Em 2026, 41% dos commits de código já são gerados com auxílio de IA — mas a taxa de defeitos no código gerado por IA é 1,7 vezes maior do que a do código humano. A geração de código está cada vez mais rápida, mas a capacidade de revisão de código é insuficiente, com uma lacuna de qualidade prevista de 40% para 2026.
A revisão de código por IA não é uma questão de "fazer ou não", mas de "como fazer bem". Este artigo apresenta 7 práticas recomendadas comprovadas e analisa profundamente por que o Claude Opus 4.6 e o Sonnet 4.6 são atualmente os modelos de IA mais adequados para revisão de código.
Valor central: Ao terminar este artigo, você dominará o fluxo de trabalho completo de revisão de código por IA e entenderá como escolher o modelo mais adequado para elevar a qualidade do código da sua equipe.
O estado atual da revisão de código por IA: por que você deve se importar agora
Desafios da revisão de código em 2026
| Desafio | Dados | Impacto |
|---|---|---|
| Aumento de código via IA | 41% dos commits são gerados com auxílio de IA | Demanda por revisão disparou |
| Taxa de falhas na IA | 1,7x maior que a de humanos | Exige revisão mais rigorosa |
| Lacuna de qualidade | Previsão de 40% em 2026 | Capacidade de revisão não acompanha a geração |
| Riscos de segurança | 45% do código de IA introduz vulnerabilidades OWASP Top 10 | Revisão de segurança é urgente |
| Taxa de aceitação | Sugestões de IA: 16,6%; humanas: 56,5% | Qualidade da revisão por IA precisa melhorar |
Revisão de código por IA vs. Revisão humana
A IA não veio para substituir os revisores humanos, mas para potencializar sua capacidade. Equipes que utilizam revisão de código por IA relatam:
- Redução de 40-60% no tempo de revisão
- Aumento na detecção de falhas — especialmente vulnerabilidades de segurança e casos de borda
- Melhoria significativa na consistência do estilo de código
Mas a revisão por IA tem limites claros:
- ❌ Não entende prazos de negócio e o contexto do projeto
- ❌ Não percebe compromissos históricos de sistemas legados
- ❌ Não assume a responsabilidade final pela revisão
- ❌ Não realiza mentoria ou transferência de conhecimento na equipe
🎯 Melhor estratégia: A IA faz a primeira varredura (estilo, bugs, segurança), o humano toma a decisão final (arquitetura, intenção, riscos). Ao utilizar a plataforma APIYI apiyi.com para invocar a API do Claude Opus 4.6 ou Sonnet 4.6, você pode integrar rapidamente a revisão de código por IA aos seus fluxos de CI/CD existentes.
7 melhores práticas para revisão de código por IA
Prática 1: Mantenha as alterações pequenas e focadas
O revisor de IA perde a coerência significativamente após um diff exceder 1000 linhas. Mesmo que o Claude Opus 4.6 possua uma janela de contexto de 1 milhão de tokens, a qualidade da revisão de alterações grandes ainda é inferior à de alterações pequenas.
Como fazer:
- Mantenha cada PR entre 200 e 400 linhas
- Divida grandes refatorações em vários PRs logicamente independentes
- Cada PR deve realizar apenas uma tarefa
Prática 2: IA primeiro, humano decide
O fluxo de trabalho mais eficaz é o modelo de "revisão em duas camadas":
Commit de código → Revisão automática por IA (primeira passada)
↓
Marcação de problemas + Classificação por nível de gravidade
↓
Revisor humano foca em áreas de alto risco (decisão final)
↓
Merge ou rejeição
A IA cuida da varredura de todos os problemas comuns (estilo, nomenclatura, código morto, bugs simples), enquanto o humano foca em:
- Racionalidade da arquitetura
- Correção da lógica de negócio
- Decisões críticas de segurança
- Avaliação de impacto de performance
Prática 3: Forneça contexto suficiente
Quanto mais informações você der ao revisor de IA, melhor será a qualidade da revisão. Recomendamos incluir na descrição do PR:
# Contexto do PR
- Objetivo: [O que este PR resolve?]
- Impacto: [Quais partes do sistema são afetadas?]
- Decisões de design: [Por que esta abordagem foi escolhida?]
Intenção da alteração
Explique em 1 ou 2 frases "por que esta alteração foi feita".
Método de verificação
- Testes unitários aprovados
- Testado manualmente no cenário XX
- Sem regressão de desempenho
Nível de Risco
Baixo/Médio/Alto + Explicação
Declaração de Assistência por IA
Nesta alteração, a parte XX foi gerada por IA; por favor, realize uma revisão detalhada.
Foco de atenção
Por favor, concentre-se nas alterações da lógica de permissão no diretório src/auth/
### Prática 4: Marcação de revisão por nível de severidade
Um problema comum na revisão por IA é o "excesso de ruído" — misturar sugestões de estilo com bugs graves, o que faz com que os desenvolvedores ignorem feedbacks importantes.
**Marcações de severidade recomendadas**:
| Marcação | Significado | Ação |
|------|------|----------|
| 🔴 **Bug** | Defeito que deve ser corrigido antes do merge | Bloqueia o merge |
| 🟡 **Nit** | Pequeno problema que vale a pena corrigir, mas não bloqueia | Correção opcional |
| 🟣 **Pre-existing** | Problema antigo não introduzido nesta alteração | Registrado, mas não bloqueia |
| 💡 **Suggestion** | Sugestão de melhoria | Decidir após discussão |
A funcionalidade nativa de revisão de código do Claude Code já implementou este sistema de classificação (Vermelho/Amarelo/Roxo).
### Prática 5: Personalização das regras de revisão
A revisão genérica por IA pode não estar alinhada com as normas da sua equipe. Personalize o comportamento da revisão através de um arquivo de configuração:
```markdown
# REVIEW.md (localizado na raiz do projeto)
## Verificações obrigatórias
- Todas as consultas ao banco de dados devem usar instruções parametrizadas
- Endpoints de API devem incluir middleware de autenticação
- Todas as entradas do usuário devem ser validadas
Pode pular
- Estilo de nomenclatura de classes CSS (já formatado automaticamente pelo prettier)
- Ordenação de imports (já processada automaticamente pelo ruff)
- Idioma dos comentários (tanto chinês quanto inglês são aceitos)
Acordos da equipe
- Priorize a composição em vez da herança
- Use o padrão Result para tratamento de erros
- Níveis de log: INFO para eventos de negócio, DEBUG para depuração
### Prática 6: Integração ao pipeline de CI/CD
A revisão de código por IA deve ser automatizada, e não disparada manualmente.
**Forma de integração recomendada**:
```yaml
# Exemplo de GitHub Actions
name: Revisão de Código por IA
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
Você também pode realizar uma revisão personalizada chamando o modelo Claude diretamente via API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Você é um especialista sênior em revisão de código.
Analise as seguintes alterações de código e classifique-as por nível de gravidade:
- 🔴 Bug: Deve ser corrigido
- 🟡 Nit: Sugestão de melhoria leve
- 💡 Suggestion: Sugestão de melhoria
Para cada problema, indique o número da linha específica e a solução de correção."""},
{"role": "user", "content": f"Por favor, revise as seguintes alterações de código:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Prática 7: Rastreamento dos resultados da revisão
A revisão de código por IA não termina após o deploy. É necessário rastrear continuamente métricas fundamentais:
- Taxa de Falsos Positivos: Quantos dos problemas marcados pela IA são problemas reais
- Taxa de Falsos Negativos: Quantos dos bugs encontrados após o deploy a IA não detectou
- Taxa de Adoção: A proporção de sugestões da IA que os desenvolvedores realmente aceitaram
- Mudança no tempo de revisão: Se o tempo médio de revisão dos revisores humanos diminuiu
💡 Sugestão de implementação: Se sua equipe está começando a experimentar a revisão de código por IA, recomendo iniciar com PRs de caminhos não críticos. Use o Claude Sonnet 4.6 através da APIYI (apiyi.com) para os testes iniciais; o custo é apenas 1/5 do Opus, com uma qualidade de revisão próxima, sendo a opção com melhor custo-benefício para começar.
Por que recomendamos o Claude Opus 4.6 e o Sonnet 4.6 para revisão de código
Entre os diversos modelos de IA, a série Claude 4.6 possui vantagens únicas em cenários de revisão de código.
Comparação dos parâmetros principais dos modelos Claude 4.6
| Parâmetro | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| ID do Modelo | claude-opus-4-6 |
claude-sonnet-4-6 |
| Data de lançamento | 5 de fevereiro de 2026 | 17 de fevereiro de 2026 |
| Janela de contexto | 1 milhão de tokens (beta) | 1 milhão de tokens (beta) |
| Saída máxima | 128K tokens | 64K tokens |
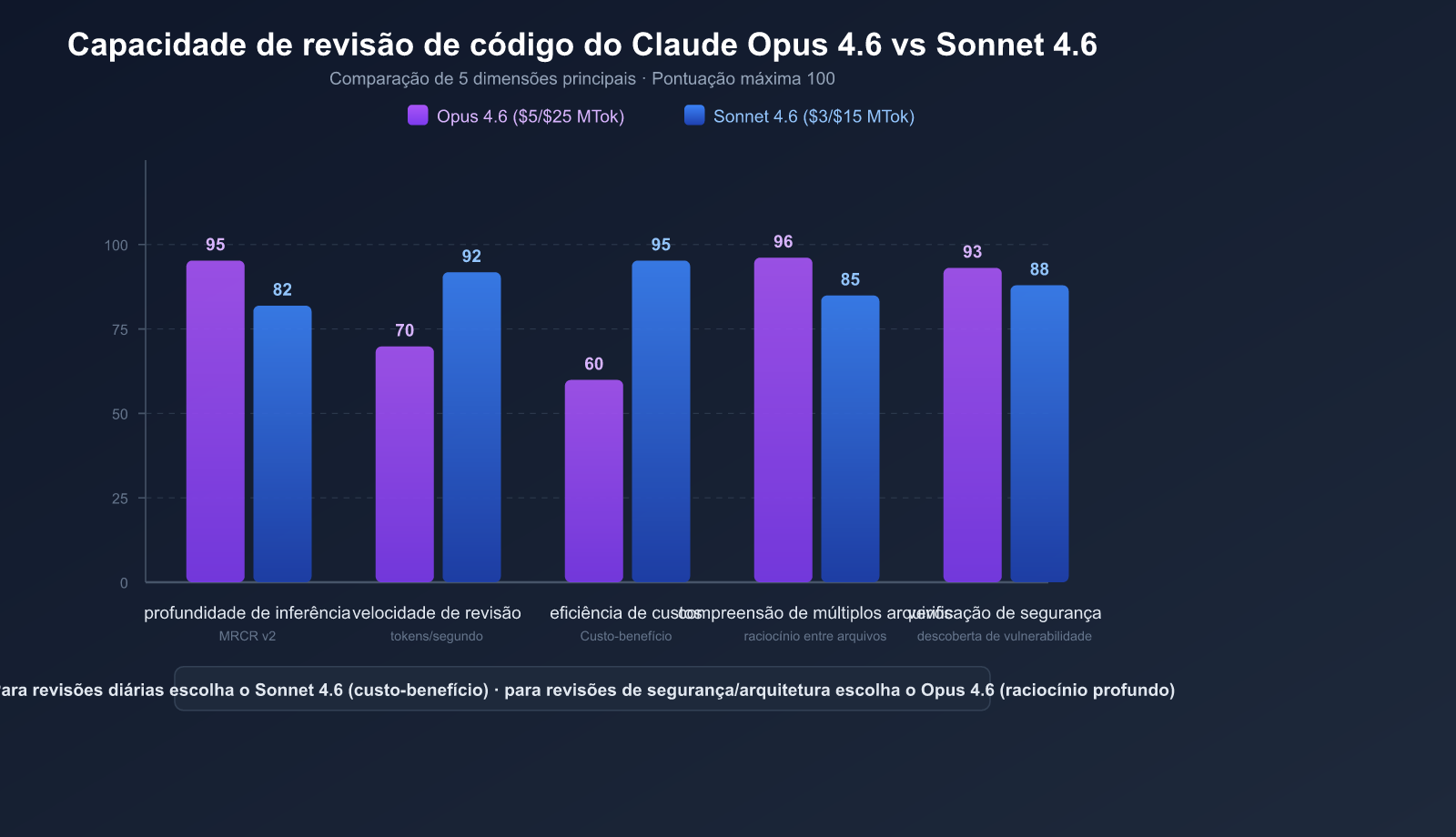
| SWE-bench Verified | 81,42% | 79,6% |
| Preço (Entrada/Saída) | $5/$25 por milhão de tokens | $3/$15 por milhão de tokens |
| Cenários de uso | Revisão de arquitetura complexa, auditoria de segurança | Revisão diária de PR, verificação de estilo |
| Preço APIYI | Mais vantajoso | Mais vantajoso |
Vantagem 1: Janela de contexto de 1 milhão de tokens
Esta é a vantagem técnica mais crucial no cenário de revisão de código.
Um PR de um projeto grande pode envolver dezenas de arquivos. As limitações da janela de contexto dos modelos de IA tradicionais significam que você precisa truncar o código, fazendo com que o revisor não veja o contexto completo.
O contexto de 1 milhão de tokens do Claude 4.6 pode acomodar de uma só vez:
- O diff completo do PR (geralmente de centenas a milhares de linhas)
- Todo o código dos arquivos relacionados (cadeia de importação, funções chamadas)
- Gráficos de dependência e definições de tipo
- Arquivos de teste e arquivos de configuração
- README e documentação de arquitetura do projeto
Isso significa que a IA pode revisar como um desenvolvedor sênior, compreendendo o contexto completo.
Vantagem 2: Capacidade de raciocínio entre arquivos de alto nível
O valor mais importante da revisão de código não é encontrar erros de sintaxe, mas sim descobrir problemas lógicos entre arquivos.
O Claude Opus 4.6 obteve uma pontuação de 76% no teste MRCR v2 (raciocínio de recuperação multi-agulha e multi-arquivo), enquanto o Sonnet 4.5 obteve apenas 18,5%. Isso significa que o Opus 4.6 tem um desempenho excelente nos seguintes cenários:
- Detectar que o arquivo A alterou uma interface, mas a chamada no arquivo B não foi atualizada
- Descobrir a falta de validação em todo o fluxo de dados, desde a entrada até o banco de dados
- Identificar condições de corrida em cenários de concorrência
Caso real: Em testes, o Claude Opus 4.6 descobriu uma condição de corrida em um PR de migração de banco de dados de 2400 linhas — uma falha na lógica de rollback que só seria acionada se a migração fosse interrompida no meio. Este é um cenário que testes automatizados não conseguem cobrir.
Vantagem 3: Profundidade de pensamento adaptativa
O Claude 4.6 introduz o modo adaptive thinking — a IA decide automaticamente "o quão profundamente pensar" com base na complexidade do problema.
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Revise esta alteração de código em busca de problemas de segurança."},
{"role": "user", "content": diff_content}
],
# Pensamento adaptativo do Claude 4.6: problemas simples são resolvidos rapidamente, problemas complexos são analisados profundamente
extra_body={"thinking": {"type": "adaptive"}}
)
- Encontra problemas de estilo simples → julga rapidamente, economizando tokens
- Encontra problemas complexos de concorrência ou segurança → raciocina profundamente, fornecendo uma análise detalhada
Vantagem 4: Detecção de vulnerabilidades de segurança muito superior às ferramentas tradicionais
Pesquisas mostram que LLMs de nível Claude são significativamente superiores às ferramentas tradicionais de análise estática na revisão de código de segurança:
| Dimensão de comparação | Claude (LLM) | CodeQL (SAST tradicional) |
|---|---|---|
| Vulnerabilidades detectadas | 55 | 27 |
| Descoberta de vulnerabilidades desconhecidas | 4 vulnerabilidades zero-day | 0 |
| Categorias de detecção | Injeção, autenticação, vazamento de dados, criptografia, falhas lógicas, etc. (mais de 10 classes) | Baseado em correspondência de padrões |
| Suporte a idiomas | Qualquer linguagem de programação | Linguagens específicas |
| Filtragem de falsos positivos | Filtragem automática pela IA | Requer filtragem manual |
Tipos de vulnerabilidades de segurança que o Claude pode detectar:
- Injeção SQL/Comando/LDAP/XPath/NoSQL
- Falhas de autenticação e autorização
- Chaves codificadas (hardcoded), logs de dados sensíveis
- Algoritmos de criptografia fracos, gerenciamento inadequado de chaves
- Condições de corrida (TOCTOU)
- Configurações padrão inseguras, CORS
- RCE de desserialização, injeção pickle/eval
- XSS (refletido, armazenado, baseado em DOM)
Vantagem 5: Flexibilidade de custos
O preço do Sonnet 4.6 é apenas 1/5 do Opus 4.6, mas fica apenas 1-2 pontos percentuais atrás no SWE-bench.
Estratégia de seleção recomendada:
| Cenário | Modelo recomendado | Motivo |
|---|---|---|
| Revisão diária de PR | Sonnet 4.6 | Melhor custo-benefício, qualidade próxima ao Opus |
| Código crítico de segurança | Opus 4.6 | Raciocínio mais profundo, não deixa passar problemas de alto risco |
| Revisão de refatoração grande | Opus 4.6 | Melhor capacidade de raciocínio entre arquivos |
| Verificação de estilo e normas | Sonnet 4.6 | Tarefas simples não precisam do Opus |
| Revisão automática CI/CD | Sonnet 4.6 | Custo controlável, adequado para cada commit |
🚀 Sugestão de seleção: A recomendação oficial da Anthropic é "usar o Sonnet 4.6 por padrão e atualizar para o Opus 4.6 apenas quando for necessário o raciocínio mais profundo". Nos testes internos do Claude Code, a taxa de preferência dos desenvolvedores pelo Sonnet 4.6 foi 70% maior que a da geração anterior (Sonnet 4.5), e até 59% maior que o antigo carro-chefe, o Opus 4.5. Ao chamar ambos os modelos via APIYI (apiyi.com), você pode desfrutar de preços mais vantajosos.
Fluxo de trabalho completo de revisão de código com IA
Visão geral do fluxo de trabalho
Desenvolvedor envia PR
↓
IA aciona revisão automática (Sonnet 4.6)
↓
┌─── Mudanças de baixo risco ──→ IA marca como Nit, aprovação automática
│
├─── Mudanças de médio risco ──→ IA marca problemas, confirmação humana rápida
│
└─── Mudanças de alto risco ──→ Escala para Opus 4.6 para revisão profunda
↓
Revisão final por especialista em segurança
↓
Merge ou rejeição
Exemplo de código: Construindo um sistema de revisão de IA personalizado
import openai
import subprocess
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
def get_pr_diff(pr_number):
"""Obtém o conteúdo do diff do PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Seleciona o modelo para revisão com base no nível de risco"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Revise as seguintes alterações:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Exemplo de uso
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Ver modelo completo de comando de revisão
REVIEW_PROMPT = """Você é um engenheiro de software sênior experiente realizando uma revisão de código.
## Foco da revisão
1. **Correção lógica**: O código implementa a funcionalidade esperada? Existem condições de contorno esquecidas?
2. **Segurança**: Existem riscos de segurança como injeção, XSS, CSRF, chaves API codificadas, etc.?
3. **Desempenho**: Existem consultas N+1, alocações de memória desnecessárias ou operações bloqueantes?
4. **Manutenibilidade**: A nomenclatura está clara? A complexidade é controlável? Existe código duplicado?
5. **Tratamento de erros**: As exceções estão sendo capturadas e tratadas corretamente?
6. **Segurança de concorrência**: Existem riscos de condições de corrida ou deadlocks?
Aqui está a tradução do conteúdo para português brasileiro:
Formato de Saída
Classifique a saída por nível de severidade:
🔴 Deve ser corrigido (Bug/Segurança)
- [Nome do arquivo:número da linha] Descrição do problema
- Impacto: …
- Sugestão de correção: …
🟡 Sugestão de correção (Nit)
- [Nome do arquivo:número da linha] Descrição do problema
- Sugestão: …
💡 Sugestão de melhoria (Suggestion)
- [Nome do arquivo:número da linha] Ponto de melhoria
- Explicação: …
Se a qualidade do código estiver boa e nenhum problema for encontrado, declare explicitamente "Revisão aprovada, nenhum problema encontrado".
Não invente problemas inexistentes apenas para preencher a saída.
💰 Otimização de custos: Ao utilizar o APIYI (apiyi.com) para realizar a invocação do modelo Claude 4.6 para revisão de código, você obtém preços mais vantajosos que os oficiais. A plataforma suporta a alternância flexível entre o Opus 4.6 e o Sonnet 4.6, permitindo escolher o modelo com o melhor custo-benefício com base no nível de risco do PR.
Limitações e Cuidados na Revisão de Código por IA
5 Limitações que você precisa conhecer
- Taxa de recall de cerca de 50%: As vulnerabilidades encontradas pelo Modelo de Linguagem Grande geralmente são reais (precisão de ~80%), mas ele deixa passar cerca de metade das vulnerabilidades existentes.
- Risco de injeção de comando: Ferramentas de revisão por IA correm o risco de sofrer injeção ao processar PRs de fontes não confiáveis.
- Pontos cegos de contexto: A IA não consegue compreender o contexto comercial do projeto, as habilidades da equipe ou as decisões históricas.
- Acúmulo de custos: Se você disparar uma revisão a cada commit, os custos em repositórios de alta frequência podem se tornar elevados.
- Risco de dependência excessiva: Os membros da equipe podem relaxar gradualmente o rigor da revisão humana.
Estratégias de mitigação
| Limitação | Estratégia de mitigação |
|---|---|
| Alta taxa de falha | Garantia dupla: revisão por IA + revisão humana |
| Injeção de comando | Revise apenas PRs de fontes confiáveis |
| Falta de contexto | Forneça o contexto do projeto no arquivo REVIEW.md |
| Custo elevado | Use o Sonnet 4.6 para o dia a dia e o Opus 4.6 para caminhos críticos |
| Dependência excessiva | Estabeleça um sistema de "Sugestão da IA + Decisão Humana" |
Perguntas Frequentes
Q1: A revisão de código por IA pode substituir totalmente a revisão humana?
Não. A revisão de código por IA é um "reforço" e não uma "substituição". A IA é excelente em encontrar problemas baseados em padrões (estilo, bugs comuns, padrões de vulnerabilidades conhecidos), mas não consegue compreender a intenção do negócio, as decisões arquiteturais por trás das escolhas ou o conhecimento tácito da colaboração em equipe. A melhor prática é usar a IA para uma primeira varredura e deixar o julgamento final para os humanos. Ao utilizar o modelo Claude 4.6 via APIYI apiyi.com, você pode configurar rapidamente um fluxo de revisão por IA, permitindo que os revisores humanos foquem em tarefas de maior valor.
Q2: Qual escolher para revisão de código: Opus 4.6 ou Sonnet 4.6?
Para a maioria dos cenários, escolha o Sonnet 4.6. Ele fica apenas 1-2 pontos percentuais abaixo do Opus no SWE-bench, mas custa apenas 1/5 do valor. Apenas em casos de revisão de código crítico de segurança, grandes refatorações de arquitetura ou quando é necessário um raciocínio profundo entre múltiplos arquivos, você deve considerar o upgrade para o Opus 4.6. Através da APIYI apiyi.com, você pode alternar entre os dois modelos de forma flexível conforme a necessidade.
Q3: Qual é o custo aproximado da revisão de código por IA?
A funcionalidade de revisão nativa do Claude Code custa em média US$ 15-25 por vez, dependendo do tamanho do PR e da complexidade da base de código. Se você construir seu próprio sistema de revisão via API, o custo dependerá do consumo de tokens. Tomando o Sonnet 4.6 como exemplo, revisar um PR de 500 linhas (aprox. 2000 tokens de entrada + 1000 tokens de saída) custa cerca de US$ 0,02. Através da APIYI apiyi.com, você ainda pode aproveitar preços mais vantajosos.
Q4: Como avaliar a eficácia da revisão de código por IA?
Sugerimos acompanhar 4 métricas principais: (1) Taxa de falsos positivos — a proporção de problemas reais entre os marcados pela IA; (2) Taxa de falsos negativos — a proporção de bugs encontrados após o deploy que a IA não marcou; (3) Taxa de adoção — a proporção de sugestões da IA que os desenvolvedores realmente aceitaram; (4) Variação no tempo de revisão — se o tempo médio de revisão dos revisores humanos diminuiu. Nos primeiros dois meses, recomendamos uma revisão semanal dos resultados.
Q5: Como começar a experimentar a revisão de código por IA rapidamente?
A maneira mais simples é seguir três passos: (1) Registrar-se na APIYI apiyi.com para obter uma chave API; (2) Usar o Sonnet 4.6 para fazer um teste de revisão em um PR recente; (3) Decidir se deseja integrar a automação no CI/CD com base nos resultados. Comece testando em códigos que não sejam críticos e expanda gradualmente para todo o projeto.
Resumo: A revisão de código por IA é um multiplicador de eficiência para a equipe
A revisão de código por IA não é uma opção, mas uma capacidade essencial para as equipes de desenvolvimento de software em 2026. O Claude Opus 4.6 e o Sonnet 4.6, com sua janela de contexto de 1 milhão de tokens, pontuação de 81%+ no SWE-bench, raciocínio adaptativo e poderosas capacidades de detecção de segurança, são atualmente a melhor escolha para cenários de revisão de código.
Sugestão de escolha:
- Revisão diária: Padrão Sonnet 4.6, o rei do custo-benefício.
- Segurança/Revisão de arquitetura: Upgrade para o Opus 4.6, para uma profundidade de raciocínio sem concessões.
Recomendamos a integração rápida de toda a série Claude 4.6 através da APIYI apiyi.com para estabelecer capacidades de revisão de código por IA para sua equipe com o melhor custo.
Referências
-
Oficial da Anthropic: Anúncio de lançamento do Claude Opus 4.6 e Sonnet 4.6
- Link:
anthropic.com/news
- Link:
-
Documentação de revisão de código do Claude Code: Guia de uso da funcionalidade de revisão nativa
- Link:
code.claude.com/docs/en/code-review
- Link:
-
Claude Code Security Review: GitHub Action de revisão de segurança de código aberto
- Link:
github.com/anthropics/claude-code-security-review
- Link:
-
Melhores práticas de revisão de código por IA 2026: Análise abrangente do setor
- Link:
verdent.ai/guides
- Link:
-
Artigo de pesquisa IRIS: Detecção de vulnerabilidades em análise estática assistida por Modelo de Linguagem Grande
- Link:
arxiv.org
- Link:
Autor: Equipe APIYI | Explorando as melhores práticas de desenvolvimento de software impulsionado por IA. Visite a APIYI em apiyi.com para obter acesso à API de toda a série de modelos Claude 4.6 e suporte técnico.




