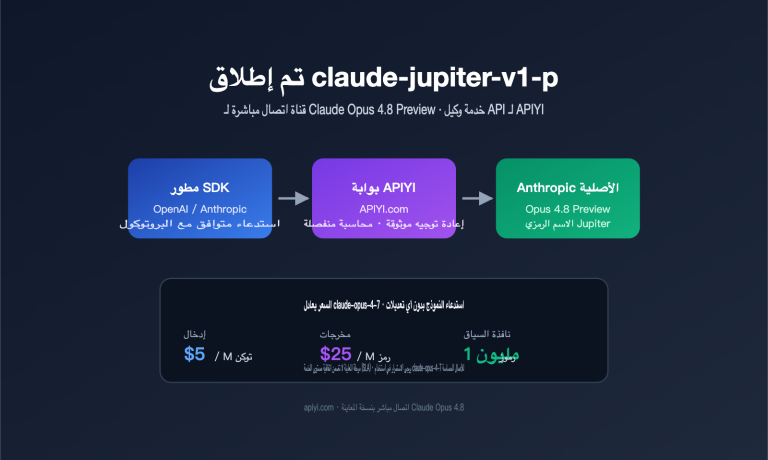
إليك تحديث يستحق اهتمام المطورين! أطلقت عائلة نماذج Dola الأساسية من ByteDance في 28 أبريل 2026 أول نموذج فهم "متعدد الوسائط بالكامل" (Omnimodal) وهو Seed-2.0-lite-260428، والذي يدعم بشكل أصلي أربعة أنواع من المدخلات: الفيديو، الصور، الصوت، والنصوص. يُعد هذا النموذج الأول في عائلة Dola Seed الذي يتمتع بقدرة "الرؤية والسمع" معاً، كما شهد تحسينات متزامنة في مهام الوكلاء (Agents)، البرمجة، وواجهات المستخدم الرسومية (GUI). يستعرض هذا المقال قدرات النموذج، وتفاصيل فهم الصوت، وسيناريوهات الاستخدام النموذجية، وذلك بناءً على المواصفات الرسمية من BytePlus ModelArk والمعايير العامة لـ ByteDance، مع دمج تجارب الاختبار الفعلية عبر خدمة وكيل API من APIYI (apiyi.com).
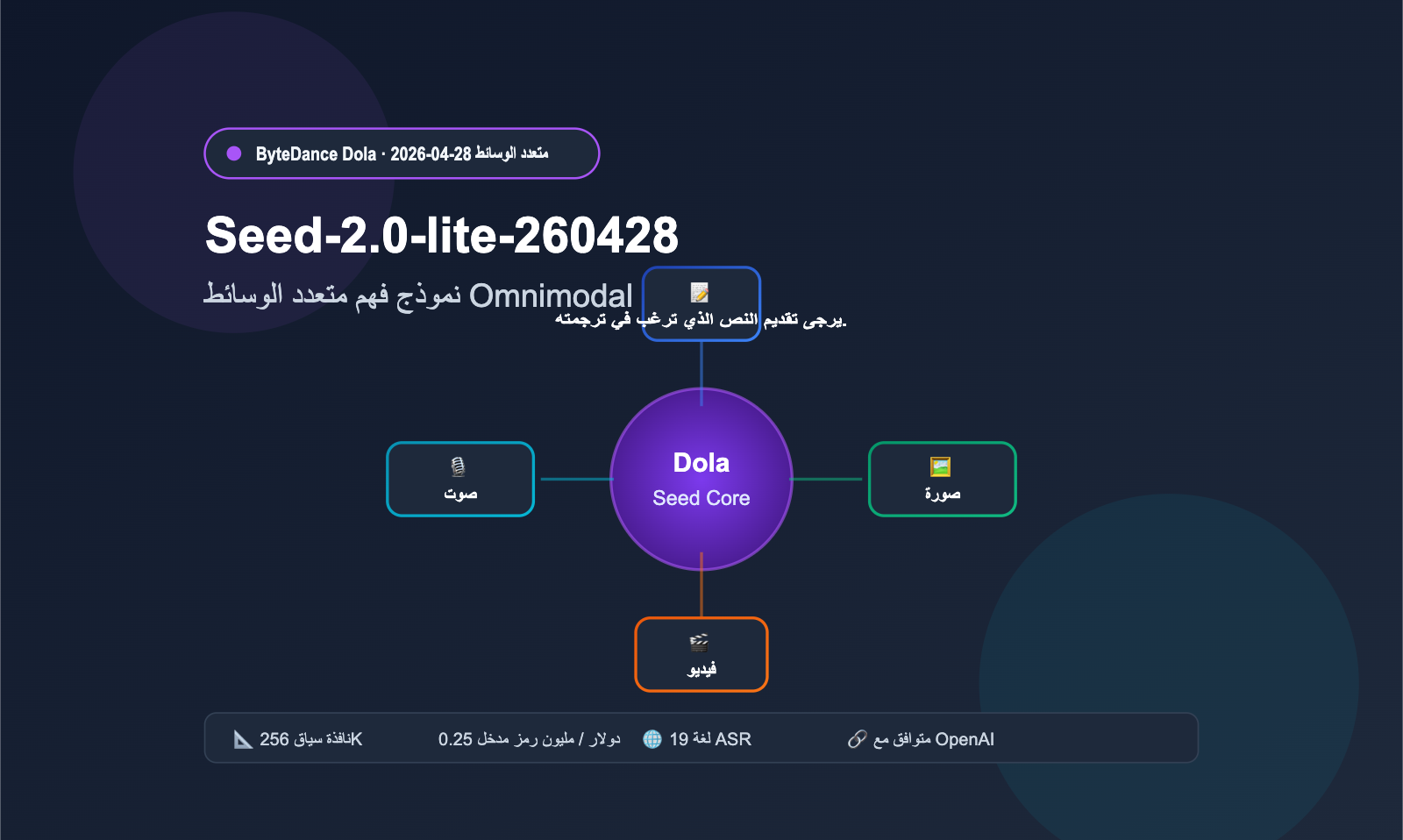
أولاً: ما هو Seed-2.0-lite-260428: التموضع الأساسي ونقاط الترقية
يُعد Seed-2.0-lite-260428 تحديثاً مهماً أطلقته ByteDance Seed في 28 أبريل 2026. ورغم أن النموذج الأساسي يعتمد على Seed-2.0-Lite الذي أُطلق في أوائل مارس، إلا أنه يضيف "المدخلات الصوتية" كقدرة أصلية لأول مرة، مما يدفع خط الإنتاج هذا نحو مرحلة "متعدد الوسائط بالكامل" (Omnimodal) الحقيقية. يشير الرقم 260428 في اسم النموذج إلى تاريخ الإصدار (28 أبريل 2026).
1.1 أول نموذج متعدد الوسائط بالكامل من عائلة Dola لـ ByteDance
في عائلة Dola Seed السابقة، كانت قدرات النصوص والوسائط المتعددة توضع في فروع منفصلة. أما Seed-2.0-lite-260428، فهو يدمج الفيديو، الصور، الصوت، والنصوص في نموذج واحد للاستدلال، مما يعني أنه يستطيع "رؤية لقطات الفيديو" و"سماع المحتوى الصوتي" في آن واحد، وإجراء أحكام مشتركة واسترجاع تسلسلي بناءً على ذلك. هذه البنية الموحدة بالغة الأهمية لتطبيقات الوكلاء (Agents)، لأن العديد من المهام الواقعية (مثل مراجعة الفيديو، تلخيص الاجتماعات، ومراقبة جودة خدمة العملاء) تتطلب بطبيعتها استدلالاً عبر الوسائط.
1.2 نظرة سريعة على المواصفات الأساسية للنموذج
يوضح الجدول أدناه المعايير الأساسية لنموذج Seed-2.0-lite-260428 على منصة BytePlus ModelArk، مما يسهل على القراء تحديد ما إذا كان يلبي احتياجات أعمالهم:
| عنصر المواصفات | المعلمة المحددة |
|---|---|
| معرف نموذج API | seed-2-0-lite-260428 |
| عائلة النموذج | ByteDance Seed / Dola |
| تاريخ الإصدار | 28-04-2026 |
| نافذة السياق | 262,144 توكن (حوالي 256 ألف) |
| الحد الأقصى للمخرجات | 131,072 توكن (حوالي 128 ألف) |
| وسائط الإدخال | نص + صورة + فيديو + صوت |
| سعر الإدخال | 0.25 دولار / مليون توكن |
| سعر المخرجات | 2.00 دولار / مليون توكن |
| توافق الواجهة | متوافق مع OpenAI API |
ثانياً: القدرات الأربع الرئيسية لنموذج Seed-2.0-lite-260428 في الفهم متعدد الوسائط
إن قدرات النموذج متعدد الوسائط لا تقتصر ببساطة على "ربط" مدخلات متنوعة، بل تعتمد على التفكير المشترك من خلال تمثيل موحد. وقد لخصت الوثائق الرسمية قدراته الجوهرية في أربعة اتجاهات:
2.1 التفكير المشترك في الصوت والفيديو والاسترجاع الزمني
يمكن للنموذج تحليل المعلومات المرئية والصوتية في الفيديو في وقت واحد، والحكم بدقة على ما إذا كانت "الصورة المرئية" تتوافق مع "الصوت المسموع". على سبيل المثال، يمكنه تحديد ما إذا كانت تعبيرات وجه الشخص في الفيديو تتوافق مع نبرة صوته، أو ما إذا كانت حركات الأجسام في المشهد تتطابق مع المؤثرات الصوتية الصحيحة. تعد قدرة المزامنة بين الصوت والفيديو هذه مفيدة للغاية في سيناريوهات مثل مراجعة الفيديوهات واكتشاف التزييف العميق.
2.2 التفكيك العميق للفيديو والتتبع الزمني الطويل
بالنسبة للفيديوهات الطويلة، يدعم Seed-2.0-lite-260428 استخراج القرائن الرئيسية عبر فترات زمنية متعددة، وتتبع تقدم الشخصيات والأحداث باستمرار، وإجراء استنتاجات متعددة الخطوات بين الإطارات لإعادة بناء علاقات الأحداث وسياق السلوك. وبالمقارنة مع الطريقة التقليدية لوصف الفيديو إطاراً بإطار، فإن قدرته على "الفهم الزمني الطويل" أكثر ملاءمة لمهام مثل مراجعة فيديوهات المراقبة ومساعد تحرير الأفلام الوثائقية.
2.3 تعزيز قدرات الوكيل (Agent) والترميز
يتمتع النموذج بقدرة تنفيذ مستقرة وموثوقة في المهام الزمنية الطويلة والمعقدة، بالإضافة إلى قدرات تطوير برمجية شاملة. وهذا يعني أنه يمكن للمطورين دمجه في إطار عمل الوكيل (Agent) لتنفيذ حلقة كاملة تتضمن التخطيط، واستدعاء الأدوات، ومراجعة الخطوات السابقة، وتوليد الأكواد البرمجية، دون الحاجة إلى تقسيم المهام بين نماذج مختلفة.
2.4 واجهة موحدة لفهم واجهة المستخدم الرسومية (GUI) وتنفيذ العمليات
تم دمج قدرات واجهة المستخدم الرسومية (GUI) في واجهة واحدة، حيث يمكن للنموذج فهم لقطات الشاشة (الأزرار، النماذج، القوائم) وإخراج تعليمات التشغيل (إحداثيات النقر، إدخال النصوص). وهذا يمثل ترقية مباشرة للقدرات في مجالات الاختبار الآلي، ووكلاء سطح المكتب، وتطبيقات أتمتة العمليات الروبوتية (RPA).
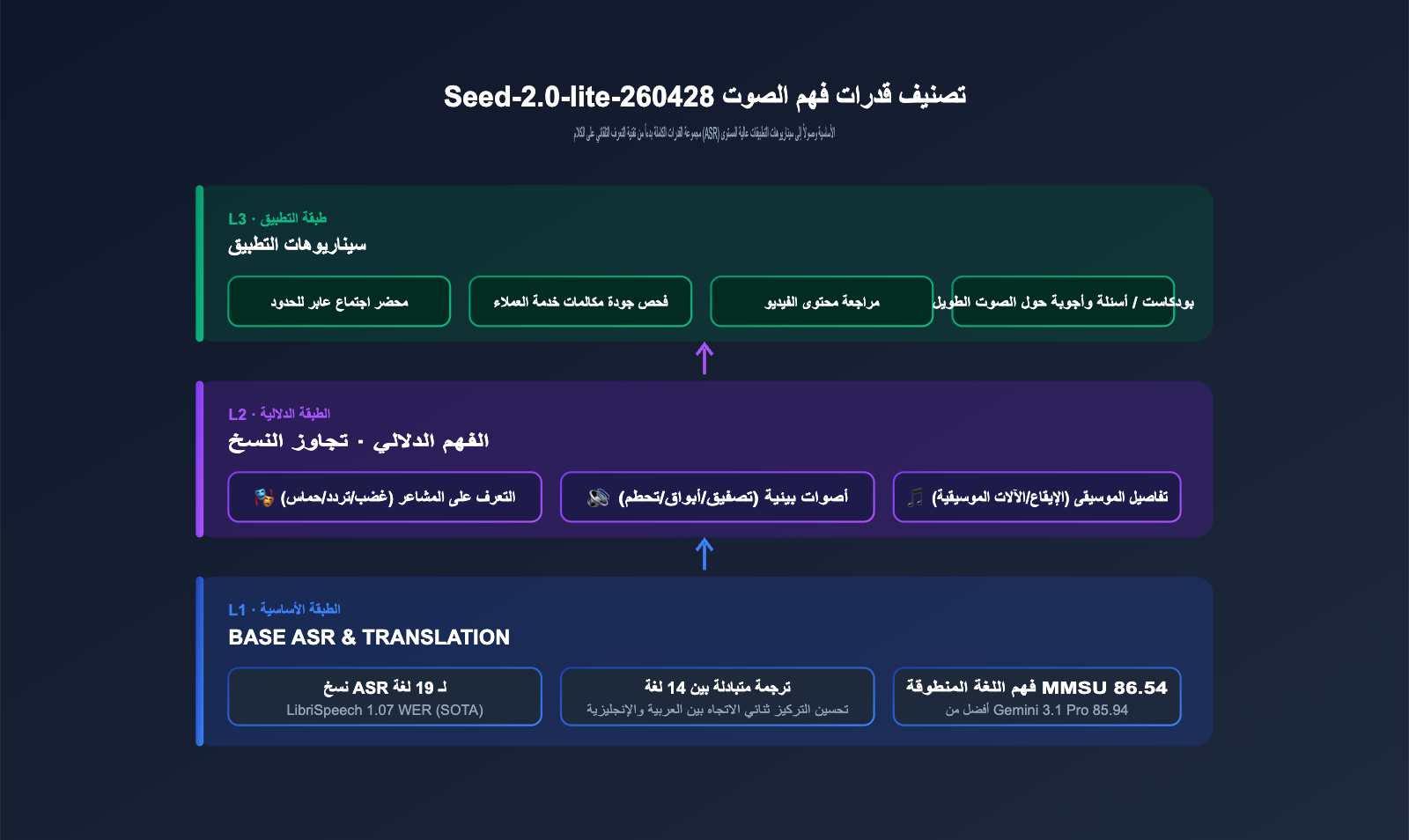
ثالثاً: تحليل عميق لقدرات فهم الصوت في Seed-2.0-lite-260428
يعد الصوت أكبر قدرة تميز هذا التحديث، لذا سنفصله بشكل منفصل. لقد حقق النموذج نتائج مبهرة في العديد من معايير الصوت الرئيسية.
3.1 نتائج الاختبارات على معايير الصوت الرئيسية
يلخص الجدول أدناه نتائج المعايير التي أعلنت عنها ByteDance رسمياً لنموذج Seed، والتي تغطي ثلاثة أبعاد: التعرف على الكلام (ASR)، وفهم اللغة المنطوقة، ومشاهد الكلام في البيئات المفتوحة.
| المعيار | نوع المهمة | Seed-2.0-lite-260428 |
|---|---|---|
| LibriSpeech test-clean | ASR للغة الإنجليزية (نقي) | 1.07 WER |
| LibriSpeech test-other | ASR للغة الإنجليزية (ضوضاء) | 2.17 WER |
| WenetSpeech test-net | ASR للغة الصينية (إنترنت) | 4.47 WER |
| WenetSpeech test-meeting | ASR لاجتماعات اللغة الصينية | 5.31 WER |
| Fleurs (15 لغة) | ASR متعدد اللغات | 74.70 |
| MMSU | فهم اللغة المنطوقة | 86.54 |
| WildSpeech | الكلام في البيئات المفتوحة | 75.81 |
إن معدل الخطأ (WER) البالغ 1.07 في اختبار LibriSpeech test-clean يضعه في صدارة المستوى الصناعي، متفوقاً على نتائج مماثلة لنموذج Whisper large-v3 المتاح للجمهور؛ كما أن درجات MMSU وWildSpeech أعلى قليلاً من البيانات المعلنة لنموذج Gemini 3.1 Pro، مما يشير إلى أن النموذج وصل إلى مستوى رائد في "الفهم" وليس مجرد "الإملاء".
3.2 النسخ بـ 19 لغة والترجمة المتبادلة بين 14 لغة
توضح الوثائق الرسمية أن النموذج يدعم نسخ الكلام بـ 19 لغة والترجمة المتبادلة بين 14 لغة، مع اعتبار الترجمة الثنائية بين الصينية والإنجليزية اتجاهاً رئيسياً للتحسين. وهذا يعني أنه بالنسبة لتسجيل اجتماع متعدد اللغات، يمكن للنموذج إخراج ترجمة نصية بلغة موحدة، وهو أمر مناسب لفرق العمل العابرة للحدود وخدمة عملاء التجارة الإلكترونية الدولية.
3.3 ما وراء "النسخ": العواطف، الأصوات المحيطة، وتفاصيل الموسيقى
يختلف Seed-2.0-lite-260428 عن نماذج ASR التقليدية في قدرته على التقاط معلومات دلالية تتجاوز "المحتوى النصي": تقلبات مشاعر المتحدث (غضب، تردد، حماس)، أصوات الخلفية (تحطم زجاج، تصفيق، أبواق سيارات)، وتفاصيل الموسيقى (الإيقاع، الآلات، النمط). هذه الأبعاد لها قيمة مباشرة في أعمال مثل مراقبة جودة خدمة العملاء، ومراجعة المحتوى، وتوصيات الموسيقى.
🎯 نصيحة للدمج: في سيناريوهات مثل محاضر الاجتماعات العابرة للحدود، ومراقبة جودة خدمة العملاء، ومراجعة محتوى الفيديو التي تتطلب تعاوناً بين "الصوت + النص"، نوصي بالاستدعاء المباشر لنموذج Seed-2.0-lite-260428 عبر خدمة APIYI (apiyi.com). باستخدام رابط أساسي (base_url) واحد، يمكنك الحصول على فوائد مزدوجة تتمثل في الاستنتاج متعدد الوسائط ونافذة سياق طويلة تصل إلى 256 ألف رمز، دون الحاجة إلى بناء خط معالجة صوتي خاص بك.
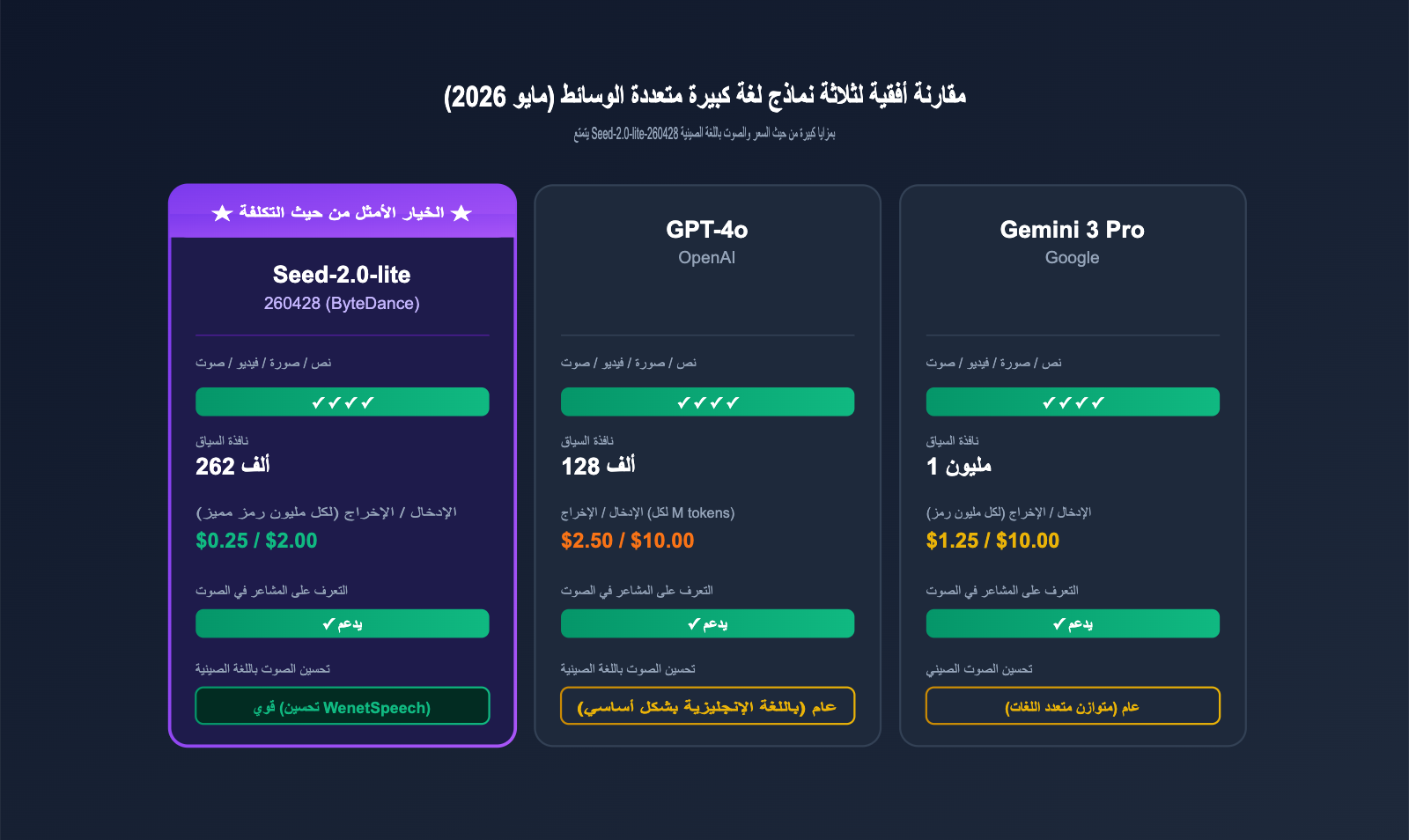
رابعاً: تحليل مقارن بين Seed-2.0-lite-260428 ونماذج اللغة الكبيرة متعددة الوسائط الرائدة
لتقييم مكانة هذا النموذج في عام 2026، فإن أفضل طريقة هي مقارنته بنماذج اللغة الكبيرة متعددة الوسائط الرائدة في نفس الفترة مثل GPT-4o وGemini 3 Pro.
4.1 مقارنة قدرات نماذج اللغة الكبيرة متعددة الوسائط
| الأبعاد | Seed-2.0-lite-260428 | GPT-4o | Gemini 3 Pro |
|---|---|---|---|
| إدخال نصي | ✓ | ✓ | ✓ |
| إدخال صوري | ✓ | ✓ | ✓ |
| إدخال فيديو | ✓ | ✓ | ✓ |
| إدخال صوتي | ✓ | ✓ | ✓ |
| نافذة السياق | 262K | 128K | 1M |
| سعر الإدخال / مليون رمز | $0.25 | $2.50 | $1.25 |
| سعر الإخراج / مليون رمز | $2.00 | $10.00 | $10.00 |
| التعرف على المشاعر الصوتية | ✓ | ✓ | ✓ |
| تحسين الصوت باللغة الصينية | قوي (تحسين WenetSpeech) | متوسط | متوسط |
كما يتضح، تكمن الميزة الأساسية لنموذج Seed-2.0-lite-260428 في الجمع بين "السعر التنافسي + دعم الصوت باللغة الصينية + نافذة سياق طويلة تصل إلى 262 ألف رمز"، مما يجعله خياراً ذا قيمة ممتازة في مهام معالجة الصوت والفيديو متعدد اللغات، وتلخيص الاجتماعات الطويلة. بينما لا يزال كل من GPT-4o وGemini 3 Pro يتفوقان في القدرات الشاملة باللغة الإنجليزية واتساع النظام البيئي، مما يجعلهما مناسبين للسيناريوهات العامة.
🎯 نصيحة للاختيار: إذا كان عملك يركز بشكل أساسي على معالجة الصوت والفيديو باللغة الصينية وكنت حساساً للتكلفة، فإن Seed-2.0-lite-260428 هو خيار ذو قيمة ممتازة في الوقت الحالي؛ أما إذا كان التركيز على اللغة الإنجليزية أو الإبداع متعدد اللغات المكثف، فيمكنك استخدام بوابة APIYI (apiyi.com) الموحدة للوصول إلى هذه النماذج الثلاثة الرائدة في وقت واحد وتوجيه الطلبات حسب السيناريو.
5. البدء السريع مع نموذج Seed-2.0-lite-260428 عبر APIYI
يتوافق النموذج تماماً مع واجهات برمجة التطبيقات (API) بأسلوب OpenAI، مما يجعل تكلفة الانتقال إليه منخفضة للغاية. فيما يلي مثال مبسط لاستدعاء النموذج لتحويل مقطع صوتي أو صورة إلى وصف هيكلي.
5.1 الحد الأدنى من مثال لواجهة برمجة التطبيقات المتوافقة مع OpenAI
from openai import OpenAI
# إعداد العميل باستخدام مفتاح API الخاص بك
client = OpenAI(
api_key="<APIYI_API_KEY>",
base_url="https://vip.apiyi.com/v1"
)
# استدعاء النموذج لتحليل محتوى صوتي
response = client.chat.completions.create(
model="seed-2-0-lite-260428",
messages=[
{"role": "user", "content": [
{"type": "text", "text": "يرجى وصف محتوى هذا المقطع الصوتي، والمشاعر، والأصوات الخلفية."},
{"type": "input_audio", "audio": {"data": "<base64-or-url>", "format": "mp3"}}
]}
]
)
print(response.choices[0].message.content)
بمجرد توجيه base_url إلى نقطة الوصول الموحدة لـ APIYI (apiyi.com) وتبديل اسم model، يمكنك استدعاء Seed-2.0-lite-260428 ونماذج أخرى متعددة الوسائط ضمن نفس حزمة تطوير البرمجيات (SDK)، دون الحاجة لإعادة كتابة الكود الخاص بأعمالك.
5.2 سيناريوهات التطبيق النموذجية لـ Seed-2.0-lite-260428
يوضح الجدول أدناه بعض السيناريوهات النموذجية، والفوائد التي يمكن الحصول عليها من ميزة "الاستدلال الموحد للصوت + الفيديو + النص" في هذا النموذج.
| سيناريو التطبيق | القدرات الرئيسية | القيمة التجارية |
|---|---|---|
| محاضر الاجتماعات العابرة للحدود | التعرف التلقائي على الكلام (ASR) بـ 19 لغة + ترجمة بـ 14 لغة + نافذة سياق 256K | تحويل اجتماعات متعددة اللغات إلى محاضر ثنائية اللغة بضغطة زر |
| مراقبة جودة مكالمات خدمة العملاء | التعرف على المشاعر + اكتشاف الأصوات المحيطة + تحليل الصوت الطويل | وضع علامات تلقائية على الغضب/المقاطعة/تجاوز الوقت |
| مراجعة محتوى الفيديو | استدلال مشترك للصوت والفيديو + تتبع زمني طويل | تحديد المشاهد الخطرة والأصوات المشبوهة بشكل متزامن |
| بودكاست / أسئلة وأجوبة للفيديوهات الطويلة | نافذة سياق طويلة 256K + تحويل الصوت إلى نص | طرح أسئلة مباشرة حول محتوى صوتي يمتد لساعات |
| أتمتة وكلاء سطح المكتب | فهم واجهة المستخدم الرسومية (GUI) + استدعاء الأدوات | إنجاز سير عمل معقد عبر تطبيقات متعددة |
6. الأسئلة الشائعة حول Seed-2.0-lite-260428
6.1 كيف يتم ملء حقل model عند استدعاء API؟
ما عليك سوى إدخال seed-2-0-lite-260428. لاحظ وجود واصلات بين الأرقام وليس شرطات سفلية؛ اللاحقة 260428 هي رقم الإصدار (28 أبريل 2026)، لا تحذفها، وإلا فقد يتم توجيه طلبك إلى إصدار قديم. يمكنك التحقق من قائمة النماذج في لوحة تحكم APIYI (apiyi.com) لضمان التوافق مع أحدث الإصدارات.
6.2 ما هي تنسيقات الصوت ومددها المدعومة؟
يتبع النموذج اتفاقية حقل input_audio الخاصة بـ OpenAI، ويدعم التنسيقات الشائعة مثل MP3 وWAV وM4A وFLAC. يرجى الرجوع إلى وثائق ModelArk الرسمية لمعرفة الحد الأقصى للمدة ومعدل العينة، ونوصي بألا يتجاوز الإدخال الفردي 30 دقيقة لضمان استقرار الاستدلال. بالنسبة للمقاطع الطويلة جداً، يمكن تقسيمها إلى أجزاء ثم دمج النتائج.
6.3 ما الفرق بينه وبين نسخة Seed-2.0-Lite بدون لاحقة 260428؟
النسخة بدون لاحقة هي الإصدار الأول من Seed-2.0-Lite الذي تم إصداره في 10 مارس، والذي يدعم فقط النص والصور والفيديو. أما 260428 فهي النسخة المحدثة لجميع الوسائط التي أُطلقت في 28 أبريل، والتي أضافت إمكانية إدخال الصوت والاستدلال المشترك للصوت والفيديو. إذا كان عملك يتطلب التعامل مع الصوت، فيجب عليك استخدام النسخة ذات اللاحقة.
6.4 هل يتم احتساب التكلفة بناءً على الرموز (tokens) أم مدة الصوت؟
يتم احتساب التكلفة بناءً على الرموز (tokens) بشكل موحد، حيث يتم ترميز الصوت داخلياً إلى رموز قبل الحساب. التسعير الحالي هو 0.25 دولار لكل مليون رمز إدخال، و2.00 دولار لكل مليون رمز إخراج. يمكنك الاطلاع على عدد الرموز المقابل لمقطع صوتي معين في "سجل الفواتير" داخل لوحة تحكم APIYI (apiyi.com)، مما يسهل تقدير التكاليف وتحسينها.
6.5 هل يدعم المخرجات المتدفقة (Streaming) واستدعاء الدوال (Function Call)؟
نعم، يدعم ذلك بالكامل. يتوافق Seed-2.0-lite-260428 مع بروتوكول OpenAI Chat Completions القياسي بما في ذلك حقول stream=true وtools، ويمكن دمجه مباشرة مع أطر العمل الرئيسية مثل LangChain وLangGraph وOpenAI Agents SDK دون الحاجة إلى تعديلات خاصة.
7. الخلاصة: النماذج متعددة الوسائط الشاملة تنقل التطبيقات إلى عصر "الاستدلال الموحد"
لا تكمن قيمة نموذج Seed-2.0-lite-260428 في كونه "يضيف قدرة صوتية إضافية" فحسب، بل في قدرته على دمج الفيديو والصور والصوت والنصوص ضمن نموذج واحد لإتمام عملية الاستدلال. بالنسبة للأعمال التي تعتمد بطبيعتها على وسائط متعددة (مثل الاجتماعات، خدمة العملاء، مراجعة المحتوى، تحليل الفيديو، وأتمتة الوكلاء الذكيين)، يمثل هذا "الاستدلال الموحد" تبسيطاً حقيقياً للبنية التحتية؛ حيث لم تعد هناك حاجة لربط ثلاثة نماذج منفصلة (للتعرف على الكلام ASR، والرؤية الحاسوبية، ومعالجة النصوص)، كما يزول القلق بشأن فقدان السياق بين النماذج المختلفة.
من منظور التكلفة وسياق اللغة العربية، يتمتع هذا النموذج بميزة تنافسية واضحة من حيث القيمة مقابل السعر مقارنة بالنماذج الرائدة الأخرى. فبسعر 0.25 دولار لكل مليون رمز (Token) للإدخال، أصبح معالجة الصوت والفيديو على نطاق واسع أمراً ممكناً من الناحية الهندسية، كما أن نافذة السياق التي تبلغ 256 ألف رمز كافية لتغطية سيناريوهات الصوت والفيديو الطويلة التي تمتد لساعات.
إذا كنت ترغب في استدعاء نموذج Seed-2.0-lite-260428 جنباً إلى جنب مع نماذج الوسائط المتعددة الرائدة الأخرى تحت نفس رابط القاعدة (base_url)، يمكنك زيارة الوثائق الرسمية لـ APIYI عبر apiyi.com للاطلاع على أمثلة الربط الكاملة وقائمة النماذج المتاحة.
المؤلف: فريق APIYI — نواصل تقديم خدمات وكيل API مستقرة وعالية الكفاءة وتوجيه النماذج المتعددة لمطوري الذكاء الاصطناعي حول العالم. للمزيد من التفاصيل، تفضل بزيارة apiyi.com