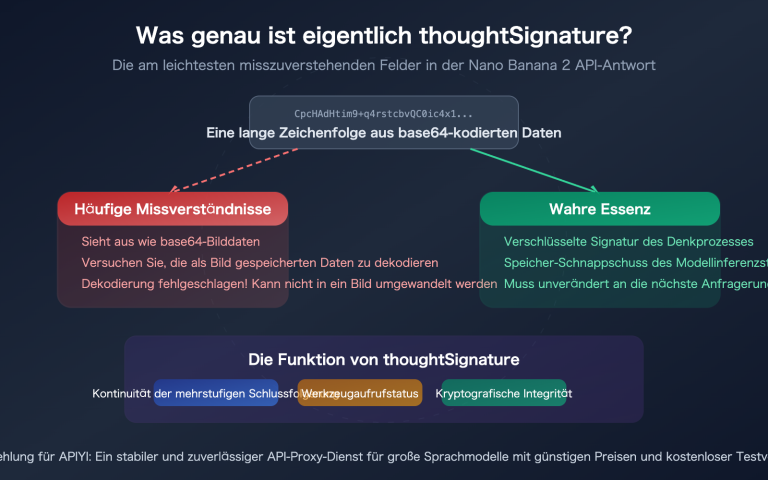
Anmerkung des Autors: Enthüllung der Ursachen für die häufige Überlastung der Nano Banana Pro API – von Googles hauseigener TPU-Chip-Architektur bis hin zu den Unterschieden zwischen AI Studio und Vertex AI. Verstehen Sie die technische Wahrheit hinter dem Nachfrageüberhang.
Seit der Einführung von Nano Banana Pro im November 2025 beobachten Entwickler ein rätselhaftes Phänomen: Obwohl Google über eigene TPU-Chips verfügt, tritt bei dieser Bildgenerierungs-API weiterhin häufig der Fehler „Modell überlastet“ auf. Warum können selbst entwickelte Chips das Problem der Rechenkapazität nicht lösen? Was sind die wesentlichen Unterschiede zwischen AI Studio und Vertex AI? In diesem Artikel analysieren wir die technische Wahrheit hinter diesen Fragen ausgehend von der zugrunde liegenden Logik der Rechenarchitektur von Google.
Kernwert: Durch reale Daten und Architekturanalysen helfen wir Ihnen, die Ursachen der Stabilitätsprobleme von Nano Banana Pro zu verstehen und die richtige Wahl für eine zuverlässige API-Integrationslösung zu treffen.
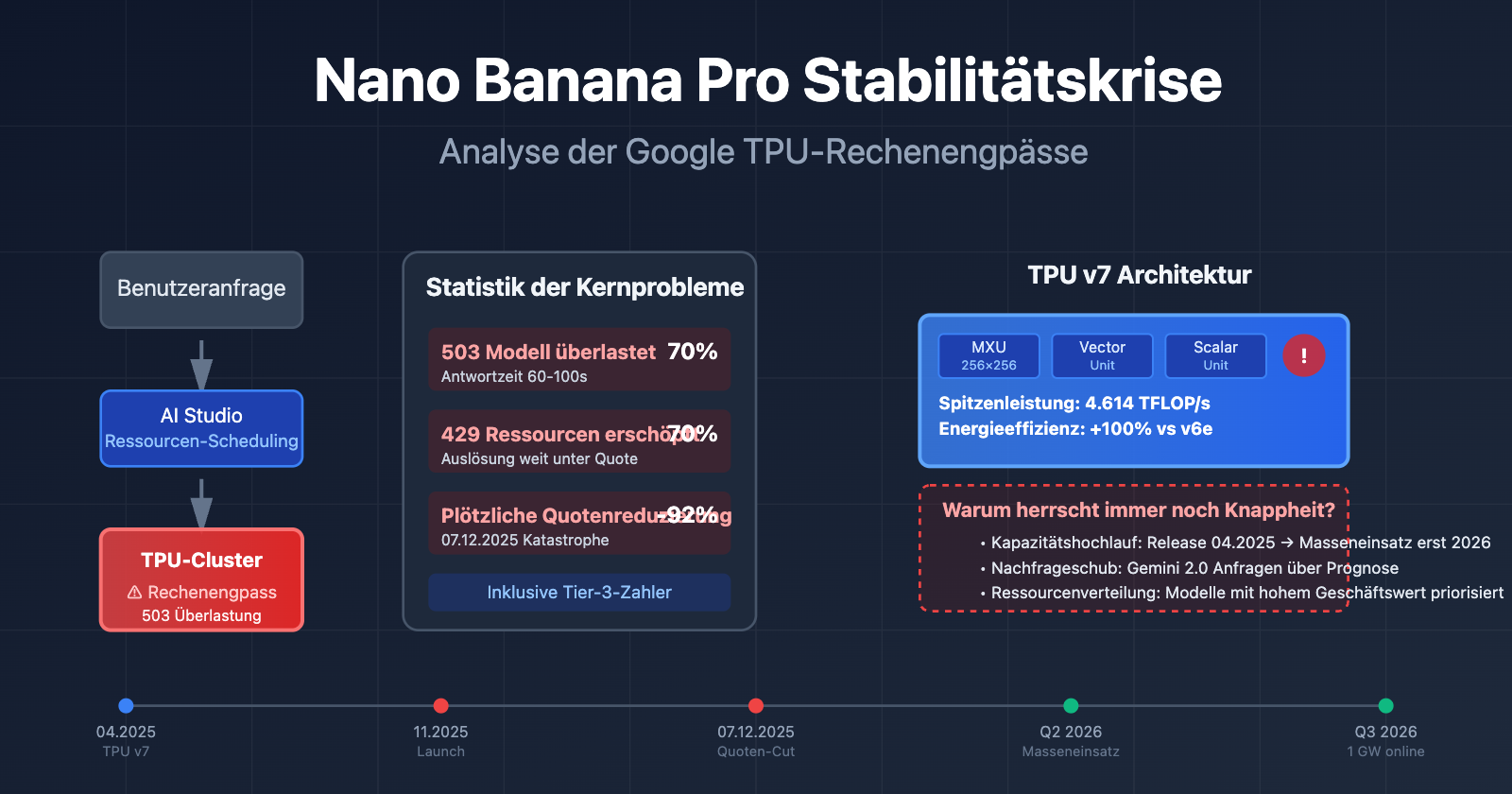
Kernprobleme bei der Stabilität der Nano Banana Pro API
Seit dem Start im November 2025 sieht sich Nano Banana Pro (gemini-2.0-flash-preview-image-generation) einer anhaltenden Stabilitätskrise gegenüber. Hier sind die Kerndaten der von der Entwickler-Community gemeldeten Probleme:
| Fehlertyp | Häufigkeit | Typisches Symptom | Auswirkungen |
|---|---|---|---|
| 503 Modellüberlastung | Hochfrequent (70%+ Fehleranteil) | Die Antwortzeit steigt sprunghaft von 30 auf 60–100 Sekunden | Alle Nutzerstufen (einschließlich zahlender Tier-3-Nutzer) |
| 429 Ressourcenerschöpfung | ca. 70 % der API-Fehler | Wird ausgelöst, obwohl das Kontingent bei weitem nicht ausgeschöpft ist | Kostenlose Stufe und Tier-1-Zahler |
| Plötzliche Quoten-Kürzung | 7. Dezember 2025 | Kostenlose Stufe von 3 auf 2 Bilder/Tag gesenkt, 2.5 Pro aus der kostenlosen Stufe entfernt | Globale Nutzer der kostenlosen Stufe |
| Dienst nicht verfügbar | Sporadisch | Am einen Tag schnelle Generierung, am nächsten komplett unerreichbar | App-Entwickler, die auf die kostenlose Stufe angewiesen sind |
Ursachen für die Stabilitätsprobleme von Nano Banana Pro
Der Kern dieser Probleme liegt nicht in Code-Fehlern, sondern in Engpässen bei der Rechenkapazität auf den Google-Servern. Selbst zahlende Tier-3-Nutzer (die höchste Kontingentstufe) stoßen auf Überlastungsfehler, wenn ihre Anfragefrequenz weit unter den offiziellen Limits liegt. Dies deutet darauf hin, dass das Problem auf Infrastrukturebene und nicht bei der Verwaltung der Nutzerkontingente liegt.
Laut offiziellen Antworten von Google in Entwicklerforen werden Rechenressourcen derzeit neu priorisiert und den neuen Modellen der Gemini 2.0-Serie zugewiesen. Dies führt dazu, dass die verfügbare Kapazität für Bildgenerierungsmodelle wie Nano Banana Pro eingeschränkt ist. Diese Strategie der Ressourcenplanung führt direkt zur Instabilität des Dienstes.
🎯 Technischer Rat: Wenn Sie Nano Banana Pro in einer Produktionsumgebung einsetzen, empfiehlt es sich, den Zugriff über die Plattform APIYI (apiyi.com) zu realisieren. Diese Plattform bietet intelligenten Lastausgleich und automatische Failover-Mechanismen, wodurch die Erfolgsrate und Stabilität Ihrer API-Aufrufe erheblich gesteigert werden können.
Die Wahrheit hinter der Google-eigenen TPU-Chiparchitektur
Viele glauben, dass Google mit seinen eigenen TPU-Chips (Tensor Processing Unit) den Rechenleistungsbedarf für KI-Modelle mühelos decken kann. Doch die Realität ist weitaus komplexer, als man denkt.
Die neueste Architektur der TPU v7 (Ironwood)
Im April 2025 stellte Google auf der Cloud Next Konferenz die siebte Generation seiner TPU vor – Ironwood. Dies ist die bisher leistungsstärkste Version:
| Architekturparameter | TPU v7 (Ironwood) | TPU v6e (Trillium) | Steigerung |
|---|---|---|---|
| Spitzenrechenleistung | 4.614 TFLOP/s | ca. 2.300 TFLOP/s | ~100% |
| Energieeffizienz | Benchmark | Referenz | 100% Leistungssteigerung pro Watt |
| Cluster-Konfiguration | 256 Chips / 9.216 Chips | Einzelkonfiguration | Flexible Skalierbarkeit |
| Matrix-Einheiten | 256×256 MXU (systolic array) | 128×128 MXU | 4-fache Rechendichte |
| Anwendungsszenario | Inference-first | Training + Inferenz (Mix) | Spezielle Optimierung für Inferenz |
Kernkomponenten der TPU-Architektur
Jeder TPU-Chip enthält einen oder mehrere TensorCores, wobei jeder TensorCore aus folgenden Teilen besteht:
- Matrix Multiplication Unit (MXU): Die Versionen TPU v6e und v7x nutzen ein 256×256 Multiply-Accumulate-Array, während frühere Versionen auf 128×128 setzten.
- Vector Unit: Verarbeitet Nicht-Matrix-Operationen.
- Scalar Unit: Führt die Steuerungslogik aus.
Diese Systolic-Array-Architektur ist besonders gut für die Inferenz neuronaler Netze geeignet, hat aber auch ihre Grenzen.
Warum lösen selbst entwickelte Chips den Rechenleistungsengpass nicht?
Trotz der starken Leistung der TPU v7 bestehen weiterhin Stabilitätsprobleme bei Nano Banana Pro. Dafür gibt es drei Gründe:
1. Kapazitätshochlauf-Phase (Ramp-up)
Die TPU v7 wurde im April 2025 veröffentlicht, aber ein flächendeckender Einsatz braucht Zeit. Ende 2025 kündigte Google eine Partnerschaft mit Anthropic in Milliardenhöhe an, mit dem Ziel, bis 2026 über 1 GW an KI-Rechenleistung online zu bringen. Das bedeutet, dass der Zeitraum von November 2025 bis Anfang 2026 eine Übergangsphase beim Kapazitätsaufbau ist, in der der Wechsel zwischen alter und neuer Architektur zu Ressourcenengpässen führt.
2. Explosionsartiges Nachfragewachstum
Nach der Veröffentlichung der Gemini 2.0-Serie Ende 2025 überstiegen die API-Anfragen Googles ursprüngliche Prognosen bei Weitem. Der Zustrom von Nutzern der kostenlosen Version (insbesondere für die Bildgenerierung von Nano Banana Pro) verdrängt Ressourcen aus dem Pool für zahlende Kunden.
3. Priorisierung der Ressourcenzuweisung
Google muss den Bedarf an Rechenleistung für verschiedene KI-Produktlinien ausbalancieren: Gemini 2.5 Pro (Text), Gemini 2.0 Flash (Multimodal), Nano Banana Pro (Bildgenerierung) usw. Wenn die Kapazitäten begrenzt sind, werden Modelle mit höherem kommerziellem Wert bevorzugt, was direkt zu Kapazitätsbeschränkungen bei Nano Banana Pro führt.
🎯 Architektur-Einsicht: Die Eigenentwicklung von TPU-Chips bedeutet nicht unbegrenzte Rechenleistung. Chip-Kapazitäten, der Bau von Rechenzentren und die Energieversorgung sind limitierende Faktoren. Wir empfehlen Unternehmenskunden, die Multi-Cloud-Scheduling-Fähigkeiten der Plattform APIYI (apiyi.com) zu nutzen, um Kapazitätsrisiken einzelner Anbieter zu vermeiden.
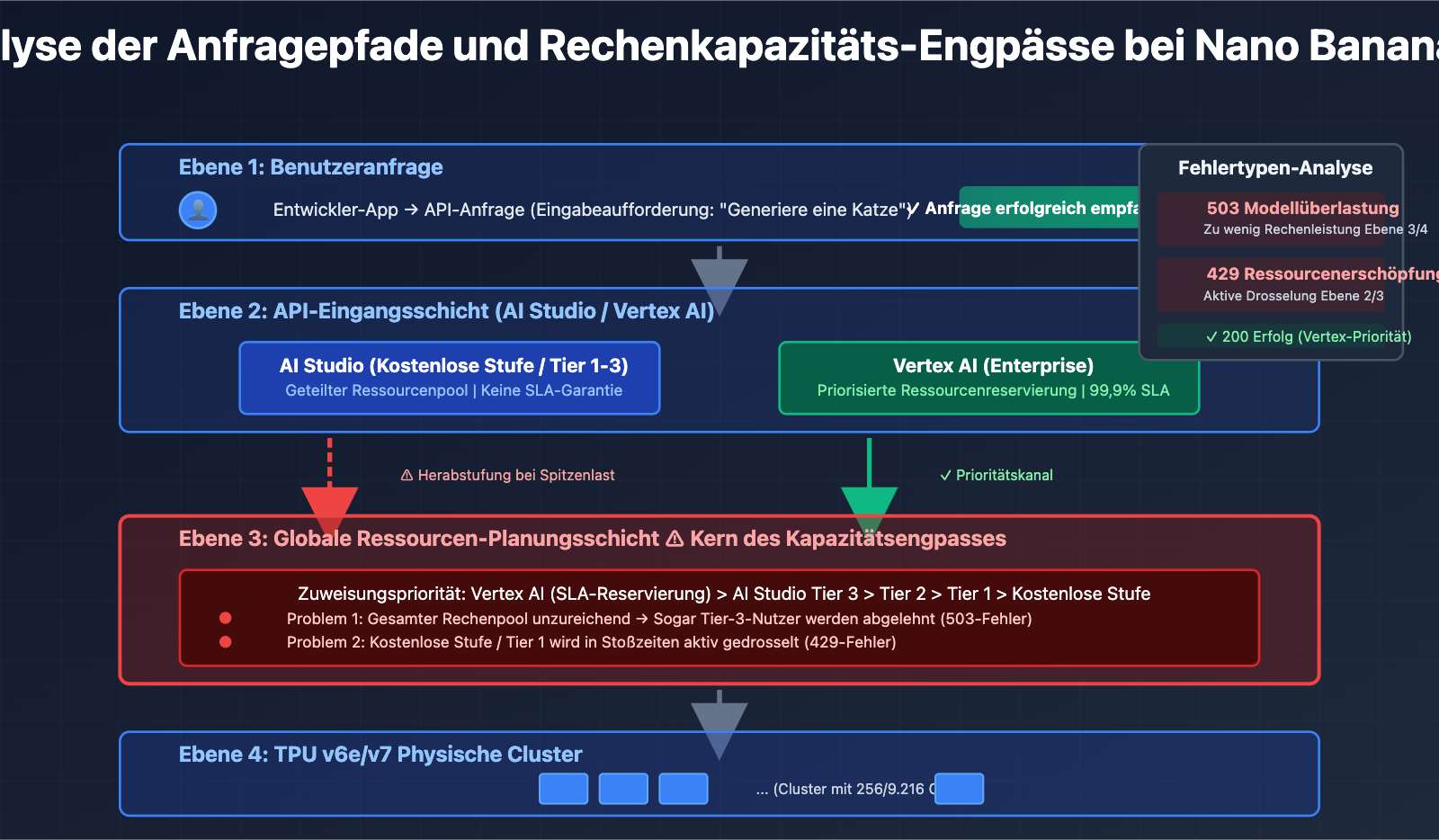
AI Studio vs. Vertex AI: Die wesentlichen Unterschiede der beiden Plattformen
Viele Entwickler sind verwirrt: Sowohl Gemini AI Studio als auch Vertex AI können Gemini-Modelle aufrufen. Warum gibt es dann so große Unterschiede bei der Stabilität und den Quoten? Die Antwort liegt in der völlig unterschiedlichen architektonischen Ausrichtung der beiden Systeme.
Vergleich der Plattform-Positionierung
| Dimension | Google AI Studio (Gemini Developer API) | Vertex AI (Gemini API auf GCP) |
|---|---|---|
| Zielgruppe | Einzelentwickler, Studenten, Startups | Unternehmensteams, Produktionsanwendungen |
| Einstiegshürde | API-Key anfordern und in Minuten starten | Google Cloud-Konto und Abrechnung erforderlich |
| Preismodell | Kostenlose Stufe (begrenzt) + Tier 1/2/3 Pay-as-you-go | Abrechnung nach Nutzung (kein Free Tier), integriert in GCP Billing |
| SLA-Garantie | Kein SLA (Service Level Agreement) | Enterprise-SLA, 99,9% Verfügbarkeit |
| Funktionsumfang | Nur Modell-API + Prototyping-Tools | Vollständiger ML-Workflow (Training, Tuning, Monitoring) |
| Quotenstabilität | Abhängig von globaler Auslastung, Quoten variabel | Reservierte Enterprise-Quoten, Priorität bei Ressourcen |
Kernvorteile und Grenzen von AI Studio
Vorteile:
- Schneller Einstieg: Nach der Registrierung sofort API-Keys erhalten, ohne Cloud-Konfiguration.
- Visuelle Prototyping-Tools: Integrierte Schnittstelle zum Testen von Eingabeaufforderungen für schnelle Iterationen.
- Attraktive Gratis-Stufe: Ideal zum Lernen, Experimentieren und für kleine Projekte.
Grenzen:
- Keine SLA-Garantie: Die Verfügbarkeit ist nicht vertraglich zugesichert.
- Instabile Quoten: Wie bei der plötzlichen Kürzung am 7. Dezember 2025, als Gemini 2.5 Pro aus der Gratis-Stufe entfernt wurde und das Limit für 2.5 Flash um 92% sank.
- Mangelnde Enterprise-Features: Keine Integration mit GCP-Datendiensten wie BigQuery oder Dataflow.
Enterprise-Fähigkeiten von Vertex AI
Kernvorteile:
- Ressourcen-Priorität: Anfragen von zahlenden Kunden haben im internen Scheduling-System von Google eine höhere Priorität.
- MLOps-Integration: Unterstützt den gesamten Lebenszyklus von Modelltraining, Versionierung, A/B-Tests und Monitoring.
- Datensouveränität: Speicherregionen sind wählbar, konform mit DSGVO, CCPA und anderen Standards.
- Enterprise-Support: Dedizierte technische Support-Teams und Architekturberatung.
Anwendungsszenarien:
- Produktionsanwendungen mit mehr als 10.000 Anfragen pro Tag.
- Szenarien, die Feinabstimmung (Fine-tuning) und individuelles Training erfordern.
- Unternehmen mit strengen SLA-Anforderungen an Verfügbarkeit und Antwortzeiten.
🎯 Auswahl-Empfehlung: Wenn Ihre Anwendung die Prototyp-Phase verlassen hat und mehr als 5.000 Aufrufe pro Tag verzeichnet, empfehlen wir die Migration zu Vertex AI oder die Nutzung einer einheitlichen Plattform wie APIYI (apiyi.com). Diese Plattform integriert Rechenressourcen mehrerer Cloud-Anbieter und ermöglicht ein plattformübergreifendes Scheduling über eine einzige Schnittstelle – so erhalten Sie die Benutzerfreundlichkeit von AI Studio kombiniert mit der Stabilitätsgarantie von Vertex AI.

Die tieferen Gründe für die Knappheit von Nano Banana Pro
Basierend auf der vorangegangenen Analyse lassen sich die Gründe für die anhaltende Knappheit von Nano Banana Pro in drei Hauptebenen unterteilen:
1. Technische Ebene: Ungleichgewicht zwischen Chip-Kapazität und Nachfrage
- Hochfahren der TPU v7-Produktion: Veröffentlicht im April 2025, wird der großflächige Einsatz jedoch erst 2026 abgeschlossen sein.
- Training hat Vorrang vor Inferenz: Die Trainingsaufgaben für die Gemini 3.0-Serie beanspruchen einen Großteil der TPU v6e- und v7-Ressourcen.
- Rechenintensive Bildgenerierung: Die Inferenz des Diffusionsmodells (Diffusion Model) von Nano Banana Pro benötigt 5- bis 10-mal mehr Rechenleistung als ein Textmodell.
2. Geschäftliche Ebene: Strategische Anpassung der kostenlosen Stufe
| Zeitpunkt | Richtlinienänderung | Hintergrund/Grund |
|---|---|---|
| November 2025 | Nano Banana Pro geht online, kostenlose Stufe: 3 Bilder/Tag | Schnelles Einholen von Nutzerfeedback, Etablierung der Marktposition. |
| 7. Dezember 2025 | Kostenlose Stufe auf 2 Bilder/Tag gesenkt, Gemini 2.5 Pro aus der kostenlosen Stufe entfernt | Rechenkosten übersteigen das Budget, Wachstum der kostenlosen Nutzer muss kontrolliert werden. |
| Januar 2026 | RPM (Requests Per Minute) der kostenlosen Stufe von 10 auf 5 gesenkt | Reservierung von Ressourcen für Unternehmenskunden von Gemini 2.0 Flash. |
Google gab in offiziellen Foren deutlich an, dass diese Anpassungen vorgenommen wurden, um eine "nachhaltige Servicequalität zu gewährleisten". Tatsächlich führte der sprunghafte Anstieg der Nutzer in der kostenlosen Stufe (insbesondere durch Automatisierungstools und Batch-Aufrufe) zu unkontrollierten Kosten, was Google dazu zwang, die Richtlinien zu verschärfen.
3. Architekturebene: Ressourcenisolierung zwischen AI Studio und Vertex AI
Obwohl beide Plattformen dieselben zugrunde liegenden Modelle aufrufen, haben sie innerhalb von Google unterschiedliche Prioritäten bei der Ressourcenplanung:
- Vertex AI: Direkt mit dem Enterprise-Rechenpool von GCP verbunden, genießt Ressourcenreservierungen mit SLA-Garantie.
- AI Studio: Nutzt einen gemeinsamen globalen Ressourcenpool, der in Stoßzeiten herabgestuft wird.
Dieses Architekturdesign führt dazu, dass Nutzer der kostenlosen Stufe und Tier-1-Nutzer von AI Studio häufiger auf 429/503-Fehler stoßen, während zahlende Nutzer von Vertex AI weniger betroffen sind.
4. Produktstrategie: Von „Markteroberung“ zu „Gewinnoptimierung“
In der Anfangsphase von Nano Banana Pro verfolgte Google eine aggressive Gratis-Strategie, um gegen Konkurrenten wie DALL-E 3 und Midjourney anzutreten. Mit dem explosionsartigen Wachstum der Nutzerzahlen erkannte Google jedoch, dass das Geschäftsmodell der kostenlosen Stufe nicht nachhaltig ist, und begann, Ressourcen verstärkt für „hochwertige zahlende Nutzer“ bereitzustellen.
Das wegweisende Ereignis dieser Kehrtwende war die Kontingentkürzung und die Entfernung der kostenlosen Stufe für 2.5 Pro im Dezember 2025, was in der Entwickler-Community als „Free Tier Fiasco“ bezeichnet wurde.
🎯 Reaktionsstrategie: Für Produktionsanwendungen, die auf Nano Banana Pro angewiesen sind, wird eine Multi-Cloud-Backup-Strategie empfohlen. Über die Plattform APIYI (apiyi.com) können Sie unter einer einzigen Schnittstelle automatische Wechselregeln für Nano Banana Pro, DALL-E 3, Stable Diffusion und andere Modelle konfigurieren. Wenn ein Dienst überlastet ist, wird automatisch auf eine Alternative umgeschaltet, um die Geschäftskontinuität zu gewährleisten.
Wie Entwickler auf die Instabilität von Nano Banana Pro reagieren können
Basierend auf der vorherigen Analyse finden Sie hier vier praxiserprobte technische Lösungen:
Lösung 1: Implementierung eines exponentiellen Backoff-Wiederholungsmechanismus
import time
import random
def call_nano_banana_with_retry(prompt, max_retries=5):
"""Aufruf der Nano Banana Pro API mit einer Strategie für exponentiellen Backoff"""
for attempt in range(max_retries):
try:
response = call_api(prompt) # Ihre eigentliche API-Aufruffunktion
return response
except Exception as e:
if "503" in str(e) or "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Überlastungsfehler aufgetreten, warte {wait_time:.2f} Sekunden vor erneutem Versuch...")
time.sleep(wait_time)
else:
raise e
raise Exception("Maximale Anzahl an Versuchen erreicht")
Kernidee: Wenn ein 503/429-Fehler auftritt, wächst die Wartezeit exponentiell an (1s → 2s → 4s → 8s), um einen Kaskadeneffekt (Avalanche Effect) zu vermeiden.
Vollständige Implementierung auf Produktionsniveau (Zum Aufklappen klicken)
import time
import random
import logging
from typing import Optional, Dict, Any
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class NanoBananaClient:
def __init__(self, api_key: str, base_delay: float = 1.0, max_retries: int = 5):
self.api_key = api_key
self.base_delay = base_delay
self.max_retries = max_retries
def generate_image(self, prompt: str, **kwargs) -> Optional[Dict[str, Any]]:
"""Bildgenerierungsmethode auf Produktionsniveau mit vollständiger Fehlerbehandlung und Monitoring"""
for attempt in range(self.max_retries):
try:
# Eigentliche API-Aufruflogik
response = self._call_api(prompt, **kwargs)
logger.info(f"Anfrage erfolgreich (Versuch {attempt + 1}/{self.max_retries})")
return response
except Exception as e:
error_code = self._parse_error_code(e)
if error_code in [429, 503]:
if attempt < self.max_retries - 1:
wait_time = self._calculate_backoff(attempt)
logger.warning(
f"Fehler {error_code}: {str(e)[:100]} | "
f"Warten {wait_time:.2f}s (Versuch {attempt + 1}/{self.max_retries})"
)
time.sleep(wait_time)
else:
logger.error(f"Maximale Versuche erreicht, endgültiger Fehler: {str(e)}")
raise
else:
logger.error(f"Nicht wiederholbarer Fehler: {str(e)}")
raise
return None
def _calculate_backoff(self, attempt: int) -> float:
"""Berechnet exponentiellen Backoff mit Jitter, um synchrone Wiederholungen zu vermeiden"""
exponential_delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, self.base_delay)
return min(exponential_delay + jitter, 60.0) # Maximal 60 Sekunden warten
def _parse_error_code(self, error: Exception) -> int:
"""Extrahiert den HTTP-Statuscode aus der Exception"""
error_str = str(error)
if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str:
return 429
elif "503" in error_str or "overloaded" in error_str:
return 503
return 500
def _call_api(self, prompt: str, **kwargs) -> Dict[str, Any]:
"""Eigentliche API-Aufruflogik (muss durch echte Implementierung ersetzt werden)"""
# Hier den echten API-Aufrufcode einfügen
pass
# Beispielnutzung
client = NanoBananaClient(api_key="ihr_api_key")
result = client.generate_image("eine süße Katze, die Klavier spielt")
Lösung 2: Steuerung der Anfrageintervalle
Laut Feedback aus der Entwickler-Community kann das Hinzufügen einer festen Verzögerung von 5 bis 10 Sekunden zwischen den Anfragen die 503-Fehlerrate erheblich senken:
import time
def batch_generate_images(prompts):
"""Batch-Generierung von Bildern mit strikter Frequenzkontrolle"""
results = []
for i, prompt in enumerate(prompts):
result = call_api(prompt)
results.append(result)
if i < len(prompts) - 1: # Bei der letzten Anfrage ist kein Warten nötig
time.sleep(7) # Festes Intervall von 7 Sekunden
return results
Anwendungsfall: Nicht-Echtzeit-Anwendungen wie Batch-Content-Erstellung, Offline-Datenverarbeitung usw.
Lösung 3: Multi-Cloud-Backup-Strategie
Realisierung eines automatischen Failovers über eine vereinheitlichte API-Plattform:
| Schritt | Technische Umsetzung | Erwarteter Effekt |
|---|---|---|
| 1. Haupt- und Backup-Modell konfigurieren | Nano Banana Pro (Haupt) + DALL-E 3 (Backup) | Fehlertoleranz bei Single Point of Failure |
| 2. Wechselregeln festlegen | 3 aufeinanderfolgende 503-Fehler → automatischer Wechsel zum Backup | Reduzierung der für den Nutzer spürbaren Latenz |
| 3. Wiederherstellungsstatus überwachen | Alle 5 Minuten den Gesundheitszustand des Hauptdienstes prüfen | Automatische Rückkehr zum Hauptdienst |
🎯 Empfohlene Umsetzung: Die Plattform APIYI (apiyi.com) unterstützt diese Multi-Cloud-Scheduling-Strategie nativ. Sie müssen lediglich die Wechselregeln in der Konsole konfigurieren; das System kümmert sich automatisch um Fehlererkennung, Traffic-Umschaltung und Kostenoptimierung, ohne dass Sie Ihren Business-Code ändern müssen.
Lösung 4: Upgrade auf Vertex AI oder Enterprise-Plattformen
Wenn Ihre Anwendung eine der folgenden Bedingungen erfüllt, wird ein Upgrade empfohlen:
- Durchschnittliches tägliches API-Aufrufvolumen > 5.000
- Strenge SLA-Anforderungen an die Antwortzeit (z. B. 95. Perzentil < 10 Sekunden)
- Dienstunterbrechungen sind inakzeptabel (z. B. E-Commerce-Bildgenerierung, Echtzeit-Content-Moderation)
Kostenvergleich:
AI Studio Tier 1: $0.05/Bild (aber oft überlastet)
Vertex AI: $0.08/Bild (stabil, mit SLA)
APIYI-Plattform: $0.06/Bild (Multi-Cloud-Scheduling, automatische Fehlertoleranz)
Obwohl der Einzelpreis bei Vertex AI höher ist, können die tatsächlichen TCO (Total Cost of Ownership) niedriger sein, wenn man Wiederholungskosten, Entwicklungszeit und Geschäftsverluste berücksichtigt.
Häufig gestellte Fragen (FAQ)
Q1: Warum erhalten auch zahlende Nutzer die Fehlermeldung "Modell überlastet"?
A: Der Kapazitätsengpass bei Nano Banana Pro tritt auf der globalen Rechenleistungs-Steuerungsebene von Google auf, nicht auf der Ebene des Nutzerkontingents. Selbst wenn Sie ein Tier-3-Zahler sind, können Sie weiterhin 503-Fehler erhalten, wenn der gesamte Rechenpool ausgelastet ist. Dies unterscheidet sich vom klassischen 429-Fehler bei Überschreitung des Kontingents.
Der Unterschied liegt hier:
- 429-Fehler: Ihr persönliches Kontingent ist erschöpft (z. B. RPM-Limit).
- 503-Fehler: Die serverseitige Rechenleistung von Google reicht nicht aus, was unabhängig von Ihrem Kontingent ist.
Q2: Nutzen AI Studio und Vertex AI dasselbe Modell?
A: Ja, das zugrunde liegende Nano Banana Pro Modell (gemini-2.0-flash-preview-image-generation), das von beiden aufgerufen wird, ist absolut identisch. Sie unterscheiden sich jedoch in der Priorisierung der Ressourcenplanung:
- Vertex AI: Bietet SLA-Garantien auf Unternehmensebene und priorisierte Zuweisung von Rechenleistung.
- AI Studio: Nutzt einen gemeinsamen Ressourcenpool; in Stoßzeiten kann es zu Herabstufungen kommen.
Dies ähnelt dem Unterschied zwischen "Pay-as-you-go" und "reservierten Instanzen" bei Cloud-Servern.
Q3: Wird Google die Kontingente für die kostenlose Nutzung weiter kürzen?
A: Historische Trends deuten darauf hin, dass Google seine Richtlinien für die kostenlose Ebene (Free Tier) weiter anpassen könnte:
- November 2025: Free Tier auf 3 Bilder/Tag begrenzt.
-
- Dezember 2025: Senkung auf 2 Bilder/Tag, 2.5 Pro wird entfernt.
- Januar 2026: RPM wird von 10 auf 5 gesenkt.
Google formuliert dies offiziell als "Sicherstellung einer nachhaltigen Servicequalität". In der Realität geht es darum, ein Gleichgewicht zwischen Kostenkontrolle und Nutzerwachstum zu finden. Wir empfehlen, für Produktionsanwendungen nicht auf die kostenlose Ebene zu setzen, sondern frühzeitig einen kostenpflichtigen Plan oder ein Multi-Cloud-Backup einzuplanen.
Q4: Wann wird sich die Stabilität von Nano Banana Pro verbessern?
A: Laut öffentlichen Informationen von Google liegt der entscheidende Zeitpunkt in der Mitte des Jahres 2026:
- Q2 2026: Der flächendeckende Einsatz von TPU v7 (Ironwood) ist abgeschlossen.
- Q3 2026: 1 GW an Rechenleistung aus der Kooperation mit Anthropic geht online.
Zu diesem Zeitpunkt wird das Angebot an Rechenleistung deutlich steigen, allerdings könnte auch die Nachfrage parallel dazu zunehmen. Konservativ geschätzt wird sich die Stabilität in der zweiten Jahreshälfte 2026 substanziell verbessern.
Q5: Wie wähle ich die richtige Zugriffsmethode für Nano Banana Pro?
A: Wählen Sie basierend auf Ihrer aktuellen Entwicklungsphase:
| Phase | Empfohlene Lösung | Grund |
|---|---|---|
| Prototypen-Entwicklung | AI Studio Free Tier | Niedrigste Kosten, schnelle Validierung von Ideen |
| Kleiner Rollout | AI Studio Tier 1 + Retry-Mechanismus | Balance zwischen Kosten und Stabilität |
| Produktionsumgebung | Vertex AI oder APIYI-Plattform | SLA-Garantien, Support auf Unternehmensebene |
| Kritische Geschäftsprozesse | Multi-Cloud-Strategie (z. B. APIYI-Plattform) | Höchste Verfügbarkeit, automatisches Failover |
🎯 Entscheidungshilfe: Wenn Sie unsicher sind, empfehlen wir A/B-Tests über die APIYI-Plattform (apiyi.com). Die Plattform ermöglicht es Ihnen, die tatsächliche Leistung von Modellen wie Nano Banana Pro (AI Studio), Nano Banana Pro (Vertex AI) und DALL-E 3 bei identischen Anfragen zu vergleichen, damit Sie Ihre Entscheidung auf Basis echter Daten treffen können.
Fazit: Ein realistischer Blick auf die Rechenleistungs-Herausforderungen von Nano Banana Pro
Die Stabilitätsprobleme von Nano Banana Pro sind kein Einzelfall, sondern spiegeln den Widerspruch zwischen Angebot und Nachfrage bei Rechenleistung wider, der die gesamte KI-Branche betrifft:
Kernkonflikte:
- Nachfrageseite: Explosives Wachstum bei generativen KI-Anwendungen, insbesondere im Bereich der Bildgenerierung.
- Angebotsseite: Der Kapazitätsausbau bei Chips verläuft schleppend, und die Bauzyklen für Rechenzentren sind lang (12–18 Monate).
- Wirtschaftsmodell: Strategien für kostenlose Nutzung sind langfristig nicht tragbar, während die Konversionsraten zu Bezahlmodellen oft noch niedrig sind.
Drei technische Wahrheiten:
-
Eigene TPU-Entwicklung ≠ Unbegrenzte Rechenleistung: Google verfügt zwar über fortschrittliche Chips wie die TPU v7, aber der Hochlauf der Produktion, die Energieversorgung und der Bau von Rechenzentren brauchen Zeit. 2026 ist hier das entscheidende Wendejahr.
-
AI Studio vs. Vertex AI: Es handelt sich nicht einfach um eine "kostenlose" und eine "kostenpflichtige" Version. Es geht um unterschiedliche Prioritäten bei der Ressourcenplanung. Hinter den Enterprise-SLAs von Vertex AI steht ein dedizierter Mechanismus zur Reservierung von Rechenkapazität.
-
Engpässe werden langfristig bestehen bleiben: Mit der Veröffentlichung neuer Modellgenerationen wie Gemini 3.0 oder GPT-5 wird der Bedarf an Rechenleistung weiter steigen. Kurzfristig (2026–2027) wird sich die angespannte Lage zwischen Angebot und Nachfrage nicht grundlegend ändern.
Praktische Empfehlungen:
- Kurzfristig: Nutzen Sie technische Kniffe wie Retry-Mechanismen und die Steuerung von Anfrageintervallen, um Probleme abzufedern.
- Mittelfristig: Bewerten Sie den ROI eines Upgrades auf Vertex AI oder den Wechsel zu einer Multi-Cloud-Plattform.
- Langfristig: Behalten Sie den Ausbau der Rechenkapazitäten bei Google Mitte 2026 im Auge und passen Sie Ihre Strategie rechtzeitig an.
Für Anwendungen auf Unternehmensebene raten wir dringend zu einer Multi-Cloud-Backup-Strategie, um Kapazitätsrisiken einzelner Anbieter zu vermeiden. Über eine einheitliche Plattform wie APIYI (apiyi.com) können Sie Cloud-übergreifendes Scheduling, automatisches Failover und Kostenoptimierung nutzen, ohne die Komplexität Ihres Codes zu erhöhen.
Abschließender Gedanke: Die Herausforderungen rund um Nano Banana Pro erinnern uns daran, dass die Stabilität von KI-Anwendungen nicht nur von der Modellleistung abhängt, sondern maßgeblich von der Reife der zugrunde liegenden Infrastruktur. In einer Ära, in der Rechenleistung das wertvollste Gut ist, werden robustes Architekturdesign und Anbieter-Diversifizierung zu entscheidenden Wettbewerbsfaktoren.
Weiterführende Artikel:
- Nano Banana Pro API – Benutzerhandbuch
- Tiefenanalyse der Google TPU v7 Architektur
- Vergleich der KI-Bildgenerierungs-APIs: Nano Banana Pro vs. DALL-E 3 vs. Stable Diffusion
- 10 Best Practices für KI-API-Aufrufe in Produktionsumgebungen