title: "Meta Llama 4: Análise Técnica do Scout e Maverick"
date: 2025-04-06
description: "Análise profunda dos novos modelos Llama 4 Scout e Maverick da Meta, com arquitetura MoE multimodal nativa e janelas de contexto massivas."
Nota do autor: A Meta lançou o Llama 4 Scout e o Maverick, utilizando uma arquitetura MoE multimodal nativa. O Scout possui uma janela de contexto de 10 milhões de tokens, enquanto o Maverick supera o GPT-4o em avaliações abrangentes. Este artigo traz uma análise detalhada dos detalhes técnicos e do impacto para desenvolvedores.
A Meta lançou oficialmente a família de modelos Llama 4, e os primeiros modelos open-source com arquitetura MoE multimodal nativa, Llama 4 Scout e Maverick, atraíram grande atenção da comunidade de IA. Este artigo traz uma análise rápida sobre o impacto desse marco para desenvolvedores de IA e para toda a indústria.
Valor central: Entenda em 3 minutos os principais avanços técnicos, desempenho em avaliações e valor prático do Llama 4 Scout e Maverick.

Visão Geral do Llama 4 Scout e Maverick
| Item | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|
| Data de lançamento | 5 de abril de 2025 | 5 de abril de 2025 |
| Tipo de arquitetura | MoE multimodal nativo | MoE multimodal nativo |
| Parâmetros ativos | 17 bilhões | 17 bilhões |
| Número de especialistas | 16 | 128 |
| Total de parâmetros | 109 bilhões | 400 bilhões |
| Janela de contexto | 10 milhões de tokens | 1 milhão de tokens |
| Licença open-source | Licença Llama | Licença Llama |
Posicionamento do Llama 4 Scout e Maverick
O Llama 4 é a quarta geração da família de modelos de linguagem grande da Meta e a primeira da série Llama a adotar arquiteturas multimodal nativa e Mistura de Especialistas (MoE). Comparado à série Llama 3, o Llama 4 passou por uma reestruturação fundamental em sua arquitetura.
O Scout é posicionado como um modelo eficiente para processamento de textos longos, oferecendo a maior janela de contexto da indústria, com 10 milhões de tokens, a um custo de inferência extremamente baixo. O Maverick é posicionado como um modelo de alto desempenho para uso geral, alcançando capacidades abrangentes que superam o GPT-4o através de seus 128 especialistas.
Ambos os modelos já tiveram seus pesos liberados para download, e os desenvolvedores podem obtê-los através do llama.com e do Hugging Face.
Análise da Arquitetura Técnica do Llama 4 Scout e Maverick
Arquitetura de Fusão Antecipada (Early Fusion) Multimodal Nativa
A maior inovação arquitetônica do Llama 4 reside no treinamento multimodal nativo. Diferente das abordagens anteriores, que conectavam módulos visuais a modelos de linguagem em uma etapa posterior, o Llama 4 adota a estratégia de Early Fusion (fusão antecipada) desde a fase de pré-treinamento, integrando tokens de texto e visuais diretamente na rede principal do modelo.
Isso significa que, ao processar conteúdos mistos de imagem e texto, o Llama 4 não realiza mais um processamento em duas etapas ("olhar a imagem e depois falar"), mas sim compreende e raciocina sobre a imagem e o texto como uma entrada unificada.
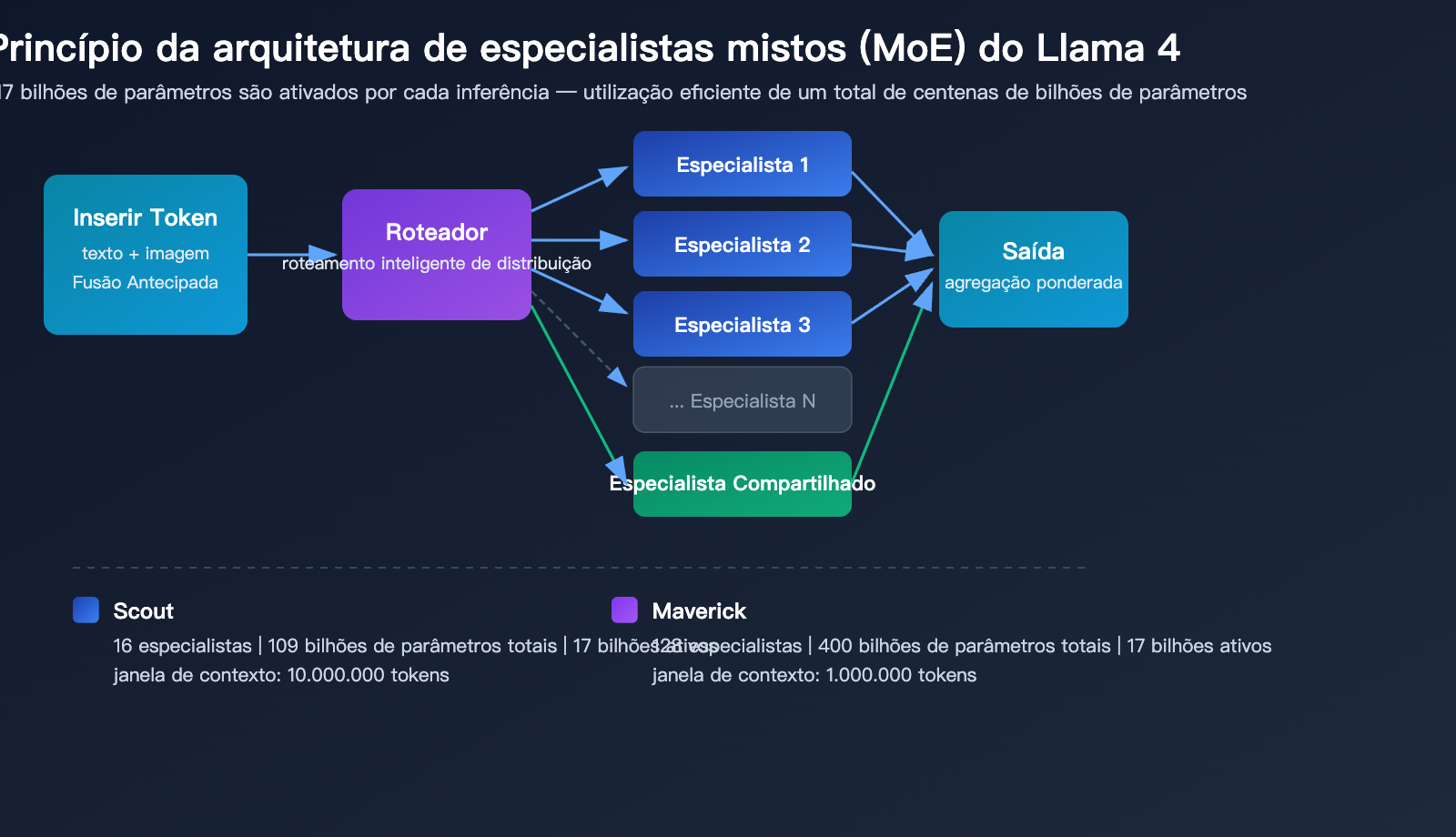
Mecanismo de Especialistas (MoE) do Llama 4
| Detalhes Técnicos | Scout (16 especialistas) | Maverick (128 especialistas) |
|---|---|---|
| Total de parâmetros | 109 bilhões | 400 bilhões |
| Ativação por inferência | 17 bilhões de parâmetros | 17 bilhões de parâmetros |
| Especialistas roteados | 16 + especialistas compartilhados | 128 + especialistas compartilhados |
| Eficiência de inferência | Executável em uma H100 (INT4) | Executável em um DGX H100 |
| Arquitetura de contexto | iRoPE (atenção sem entrelaçamento de codificação posicional) | Atenção padrão |
A principal vantagem da arquitetura MoE é que, embora o total de parâmetros seja de 109 bilhões e 400 bilhões, respectivamente, apenas 17 bilhões de parâmetros são ativados em cada inferência. Isso permite que o Llama 4 Scout seja executado em uma única GPU NVIDIA H100 com quantização INT4, reduzindo drasticamente a barreira de implantação.
Dados e Escala de Treinamento do Llama 4
O volume de dados de treinamento do Llama 4 atingiu mais de 30 trilhões de tokens, o dobro do Llama 3. O volume de dados multilingues é 10 vezes maior que o do Llama 3, cobrindo 200 idiomas. O treinamento utiliza precisão FP8, alcançando uma eficiência de 390 TFLOPs por GPU no modelo Behemoth.
Desempenho de Avaliação do Llama 4 Scout e Maverick
Dados de Avaliação do Llama 4 Maverick
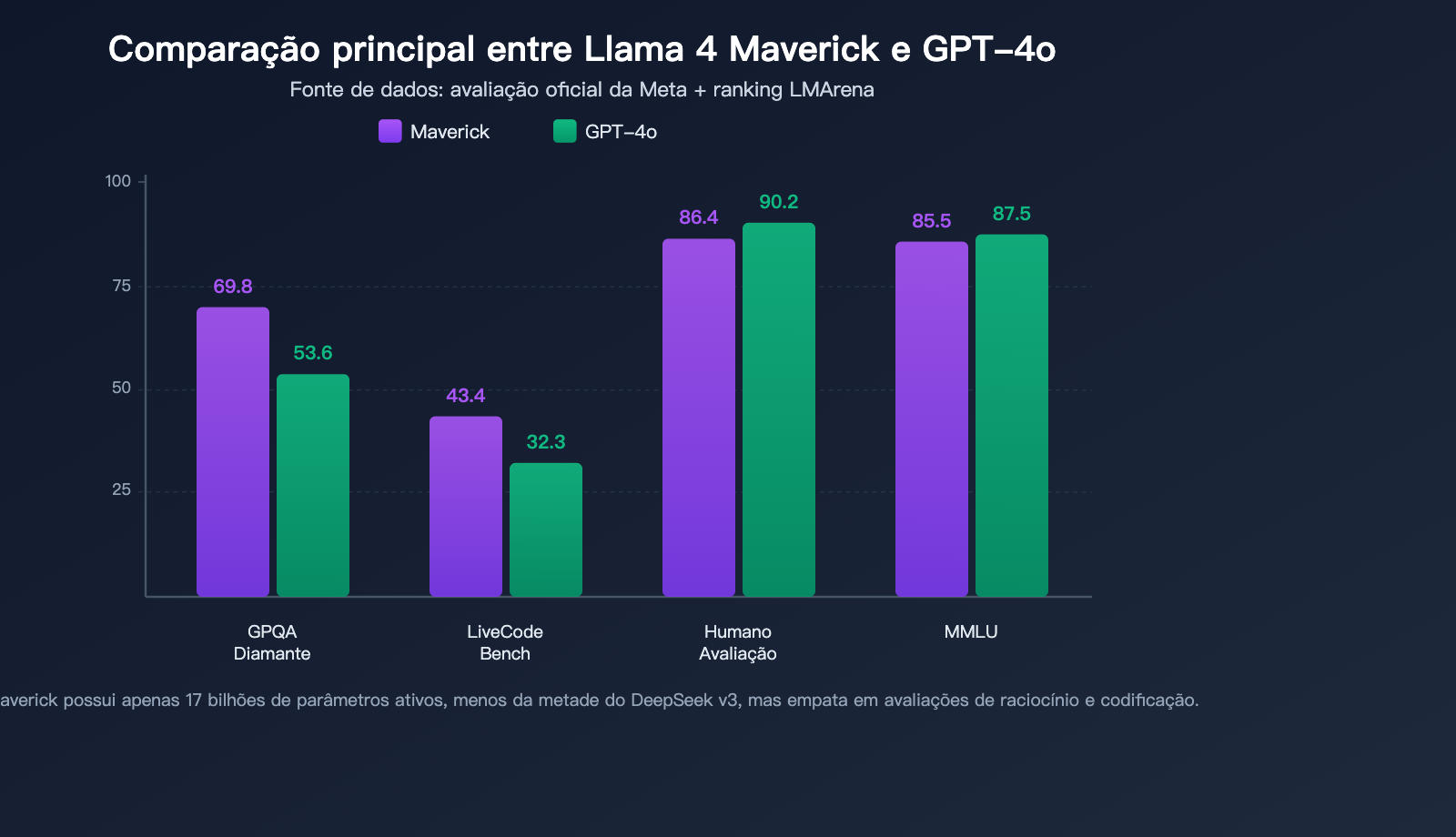
O Maverick apresenta um desempenho excepcional em diversas avaliações autorizadas, superando o GPT-4o e o Gemini 2.0 Flash em capacidade abrangente:
| Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | Avaliação |
|---|---|---|---|---|
| MMLU | 85.5 | ~87-88 | – | Próximo ao topo |
| GPQA Diamond | 69.8 | 53.6 | – | Liderança significativa |
| LiveCodeBench | 43.4 | 32.3 | – | Liderança notável |
| HumanEval | 86.4% | 90.2% | – | Nível próximo |
| LMArena ELO | 1417 | Abaixo de 1417 | Abaixo de 1417 | Nível de elite |
Alguns destaques importantes:
Liderança em raciocínio científico no GPQA Diamond: O Maverick obteve 69,8 pontos no GPQA Diamond, superando os 53,6 do GPT-4o em mais de 16 pontos percentuais, demonstrando uma poderosa capacidade de raciocínio em disciplinas especializadas.
Capacidade de codificação no LiveCodeBench: No benchmark de programação em tempo real LiveCodeBench, o Maverick lidera com 43,4 pontos contra 32,3 do GPT-4o, mantendo-se no mesmo nível do DeepSeek v3 em tarefas de raciocínio e codificação — sendo que o número de parâmetros ativos do Maverick é menos da metade do DeepSeek v3.
Nível de elite na avaliação de preferência humana LMArena: A versão experimental do Maverick obteve uma pontuação ELO de 1417 no LMArena (Chatbot Arena), entrando no grupo dos modelos de elite global.
Destaques da Avaliação do Llama 4 Scout
Como um "pequeno" modelo com apenas 17 bilhões de parâmetros ativos, o desempenho do Scout é impressionante:
- Supera o Gemma 3, Gemini 2.0 Flash-Lite e Mistral 3.1 em uma ampla gama de benchmarks.
- Supera todos os modelos Llama 3 da geração anterior, incluindo o Llama 3.3 70B, que possui mais parâmetros.
- Possui a janela de contexto de 10 milhões de tokens mais longa da indústria, capaz de processar cerca de 7,5 milhões de palavras.
- Pode ser executado em uma única GPU H100, com custo de inferência extremamente baixo.
🎯 Dica para desenvolvedores: Tanto o Llama 4 Scout quanto o Maverick suportam chamadas de interface compatíveis com OpenAI. Se precisar testar rapidamente os efeitos práticos desses modelos, você pode obter uma interface de API unificada através da plataforma APIYI (apiyi.com). Com apenas uma chave API, você pode alternar entre a invocação de vários modelos de código aberto e fechado.
O impacto do Llama 4 Scout e Maverick para desenvolvedores
O valor prático da janela de contexto de 10 milhões de tokens
A janela de contexto de 10 milhões de tokens do Scout é a maior entre os modelos disponíveis publicamente, e essa capacidade abre novos horizontes para os desenvolvedores:
- Análise completa de bases de código: É possível inserir todo o código de projetos de médio a grande porte no modelo para análise de uma só vez.
- Processamento de documentos longos: Analise centenas de páginas de documentação técnica, contratos jurídicos ou artigos de pesquisa em uma única requisição.
- Memória de conversação de longo prazo: Mantenha um histórico de contexto extremamente longo em aplicações baseadas em chat.
- Extração de dados em larga escala: Extraia informações estruturadas em lote a partir de grandes volumes de textos não estruturados.
Impacto do Llama 4 no ecossistema open source
| Dimensão do Impacto | Mudança Específica | Benefício para o Desenvolvedor |
|---|---|---|
| Barreira de implantação | Scout roda em uma única GPU | Redução de custos de hardware |
| Capacidade do modelo | Nível superior ao GPT-4o | Open source equiparado ao fechado |
| Multimodal | Compreensão nativa de imagem e texto | Sem necessidade de módulos visuais extras |
| Contexto | 10 milhões de tokens | Novos cenários de aplicação |
| Customização | Pesos abertos para fine-tuning | Otimização para cenários verticais |
O lançamento do Llama 4 marca a primeira vez que um modelo open source alcança ou até supera, em capacidades abrangentes, os principais modelos comerciais fechados. Para os desenvolvedores, isso significa:
Vantagem de custo: A implantação privada baseada no Llama 4 pode reduzir significativamente os custos de invocação do modelo, sendo ideal para cenários de produção com alta frequência de uso.
Liberdade de customização: Os pesos abertos permitem que desenvolvedores realizem fine-tuning, quantização, destilação e outras operações, criando modelos exclusivos para nichos específicos.
Ecossistema próspero: No dia do lançamento, o Llama 4 já contava com suporte de diversas plataformas de nuvem, como AWS, Google Cloud, Azure, Together.ai, Groq e Fireworks.
Integração do Llama 4 nas plataformas
A Meta integrou o Llama 4 em suas plataformas sociais, fornecendo capacidades multimodais para o assistente Meta AI:
- WhatsApp: Suporte para envio de imagens para análise e conversação com IA
- Messenger: Perguntas e respostas com interação multimodal
- Instagram Direct: Compreensão de imagens e auxílio criativo
- Meta.ai: Uso direto via navegador
Esta é a primeira vez que um Modelo de Linguagem Grande é implantado diretamente para o consumidor final em uma escala tão massiva, atingindo bilhões de usuários.
Llama 4 Behemoth: O modelo carro-chefe ainda em treinamento
Além do Scout e do Maverick, a Meta anunciou o modelo carro-chefe da família Llama 4: o Behemoth:
| Parâmetro | Especificações do Behemoth |
|---|---|
| Parâmetros ativos | 288 bilhões |
| Número de especialistas | 16 |
| Total de parâmetros | Cerca de 2 trilhões |
| Status de treinamento | Em andamento |
De acordo com os dados preliminares de checkpoints divulgados pela Meta, o Behemoth já superou o GPT-4.5, o Claude Sonnet 3.7 e o Gemini 2.0 Pro em diversos testes de STEM. O Maverick obteve melhorias de capacidade durante o treinamento por meio da destilação de conhecimento do Behemoth, o que explica como o Maverick alcança um desempenho de elite com um número menor de parâmetros ativos.
💡 Dica de acompanhamento: O lançamento final do Behemoth elevará ainda mais o teto de capacidade dos modelos open source. Os desenvolvedores podem começar a construir aplicações baseadas no Scout e no Maverick, realizar testes comparativos entre modelos na plataforma APIYI (apiyi.com) e migrar sem problemas assim que o Behemoth for lançado.
Acesso rápido ao Llama 4 Scout e Maverick
Exemplo de invocação de API simplificada
Através da interface compatível com OpenAI, você pode invocar o modelo Llama 4 com apenas 10 linhas de código:
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{"role": "user", "content": "Explique como funciona a arquitetura MoE"}]
)
print(response.choices[0].message.content)
Ver exemplo de invocação multimodal
import openai
import base64
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Ler imagem local e codificar
with open("image.jpg", "rb") as f:
image_data = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="meta-llama/llama-4-maverick",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Por favor, descreva o conteúdo desta imagem"},
{"type": "image_url", "image_url": {
"url": f"data:image/jpeg;base64,{image_data}"
}}
]
}]
)
print(response.choices[0].message.content)
🚀 Início rápido: Recomendamos obter sua chave API e créditos de teste gratuitos através da APIYI (apiyi.com). A plataforma oferece uma interface unificada para o Llama 4 Scout, Maverick e outros modelos populares, facilitando a comparação rápida do desempenho real de cada modelo.
Perguntas frequentes
Q1: Como escolher entre o Llama 4 Scout e o Maverick?
Se você precisa processar textos extremamente longos (como bases de código completas ou análise de documentos extensos), escolha o Scout (janela de contexto de 10 milhões de tokens). Se você busca um modelo de uso geral com a capacidade mais abrangente, escolha o Maverick (128 especialistas, superando o GPT-4o em avaliações). Ambos podem ser testados na prática através da plataforma APIYI (apiyi.com) para ajudar na sua decisão.
Q2: O Llama 4 é totalmente gratuito?
O Llama 4 adota a licença Llama para pesos abertos, permitindo o uso comercial. No entanto, empresas com mais de 700 milhões de usuários ativos mensais precisam solicitar uma licença especial à Meta. Para a grande maioria dos desenvolvedores e empresas, o uso é gratuito. Se você não deseja realizar o deploy por conta própria, também pode invocá-lo sob demanda via API através de plataformas terceiras como a APIYI (apiyi.com).
Q3: O Llama 4 Maverick é realmente melhor que o GPT-4o?
Em avaliações cruciais como GPQA Diamond (raciocínio científico) e LiveCodeBench (programação em tempo real), o Maverick supera significativamente o GPT-4o. Em MMLU e HumanEval, ambos apresentam resultados próximos. Na avaliação de preferência humana LMArena, o Maverick também alcançou pontuações ELO de elite. Em suma, o Maverick está no mesmo patamar do GPT-4o em avaliações abrangentes, liderando em alguns indicadores específicos.
Resumo
Pontos principais sobre o Llama 4 Scout e Maverick:
- Inovação na arquitetura: Primeiros modelos de código aberto MoE multimodais nativos, com arquitetura de Early Fusion que alcança uma compreensão verdadeiramente integrada de texto e imagem.
- Salto de desempenho: O Maverick supera o GPT-4o em mais de 16 pontos percentuais no GPQA Diamond, enquanto o Scout, com 17 bilhões de parâmetros ativos, supera o Llama 3.3 70B.
- Transformação de aplicações: Janela de contexto de 10 milhões de tokens e pesos abertos, abrindo novos cenários de aplicação e possibilidades de implantação para desenvolvedores.
O lançamento do Llama 4 marca o início de uma nova era para os Modelos de Linguagem Grande de código aberto. Seja para criar aplicações corporativas ou projetos pessoais, os desenvolvedores agora podem obter capacidades comparáveis aos melhores modelos de código fechado com o Llama 4. Recomendamos experimentar a série Llama 4 através da APIYI (apiyi.com); a plataforma oferece créditos gratuitos e uma interface unificada para diversos modelos, ajudando os desenvolvedores a selecionar a melhor opção com eficiência.
📚 Referências
-
Blog oficial da Meta AI – Anúncio do Llama 4: Fonte oficial sobre detalhes técnicos e dados de avaliação do modelo.
- Link:
ai.meta.com/blog/llama-4-multimodal-intelligence - Descrição: Contém a introdução completa da arquitetura, dados de avaliação e detalhes do lançamento.
- Link:
-
Site oficial do Llama – Download do modelo: Obtenha os pesos e a documentação do Llama 4.
- Link:
llama.com/models/llama-4 - Descrição: Disponibiliza downloads de modelos, informações de licença e documentação técnica.
- Link:
-
Hugging Face – Repositório de modelos Llama 4: Guia de hospedagem e uso pela comunidade de código aberto.
- Link:
huggingface.co/meta-llama - Descrição: Oferece cartões de modelo, versões quantizadas e discussões da comunidade.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir suas experiências com o Llama 4 na seção de comentários. Para mais materiais sobre a integração de modelos de IA, acesse a central de documentação da APIYI em docs.apiyi.com.