Недавно получил типичный запрос: пользователь хочет «дистиллировать» сотни тысяч слов текстов талантливого автора, чтобы обучить большую языковую модель его стилю, но не знает, как наиболее выгодно «скормить» ей Markdown-материалы. Обычно рассматривают три пути: загружать файлы по одному в инструменты для чата вроде Cherry Studio, использовать MCP для прямого доступа модели к файлам на диске или закинуть всё в базу знаний для RAG. На первый взгляд, всё это работает, но когда объем данных превышает 300 тысяч слов, счета за токены и задержки начинают резко расти, и неверный выбор может стоить в десять раз дороже.
В этой статье мы разберем четыре основных способа подачи Markdown-материалов в большую языковую модель с точки зрения экономии токенов: реальный расход, стоимость одной задачи, задержка до получения первого токена, управляемость и оптимальный выбор для разных объемов данных. В конце я предложу пошаговый план принятия решений: что использовать на этапе экспериментов, а на что переходить при масштабировании. Если вы занимаетесь дистилляцией стиля, созданием базы знаний или очисткой данных перед дообучением, этот материал поможет вам сразу выбрать правильный инструмент.
I. Основная проблема экономии токенов при работе с Markdown-материалами
Прежде чем разбирать варианты, давайте проясним, где именно скрываются основные расходы. Подача сотен тысяч слов в Markdown в большую языковую модель — это балансировка между четырьмя типами затрат: входными токенами, выходными токенами, стоимостью индексации/поиска и трудозатратами на настройку.
Входные токены — это то, что недооценивают чаще всего. Если технический блог представлен в исходном HTML, преобразование его в Markdown обычно экономит 70–80% токенов, так как удаляются теги, стили и встроенные скрипты. Именно поэтому первый этап любого конвейера обработки больших объемов данных — приведение контента к единому формату Markdown или TXT. Если сделать это качественно, базовая стоимость любого способа подачи данных сразу снизится на порядок.
Выходные токены кажутся не столь важными, но в задачах «дистилляции» они становятся скрытым «бутылочным горлышком». Claude Sonnet и Opus уже сделали контекстное окно в 1 миллион токенов стандартным (вход Sonnet — $3/млн, Opus — $5/млн). Теоретически можно загрузить сотни тысяч слов за раз, но максимальный объем ответа за один вызов модели всё равно ограничен несколькими десятками тысяч токенов. Это значит, что вы не сможете выполнить полную переработку текста за один запрос. Задачу придется разбивать на части, что делает пакетную обработку скриптами гораздо более подходящей для масштабируемых сценариев, чем интерактивный чат.
🎯 Совет перед выбором: Прежде чем выбирать метод, выполните десенсибилизацию и нормализацию всех Markdown-файлов. Мы рекомендуем сначала протестировать небольшие выборки через платформу APIYI (apiyi.com), чтобы подтвердить реальный расход токенов на тысячу знаков. Только после этого решайте, использовать ли инструменты для чата или пакетные скрипты, чтобы избежать неконтролируемых расходов в будущем.
二、4 种方案的核心差异与适用边界
这四种方案各有各的“地盘”,理解它们的能力边界,比死记硬背参数要管用得多。
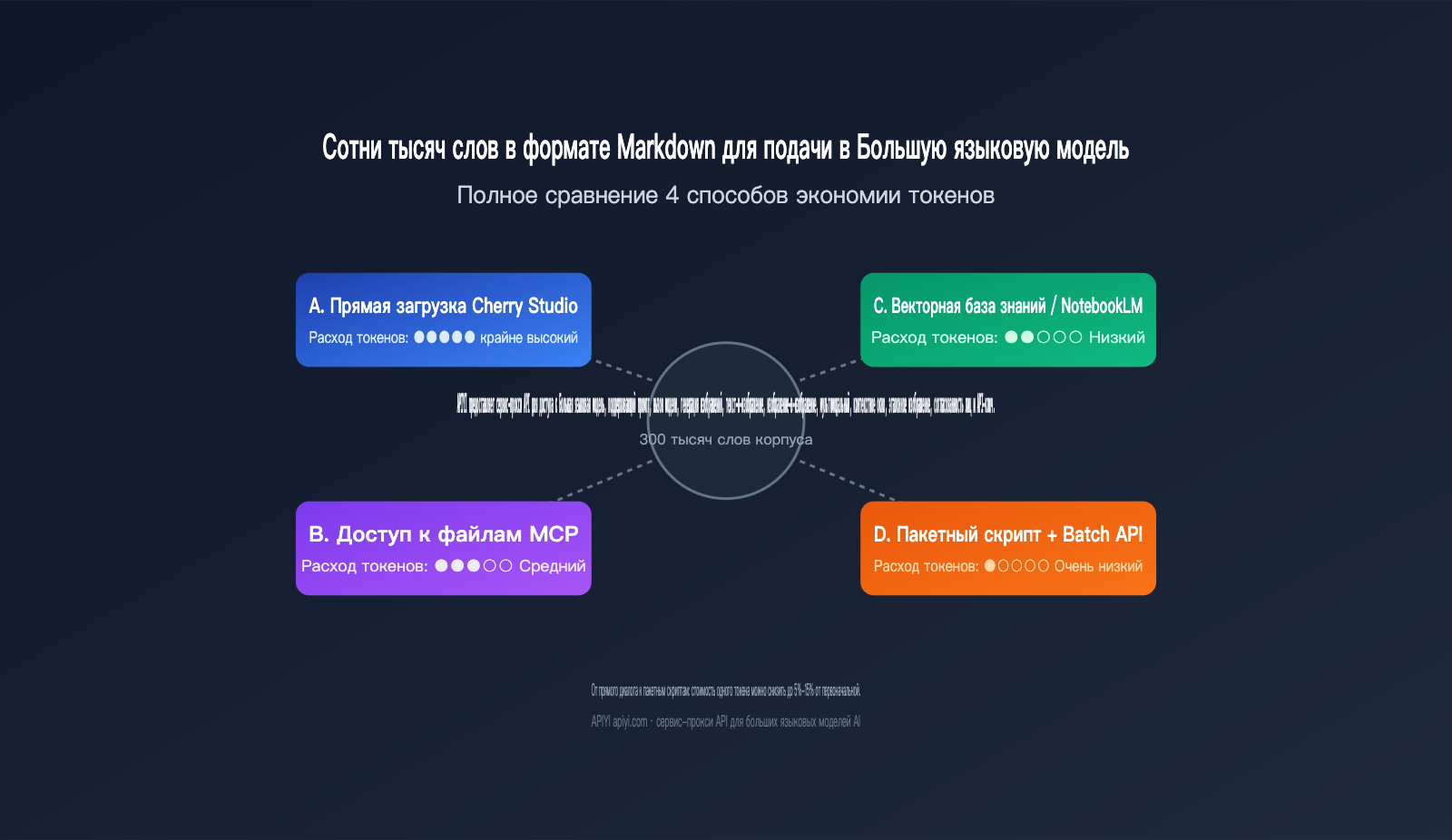
2.1 方案 A:Cherry Studio 等对话工具直接上传
这是门槛最低的玩法。Cherry Studio、Claude Desktop 或 ChatGPT 这类工具允许你直接把一堆 Markdown 文件拖进对话框,模型会自动把所有内容拼成一个超长的提示词来处理。优点是零工程量、所见即所得;缺点是每开一个新会话都要重新“喂”一遍,Token 消耗严重,而且单次能处理的文件量受限于上下文窗口。
对于 5 万字以内的小任务,这种方式效率最高,因为你可以一边调一边看效果。但语料一旦超过 20 万字,就会频繁遇到上下文截断、长上下文延迟(首 Token 响应可能要等 20-30 秒)以及重复扣费的问题。
2.2 方案 B:MCP 直连本地文件
MCP (Model Context Protocol) 让模型能像调用工具一样去读取你硬盘上的文件。听起来很优雅:模型按需调用,不需要全量加载。但实测下来,MCP 的 Token 消耗经常被低估——一次工具调用返回的 JSON 哪怕你只用得到 3 个字段,完整结构都会进入上下文。关键词匹配模式比向量检索多消耗约 3 倍 Token。
MCP 的真正强项在于动态变化的数据源,比如实时日志、用户私有数据,或是必须保存在本地的财务数据。对于“几十万字静态 Markdown”这种典型场景,用 MCP 有点杀鸡用牛刀,而且容易在多轮调用中把上下文窗口提前耗光。
2.3 方案 C:向量化知识库 / NotebookLM
把所有文件切片、嵌入、入库,通过语义检索按需调用相关片段,这就是 RAG(检索增强生成)路线。一个设计良好的 RAG 流水线每次查询只检索 5-20 个数据块(chunk),通常合计 2000-10000 Token,相比全量加载能省下 50-200 倍的输入 Token。
NotebookLM 是 Google 提供的开箱即用 RAG 产品,自动处理嵌入、检索和引用,非常适合写作风格分析、文献综述、笔记问答等读取类任务。它的局限是回答仅基于源文件,不会主动联想训练数据,且自定义程度有限。如果你需要复杂的检索策略或多步推理,自己搭建一套向量知识库会更灵活。
🎯 方案 C 落地提醒:向量知识库的检索质量直接决定输出质量,chunk 切分、embedding 模型、检索 top-k 等参数都要根据语料进行调优。我们建议在 APIYI (apiyi.com) 平台先用 Claude 或 GPT 跑一次小规模评测,对比不同检索参数下的回答准确率,再决定是直接用 NotebookLM 还是自建系统。
2.4 方案 D:AI 写批处理脚本(规模化最优解)
这是之前提到的方案中最推荐的一种:让 AI 帮你写一段批处理脚本,先用大模型处理 5-10 篇样本数据,人工或自动识别出可复用的规律(比如句式模板、段落结构、关键词分布),然后把规律固化进代码,让代码去处理剩余的几十万字,大模型只在关键节点介入。
这本质上是“规则下沉”:大模型用来发现模式,代码负责批量执行。配合 Claude/GPT 的 Batch API(通常有 50% 折扣),整体成本通常只有方案 A 的 5%-15%。劣势是前期需要 1-2 天的工程投入,不适合一次性任务。
三、Сравнение потребления токенов и стоимости для 4 подходов
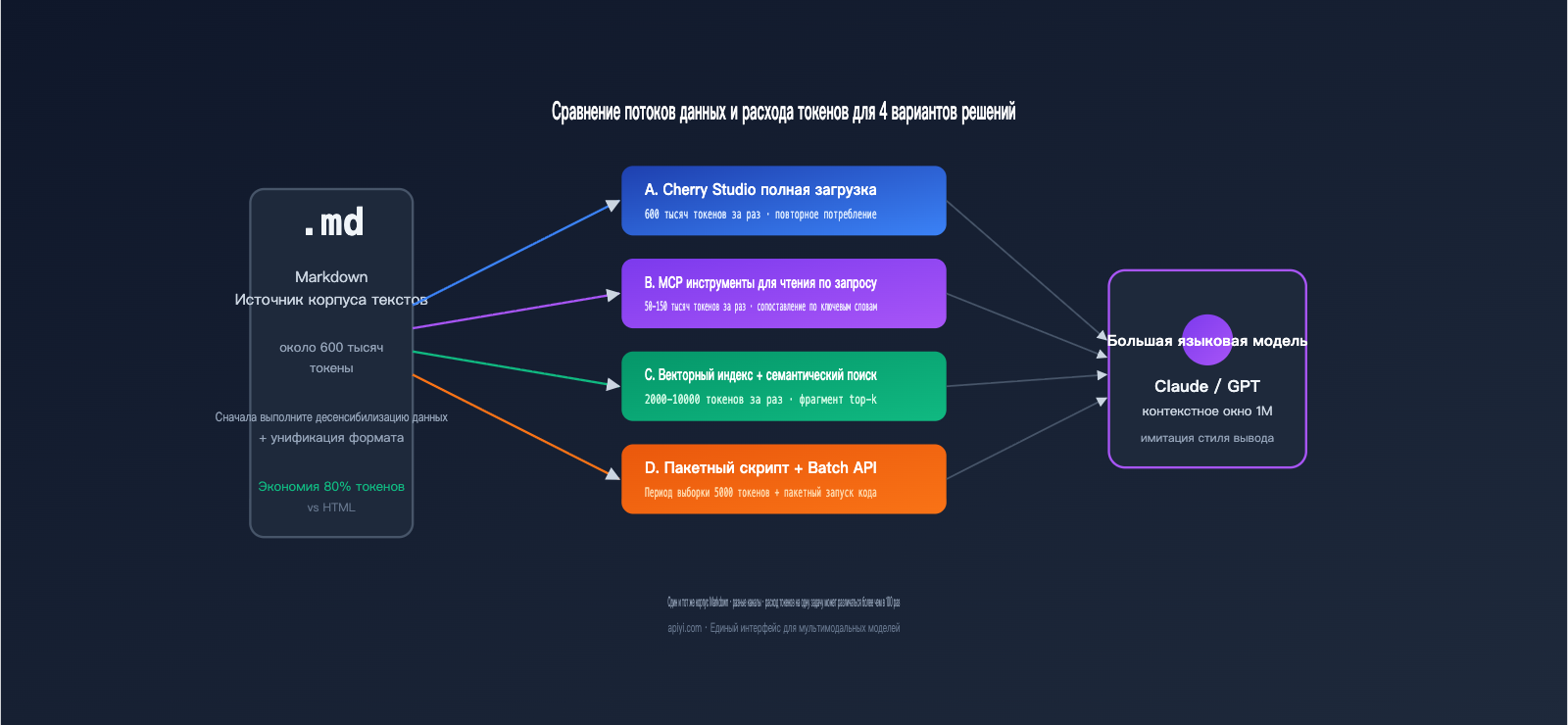
Чтобы понять реальную разницу, нужно перевести абстрактные понятия в цифры. В таблице ниже приведено сравнение для конкретного сценария: пользователю нужно обработать 300 000 слов в формате Markdown (около 600 000 токенов) и сгенерировать 100 статей в заданном стиле (по 2000 слов каждая).
| Подход | Входные токены (за раз) | Всего входных токенов | Всего выходных токенов | Оценка стоимости (Sonnet) | Задержка первого токена |
|---|---|---|---|---|---|
| A. Прямая передача в чат | 600 тыс. | 60 млн (100 раз) | 6 млн | ≈ $270 | 20-30 сек |
| B. Доступ к файлам через MCP | 50-150 тыс. (частями) | 15 млн | 6 млн | ≈ $135 | 8-15 сек |
| C. Векторная база знаний | 5-10 тыс. | 1 млн | 6 млн | ≈ $93 | 1-2 сек |
| D. Скрипт пакетной обработки + Batch API | 5 тыс. (семпл) + обработка кода | 1 млн | 6 млн | ≈ $46 | Асинхронно |
Как видите, стоимость подхода D составляет всего около 17% от подхода A, при этом задержка наиболее стабильна. Если добавить 50% скидку на Batch API, реальные затраты на вариант D можно сократить еще вдвое. После того как Claude 1M context ввел стандартное ценообразование для длинного контекста, подход A перестал стоить в 2 раза дороже, но проблема избыточного повторного ввода одних и тех же данных осталась — это «ахиллесова пята» всех диалоговых рабочих процессов.
🎯 Совет по проверке расходов: Приведенные выше цифры основаны на публичных тарифах. Реальные значения могут колебаться на 30-50% в зависимости от дизайна промпта, частоты попаданий в кэш и использования prompt caching. Мы рекомендуем включить мониторинг использования в консоли APIYI (apiyi.com), первые 3 дня сверять расходы и превратить абстрактный бюджет в наглядный график, прежде чем переносить больше задач на Batch API.
Ниже приведена таблица, учитывающая инженерную сложность всех четырех подходов для наглядности:
| Параметр | Подход A: Чат | Подход B: MCP | Подход C: Векторная БД | Подход D: Пакетный скрипт |
|---|---|---|---|---|
| Инженерные затраты | Почти нулевые | Средние | Выше среднего | Высокие (на старте) |
| Время на освоение | 5 минут | 1-2 часа | От полдня до дня | 1-2 дня |
| Воспроизводимость | Слабая (история чата теряется) | Средняя | Высокая | Очень высокая |
| Объем данных | < 50 тыс. слов | 50-300 тыс. (динамика) | 100 тыс. — 10 млн (статика) | > 300 тыс. слов |
| Контроль вывода | Ограничен контекстным окном | Ограничен числом вызовов инструментов | Ограничен качеством поиска | Полностью под контролем |
四、Рекомендации по сценариям в зависимости от объема данных
Применять подходы к конкретным задачам гораздо проще, если разделить их по трем масштабам.
4.1 Малый объем (< 50 тыс. слов): этап обучения и поиска
Здесь главная цель — быстро проверить идеи, а не оптимизировать затраты. Подход A (прямая передача в чат) — самый разумный выбор. Загрузите все файлы в Cherry Studio или Claude Desktop и общайтесь с моделью, отлаживая промпт. На этом этапе сфокусируйтесь на вопросах: может ли модель уловить стиль автора? Какие параметры поддаются количественной оценке (длина предложений, лексика, синтаксис), а какие — нет (тон, ритм)? На малых выборках это стоит копейки, хватит пары долларов.
4.2 Средний объем (50-300 тыс. слов): этап исследования и анализа
В этом диапазоне расходы на повторный ввод данных (подход A) быстро растут. Лучшая практика — переход к подходу C (векторная база знаний) или NotebookLM. Загрузите образцы в векторную базу и используйте семантический поиск по мере необходимости. Если вы занимаетесь анализом контента, обобщением стиля или поиском ответов, NotebookLM справится практически без инженерных усилий. Если нужно многошаговое рассуждение, соберите свою RAG-систему на базе Claude или GPT.
🎯 Совет по выбору для среднего объема: NotebookLM хорош для чтения и анализа, но не поддерживает гибкие стратегии поиска и сложные рабочие процессы. Мы рекомендуем использовать платформу APIYI (apiyi.com) для подключения Claude Sonnet или Opus с контекстом 1M для работы с RAG. Это позволяет пользоваться стандартными тарифами и гибко управлять размером чанков (chunk) и весами поиска — идеально для долгосрочных проектов.
4.3 Большой объем (> 300 тыс. слов): этап производства
При объемах в сотни тысяч или миллионы слов подход D (пакетная обработка) — практически единственный устойчивый вариант. Разбейте рабочий процесс на три этапа: «выявление закономерностей на образцах» → «пакетная обработка кодом» → «использование большой языковой модели только для ключевых узлов». В сочетании с асинхронным Batch API это позволит снизить стоимость обработки одного слова до 5-15% от начальной. На этом этапе вам нужен не более «умный» промпт, а более инженерный конвейер.

五、 Рекомендации по оптимизации токенов: пошаговый план
Мы сжали весь анализ выше в удобную таблицу. Вы можете использовать её как чек-лист при выборе стратегии:
| Условие | Рекомендуемое решение | Ключевое действие |
|---|---|---|
| < 50 тыс. знаков / разовый запрос | Вариант А: Прямой диалог | Загрузка файла, настройка промпта, сохранение лучших промптов |
| 50–300 тыс. знаков / статика / анализ | Вариант С: Векторная база знаний | NotebookLM или свой RAG, настройка chunk и top-k |
| > 300 тыс. знаков / рутина / поток | Вариант D: Скрипты + Batch API | Написание скриптов с AI, ручная проверка на выборке |
| Динамические данные / локально | Вариант B: MCP | Лимит вызовов инструментов, осторожность с поиском |
В реальных проектах чаще всего используется комбинация: «Вариант А для старта, Вариант С для середины, Вариант D для финала». Понимание задачи всегда приходит постепенно: на малых объемах вы уточняете требования, на средних — проверяете качество поиска и обобщаемость, а на больших — автоматизируете отлаженный процесс.
Типичная ошибка — перескакивать сразу к скриптам. Вы можете написать идеальный код, но результат будет «мимо», так как промпт не прошел стадию дообучения. С другой стороны, застревание на этапе диалогов — это прямой путь к лишним тратам: можно потратить сотни долларов, получив на выходе всего пару десятков полезных примеров.
🎯 Когда пора переключаться?: Если вы 5 раз подряд используете похожий промпт для обработки однотипных файлов — пора переходить к векторной базе знаний. Если вы каждый раз вручную повторяете одну и ту же логику поиска — пора писать скрипт. Мы рекомендуем использовать APIYI (apiyi.com) для отслеживания кэширования промптов и статистики использования, чтобы принимать решения на основе данных, а не интуиции.
VI. Минимальный пример скрипта для пакетной обработки
Чтобы сделать Вариант D более наглядным, вот базовый шаблон скрипта, который демонстрирует цикл «поиск закономерностей → фиксация правил → массовое выполнение»:
import os, json
from anthropic import Anthropic
# Используем сервис-прокси APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Используем большую языковую модель для извлечения количественных характеристик стиля."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Извлеки характеристики стиля письма из следующей статьи в формате JSON:
- avg_sentence_length: средняя длина предложения
- paragraph_structure: структура абзацев
- key_phrases: топ-10 частотных фраз
- tone: тон (например, строгий/дружелюбный/агрессивный)
Текст статьи:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Этап выборки: анализируем 10 статей для поиска закономерностей
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Фиксация правил: сохраняем профиль стиля в файл для последующего применения
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
После завершения этапа выборки, массовая обработка может выполняться по правилам из style_profile.json. Большая языковая модель будет подключаться только на этапе «финальной полировки», что сократит расход токенов с сотен тысяч до нескольких тысяч.
🎯 Совет по интеграции API: Параметр
base_urlв примере указывает на сервис-прокси APIYI (apiyi.com). Это позволяет использовать стандартный SDK Anthropic без изменения кода. Рекомендуем добавить в скрипт логику повторных попыток (retry) и отслеживание затрат — это спасет от перерасхода бюджета при запуске тяжелых задач.
VII. Часто задаваемые вопросы (FAQ)
Q1: У Claude Sonnet и Opus уже есть контекстное окно на 1 млн токенов, почему бы просто не загрузить всё туда?
Технически это возможно, но есть два скрытых минуса. Во-первых, задержка первого токена (TTFT) может растянуться на 20–30 секунд, что сильно портит пользовательский опыт. Во-вторых, один и тот же массив данных придется отправлять при каждом новом диалоге, что в 50–200 раз дороже, чем использование RAG. Контекст 1M отлично подходит для разового глобального анализа (например, «поиск противоречий между документами»), но не для многократного обращения к одним и тем же материалам. Мы рекомендуем использовать Sonnet 1M на APIYI (apiyi.com) для глобальных задач, а Haiku — для пакетной обработки мелких фрагментов. Это даст лучшее соотношение цены и качества.
Q2: Что выбрать: NotebookLM или собственный векторный поиск?
Если вы частное лицо или небольшая команда, которой нужно анализировать статические данные, изучать стили или искать ответы на вопросы — NotebookLM будет самым быстрым решением: просто перетащили файлы и работаете. Если же вам нужна настройка стратегии чанкинга (разбивки на части), контроль весов поиска, интеграция с бизнес-системами или использование моделей других провайдеров для генерации — лучше построить свою векторную базу данных.
Q3: MCP действительно бесполезен?
Вовсе нет. Сильная сторона MCP — это сценарии, где данные постоянно меняются или их нельзя выносить за пределы локальной сети: например, чтение логов в реальном времени, запросы к приватным базам данных или вызов внутренних API. Но для статических Markdown-файлов RAG практически по всем параметрам выигрывает — именно в этом и заключается вывод.
Q4: Batch API действительно экономит 50%? А как насчет скорости ответа?
Batch API работает асинхронно, результаты обычно приходят в течение 24 часов, а цена составляет 50% от стандартного API. Это идеально подходит для задач, не требующих мгновенного отклика, например, «сгенерировать 100 статей в заданном стиле». В сочетании со стандартными тарифами на 1M контекста общие затраты можно снизить до 30–40% от первоначальных. Мы советуем сначала отладить процесс через синхронный API на платформе APIYI (apiyi.com), а затем переключаться на Batch-режим для массового производства.
Q5: Что делать, если в материалах есть изображения, таблицы и блоки кода?
Markdown сам по себе отлично сохраняет эту структуру, но будьте осторожны: объемные блоки кода потребляют много токенов. Если вы анализируете только текстовый стиль, лучше сначала отфильтровать код скриптом. Если таблицы слишком сложные, рекомендуем перевести их в CSV и хранить отдельно, передавая большой языковой модели только краткое резюме — это сэкономит еще более 30% токенов.
VIII. Заключение
Вернемся к главному вопросу: какой способ лучше всего подходит для обработки сотен тысяч слов в Markdown? Ответ не в выборе одного инструмента, а в комбинировании подходов на разных этапах. На этапе исследования небольших объемов быстрее всего работает прямая загрузка в чат. Для средних объемов надежнее использовать векторную базу знаний или NotebookLM. На этапе масштабируемого производства обязательно переходите на скрипты пакетной обработки в связке с Batch API. Сведите роль большой языковой модели к «поиску закономерностей», а всю рутинную работу по обработке объемов оставьте коду.
Поняв этот путь, задача по «экономии токенов при работе с Markdown» превращается из выбора «какой инструмент взять» в выбор «какую комбинацию использовать на текущем этапе». Если вы сейчас застряли на каком-то этапе и сомневаетесь, стоит ли переключаться, попробуйте провести небольшое тестирование на платформе APIYI (apiyi.com). Сравните три показателя: стоимость за тысячу символов, точность поиска и задержку первого токена — решение станет очевидным. Надеемся, этот разбор поможет вам избежать лишних трат и направить бюджет на то, что действительно приносит результат.
— Команда APIYI (api.apiyi.com)