Gemini 3.1 Pro Preview 和 Gemini 3.0 Pro Preview 價格完全一樣——Input $2.00、Output $12.00 / 百萬 tokens。那問題來了: 3.1 到底比 3.0 強在哪? 值不值得切換?
答案是: 非常值得,而且沒有任何不切換的理由。
本文將用真實基準數據逐項對比兩個版本的差異。劇透一下結論——3.1 Pro 的 ARC-AGI-2 推理得分從 31.1% 飆升到 77.1%,翻了 2.5 倍; SWE-Bench 編碼從 76.8% 提升到 80.6%; BrowseComp 搜索從 59.2% 跳到 85.9%。這不是微調,這是換代級升級。
核心價值: 讀完本文,你將清楚瞭解 3.1 Pro 相對於 3.0 Pro 的每一項具體改進,以及在不同場景下該如何選擇。

Gemini 3.1 Pro 與 3.0 Pro 參數對比總表
先看硬參數層面的差異:
| 對比維度 | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | 變化 |
|---|---|---|---|
| 模型 ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
新版本 |
| 發佈日期 | 2025 年 11 月 18 日 | 2026 年 2 月 19 日 | +3 個月 |
| Input 價格 (≤200K) | $2.00 / M tokens | $2.00 / M tokens | 不變 |
| Output 價格 (≤200K) | $12.00 / M tokens | $12.00 / M tokens | 不變 |
| Input 價格 (>200K) | $4.00 / M tokens | $4.00 / M tokens | 不變 |
| Output 價格 (>200K) | $18.00 / M tokens | $18.00 / M tokens | 不變 |
| 上下文窗口 | 1M tokens | 1M tokens | 不變 |
| 最大輸出 | — | 65K tokens | 明確提升 |
| 文件上傳上限 | 20MB | 100MB | 5 倍 |
| YouTube URL 支持 | ❌ | ✅ | 新增 |
| 思考級別 | 2 級 (low/high) | 3 級 (low/medium/high) | 新增 medium |
| customtools 端點 | ❌ | ✅ | 新增 |
| 知識截止日期 | 2025 年 1 月 | 2025 年 1 月 | 不變 |
價格、上下文窗口、知識截止完全不變。所有變化都是純粹的能力提升。
🎯 核心結論: 價格一分不多,功能只多不少。從參數層面看,3.1 Pro 是 3.0 Pro 的嚴格上位替代。通過 API易 apiyi.com 調用,只需把 model 參數從
gemini-3-pro-preview改爲gemini-3.1-pro-preview即可完成升級。
差異 1: 推理能力——從「優秀」到「頂尖」
這是 3.0 → 3.1 最大的改進,也是谷歌官方最強調的升級點。
| 推理基準 | 3.0 Pro | 3.1 Pro | 提升幅度 | 說明 |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | 全新邏輯模式推理 |
| GPQA Diamond | — | 94.3% | — | 研究生級科學推理 |
| MMMLU | — | 92.6% | — | 多學科多模態理解 |
| LiveCodeBench Pro | — | Elo 2887 | — | 實時編程競賽 |
ARC-AGI-2 的提升最爲驚人: 從 31.1% 到 77.1%,不是翻倍而是翻了 2.5 倍。這個基準測試評估的是模型解決全新邏輯模式的能力——即模型從未見過的推理題型。77.1% 的分數也超越了 Claude Opus 4.6 的 68.8%,在推理維度上確立了領先地位。
背後的技術原因: 谷歌官方將 3.1 Pro 描述爲擁有「unprecedented depth and nuance」(前所未有的深度和細膩度),而 3.0 Pro 的描述是「advanced intelligence」(高級智能)。這不僅是營銷措辭的變化,ARC-AGI-2 的數據證明了推理深度確實有質的飛躍。
差異 2: 思考級別系統——從 2 級到 3 級
這是 3.1 Pro 最具實操意義的改進之一。
3.0 Pro 的思考系統 (2 級)
| 級別 | 行爲 |
|---|---|
| low | 最小推理,快速響應 |
| high | 深度推理,較高延遲 |
3.1 Pro 的思考系統 (3 級)
| 級別 | 行爲 | 對應關係 |
|---|---|---|
| low | 最小推理,快速響應 | 類似 3.0 的 low |
| medium (新增) | 適度推理,平衡速度和質量 | ≈ 3.0 的 high |
| high | Deep Think Mini 模式,最深推理 | 遠超 3.0 的 high |
關鍵信息: 3.1 Pro 的 medium ≈ 3.0 Pro 的 high。這意味着:
- 用 3.1 的 medium 就能獲得 3.0 最高級別的推理質量
- 3.1 的 high 是全新檔次——類似 Gemini Deep Think 的迷你版
- 同樣的推理質量 (medium),延遲比 3.0 的 high 更低
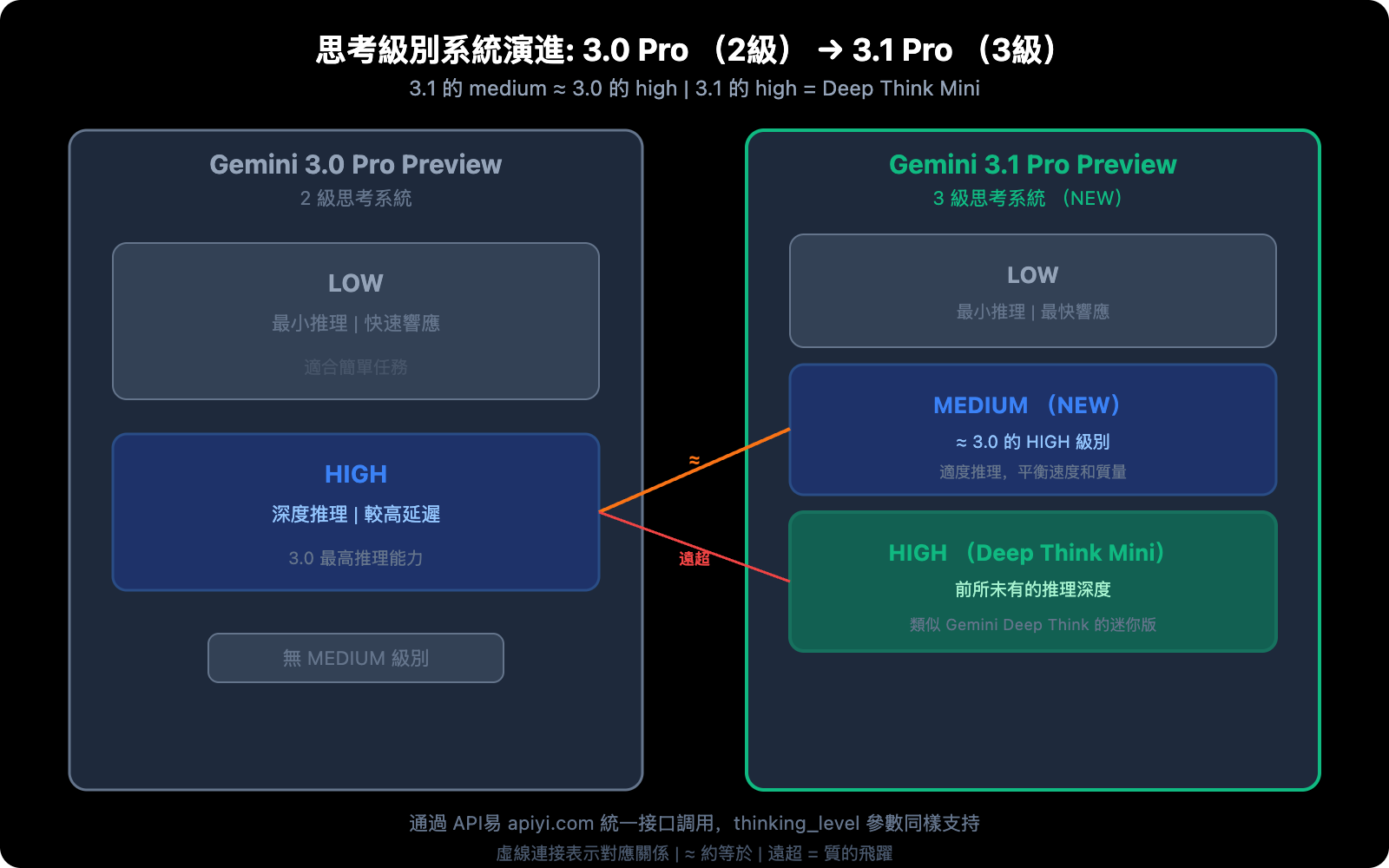
💡 實戰建議: 如果你之前一直用 3.0 Pro 的 high 模式,切換到 3.1 Pro 後建議先用 medium——推理質量相當,但延遲更低。只在遇到真正複雜的推理任務時才切換到 high (Deep Think Mini),這樣可以在不增加成本的前提下獲得更好的整體體驗。API易 apiyi.com 平臺支持傳遞 thinking_level 參數。
差異 3: 編碼能力——躋身第一梯隊
| 編碼基準 | 3.0 Pro | 3.1 Pro | 提升 | 行業對比 |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | Agent 終端編碼 |
| LiveCodeBench Pro | — | Elo 2887 | — | 實時編程競賽 |
SWE-Bench Verified 的提升從表面看只有 3.8 個百分點(76.8% → 80.6%),但在這個分數段每提升 1% 都極爲困難。80.6% 的成績讓 Gemini 3.1 Pro 與 Claude Opus 4.6 (80.9%) 的差距縮小到僅 0.3%——從「第二梯隊領先」變成了「第一梯隊比肩」。
Terminal-Bench 2.0 的提升更爲顯著: 56.9% → 68.5%,提升 20.4%。這個基準專門評估 Agent 在終端環境中執行編碼任務的能力,11.6 個百分點的提升意味着 3.1 Pro 在自動化編程場景中的可靠性大幅增強。
差異 4: Agent 和搜索能力——跨越式飛躍
| Agent 基準 | 3.0 Pro | 3.1 Pro | 提升幅度 |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
這兩項是 3.0 → 3.1 提升幅度最大的基準:
BrowseComp 評估的是 Agent 網絡搜索能力——從 59.2% 飆升到 85.9%,提升了 26.7 個百分點。這對構建研究助手、競品分析、實時信息檢索類 Agent 有重大意義。
MCP Atlas 衡量使用 Model Context Protocol 的多步驟工作流能力——從 54.1% 提升到 69.2%。MCP 是谷歌推動的 Agent 協議標準,這個提升說明 3.1 Pro 在複雜 Agent 工作流中的協調和執行能力顯著增強。
customtools 專用端點: 3.1 Pro 還新增了 gemini-3.1-pro-preview-customtools 專用端點,針對 bash 命令與自定義函數混合調用場景進行了專門優化。該端點特別調優了 view_file、search_code 等開發者常用工具的調用優先級,在自動化運維、AI 編程助手等 Agent 場景中比通用端點更穩定可靠。
🎯 Agent 開發者注意: 如果你正在構建代碼審查 Bot、自動化部署 Agent 等工具,強烈建議使用 customtools 端點。通過 API易 apiyi.com 可以直接調用此端點,model 參數填寫
gemini-3.1-pro-preview-customtools即可。
差異 5: 輸出能力和 API 特性
| 特性 | 3.0 Pro | 3.1 Pro | 變化 |
|---|---|---|---|
| 最大輸出 tokens | 未明確 | 65,000 | 明確標註 65K |
| 文件上傳上限 | 20MB | 100MB | 5 倍提升 |
| YouTube URL | ❌ 不支持 | ✅ 直接傳入 | 新增 |
| customtools 端點 | ❌ | ✅ | 新增 |
| 輸出效率 | 基準 | +15% | 更少 token 更好結果 |
65K 輸出上限: 可以一次性生成完整的長文檔、大段代碼或詳細分析報告,無需分多次請求拼接。
100MB 文件上傳: 從 20MB 擴展到 100MB,意味着可以直接上傳更大的代碼倉庫、PDF 文檔集或媒體文件進行分析。
YouTube URL 直接傳入: 在 prompt 中直接傳入 YouTube 鏈接,模型會自動解析和分析視頻內容——無需下載、轉碼、上傳。
15% 輸出效率提升: JetBrains AI 總監的實測反饋——3.1 Pro 用更少的 token 產出更可靠的結果。這意味着同等任務下,實際 token 消耗更低,成本更優。
各特性對不同用戶的價值
| 特性 | 對個人開發者的價值 | 對企業團隊的價值 |
|---|---|---|
| 65K 輸出 | 一次生成完整代碼文件 | 批量生成技術文檔和報告 |
| 100MB 上傳 | 上傳完整項目進行分析 | 大型代碼倉庫審計 |
| YouTube URL | 快速分析教程視頻 | 競品產品演示分析 |
| customtools | AI 編程助手開發 | 自動化運維 Agent |
| 效率 +15% | 降低個人調用成本 | 規模化場景成本優化顯著 |
💰 成本實測: 在相同任務上,3.1 Pro 的實際 output token 消耗比 3.0 Pro 平均低 10-15%。對於日均百萬 token 級別的企業應用,切換後每月可節省數百美元。通過 API易 apiyi.com 的用量統計功能可以精確對比。
差異 6: 輸出效率——用更少 token 得到更好結果
這是一項容易被忽視但實際影響很大的改進。JetBrains AI 總監 Vladislav Tankov 的實測反饋: 3.1 Pro 相比 3.0 Pro 質量提升 15%,同時消耗更少的輸出 token。
這意味着什麼?
更低的實際使用成本: 雖然單價相同,但 3.1 Pro 完成同樣任務消耗的 token 更少,實際賬單會更低。假設一個日均 100 萬 output tokens 的應用,15% 的效率提升意味着每天節省約 $1.80 的輸出費用。
更快的響應速度: 更少的輸出 token 意味着更短的生成時間。在對延遲敏感的實時應用中,這個提升很有價值。
更精練的輸出質量: 3.1 Pro 不是簡單地「說得更少」,而是「說得更精準」——用更緊湊的表述傳達相同甚至更多的信息量,減少了冗餘和廢話。
差異 7: 安全性和可靠性
| 安全維度 | 3.0 Pro | 3.1 Pro | 變化 |
|---|---|---|---|
| 文本安全性 | 基準 | +0.10% | 微提升 |
| 多語言安全性 | 基準 | +0.11% | 微提升 |
| 錯誤拒絕率 | 基準 | 保持低水平 | 不變 |
| 長任務穩定性 | 基準 | 提升 | 更可靠 |
安全性的提升雖然數值不大,但方向正確——在提升能力的同時沒有犧牲安全性。長任務穩定性的提升對 Agent 應用尤爲重要,意味着在多步驟工作流中,3.1 Pro 更不容易「跑偏」或產生不可靠輸出。
差異 8: 官方定位描述的變化
| 維度 | 3.0 Pro 描述 | 3.1 Pro 描述 |
|---|---|---|
| 核心定位 | advanced intelligence | unprecedented depth and nuance |
| 推理特徵 | advanced reasoning | SOTA reasoning |
| 編碼特徵 | agentic and vibe coding | powerful coding |
| 多模態 | multimodal understanding | powerful multimodal understanding |
從「advanced」到「unprecedented」,從「agentic and vibe coding」到「powerful coding」——措辭變化反映了定位的升級。3.0 Pro 強調的是「高級」和「創新」(vibe coding),3.1 Pro 強調的是「深度」和「強大」。
差異 9: 使用建議——什麼時候該用哪個

遷移代碼示例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
# 3.0 Pro → 3.1 Pro 只改一個參數
# 舊版: model="gemini-3-pro-preview"
# 新版: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # 唯一需要修改的地方
messages=[{"role": "user", "content": "分析這段代碼的性能瓶頸"}]
)
查看 A/B 對比測試代碼
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易統一接口
)
test_prompt = "給定數組 [3,1,4,1,5,9,2,6], 使用歸併排序並分析時間複雜度"
# 測試 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# 測試 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\n3.0 回答:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 回答:\n{resp_31.choices[0].message.content[:300]}...")
遷移注意事項和最佳實踐
第一步: 測試核心場景
在你最常用的 3-5 個 prompt 上對比 3.0 和 3.1 的輸出。重點關注推理質量、代碼準確性和輸出格式。
第二步: 調整思考級別
如果之前用 3.0 的 high 模式,切換到 3.1 後建議先用 medium (推理質量相當但更快)。只在真正需要深度推理時使用 high (Deep Think Mini)。
第三步: 探索新能力
嘗試 100MB 文件上傳、YouTube URL 分析、65K 長輸出等 3.1 獨有功能,可能會發現新的應用場景。
第四步: 全量切換
確認效果後,將所有調用從 gemini-3-pro-preview 改爲 gemini-3.1-pro-preview。建議保留 3.0 作爲 fallback,直到 3.1 在你的場景中穩定運行一週以上。
🚀 快速遷移: 通過 API易 apiyi.com 平臺,3.0 → 3.1 的遷移只需改一個參數。建議先用 A/B 測試跑幾個核心場景確認效果,然後全量切換。
常見問題
Q1: 3.1 Pro 和 3.0 Pro 完全兼容嗎? 切換後需要改 prompt 嗎?
API 接口完全兼容,只需修改 model 參數。但由於 3.1 Pro 的推理方式有所改進,某些經過精心調教的 prompt 在 3.1 上的表現可能略有不同——通常是更好,但建議在覈心場景上做迴歸測試。通過 API易 apiyi.com 可以同時調用兩個版本進行對比。
Q2: 3.0 Pro 還會繼續維護嗎? 什麼時候會下線?
作爲 Preview 模型,谷歌通常會提前至少 2 周通知下線。目前 3.0 Pro 仍然可用,但考慮到 3.1 Pro 在所有維度上都是嚴格上位替代,建議儘早遷移。通過 API易 apiyi.com 調用不受谷歌側版本調整影響,平臺會自動處理模型路由。
Q3: 3.1 Pro 的 high 思考模式 token 消耗大嗎?
high 模式 (Deep Think Mini) 確實會消耗更多輸出 token,因爲模型在內部進行了更深的推理鏈條。建議日常任務使用 medium (等價於 3.0 的 high 質量),只在數學推理、複雜調試等場景使用 high。這樣可以在大多數任務上保持甚至降低成本。
Q4: 這兩個版本在 API易 都可以用嗎?
都可以。API易 apiyi.com 同時支持 gemini-3-pro-preview 和 gemini-3.1-pro-preview,使用同一個 API Key 和 base_url,方便進行 A/B 對比測試和靈活切換。
不同用戶的 Gemini 3.1 Pro 升級建議
不同類型的開發者從 3.0 → 3.1 升級中獲得的收益不同,以下是針對性建議:
| 用戶類型 | 最受益的差異 | 升級優先級 | 建議操作 |
|---|---|---|---|
| AI Agent 開發者 | Agent/搜索 +45%、MCP Atlas +28% | ⭐⭐⭐⭐⭐ | 立即切換,效果提升最明顯 |
| 代碼輔助工具 | SWE-Bench +5%、Terminal-Bench +20% | ⭐⭐⭐⭐ | 推薦切換,用 medium 模式即可 |
| 數據分析師 | 推理 ARC-AGI-2 +148%、100MB 上傳 | ⭐⭐⭐⭐⭐ | 優先切換,大文件分析能力大幅增強 |
| 內容創作者 | 65K 長輸出、YouTube URL 分析 | ⭐⭐⭐⭐ | 推薦切換,新功能實用 |
| 輕量 API 用戶 | 輸出效率 +15%、成本不變 | ⭐⭐⭐ | 方便時切換,同價格更優 |
| 安全敏感應用 | 安全可靠性提升、長任務穩定性 | ⭐⭐⭐⭐ | 先做迴歸測試再切換 |
💡 通用建議: 無論哪種用戶類型,都可以通過 API易 apiyi.com 同時保留 3.0 和 3.1 兩個版本,用 A/B 測試確認效果後再全量切換。零遷移成本,零風險。
Gemini 3.1 Pro 版本切換決策流程
按以下步驟決定是否切換:
- 你的應用是否依賴推理準確性? → 是 → 立即切換 (ARC-AGI-2 提升 148%)
- 你的應用涉及 Agent/搜索? → 是 → 強烈推薦 (BrowseComp +45%)
- 你的 prompt 經過高度定製? → 是 → 先用 medium 模式測試,確認輸出一致後切換
- 你只做簡單問答/翻譯? → 是 → 隨時切換,效果至少持平且效率更高
- 不確定? → 在 API易 apiyi.com 上跑 5 個核心 prompt 的 A/B 測試,10 分鐘出結論
總結: 9 項差異歸納
| # | 差異維度 | 3.0 Pro → 3.1 Pro | 切換價值 |
|---|---|---|---|
| 1 | 推理能力 | ARC-AGI-2: 31.1% → 77.1% | 極高 |
| 2 | 思考系統 | 2 級 → 3 級 (含 Deep Think Mini) | 高 |
| 3 | 編碼能力 | SWE-Bench: 76.8% → 80.6% | 高 |
| 4 | Agent/搜索 | BrowseComp: 59.2% → 85.9% | 極高 |
| 5 | 輸出/API 特性 | 65K 輸出、100MB 上傳、YouTube URL | 高 |
| 6 | 輸出效率 | 用更少 token 得到更好結果 (+15%) | 高 |
| 7 | 安全可靠性 | 安全性微提升,長任務穩定性提升 | 中 |
| 8 | 官方定位 | advanced → unprecedented depth | 信號 |
| 9 | 適用場景 | 幾乎所有場景都應切換 | 明確 |
一句話總結: 同價格、API 兼容、每項指標都更強——Gemini 3.1 Pro Preview 是 3.0 Pro Preview 的免費換代升級,沒有任何不切換的理由。
推薦通過 API易 apiyi.com 快速完成遷移,只需修改一個 model 參數即可。
參考資料
-
Google 官方博客: Gemini 3.1 Pro 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 說明: 官方基準成績和功能介紹
- 鏈接:
-
Google DeepMind 模型卡: 3.1 Pro 技術細節和安全評估
- 鏈接:
deepmind.google/models/model-cards/gemini-3-1-pro - 說明: 安全性數據和詳細參數
- 鏈接:
-
VentureBeat 首測: Deep Think Mini 特性深度體驗
- 鏈接:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 說明: 三級思考系統實際體驗報告
- 鏈接:
-
Artificial Analysis: 3.1 Pro vs 3.0 Pro 對比數據
- 鏈接:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - 說明: 第三方基準對比和性能分析
- 鏈接:
📝 作者: APIYI Team | 技術交流請訪問 API易 apiyi.com
📅 更新時間: 2026 年 2 月 20 日
🏷️ 關鍵詞: Gemini 3.1 Pro vs 3.0 Pro, 模型對比, 推理翻倍, SWE-Bench, ARC-AGI-2, Deep Think Mini