Author's Note: Uncovering the root cause of frequent Nano Banana Pro API overloads—from Google's custom TPU chip architecture to the differences between AI Studio and Vertex AI, we'll dive into the technical truth behind the supply shortage.
Since Nano Banana Pro launched in November 2025, developers have noticed a confusing phenomenon: Even though Google has its own custom TPU chips, this image generation API still frequently hits "model overloaded" errors. Why can't in-house chips solve the computing power problem? What's the fundamental difference between the AI Studio and Vertex AI platforms? In this post, we'll dive deep into the underlying logic of Google's computing architecture to uncover the technical truth.
Core Value: Using real data and architectural analysis, we'll help you understand the root cause of Nano Banana Pro's stability issues and how to choose a more reliable API integration plan.
{{SVG_TEXT_0}}: Nano Banana Pro Stability Crisis
{{SVG_TEXT_1}}: Deep Dive into Google TPU Computing Bottlenecks
{{SVG_TEXT_2}}: User Request
{{SVG_TEXT_3}}: AI Studio
{{SVG_TEXT_4}}: Resource Scheduling
{{SVG_TEXT_5}}: TPU Cluster
{{SVG_TEXT_6}}: ⚠️ Computing Bottleneck
{{SVG_TEXT_7}}: 503 Overload
{{SVG_TEXT_8}}: Core Issue Statistics
{{SVG_TEXT_9}}: 503 Model Overloaded
{{SVG_TEXT_10}}: 70%
{{SVG_TEXT_11}}: Response Time 60-100s
{{SVG_TEXT_12}}: 429 Resource Exhausted
{{SVG_TEXT_13}}: 70%
{{SVG_TEXT_14}}: Triggered even when far below quota
{{SVG_TEXT_15}}: Sudden Quota Cut
{{SVG_TEXT_16}}: -92%
{{SVG_TEXT_17}}: 2025.12.7 Great Disaster
{{SVG_TEXT_18}}: Including Tier 3 Paid Users
{{SVG_TEXT_19}}: TPU v7 Architecture
{{SVG_TEXT_20}}: MXU
{{SVG_TEXT_21}}: 256×256
{{SVG_TEXT_22}}: Vector
{{SVG_TEXT_23}}: Unit
{{SVG_TEXT_24}}: Scalar
{{SVG_TEXT_25}}: Unit
{{SVG_TEXT_26}}: Peak Compute: 4,614 TFLOP/s
{{SVG_TEXT_27}}: Efficiency: +100% vs v6e
{{SVG_TEXT_28}}: !
{{SVG_TEXT_29}}: Why is it still in short supply?
{{SVG_TEXT_30}}: • Production Ramp: Released April 2025 → Mass deployment in 2026
{{SVG_TEXT_31}}: • Demand Surge: Gemini 2.0 requests exceeded forecasts
{{SVG_TEXT_32}}: • Resource Allocation: High-value models prioritized
{{SVG_TEXT_33}}: 2025.4
{{SVG_TEXT_34}}: TPU v7
{{SVG_TEXT_35}}: 2025.11
{{SVG_TEXT_36}}: Launch
{{SVG_TEXT_37}}: 2025.12.7
{{SVG_TEXT_38}}: Quota Cut
{{SVG_TEXT_39}}: 2026 Q2
{{SVG_TEXT_40}}: Mass Deployment
{{SVG_TEXT_41}}: 2026 Q3
{{SVG_TEXT_42}}: 1 GW Online
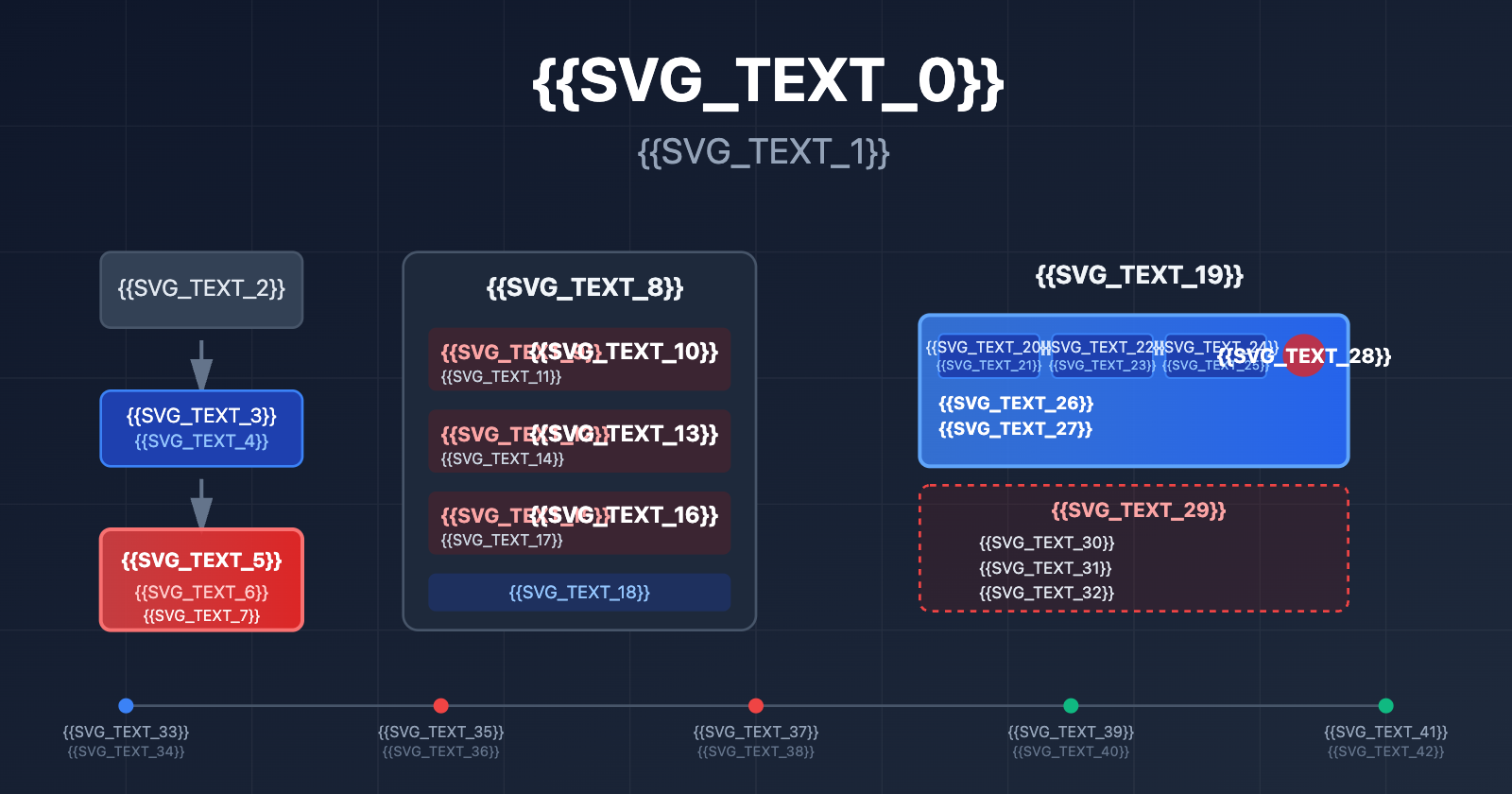
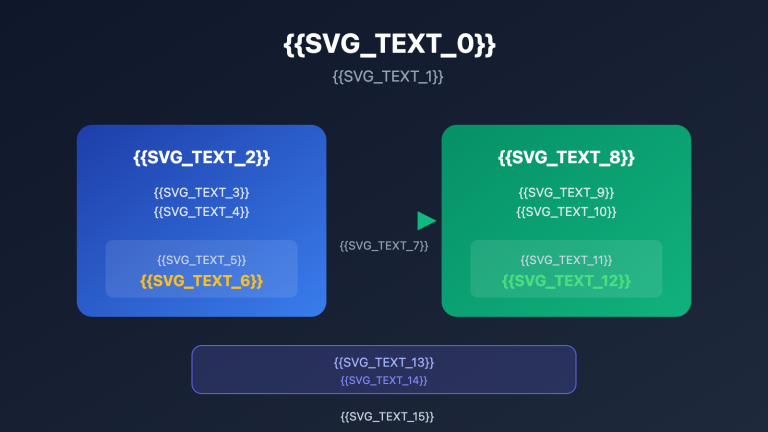
Core Stability Issues of Nano Banana Pro API
Since its launch in November 2025, Nano Banana Pro (gemini-2.0-flash-preview-image-generation) has been facing a persistent stability crisis. Here’s the data on core issues reported by the developer community:
| Issue Type | Frequency | Typical Behavior | Impact Scope |
|---|---|---|---|
| 503 Model Overloaded | High (70%+ of errors) | Response times spike from 30s to 60-100s | All users (including Tier 3 paid users) |
| 429 Resource Exhausted | ~70% of API errors | Triggered even when far below quota limits | Free tier and Tier 1 paid users |
| Sudden Quota Cuts | Dec 7, 2025 | Free tier dropped from 3 to 2 images/day; 2.5 Pro removed from free tier | Global free tier users |
| Service Unavailable | Intermittent | High-speed generation one day, completely unusable the next | App developers relying on the free tier |
The Root Cause of Nano Banana Pro's Stability Issues
The heart of these problems isn't actually code defects—it's computing power capacity bottlenecks on Google's server side. Even Tier 3 paid users (the highest quota tier) are hitting overload errors while their request frequency is well below official limits. This proves the issue lies within the infrastructure rather than user quota management.
According to Google's official responses on developer forums, computing resources are being reallocated to new models in the Gemini 2.0 series. This leaves image generation models like Nano Banana Pro with limited available capacity. This resource scheduling strategy is the direct cause of the service's instability.
🎯 Tech Tip: When using Nano Banana Pro in a production environment, we recommend connecting through the APIYI platform. It offers intelligent load balancing and automatic failover mechanisms, which can significantly boost your API call success rate and overall stability.
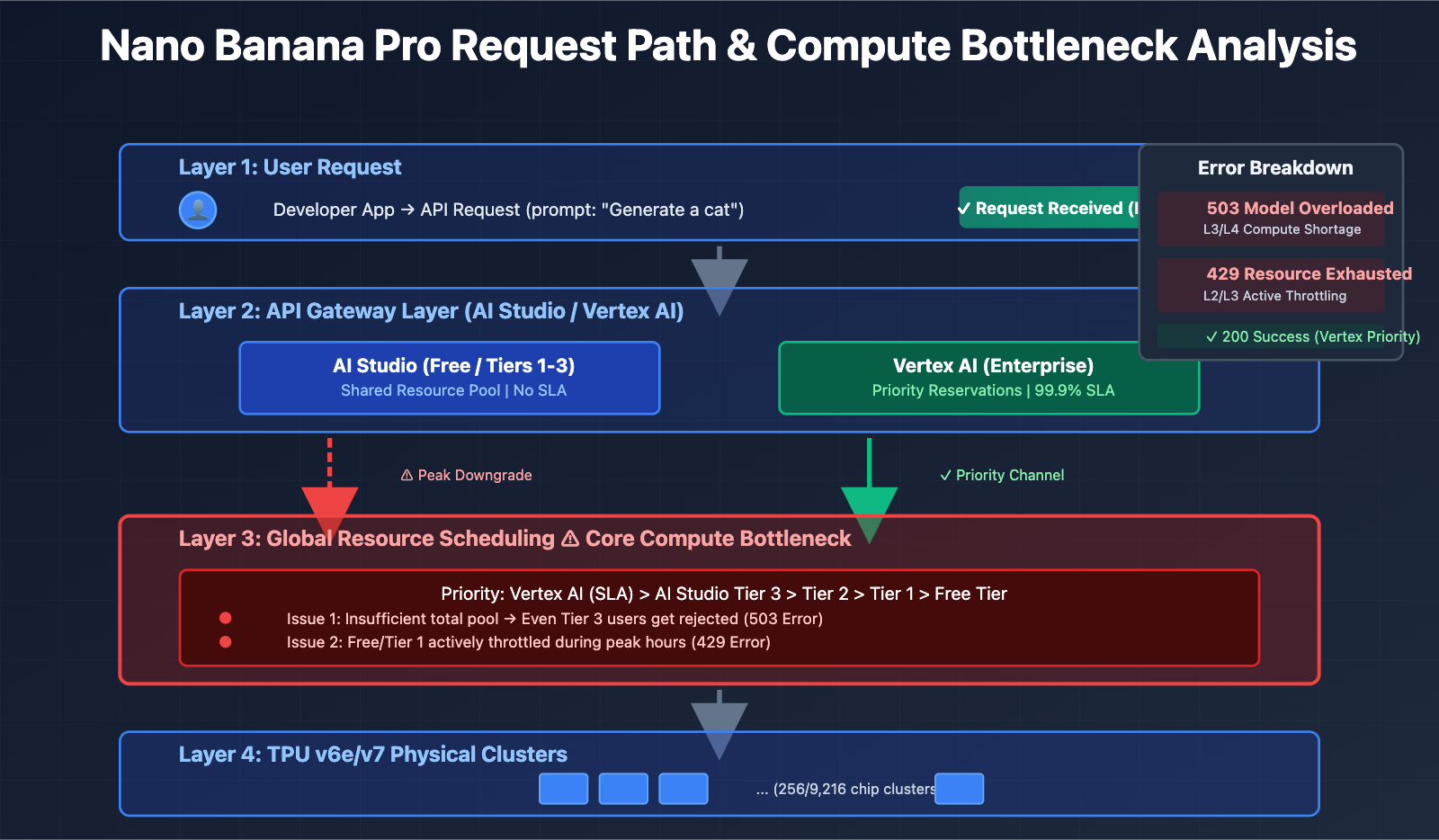
The Truth Behind Google's In-House TPU Architecture
Many people assume that because Google has its own in-house TPU (Tensor Processing Unit) chips, it should be able to effortlessly handle the compute demands of Large Language Models. However, the reality is far more complex than you'd imagine.
The Latest Architecture: TPU v7 (Ironwood)
In April 2025, Google unveiled its seventh-generation TPU, Ironwood, at the Cloud Next conference. This is their most powerful version to date:
| Architecture Parameter | TPU v7 (Ironwood) | TPU v6e (Trillium) | Improvement |
|---|---|---|---|
| Peak Compute | 4,614 TFLOP/s | ~2,300 TFLOP/s | ~100% |
| Energy Efficiency | Baseline | Reference | 100% improvement in Performance/Watt |
| Cluster Config | 256 or 9,216 chips | Single configuration | Flexible scaling capabilities |
| Matrix Units | 256×256 MXU (systolic array) | 128×128 MXU | 4x compute density |
| Application Scenarios | Inference-first era | Mixed Training + Inference | Specifically optimized for inference |
Core TPU Architectural Components
Each TPU chip contains one or more TensorCores, and each TensorCore consists of the following parts:
- Matrix Multiply Unit (MXU): TPU v6e and v7x use a 256×256 multiply-accumulate array, while earlier versions used 128×128.
- Vector Unit: Handles non-matrix operations.
- Scalar Unit: Executes control logic.
This "systolic array" architecture is perfectly suited for neural network inference, but it does have its limitations.
Why Do In-House Chips Still Fail to Solve Compute Shortages?
Even though the TPU v7 is a powerhouse, stability issues with Nano Banana Pro persist for three main reasons:
1. Production Ramp-up Cycles
TPU v7 was launched in April 2025, but large-scale deployment takes time. Google announced a $10 billion partnership with Anthropic in late 2025, with plans to bring over 1 GW of AI compute online in 2026. This means that the period between November 2025 and early 2026 is a transitional ramp-up phase, where the switch between old and new architectures leads to tight resource availability.
2. Explosive Demand Growth
Following the release of the Gemini 2.0 series in late 2025, API request volumes surged far beyond Google's initial forecasts. The influx of free-tier users—especially for Nano Banana Pro's image generation features—directly crowded the resource pool intended for paid users.
3. Resource Allocation Priorities
Google has to balance compute needs across several AI product lines: Gemini 2.5 Pro (text), Gemini 2.0 Flash (multimodal), Nano Banana Pro (image generation), and others. When compute is limited, models with higher commercial value get priority, which directly results in capacity limits for Nano Banana Pro.
🎯 Architectural Insight: Developing your own TPU chips doesn't equal infinite compute. Chip yields, data center construction, and energy supply are all major bottlenecks. We recommend that enterprise users leverage the multi-cloud compute scheduling of the APIYI (apiyi.com) platform to avoid capacity risks from a single provider.
AI Studio vs Vertex AI: Fundamental Differences Between the Two Platforms
Many developers are confused: both Gemini AI Studio and Vertex AI can call Gemini models, so why is there such a massive difference in stability and quotas? The answer lies in their completely different architectural positioning.
Platform Comparison
| Dimension | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API on GCP) |
|---|---|---|
| Target Users | Individual developers, students, startups | Enterprise teams, production applications |
| Barrier to Entry | Get an API Key and start prototyping in minutes | Requires a Google Cloud account and billing setup |
| Pricing Model | Free tier (with limits) + Tier 1/2/3 paid | Pay-as-you-go (no free tier), integrated with GCP billing |
| SLA Guarantee | No SLA (Service Level Agreement) | Enterprise-grade SLA, 99.9% availability |
| Feature Scope | Model API + visual prototyping tool | Full ML lifecycle (labeling, training, tuning, deployment, monitoring) |
| Quota Stability | Subject to global resource scheduling; quotas may fluctuate | Enterprise quota reservation, priority allocation |
AI Studio: Key Strengths and Limitations
Strengths:
- Fast Onboarding: Get an API key instantly without messing with cloud configurations.
- Visual Prototyping: Built-in prompt testing interface for rapid iteration.
- Free-Tier Friendly: Ideal for learning, experimentation, and small-scale projects.
Limitations:
- No SLA Guarantee: Service availability isn't contractually protected.
- Unstable Quotas: Take the sudden cut on December 7, 2025, for example: Gemini 2.5 Pro was removed from the free tier, and 2.5 Flash's daily limit plummeted from 250 to just 20 requests (a 92% reduction).
- Lacks Enterprise Features: No native integration with GCP data services like BigQuery or Dataflow.
Vertex AI: Enterprise-Grade Capabilities
Core Strengths:
- Resource Priority: Paid user requests have much higher priority in Google's internal scheduling system.
- MLOps Integration: Supports the full lifecycle, including model training, versioning, A/B testing, and monitoring/alerts.
- Data Sovereignty: You can specify data storage regions to comply with GDPR, CCPA, and other regulations.
- Enterprise Support: Dedicated technical support teams and architectural consulting.
Best Use Cases:
- Production apps with more than 10,000 requests per day.
- Scenarios requiring model fine-tuning or custom training.
- Enterprises with strict SLA requirements for availability and response times.
🎯 Recommendation: If your app has moved past the prototype stage and your daily calls exceed 5,000, you should migrate to Vertex AI or connect via a unified platform like APIYI (apiyi.com). This platform aggregates compute resources from multiple cloud providers, allowing for cross-platform scheduling under a single interface. You'll keep the ease of use found in AI Studio while gaining the stability of Vertex AI.

The Deep-Seated Reasons Behind the Nano Banana Pro Shortage
Based on the previous analysis, the reasons why Nano Banana Pro continues to be in short supply can be summarized into the following three main levels:
1. Technical Level: Imbalance Between Chip Capacity and Demand
- TPU v7 Production Ramp-up: Released in April 2025, but large-scale deployment won't be completed until 2026.
- Training Prioritized Over Inference: Training tasks for the Gemini 3.0 series are consuming a vast amount of TPU v6e and v7 resources.
- Computation-Intensive Image Generation: The inference required for Nano Banana Pro's Diffusion Model takes 5-10 times more computing power than text models.
2. Commercial Level: Free Tier Policy Adjustments
| Timeframe | Policy Change | Background Reason |
|---|---|---|
| November 2025 | Nano Banana Pro launched; Free tier at 3 images/day | Quickly gather user feedback and establish market position |
| December 7, 2025 | Free tier reduced to 2 images/day; Gemini 2.5 Pro removed from free tier | Computing costs exceeded budget; need to control free user growth |
| January 2026 | Free tier RPM dropped from 10 to 5 | Reserving resources for Gemini 2.0 Flash enterprise customers |
Google explicitly stated in official forums that these adjustments are intended to "ensure sustainable service quality." In reality, the surge in free-tier users (especially from automation tools and batch calls) led to spiraling costs, forcing Google to tighten its policies.
3. Architectural Level: Resource Isolation between AI Studio and Vertex AI
Although both platforms call the same underlying models, they have different resource scheduling priorities within Google:
- Vertex AI: Directly connected to GCP's enterprise-grade computing pools, benefiting from resource reservations with SLA guarantees.
- AI Studio: Shares a global resource pool and is subject to downgrades during peak hours.
This architectural design means that AI Studio's Free Tier and Tier 1 users are more likely to encounter 429/503 errors, while Vertex AI's paid users are less affected.
4. Product Strategy: Moving from "Market Capture" to "Profit Optimization"
When Nano Banana Pro first launched, Google adopted an aggressive free strategy to compete with the likes of DALL-E 3 and Midjourney. However, as the user base exploded, Google realized the free tier business model was unsustainable and began shifting resources toward "high-value paid users."
The landmark event of this shift was the December 2025 quota cuts and the removal of the 2.5 Pro free tier, which the developer community dubbed the "Free Tier Fiasco."
🎯 Response Strategy: For production applications that rely on Nano Banana Pro, we recommend adopting a multi-cloud backup strategy. Through the APIYI (apiyi.com) platform, you can configure automatic switching rules for multiple models like Nano Banana Pro, DALL-E 3, and Stable Diffusion under a single interface. When one service becomes overloaded, it automatically fails over to an alternative, ensuring business continuity.
How Developers Can Handle Nano Banana Pro's Instability
Based on the previous analysis, here are four proven technical solutions:
Solution 1: Implement an Exponential Backoff Retry Mechanism
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""使用指数退避策略调用 Nano Banana Pro API"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # 你的实际 API 调用函数
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"遇到过载错误,等待 {wait_time:.2f} 秒后重试...")
time.sleep(wait_time)
else:
raise e
raise Exception("达到最大重试次数")
Core Idea: When a 503/429 error occurs, the wait time increases exponentially (1s → 2s → 4s → 8s) to avoid a thundering herd effect.
Full Production-Grade Implementation (Click to expand)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""生产级图像生成方法,包含完整的错误处理和监控"""
for attempt in range(self.max_retries):
try:
# 实际 API 调用逻辑
response = self._call_api(prompt, **kwargs)
logger.info(f"请求成功 (尝试 {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"错误 {error_code}: {str(e)[:100]} | "
f"等待 {wait_time:.2f}s (尝试 {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"达到最大重试次数,最终失败: {str(e)}")
raise
else:
logger.error(f"不可重试的错误: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""计算指数退避时间,加入抖动避免同步重试"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # 最大等待 60 秒
def _parse_error_code(self, error: Exception) -> int:
"""从异常中提取 HTTP 状态码"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""实际的 API 调用逻辑 (需替换为真实实现)"""
# 这里放置你的实际 API 调用代码
pass
# 使用示例
client = NanoBananaClient(api_key="your_api_key")
result = client.generate_image("a cute cat playing piano")
Solution 2: Request Interval Control
According to feedback from the developer community, adding a fixed delay of 5-10 seconds between requests can significantly reduce the 503 error rate:
import time
def batch_generate_images(prompts):
"""批量生成图像,严格控制请求频率"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # 最后一个请求不需要等待
time.sleep(7) # 固定 7 秒间隔
return results
Applicable Scenarios: Non-real-time applications, such as batch content generation or offline data processing.
Solution 3: Multi-Cloud Backup Strategy
Implement automatic failover through a unified API platform:
| Step | Technical Implementation | Expected Result |
|---|---|---|
| 1. Configure Primary/Backup | Nano Banana Pro (Primary) + DALL-E 3 (Backup) | Single point of failure tolerance |
| 2. Set Switching Rules | 3 consecutive 503 errors → Auto-switch to backup | Reduced perceived latency for users |
| 3. Monitor Recovery | Probe primary service health every 5 minutes | Auto-revert to primary service |
🎯 Recommended Implementation: The APIYI (apiyi.com) platform natively supports this multi-cloud scheduling strategy. You just need to configure the switching rules in the console, and the system handles failure detection, traffic switching, and cost optimization automatically—no changes to your business code required.
Solution 4: Upgrade to Vertex AI or Enterprise-Grade Platforms
If your application meets any of the following conditions, we recommend considering an upgrade:
- Daily API calls > 5,000.
- Strict SLA requirements for response times (e.g., 95th percentile < 10 seconds).
- Zero tolerance for service interruptions (e.g., e-commerce image generation, real-time content moderation).
Cost Comparison:
AI Studio Tier 1: $0.05/image (but frequent overloads)
Vertex AI: $0.08/image (stable, with SLA)
APIYI Platform: $0.06/image (multi-cloud scheduling, auto-failover)
While the unit price for Vertex AI is higher, the actual TCO (Total Cost of Ownership) may be lower when you factor in retry costs, development time, and potential business losses.
FAQ
Q1: Why do paid users still run into "Model Overloaded" errors?
A: Nano Banana Pro's capacity bottleneck happens at Google's global compute scheduling layer, not the user quota layer. Even if you're a Tier 3 paid user, you'll still receive a 503 error when the overall compute pool is maxed out. This is different from the traditional 429 quota limit error.
The difference is:
- 429 Error: Your personal quota is exhausted (like RPM limits).
- 503 Error: Google's server-side compute is insufficient, which has nothing to do with your quota.
Q2: Do AI Studio and Vertex AI call the same model?
A: Yes, the underlying Nano Banana Pro model (gemini-2.0-flash-preview-image-generation) they both call is exactly the same. However, their resource scheduling priorities differ:
- Vertex AI: Enterprise-grade SLA guarantees, with priority compute allocation.
- AI Studio: Shared resource pool, which might be downgraded during peak hours.
It's similar to the difference between "pay-as-you-go" and "reserved instances" for cloud servers.
Q3: Will Google continue to cut free tier quotas?
A: Based on historical trends, Google will likely continue adjusting its free tier policy:
- November 2025: Free tier limited to 3 images/day.
- December 7, 2025: Dropped to 2 images/day; 1.5 Pro removed.
- January 2026: RPM dropped from 10 to 5.
Google's official stance is to "ensure sustainable service quality," but in reality, they're finding a balance between cost control and user growth. We recommend that production applications don't rely on the free tier; plan for paid options or multi-cloud backups in advance.
Q4: When will Nano Banana Pro's stability improve?
A: According to Google's public info, the key milestones are in mid-2026:
- Q2 2026: Large-scale deployment of TPU v7 (Ironwood) completed.
- Q3 2026: 1 GW of compute power from the Anthropic partnership goes online.
At that point, compute supply will increase significantly, though demand might grow right along with it. Conservatively, we expect stability to see substantial improvement in the second half of 2026.
Q5: How should I choose my Nano Banana Pro access method?
A: Choose based on your application's stage:
| Stage | Recommended Solution | Reason |
|---|---|---|
| Prototyping | AI Studio Free Tier | Lowest cost, fast idea validation |
| Small-scale Launch | AI Studio Tier 1 + Retry Mechanism | Balances cost and stability |
| Production Environment | Vertex AI or APIYI Platform | SLA guarantees, enterprise-grade support |
| Critical Business | Multi-cloud Backup Strategy (e.g., APIYI) | Highest availability, automatic failover |
🎯 Decision Advice: If you're not sure which to pick, we suggest running A/B tests through the APIYI (apiyi.com) platform. The platform lets you compare the actual performance of Nano Banana Pro (AI Studio), Nano Banana Pro (Vertex AI), and DALL-E 3 under the same requests, helping you make a decision based on real data.
Summary: A Rational Look at Nano Banana Pro's Compute Challenges
The stability issues with Nano Banana Pro aren't isolated incidents—they're a microcosm of the compute supply-demand contradiction facing the entire AI industry:
The Core Contradictions:
- Demand Side: Explosive growth in generative AI apps, especially in image generation.
- Supply Side: Slow ramp-up in chip production and long data center construction cycles (12-18 months).
- Economic Model: Free tier strategies aren't sustainable, yet paid conversion rates remain low.
Three Technical Truths:
-
In-house TPUs ≠ Infinite Compute: While Google has advanced chips like the TPU v7, scaling production, securing energy supplies, and building data centers takes time. 2026 is the critical turning point.
-
The Essence of AI Studio vs. Vertex AI: These aren't just "free" vs. "paid" versions; they reflect different resource scheduling priorities. Behind Vertex AI's enterprise SLA is an independent compute reservation mechanism.
-
Supply Shortages Will Persist: As next-gen models like Gemini 3.0 and GPT-5 are released, compute demand will keep climbing. In the short term (2026-2027), the supply-demand tension won't fundamentally change.
Practical Advice:
- Short-term: Use engineering tactics like retry mechanisms and request interval controls to mitigate issues.
- Mid-term: Evaluate the ROI of upgrading to Vertex AI or a multi-cloud platform.
- Long-term: Monitor Google's compute expansion progress in mid-2026 and adjust your strategy accordingly.
For enterprise-level applications, we strongly recommend a multi-cloud backup strategy to avoid capacity risks from a single provider. By using a unified platform like APIYI (apiyi.com), you can gain cross-cloud scheduling, automatic failover, and cost optimization without increasing code complexity.
Final Thought: The challenges with Nano Banana Pro remind us that AI application stability doesn't just depend on model capability—it relies on the maturity of the underlying infrastructure. In this era where compute is king, architectural robustness and supplier diversification are becoming the keys to product competitiveness.
Related Reading:
- Nano Banana Pro API Usage Guide
- Deep Dive into Google TPU v7 Architecture
- Choosing an AI Image Generation API: Nano Banana Pro vs. DALL-E 3 vs. Stable Diffusion
- 10 Best Practices for AI API Calls in Production Environments