При загрузке десятков тысяч строк Excel в инструмент ИИ интерфейс выдает ошибку «недостаточно средств» — но на счету же есть деньги? Это самая распространенная ловушка при использовании ИИ для обработки больших данных Excel, за этим стоят двойные ограничения: механизм предварительного списания токенов и лимит контекстного окна.
Ключевая ценность: Прочитав эту статью, вы полностью поймете, почему большие файлы Excel вызывают ошибки, как правильно анализировать десятки тысяч строк данных с помощью ИИ, и какое решение является наиболее экономичным и эффективным.
<!-- Error response bubble -->
<rect x="0" y="58" width="256" height="84" rx="9" fill="#2d0808" stroke="#ef4444" stroke-width="1.5"/>
<text x="128" y="80" font-family="'PingFang SC',sans-serif" font-size="13" font-weight="bold" fill="#ef4444" text-anchor="middle">❌ Ошибка 402</text>
<text x="128" y="100" font-family="monospace" font-size="10" fill="#fca5a5" text-anchor="middle">Недостаточный баланс</text>
<text x="128" y="116" font-family="'PingFang SC',sans-serif" font-size="10" fill="#fca5a5" text-anchor="middle">Недостаточно средств, пополните баланс и повторите попытку</text>
<text x="128" y="132" font-family="'PingFang SC',sans-serif" font-size="9" fill="#94a3b8" text-anchor="middle">(Удержано $9.00 · Баланс $5.20)</text>
<!-- AI avatar -->
<circle cx="268" cy="100" r="10" fill="#991b1b"/>
<text x="268" y="105" font-family="sans-serif" font-size="11" fill="#fecaca" text-anchor="middle">🤖</text>
<!-- Confused user thought -->
<rect x="40" y="158" width="218" height="50" rx="9" fill="#0f2028"/>
<text x="149" y="178" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">😕 Но у меня же явно есть баланс на счету!</text>
<text x="149" y="196" font-family="'PingFang SC',sans-serif" font-size="10" fill="#7dd3fc" text-anchor="middle">Почему говорится, что недостаточно средств?</text>
<circle cx="28" cy="183" r="10" fill="#1d4ed8"/>
<text x="28" y="188" font-family="sans-serif" font-size="11" fill="#ffffff" text-anchor="middle">👤</text>
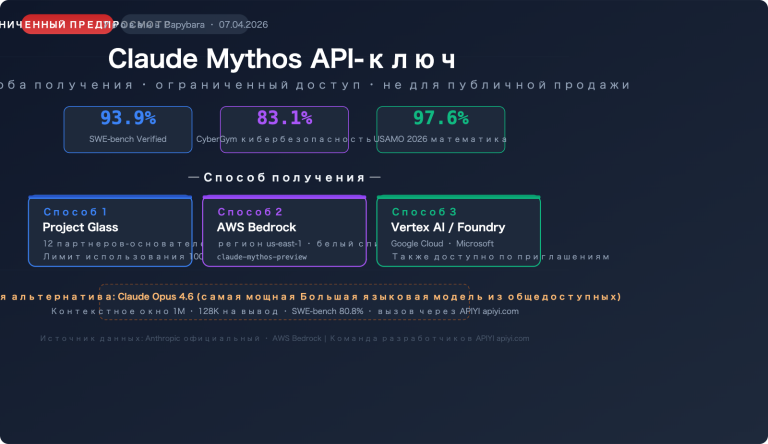
1. Почему при загрузке большого файла Excel появляется ошибка «Недостаточно средств»?
Многие пользователи, впервые столкнувшись с этой проблемой, очень смущены: почему, если на счете достаточно средств, API все равно возвращает ошибку «Недостаточно средств»?
Здесь нужно понять ключевой механизм AI API: механизм предварительного списания токенов.
Подробное описание механизма предварительного списания токенов
Когда вы загружаете файл и отправляете запрос в AI-клиенте, таком как Cherry Studio или Chatbox, API не ждет завершения генерации ответа, чтобы списать средства. В момент отправки запроса он заранее оценивает максимально возможное количество токенов, которое может быть израсходовано, и временно «замораживает» (предварительно списывает) соответствующую сумму с баланса вашего счета.
Этот процесс предварительного списания выглядит примерно так:
- Пользователь загружает файл Excel → клиент преобразует содержимое файла в обычный текст.
- Весь обычный текст помещается в промпт (контекст диалога).
- API рассчитывает количество входных токенов + оценивает максимальное количество выходных токенов.
- Система определяет: общая сумма предварительного списания > баланс счета → возвращает ошибку «Недостаточно средств».
Так что, по сути, дело не в том, что у вас «нет денег», а в том, что сумма предварительного списания для этого запроса слишком велика и превышает текущий баланс вашего счета.
Принципиальные различия между AI-клиентами и ChatGPT
Многие ошибочно полагают, что загрузка Excel в Cherry Studio — это то же самое, что загрузка файла в ChatGPT.
На самом деле это совершенно разные вещи:
| Параметр сравнения | Cherry Studio / Chatbox | ChatGPT (Code Interpreter) |
|---|---|---|
| Способ обработки файлов | Преобразуется в текст и полностью помещается в контекст | Обрабатывается путем выполнения кода в изолированной среде |
| Расход токенов | Размер файла напрямую равен расходу токенов | Не занимает токены контекста диалога |
| Подходящий размер файла | Рекомендуется до 100 строк | Поддерживает большие файлы (официальное ограничение около 512 МБ) |
| Возможности анализа данных | Только понимание текста, не может выполнять код | Может напрямую запускать Python для статистики |
| Способ подключения API | Вызов через API-ключ, оплата по токенам | Подписка ChatGPT Plus |
🎯 Ключевое понимание: При вызове AI через сервис-прокси API (например, APIYI apiyi.com), загрузка файлов происходит через сторонний клиент, и все содержимое файла преобразуется в текстовые токены, которые передаются модели. Это принципиально отличается от официального механизма обработки файлов в изолированной среде ChatGPT.
2. Сколько токенов на самом деле потребляет большой файл Excel?
Прежде чем обсуждать решения, давайте получим наглядное представление о расходе токенов.
Базовые знания о конвертации токенов
| Тип содержимого | Оценка токенов |
|---|---|
| 1 английское слово | около 1-2 токенов |
| 1 английский символ | около 0.25 токена (4 символа = 1 токен) |
| 1 китайский иероглиф | около 1-2 токенов |
| 1 дата (например, 2024-01-15) | около 5 токенов |
| 1 число (например, 12345.67) | около 3-4 токенов |
| 1 строка данных Excel (10 столбцов) | около 30-80 токенов |
Расчет на реальных примерах
Рассмотрим реальные сценарии, с которыми сталкиваются пользователи:
Файл A: Данные об эффективности процессов, 60 000 строк × 10 столбцов
Оценка: 60 000 строк × 10 столбцов × в среднем 5 токенов/ячейка
= 60 000 × 50
= 3 000 000 токенов (около 3 миллионов токенов!)
Файл B: Бизнес-данные, 40 000 строк × 8 столбцов
Оценка: 40 000 строк × 8 столбцов × в среднем 5 токенов/ячейка
= 40 000 × 40
= 1 600 000 токенов (около 1,6 миллиона токенов)
Сравнение контекстных окон и стоимости для различных моделей
| Модель | Контекстное окно | Цена за вход (за 1 млн токенов) | Стоимость обработки 3 млн токенов |
|---|---|---|---|
| GPT-4o | 128K токенов | $2.50 | Невозможно обработать (превышение лимита) |
| Claude 3.5 Sonnet | 200K токенов | $3.00 | Невозможно обработать (превышение лимита) |
| Gemini 1.5 Pro | 1M токенов | $1.25 | Невозможно обработать (превышение лимита) |
| Gemini 1.5 Pro 2.0 | 2M токенов | $1.25 | около $3.75/запрос |
💡 Как видно, контекстное окно большинства моделей просто не вмещает 60 000 строк Excel. Даже если использовать модель Gemini с контекстом в 2M токенов, каждый запрос будет стоить около $3.75.
3. Четыре правильных способа обработки больших данных Excel с помощью ИИ
Разобравшись с основными причинами, давайте рассмотрим 4 проверенных решения, отсортированных по степени рекомендации.
<line x1="0" y1="56" x2="194" y2="56" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#34d399">Шаги операции</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="93" font-size="9.5" fill="#6ee7b7">① Извлечь 10 строк выборочных данных для ИИ</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="115" font-size="9.5" fill="#6ee7b7">AI понимает структуру, генерирует аналитические скрипты</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#022c22"/>
<text x="8" y="137" font-size="9.5" fill="#6ee7b7">③ Запустите скрипт локально для обработки всех данных</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#059669" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#34d399">Сценарии применения</text>
<text x="0" y="186" font-size="10" fill="#a7f3d0">Количество данных > 10 000 строк</text>
<text x="0" y="200" font-size="10" fill="#a7f3d0">Статистический анализ / Генерация отчетов</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#065f46" stroke="#10b981" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#34d399" text-anchor="middle">Расход токенов: < 2,000</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#93c5fd">Порядок действий</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="93" font-size="9.5" fill="#93c5fd">① Разделить на несколько подфайлов построчно</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="115" font-size="9.5" fill="#93c5fd">② Циклический вызов API для обработки каждой партии</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#1e3a5f"/>
<text x="8" y="137" font-size="9.5" fill="#93c5fd">③ Суммировать результаты по каждой партии</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#3b82f6" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#93c5fd">Сценарии применения</text>
<text x="0" y="186" font-size="10" fill="#bfdbfe">5000-20000 строк данных</text>
<text x="0" y="200" font-size="10" fill="#bfdbfe">Построчная классификация / Анализ настроений</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#1e3a5f" stroke="#3b82f6" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#93c5fd" text-anchor="middle">Общая стоимость около $0.5-1.5</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#d8b4fe">Порядок действий</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="93" font-size="9.5" fill="#d8b4fe">Сводная таблица Excel выполняет агрегированную статистику</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="115" font-size="9.5" fill="#d8b4fe">② Отправить сводные данные (несколько десятков строк) ИИ</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#3b0764"/>
<text x="8" y="137" font-size="9.5" fill="#d8b4fe">③ ИИ для написания аналитических отчетов и инсайтов</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#a855f7" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#d8b4fe">Сценарии применения</text>
<text x="0" y="186" font-size="10" fill="#e9d5ff">Требуется отчет по анализу общих тенденций.</text>
<text x="0" y="200" font-size="10" fill="#e9d5ff">Не нужно построчно понимать исходные данные</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#3b0764" stroke="#a855f7" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#d8b4fe" text-anchor="middle">Расход токенов: крайне мал</text>
<line x1="0" y1="56" x2="194" y2="56" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="74" font-size="11" font-weight="bold" fill="#fdba74">Рекомендовать модель</text>
<rect x="0" y="80" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="93" font-size="9.5" fill="#fdba74">Gemini 2.0 Flash (1M контекстное окно)</text>
<rect x="0" y="102" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="115" font-size="9.5" fill="#fdba74">Gemini 1.5 Pro (1M контекстное окно)</text>
<rect x="0" y="124" width="194" height="18" rx="4" fill="#431407"/>
<text x="8" y="137" font-size="9.5" fill="#fdba74">Claude 3.5 Sonnet(200K)</text>
<line x1="0" y1="152" x2="194" y2="152" stroke="#f97316" stroke-width="1" opacity="0.5"/>
<text x="0" y="170" font-size="11" font-weight="bold" fill="#fdba74">Сценарии применения</text>
<text x="0" y="186" font-size="10" fill="#fed7aa">Объем данных < 5000 строк</text>
<text x="0" y="200" font-size="10" fill="#fed7aa">может позволить себе более высокие расходы на API</text>
<rect x="0" y="214" width="194" height="26" rx="6" fill="#431407" stroke="#f97316" stroke-width="1.5"/>
<text x="97" y="231" font-size="11" font-weight="bold" fill="#fdba74" text-anchor="middle">Стоимость: $1-5 / за раз</text>
Вариант A (настоятельно рекомендуется): Выборочные данные + ИИ пишет скрипт
Основная идея: Не давать ИИ обрабатывать все данные напрямую, а позволить ему понять структуру данных и сгенерировать скрипт для локального выполнения.
Шаги:
Шаг 1: Извлечение выборочных данных (достаточно 10 строк)
import pandas as pd
# Читаем первые 10 строк как образец (включая заголовки)
df_sample = pd.read_excel("your_data.xlsx", nrows=10)
# Выводим в текстовом формате для удобства копирования в ИИ
print(df_sample.to_string())
print("\n--- Данные в общих чертах ---")
print(f"Общее количество строк: {len(pd.read_excel('your_data.xlsx'))}")
print(f"Имена столбцов: {list(df_sample.columns)}")
print(f"Типы данных:\n{df_sample.dtypes}")
Шаг 2: Отправка выборочных данных и требований ИИ
Пример промпта:
Ниже приведены 10 строк выборочных данных из моего файла Excel и описание структуры:
[Вставьте вывод предыдущего шага]
Всего данных 60 000 строк. Мне нужно проанализировать следующее:
1. Статистика коэффициента завершения процессов по отделам
2. Найти узлы процесса, где среднее время обработки превышает 2 часа
3. Сгенерировать еженедельный отчет о тенденциях
Пожалуйста, напишите мне скрипт на Python, который прочитает все данные и выведет результаты анализа.
Шаг 3: Запуск сгенерированного ИИ скрипта локально
ИИ, основываясь на ваших 10 строках выборочных данных, поймет значения полей и сгенерирует полный аналитический скрипт. Вы запускаете этот скрипт локально для обработки всех 60 000 строк данных. Весь процесс больше не требует вызова API ИИ, потребление токенов равно нулю.
Преимущества решения:
- Крайне низкое потребление токенов (всего 10 строк образца ≈ несколько сотен токенов)
- Локальный скрипт можно запускать многократно; после обновления данных просто перезапустите его.
- Подходит для сценариев, где требуется регулярная обработка однотипных данных.
🎯 Рекомендуемые инструменты: Используйте APIYI apiyi.com для вызова Claude 3.5 Sonnet или GPT-4o для генерации скриптов обработки данных. Эти модели отлично справляются с задачами генерации кода, а стоимость одного запроса обычно не превышает 2000 токенов, что очень дешево.
Вариант B: Пакетная обработка данных
Сценарий применения: Количество строк данных от 5 000 до 20 000, и ИИ должен понимать содержимое каждой строки (например, для анализа настроений, классификации текста).
Шаги:
import pandas as pd
def process_in_batches(file_path, batch_size=500):
"""Обрабатывает большой файл Excel партиями"""
df = pd.read_excel(file_path)
total_rows = len(df)
results = []
for start in range(0, total_rows, batch_size):
end = min(start + batch_size, total_rows)
batch = df.iloc[start:end]
# Преобразуем эту партию данных в CSV-текст и передаем ИИ для обработки
batch_text = batch.to_csv(index=False)
print(f"Обрабатывается строка {start+1}-{end} (всего {total_rows} строк)")
# Здесь вызываем API ИИ для обработки batch_text
# result = call_ai_api(batch_text)
# results.append(result)
return results
Каждая партия из 500 строк потребляет примерно 25 000-40 000 токенов. Общая стоимость обработки 60 000 строк данных с помощью GPT-4o mini составит около $0.5-1.5.
Важные примечания:
- После обработки каждой партии необходимо агрегировать результаты, обращая внимание на точность статистики между партиями.
- Пакетная обработка может привести к потере межстрочных связей, поэтому она подходит для задач, где строки независимы друг от друга.
Вариант C: Предварительная обработка данных перед загрузкой
Сценарий применения: ИИ нужен для анализа общих тенденций и написания аналитических отчетов, но ему не нужно видеть каждую строку исходных данных.
Шаги:
Шаг 1: Создание сводки данных с помощью сводных таблиц Excel или Python
import pandas as pd
df = pd.read_excel("data.xlsx")
# Генерируем сводную статистику
summary = {
"Общее количество строк": len(df),
"Временной диапазон": f"{df['日期'].min()} 至 {df['日期'].max()}",
"Статистика по отделам": df.groupby('部门')['完成率'].mean().to_dict(),
"Ежемесячные тенденции": df.groupby(df['日期'].dt.month)['处理时长'].mean().to_dict(),
"Количество аномальных данных": len(df[df['处理时长'] > 120])
}
# Преобразуем сводку в структурированный текст и передаем ИИ для написания аналитического отчета
import json
print(json.dumps(summary, ensure_ascii=False, indent=2))
Шаг 2: Передача сводных данных ИИ для написания аналитического отчета
Сводные данные обычно состоят всего из нескольких сотен строк, их передача ИИ практически не потребляет токенов, но позволяет ИИ генерировать полные отчеты об анализе тенденций и бизнес-инсайтах.
Вариант D: Выбор модели с большим контекстным окном
Сценарий применения: Действительно необходимо, чтобы ИИ понимал семантическое содержание всех данных, и вы готовы нести более высокие расходы.
| Модель | Макс. контекст | Подходящий объем данных | Примерная стоимость |
|---|---|---|---|
| Gemini 1.5 Pro | 1 млн токенов | Около 20-30 тыс. строк | Оплата по факту использования через APIYI |
| Gemini 2.0 Flash | 1 млн токенов | Около 20-30 тыс. строк | Высокое соотношение цена/качество |
| Claude 3.5 Sonnet | 200 тыс. токенов | Около 3000-5000 строк | Отличное качество генерации кода |
💡 Даже при использовании моделей с очень большим контекстным окном настоятельно рекомендуется сначала очистить данные (удалить пустые строки, объединить повторяющиеся столбцы, удалить нерелевантные поля), чтобы уменьшить потребление токенов и избежать превышения лимитов предварительной оплаты.
🎯 Преимущество единого интерфейса: Через платформу APIYI apiyi.com вы можете использовать единый API-интерфейс для вызова различных Больших языковых моделей с большим контекстным окном, таких как Gemini, Claude, GPT. Это избавляет от необходимости регистрировать отдельный аккаунт для каждой модели, упрощает быстрое переключение и сравнение затрат.
IV. Как избежать повторных ошибок
После освоения вышеуказанных решений, вот несколько лучших практик для повседневной работы с данными с помощью ИИ.
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#ef4444"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#2d1414" stroke="#ef4444" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#fca5a5">📊 Резкий рост количества токенов: ≈ 3 млн токенов</text>
<text x="22" y="86" font-size="10" fill="#ef4444">60 000 строк × 10 столбцов × 5 токенов ≈ 3 000 000 токенов</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#ef4444" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#ef4444"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#3d0808" stroke="#dc2626" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#ff6b6b">💥 API ошибка 402: недостаточно средств</text>
<text x="22" y="142" font-size="10" fill="#fca5a5">Сумма к списанию $9.00 > Баланс счета $5.20 → Запрос не выполнен</text>
<!-- Problem stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Потребление токенов</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#ef4444" text-anchor="middle">3 миллиона</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#1a0505" stroke="#ef4444" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#fca5a5" text-anchor="middle">Анализ результатов</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#ef4444" text-anchor="middle">Невозможно завершить</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#2d0808" stroke="#dc2626" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#ff6b6b" text-anchor="middle">Ориентировочная стоимость: $7.5+ · и превышает лимит контекстного окна</text>
<!-- Arrow -->
<line x1="182" y1="38" x2="182" y2="52" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,50 188,50 182,56" fill="#10b981"/>
<!-- Step 2 -->
<rect x="0" y="56" width="364" height="38" rx="7" fill="#022c22" stroke="#10b981" stroke-width="1"/>
<text x="22" y="70" font-size="11" font-weight="bold" fill="#6ee7b7">🤖 ИИ понимает структуру, генерирует аналитические скрипты Python</text>
<text x="22" y="86" font-size="10" fill="#34d399">Потребляет около 1500-2000 токенов для завершения генерации скрипта.</text>
<!-- Arrow -->
<line x1="182" y1="94" x2="182" y2="108" stroke="#10b981" stroke-width="1.5" stroke-dasharray="4,3"/>
<polygon points="176,106 188,106 182,112" fill="#10b981"/>
<!-- Step 3 -->
<rect x="0" y="112" width="364" height="38" rx="7" fill="#064e3b" stroke="#059669" stroke-width="2"/>
<text x="22" y="126" font-size="12" font-weight="bold" fill="#34d399">🚀 Запустить скрипт локально, обработать все 60 тысяч строк данных</text>
<text x="22" y="142" font-size="10" fill="#a7f3d0">Скрипт выполняется локально, результаты сохраняются в analysis.xlsx</text>
<!-- Success stats -->
<rect x="0" y="162" width="174" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="87" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Потребление токенов</text>
<text x="87" y="202" font-size="22" font-weight="bold" fill="#34d399" text-anchor="middle">~2000</text>
<rect x="186" y="162" width="178" height="54" rx="7" fill="#021a0d" stroke="#10b981" stroke-width="1"/>
<text x="275" y="180" font-size="10" fill="#6ee7b7" text-anchor="middle">Анализ результатов</text>
<text x="275" y="202" font-size="18" font-weight="bold" fill="#34d399" text-anchor="middle">✅ Полный и точный</text>
<!-- Cost label -->
<rect x="0" y="228" width="364" height="28" rx="6" fill="#064e3b" stroke="#059669" stroke-width="1.5"/>
<text x="182" y="246" font-size="12" font-weight="bold" fill="#34d399" text-anchor="middle">Фактическая стоимость: < 0,01 $ · Скрипт можно многократно использовать повторно</text>
Метод оценки токенов перед использованием
Перед загрузкой файла вы можете быстро оценить количество токенов следующим образом:
import pandas as pd
def estimate_tokens(file_path):
"""Приблизительная оценка количества токенов после преобразования файла Excel в текст"""
df = pd.read_excel(file_path)
# Преобразуем данные в CSV-текст
csv_text = df.to_csv(index=False)
# Приблизительная оценка: английский около 4 символов/токен, китайский около 1.5 символов/токен
char_count = len(csv_text)
estimated_tokens = char_count / 3.5 # Берем среднее для смешанного англо-китайского текста
print(f"Количество строк в файле: {len(df)}")
print(f"Количество столбцов в файле: {len(df.columns)}")
print(f"Количество символов в CSV: {char_count:,}")
print(f"Приблизительное количество токенов: {estimated_tokens:,.0f}")
print(f"Расчетная стоимость для GPT-4o ($2.5/1M): ${estimated_tokens/1_000_000*2.5:.4f}")
if estimated_tokens > 100_000:
print("⚠️ Внимание: Количество токенов превышает 100 тысяч, рекомендуется использовать подход A (выборка + скрипт)")
estimate_tokens("your_data.xlsx")
Таблица распространенных ошибок и их решений
| Ошибка | Основная причина | Решение |
|---|---|---|
| Сообщение «Недостаточно средств», но баланс есть | Предварительное списание токенов превышает баланс счета | Пополнить баланс или использовать подход A/C |
| Очень медленный отклик или таймаут | Слишком много входных токенов, длительное время инференса | Уменьшить объем входных данных |
| Неточные результаты анализа ИИ | Слишком большой объем данных, эффект "lost-in-the-middle" | Оптимизировать данные, использовать пакетную обработку |
| Интерфейс сообщает "context length exceeded" | Превышено максимальное контекстное окно модели | Использовать модель с большим контекстным окном или пакетную обработку |
| Очень высокая стоимость каждого вызова | Многократная загрузка больших объемов данных | Использовать подход A для генерации многоразового локального скрипта |
V. Практический пример: анализ 60 000 строк данных о процессах
Ниже представлен полный бизнес-кейс, демонстрирующий весь процесс — от обнаружения проблем до их решения.
Предыстория: У операционной команды есть файл с 60 000 строками данных об эффективности процессов, включающий такие поля, как: отдел, название процесса, время начала, время окончания, исполнитель, статус завершения. Необходимо, чтобы AI проанализировал, какие узлы процесса наименее эффективны.
Шаг 1: Извлечение образца данных
import pandas as pd
# Читаем первые 10 строк
df = pd.read_excel("process_data.xlsx", nrows=10)
print("=== Образец данных (первые 10 строк) ===")
print(df.to_string())
print("\n=== Описание полей ===")
for col in df.columns:
print(f"- {col}: {df[col].dtype}, Пример значения: {df[col].iloc[0]}")
Шаг 2: Отправка данных AI для получения скрипта анализа
Отправьте приведенный выше вывод AI, добавив описание задачи:
Ниже представлена структура и 10 строк образца моих данных Excel по процессам:
[Вставьте вывод]
Задача:
1. Вычислить среднее время обработки (время окончания - время начала) для каждого «названия процесса».
2. Статистика процента завершения процессов по отделам (доля процессов со статусом "Завершено").
3. Найти 10 процессов с самым высоким средним временем обработки и вывести их в виде таблицы.
4. Сохранить результаты в файл analysis_result.xlsx.
Пожалуйста, напишите полный, рабочий Python-скрипт.
Шаг 3: Запуск скрипта локально
AI сгенерирует скрипт анализа, похожий на следующий (упрощенная версия):
import pandas as pd
# Читаем полные данные
df = pd.read_excel("process_data.xlsx")
# Вычисляем время обработки (в минутах)
df['处理时长_分钟'] = (
pd.to_datetime(df['结束时间']) - pd.to_datetime(df['开始时间'])
).dt.total_seconds() / 60
# Статистика среднего времени по процессам
process_avg = (
df.groupby('流程名称')['处理时长_分钟']
.agg(['mean', 'count'])
.rename(columns={'mean': '平均时长', 'count': '总次数'})
.sort_values('平均时长', ascending=False)
)
# Статистика процента завершения по отделам
dept_completion = (
df.groupby('部门')['完成状态']
.apply(lambda x: (x == '完成').mean() * 100)
.round(2)
.rename('完成率%')
)
# Выводим 10 самых медленных процессов
print("=== 耗时最长的10个流程节点 ===")
print(process_avg.head(10).to_string())
# Сохраняем результаты
with pd.ExcelWriter("analysis_result.xlsx") as writer:
process_avg.to_excel(writer, sheet_name="流程效率分析")
dept_completion.to_excel(writer, sheet_name="部门完成率")
print("\n✅ Результаты анализа сохранены в analysis_result.xlsx")
Сравнение расхода токенов для всего процесса:
| Метод | Расход токенов | Примерная стоимость (GPT-4o) | Качество анализа |
|---|---|---|---|
| Прямая загрузка 60 тыс. строк | ~3 млн токенов | $7.5+ и превышение контекстного окна | Невозможно выполнить |
| Вариант А (выборка + скрипт) | ~2000 токенов | < $0.01 | Полный и точный |
🎯 Сравнение стоимости: Расход токенов по варианту А составляет менее 0.1% от расхода при прямой загрузке, а результаты анализа более точные и многоразовые. Рекомендуем использовать APIYI (apiyi.com) для вызова GPT-4o или Claude 3.5 Sonnet для генерации скриптов обработки данных — это эффективно и очень недорого.
VI. Часто задаваемые вопросы (FAQ)
Q1: У меня нет опыта работы с Python, могу ли я использовать это решение?
Конечно, можете. Суть варианта А в том, чтобы «AI написал скрипт, а вы его запустили». Вам нужно всего лишь:
- Установить Python (официальный сайт: python.org, просто следуйте инструкциям).
- Установить pandas: введите в терминале
pip install pandas openpyxl. - Извлечь образец данных и отправить AI → AI сгенерирует скрипт → сохранить его как файл
.py→ запустить двойным щелчком.
Для пользователей, не знакомых с командной строкой, можно также использовать Jupyter Notebook (входит в установочный пакет Anaconda), что более наглядно.
💡 На APIYI (apiyi.com) вы также можете использовать встроенный интерпретатор кода, чтобы AI напрямую генерировал и проверял логику скриптов, сокращая время отладки.
Q2: Помимо Python, есть ли другие способы обработки больших данных?
Да, есть несколько способов, отсортированных по простоте использования:
- Встроенные функции Excel: сводные таблицы + Power Query, не требуют программирования, подходят для агрегированной статистики.
- Python pandas: наиболее гибкий, высокая эффективность обработки, рекомендуется для пользователей среднего и продвинутого уровня.
- Microsoft Copilot (плагин для Excel): прямой диалог с AI для анализа в Excel, но все еще имеет ограничения по количеству строк.
- Профессиональные инструменты анализа данных: Tableau, Power BI подключаются к источникам данных, обладают мощными возможностями обработки больших данных.
Q3: Какой баланс на счете достаточен, чтобы избежать ошибок из-за предварительной блокировки средств?
Это зависит от вашего повседневного использования. Обычно рекомендуется:
- Обычные пользователи для диалогов: поддерживать баланс $5-20.
- Пользователи для обработки данных (иногда загружающие файлы): поддерживать баланс $20-50.
- Частые вызовы API: рекомендуется настроить автопополнение или поддерживать баланс $100+.
🎯 Управление балансом: В консоли APIYI (apiyi.com) вы можете просматривать детализацию расхода токенов, настраивать уведомления о расходе, чтобы избежать влияния недостаточного баланса на вашу работу. Платформа поддерживает пополнение по мере необходимости, без требований к минимальному расходу.
Q4: Мои данные содержат конфиденциальную информацию, можно ли отправлять образцы данных AI?
Разумные подходы:
- Деперсонализировать перед отправкой AI: Замените конфиденциальные поля, такие как имена, номера телефонов, идентификационные номера, на примеры значений (например, «Иван Иванов» → «Пользователь А»).
- Предоставлять только названия полей и типы данных: Не предоставлять конкретные значения, а только структуру полей и их типы данных.
- Решение с локальной моделью: Использовать Ollama для запуска локальных моделей (например, Qwen2.5), при этом данные полностью не покидают ваш компьютер.
Резюме
Самая распространённая ошибка при обработке больших данных Excel с помощью ИИ — это прямая загрузка всего файла, что приводит к переполнению токенов, ошибкам интерфейса и неконтролируемым расходам. Основная идея решения проста:
Пусть ИИ «смотрит на образец, пишет скрипт», а не «смотрит на весь объём, выполняет вычисления».
Обзор сценариев применения четырёх решений:
| Сценарий | Рекомендуемое решение | Сложность |
|---|---|---|
| Объём данных > 10 тыс. строк, требуется статистический анализ | Решение A: Образец + скрипт | ⭐⭐ (требуется запуск Python) |
| Объём данных 5-20 тыс. строк, требуется построчное понимание | Решение B: Пакетная обработка | ⭐⭐⭐ (требуется вызов API) |
| Требуется только отчёт о тенденциях, построчный анализ не нужен | Решение C: Предварительная обработка и резюмирование | ⭐ (достаточно Excel) |
| Объём данных < 5 тыс. строк, готовы к высоким расходам | Решение D: Большая языковая модель с большим контекстным окном | ⭐ (прямая загрузка) |
Попробуйте решение A прямо сейчас: извлеките первые 10 строк вашего Excel-файла, выберите GPT-4o или Claude 3.5 Sonnet на APIYI apiyi.com, сообщите ИИ ваши аналитические потребности, и пусть он сгенерирует скрипт для обработки — большинство задач по анализу данных можно решить менее чем за $0.01.
🎯 Быстрый старт: Посетите APIYI apiyi.com, зарегистрируйтесь и опробуйте различные популярные модели. Поддерживается унифицированный вызов API для OpenAI, Claude, Gemini и других, оплата по факту использования, без ежемесячной платы и минимального потребления. Подходит для бизнес-команд и индивидуальных пользователей для решения различных задач по анализу данных.
Эта статья подготовлена технической командой APIYI на основе реальных отзывов пользователей и практического опыта. Если у вас есть вопросы или предложения, свяжитесь с нами через apiyi.com.