2026 年 7 月 1 日,Anthropic officially announced that Claude Fable 5 was back and globally available again. This Mythos-class flagship model was released on June 9, pulled just three days later, and then disappeared for nearly three weeks before returning with a brand-new set of safety classifiers on Claude API, Amazon Bedrock, and other major platforms. For developers, this isn’t just news — it’s a real integration opportunity.
That said, the re-released claude-fable-5 is different from a typical Claude model in a few important ways: Adaptive Thinking is forced on, requests may be blocked by the safety classifiers and return stop_reason: "refusal", and your integration code needs fallback logic. These changes directly affect how you write your calls.
This article breaks down Claude Fable 5’s return from four angles — timeline, model specs, API integration, and refusal response handling — and includes runnable code examples. If you want to skip the hassle of applying for an AWS account, you can call claude-fable-5 directly through the official AWS Claude relay channel provided by APIYI apiyi.com, with the exact same model name as the official one.
Claude Fable 5 Return Timeline: From Removal to Relaunch
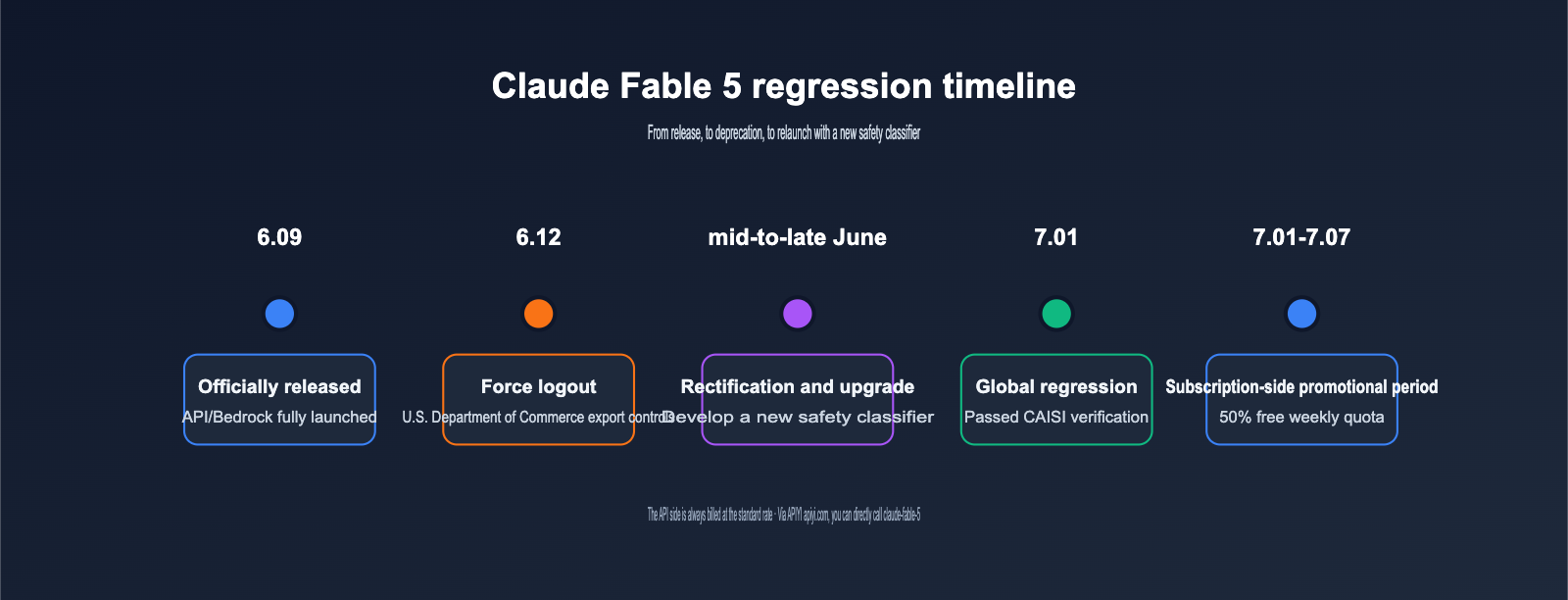
To understand why this comeback matters, you first need to know what Claude Fable 5 actually went through. According to Anthropic’s official announcement and coverage from multiple media outlets, the timeline looked like this:
| Time | Event |
|---|---|
| June 9, 2026 | Claude Fable 5 and Claude Mythos 5 were officially released, and Fable 5 went live across Claude API, Amazon Bedrock, Google Cloud, and Microsoft Foundry |
| June 12, 2026 | Due to a U.S. Department of Commerce export control directive, Fable 5 and Mythos 5 were forcibly taken offline |
| Mid-to-late June 2026 | Anthropic coordinated with the U.S. government and developed a next-generation cybersecurity classifier |
| July 1, 2026 | Export control restrictions were lifted, and Claude Fable 5 relaunched globally with the new safety classifier |
| July 1–7, 2026 | Subscription promo period: Pro/Max/Team and enterprise premium seats could use up to 50% of the weekly limit for free |
The direct trigger for the takedown was a jailbreak technique found by Amazon’s research team that could bypass Fable 5’s safety protections and trick the model into identifying software vulnerabilities. The U.S. government said this posed a serious cybersecurity risk, and the Commerce Department quickly issued an export control directive. This was the first time in the AI industry that a flagship model was fully removed from service because of a government order.
The key change in the returned version is a new classifier built specifically for cybersecurity tasks. Anthropic says the new classifier can block the jailbreak technique mentioned in Amazon’s report more than 99% of the time, and it has been validated by the U.S. Center for AI Standards and Innovation (CAISI). The trade-off is that some legitimate coding and debugging tasks may get caught in the filter too, which is exactly why the refusal-handling mechanism later in this article matters.
claude-fable-5 Model Specs and Pricing: One Tier Above Opus
Claude Fable 5 is the debut model in Anthropic’s new Mythos-tier model family. It’s positioned above Claude Opus and is currently the most capable publicly available model Anthropic offers. It shares the same underlying model as Claude Mythos 5, which is only available to approved Project Glasswing customers. The difference is that Fable 5 includes a built-in safety classifier, while Mythos 5 does not.
For developers, the most important specs are listed below.
| Spec Item | claude-fable-5 Parameters |
|---|---|
| API model name | claude-fable-5 |
| Context window | Default 1M (1 million) tokens |
| Maximum output per request | 128K tokens |
| Input price | $10 / million tokens |
| Output price | $50 / million tokens |
| Thinking mode | Adaptive thinking is always on; cannot be disabled |
| Data retention | 30 days; ZDR (zero data retention) not supported |
| Available platforms | Claude API, Amazon Bedrock, Google Cloud, Microsoft Foundry |
Two points are worth calling out. First, the 1M-token context window is the default, not a beta feature you need to apply for. That means you can feed an entire mid-sized codebase or hundreds of pages of documentation into the model in one shot, which is a real step up for long-document analysis and large-scale codebase refactoring. Second, adaptive thinking is the only thinking mode available in claude-fable-5. Setting thinking: {"type": "disabled"} will throw an error. You can only control thinking depth and cost through the effort parameter, so code migrated from Opus 4.8 needs extra attention here.
Beyond the core specs, the feature set available at launch is also worth looking at. On day one, claude-fable-5 supported nearly all of the agent infrastructure Anthropic introduced over the past year, which is why it’s being positioned as the preferred model for long-horizon agent tasks. Here’s the support matrix:
| Feature | Status | Value for developers |
|---|---|---|
effort parameter |
Generally available | Controls thinking depth and replaces the removed thinking toggle |
| Memory tool | Generally available | Persists context across sessions, ideal for long-lived agents |
| Code execution | Generally available | Lets the model run code directly to verify results |
| Programmatic tool use | Generally available | Orchestrates tools in code, reducing back-and-forth token usage |
| Task budgets | Beta | Sets a token cap for a task via headers |
| Context editing | Beta | Automatically clears old tool results to compress long-session costs |
| Compaction and visual understanding | Generally available | Auto-summarizes long sessions; supports image input |
The architectural takeaway is pretty clear: if your agent system was previously tied to Sonnet just to use memory tools or code execution, claude-fable-5 now gives you a stronger option on the same interface. Migration mostly comes down to changing the model name and handling refusals properly.
There’s also an important distinction around the promotion. The free quota from July 1 to July 7 — 50% of the weekly limit — applies only to Claude subscription users on Pro, Max, Team, and enterprise premium seats. Reference: support.claude.com/en/articles/15424964. API calls aren’t part of the promotion and are always billed separately at the standard $10/$50 rate. So for API developers, the main cost question after the relaunch is how to use the effort parameter to control output tokens, not how to hit a promo window.
🎯 Recommendation: A $50 per million output-token price means claude-fable-5 is a good fit for “low-volume, high-value” use cases, such as complex reasoning, long-horizon agent tasks, and large-scale code review. It’s not a great match for high-frequency lightweight tasks. We recommend starting with a small traffic test on the APIYI apiyi.com platform, which supports a unified interface switch between claude-fable-5, Opus, Sonnet, and other models. That makes it easy to compare quality and cost with the same code before you decide.
claude-fable-5 API Quick Start: 3 Steps to Get Connected
After Claude Fable 5 came back online, the official channel required a Claude API account or AWS Bedrock access (the Bedrock model ID is anthropic.claude-fable-5). For developers in China, the more common approach is to connect through an aggregation platform. APIYI provides exactly that: an official AWS Claude forwarding channel, where requests are relayed through the official AWS Bedrock route while keeping the model name as claude-fable-5. It’s compatible with both OpenAI-style and Anthropic-style calling formats.
Step 1: Get an API Key
After registering an APIYI apiyi.com account, create an API Key in the console. New users get free trial credits, so you can verify claude-fable-5’s real-world performance before topping up.
Step 2: Send Your First Request
Here’s the simplest curl example. Just point base_url to APIYI’s endpoint:
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $APIYI_API_KEY" \
-d '{
"model": "claude-fable-5",
"messages": [
{"role": "user", "content": "用一段话解释什么是自适应思考"}
],
"max_tokens": 1024
}'
The Python version is just as straightforward. If you use the OpenAI SDK, you only need to change base_url:
from openai import OpenAI
client = OpenAI(
api_key="your_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
resp = client.chat.completions.create(
model="claude-fable-5",
messages=[{"role": "user", "content": "分析这段代码的时间复杂度"}],
max_tokens=2048
)
print(resp.choices[0].message.content)
Step 3: Use the effort Parameter to Control Thinking Depth
Since adaptive thinking can’t be turned off, the right way to control cost is by tuning the effort parameter. Low effort is a good fit for simple tasks like formatting and summarization, while high effort should be reserved for harder workloads like mathematical reasoning and architecture design. Also note that claude-fable-5 never returns the raw chain of thought. If thinking.display is set to "summarized", you’ll get a reasoning summary; if it uses the default "omitted", the thinking field will be empty. Workflows that rely on chain-of-thought for debugging will need to adjust expectations.
There’s another easy-to-miss detail in multi-turn chats: within the same session, you need to pass the previous turn’s thinking block back to the model unchanged. Don’t modify or delete it, or you may affect reasoning continuity. When switching sessions across models — for example, downgrading from claude-fable-5 to Opus 4.8 and continuing the conversation — you’ll need to follow the official guidance for handling thinking-block compatibility. These are the kinds of details that are easy to get wrong in a self-built integration, while mature aggregation platforms usually handle them at the gateway layer.
Here are the recommended parameter settings for different task types:
| Task Type | Recommended effort |
Recommended max_tokens |
Cost Level |
|---|---|---|---|
| Summarization, format conversion | low | 1K–2K | Low |
| Standard code generation | medium | 4K–8K | Medium |
| Complex reasoning, mathematical proofs | high | 16K+ | High |
| Long-horizon agent tasks, large refactors | high | 32K–128K | Very high |
💡 Practical tip: If your business has both lightweight and heavy-duty tasks, you don’t need to send everything through claude-fable-5. With APIYI apiyi.com’s unified interface, you can route requests to claude-fable-5, Opus 4.8, or Sonnet based on task complexity. Using the same auth and code structure, you can often cut overall costs by more than half.
Claude Fable 5 Refusal Handling: The Biggest Integration Change After the Regression
This is the biggest difference between claude-fable-5 after the regression and all older Claude models, and it’s also one of the integration points the official docs keep stressing. Because of the new safety classifier, the model may refuse certain requests, especially cybersecurity tasks involving vulnerability analysis and penetration testing. In a few cases, normal coding/debugging requests can also get misclassified.
The key thing is this: a refusal isn’t an error. When the classifier blocks a request, the Messages API still returns a successful HTTP 200 response. The stop_reason field will be "refusal", and the response will also indicate which classifier made the block. If your code only checks the HTTP status code, you’ll treat a refusal response as if it were normal output — that’s one of the easiest integration traps to fall into.
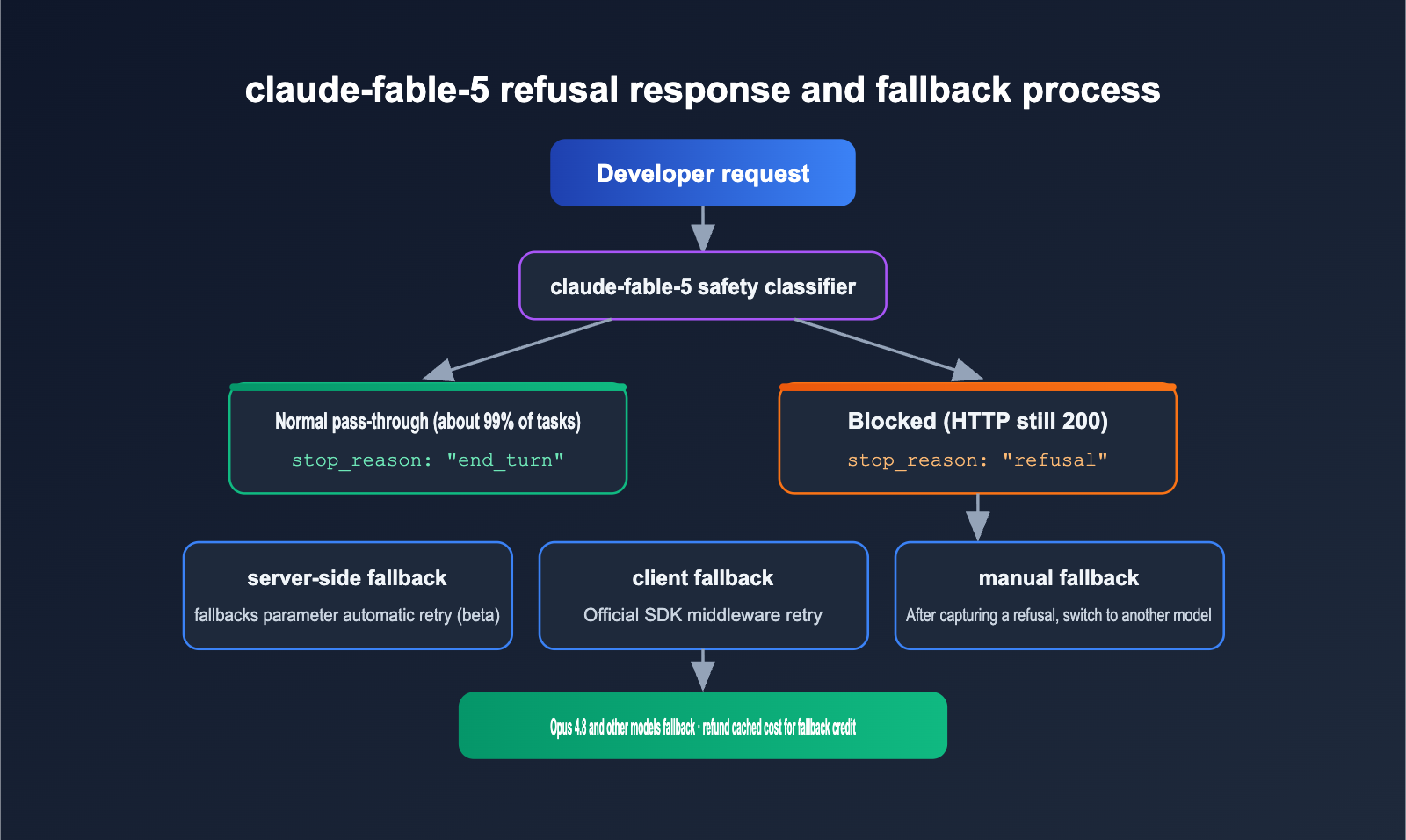
The good news is that requests refused by Fable 5 can usually be handled by other Claude models. The official docs provide three fallback options:
| Fallback option | How it works | Best for |
|---|---|---|
| Server-side fallback | Pass the fallbacks parameter in the request, and the API retries automatically (beta) |
You want zero code changes and can accept beta behavior |
| Client-side fallback | Official SDK middleware (Python/TS/Go/Java/C#) retries automatically | You need consistent behavior across platforms |
| Manual fallback | Catch stop_reason: "refusal" yourself and switch to another model |
You want full control over retry logic |
The billing rules are designed around this too: if a request is refused before generating any output, it isn’t billed. When a fallback retry switches to another model, the fallback credit mechanism refunds the prompt caching cost caused by the switch, so you’re not paying twice for the same context.
Beyond implementing fallback itself, we also recommend logging each request’s stop_reason at the gateway or application layer, and setting up monitoring alerts for refusal rates. On one hand, a sudden jump in refusals often means Anthropic has adjusted the classifier policy, which you’ll want to review quickly for business impact. On the other hand, long-term data helps you identify which prompts are likely to trigger false positives. Rewriting prompts — for example, avoiding phrases like “scan vulnerabilities” or “bypass restrictions” — can significantly reduce the chance of being blocked.
The core manual fallback logic is only about ten lines of code:
resp = call_model("claude-fable-5", messages)
if resp.stop_reason == "refusal":
# Blocked by the safety classifier, fall back to Opus 4.8
resp = call_model("claude-opus-4-8", messages)
🎯 Architecture recommendation: If you’re integrating claude-fable-5 into production, make refusal handling part of your launch checklist. We recommend enabling both claude-fable-5 and claude-opus-4-8 on the APIYI apiyi.com platform, since they share the same base_url and API key. That means the fallback code above can run directly without any extra auth setup.
Claude Fable 5 FAQ
Q1: What’s the difference between Claude Fable 5 and Claude Mythos 5? Which one should I use?
They’re the same underlying model, with identical capabilities and pricing. The difference is that Fable 5 has a built-in safety classifier and is publicly available, while Mythos 5 has no classifier and is only open to approved Project Glasswing customers. For most developers, claude-fable-5 is the only option, and it’s more than enough.
Q2: Does the July 1–7 promotion apply to API calls?
No. The promotion only applies to the Claude subscription products (Pro/Max/Team/enterprise premium seats), with a cap of 50% of the weekly quota. API calls are always billed at the standard rate of $10/$50 per million tokens. Using claude-fable-5 through APIYI apiyi.com is billed by actual usage, with no monthly minimum, so it’s a good choice for small-scale validation first.
Q3: Will the regression version of claude-fable-5 refuse normal requests often?
Anthropic says about 99% of routine tasks aren’t affected, but the chance of blocking requests related to vulnerability discovery and security auditing is much higher. Normal coding/debugging can still get caught occasionally. In production, you should absolutely implement fallback logic and route refused requests to Opus 4.8 or another backup model.
Q4: Could the model be taken offline again for policy reasons?
You can’t rule it out completely, but this return has gone through CAISI validation and export controls have been formally lifted, so the short-term risk of another takedown is low. Architecturally, the best defense is not to hardcode a single model: use a unified interface through an aggregation platform, and if one model becomes unavailable, you can switch to Opus 4.8 or another backup by changing one model name. Your service won’t go down.
Q5: What’s the difference between calling claude-fable-5 through AWS’s official forwarding path and connecting directly to the Anthropic API?
The model itself is exactly the same — same weights, same capabilities, same safety classifier behavior. The main difference is the integration experience: direct Anthropic access requires overseas payment methods and network setup, while Bedrock direct access requires an AWS account and model approval (the Bedrock model ID is anthropic.claude-fable-5). The APIYI apiyi.com AWS official forwarding channel removes both of those steps. It keeps the model name as claude-fable-5, bills in RMB, and still retains the stability of the official Bedrock route, which makes it a much easier option for teams in China.
Q6: What should I watch out for when using the 1M context window in practice?
Very long contexts will push input costs up sharply — 1M tokens in one call is already $10 — so it’s a good idea to pair this with prompt caching. Repeated long-document prefixes can cut costs a lot. Also note that claude-fable-5 has a 30-day data retention period and doesn’t support zero-data retention. If your business is sensitive to data compliance, make sure you evaluate that up front.
Summary: The Right Way to Integrate Claude Fable 5 After Its Return
The return of Claude Fable 5 gives developers access to a Mythos-tier model again: 1M context, 128K output, and reasoning that outperforms Opus. The model name claude-fable-5 stays the same. But this comeback isn’t just a simple “back to the old version.” Adaptive thinking is now forced on, the safety classifier may return stop_reason: "refusal", and you’ll need proper fallback downgrade logic. Those are the three new realities every integration needs to handle.
As for access, subscribers can take advantage of the promo period before July 7 to try it for free in the Claude client. For API developers, the recommendation is to connect through APIYI apiyi.com’s official AWS Claude relay channel, which offers a unified interface covering both claude-fable-5 and fallback options like Opus and Sonnet. Once you’ve implemented the three-step integration flow and handled refusal properly, you can confidently put this strongest Claude model into production.
Author: APIYI Team, focused on AI Large Language Model API integration and engineering practices. For more model evaluations and integration tutorials, visit APIYI apiyi.com.