**Niveaux de sévérité recommandés pour le marquage** :
| Marque | Signification | Traitement |
|------|------|----------|
| 🔴 **Bug** | Défaut devant être corrigé avant la fusion | Bloque la fusion |
| 🟡 **Nit** | Petit problème à corriger, mais non bloquant | Correction optionnelle |
| 🟣 **Pre-existing** | Ancien problème non introduit par cette PR | Noté, mais non bloquant |
| 💡 **Suggestion** | Suggestion d'amélioration | Décidé après discussion |
La fonctionnalité native de revue de code de Claude Code a déjà implémenté ce système de classification (Rouge/Jaune/Violet).
### Pratique 5 : Personnalisation des règles de revue
Une revue par IA généraliste peut ne pas correspondre aux normes de votre équipe. Personnalisez le comportement de revue via un fichier de configuration :
```markdown
# REVIEW.md (à placer à la racine du projet)
## Points à vérifier obligatoirement
- Toutes les requêtes de base de données doivent utiliser des instructions paramétrées
- Les points de terminaison API doivent inclure un middleware d'authentification
- Toutes les entrées utilisateur doivent être validées
Ce qui peut être ignoré
- Style de nommage des classes CSS (déjà formaté automatiquement par Prettier)
- Tri des imports (déjà géré par Ruff)
- Langue des commentaires (chinois ou anglais acceptés)
Conventions d'équipe
- Privilégier la composition plutôt que l'héritage
- Utiliser le pattern Result pour la gestion des erreurs
- Niveaux de journalisation : INFO pour les événements métier, DEBUG pour le débogage
Pratique 6 : Intégration dans le pipeline CI/CD
La revue de code par IA doit être automatisée, et non déclenchée manuellement.
Méthode d'intégration recommandée :
# Exemple GitHub Actions
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
Vous pouvez également effectuer des revues personnalisées en appelant directement le modèle Claude via l'API :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Tu es un expert en revue de code.
Analyse les modifications de code suivantes et classe-les par niveau de gravité :
- 🔴 Bug : doit être corrigé
- 🟡 Nit : suggestion mineure
- 💡 Suggestion : conseil d'amélioration
Pour chaque problème, indique le numéro de ligne et la solution proposée."""},
{"role": "user", "content": f"Veuillez examiner les modifications de code suivantes :\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Pratique 7 : Suivi de l'efficacité de la revue
La revue de code par IA ne s'arrête pas au déploiement. Il est nécessaire de suivre en continu des indicateurs clés :
- Taux de faux positifs : combien de problèmes signalés par l'IA sont de réels problèmes
- Taux de faux négatifs : combien de bugs découverts après la mise en production n'ont pas été détectés par l'IA
- Taux d'adoption : proportion de suggestions de l'IA réellement appliquées par les développeurs
- Évolution du temps de revue : le temps moyen de revue par les humains a-t-il diminué ?
💡 Conseil de mise en œuvre : Si votre équipe débute avec la revue de code par IA, commencez par tester sur des PR non critiques. Utilisez Claude Sonnet 4.6 via APIYI (apiyi.com) pour vos premiers essais ; le coût est 5 fois inférieur à celui d'Opus, pour une qualité de revue proche, ce qui en fait la solution la plus rentable pour démarrer.
Pourquoi recommander Claude Opus 4.6 et Sonnet 4.6 pour la revue de code
Parmi la multitude de modèles d'IA disponibles, la série Claude 4.6 possède des atouts uniques pour les scénarios de revue de code.
Comparaison des paramètres clés des modèles Claude 4.6
| Paramètre | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| ID du modèle | claude-opus-4-6 |
claude-sonnet-4-6 |
| Date de sortie | 5 février 2026 | 17 février 2026 |
| Fenêtre de contexte | 1 million de jetons (bêta) | 1 million de jetons (bêta) |
| Sortie maximale | 128K jetons | 64K jetons |
| SWE-bench Verified | 81,42 % | 79,6 % |
| Tarification (Entrée/Sortie) | 5 $/25 $ par million de jetons | 3 $/15 $ par million de jetons |
| Scénarios d'usage | Revue d'architecture complexe, audit de sécurité | Revue de PR quotidienne, vérification de style |
| Prix APIYI | Plus avantageux | Plus avantageux |
Avantage 1 : Fenêtre de contexte de 1 million de jetons
C'est l'avantage technique le plus crucial pour la revue de code.
Une PR (Pull Request) dans un grand projet peut impliquer des dizaines de fichiers. Les limites des fenêtres de contexte des modèles d'IA traditionnels vous obligent à tronquer le code, empêchant ainsi l'examinateur de voir le contexte complet.
La fenêtre de 1 million de jetons de Claude 4.6 permet d'intégrer en une seule fois :
- Le diff complet de la PR (généralement de quelques centaines à quelques milliers de lignes)
- L'intégralité du code des fichiers concernés (chaînes d'import, fonctions appelées)
- Le graphe des dépendances et les définitions de types
- Les fichiers de test et de configuration
- Le README et la documentation d'architecture du projet
Cela signifie que l'IA peut effectuer une revue en comprenant parfaitement le contexte, tout comme un développeur expérimenté.
Avantage 2 : Capacités de raisonnement inter-fichiers de haut niveau
La valeur ajoutée d'une revue de code ne réside pas dans la recherche d'erreurs de syntaxe, mais dans la détection de problèmes logiques entre plusieurs fichiers.
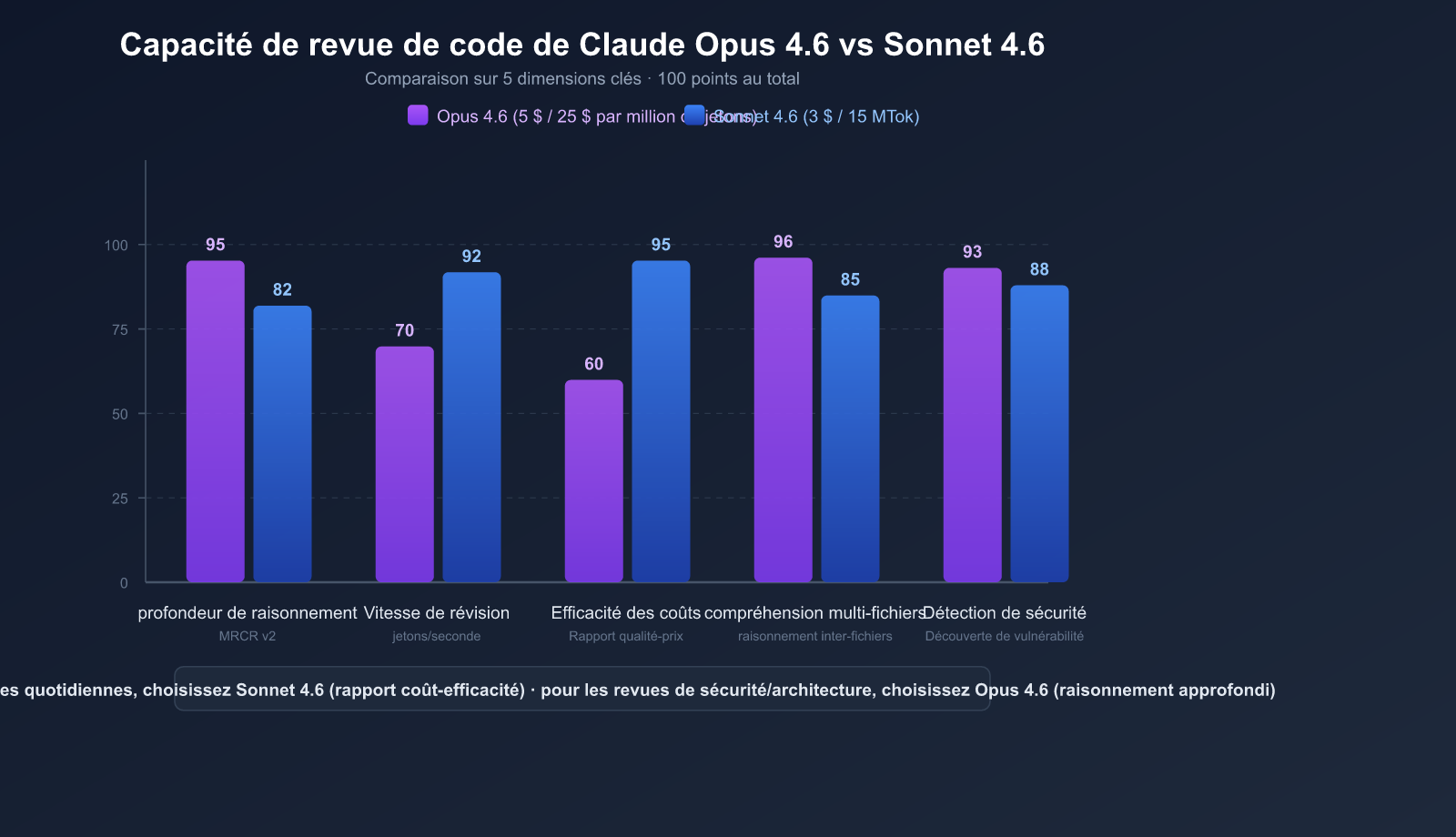
Claude Opus 4.6 obtient un score de 76 % au test MRCR v2 (raisonnement par récupération multi-fichiers), contre seulement 18,5 % pour Sonnet 4.5. Cela signifie qu'Opus 4.6 excelle dans les scénarios suivants :
- Détecter qu'une modification d'interface dans le fichier A n'a pas été répercutée dans les appels du fichier B.
- Découvrir des lacunes de validation dans le flux de données, de l'entrée jusqu'à la base de données.
- Identifier des conditions de concurrence (race conditions) dans des scénarios multi-threadés.
Cas réel : Lors de tests, Claude Opus 4.6 a identifié une condition de concurrence dans une PR de migration de base de données de 2 400 lignes — un défaut de logique de rollback qui ne se déclenchait qu'en cas d'interruption de la migration. C'est un scénario que les tests automatisés ne peuvent pas couvrir.
Avantage 3 : Profondeur de réflexion adaptative
Claude 4.6 introduit le mode adaptive thinking : l'IA décide automatiquement de la "profondeur de réflexion" nécessaire en fonction de la complexité du problème.
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Revue de code pour détecter des problèmes de sécurité."},
{"role": "user", "content": diff_content}
],
# Réflexion adaptative de Claude 4.6 : rapide pour les questions simples, approfondie pour les complexes
extra_body={"thinking": {"type": "adaptive"}}
)
- Problème de style simple → Jugement rapide, économie de jetons.
- Problème complexe de concurrence ou de sécurité → Raisonnement approfondi, analyse détaillée fournie.
Avantage 4 : Détection de failles de sécurité bien supérieure aux outils traditionnels
Les recherches montrent que les LLM de niveau Claude surpassent nettement les outils d'analyse statique traditionnels pour la revue de sécurité :
| Dimension de comparaison | Claude (LLM) | CodeQL (SAST traditionnel) |
|---|---|---|
| Nombre de failles détectées | 55 | 27 |
| Découverte de failles inconnues | 4 vulnérabilités zero-day | 0 |
| Catégories détectées | Injection, authentification, fuite de données, chiffrement, défauts logiques, etc. (10+) | Basé sur la correspondance de modèles |
| Support linguistique | N'importe quel langage | Langages spécifiques |
| Filtrage des faux positifs | Automatique par l'IA | Nécessite une intervention humaine |
Types de failles de sécurité que Claude peut détecter :
- Injections SQL/Commande/LDAP/XPath/NoSQL
- Défauts d'authentification et d'autorisation
- Clés codées en dur, logs de données sensibles
- Algorithmes de chiffrement faibles, mauvaise gestion des clés
- Conditions de concurrence (TOCTOU)
- Configurations par défaut non sécurisées, CORS
- RCE par désérialisation, injection pickle/eval
- XSS (réfléchies, stockées, DOM)
Avantage 5 : Flexibilité des coûts
Le prix de Sonnet 4.6 est seulement 1/5 de celui d'Opus 4.6, tout en n'étant distancé que de 1 à 2 points de pourcentage sur le benchmark SWE-bench.
Stratégie de sélection recommandée :
| Scénario | Modèle recommandé | Raison |
|---|---|---|
| Revue de PR quotidienne | Sonnet 4.6 | Meilleur rapport qualité-prix, qualité proche d'Opus |
| Code critique pour la sécurité | Opus 4.6 | Raisonnement le plus profond, aucune faille critique manquée |
| Revue de refactorisation majeure | Opus 4.6 | Meilleure capacité de raisonnement inter-fichiers |
| Vérification de style et normes | Sonnet 4.6 | Tâches simples ne nécessitant pas Opus |
| Revue automatique CI/CD | Sonnet 4.6 | Coûts maîtrisés, idéal pour chaque commit |
🚀 Conseil de sélection : La recommandation officielle d'Anthropic est d'utiliser "Sonnet 4.6 par défaut, et de passer à Opus 4.6 uniquement lorsque le raisonnement le plus profond est requis". Dans les tests internes de Claude Code, le taux de préférence des développeurs pour Sonnet 4.6 est 70 % plus élevé que pour la génération précédente (Sonnet 4.5), et même 59 % plus élevé que pour l'ancien fleuron, Opus 4.5. Vous pouvez profiter de tarifs plus avantageux en appelant les deux modèles via APIYI apiyi.com.
Flux de travail complet de revue de code par IA
Aperçu du flux de travail
Développeur soumet une PR
↓
Déclenchement automatique de la revue par IA (Sonnet 4.6)
↓
┌─── Changement à faible risque ──→ IA marque "Nit", approbation automatique
│
├─── Changement à risque moyen ──→ IA signale des problèmes, confirmation humaine rapide
│
└─── Changement à haut risque ──→ Escalade vers Opus 4.6 pour une revue approfondie
↓
Validation finale par un expert en sécurité
↓
Fusion ou rejet
Exemple de code : Mettre en place un système de revue par IA personnalisé
import openai
import subprocess
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
def get_pr_diff(pr_number):
"""Récupère le contenu diff de la PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Sélectionne le modèle pour la revue selon le niveau de risque"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Révisez les changements suivants:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Exemple d'utilisation
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Voir le modèle d’invite (Prompt) de revue complet
REVIEW_PROMPT = """Vous êtes un ingénieur logiciel senior expérimenté effectuant une revue de code.
## Points d'attention pour la revue
1. **Exactitude logique**: Le code remplit-il les fonctionnalités attendues ? Y a-t-il des cas limites oubliés ?
2. **Sécurité**: Existe-t-il des risques de sécurité tels que des injections, XSS, CSRF, ou des clés codées en dur ?
3. **Performance**: Y a-t-il des requêtes N+1, des allocations mémoire inutiles ou des opérations bloquantes ?
4. **Maintenabilité**: Le nommage est-il clair ? La complexité est-elle contrôlée ? Y a-t-il du code dupliqué ?
5. **Gestion des erreurs**: Les exceptions sont-elles correctement capturées et traitées ?
6. **Sécurité de la concurrence**: Existe-t-il des risques de conditions de concurrence (race conditions) ou d'interblocage (deadlocks) ?
"""
Format de sortie
Classez les résultats par niveau de gravité :
🔴 À corriger impérativement (Bug/Sécurité)
- [Nom du fichier:Numéro de ligne] Description du problème
- Impact : …
- Suggestion de correction : …
🟡 Correction recommandée (Nit)
- [Nom du fichier:Numéro de ligne] Description du problème
- Suggestion : …
💡 Suggestions d'amélioration (Suggestion)
- [Nom du fichier:Numéro de ligne] Point d'amélioration
- Explication : …
Si la qualité du code est bonne et qu'aucun problème n'est détecté, veuillez indiquer explicitement : "Examen réussi, aucun problème détecté".
Ne créez pas de problèmes inexistants juste pour remplir le rapport.
💰 Optimisation des coûts : Utilisez APIYI (apiyi.com) pour invoquer le modèle Claude 4.6 lors de vos revues de code, à un tarif plus avantageux que l'officiel. La plateforme permet de basculer facilement entre Opus 4.6 et Sonnet 4.6, vous permettant de choisir automatiquement le modèle le plus rentable selon le niveau de risque de votre PR.
Limites et points d'attention de la revue de code par IA
5 limites à connaître absolument
- Taux de rappel d'environ 50 % : Les vulnérabilités détectées par les grands modèles de langage sont généralement réelles (précision d'environ 80 %), mais ils laissent passer environ la moitié des failles existantes.
- Risque d'injection d'invite : Les outils de revue par IA sont exposés au risque d'injection lorsqu'ils traitent des PR provenant de sources non fiables.
- Angle mort contextuel : L'IA ne peut pas comprendre le contexte métier du projet, les compétences des membres de l'équipe ou les décisions historiques.
- Coûts cumulés : Si vous déclenchez une revue à chaque commit, les frais peuvent rapidement grimper pour les dépôts à haute fréquence.
- Risque de dépendance excessive : Les membres de l'équipe pourraient progressivement relâcher leur rigueur lors des revues manuelles.
Stratégies d'atténuation
| Limite | Stratégie d'atténuation |
|---|---|
| Taux de détection faible | Double garantie : revue par IA + revue humaine |
| Injection d'invite | Ne réviser que les PR provenant de sources de confiance |
| Manque de contexte | Fournir le contexte du projet dans un fichier REVIEW.md |
| Coûts élevés | Utiliser Sonnet 4.6 au quotidien et Opus 4.6 pour les chemins critiques |
| Dépendance excessive | Établir un système de "suggestions de l'IA + décision humaine" |
FAQ
Q1 : L’examen de code par IA peut-il remplacer totalement l’examen humain ?
Non. L'examen de code par IA est un outil d'"augmentation" et non de "remplacement". L'IA excelle à détecter les problèmes récurrents (style, bugs courants, modèles de vulnérabilités connus), mais elle ne peut pas saisir l'intention métier, les compromis derrière les décisions architecturales ou les connaissances tacites liées à la collaboration d'équipe. La meilleure pratique consiste à laisser l'IA effectuer un premier balayage, puis à laisser l'humain porter le jugement final. En utilisant le modèle Claude 4.6 via APIYI apiyi.com, vous pouvez rapidement mettre en place un flux de travail d'examen par IA, permettant aux relecteurs humains de se concentrer sur des tâches à plus forte valeur ajoutée.
Q2 : Faut-il choisir Opus 4.6 ou Sonnet 4.6 pour l’examen de code ?
Pour la plupart des scénarios, choisissez Sonnet 4.6. Il n'est qu'à 1 ou 2 points de pourcentage derrière Opus sur SWE-bench, mais son coût est cinq fois inférieur. Il n'est nécessaire de passer à Opus 4.6 que pour l'examen de code critique en matière de sécurité, les refontes architecturales majeures ou lorsque vous avez besoin d'un raisonnement approfondi sur plusieurs fichiers. Grâce à APIYI apiyi.com, vous pouvez basculer entre les deux modèles de manière flexible selon vos besoins.
Q3 : Quel est le coût approximatif de l’examen de code par IA ?
La fonctionnalité d'examen native de Claude Code coûte en moyenne 15 à 25 $ par session, selon la taille de la PR et la complexité de la base de code. Si vous construisez votre propre système d'examen via API, le coût dépend de la consommation de jetons (tokens). Prenons l'exemple de Sonnet 4.6 : l'examen d'une PR de 500 lignes (environ 2 000 jetons en entrée + 1 000 jetons en sortie) coûte environ 0,02 $. Vous pouvez également bénéficier de tarifs plus avantageux via APIYI apiyi.com.
Q4 : Comment évaluer l’efficacité de l’examen de code par IA ?
Nous recommandons de suivre 4 indicateurs clés : (1) Taux de faux positifs — la proportion de problèmes réels parmi ceux signalés par l'IA ; (2) Taux de détection manquée — la proportion de bugs découverts après la mise en production que l'IA n'avait pas signalés ; (3) Taux d'adoption — la proportion de suggestions de l'IA réellement adoptées par les développeurs ; (4) Évolution du temps d'examen — le temps moyen d'examen par les relecteurs humains a-t-il diminué ? Il est conseillé de faire un point hebdomadaire pendant les deux premiers mois.
Q5 : Comment débuter rapidement avec l’examen de code par IA ?
La méthode la plus simple se décline en trois étapes : (1) Inscrivez-vous sur APIYI apiyi.com pour obtenir une clé API ; (2) Effectuez un test d'examen sur une PR récente avec Sonnet 4.6 ; (3) Décidez, en fonction des résultats, si vous souhaitez l'intégrer à votre automatisation CI/CD. Commencez par tester sur des parties non critiques du code avant de généraliser à l'ensemble du projet.
Conclusion : L'examen de code par IA est un multiplicateur d'efficacité pour les équipes
L'examen de code par IA n'est plus une option, c'est une compétence indispensable pour les équipes de développement en 2026. Avec une fenêtre de contexte d'un million de jetons, un score de plus de 81 % sur SWE-bench, un raisonnement adaptatif et de puissantes capacités de détection de sécurité, Claude Opus 4.6 et Sonnet 4.6 sont actuellement les meilleurs choix pour l'examen de code.
Conseils de sélection :
- Examen quotidien : Par défaut, Sonnet 4.6, le champion du rapport qualité-prix.
- Examen de sécurité/architecture : Passez à Opus 4.6 pour une profondeur de raisonnement sans compromis.
Nous vous recommandons d'accéder rapidement à toute la gamme de modèles Claude 4.6 via APIYI apiyi.com pour doter votre équipe de capacités d'examen de code par IA au meilleur coût.
Références
-
Officiel Anthropic : Annonces de sortie de Claude Opus 4.6 et Sonnet 4.6
- Lien :
anthropic.com/news
- Lien :
-
Documentation de revue de code Claude Code : Guide d'utilisation de la fonctionnalité de revue native
- Lien :
code.claude.com/docs/en/code-review
- Lien :
-
Claude Code Security Review : Action GitHub de revue de sécurité open source
- Lien :
github.com/anthropics/claude-code-security-review
- Lien :
-
Meilleures pratiques de revue de code par IA 2026 : Analyse sectorielle complète
- Lien :
verdent.ai/guides
- Lien :
-
Document de recherche IRIS : Détection de vulnérabilités par analyse statique assistée par Grand modèle de langage
- Lien :
arxiv.org
- Lien :
Auteur : Équipe APIYI | Explorez les meilleures pratiques de l'IA appliquée au développement logiciel. Visitez APIYI sur apiyi.com pour obtenir les API et le support technique de la gamme complète des modèles Claude 4.6.