Viele Designer, die zum ersten Mal mit GPT-Image-2 in Berührung kommen, stellen sich eine grundlegende Frage: Wenn ich ein Foto hochlade und die KI anweise, „die Kleidung der Person blau zu färben“, ändert die KI dann präzise die Pixel wie in Photoshop, oder zeichnet sie das Bild im Hintergrund komplett neu? Die Antwort auf diese Frage ist entscheidend dafür, wie wir KI-Bildbearbeitungstools nutzen und wie wir die Vorhersehbarkeit der Ergebnisse einschätzen.
Tatsächlich handelt es sich hierbei um ein weit verbreitetes Missverständnis technischer Details. Dieser Artikel beleuchtet die Prinzipien der KI-Bildbearbeitung und analysiert die Funktionsweise der neuen Generation autoregressiver Bildmodelle wie GPT-Image-2 und Nano Banana. Wir klären die Kernfrage „lokale Änderung oder Neuzeichnung“ und zeigen auf, wie diese Modelle trotz einer vollständigen Bildneugenerierung eine beeindruckende visuelle Konsistenz wahren.

| Kernfrage | Intuitive Antwort | Wahre Antwort |
|---|---|---|
| Bearbeitungsweise | Lokale PS-Überlagerung | Token-basiertes Neuzeichnen |
| Konsistenzquelle | Beibehaltung der Pixel | Self-Attention verankert Originalmerkmale |
| Hauptarchitektur | Diffusions-Denoising | Autoregressiver Transformer |
| Mehrfache Bearbeitung | Artefaktbildung | GPT-Image-2 ohne Drift |
Sobald Sie dieses Prinzip verstanden haben, werden Sie feststellen, dass die Formulierung der Eingabeaufforderung, die Verwendung von Masken und die Strategien zur Einbindung von Referenzbildern eine neue theoretische Grundlage erhalten. Wir empfehlen unseren Lesern, die GPT-Image-2-Schnittstelle auf der Plattform APIYI (apiyi.com) begleitend zum Lesen zu testen, um die Theorie in die Praxis umzusetzen.
Prinzip der KI-Bildbearbeitung: Keine lokale PS-Änderung, sondern intelligente Neugenerierung
Viele Nutzer gehen aufgrund der Interaktionserfahrung mit ChatGPT davon aus, dass KI-Bildbearbeitung wie eine „lokale Änderung“ in Photoshop funktioniert: Das System erkennt den zu ändernden Bereich, überlagert ihn mit ein paar Pixeln und lässt den Rest unverändert. Dieses mentale Modell ist zwar intuitiv, aber grundlegend falsch.
Alle gängigen KI-Bildbearbeitungsmodelle basieren im Kern auf einer „Neuzeichnungs“-Logik. Ob GPT-Image-2, Nano Banana oder die Stable-Diffusion-Serie – alle müssen das Originalbild zunächst in eine interne Repräsentation (Token oder Latent) kodieren, damit das Modell eine neue, vollständige interne Repräsentation „imaginiert“ und diese schließlich wieder in Pixel dekodiert. Es gibt dazwischen keinen Schritt, bei dem „direkt auf dem Originalbild gezeichnet“ wird.
Das ist der Grund, warum manchmal bei der Änderung der Augenfarbe auch Haarsträhnen oder Hintergrundtexturen leicht variieren. Das Modell ist nicht nachlässig; es zeichnet tatsächlich das gesamte Bild neu, wobei es die meisten Bereiche sehr nah am Original hält.
Die Frage bleibt: Warum sehen die mit GPT-Image-2 bearbeiteten Bilder dann so konsistent aus und erlauben sogar mehrfache Bearbeitungsrunden ohne „Abdriften“? Die Antwort liegt in der Architektur. Wenn Sie dieses Verhalten selbst verifizieren möchten, können Sie die /v1/images/edits-Schnittstelle von GPT-Image-2 auf APIYI (apiyi.com) aufrufen, dasselbe Bild mit derselben Eingabeaufforderung mehrfach bearbeiten und die Detailänderungen beobachten.
Wesentliche Unterschiede zwischen PS-Bearbeitung und KI-Neugenerierung
| Vergleichsdimension | Photoshop lokale Änderung | GPT-Image-2 intelligente Neugenerierung |
|---|---|---|
| Operationseinheit | Pixel | Visuelle Token (8×8 oder 16×16 Pixelblöcke) |
| Unbearbeitete Bereiche | Physisch unverändert | Durch Kodierung/Dekodierung theoretisch leicht rekonstruiert |
| Konsistenzgarantie | 100% (direktes Kopieren der Pixel) | Durch Attention-Mechanismus des Modells |
| Semantisches Verständnis | Nein, nur Pixelwerte | Versteht Semantik wie „Kleidung“, „Hintergrund“, „Licht“ |
| Randübergänge | Manuelle Weichzeichnung nötig | Automatische, semantisch natürliche Übergänge |
Photoshop ist eine „mechanische Änderung“ auf Pixelebene, während die KI auf einem semantischen „Verstehen und Neuzeichnen“ basiert. Deshalb kann die KI ganzheitliche Bearbeitungen wie „Tag in Abenddämmerung verwandeln“ durchführen – etwas, das mit Photoshop unmöglich wäre, da sie die semantische Repräsentation des Bildes und nicht nur die RGB-Werte der Pixel ändert.
Das Bearbeitungsprinzip von gpt-image-2: Wie autoregressive Transformer das Originalbild „verstehen“
Um das Bearbeitungsprinzip von gpt-image-2 wirklich zu verstehen, kommt man an einer zentralen Architektur-Entscheidung nicht vorbei, die OpenAI am 21. April 2026 mit der Veröffentlichung dieses Modells traf: der Abkehr von den Diffusionsmodellen der DALL-E-Serie hin zu autoregressiven Transformern. Diese Entscheidung orientiert sich direkt an der multimodalen Architektur von GPT-4o.
Die autoregressive Generierung folgt im Wesentlichen demselben Mechanismus, den ChatGPT beim Schreiben von Texten verwendet – die Vorhersage des nächsten Tokens. Der Unterschied besteht darin, dass es sich hierbei nicht um Text, sondern um visuelle Token handelt. Das Modell geht dabei wie folgt vor:
- Bild-Tokenisierung: Durch einen Diskretisierungsmechanismus ähnlich wie bei VQ-VAE wird ein Bild in etwa 1024 bis 1290 visuelle Token zerlegt, wobei jedes Token grob einem 8×8- oder 16×16-Pixelblock des Originalbilds entspricht.
- Sequenz-Zusammenführung: Die Eingabeaufforderung des Benutzers und die visuellen Token des Originalbilds werden zu einer langen Sequenz kombiniert und in einen einheitlichen Transformer eingespeist.
- Token-für-Token-Generierung: Das Modell sagt von links nach rechts (oder in Raster-Scan-Reihenfolge) jedes visuelle Token des Ausgabebildes einzeln voraus. Bei der Generierung jedes neuen Tokens kann es alle vorherigen Eingaben und bereits generierten Inhalte „sehen“.
- Dekodierung in Pixel: Sobald alle visuellen Token generiert sind, werden sie durch einen Dekodierer in das endgültige Pixelbild zurückverwandelt.
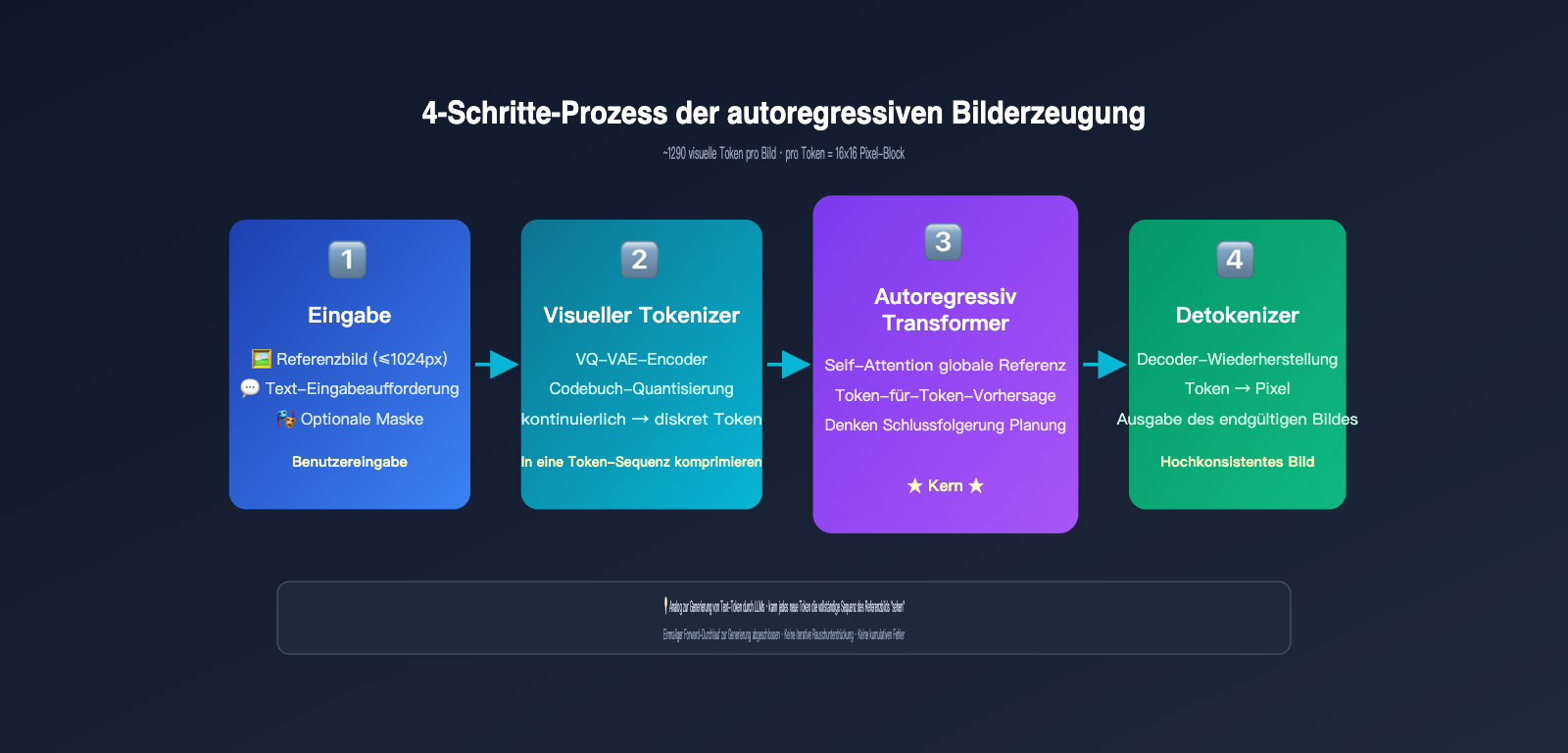
Die entscheidende Erkenntnis hierbei ist: Bei der Generierung eines neuen Bildes befinden sich alle Token des Originalbildes im „Sichtfeld“ von GPT-Image-2. Das Prinzip ist identisch mit dem einer Unterhaltung mit ChatGPT, bei der das Modell alle vorherigen Nachrichten sehen kann. Der Self-Attention-Mechanismus ermöglicht es jedem neu generierten Token, auf die Merkmale an jeder beliebigen Stelle des Originalbildes zu „verweisen“.
OpenAI hat in GPT-Image-2 zudem einen „Thinking-Modus“ eingeführt, der es dem Modell erlaubt, vor der eigentlichen Generierung der visuellen Token eine interne logische Prüfung durchzuführen: Was möchte der Benutzer ändern, welche Teile sollen beibehalten werden und wie soll das räumliche Layout aussehen? Dies hat die Genauigkeit bei komplexen Bearbeitungsanweisungen weiter verbessert und erreicht eine Textgenauigkeit von 99 % sowie eine präzise Anordnung mehrerer Objekte. Wenn Sie diese Funktionen in einer Produktionsumgebung testen möchten, können Sie über den API-Proxy-Dienst APIYI (apiyi.com) auf gpt-image-2 zugreifen. Die Plattform bietet eine mit dem offiziellen Standard identische Schnittstelle sowie einen bequemen Wechsel zwischen verschiedenen Modellen.
Visueller Tokenizer: Die Balance zwischen Kompression und Informationserhalt
Der visuelle Tokenizer ist der entscheidende Flaschenhals des gesamten autoregressiven Bilderzeugungs-Systems. Er muss einen Kompromiss zwischen zwei Zielen finden:
- Hohe Kompressionsrate: Je weniger Token, desto schneller arbeitet der Transformer und desto geringer sind die Kosten.
- Hohe Rekonstruktionsqualität: Die dekodierten Pixel sollten das Originalbild so detailgetreu wie möglich wiedergeben.
Der gängige Ansatz ist VQ-VAE (Vector Quantized Variational Autoencoder): Ein Encoder komprimiert Bildbereiche in einen kontinuierlichen Vektor, der dann einem begrenzten „Codebuch“ zugeordnet wird, um den Index des am nächsten liegenden Codeworts zu finden – dieser Index ist das Token. Ein 1024×1024-Bild wird normalerweise auf etwa 1024 Token komprimiert, was eine extrem hohe Informationsdichte bedeutet.
Da diese Kompression verlustbehaftet ist, kann kein KI-Bearbeitungstool die Pixelwerte der nicht bearbeiteten Bereiche des Originalbildes „zu 100 % beibehalten“. Dies führt uns zum nächsten kritischen Punkt – der Konsistenz.
Kernmechanismen der KI-Bildkonsistenz: Visuelle Tokenisierung und Attention-Anker
Da GPT-Image-2 das gesamte Bild neu generiert, stellt sich die Frage: Wie wird KI-Bildkonsistenz erreicht? Warum verändern sich Gesichtszüge, Hautton oder Frisur nicht in eine fremde Person, wenn man ein Porträt bearbeitet? Die Antwort liegt auf vier Ebenen.
Erste Ebene: Die hohe Abstraktion visueller Token. Nach der Tokenisierung eines Gesichts kodiert die resultierende Token-Sequenz die Kernmerkmale der Person – Gesichtsform, Proportionen, Hauttöne usw. Solange diese „Identitäts-Token“ bei der Generierung des neuen Bildes weitgehend erhalten bleiben, bleibt die Person erkennbar.
Zweite Ebene: Globale Referenz durch Self-Attention. Bei der Generierung jedes neuen Tokens berechnet der autoregressive Transformer die Aufmerksamkeitsgewichtung zu allen Eingabe-Token (einschließlich der Token des Originalbildes). Wenn der Nutzer für einen Bereich keine Änderungen vorgibt, weist das Modell den Token an der entsprechenden Stelle des Originals ein hohes Gewicht zu – es „kopiert“ also faktisch das Original.
Dritte Ebene: Induktiver Bias durch Trainingsdaten. OpenAI hat GPT-Image-2 mit einer riesigen Menge an „Original-Bild-zu-bearbeitetes-Bild“-Paaren trainiert. Das Modell hat dabei eine implizite Regel gelernt: Ändere nichts, sofern der Prompt dies nicht explizit verlangt. Dieser Bias ist in den Gewichten verankert und wirkt bei der Inferenz automatisch.
Vierte Ebene: Explizite Planung im Thinking-Modus. GPT-Image-2 erstellt vor der Generierung eine interne Analyse, um festzulegen, „welche Bereiche geändert und welche beibehalten werden sollen“. Es erstellt also quasi eine „Bewahrungsliste“, bevor es mit der eigentlichen Generierung beginnt.
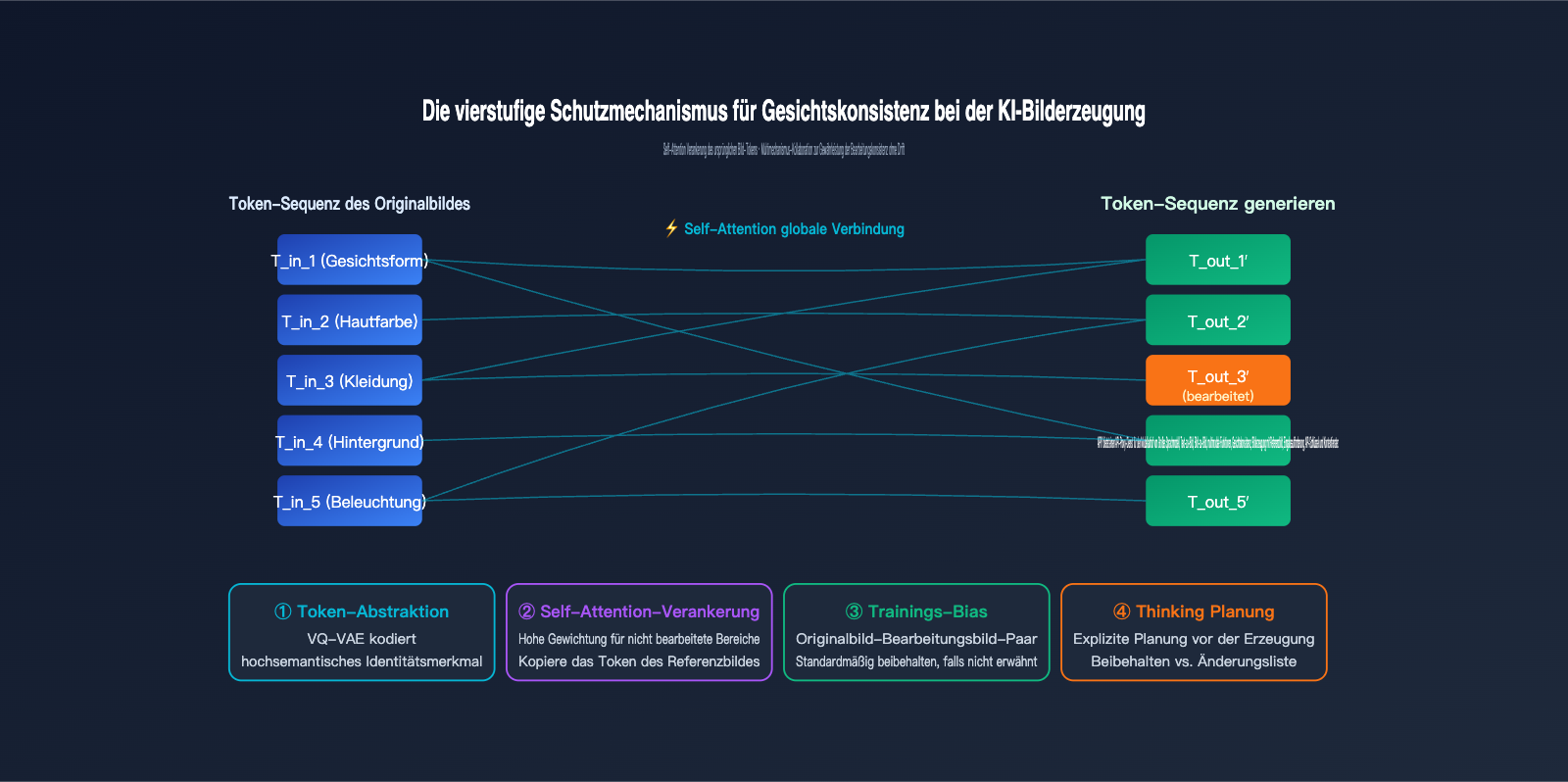
Vergleich der vier Schutzschichten für Konsistenz
| Mechanismus-Ebene | Wirkungsbereich | Versagensszenario |
|---|---|---|
| Token-Abstraktion | Globale Identitätsmerkmale | Gesicht zu weit entfernt, zu wenige Token |
| Self-Attention | Lokale Detailverankerung | Semantischer Konflikt zwischen Prompt und Original |
| Trainings-Bias | Bewahrung nicht erwähnter Bereiche | Zu aggressiver Prompt |
| Thinking-Planung | Komplexe Bearbeitungsbefehle | Erfordert mehrfache Optimierung |
Wenn Sie diese vier Schutzschichten verstehen, können Sie präzisere Prompts formulieren, um „Drift“ zu vermeiden. Anstatt beispielsweise „Zeichne die Kleidung dieser Person neu“ zu schreiben, formulieren Sie besser: „Behalte die Identität der Person bei und ändere nur die Farbe der Kleidung von Weiß zu Blau.“ Bei Tests von GPT-Image-2 auf APIYI (apiyi.com) haben wir festgestellt, dass explizite Einschränkungen wie „andere Elemente unverändert lassen“ den Thinking-Modus deutlich effektiver machen.
Masken-Modus: Wenn Neugenerierung wie lokale Bearbeitung wirkt
Wenn Nutzer eine deterministischere Erfahrung bei „lokalen Änderungen“ wünschen, bietet GPT-Image-2 den mask-Parameter für den /v1/images/edits-Endpunkt. Nutzer können ein binäres Maskenbild übergeben: Weiße Bereiche erlauben der KI die Generierung, schwarze Bereiche müssen das Original beibehalten.
Es ist jedoch wichtig zu betonen, dass der Masken-Modus die Natur der Neugenerierung nicht ändert. Seine Funktion besteht darin, bei der Token-Generierung eine harte Einschränkung hinzuzufügen: Die Token für die schwarzen Bereiche müssen exakt den Token des Originals entsprechen. Dies ist eine „eingeschränkte Generierung“ innerhalb des autoregressiven Frameworks und keine bloße Pixel-Überlagerung wie in Photoshop.
Diffusionsmodelle vs. autoregressive Bilderzeugung: Ein Vergleich der Implementierungsprinzipien
Um die Vorteile von GPT-Image-2 vollständig zu verstehen, ist ein systematischer Vergleich mit der vorherigen Generation von Diffusionsmodellen (Stable Diffusion, DALL-E 3, Midjourney) erforderlich. Beide Systeme unterscheiden sich grundlegend in ihrem Prinzip der KI-Bildbearbeitung.
Der Arbeitsablauf von Diffusionsmodellen beginnt mit einem reinen Rauschbild, das durch Dutzende von iterativen Entrauschungsschritten allmählich das endgültige Bild hervorbringt. Bei der Bearbeitung wird das Originalbild zunächst in den latenten Raum komprimiert, dort teilweise mit Rauschen versehen und dann durch eine Eingabeaufforderung (Prompt) durch den Entrauschungsprozess geführt, bevor es schließlich wieder in Pixel dekodiert wird. Der Inpainting-Modus setzt bei jedem Entrauschungsschritt die latenten Werte außerhalb der Maske auf die Werte des Originalbildes zurück, um so die nicht bearbeiteten Bereiche zu „fixieren“.
Der Arbeitsablauf von autoregressiven Modellen ist völlig anders: Das Bild wird in Token kodiert und dann, ähnlich wie beim Schreiben eines Textes, Token für Token vorhergesagt. Es gibt keine iterative Entrauschung, kein latentes Rauschen – die Generierung erfolgt in einem einzigen Durchgang.

Die Leistungsunterschiede beider Paradigmen bei der Bildbearbeitung sind enorm, wie die folgende Tabelle zeigt:
| Vergleichspunkt | Diffusionsmodell (SD/DALL-E 3) | Autoregressives Modell (GPT-Image-2/Nano Banana) |
|---|---|---|
| Generierungsart | Mehrstufige Entrauschungsiteration | Einzelne Token-Sequenzvorhersage |
| Masken-Implementierung | Zurücksetzen des unmaskierten Latents pro Schritt | Harte Token-Ebene-Beschränkung |
| Randbehandlung | Anfällig für latente Artefakte | Natürlicher Übergang (semantische Ebene) |
| Text-Rendering | Häufig fehlerhaft | Ca. 99 % Genauigkeit |
| Mehrstufige Bearbeitung | Kumulativer Rekodierungsverlust | Nahezu kein Drift |
| Komplexe Anweisungen | Schwierige präzise Anordnung | Unterstützt Layouts mit 100+ Objekten |
| Geschwindigkeit | Normalerweise 10–30 Sekunden | Ca. 60 % schneller als Diffusion |
| Langer Text | Schwierig | Beliebige Sprachen/Skripte |
Das Hauptproblem von Diffusionsmodellen liegt im Rekodierungsverlust der VAE-Kodierung/Dekodierung – selbst wenn die unmaskierten Bereiche theoretisch fixiert sind, führt die Hin- und Her-Konvertierung zwischen latentem Raum und Pixeln zu winzigen Farbabweichungen. Nach mehrfacher Bearbeitung summieren sich diese Verluste zu sichtbaren Artefakten. GPT-Image-2 umgeht dieses Problem durch seine autoregressive Architektur, da die Token-Dekodierung nur einmal stattfindet.
Doch die autoregressive Methode hat ihren Preis. Die Generierungskosten sind höher, vor allem weil die Anzahl der Token groß ist und jedes Token einen vollständigen Transformer-Forward-Pass erfordert. Wir empfehlen den Einsatz von GPT-Image-2 (zugänglich über APIYI apiyi.com) für Szenarien, die höchste Konsistenz und präzises Text-Rendering erfordern, während die Stable-Diffusion-Serie für kostensensible Hochlast-Szenarien weiterhin als Ergänzung dienen kann.
Praxis der GPT-Image-2-Bearbeitung: API-Aufrufe und Konsistenzoptimierung
Nachdem wir die GPT-Image-2-Bearbeitungsprinzipien verstanden haben, schauen wir uns an, wie man diesen Mechanismus optimal einsetzt. Hier ist ein minimales, ausführbares Beispiel für den Aufruf der Bearbeitungsschnittstelle von GPT-Image-2 über den APIYI-kompatiblen Endpunkt:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Behalte die Identität der Person und den Hintergrund bei, ändere nur die Farbe des Oberteils von Weiß zu Dunkelblau",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Beachten Sie die Formulierung der Eingabeaufforderung: Geben Sie explizit an, was beibehalten und was geändert werden soll. Dies triggert den Thinking-Modus von GPT-Image-2 direkt, sodass die Generierung wie erwartet geplant wird. Wenn Sie präzise Bereichsbearbeitungen vornehmen möchten, können Sie den mask-Parameter hinzufügen:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Ändere das weiße Oberteil in einen dunkelblauen Anzug",
size="1024x1024"
)
Die Maske ist ein PNG in derselben Größe, wobei weiße Bereiche den bearbeitbaren Bereich definieren und schwarze Bereiche das Original-Token zwingend beibehalten.
5 praktische Tipps zur Konsistenzoptimierung
Für das tatsächliche Debugging der AI-Bildkonsistenz haben wir 5 Erfahrungen aus realen Tests zusammengefasst:
- Definieren Sie in der Eingabeaufforderung, was "beibehalten" werden soll: Sagen Sie nicht nur "Ändere X", sondern "Behalte Y bei, ändere X".
- Angemessene Auflösung des Referenzbildes: OpenAI empfiehlt, dass die lange Seite des Referenzbildes 1024px nicht überschreitet; eine zu hohe Auflösung verwässert die Aufmerksamkeit der Token.
- Verwenden Sie für mehrstufige Bearbeitungen dasselbe Basisbild: Nutzen Sie nicht das Ergebnis der letzten Bearbeitung als Eingabe für die nächste, sondern basieren Sie jede Bearbeitung auf dem Originalbild und kombinieren Sie die Eingabeaufforderungen am Ende.
- Zerlegen Sie Anweisungen bei komplexen Szenen: Teilen Sie "Ändere die Person in einen japanischen Stil mit Abendhintergrund" in zwei Schritte auf, wobei jeder Schritt nur eine Variable ändert.
- Wählen Sie den Qualitätsparameter 'high': Niedrige Qualität reduziert die Anzahl der Token und schwächt direkt die Konsistenz.
Preis-Leistungs-Verhältnis von GPT-Image-2 und Konsistenz
| Parameterkombination | Kosten pro Bild | Anwendungsfall |
|---|---|---|
| 1024×1024 low | $0.006 | Kreative Skizzen/Schnellvorschau |
| 1024×1024 medium | $0.053 | Social-Media-Bilder |
| 1024×1024 high | $0.211 | Kommerzielle Bearbeitung/Iterationen |
| 4K high | $0.50+ | Druck/Hochauflösende Präsentation |
Kosten und Konsistenz korrelieren positiv – der High-Quality-Modus weist dem Modell mehr Token zu, wodurch natürlich mehr Merkmale des Originalbildes erhalten bleiben. Wir empfehlen, in Produktionsumgebungen den 'high'-Modus zu bevorzugen. Mit der Batch-API von APIYI (apiyi.com) lassen sich die Kosten zudem um weitere 50 % senken.
FAQ zu Prinzipien der KI-Bildbearbeitung und Zukunftstrends
Q1: Ist GPT-Image-2 eine lokale Photoshop-Bearbeitung oder eine Neuzeichnung?
A: Es ist eine Neuzeichnung. Alle autoregressiven Bildmodelle müssen das Originalbild in Token kodieren, dann eine vollständige Sequenz von Ausgabe-Token generieren und diese schließlich in ein neues Bild dekodieren. Selbst wenn eine Maske aktiviert ist, dient dies nur als Einschränkung während des Neuzeichnungsprozesses, nicht als echte lokale Pixel-Überlagerung.
Q2: Wenn es eine Neuzeichnung ist, warum sieht das bearbeitete Bild dann fast identisch aus?
A: Dies basiert auf vier Konsistenzmechanismen: Merkmalsabstraktion der visuellen Token, globale Referenz des Originalbildes durch Self-Attention, induktiver Bias der Trainingsdaten und explizite Planung durch den Thinking-Modus. Diese Mechanismen veranlassen die KI dazu, "aktiv zu wählen", die nicht erwähnten Bereiche beizubehalten.
Q3: Zählt das Inpainting von Diffusionsmodellen als echte lokale Änderung?
A: Nein. Das Inpainting von Stable Diffusion muss die unmaskierten Bereiche ebenfalls durch die VAE-Kodierung/Dekodierung laufen lassen, was zu kleinen Rekodierungsverlusten führt. Mehrstufige Bearbeitungen akkumulieren sich zu sichtbaren Artefakten – genau das ist einer der Hauptgründe, warum GPT-Image-2 auf autoregressive Modelle setzt. Sie können über APIYI (apiyi.com) beide Modelle gleichzeitig für einen Vergleich aufrufen.
Q4: Warum kann GPT-Image-2 mehrstufige Bearbeitungen ohne Drift durchführen?
A: Weil die autoregressive Architektur bei jeder Generierung auf die vollständige Token-Sequenz des Originalbildes verweist, ohne kumulative Fehler durch iterative Entrauschung. In Kombination mit der expliziten Erhaltungsplanung des Thinking-Modus ist die Stabilität bei mehrstufigen Bearbeitungen weit überlegen gegenüber Diffusionsmodellen.
Q5: Sollte ich eine Maske oder nur eine Eingabeaufforderung zur Bearbeitung verwenden?
A: Bevorzugen Sie die Eingabeaufforderung + explizite Erhaltungsanweisungen, um die automatische Planung des Thinking-Modus zu nutzen. Nur wenn die Grenzen des zu ändernden Bereichs klar definiert und präzise sein müssen (z. B. bestimmte Gesichtspartien), sollten Sie eine Maske als harte Einschränkung hinzufügen.
Q6: Wie wird sich die KI-Bildbearbeitung in Zukunft entwickeln?
A: Drei Trends: (1) Kontinuierliche Steigerung der Informationsdichte der Tokenizer zur Senkung von Token-Anzahl und Kosten; (2) Multimodale Vereinheitlichung, bei der Text/Bild/Video denselben Transformer teilen; (3) Verstärkte Thinking-Schlussfolgerungsfähigkeiten zur Unterstützung längerer, mehrstufiger Bearbeitungsketten. Wir empfehlen, die neuen Modellveröffentlichungen auf APIYI (apiyi.com) zu verfolgen, um Upgrade-Pfade sofort bewerten zu können.
Fazit: Prinzipien verstehen, um Werkzeuge zu beherrschen
Autoregressive Bildmodelle wie GPT-Image-2 haben unser intuitives Verständnis von "KI-Bildbearbeitung" revolutioniert. Es handelt sich nicht um lokale Änderungen im Photoshop-Stil, sondern um intelligentes Neuzeichnen auf Basis der autoregressiven Bilderzeugung. Die Konsistenz resultiert aus dem Zusammenspiel von vier Mechanismen: semantische Abstraktion durch Tokenisierung, globale Verankerung durch Self-Attention, Trainings-Bias und der Thinking-Modus.
Wenn Sie diese Prinzipien verstehen, können Sie Eingabeaufforderungen schreiben, die tatsächlich die Thinking-Planung auslösen, Fallstricke bei mehrstufigen Bearbeitungen vermeiden und das Gleichgewicht zwischen Kosten und Qualität finden. Wir empfehlen, praktische Tests und Vergleiche über die Plattform APIYI (apiyi.com) durchzuführen, da diese eine einheitliche Schnittstelle für verschiedene Mainstream-Modelle wie GPT-Image-2, Nano Banana und Stable Diffusion bietet.
Dieser Artikel wurde vom APIYI-Team verfasst und basiert auf offiziellen Informationen von OpenAI, Google DeepMind sowie eigenen Praxistests. Für den Einsatz von GPT-Image-2 in Produktionsumgebungen besuchen Sie die APIYI-Website: apiyi.com, um die Integrationsdokumentation zu erhalten.