Nota del autor: Descubre la causa raíz de las frecuentes sobrecargas de la API de Nano Banana Pro, desde la arquitectura de los chips TPU de Google hasta las diferencias entre AI Studio y Vertex AI, para entender la verdad técnica detrás de la falta de suministro.
Desde el lanzamiento de Nano Banana Pro en noviembre de 2025, los desarrolladores han notado un fenómeno desconcertante: incluso con los chips TPU de desarrollo propio de Google, esta API de generación de imágenes sigue presentando frecuentes errores de "modelo sobrecargado". ¿Por qué los chips propios no pueden resolver el problema de la capacidad de cómputo? ¿Cuáles son las diferencias fundamentales entre las plataformas AI Studio y Vertex AI? En este artículo, partiremos de la lógica subyacente de la arquitectura de cómputo de Google para analizar en profundidad la realidad técnica de estos problemas.
Valor principal: A través de datos reales y un análisis de arquitectura, te ayudaremos a comprender la causa raíz de los problemas de estabilidad de Nano Banana Pro y cómo elegir una solución de acceso a la API más confiable.
Problemas centrales de estabilidad de la API de Nano Banana Pro
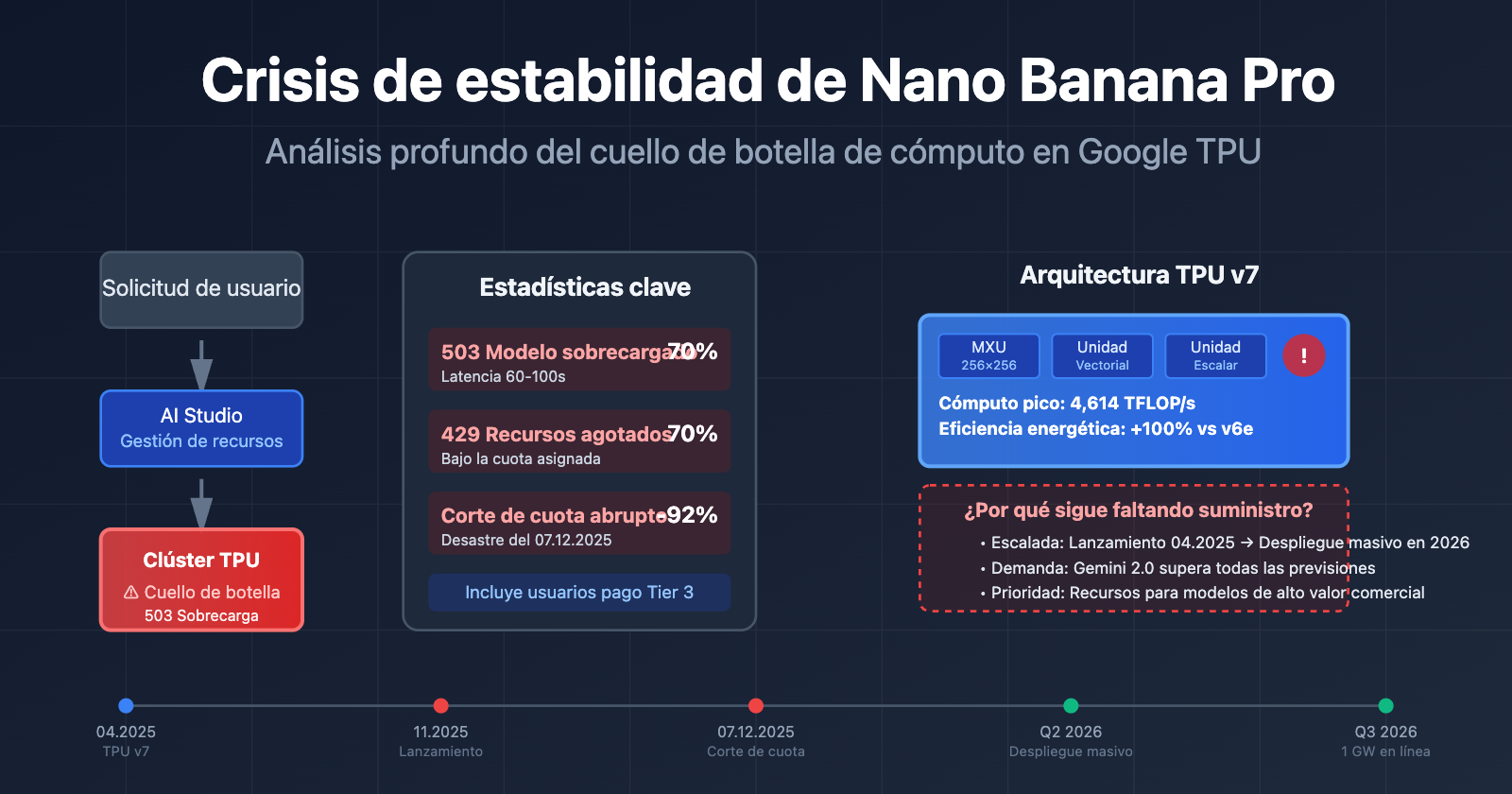
Desde su lanzamiento en noviembre de 2025, Nano Banana Pro (gemini-2.0-flash-preview-image-generation) ha atravesado una crisis de estabilidad persistente. A continuación, se presentan los datos de los problemas principales reportados por la comunidad de desarrolladores:
| Tipo de problema | Frecuencia | Manifestación típica | Alcance del impacto |
|---|---|---|---|
| 503 Sobrecarga del modelo | Alta (70%+ de los errores) | El tiempo de respuesta aumentó de 30 a 60-100 segundos | Usuarios de todos los niveles (incluidos los de pago Tier 3) |
| 429 Agotamiento de recursos | Aprox. 70% de los errores de API | Se activa incluso estando muy por debajo de los límites de cuota | Nivel gratuito y usuarios de pago Tier 1 |
| Recorte repentino de cuota | 7 de diciembre de 2025 | El nivel gratuito bajó de 3 imágenes/día a 2 imágenes/día; 2.5 Pro fue eliminado del nivel gratuito | Usuarios del nivel gratuito a nivel mundial |
| Servicio no disponible | Intermitente | Generación de alta velocidad un día, totalmente inaccesible al día siguiente | Desarrolladores de aplicaciones que dependen del nivel gratuito |
Causa raíz de los problemas de estabilidad de Nano Banana Pro
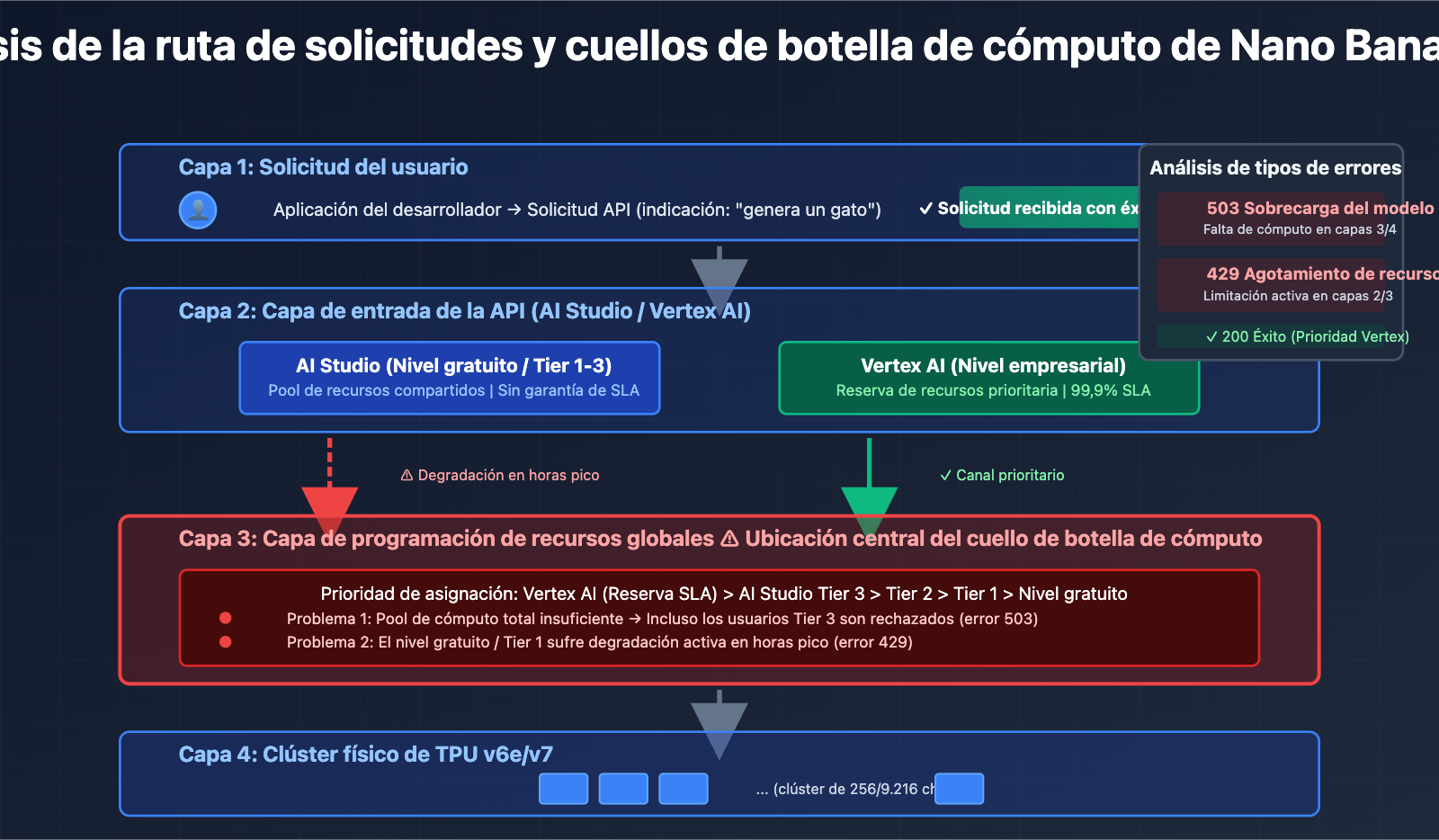
El núcleo de estos problemas no son fallos en el código, sino cuellos de botella en la capacidad de cómputo de los servidores de Google. Incluso los usuarios de pago Tier 3 (el nivel de cuota más alto) han experimentado errores de sobrecarga con frecuencias de solicitud muy inferiores a los límites oficiales, lo que indica que el problema reside en la infraestructura y no en la gestión de cuotas de usuario.
Según las respuestas oficiales de Google en los foros de desarrolladores, los recursos de cómputo se están reasignando a los nuevos modelos de la serie Gemini 2.0, lo que limita la capacidad disponible para modelos de generación de imágenes como Nano Banana Pro. Esta estrategia de programación de recursos es la causa directa de la inestabilidad del servicio.
🎯 Sugerencia técnica: Al usar Nano Banana Pro en entornos de producción, se recomienda acceder a través de la plataforma APIYI (apiyi.com). Esta plataforma ofrece mecanismos inteligentes de equilibrio de carga y conmutación por error automática, lo que puede mejorar significativamente la tasa de éxito y la estabilidad de las llamadas a la API.
La realidad tras la arquitectura de los chips TPU de Google
Mucha gente piensa que Google, al contar con sus propios chips TPU (Tensor Processing Unit), debería poder satisfacer fácilmente la demanda de potencia de cómputo para sus modelos de IA. Pero la realidad es mucho más compleja de lo que imaginas.
La última arquitectura: TPU v7 (Ironwood)
En abril de 2025, durante la conferencia Cloud Next, Google presentó la séptima generación de sus TPU, denominada Ironwood. Esta es la versión más potente hasta la fecha:
| Parámetro de Arquitectura | TPU v7 (Ironwood) | TPU v6e (Trillium) | Mejora |
|---|---|---|---|
| Potencia de cómputo máxima | 4,614 TFLOP/s | ~2,300 TFLOP/s | ~100% |
| Eficiencia energética | Base | Referencia | +100% en rendimiento/vatio |
| Configuración de clúster | 256 o 9,216 chips | Configuración única | Capacidad de expansión flexible |
| Unidades de matriz | MXU 256×256 (matriz sistólica) | MXU 128×128 | 4x densidad de cómputo |
| Escenario de aplicación | Era de la inferencia (Inference-first) | Híbrido entrenamiento+inferencia | Optimización específica para inferencia |
Componentes principales de la arquitectura TPU
Cada chip TPU contiene uno o más TensorCores, y cada TensorCore se compone de:
- Unidad de Multiplicación de Matrices (MXU): Las versiones TPU v6e y v7x utilizan matrices de acumuladores de multiplicación de 256×256 (las versiones anteriores eran de 128×128).
- Unidad Vectorial: Se encarga de las operaciones que no son de matriz.
- Unidad Escalar: Ejecuta la lógica de控制 (control).
Esta arquitectura de matriz sistólica (systolic array) es ideal para la inferencia de redes neuronales, aunque también tiene sus limitaciones.
¿Por qué los chips de diseño propio no solucionan la escasez de potencia?
A pesar del gran rendimiento de la TPU v7, los problemas de estabilidad de Nano Banana Pro persisten por tres razones:
1. Ciclo de aumento de producción (Ramp-up)
La TPU v7 se lanzó en abril de 2025, pero su despliegue a gran escala lleva tiempo. Google anunció a finales de 2025 una colaboración de diez mil millones de dólares con Anthropic, con planes de poner en marcha más de 1 GW de potencia para IA en 2026. Esto significa que el periodo entre noviembre de 2025 y principios de 2026 es una etapa de transición, donde el cambio entre arquitecturas antiguas y nuevas genera tensión en los recursos disponibles.
2. Crecimiento explosivo de la demanda
Tras el lanzamiento de la serie Gemini 2.0 a finales de 2025, el volumen de solicitudes por API superó las previsiones iniciales de Google. La llegada masiva de usuarios de la capa gratuita (especialmente para la generación de imágenes en Nano Banana Pro) saturó directamente los recursos destinados a los usuarios de pago.
3. Prioridades en la asignación de recursos
Google debe equilibrar la demanda de varias líneas de productos de IA: Gemini 2.5 Pro (texto), Gemini 2.0 Flash (multimodal), Nano Banana Pro (generación de imágenes), entre otros. Cuando la potencia es limitada, los modelos con mayor valor comercial reciben prioridad, lo que limita directamente la capacidad de Nano Banana Pro.
🎯 Visión técnica: Diseñar tus propios chips TPU no garantiza potencia infinita. La capacidad de fabricación, la construcción de centros de datos y el suministro energético son factores limitantes. Recomendamos a las empresas utilizar la plataforma APIYI (apiyi.com) para obtener capacidades de gestión de cómputo multi-nube y evitar los riesgos de depender de un solo proveedor.
AI Studio vs. Vertex AI: Diferencias fundamentales
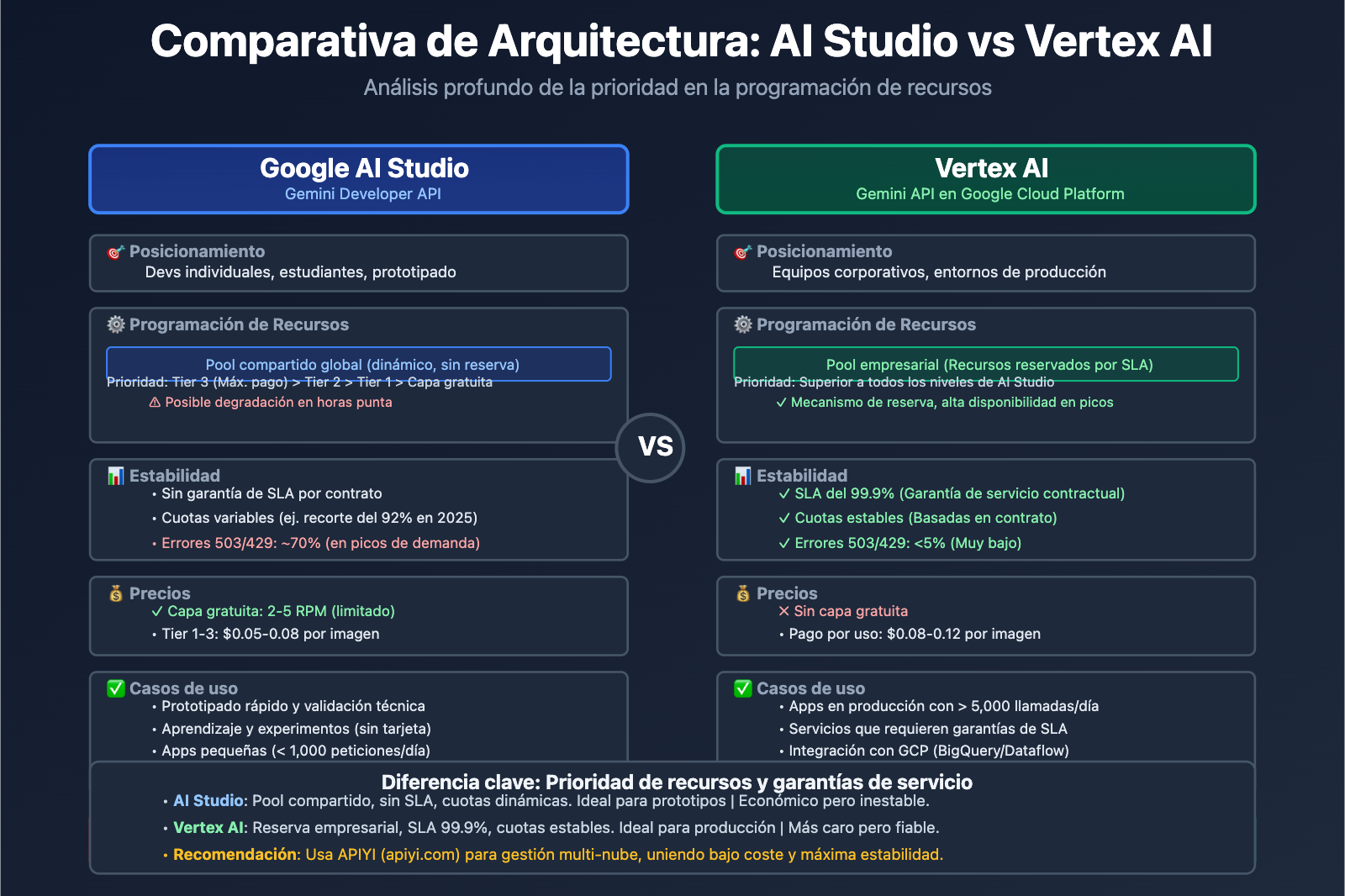
Muchos desarrolladores se preguntan: si tanto Gemini AI Studio como Vertex AI permiten llamar a los modelos Gemini, ¿por qué hay tanta diferencia en estabilidad y cuotas? La respuesta está en que sus arquitecturas están orientadas a fines totalmente distintos.
Comparativa de posicionamiento
| Dimensión | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API en GCP) |
|---|---|---|
| Usuario objetivo | Desarrolladores individuales, estudiantes, startups | Equipos empresariales, aplicaciones en producción |
| Barrera de entrada | Solo necesitas una API Key; prototipado en minutos | Requiere cuenta de Google Cloud y configuración de facturación |
| Modelo de precios | Capa gratuita (con límites) + Niveles de pago (Tier 1/2/3) | Pago por uso (sin capa gratuita), integrado en GCP |
| Garantía de SLA | Sin SLA (Acuerdo de Nivel de Servicio) | SLA empresarial, garantía de disponibilidad del 99.9% |
| Funcionalidades | API de modelos + herramientas visuales de prototipado | Flujo de ML completo (etiquetado, entrenamiento, ajuste, despliegue) |
| Estabilidad de cuota | Sujeta a la carga global; las cuotas pueden variar | Reserva de cuota empresarial, prioridad en recursos |
Ventajas y limitaciones de AI Studio
Ventajas:
- Inicio rápido: Obtienes tu clave API al instante sin configurar servicios en la nube.
- Herramientas visuales: Interfaz integrada para probar indicaciones (prompts) y realizar iteraciones rápidas.
- Capa gratuita atractiva: Ideal para aprendizaje, experimentos y proyectos pequeños.
Limitaciones:
- Sin garantía de SLA: La disponibilidad del servicio no está respaldada por contrato.
- Cuotas inestables: Como ocurrió el 7 de diciembre de 2025, cuando Gemini 2.5 Pro salió de la capa gratuita y el límite diario de 2.5 Flash cayó de 250 a 20 peticiones (un recorte del 92%).
- Sin características empresariales: No se puede integrar nativamente con BigQuery, Dataflow u otros servicios de GCP.
Capacidades empresariales de Vertex AI
Ventajas principales:
- Prioridad de recursos: Las peticiones de usuarios de pago tienen mayor prioridad en el sistema de programación de Google.
- Integración MLOps: Soporte para entrenamiento de modelos, gestión de versiones, pruebas A/B, monitorización y alertas.
- Soberanía de datos: Puedes elegir la región de almacenamiento para cumplir con normativas como GDPR o CCPA.
- Soporte empresarial: Equipo técnico dedicado y servicios de consultoría de arquitectura.
Casos de uso ideales:
- Aplicaciones en producción con más de 10,000 peticiones diarias.
- Escenarios que requieren ajuste fino (fine-tuning) y entrenamiento personalizado.
- Empresas con requisitos estrictos de SLA en cuanto a disponibilidad y tiempo de respuesta.
🎯 Recomendación: Si tu aplicación ya superó la fase de prototipo y realizas más de 5,000 llamadas al día, te sugerimos migrar a Vertex AI o usar una plataforma unificada como APIYI (apiyi.com). Esta plataforma integra recursos de múltiples proveedores de nube, permitiendo una gestión multiplataforma bajo una única interfaz, manteniendo la facilidad de AI Studio con la estabilidad de Vertex AI.
Razones profundas tras la escasez de Nano Banana Pro
Tras el análisis anterior, las razones por las que Nano Banana Pro sigue teniendo una demanda que supera la oferta pueden resumirse en los siguientes tres niveles:
1. Nivel técnico: Desequilibrio entre la capacidad de los chips y la demanda
- Aumento gradual de la capacidad de TPU v7: Se lanzó en abril de 2025, pero su despliegue a gran escala no se completará hasta 2026.
- Prioridad del entrenamiento sobre la inferencia: Las tareas de entrenamiento de la serie Gemini 3.0 ocupan una gran cantidad de recursos de TPU v6e y v7.
- Intensidad computacional de la generación de imágenes: La inferencia del modelo de difusión (Diffusion Model) de Nano Banana Pro requiere entre 5 y 10 veces más potencia de cálculo que los modelos de texto.
2. Nivel comercial: Ajuste de la estrategia del nivel gratuito
| Momento | Cambio de política | Razón de fondo |
|---|---|---|
| Noviembre de 2025 | Lanzamiento de Nano Banana Pro, nivel gratuito: 3 imágenes/día | Obtener rápidamente comentarios de los usuarios y establecer una posición en el mercado. |
| 7 de diciembre de 2025 | El nivel gratuito baja a 2 imágenes/día, Gemini 2.5 Pro se elimina del nivel gratuito | Los costes de computación superaron el presupuesto; necesidad de controlar el crecimiento de usuarios gratuitos. |
| Enero de 2026 | El RPM del nivel gratuito baja de 10 a 5 | Reservar recursos para los clientes empresariales de Gemini 2.0 Flash. |
Google declaró explícitamente en su foro oficial que estos ajustes se realizaron para "garantizar una calidad de servicio sostenible". En realidad, la explosión de usuarios del nivel gratuito (especialmente por herramientas de automatización y llamadas masivas) provocó que los costes se descontrolaran, obligando a Google a endurecer sus políticas.
3. Nivel de arquitectura: Aislamiento de recursos entre AI Studio y Vertex AI
Aunque ambas plataformas llaman al mismo modelo subyacente, tienen diferentes prioridades de programación de recursos dentro de Google:
- Vertex AI: Se conecta directamente al grupo de potencia de cálculo de nivel empresarial de GCP y disfruta de reservas de recursos garantizadas por SLA (Acuerdos de Nivel de Servicio).
- AI Studio: Comparte un grupo de recursos global y su prioridad se reduce durante las horas punta.
Este diseño de arquitectura hace que los usuarios del nivel gratuito y del Tier 1 de AI Studio sean más propensos a encontrar errores 429/503, mientras que los usuarios de pago de Vertex AI se ven menos afectados.
4. Estrategia de producto: De "capturar el mercado" a "optimizar la rentabilidad"
En la fase inicial del lanzamiento de Nano Banana Pro, Google adoptó una estrategia gratuita agresiva para competir con rivales como DALL-E 3 y Midjourney. Sin embargo, con el crecimiento explosivo del volumen de usuarios, Google se dio cuenta de que el modelo de negocio del nivel gratuito no era sostenible y comenzó a inclinar los recursos hacia los "usuarios de pago de alto valor".
El evento que marcó este cambio fue el recorte de cuotas y la eliminación del nivel gratuito de 2.5 Pro en diciembre de 2025, lo que la comunidad de desarrolladores denominó el "Free Tier Fiasco" (El fiasco del nivel gratuito).
🎯 Estrategia de respuesta: Para aplicaciones de producción que dependen de Nano Banana Pro, se recomienda adoptar una estrategia de respaldo multicloud. A través de la plataforma APIYI (apiyi.com), puedes configurar reglas de cambio automático entre múltiples modelos como Nano Banana Pro, DALL-E 3 y Stable Diffusion bajo una única interfaz. Cuando un servicio se sobrecarga, el sistema cambia automáticamente a una alternativa, garantizando la continuidad del negocio.
Cómo los desarrolladores pueden enfrentar la inestabilidad de Nano Banana Pro
Basándonos en el análisis anterior, aquí presentamos cuatro soluciones técnicas probadas:
Opción 1: Implementar un mecanismo de reintento con retroceso exponencial
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""Llamada a la API de Nano Banana Pro usando una estrategia de retroceso exponencial"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # Tu función real de llamada a la API
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Error de sobrecarga detectado, reintentando en {wait_time:.2f} segundos...")
time.sleep(wait_time)
else:
raise e
raise Exception("Se alcanzó el número máximo de reintentos")
Idea central: Cuando se encuentra un error 503 o 429, el tiempo de espera aumenta exponencialmente (1s → 2s → 4s → 8s), evitando el efecto avalancha.
Implementación completa de nivel de producción (clic para desplegar)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""Método de generación de imágenes de nivel de producción con manejo de errores y monitoreo completo"""
for attempt in range(self.max_retries):
try:
# Lógica real de llamada a la API
response = self._call_api(prompt, **kwargs)
logger.info(f"Solicitud exitosa (intento {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"Error {error_code}: {str(e)[:100]} | "
f"Esperando {wait_time:.2f}s (intento {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"Máximo de reintentos alcanzado, fallo final: {str(e)}")
raise
else:
logger.error(f"Error no reintentable: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""Calcula el tiempo de retroceso exponencial con jitter para evitar reintentos síncronos"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # Máximo de 60 segundos de espera
def _parse_error_code(self, error: Exception) -> int:
"""Extrae el código de estado HTTP de una excepción"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""Lógica real de la llamada a la API (debe reemplazarse con la implementación real)"""
# Aquí va tu código de llamada a la API real
pass
# Ejemplo de uso
client = NanoBananaClient(api_key="tu_api_key")
result = client.generate_image("un lindo gato tocando el piano")
Opción 2: Control del intervalo de solicitudes
Según los comentarios de la comunidad de desarrolladores, añadir un retraso fijo de 5 a 10 segundos entre solicitudes puede reducir significativamente la tasa de errores 503:
import time
def batch_generate_images(prompts):
"""Generación de imágenes por lotes, controlando estrictamente la frecuencia de solicitudes"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # No es necesario esperar tras la última solicitud
time.sleep(7) # Intervalo fijo de 7 segundos
return results
Escenario aplicable: Aplicaciones que no son en tiempo real, como la generación de contenido por lotes o el procesamiento de datos fuera de línea.
Opción 3: Estrategia de respaldo multicloud
Lograr una transferencia automática de fallos (failover) mediante una plataforma de API unificada:
| Paso | Implementación técnica | Efecto esperado |
|---|---|---|
| 1. Configurar modelos principal y de reserva | Nano Banana Pro (principal) + DALL-E 3 (reserva) | Tolerancia a fallos de punto único |
| 2. Establecer reglas de cambio | 3 errores 503 consecutivos → cambiar automáticamente al de reserva | Reducción de la latencia percibida por el usuario |
| 3. Monitorear estado de recuperación | Probar la salud del servicio principal cada 5 minutos | Recuperación automática al servicio principal |
🎯 Implementación recomendada: La plataforma APIYI (apiyi.com) admite nativamente esta estrategia de programación multicloud. Solo necesitas configurar las reglas de cambio en la consola; el sistema se encargará automáticamente de la detección de fallos, el desvío de tráfico y la optimización de costes, sin necesidad de modificar el código de tu aplicación.
Opción 4: Actualizar a Vertex AI o plataformas empresariales
Si tu aplicación cumple con cualquiera de las siguientes condiciones, se recomienda considerar la actualización:
- Volumen diario de llamadas a la API > 5,000 veces.
- Requisitos estrictos de SLA para el tiempo de respuesta (ej. percentil 95 < 10 segundos).
- No se pueden aceptar interrupciones del servicio (ej. generación de imágenes para comercio electrónico, moderación de contenido en tiempo real).
Comparativa de costes:
AI Studio Tier 1: $0.05/imagen (pero con sobrecargas frecuentes)
Vertex AI: $0.08/imagen (estable, con SLA)
Plataforma APIYI: $0.06/imagen (programación multicloud, tolerancia a fallos automática)
Aunque el precio unitario de Vertex AI es más alto, al considerar los costes de reintento, el tiempo de desarrollo y las pérdidas comerciales, el TCO real (Coste Total de Propiedad) podría ser menor.
Preguntas frecuentes (FAQ)
Q1: ¿Por qué los usuarios de pago también encuentran el error "modelo sobrecargado"?
R: El cuello de botella de capacidad de Nano Banana Pro ocurre en la capa de programación de cómputo global de Google, no en la capa de cuota del usuario. Incluso si eres un usuario de pago Tier 3, recibirás un error 503 cuando el grupo de cómputo global esté saturado. Esto es diferente al error tradicional 429 de exceso de cuota.
La diferencia es:
- Error 429: Has agotado tu cuota personal (como el límite de RPM).
- Error 503: Falta de capacidad de cómputo en el lado del servidor de Google, independientemente de tu cuota.
Q2: ¿AI Studio y Vertex AI llaman al mismo modelo?
R: Sí, ambos llaman al mismo modelo Nano Banana Pro subyacente (gemini-2.0-flash-preview-image-generation). Sin embargo, tienen prioridades de programación de recursos diferentes:
- Vertex AI: Garantía de SLA de nivel empresarial, con prioridad en la asignación de cómputo.
- AI Studio: Grupo de recursos compartidos, que puede sufrir degradaciones durante las horas pico.
Esto es similar a la diferencia entre el "pago por uso" y las "instancias reservadas anuales/mensuales" en los servidores en la nube.
Q3: ¿Seguirá Google recortando las cuotas del nivel gratuito?
R: Según las tendencias históricas, es probable que Google continúe ajustando sus políticas para el nivel gratuito:
- Noviembre de 2025: Nivel gratuito a 3 imágenes/día.
- 7 de diciembre de 2025: Baja a 2 imágenes/día, se elimina 2.5 Pro.
- Enero de 2026: El RPM baja de 10 a 5.
La postura oficial de Google es "garantizar una calidad de servicio sostenible", pero en realidad se trata de buscar un equilibrio entre el control de costes y el crecimiento de usuarios. Se recomienda que las aplicaciones en producción no dependan del nivel gratuito y planifiquen con antelación soluciones de pago o respaldos multinube.
Q4: ¿Cuándo mejorará la estabilidad de Nano Banana Pro?
R: Según la información pública de Google, los hitos clave se sitúan a mediados de 2026:
- Q2 de 2026: Finalización del despliegue masivo de TPU v7 (Ironwood).
- Q3 de 2026: Entrada en funcionamiento de 1 GW de potencia de cómputo en colaboración con Anthropic.
En ese momento, la oferta de cómputo aumentará significativamente, aunque la demanda también podría crecer en paralelo. Siendo conservadores, la estabilidad tendrá una mejora sustancial en la segunda mitad de 2026.
Q5: ¿Cómo elegir la forma de acceso a Nano Banana Pro?
R: Elige según la etapa de tu aplicación:
| Etapa | Solución recomendada | Razón |
|---|---|---|
| Desarrollo de prototipos | Nivel gratuito de AI Studio | Coste mínimo, validación rápida de ideas |
| Lanzamiento a pequeña escala | AI Studio Tier 1 + Mecanismo de reintento | Equilibrio entre coste y estabilidad |
| Entorno de producción | Vertex AI o plataforma APIYI | Garantía de SLA, soporte empresarial |
| Operaciones críticas | Estrategia de respaldo multinube (ej. plataforma APIYI) | Máxima disponibilidad, conmutación por error automática |
🎯 Sugerencia de decisión: Si no estás seguro de qué elegir, te recomiendo realizar pruebas A/B a través de la plataforma APIYI (apiyi.com). Esta plataforma permite comparar el rendimiento real de modelos como Nano Banana Pro (AI Studio), Nano Banana Pro (Vertex AI) y DALL-E 3 bajo las mismas solicitudes, ayudándote a decidir basándote en datos reales.
Resumen: Una visión racional de los desafíos de cómputo de Nano Banana Pro
Los problemas de estabilidad de Nano Banana Pro no son eventos aislados, sino un reflejo de la contradicción entre la oferta y la demanda de cómputo que enfrenta toda la industria de la IA:
Contradicciones principales:
- Lado de la demanda: Crecimiento explosivo de las aplicaciones de IA generativa, especialmente en el ámbito de la generación de imágenes.
- Lado de la oferta: El aumento de la producción de chips es lento y los ciclos de construcción de centros de datos son largos (12-18 meses).
- Modelo económico: Las estrategias de nivel gratuito no son sostenibles, pero la tasa de conversión a pago es baja.
Tres verdades técnicas:
-
TPU propia ≠ Cómputo infinito: Aunque Google posee chips avanzados como el TPU v7, aumentar la producción, el suministro de energía y la construcción de centros de datos requiere tiempo. 2026 será el punto de inflexión clave.
-
La esencia de AI Studio vs Vertex AI: No es simplemente una relación de "versión gratuita" y "versión de pago", sino una manifestación de diferentes prioridades de programación de recursos. Detrás del SLA empresarial de Vertex AI hay un mecanismo de reserva de cómputo independiente.
-
La escasez persistirá a largo plazo: Con el lanzamiento de nuevos modelos como Gemini 3.0 o GPT-5, la demanda de cómputo seguirá creciendo. A corto plazo (2026-2027), la tensión entre oferta y demanda no cambiará fundamentalmente.
Consejos prácticos:
- A corto plazo: Utiliza medios de ingeniería como mecanismos de reintento y control de intervalos de solicitud para mitigar el problema.
- A medio plazo: Evalúa el ROI (retorno de inversión) de actualizar a Vertex AI o a plataformas multinube.
- A largo plazo: Presta atención al progreso de la expansión de cómputo de Google a mediados de 2026 y ajusta tu estrategia oportunamente.
Para aplicaciones de nivel empresarial, recomendamos encarecidamente adoptar una estrategia de respaldo multinube para evitar los riesgos de capacidad de un único proveedor. A través de una plataforma unificada como APIYI (apiyi.com), puedes obtener capacidades de programación entre nubes, conmutación por error automática y optimización de costes sin aumentar la complejidad de tu código.
Reflexión final: Los desafíos de Nano Banana Pro nos recuerdan que la estabilidad de una aplicación de IA no solo depende de la capacidad del modelo, sino también de la madurez de la infraestructura subyacente. En esta era donde el cómputo es el rey, la robustez del diseño de arquitectura y la diversificación de proveedores se están convirtiendo en claves de la competitividad del producto.
Lecturas relacionadas:
- Guía de uso de la API de Nano Banana Pro
- Análisis profundo de la arquitectura Google TPU v7
- Cómo elegir una API de generación de imágenes por IA: Nano Banana Pro vs DALL-E 3 vs Stable Diffusion
- 10 mejores prácticas para llamadas a APIs de IA en entornos de producción