2026 年,41% 的代碼提交已經是 AI 輔助生成的——但 AI 生成的代碼缺陷率比人類代碼高 1.7 倍。代碼生成越來越快,但代碼審查的產能嚴重不足,預計 2026 年將出現 40% 的質量缺口。
AI 代碼審查不是"要不要做"的問題,而是"怎麼做好"的問題。本文將介紹 7 個經過驗證的最佳實踐,並深入分析爲什麼 Claude Opus 4.6 和 Sonnet 4.6 是目前最適合代碼審查的 AI 模型。
核心價值: 讀完本文,你將掌握 AI 代碼審查的完整工作流,並瞭解如何選擇最合適的模型來提升團隊代碼質量。
<!– 裝飾 –>
<!– 標題 –>
<!– 左側:代碼 Diff 模擬 –>
<!– Diff 頂欄 –>
<!– Diff 內容 –>
<!– AI 審查氣泡指向第14行 –>
<!– 右側:Claude 4.6 能力標註 –>
<!– 能力1 –>
<!– 能力2 –>
<!– 能力3 –>
<!– 能力4 –>
<!– 底部數據標籤 –>
AI 代碼審查的現狀:爲什麼現在必須重視
2026 年代碼審查面臨的挑戰
| 挑戰 | 數據 | 影響 |
|---|---|---|
| AI 代碼佔比激增 | 41% 的提交由 AI 輔助生成 | 審查需求激增 |
| AI 代碼缺陷率 | 比人類代碼高 1.7 倍 | 需要更嚴格的審查 |
| 質量缺口 | 預計 2026 年出現 40% | 審查產能跟不上生成速度 |
| 安全風險 | 45% 的 AI 代碼引入 OWASP Top 10 漏洞 | 安全審查尤爲緊迫 |
| 建議採納率 | AI 建議僅 16.6%,人類建議 56.5% | AI 審查質量有待提升 |
AI 代碼審查 vs 人類代碼審查
AI 不是來替代人類審查者的,而是來增強人類的審查能力。使用 AI 代碼審查的團隊報告:
- 審查時間減少 40-60%
- 缺陷檢出率提升——尤其是安全漏洞和邊界條件
- 代碼風格一致性大幅改善
但 AI 審查也有明確的邊界:
- ❌ 無法理解業務截止日期和項目上下文
- ❌ 無法感知遺留系統的歷史妥協
- ❌ 無法承擔審查的最終責任
- ❌ 無法進行團隊知識傳承和 mentor
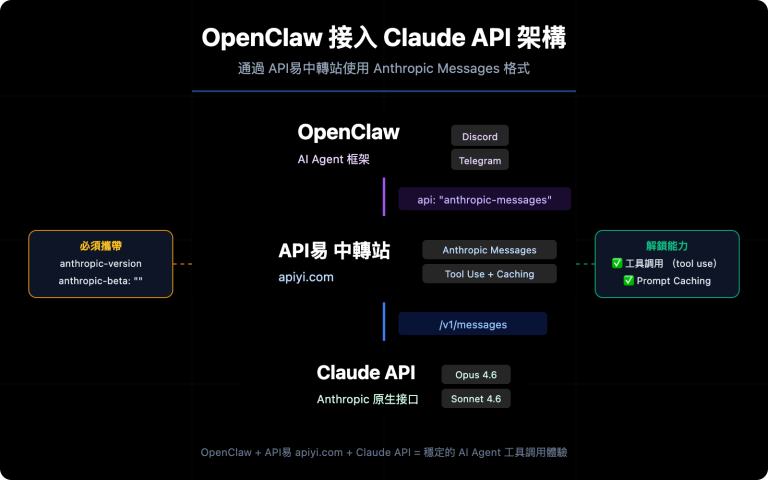
🎯 最佳策略: AI 做第一遍掃描 (風格、bug、安全),人類做最終判斷 (架構、意圖、風險)。通過 API易 apiyi.com 平臺調用 Claude Opus 4.6 或 Sonnet 4.6 的 API,可以快速將 AI 代碼審查集成到現有 CI/CD 流程中。
AI 代碼審查的 7 個最佳實踐
<!– 標題 –>
<!– 中心節點 –>
<!– 連線 –>
<!– 實踐1: 保持變更小 (正上方) –>
<!– 實踐2: AI先行人類終審 (左上) –>
<!– 實踐3: 提供充分上下文 (左) –>
<!– 實踐4: 分級標記意見 (左下) –>
<!– 實踐5: 定製審查規則 (下) –>
<!– 實踐6: 集成CI/CD (右下) –>
<!– 實踐7: 追蹤審查效果 (右) –>
<!– 底部說明 –>
實踐一:保持變更小而聚焦
AI 審查者在 diff 超過 1000 行後會顯著失去連貫性。即使 Claude Opus 4.6 擁有 100 萬 token 的上下文窗口,大型變更的審查質量仍不如小型變更。
具體做法:
- 單個 PR 控制在 200-400 行以內
- 大型重構拆分爲多個邏輯獨立的 PR
- 每個 PR 只做一件事
實踐二:AI 先行,人類終審
最有效的工作流是"雙層審查"模式:
代碼提交 → AI 自動審查 (第一遍)
↓
標記問題 + 嚴重級別分類
↓
人類審查者聚焦高風險區域 (終審)
↓
合併或駁回
AI 負責掃描所有常規問題 (風格、命名、死代碼、簡單 bug),人類聚焦於:
- 架構合理性
- 業務邏輯正確性
- 安全關鍵決策
- 性能影響評估
實踐三:提供充分的上下文
給 AI 審查者的信息越多,審查質量越高。推薦在 PR 描述中包含:
## 變更意圖
用 1-2 句話說明"爲什麼做這個變更"
## 驗證方式
- [ ] 單元測試通過
- [ ] 手動測試了 XX 場景
- [ ] 性能無回退
## 風險等級
低/中/高 + 說明
## AI 輔助聲明
本次變更中 XX 部分由 AI 生成,請重點審查
## 人工聚焦區域
請重點關注 src/auth/ 目錄下的權限邏輯變更
實踐四:分級標記審查意見
AI 審查的一個常見問題是"噪音太多"——把風格建議和嚴重 bug 混在一起,導致開發者忽視重要反饋。
推薦的嚴重級別標記:
| 標記 | 含義 | 處理方式 |
|---|---|---|
| 🔴 Bug | 合併前必須修復的缺陷 | 阻塞合併 |
| 🟡 Nit | 值得修復但不阻塞的小問題 | 可選修復 |
| 🟣 Pre-existing | 不是本次引入的舊問題 | 記錄但不阻塞 |
| 💡 Suggestion | 改進建議 | 討論後決定 |
Claude Code 的原生代碼審查功能已經實現了這套分級系統 (Red/Yellow/Purple)。
實踐五:定製審查規則
通用的 AI 審查可能不符合團隊規範。通過配置文件定製審查行爲:
# REVIEW.md (放在項目根目錄)
## 必須檢查
- 所有數據庫查詢必須使用參數化語句
- API 端點必須包含認證中間件
- 所有用戶輸入必須做校驗
## 可以跳過
- CSS 類名的命名風格 (已用 prettier 自動格式化)
- import 排序 (已用 ruff 自動處理)
- 註釋語言 (中英文均可)
## 團隊約定
- 優先使用組合而非繼承
- 錯誤處理使用 Result 模式
- 日誌級別: 業務事件用 INFO,調試用 DEBUG
實踐六:集成到 CI/CD 流水線
AI 代碼審查應該是自動化的,而非手動觸發的。
推薦的集成方式:
# GitHub Actions 示例
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
也可以通過 API 直接調用 Claude 模型進行自定義審查:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """你是資深代碼審查專家。
請分析以下代碼變更,按嚴重級別分類:
- 🔴 Bug: 必須修復
- 🟡 Nit: 建議修復
- 💡 Suggestion: 改進建議
每個問題指出具體行號和修復方案。"""},
{"role": "user", "content": f"請審查以下代碼變更:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
實踐七:追蹤審查效果
AI 代碼審查不是部署後就不管了。需要持續追蹤關鍵指標:
- 誤報率 (False Positive Rate): AI 標記的問題中有多少是真實問題
- 漏檢率 (False Negative Rate): 上線後發現的 bug 中有多少 AI 沒有發現
- 採納率: 開發者實際採納 AI 建議的比例
- 審查時間變化: 人類審查者的平均審查時間是否減少
💡 實施建議: 如果你的團隊剛開始嘗試 AI 代碼審查,建議從非關鍵路徑的 PR 開始試點。通過 API易 apiyi.com 調用 Claude Sonnet 4.6 做初期試驗,成本僅爲 Opus 的 1/5,審查質量接近 Opus 水平,是性價比最高的起步方案。
爲什麼推薦 Claude Opus 4.6 和 Sonnet 4.6 做代碼審查
在衆多 AI 模型中,Claude 4.6 系列在代碼審查場景下有着獨特的優勢。
Claude 4.6 模型核心參數對比
| 參數 | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| 模型 ID | claude-opus-4-6 |
claude-sonnet-4-6 |
| 發佈時間 | 2026年2月5日 | 2026年2月17日 |
| 上下文窗口 | 100 萬 token (beta) | 100 萬 token (beta) |
| 最大輸出 | 128K token | 64K token |
| SWE-bench Verified | 81.42% | 79.6% |
| 定價 (輸入/輸出) | $5/$25 每百萬 token | $3/$15 每百萬 token |
| 適用場景 | 複雜架構審查、安全審計 | 日常 PR 審查、風格檢查 |
| API易價格 | 更優惠 | 更優惠 |
<!– 標題 –>
<!– 圖例 –>
<!– X軸基線 –>
<!– Y軸刻度線 –>
<!– 網格線 –>
<!– 維度1: 推理深度 Opus=95 Sonnet=82 –>
<!– 維度2: 審查速度 Opus=70 Sonnet=92 –>
<!– 維度3: 成本效率 Opus=60 Sonnet=95 –>
<!– 維度4: 多文件理解 Opus=96 Sonnet=85 –>
<!– 維度5: 安全檢測 Opus=93 Sonnet=88 –>
<!– 底部總結 –>
優勢一:100 萬 token 上下文窗口
這是代碼審查場景下最關鍵的技術優勢。
大型項目的一個 PR 可能涉及幾十個文件。傳統 AI 模型的上下文窗口限制意味着你必須截斷代碼,導致審查者看不到完整上下文。
Claude 4.6 的 100 萬 token 上下文可以一次性容納:
- 完整的 PR diff (通常幾百到幾千行)
- 相關文件的全部代碼 (import 鏈、被調用的函數)
- 依賴關係圖和類型定義
- 測試文件和配置文件
- 項目的 README 和架構文檔
這意味着 AI 可以像資深開發者一樣,在理解完整上下文的情況下進行審查。
優勢二:頂級的跨文件推理能力
代碼審查最有價值的地方不是找語法錯誤,而是發現跨文件的邏輯問題。
Claude Opus 4.6 在 MRCR v2 (多針多文件檢索推理) 測試中得分 76%,而 Sonnet 4.5 僅爲 18.5%。這意味着 Opus 4.6 在以下場景表現卓越:
- 檢測 A 文件修改了接口,但 B 文件的調用沒有同步更新
- 發現數據流從入口到數據庫全鏈路上的校驗缺失
- 識別併發場景下的競態條件
真實案例: 在測試中,Claude Opus 4.6 在一個 2400 行的數據庫遷移 PR 中發現了一個競態條件——只有在遷移中途中斷時纔會觸發的回滾邏輯缺陷。這是自動化測試無法覆蓋的場景。
優勢三:自適應思考深度
Claude 4.6 引入了 adaptive thinking 模式——AI 會根據問題複雜度自動決定"想多深"。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Review this code change for security issues."},
{"role": "user", "content": diff_content}
],
# Claude 4.6 自適應思考:簡單問題快速過,複雜問題深入分析
extra_body={"thinking": {"type": "adaptive"}}
)
- 遇到簡單的風格問題 → 快速判斷,節省 token
- 遇到複雜的併發或安全問題 → 深入推理,給出詳盡分析
優勢四:安全漏洞檢測遠超傳統工具
研究表明,Claude 級別的 LLM 在安全代碼審查中顯著優於傳統靜態分析工具:
| 對比維度 | Claude (LLM) | CodeQL (傳統 SAST) |
|---|---|---|
| 檢測漏洞數 | 55 個 | 27 個 |
| 未知漏洞發現 | 4 個零日漏洞 | 0 個 |
| 檢測類別 | 注入、認證、數據泄露、加密、邏輯缺陷等 10+ 類 | 基於模式匹配 |
| 語言支持 | 任何編程語言 | 特定語言 |
| 誤報過濾 | AI 自動過濾 | 需人工過濾 |
Claude 可以檢測的安全漏洞類型:
- SQL/命令/LDAP/XPath/NoSQL 注入
- 認證和授權缺陷
- 硬編碼密鑰、敏感數據日誌
- 弱加密算法、密鑰管理不當
- 競態條件 (TOCTOU)
- 不安全的默認配置、CORS
- 反序列化 RCE、pickle/eval 注入
- XSS (反射型、存儲型、DOM 型)
優勢五:成本靈活性
Sonnet 4.6 的定價僅爲 Opus 4.6 的 1/5,但在 SWE-bench 上僅落後 1-2 個百分點。
推薦的選型策略:
| 場景 | 推薦模型 | 理由 |
|---|---|---|
| 日常 PR 審查 | Sonnet 4.6 | 性價比最高,質量接近 Opus |
| 安全關鍵代碼 | Opus 4.6 | 最深推理,不漏過高危問題 |
| 大型重構審查 | Opus 4.6 | 跨文件推理能力最強 |
| 風格和規範檢查 | Sonnet 4.6 | 簡單任務無需 Opus |
| CI/CD 自動審查 | Sonnet 4.6 | 成本可控,適合每次提交觸發 |
🚀 選型建議: Anthropic 官方的建議是"默認使用 Sonnet 4.6,僅在需要最深推理時升級到 Opus 4.6"。在 Claude Code 的內部測試中,開發者對 Sonnet 4.6 的偏好率比上一代 Sonnet 4.5 高 70%,甚至比前旗艦 Opus 4.5 高 59%。通過 API易 apiyi.com 調用兩個模型都可以享受更優惠的價格。
完整的 AI 代碼審查工作流
工作流總覽
開發者提交 PR
↓
AI 自動觸發審查 (Sonnet 4.6)
↓
┌─── 低風險變更 ──→ AI 標記 Nit,自動通過
│
├─── 中風險變更 ──→ AI 標記問題,人工快速確認
│
└─── 高風險變更 ──→ 升級到 Opus 4.6 深度審查
↓
安全專家人工終審
↓
合併或駁回
代碼示例:搭建自定義 AI 審查系統
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
def get_pr_diff(pr_number):
"""獲取 PR 的 diff 內容"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""根據風險級別選擇模型進行審查"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"審查以下變更:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# 使用示例
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
查看完整審查 Prompt 模板
REVIEW_PROMPT = """你是一位經驗豐富的高級軟件工程師,正在進行代碼審查。
## 審查重點
1. **邏輯正確性**: 代碼是否實現了預期功能?是否有邊界條件遺漏?
2. **安全性**: 是否存在注入、XSS、CSRF、硬編碼密鑰等安全風險?
3. **性能**: 是否有 N+1 查詢、不必要的內存分配、阻塞操作?
4. **可維護性**: 命名是否清晰?複雜度是否可控?是否有重複代碼?
5. **錯誤處理**: 異常是否被正確捕獲和處理?
6. **併發安全**: 是否存在競態條件或死鎖風險?
## 輸出格式
按嚴重級別分類輸出:
### 🔴 必須修復 (Bug/Security)
- [文件名:行號] 問題描述
- 影響: ...
- 建議修復: ...
### 🟡 建議修復 (Nit)
- [文件名:行號] 問題描述
- 建議: ...
### 💡 改進建議 (Suggestion)
- [文件名:行號] 改進點
- 說明: ...
如果代碼質量良好且沒有發現問題,請明確說明"審查通過,未發現問題"。
不要爲了輸出而編造不存在的問題。"""
💰 成本優化: 通過 API易 apiyi.com 調用 Claude 4.6 模型進行代碼審查,價格比官方更優惠。平臺支持 Opus 4.6 和 Sonnet 4.6 的靈活切換,可以根據 PR 的風險等級自動選擇最具性價比的模型。
AI 代碼審查的侷限與注意事項
必須瞭解的 5 個侷限
- 召回率約 50%: LLM 發現的漏洞通常是真實的 (精確率 ~80%),但大約會漏掉一半的現有漏洞
- Prompt 注入風險: AI 審查工具處理不可信 PR 時存在被注入的風險
- 上下文盲區: AI 無法理解項目的商業背景、團隊人員能力和歷史決策
- 成本累積: 如果對每次提交都觸發審查,高頻倉庫的費用可能較高
- 過度依賴風險: 團隊成員可能逐漸放鬆人工審查的嚴謹性
規避策略
| 侷限 | 規避方案 |
|---|---|
| 漏檢率高 | AI 審查 + 人工審查雙重保障 |
| Prompt 注入 | 僅審查可信來源的 PR |
| 上下文不足 | 在 REVIEW.md 中提供項目背景 |
| 成本過高 | 日常用 Sonnet 4.6,關鍵路徑用 Opus 4.6 |
| 過度依賴 | 建立"AI 建議 + 人工決策"的制度 |
常見問題
Q1: AI 代碼審查可以完全替代人類審查嗎?
不能。AI 代碼審查是"增強"而非"替代"。AI 擅長髮現模式化的問題 (風格、常見 bug、已知漏洞模式),但無法理解業務意圖、架構決策背後的權衡和團隊協作中的隱性知識。最佳實踐是 AI 做第一遍掃描,人類做最終判斷。通過 API易 apiyi.com 調用 Claude 4.6 模型可以快速搭建 AI 審查流程,讓人類審查者聚焦於更高價值的工作。
Q2: Opus 4.6 和 Sonnet 4.6 選哪個做代碼審查?
大多數場景選 Sonnet 4.6。它在 SWE-bench 上僅比 Opus 低 1-2 個百分點,但成本只有 1/5。只有在審查安全關鍵代碼、大型架構重構、需要深度跨文件推理時才需要升級到 Opus 4.6。通過 API易 apiyi.com 可以按需靈活切換兩個模型。
Q3: AI 代碼審查的成本大約是多少?
Claude Code 原生審查功能平均每次 $15-25,取決於 PR 大小和代碼庫複雜度。如果通過 API 自建審查系統,成本取決於 token 消耗量。以 Sonnet 4.6 爲例,審查一個 500 行的 PR (約 2000 token 輸入 + 1000 token 輸出) 約 $0.02。通過 API易 apiyi.com 還能享受更優惠的價格。
Q4: 如何評估 AI 代碼審查的效果?
建議追蹤 4 個核心指標:(1) 誤報率——AI 標記的問題中真實問題的比例;(2) 漏檢率——上線後發現的 bug 中 AI 未標記的比例;(3) 採納率——開發者實際採納 AI 建議的比例;(4) 審查時間變化——人工審查者的平均審查時間是否減少。前兩個月建議每週覆盤一次。
Q5: 如何快速開始嘗試 AI 代碼審查?
最簡單的方式是三步走:(1) 通過 API易 apiyi.com 註冊獲取 API Key;(2) 用 Sonnet 4.6 對最近的一個 PR 做一次審查測試;(3) 根據效果決定是否接入 CI/CD 自動化。從非關鍵路徑的代碼開始試點,逐步推廣到全量。
總結:AI 代碼審查是團隊效率的倍增器
AI 代碼審查不是可選項,而是 2026 年軟件開發團隊的必備能力。Claude Opus 4.6 和 Sonnet 4.6 憑藉 100 萬 token 上下文、81%+ 的 SWE-bench 得分、自適應思考和強大的安全檢測能力,是目前代碼審查場景下的最優選擇。
選型建議:
- 日常審查: 默認 Sonnet 4.6,性價比之王
- 安全/架構審查: 升級 Opus 4.6,不妥協的推理深度
推薦通過 API易 apiyi.com 快速接入 Claude 4.6 全系列模型,以最優成本爲團隊建立 AI 代碼審查能力。
參考資料
-
Anthropic 官方: Claude Opus 4.6 和 Sonnet 4.6 發佈公告
- 鏈接:
anthropic.com/news
- 鏈接:
-
Claude Code 代碼審查文檔: 原生審查功能使用指南
- 鏈接:
code.claude.com/docs/en/code-review
- 鏈接:
-
Claude Code Security Review: 開源安全審查 GitHub Action
- 鏈接:
github.com/anthropics/claude-code-security-review
- 鏈接:
-
AI 代碼審查最佳實踐 2026: 行業綜合分析
- 鏈接:
verdent.ai/guides
- 鏈接:
-
IRIS 研究論文: LLM 輔助靜態分析漏洞檢測
- 鏈接:
arxiv.org
- 鏈接:
作者: APIYI Team | 探索 AI 賦能軟件開發的最佳實踐,歡迎訪問 API易 apiyi.com 獲取 Claude 4.6 全系列模型的 API 接口和技術支持。