作者注:詳解 Gemini 3.1 Pro API 429 Quota Exceeded 報錯原因和 5 種解決方案,包括多 AI Studio 賬號 Key 輪詢、API 中轉站高併發不限速、指數退避重試等實戰方法
使用 Gemini 3.1 Pro API 時頻繁遇到 429 限速報錯是開發者最頭疼的問題之一。本文將介紹 5 種經過實戰驗證的 Gemini 3.1 Pro 429 報錯解決方案,幫助你快速恢復正常的 API 調用。
核心價值: 讀完本文,你將掌握 Gemini 3.1 Pro 429 報錯的根本原因和 5 種解決方案,其中包括 2 種可以從根源上消除限速問題的方案。
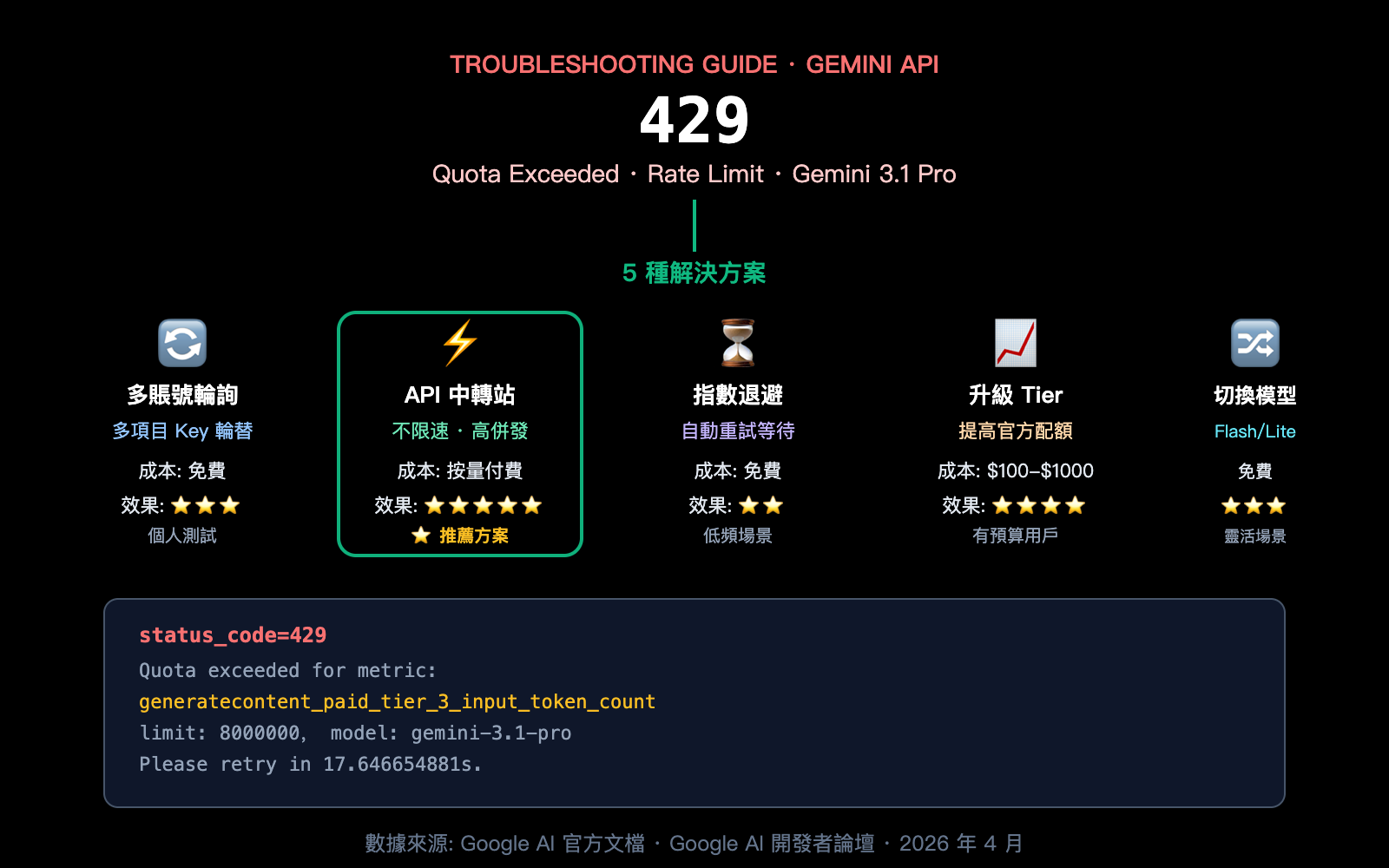
Gemini 3.1 Pro 429 報錯核心信息
Gemini 3.1 Pro 429 錯誤解析
當你看到以下報錯信息時,說明你的 API 請求已觸及 Google 的速率限制:
status_code=429
You exceeded your current quota, please check your plan and billing details.
Quota exceeded for metric: generatecontent_paid_tier_3_input_token_count
limit: 8000000
model: gemini-3.1-pro
Please retry in 17.646654881s.
這條報錯信息包含了 3 個關鍵信息:
| 信息項 | 含義 | 重要性 |
|---|---|---|
| status_code=429 | HTTP 429 = 請求過多(Rate Limit) | 非賬戶問題,是速率限制 |
| paid_tier_3_input_token_count | 你在 Tier 3 付費層級,輸入 Token 達到上限 | 說明你已是最高付費層級 |
| limit: 8000000 | 當前配額上限 800 萬輸入 Token | 這是每分鐘/每天的 Token 限額 |
| retry in 17.6s | Google 建議等待 17.6 秒後重試 | 等待後可恢復,但治標不治本 |
爲什麼 Gemini 3.1 Pro 特別容易觸發 429
Gemini 3.1 Pro 是 Google 最強大的推理模型之一,其 429 報錯特別頻繁有以下原因:
模型本身計算量大 — Gemini 3.1 Pro 是 Preview 版本,Google 分配的全局共享算力有限,多個用戶競爭同一資源池
Tier 限制嚴格 — 即使是 Tier 3 付費用戶(累計消費 $1,000+),配額依然相對緊張:
| 層級 | 解鎖條件 | 月消費上限 | RPM(請求/分) | 日請求限制 |
|---|---|---|---|---|
| Free | 無需付費 | 免費 | 2-15 | 50-1,000 |
| Tier 1 | 開通計費 | $250 | 150-300 | 1,500 |
| Tier 2 | 消費 $100 + 3 天 | $2,000 | 500-1,500 | 10,000 |
| Tier 3 | 消費 $1,000 + 30 天 | $20,000-$100,000 | 1,000-4,000 | 自定義 |
關鍵認知: 即使你已經是 Tier 3 用戶,在高併發場景下仍然會頻繁遇到 429。這不是你的問題,而是 Google Gemini API 的結構性限制。

Gemini 3.1 Pro 429 解決方案一:多 AI Studio 賬號 Key 輪詢
核心原理
Google Gemini API 的限速是按項目(Project)計算的,不是按 API Key 計算的。
這意味着:
- ❌ 在同一個項目下創建多個 API Key → 無效,所有 Key 共享同一配額池
- ✅ 使用多個 Google 賬號創建多個項目 → 有效,每個項目有獨立配額
多賬號輪詢實現方法
第一步: 準備多個 Google 賬號,每個賬號在 AI Studio 中創建獨立項目並獲取 API Key
第二步: 實現 Key 輪詢邏輯
import openai
import random
# 多個 AI Studio 賬號的 API Key(每個來自不同項目)
GEMINI_KEYS = [
"AIzaSy_account1_project1_key",
"AIzaSy_account2_project2_key",
"AIzaSy_account3_project3_key",
"AIzaSy_account4_project4_key",
]
def call_gemini_with_rotation(prompt, max_retries=3):
"""帶 Key 輪詢的 Gemini API 調用"""
keys = GEMINI_KEYS.copy()
random.shuffle(keys)
for i, key in enumerate(keys):
try:
client = openai.OpenAI(
api_key=key,
base_url="https://generativelanguage.googleapis.com/v1beta/openai/"
)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except openai.RateLimitError:
if i < len(keys) - 1:
continue # 切換到下一個 Key
raise # 所有 Key 都用完了
result = call_gemini_with_rotation("Hello, Gemini!")
多賬號方案的優缺點
| 優勢 | 侷限 |
|---|---|
| 免費(使用 Free Tier) | 需要管理多個 Google 賬號 |
| 配額線性增長 | 違反 Google 服務條款風險 |
| 實現簡單 | Free Tier 配額極低(2-15 RPM) |
| 無需額外成本 | 賬號可能被封禁 |
⚠️ 風險提示: 創建多個 Google 賬號繞過限速可能違反 Google 的服務條款。Google 有權檢測並封禁此類行爲。此方案適合個人學習和測試,不建議用於生產環境。
Gemini 3.1 Pro 429 解決方案二:使用 API 中轉站(推薦)
爲什麼 API 中轉站能解決 429 問題
API 中轉站(如 API易)的核心優勢在於聚合了大量 Gemini API 配額。中轉站在後端維護多個高層級 API 賬戶和項目,通過智能負載均衡將你的請求分發到不同的配額池中。
對於單個開發者而言,你看到的效果就是:不限速、高併發、無 429 報錯。
API 中轉站接入方式
只需修改 base_url,其他代碼完全不變:
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # API易 中轉站
)
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "分析這段代碼的時間複雜度"}]
)
print(response.choices[0].message.content)
查看高併發批量調用示例
import openai
import asyncio
from typing import List
client = openai.AsyncOpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
async def call_gemini(prompt: str) -> str:
"""單次異步調用"""
response = await client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def batch_call(prompts: List[str]) -> List[str]:
"""批量併發調用 - 通過 API易 無 429 限制"""
tasks = [call_gemini(p) for p in prompts]
return await asyncio.gather(*tasks)
# 同時發送 50 個請求 - 不會觸發 429
prompts = [f"問題 {i}: 請解釋快速排序算法" for i in range(50)]
results = asyncio.run(batch_call(prompts))
print(f"成功完成 {len(results)} 個請求")
直連 vs API 中轉站對比
| 對比維度 | Google 直連(Tier 3) | API易 中轉站 |
|---|---|---|
| RPM 限制 | 1,000-4,000 | 不限速 |
| 429 報錯 | 高併發時頻繁 | 極少出現 |
| 解鎖條件 | 累計消費 $1,000 + 30 天 | 註冊即用 |
| 月消費上限 | $20,000-$100,000 | 按量付費無上限 |
| 配置複雜度 | 需要 GCP 項目+計費 | 修改 base_url 即可 |
| 多模型支持 | 僅 Gemini | Claude/GPT/Gemini/Qwen 等 |
🚀 快速開始: 通過 API易 apiyi.com 註冊後獲取 API Key,將代碼中的
base_url改爲https://api.apiyi.com/v1即可立即解除 Gemini 3.1 Pro 的 429 限速問題。
Gemini 3.1 Pro 429 解決方案三:指數退避重試
適用場景
如果你的使用量不大,只是偶爾遇到 429,指數退避重試(Exponential Backoff)是最輕量的解決方案。
實現代碼
import time
import random
import openai
def call_with_backoff(client, prompt, max_retries=5):
"""指數退避重試策略"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
# 指數退避 + 隨機抖動
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"429 限速,等待 {wait:.1f}s 後重試...")
time.sleep(wait)
退避策略說明:
- 第 1 次重試: 等待 ~2 秒
- 第 2 次重試: 等待 ~4 秒
- 第 3 次重試: 等待 ~8 秒
- 第 4 次重試: 等待 ~16 秒
💡 注意: 指數退避只是「等限速過去再試」,不能真正提高吞吐量。如果你需要持續的高併發調用,建議使用方案二(API 中轉站)或方案四(升級 Tier)。
Gemini 3.1 Pro 429 解決方案四:升級 Google API 層級
Tier 升級路徑
Google Gemini API 的層級升級是自動觸發的——達到消費門檻後系統自動升級:
| 當前層級 | 升級到 | 條件 | 生效時間 |
|---|---|---|---|
| Free → Tier 1 | Tier 1 | 開通 GCP 計費 | 即時生效 |
| Tier 1 → Tier 2 | Tier 2 | 累計消費 $100 + 3 天 | 10 分鐘內 |
| Tier 2 → Tier 3 | Tier 3 | 累計消費 $1,000 + 30 天 | 10 分鐘內 |
Ghost 429 Bug 警告
如果你剛從 Free 升級到 Tier 1,在 24-48 小時內可能遇到「Ghost 429」問題——明明使用量很低但仍報 429。這是 Google 已確認的 Bug,配額系統需要時間校準。
臨時解決方法:
- 等待 24-48 小時讓配額系統重新校準
- 切換到其他模型變體(如從 gemini-3.1-pro 切到 gemini-3-pro)
- 使用 API 中轉站繞過此問題
Gemini 3.1 Pro 429 解決方案五:切換模型變體
不同模型的限速差異
如果你不是必須使用 Gemini 3.1 Pro,切換到限速更寬鬆的模型變體也是有效的解決辦法:
| 模型 | 適用場景 | 限速寬鬆度 | 能力水平 |
|---|---|---|---|
| gemini-3.1-pro | 複雜推理、長上下文 | 最嚴格 | 最強 |
| gemini-3.1-flash | 快速響應、日常任務 | 較寬鬆 | 中等偏上 |
| gemini-3-pro | 通用推理 | 中等 | 強 |
| gemini-3.1-flash-lite | 大批量簡單任務 | 最寬鬆 | 基礎 |
🎯 選型建議: 對於大部分開發場景,gemini-3.1-flash 在速度和質量之間有很好的平衡,且限速更寬鬆。如果你需要在同一項目中靈活切換不同模型,通過 API易 apiyi.com 可以用一個 API Key 同時訪問 Gemini、Claude、GPT 等全系模型。

5 種 Gemini 3.1 Pro 429 解決方案總覽
| 方案 | 成本 | 效果 | 複雜度 | 推薦場景 |
|---|---|---|---|---|
| 多賬號輪詢 | 免費 | 中等 | 中 | 個人學習/測試 |
| API 中轉站 | 按量付費 | 最佳 | 最低 | 生產環境/高併發 |
| 指數退避 | 免費 | 低 | 低 | 偶發 429、低頻使用 |
| 升級 Tier | $100-$1,000 | 中高 | 低 | 有預算、中等併發 |
| 切換模型 | 不變 | 中 | 最低 | 非 Pro 模型也能滿足需求 |
常見問題
Q1: 在同一個 Google 項目下創建多個 API Key 能繞過 429 嗎?
不能。Google Gemini API 的限速是按項目(Project)計算的,不是按 API Key 計算的。同一項目下的所有 API Key 共享同一個配額池。要通過 Key 輪詢繞過限速,必須使用來自不同 Google 賬號/不同項目的 Key。不過更推薦使用 API易 apiyi.com 等中轉站方案,無需管理多個賬號即可實現高併發。
Q2: Gemini 3.1 Pro 的 429 報錯中 “retry in 17.6s” 是什麼意思?
這是 Google 告訴你當前配額窗口還需要約 17.6 秒纔會刷新。你可以等待這段時間後重試,但這只是臨時解決。如果你的應用需要持續高頻調用,僅靠等待無法從根本上解決問題。建議使用指數退避策略自動處理重試,或切換到 API 中轉站方案徹底消除限速。
Q3: API 中轉站爲什麼能做到不限速?
API 中轉站(如 API易)在後端維護了多個高 Tier 的 Google Cloud 項目和大量 API 配額。當你的請求到達中轉站時,它會通過智能負載均衡將請求分發到不同的配額池中。對於單個開發者來說,相當於擁有了遠超個人 Tier 限制的總配額。通過 API易 apiyi.com 註冊即可獲取不限速的 Gemini API 接入。
總結
Gemini 3.1 Pro 429 限速報錯的核心解決思路:
- 理解限速機制: 429 是按項目限速,不是按 Key 限速,同項目多 Key 無效
- 多賬號輪詢: 用多個 Google 賬號的 Key 輪詢,適合個人測試但有封號風險
- API 中轉站: 修改 base_url 即可不限速,是生產環境的最佳方案
- 指數退避: 輕量級方案,適合偶發 429 的低頻場景
- 升級 Tier 或切換模型: 從源頭提高配額或降低需求
對於需要穩定、高併發 Gemini 3.1 Pro 調用的開發者,推薦通過 API易 apiyi.com 接入。只需修改一行 base_url,即可獲得不限速的 Gemini API 訪問,同時支持 Claude、GPT 等全系模型的統一調用。
📚 參考資料
-
Google 官方限速文檔: Gemini API Rate Limits
- 鏈接:
ai.google.dev/gemini-api/docs/rate-limits - 說明: 官方限速規則和層級說明
- 鏈接:
-
Google AI 開發者論壇: 429 報錯討論帖
- 鏈接:
discuss.ai.google.dev/t/constant-429-no-capacity-available-for-model-gemini-3-1-pro-preview-on-the-server - 說明: 開發者社區討論和 Google 官方回覆
- 鏈接:
-
Google 官方定價頁: Gemini API 定價和層級
- 鏈接:
ai.google.dev/gemini-api/docs/pricing - 說明: 各層級消費門檻和定價詳情
- 鏈接:
-
Gemini API 錯誤排查指南: 429/400/500 錯誤處理
- 鏈接:
ai.google.dev/gemini-api/docs/troubleshooting - 說明: 官方錯誤排查文檔
- 鏈接:
作者: APIYI 技術團隊
技術交流: 遇到 Gemini API 限速問題歡迎在評論區討論,更多 AI 開發資料可訪問 API易 docs.apiyi.com 文檔中心