Was sind die Unterschiede zwischen synchronen und asynchronen Aufrufen bei der Bildgenerierung mit der Nano Banana Pro API? Derzeit unterstützen sowohl APIYI als auch die offizielle Gemini-API ausschließlich den synchronen Modus. APIYI hat jedoch das Benutzererlebnis durch die Bereitstellung von OSS-Bild-URLs erheblich verbessert. In diesem Artikel analysieren wir systematisch die Kernunterschiede zwischen synchronen und asynchronen Aufrufen sowie die Optimierungslösungen der APIYI-Plattform für Bildausgabeformate.
Kernwert: Nach der Lektüre dieses Artikels werden Sie den wesentlichen Unterschied zwischen synchronen und asynchronen Aufrufen im API-Design verstehen, die Vorteile der OSS-URL-Ausgabe von APIYI gegenüber der Base64-Kodierung kennen und wissen, wie Sie die optimale Lösung für den Bildabruf basierend auf Ihrem Geschäftsszenario auswählen.

Kernvergleich der Nano Banana Pro API Aufrufmodi
| Merkmal | Synchroner Aufruf (Synchronous) | Asynchroner Aufruf (Asynchronous) | APIYI Aktuelle Unterstützung |
|---|---|---|---|
| Verbindungsmodus | Hält HTTP-Verbindung bis zum Abschluss | Sofortige Rückgabe der Task-ID, Verbindung schließen | ✅ Synchroner Aufruf |
| Warteverhalten | Blockierendes Warten (30-170 Sek.) | Nicht-blockierend, Polling oder Webhook | ✅ Synchron (blockierend) |
| Timeout-Risiko | Hoch (erfordert 300-600 Sek. Timeout) | Gering (nur für Task-Einreichung) | ⚠️ Angemessene Timeouts nötig |
| Komplexität | Gering (Einmalige Anfrage) | Mittel (erfordert Polling oder Webhook) | ✅ Einfach zu bedienen |
| Anwendungsfall | Echtzeit-Anzeige, sofortige Generierung | Batch-Verarbeitung, Hintergrundprozesse | ✅ Echtzeit-Generierung |
| Kostenoptimierung | Standardpreis | Google Batch API spart bis zu 50% | – |
Funktionsweise des synchronen Aufrufs
Der synchrone Aufruf (Synchronous Call) folgt dem Muster Anfrage-Warten-Antwort:
- Client initiiert Anfrage: Sendet die Bildgenerierungsanfrage an den Server.
- HTTP-Verbindung halten: Der Client hält die TCP-Verbindung offen und wartet auf den Abschluss der Server-Inferenz.
- Blockierendes Warten: Während der Inferenzzeit von 30 bis 170 Sekunden kann der Client keine weiteren Operationen auf dieser Verbindung durchführen.
- Vollständige Antwort empfangen: Der Server gibt die generierten Bilddaten (Base64 oder URL) zurück.
- Verbindung schließen: Nach Abschluss wird die HTTP-Verbindung beendet.
Hauptmerkmal: Synchrones Aufrufen ist blockierend (Blocking). Der Client muss auf die Serverantwort warten, bevor er mit nachfolgenden Operationen fortfahren kann. Dies erfordert die Konfiguration ausreichend langer Timeout-Zeiten (empfohlen: 300s für 1K/2K, 600s für 4K), um Verbindungsabbrüche während der Inferenz zu vermeiden.
Funktionsweise des asynchronen Aufrufs
Der asynchrone Aufruf (Asynchronous Call) folgt dem Muster Anfrage-Annahme-Benachrichtigung:
- Client reicht Task ein: Sendet die Bildgenerierungsanfrage an den Server.
- Sofortige Rückgabe der Task-ID: Der Server nimmt die Anfrage an, gibt eine Task-ID (z. B.
task_abc123) zurück und schließt sofort die Verbindung. - Hintergrund-Inferenz: Der Server generiert das Bild im Hintergrund; der Client kann währenddessen andere Aufgaben bearbeiten.
- Ergebnis abrufen: Der Client erhält das Ergebnis auf einem von zwei Wegen:
- Polling: Regelmäßige Abfrage von
/tasks/task_abc123/status, um den Status zu prüfen. - Webhook-Callback: Nach Fertigstellung ruft der Server aktiv eine vom Client bereitgestellte Callback-URL auf.
- Polling: Regelmäßige Abfrage von
- Bild herunterladen: Sobald der Task abgeschlossen ist, wird das Bild über die bereitgestellte URL heruntergeladen.
Hauptmerkmal: Asynchrones Aufrufen ist nicht-blockierend (Non-blocking). Der Client kann nach dem Einreichen des Tasks sofort andere Anfragen bearbeiten, ohne die Verbindung lange offen halten zu müssen. Dies eignet sich hervorragend für Batch-Verarbeitung und Szenarien mit geringeren Anforderungen an die Echtzeitfähigkeit.
💡 Technischer Rat: Die APIYI-Plattform unterstützt derzeit nur den synchronen Modus, verbessert das Benutzererlebnis jedoch signifikant durch optimierte Timeout-Konfigurationen und die Ausgabe von OSS-URLs. Für Szenarien, die eine massenhafte Bildgenerierung erfordern, empfehlen wir den Aufruf über die Plattform APIYI (apiyi.com). Diese bietet stabile HTTP-Schnittstellen mit vorkonfigurierten Timeouts und unterstützt hohe Parallelität bei synchronen Aufrufen.
Kernunterschied 1: Verbindungshaltezeit und Timeout-Konfiguration
Anforderungen an die Verbindung bei synchronen Aufrufen
Ein synchroner Aufruf erfordert, dass der Client die HTTP-Verbindung während des gesamten Bildgenerierungsprozesses offen hält. Dies führt zu folgenden technischen Herausforderungen:
| Herausforderung | Auswirkung | Lösung |
|---|---|---|
| Lange Leerlaufzeiten | Zwischengeschaltete Netzwerkgeräte (NAT, Firewalls) könnten die Verbindung trennen | TCP Keep-Alive konfigurieren |
| Komplexe Timeout-Konfiguration | Timeouts müssen präzise auf die Auflösung abgestimmt werden | 1K/2K: 300 Sek., 4K: 600 Sek. |
| Empfindlichkeit gegenüber Netzwerkschwankungen | In instabilen Netzwerken bricht die Verbindung leicht ab | Implementierung von Retry-Mechanismen |
| Limitierung paralleler Verbindungen | Browser erlauben standardmäßig maximal 6 gleichzeitige Verbindungen | Serverseitige Aufrufe oder Connection-Pools nutzen |
Beispiel für synchronen Python-Aufruf:
import requests
import time
def generate_image_sync(prompt: str, size: str = "4096x4096") -> dict:
"""
Synchroner Aufruf der Nano Banana Pro API zur Bildgenerierung
Args:
prompt: Eingabeaufforderung für das Bild
size: Bildgröße
Returns:
API-Antwort
"""
start_time = time.time()
# Synchroner Aufruf: Verbindung bleibt bis zum Abschluss offen
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # APIYI unterstützt URL-Ausgabe
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 600) # Verbindungs-Timeout 10 Sek., Lese-Timeout 600 Sek.
)
elapsed = time.time() - start_time
print(f"⏱️ Dauer des synchronen Aufrufs: {elapsed:.2f} Sek.")
print(f"🔗 Verbindungsstatus: Offengehalten für {elapsed:.2f} Sek.")
return response.json()
# Anwendungsbeispiel
result = generate_image_sync(
prompt="A futuristic cityscape at sunset",
size="4096x4096"
)
print(f"✅ Bild-URL: {result['data'][0]['url']}")
Wichtige Beobachtungen:
- Der Client ist während der 100–170 Sekunden dauernden Inferenzzeit vollständig blockiert.
- Die HTTP-Verbindung bleibt dauerhaft offen und verbraucht Systemressourcen.
- Wenn das Timeout falsch konfiguriert ist (z. B. 60 Sek.), bricht die Verbindung ab, bevor die Inferenz abgeschlossen ist.
Vorteile von Kurzzeitverbindungen bei asynchronen Aufrufen
Asynchrone Aufrufe bauen Kurzzeitverbindungen nur zum Übermitteln der Aufgabe und zum Abfragen des Status auf, was die Verbindungshaltezeit drastisch reduziert:
| Phase | Verbindungsdauer | Timeout-Konfiguration |
|---|---|---|
| Aufgabe übermitteln | 1–3 Sek. | 30 Sek. sind ausreichend |
| Status abfragen (Polling) | Jedes Mal 1–2 Sek. | 10 Sek. sind ausreichend |
| Bild herunterladen | 5–10 Sek. | 60 Sek. sind ausreichend |
| Gesamt | 10–20 Sek. (verteilt) | Weit unter dem synchronen Aufruf |
Beispiel für asynchronen Python-Aufruf (Simulation zukünftiger APIYI-Unterstützung):
import requests
import time
def generate_image_async(prompt: str, size: str = "4096x4096") -> str:
"""
Asynchroner Aufruf der Nano Banana Pro API (Zukünftiges Feature)
Args:
prompt: Eingabeaufforderung für das Bild
size: Bildgröße
Returns:
Aufgaben-ID (Task ID)
"""
# Schritt 1: Aufgabe übermitteln (Kurzzeitverbindung)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # Zukünftiger Endpunkt
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30) # Nur 30 Sek. Timeout für die Übermittlung nötig
)
task_data = response.json()
task_id = task_data["task_id"]
print(f"✅ Aufgabe übermittelt: {task_id}")
print(f"🔓 Verbindung geschlossen, andere Aufgaben können bearbeitet werden")
return task_id
def poll_task_status(task_id: str, max_wait: int = 300) -> dict:
"""
Aufgabenstatus per Polling abfragen, bis sie abgeschlossen ist
Args:
task_id: Aufgaben-ID
max_wait: Maximale Wartezeit (Sek.)
Returns:
Generierungsergebnis
"""
start_time = time.time()
poll_interval = 5 # Alle 5 Sekunden abfragen
while time.time() - start_time < max_wait:
# Status abfragen (Kurzzeitverbindung)
response = requests.get(
f"http://api.apiyi.com:16888/v1/tasks/{task_id}", # Zukünftiger Endpunkt
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 10) # Nur 10 Sek. Timeout für die Abfrage nötig
)
status_data = response.json()
status = status_data["status"]
if status == "completed":
elapsed = time.time() - start_time
print(f"✅ Aufgabe abgeschlossen! Gesamtdauer: {elapsed:.2f} Sek.")
return status_data["result"]
elif status == "failed":
raise Exception(f"Aufgabe fehlgeschlagen: {status_data.get('error')}")
else:
print(f"⏳ Aufgabenstatus: {status}, warte {poll_interval} Sek. auf nächsten Versuch...")
time.sleep(poll_interval)
raise TimeoutError(f"Zeitüberschreitung bei Aufgabe: {task_id}")
# Anwendungsbeispiel
task_id = generate_image_async(
prompt="A serene mountain landscape",
size="4096x4096"
)
# Während des Pollings können andere Aufgaben erledigt werden
print("🚀 Andere Anfragen können parallel bearbeitet werden...")
# Status abfragen
result = poll_task_status(task_id, max_wait=600)
print(f"✅ Bild-URL: {result['data'][0]['url']}")
Beispiel für Webhook-Callback-Modus anzeigen (Zukünftiges Feature)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
# Globales Dictionary zum Speichern von Ergebnissen
task_results = {}
@app.route('/webhook/image_completed', methods=['POST'])
def handle_webhook():
"""Empfängt Webhook-Callbacks von APIYI bei Abschluss asynchroner Aufgaben"""
data = request.json
task_id = data['task_id']
status = data['status']
result = data.get('result')
if status == 'completed':
task_results[task_id] = result
print(f"✅ Aufgabe {task_id} abgeschlossen: {result['data'][0]['url']}")
else:
print(f"❌ Aufgabe {task_id} fehlgeschlagen: {data.get('error')}")
return jsonify({"received": True}), 200
def generate_image_with_webhook(prompt: str, size: str = "4096x4096") -> str:
"""
Bild asynchron via Webhook-Modus generieren
Args:
prompt: Eingabeaufforderung für das Bild
size: Bildgröße
Returns:
Aufgaben-ID
"""
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": "https://ihre-domain.de/webhook/image_completed" # Callback-URL
},
headers={"Authorization": "Bearer YOUR_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
print(f"✅ Aufgabe übermittelt: {task_id}")
print(f"📞 Webhook wird aufgerufen unter: https://ihre-domain.de/webhook/image_completed")
return task_id
# Flask-Server starten, um auf Webhooks zu warten
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
🎯 Aktuelle Einschränkung: APIYI und die offiziellen Gemini-Schnittstellen unterstützen derzeit nur den synchronen Modus. Asynchrone Funktionen sind für zukünftige Versionen geplant. Für Szenarien mit hohem Aufkommen an Bildgenerierungen wird empfohlen, über die Plattform APIYI (apiyi.com) Multi-Threading oder Multi-Processing für parallele synchrone Aufrufe zu nutzen und angemessene Timeouts zu konfigurieren.
Kernunterschied 2: Parallele Verarbeitung und Ressourcenverbrauch
Parallelitätsbeschränkungen bei synchronen Aufrufen
Synchrone Aufrufe führen in High-Concurrency-Szenarien zu erheblichen Ressourcenproblemen:
Problem der Blockierung bei Einzelthreads:
import time
# ❌ FALSCH: Sequenzieller Aufruf in einem Thread, Gesamtdauer = Einzeldauer × Anzahl der Aufgaben
def generate_multiple_images_sequential(prompts: list) -> list:
results = []
start_time = time.time()
for prompt in prompts:
result = generate_image_sync(prompt, size="4096x4096")
results.append(result)
elapsed = time.time() - start_time
print(f"❌ Sequenzieller Aufruf von {len(prompts)} Bildern dauerte: {elapsed:.2f} Sek.")
# Angenommen 120 Sek. pro Bild, 10 Bilder = 1200 Sek. (20 Minuten!)
return results
Optimierung durch Multi-Threading:
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# ✅ RICHTIG: Parallele Aufrufe mittels Threads nutzen die I/O-Wartezeit effizient
def generate_multiple_images_concurrent(prompts: list, max_workers: int = 5) -> list:
"""
Mehrere Bilder parallel über Threads generieren
Args:
prompts: Liste der Eingabeaufforderungen
max_workers: Maximale Anzahl paralleler Threads
Returns:
Liste der Ergebnisse
"""
results = []
start_time = time.time()
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# Alle Aufgaben abschicken
future_to_prompt = {
executor.submit(generate_image_sync, prompt, "4096x4096"): prompt
for prompt in prompts
}
# Auf Abschluss aller Aufgaben warten
for future in as_completed(future_to_prompt):
prompt = future_to_prompt[future]
try:
result = future.result()
results.append(result)
print(f"✅ Fertig: {prompt[:30]}...")
except Exception as e:
print(f"❌ Fehlgeschlagen: {prompt[:30]}... - {e}")
elapsed = time.time() - start_time
print(f"✅ Paralleler Aufruf von {len(prompts)} Bildern dauerte: {elapsed:.2f} Sek.")
# Angenommen 120 Sek. pro Bild, 10 Bilder ≈ 120-150 Sek. (2-2,5 Minuten)
return results
# Anwendungsbeispiel
prompts = [
"A cyberpunk city at night",
"A serene forest landscape",
"An abstract geometric pattern",
"A futuristic space station",
"A vintage car in the desert",
# ...weitere Prompts
]
results = generate_multiple_images_concurrent(prompts, max_workers=5)
print(f"🎉 {len(results)} Bilder generiert")
| Parallelitäts-Methode | Dauer für 10x 4K-Bilder | Ressourcenverbrauch | Anwendungsfall |
|---|---|---|---|
| Sequenziell | 1200 Sek. (20 Min.) | Niedrig (1 Verbindung) | Einzelbilder, Echtzeit |
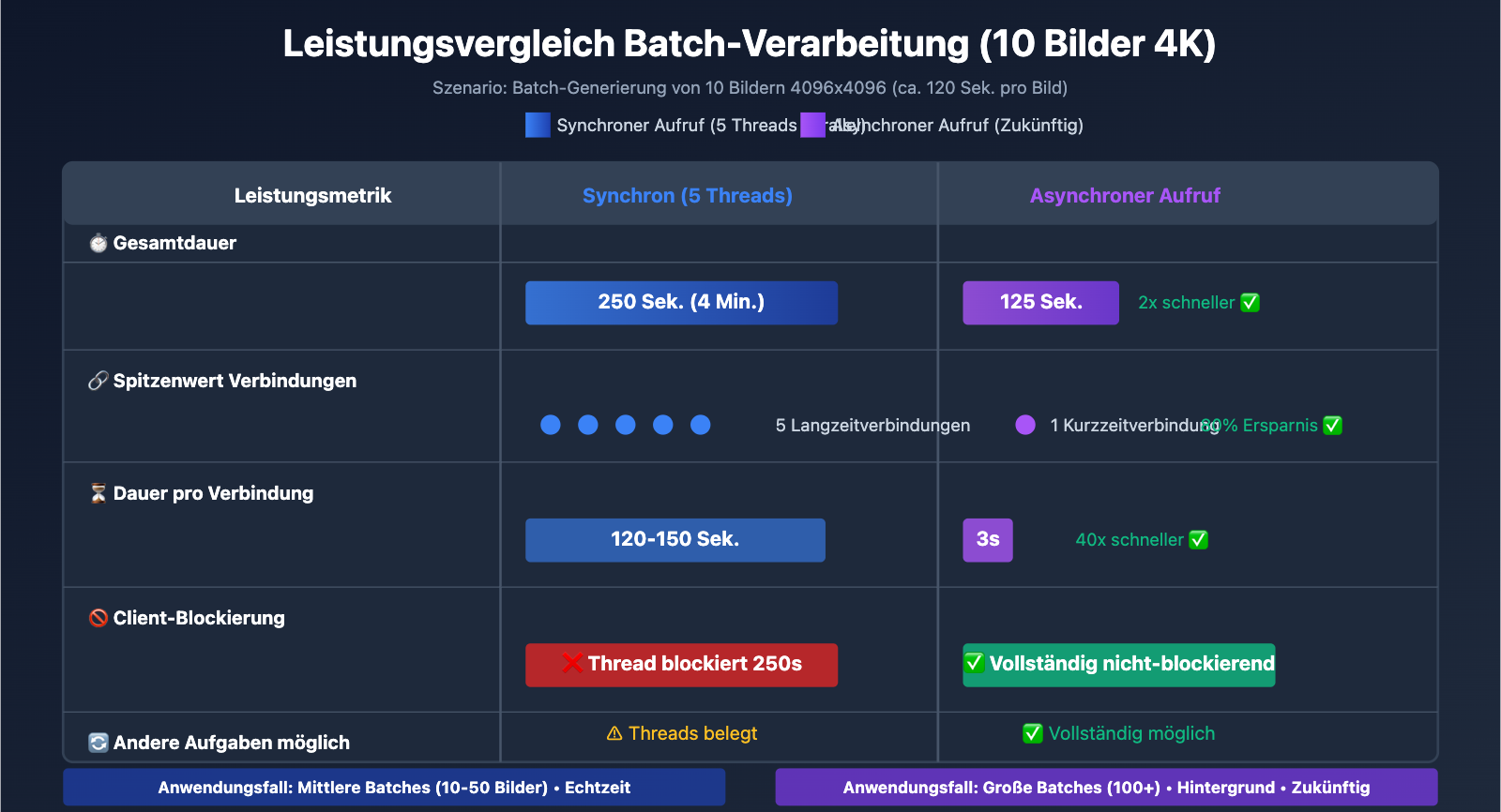
| Multi-Threading (5 Threads) | 250 Sek. (4 Min.) | Mittel (5 Verbindungen) | Kleine Batches (10-50 Bilder) |
| Multi-Processing (10 Prozesse) | 150 Sek. (2,5 Min.) | Hoch (10 Verbindungen) | Große Batches (50+ Bilder) |
| Asynchron (Zukünftig) | 120 Sek. + Polling-Overhead | Niedrig (Kurze Polling-Verbindungen) | Riesige Batches (100+ Bilder) |
Parallelitätsvorteile asynchroner Aufrufe
Asynchrone Aufrufe glänzen besonders in Szenarien mit Stapelverarbeitung (Batch Processing):
Batch-Übermittlung + Batch-Polling:
def generate_batch_async(prompts: list) -> list:
"""
Bilder im Batch asynchron generieren (Zukünftiges Feature)
Args:
prompts: Liste der Eingabeaufforderungen
Returns:
Liste der Aufgaben-IDs
"""
task_ids = []
# Schritt 1: Schnelle Batch-Übermittlung aller Aufgaben (ca. 1-3 Sek. pro Aufgabe)
for prompt in prompts:
task_id = generate_image_async(prompt, size="4096x4096")
task_ids.append(task_id)
print(f"✅ {len(task_ids)} Aufgaben im Batch übermittelt, Dauer ca. {len(prompts) * 2} Sek.")
# Schritt 2: Batch-Polling des Aufgabenstatus
results = []
for task_id in task_ids:
result = poll_task_status(task_id, max_wait=600)
results.append(result)
return results
| Metrik | Synchron (Multi-Threading) | Asynchron (Zukünftig) | Differenz |
|---|---|---|---|
| Dauer Übermittlungsphase | 1200 Sek. (blockierendes Warten) | 20 Sek. (schnelles Abschicken) | Asynchron 60x schneller |
| Gesamtdauer | 250 Sek. (5 Threads) | 120 Sek. + Polling-Overhead | Asynchron 2x schneller |
| Spitzenwert Verbindungen | 5 Langzeitverbindungen | 1 Kurzzeitverbindung (bei Übermittlung) | Asynchron spart 80% |
| Andere Aufgaben bearbeitbar | ❌ Threads blockiert | ✅ Vollständig nicht-blockierend | Asynchron flexibler |
💰 Kostenoptimierung: Die Google Gemini API bietet einen Batch-API-Modus an. Dieser unterstützt die asynchrone Verarbeitung und bietet einen Preisnachlass von 50 % (Standardpreis $0,133–$0,24 pro Bild, Batch-API $0,067–$0,12 pro Bild). Dafür muss eine Lieferzeit von bis zu 24 Stunden in Kauf genommen werden. Für Szenarien, die keine Echtzeitgenerierung erfordern, ist die Batch-API eine exzellente Wahl zur Kostensenkung.
Kernunterschied 3: Vorteile der OSS-URL-Ausgabe der APIYI-Plattform
Vergleich: base64-Kodierung vs. URL-Ausgabe
Die Nano Banana Pro API unterstützt zwei Formate für die Bildausgabe:
| Merkmal | base64-Kodierung | OSS-URL-Ausgabe (exklusiv bei APIYI) | Empfehlung |
|---|---|---|---|
| Größe des Response-Bodys | 6-8 MB (4K-Bild) | 200 Bytes (nur URL) | URL ✅ |
| Übertragungszeit | 5-10 Sek. (bei schwachem Netz langsamer) | < 1 Sek. | URL ✅ |
| Browser-Caching | ❌ Nicht möglich | ✅ Standard HTTP-Caching | URL ✅ |
| CDN-Beschleunigung | ❌ Nicht nutzbar | ✅ Globale CDN-Beschleunigung | URL ✅ |
| Bildoptimierung | ❌ Unterstützt kein WebP etc. | ✅ Unterstützt Formatkonvertierung | URL ✅ |
| Progressives Laden | ❌ Muss vollständig geladen werden | ✅ Unterstützt progressives Laden | URL ✅ |
| Mobile Performance | ❌ Hoher Speicherverbrauch | ✅ Optimierter Download-Stream | URL ✅ |
Performance-Probleme bei base64-Kodierung:
- Aufblähen des Response-Bodys um 33 %: Die base64-Kodierung erhöht die Datenmenge um etwa 33 %.
- Original 4K-Bild: ca. 6 MB
- Nach base64-Kodierung: ca. 8 MB
- Keine CDN-Nutzung möglich: Da der base64-String in der JSON-Antwort eingebettet ist, kann er nicht über ein CDN gecached werden.
- Speicherdruck auf Mobilgeräten: Das Dekodieren von base64-Strings erfordert zusätzliche Arbeitsspeicher- und CPU-Ressourcen.
Vorteile der OSS-URL-Ausgabe von APIYI:
import requests
# ✅ Empfohlen: Nutzung der APIYI OSS-URL-Ausgabe
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "url" # URL-Ausgabe festlegen
},
headers={"Authorization": "Bearer DEIN_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# Der Response-Body enthält nur die URL, Größe ca. 200 Bytes
print(f"Größe des Response-Bodys: {len(response.content)} Bytes")
# Ausgabe: Größe des Response-Bodys: 234 Bytes
# Beispiel für OSS-URL
image_url = result['data'][0]['url']
print(f"Bild-URL: {image_url}")
# Ausgabe: https://apiyi-oss.oss-cn-beijing.aliyuncs.com/nano-banana/abc123.png
# Anschließender Download des Bildes über Standard-HTTP mit CDN-Beschleunigung
image_response = requests.get(image_url)
with open("output.png", "wb") as f:
f.write(image_response.content)
Vergleich: Performance-Probleme bei base64-Ausgabe:
# ❌ Nicht empfohlen: Ausgabe per base64-Kodierung
response = requests.post(
"https://api.example.com/v1/images/generations",
json={
"prompt": "A beautiful sunset over mountains",
"size": "4096x4096",
"model": "nano-banana-pro",
"n": 1,
"response_format": "b64_json" # base64-Kodierung
},
headers={"Authorization": "Bearer DEIN_API_KEY"},
timeout=(10, 600)
)
result = response.json()
# Der Response-Body enthält den kompletten base64-String, Größe ca. 8 MB
print(f"Größe des Response-Bodys: {len(response.content)} Bytes")
# Ausgabe: Größe des Response-Bodys: 8388608 Bytes (8 MB!)
# Der base64-String muss dekodiert werden
import base64
image_b64 = result['data'][0]['b64_json']
image_bytes = base64.b64decode(image_b64)
with open("output.png", "wb") as f:
f.write(image_bytes)
| Vergleichskriterium | base64-Kodierung | APIYI OSS-URL | Performance-Steigerung |
|---|---|---|---|
| API-Response-Größe | 8 MB | 200 Bytes | Reduziert um 99,998 % |
| API-Response-Zeit | 125 Sek. + 5-10 Sek. Transfer | 125 Sek. + < 1 Sek. | Ersparnis von 5-10 Sek. |
| Bild-Download-Methode | In JSON eingebettet | Unabhängiger HTTP-Request | Parallelisierbar |
| Browser-Cache | Nicht cachebar | Standard HTTP-Cache | Sofortiges Laden bei Zweitbesuch |
| CDN-Beschleunigung | Nicht unterstützt | Globale CDN-Knoten | Beschleunigung bei internationalem Zugriff |
🚀 Empfohlene Konfiguration: Verwenden Sie beim Aufruf der Nano Banana Pro API auf der APIYI-Plattform immer
response_format: "url", um eine OSS-URL zu erhalten, anstatt der base64-Kodierung. Dies reduziert nicht nur die API-Antwortgröße und die Übertragungszeit erheblich, sondern nutzt auch CDN-Beschleunigung und Browser-Caching voll aus, um das Nutzererlebnis zu verbessern.
Kernunterschied 4: Anwendungsszenarien und Zukunftspläne
Best-Practice-Szenarien für synchrone Aufrufe
Empfohlene Szenarien:
- Echtzeit-Bilderzeugung: Das generierte Bild wird sofort angezeigt, nachdem der Nutzer die Eingabeaufforderung abgeschickt hat.
- Verarbeitung kleiner Batches: Bei der Erzeugung von 1 bis 10 Bildern können die Performance-Anforderungen durch einfache parallele Aufrufe erfüllt werden.
- Einfache Integration: Es müssen kein Polling oder Webhooks implementiert werden, was die Entwicklungskomplexität verringert.
- Interaktive Anwendungen: KI-Malwerkzeuge, Bildeditoren und andere Szenarien, die sofortiges Feedback erfordern.
Typisches Codemuster:
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/generate', methods=['POST'])
def generate_image():
"""Schnittstelle für Echtzeit-Bilderzeugung"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
# Synchroner Aufruf, Nutzer wartet auf die Fertigstellung
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer DEIN_API_KEY"},
timeout=(10, 300 if size != '4096x4096' else 600)
)
result = response.json()
return jsonify({
"success": True,
"image_url": result['data'][0]['url']
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
Zukünftige Anwendungsszenarien für asynchrone Aufrufe
Geeignete Szenarien (zukünftige Unterstützung):
- Massenhafte Bilderzeugung: Erstellung von mehr als 100 Bildern, z. B. für E-Commerce-Produktkataloge oder Design-Asset-Bibliotheken.
- Hintergrund-Batch-Jobs: Tägliche automatische Erstellung bestimmter Bildtypen ohne Notwendigkeit einer Echtzeit-Antwort.
- Kostengünstige Verarbeitung: Nutzung der Google Batch API für 50 % Preisnachlass bei einer tolerierten Lieferzeit von 24 Stunden.
- Hochlast-Szenarien: Wenn Hunderte von Nutzern gleichzeitig Anfragen senden, um eine Erschöpfung des Connection Pools zu vermeiden.
Typisches Codemuster (Zukunft):
from flask import Flask, request, jsonify
from celery import Celery
import requests
app = Flask(__name__)
celery = Celery('tasks', broker='redis://localhost:6379/0')
@celery.task
def generate_image_task(prompt: str, size: str, user_id: str):
"""Celery-Hintergrundaufgabe: Bild generieren"""
# Asynchrone Aufgabe an APIYI übermitteln
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations/async", # Zukünftige Schnittstelle
json={
"prompt": prompt,
"size": size,
"model": "nano-banana-pro",
"n": 1,
"response_format": "url",
"webhook_url": f"https://deine-domain.de/webhook/{user_id}"
},
headers={"Authorization": "Bearer DEIN_API_KEY"},
timeout=(10, 30)
)
task_id = response.json()["task_id"]
return task_id
@app.route('/generate_async', methods=['POST'])
def generate_image_async():
"""Schnittstelle für asynchrone Bilderzeugung"""
data = request.json
prompt = data['prompt']
size = data.get('size', '1024x1024')
user_id = data['user_id']
# Celery-Aufgabe abschicken und sofort antworten
task = generate_image_task.delay(prompt, size, user_id)
return jsonify({
"success": True,
"message": "Aufgabe übermittelt. Benachrichtigung erfolgt nach Fertigstellung per Webhook.",
"task_id": task.id
})
@app.route('/webhook/<user_id>', methods=['POST'])
def handle_webhook(user_id: str):
"""Empfang des Webhook-Callbacks nach Abschluss der asynchronen APIYI-Aufgabe"""
data = request.json
task_id = data['task_id']
result = data['result']
# Nutzer über Fertigstellung benachrichtigen (z. B. E-Mail, Push-Nachricht)
notify_user(user_id, result['data'][0]['url'])
return jsonify({"received": True}), 200
Zukunftspläne der APIYI-Plattform
| Funktion | Aktueller Status | Zukunftspläne | Erwarteter Zeitraum |
|---|---|---|---|
| Synchroner Aufruf | ✅ Unterstützt | Kontinuierliche Optimierung der Timeout-Konfiguration | – |
| OSS-URL-Ausgabe | ✅ Unterstützt | Hinzufügen weiterer CDN-Knoten | Q2 2026 |
| Asynchroner Aufruf (Polling) | ❌ Nicht unterstützt | Unterstützung von Aufgabenübermittlung + Statusabfrage | Q2 2026 |
| Asynchroner Aufruf (Webhook) | ❌ Nicht unterstützt | Unterstützung von Callback-Benachrichtigungen bei Abschluss | Q2 2026 |
| Batch API Integration | ❌ Nicht unterstützt | Integration der Google Batch API | Q4 2026 |
💡 Entwicklungsempfehlung: APIYI plant, im dritten Quartal 2026 asynchrone Aufruffunktionen einzuführen, die Aufgabenübermittlung, Statusabfrage und Webhook-Callbacks unterstützen. Entwicklern, die derzeit Bedarf an Stapelverarbeitung haben, wird empfohlen, synchrone Schnittstellen mit Multithreading parallel aufzurufen und über die APIYI-Plattform (apiyi.com) stabile HTTP-Ports sowie optimierte Timeout-Konfigurationen zu beziehen.
Häufig gestellte Fragen
Q1: Warum unterstützen weder APIYI noch das offizielle Gemini asynchrone Aufrufe?
Technische Gründe:
-
Google Infrastruktur-Einschränkungen: Die zugrunde liegende Infrastruktur der Google Gemini API unterstützt derzeit nur den synchronen Inferenzmodus. Asynchrone Aufrufe erfordern zusätzliche Aufgabenwarteschlangen und Statusverwaltungssysteme.
-
Entwicklungskomplexität: Asynchrone Aufrufe erfordern die Implementierung von:
- Aufgabenwarteschlangen-Management
- Status-Persistenz der Aufgaben
- Webhook-Callback-Mechanismen
- Logik für Fehlversuche (Retries) und Kompensation
-
Priorität der Nutzeranforderungen: Die meisten Nutzer benötigen eine Bildgenerierung in Echtzeit. Synchrone Aufrufe decken bereits über 80 % der Anwendungsszenarien ab.
Lösungen:
- Aktuell: Verwendung von Multi-Threading oder Multi-Processing für den parallelen Aufruf synchroner Schnittstellen.
- Zukunft: APIYI plant die Einführung asynchroner Aufruffunktionen für Q2 2026.
Q2: Werden Bilder über die OSS-URLs von APIYI dauerhaft gespeichert?
Speicherstrategie:
| Speicherdauer | Erläuterung | Anwendungsfall |
|---|---|---|
| 7 Tage | Standardmäßige Speicherung für 7 Tage, danach automatische Löschung | Temporäre Vorschau, Testgenerierung |
| 30 Tage | Für zahlende Nutzer auf 30 Tage verlängerbar | Kurzfristige Projekte, Event-Materialien |
| Dauerhaft | Nutzer laden die Bilder in ihren eigenen OSS-Speicher herunter | Langzeitnutzung, kommerzielle Projekte |
Empfohlenes Vorgehen:
import requests
# 生成图像并获取 URL
result = generate_image_sync(prompt="A beautiful landscape", size="4096x4096")
temp_url = result['data'][0]['url']
print(f"临时 URL: {temp_url}")
# 下载图像到本地 or 自己的 OSS
image_response = requests.get(temp_url)
with open("permanent_image.png", "wb") as f:
f.write(image_response.content)
# 或上传到自己的 OSS (以阿里云 OSS 为例)
import oss2
auth = oss2.Auth('YOUR_ACCESS_KEY', 'YOUR_SECRET_KEY')
bucket = oss2.Bucket(auth, 'oss-cn-beijing.aliyuncs.com', 'your-bucket')
bucket.put_object('images/permanent_image.png', image_response.content)
Hinweis: Die von APIYI bereitgestellten OSS-URLs dienen der temporären Speicherung und sind ideal für schnelle Vorschauen und Tests. Für Bilder, die langfristig benötigt werden, laden Sie diese bitte rechtzeitig lokal herunter oder sichern Sie sie in Ihrem eigenen Cloud-Speicher.
Q3: Wie vermeide ich Timeouts bei synchronen Aufrufen?
3 entscheidende Konfigurationen zur Vermeidung von Timeouts:
-
Timeout-Zeiten korrekt festlegen:
# ✅ Richtig: Getrennte Einstellung für Connection- und Read-Timeout timeout=(10, 600) # (Verbindungs-Timeout 10 Sek., Lese-Timeout 600 Sek.) # ❌ Falsch: Nur ein einzelner Timeout-Wert timeout=600 # Wirkt sich möglicherweise nur auf den Verbindungsaufbau aus -
HTTP-Port-Schnittstelle verwenden:
# ✅ Empfohlen: APIYI HTTP-Port nutzen, um HTTPS-Handshake-Overhead zu vermeiden url = "http://api.apiyi.com:16888/v1/images/generations" # ⚠️ Optional: HTTPS-Schnittstelle, erhöht die TLS-Handshake-Zeit url = "https://api.apiyi.com/v1/images/generations" -
Retry-Mechanismus implementieren:
from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry # 配置重试策略 retry_strategy = Retry( total=3, # 最多重试 3 次 status_forcelist=[429, 500, 502, 503, 504], # 仅对这些状态码重试 backoff_factor=2 # 指数退避: 2s, 4s, 8s ) adapter = HTTPAdapter(max_retries=retry_strategy) session = requests.Session() session.mount("http://", adapter) # 使用 session 发起请求 response = session.post( "http://api.apiyi.com:16888/v1/images/generations", json={...}, timeout=(10, 600) )
Q4: Wie rufe ich die Nano Banana Pro API direkt im Frontend auf?
Warum ein direkter Aufruf im Frontend nicht empfohlen wird:
- Risiko von API-Key-Leaks: Frontend-Code macht den API-Key für alle Nutzer sichtbar.
- Browser-Concurrency-Limits: Browser begrenzen standardmäßig die Anzahl gleichzeitiger Verbindungen zu derselben Domain (meist max. 6).
- Timeout-Beschränkungen: Die Standard-Timeouts der Browser-
fetch-API sind oft zu kurz, um den Generierungsprozess abzuschließen.
Empfohlene Architektur: Backend-Proxy-Modus:
// 前端代码 (React 示例)
async function generateImage(prompt, size) {
// 调用自己的后端接口
const response = await fetch('https://your-backend.com/api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_USER_TOKEN' // 用户认证 token
},
body: JSON.stringify({ prompt, size })
});
const result = await response.json();
return result.image_url; // 返回 APIYI OSS URL
}
// 使用
const imageUrl = await generateImage("A futuristic city", "4096x4096");
document.getElementById('result-image').src = imageUrl;
# 后端代码 (Flask 示例)
from flask import Flask, request, jsonify
import requests
app = Flask(__name__)
@app.route('/api/generate', methods=['POST'])
def generate():
# 验证用户 token
user_token = request.headers.get('Authorization')
if not verify_user_token(user_token):
return jsonify({"error": "Unauthorized"}), 401
data = request.json
# 后端调用 APIYI API (API Key 不会暴露给前端)
response = requests.post(
"http://api.apiyi.com:16888/v1/images/generations",
json={
"prompt": data['prompt'],
"size": data['size'],
"model": "nano-banana-pro",
"n": 1,
"response_format": "url"
},
headers={"Authorization": "Bearer YOUR_APIYI_API_KEY"}, # 安全存储在后端
timeout=(10, 600)
)
result = response.json()
return jsonify({"image_url": result['data'][0]['url']})
Zusammenfassung
Die wichtigsten Punkte zu synchronen und asynchronen Aufrufen der Nano Banana Pro API:
- Merkmale synchroner Aufrufe: Die HTTP-Verbindung bleibt bis zum Abschluss der Generierung bestehen. Dies erfordert eine blockierende Wartezeit von 30–170 Sekunden und entsprechend konfigurierte lange Timeouts (300–600 Sekunden).
- Vorteile asynchroner Aufrufe: Sofortige Rückgabe einer Task-ID, nicht-blockierend, ideal für Stapelverarbeitung und Hintergrundaufgaben. Derzeit werden diese jedoch weder von APIYI noch von Google Gemini offiziell unterstützt.
- APIYI OSS-URL-Ausgabe: Im Vergleich zur Base64-Kodierung wird der Response-Body um 99,998 % reduziert. Dies unterstützt CDN-Beschleunigung und Browser-Caching, was die Performance erheblich steigert.
- Aktuelle Best Practices: Verwendung synchroner Aufrufe in Kombination mit Multi-Threading und OSS-URL-Ausgabe. Nutzen Sie den APIYI HTTP-Port für optimierte Timeout-Konfigurationen.
- Zukunftsplanung: APIYI plant für Q2 2026 die Einführung asynchroner Funktionen inklusive Aufgabenübermittlung, Statusabfrage und Webhook-Callbacks.
Wir empfehlen die schnelle Integration der Nano Banana Pro API über APIYI (apiyi.com). Die Plattform bietet optimierte HTTP-Port-Schnittstellen (http://api.apiyi.com:16888/v1), exklusive Bildausgabe via OSS-URL sowie angemessene Timeout-Konfigurationen, die ideal für Echtzeit-Bildgenerierung und Stapelverarbeitung geeignet sind.
Autor: APIYI Tech-Team | Bei technischen Fragen besuchen Sie bitte APIYI (apiyi.com) für weitere Integrationslösungen zu KI-Modellen.