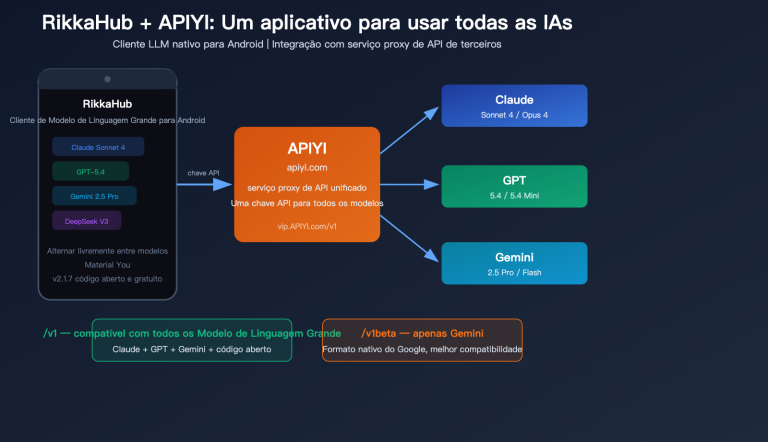
Já passou pela frustração de ter um projeto que usa GPT da OpenAI, Claude da Anthropic e Gemini do Google ao mesmo tempo, onde cada um tem um SDK diferente, um formato de API distinto e até formas diferentes de tratar erros? Precisa mudar de modelo e acaba tendo que reescrever metade do código?
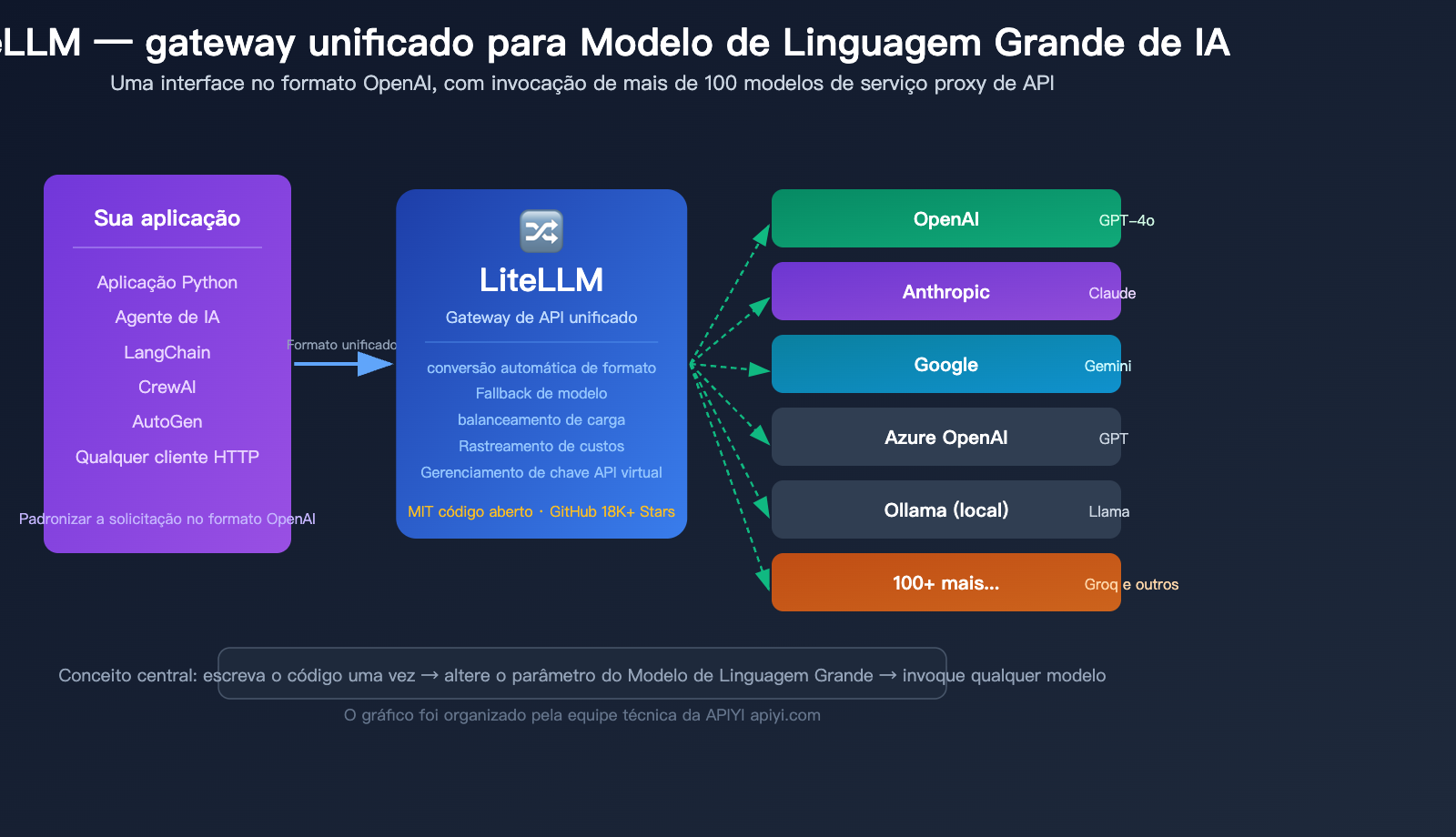
É exatamente esse o problema que o LiteLLM resolve. Em resumo, o LiteLLM é o "tradutor universal" para Modelos de Linguagem Grande — você só precisa aprender uma única forma de invocação (o formato da OpenAI) e ele traduz isso para o formato de API de mais de 100 provedores diferentes.
Valor central: Ao ler este artigo, você entenderá o que é o LiteLLM, por que os frameworks de agentes de IA estão usando-o e como começar a utilizá-lo em 5 minutos.
title: "O que é o LiteLLM: 5 conceitos fundamentais e modos de uso"
description: "Entenda os 5 conceitos principais do LiteLLM e escolha entre o modo SDK ou Proxy para gerenciar suas invocações de modelos de linguagem de forma eficiente."
O que é o LiteLLM: 5 conceitos fundamentais
Antes de começar, vamos entender os 5 conceitos principais do LiteLLM da forma mais simples possível. Com esses conceitos claros, tudo o que vier a seguir será natural.
| Conceito Fundamental | Explicação simples | Problema que resolve |
|---|---|---|
| Interface Unificada | Todos os modelos são chamados da mesma forma | Não precisa aprender um SDK para cada modelo |
| Provider (Provedor) | Fabricantes de modelos como OpenAI, Anthropic, etc. | Gerencia as formas de conexão com diferentes fornecedores |
| Fallback (Failover) | Se o modelo A falhar, muda automaticamente para o B | Garante que o serviço não seja interrompido |
| Virtual Key (Chave Virtual) | Cria "subcontas" para membros da equipe | Controla o uso e o orçamento |
| Proxy (Gateway) | Servidor proxy de API independente | Qualquer linguagem ou ferramenta pode se conectar |
Que problemas o LiteLLM resolve?
Imagine um mundo sem o LiteLLM:
Chamando a OpenAI:
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Olá"}]
)
Chamando a Anthropic:
import anthropic
client = anthropic.Anthropic(api_key="sk-ant-xxx")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024, # Anthropic exige especificação
messages=[{"role": "user", "content": "Olá"}]
)
Chamando o Google Gemini:
import google.generativeai as genai
genai.configure(api_key="AIza-xxx")
model = genai.GenerativeModel("gemini-2.0-flash")
response = model.generate_content("Olá")
Viu só? Três modelos, três SDKs diferentes, três formas de escrever. Se o seu projeto precisar alternar entre modelos, o código ficará cheio de condicionais como if provider == "openai"... elif provider == "anthropic"....
Com o LiteLLM:
import litellm
# Chamando a OpenAI
response = litellm.completion(model="gpt-4o", messages=[{"role": "user", "content": "Olá"}])
# Chamando a Anthropic — a mesma sintaxe
response = litellm.completion(model="anthropic/claude-sonnet-4-6", messages=[{"role": "user", "content": "Olá"}])
# Chamando o Gemini — ainda a mesma sintaxe
response = litellm.completion(model="gemini/gemini-2.0-flash", messages=[{"role": "user", "content": "Olá"}])
Um único litellm.completion(), basta trocar o parâmetro model. O LiteLLM cuida automaticamente da conversão de formato, adaptação de parâmetros e padronização da resposta.
🎯 Dica técnica: O conceito de interface unificada do LiteLLM é semelhante ao APIYI (apiyi.com) — ambos permitem invocar vários modelos através de uma única interface. A diferença é que o LiteLLM é uma solução de código aberto para auto-hospedagem, enquanto o APIYI é um serviço gerenciado que não exige implantação. Escolha a solução que melhor se adapta à capacidade técnica da sua equipe.
Detalhes dos dois modos de uso do LiteLLM
O LiteLLM oferece dois modos de uso, adequados para diferentes cenários. Entender a diferença entre eles é a chave para escolher a forma correta de trabalhar.
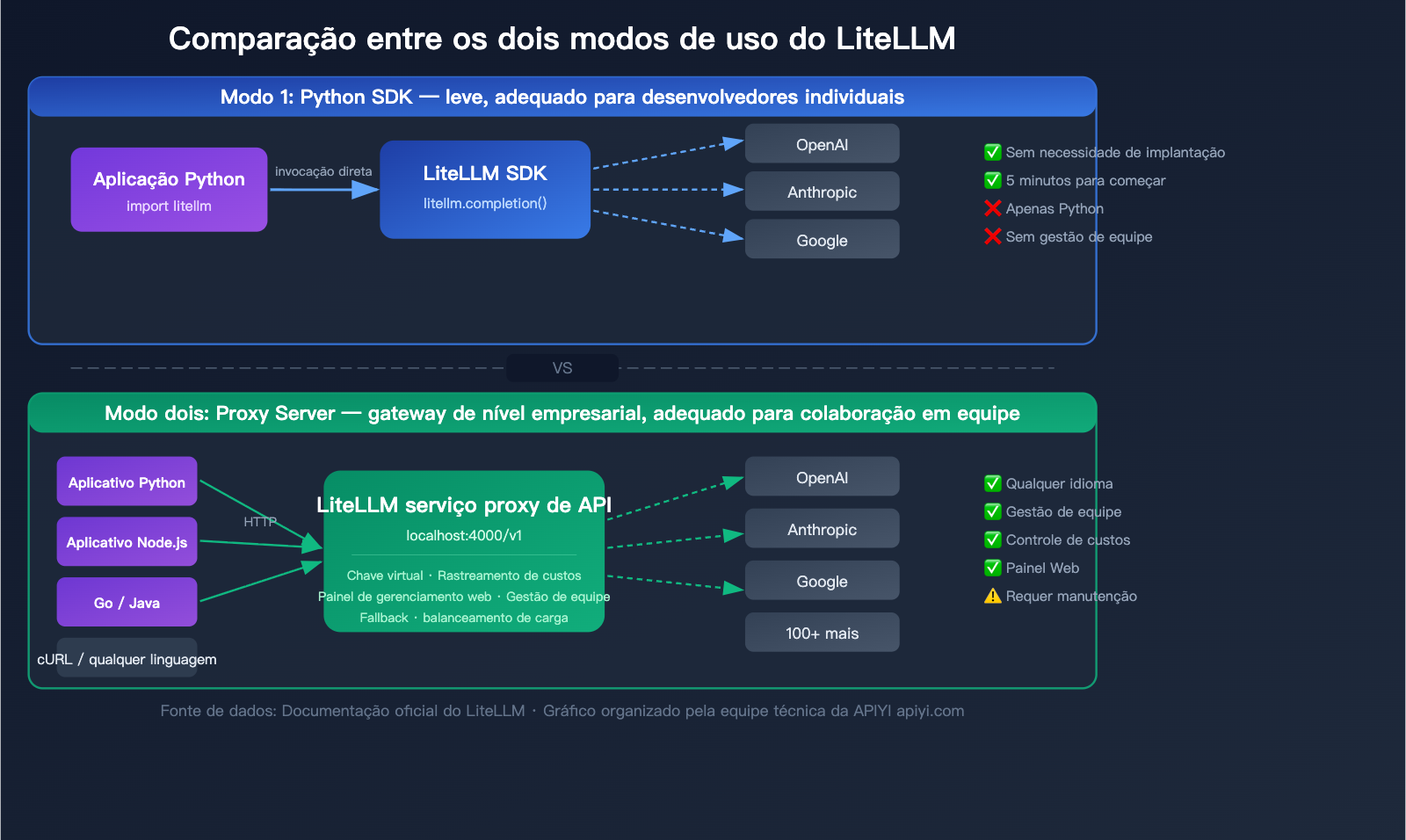
Modo 1: Python SDK (Leve)
Importe o pacote litellm diretamente no seu código Python e use-o como uma chamada de função.
Cenários de uso:
- Desenvolvedores individuais
- Projetos puramente em Python
- Prototipagem rápida
- Sem necessidade de recursos de gestão de equipe
Instalação:
pip install litellm
Uso básico:
import litellm
import os
# Configurar API Key (via variáveis de ambiente)
os.environ["OPENAI_API_KEY"] = "sk-sua-chave"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-sua-chave"
# Chamar qualquer modelo
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Explique o que é um gateway de API"}]
)
print(response.choices[0].message.content)
Modo 2: Proxy Server (Gateway de nível empresarial)
Executado como um servidor independente, expondo uma interface HTTP compatível com a OpenAI. Qualquer linguagem de programação ou ferramenta que consiga enviar requisições HTTP pode usá-lo.
Cenários de uso:
- Colaboração em equipe
- Projetos multilíngues (Java, Go, Node.js, etc.)
- Necessidade de rastreamento de custos e gestão de orçamento
- Necessidade de atribuir chaves virtuais para diferentes equipes
- Integração com frameworks de AI Agent
Instalação e inicialização:
# Instalação
pip install 'litellm[proxy]'
# Iniciar com arquivo de configuração
litellm --config config.yaml --port 4000
# Ou usando Docker
docker run -p 4000:4000 \
-e OPENAI_API_KEY=sk-xxx \
ghcr.io/berriai/litellm:main-latest
Após iniciar, qualquer aplicação pode chamá-lo como se estivesse chamando a OpenAI:
from openai import OpenAI
# Aponte o base_url para o LiteLLM Proxy
client = OpenAI(
api_key="sk-sua-chave-virtual",
base_url="http://localhost:4000/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Olá"}]
)
Comparação: LiteLLM SDK vs. Modo Proxy
| Dimensão de comparação | Python SDK | Proxy Server |
|---|---|---|
| Método de instalação | pip install litellm |
pip install 'litellm[proxy]' ou Docker |
| Método de invocação | Chamada de função Python | HTTP API (qualquer linguagem) |
| Configuração | Definida no código | Arquivo de configuração config.yaml |
| Gestão de chave virtual | Não suportado | Suportado, com limite de orçamento |
| Painel de gestão Web | Nenhum | Sim, gestão visual |
| Gestão de equipe | Não suportado | Suporta usuários/equipes/orçamentos |
| Rastreamento de custos | Básico (nível de código) | Completo (persistência em banco de dados) |
| Complexidade de implantação | Zero | Requer manutenção de servidor |
| Público-alvo | Desenvolvedores individuais | Equipes/Empresas |
💡 Sugestão de escolha: Se você é um desenvolvedor individual fazendo prototipagem, o modo SDK funciona em 5 minutos. Se for para uso em equipe ou ambiente de produção, o modo Proxy é mais adequado. Claro, se você não quiser implantar e manter seu próprio servidor, também pode usar serviços de interface unificada gerenciados como o APIYI (apiyi.com), que já vêm prontos para uso.
Tutorial de Início Rápido com LiteLLM
Aqui estão os passos completos para começar a usar o LiteLLM do zero.
Início rápido com o modo SDK do LiteLLM
Passo 1: Instalação
pip install litellm
Passo 2: Configurar variáveis de ambiente
# macOS / Linux
export OPENAI_API_KEY="sk-sua-chave"
export ANTHROPIC_API_KEY="sk-ant-sua-chave"
# Windows
set OPENAI_API_KEY=sk-sua-chave
Passo 3: Escrever o código
import litellm
# Invocação básica do modelo
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "system", "content": "Você é um assistente técnico"},
{"role": "user", "content": "O que é um gateway de LLM?"}
],
temperature=0.7
)
print(response.choices[0].message.content)
print(f"Uso de tokens: {response.usage.total_tokens}")
print(f"Custo estimado: ${response._hidden_params.get('response_cost', 'N/A')}")
Ver código completo: com Fallback e saída em streaming
import litellm
import os
os.environ["OPENAI_API_KEY"] = "sk-sua-chave"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-sua-chave"
# Invocação com Fallback: se o GPT-4o falhar, muda automaticamente para o Claude
response = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Explique a API RESTful"}],
fallbacks=["anthropic/claude-sonnet-4-6"],
num_retries=2
)
# Saída em streaming
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Escreva um poema sobre programação"}],
stream=True
)
for chunk in stream:
content = chunk.choices[0].delta.content
if content:
print(content, end="", flush=True)
Início rápido com o modo Proxy do LiteLLM
Passo 1: Criar o arquivo de configuração config.yaml
model_list:
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-sonnet
litellm_params:
model: anthropic/claude-sonnet-4-6
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: gemini-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
litellm_settings:
drop_params: true
num_retries: 3
general_settings:
master_key: sk-my-master-key
Passo 2: Iniciar o Proxy
litellm --config config.yaml --port 4000
Passo 3: Usar a invocação do modelo via SDK padrão da OpenAI
from openai import OpenAI
client = OpenAI(
api_key="sk-my-master-key",
base_url="http://localhost:4000/v1"
)
# Invocação do modelo GPT-4o (via LiteLLM Proxy)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Olá"}]
)
print(response.choices[0].message.content)
Também é possível usar cURL diretamente:
curl http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-my-master-key" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-sonnet",
"messages": [{"role": "user", "content": "Olá"}]
}'
🚀 Início rápido: O LiteLLM Proxy exige que você gerencie seu próprio servidor e chave API. Se você deseja usar uma interface unificada sem precisar de implantação, experimente o APIYI (apiyi.com). Ele também suporta o formato compatível com OpenAI para invocar mais de 100 modelos, sem a necessidade de configurar qualquer infraestrutura.
O papel central do LiteLLM em Agentes de IA
Esta é uma dúvida comum entre iniciantes: por que quase todos os frameworks de agentes de IA populares suportam ou até recomendam o uso do LiteLLM?
Por que os Agentes de IA precisam do LiteLLM?
Agentes de IA (agentes inteligentes) frequentemente precisam realizar estas tarefas ao executar comandos:
- Invocar diferentes modelos: usar modelos pequenos e baratos para tarefas simples e modelos de linguagem grandes para raciocínios complexos.
- Fallback automático: alternar automaticamente para um modelo reserva quando o modelo principal atingir o limite de taxa ou ficar indisponível.
- Controle de custos: rastrear e limitar o consumo de tokens de forma unificada quando vários agentes rodam em paralelo.
- Colaboração em equipe: compartilhar um pool de recursos de chave API entre diferentes desenvolvedores.
O LiteLLM resolve essas necessidades perfeitamente, atuando como um "centro de despacho" entre o agente e o modelo.
Integração do LiteLLM com frameworks de Agentes de IA populares
| Framework de Agente | Método de Integração | Uso típico |
|---|---|---|
| LangChain / LangGraph | Suporte nativo no SDK | ChatLiteLLM como backend de Modelo de Linguagem Grande |
| CrewAI | Conexão via Proxy | Pool de recursos de modelo compartilhado entre múltiplos agentes |
| AutoGen (Microsoft) | Conexão via Proxy | Acesso via endpoint compatível com OpenAI |
| Dify | Provedor personalizado | Configurado como endpoint compatível com OpenAI |
| Open WebUI | Conexão via Proxy | Endpoint de API backend |
| Aider | Conexão via Proxy | Camada de modelo para agentes de geração de código |
| Continue.dev | Conexão via Proxy | Backend para assistente de codificação de IA no IDE |
Arquitetura típica do LiteLLM em sistemas multi-agente
Em um sistema multi-agente, o LiteLLM Proxy geralmente funciona assim:
- Agente de Planejamento → invoca o Claude Opus (modelo de raciocínio avançado)
- Agente de Execução → invoca o GPT-4o (desempenho equilibrado)
- Agente de Verificação → invoca o GPT-4o-mini (rápido e de baixo custo)
- Agente de Resumo → invoca o Gemini Flash (janela de contexto grande)
Todos os agentes fazem a invocação do modelo através do mesmo endpoint do LiteLLM Proxy, que roteia automaticamente para o modelo backend correto. Os administradores podem visualizar o uso de tokens e os custos de todos os agentes através de um painel centralizado.
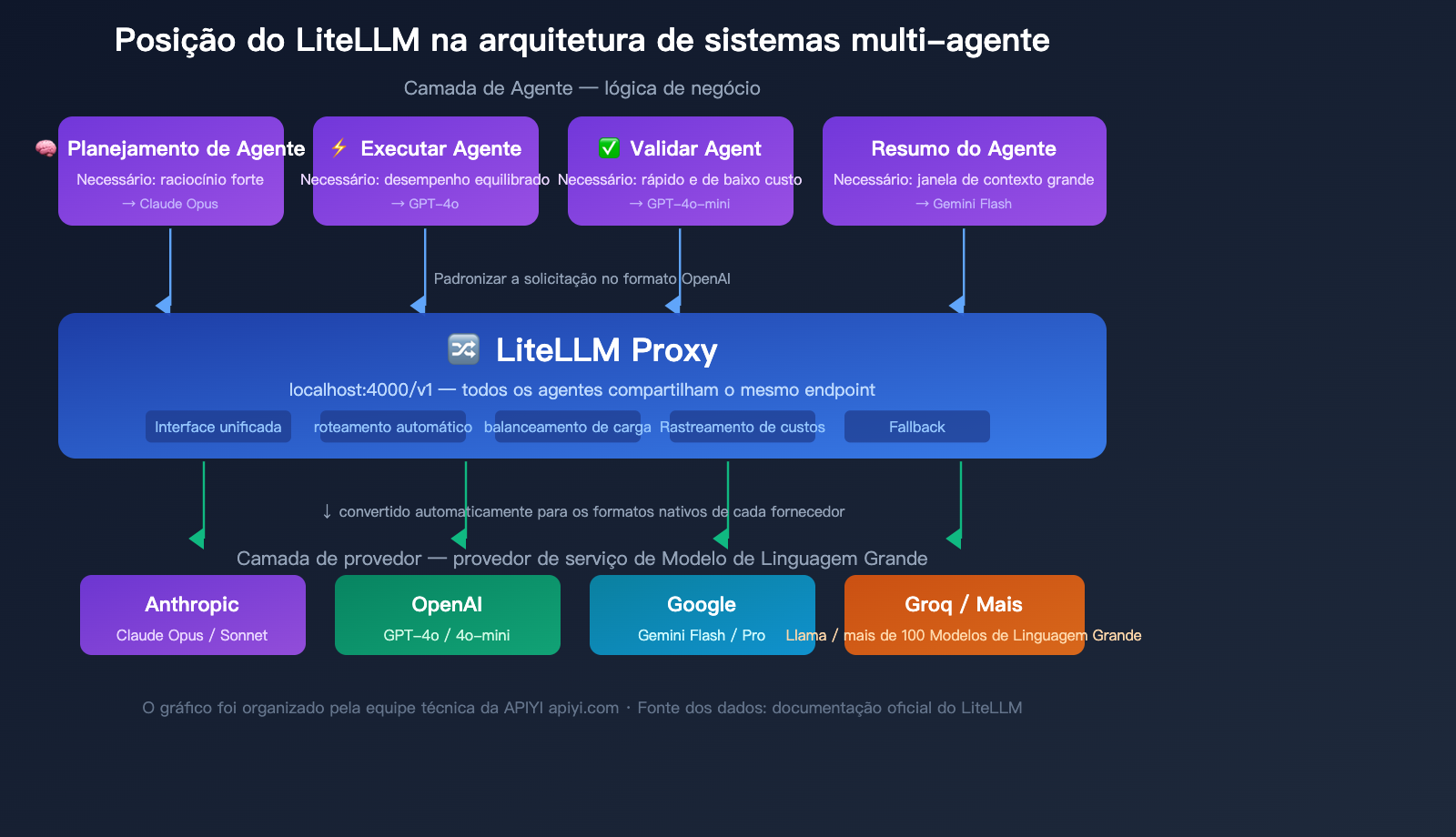
🎯 Sugestão técnica: Em sistemas multi-agente em ambiente de produção, o LiteLLM Proxy precisa ser combinado com PostgreSQL e Redis para utilizar totalmente as funções de rastreamento de custos e cache. Se sua equipe for pequena ou se você não quiser manter infraestrutura adicional, o APIYI (apiyi.com) oferece capacidades de interface unificada semelhantes, com rastreamento de custos e estatísticas de uso integrados, sem a necessidade de implantar bancos de dados extras.
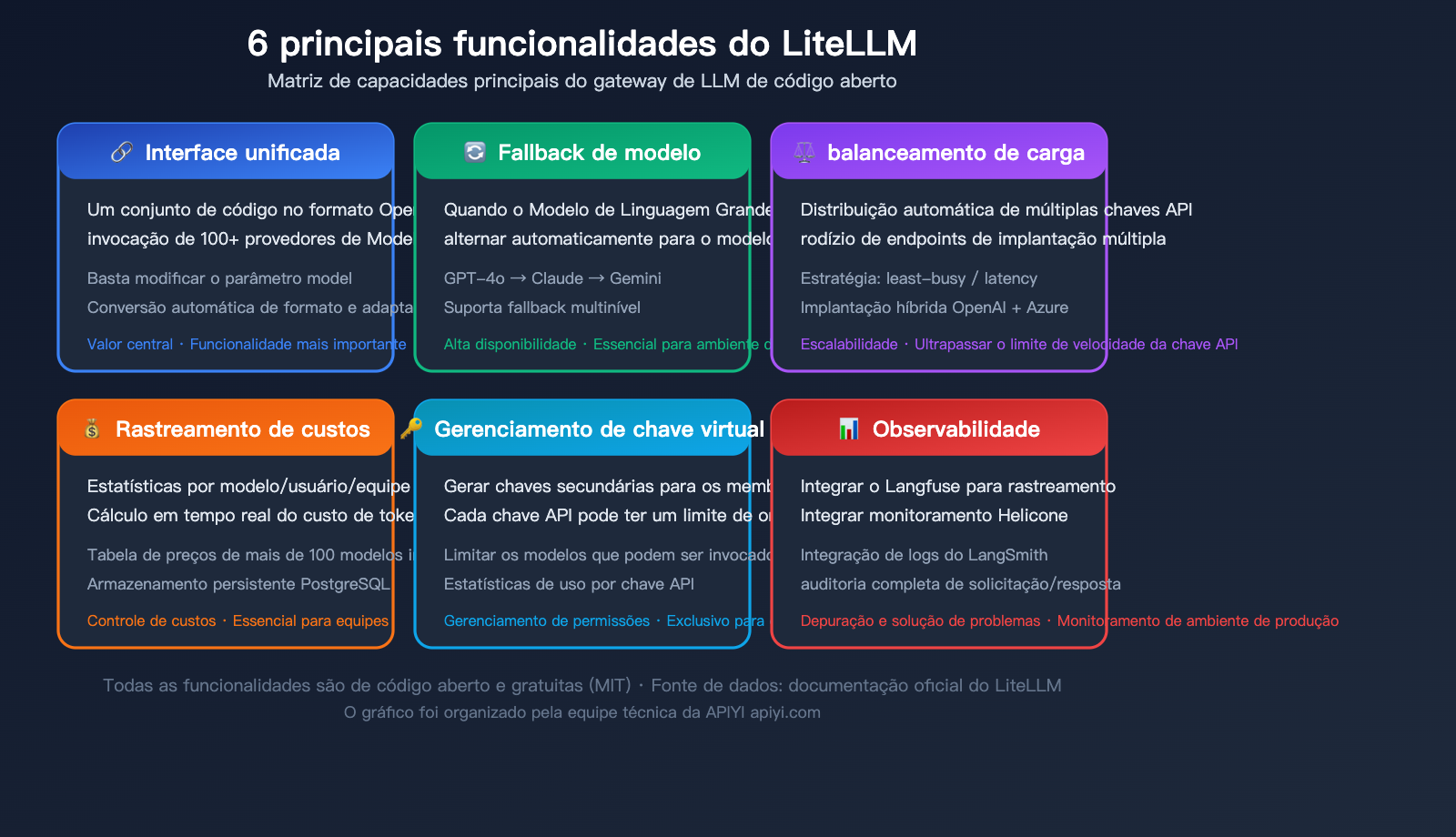
Detalhamento das funcionalidades avançadas do LiteLLM
Após dominar o uso básico, estas 3 funcionalidades avançadas são as mais utilizadas em ambientes de produção.
Funcionalidade avançada 1: Fallback de modelo (Failover)
Quando o modelo principal sofre limitação de taxa (rate limit), timeout ou erros, o LiteLLM alterna automaticamente para um modelo de reserva, garantindo que o serviço não seja interrompido.
Configuração de Fallback no SDK:
response = litellm.completion(
model="gpt-4o",
messages=messages,
fallbacks=["anthropic/claude-sonnet-4-6", "gemini/gemini-2.0-flash"],
num_retries=2
)
Lógica de execução: tenta primeiro o GPT-4o → se falhar, tenta o Claude Sonnet → se falhar novamente, tenta o Gemini Flash.
Configuração de Fallback no Proxy (config.yaml):
litellm_settings:
fallbacks:
- gpt-4o: [claude-sonnet, gemini-flash]
- claude-sonnet: [gpt-4o, gemini-flash]
Funcionalidade avançada 2: Balanceamento de carga
Configure vários backends para o mesmo nome de modelo e o LiteLLM distribuirá as solicitações automaticamente.
model_list:
# Mesmo nome de modelo, dois backends diferentes
- model_name: gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_KEY_1
- model_name: gpt-4o
litellm_params:
model: azure/gpt-4o-deployment
api_key: os.environ/AZURE_KEY_1
api_base: https://my-azure.openai.azure.com
router_settings:
routing_strategy: least-busy # Prioridade para o menos ocupado
# Outras estratégias: simple-shuffle, latency-based
Ao realizar a invocação do modelo, basta especificar model="gpt-4o" e o LiteLLM distribuirá o tráfego automaticamente entre a conexão direta da OpenAI e a implantação no Azure.
Funcionalidade avançada 3: Rastreamento de custos e chaves virtuais
Gerar chaves virtuais (modo Proxy):
curl http://localhost:4000/key/generate \
-H "Authorization: Bearer sk-master-key" \
-H "Content-Type: application/json" \
-d '{
"max_budget": 50.0,
"budget_duration": "monthly",
"models": ["gpt-4o", "claude-sonnet"],
"metadata": {"user": "developer-01"}
}'
Isso gerará uma chave virtual com um orçamento mensal máximo de US$ 50, permitindo apenas a invocação do GPT-4o e do Claude Sonnet.
Rastreamento de custos:
O LiteLLM possui uma tabela de preços integrada para cada modelo, calculando automaticamente os custos a cada invocação de API. No painel de gerenciamento do Proxy, você pode visualizar:
- Custo total por modelo
- Detalhamento de custos por usuário/equipe
- Tendências de custos por período
- Estatísticas de uso de tokens
💰 Otimização de custos: A funcionalidade de rastreamento de custos do LiteLLM ajuda a identificar quais invocações de modelo são mais caras. Combinado com as vantagens de preço da APIYI (apiyi.com), a mesma invocação de modelo pode obter preços mais competitivos, reduzindo ainda mais os custos operacionais da sua aplicação de IA.
Visão geral dos mais de 100 provedores de modelos suportados pelo LiteLLM
O número de provedores suportados pelo LiteLLM é vasto. Abaixo estão as categorias mais comuns:
| Categoria | Provedor | Prefixo do modelo | Modelos representativos |
|---|---|---|---|
| Modelos de Linguagem Grande comerciais | OpenAI | openai/ |
GPT-4o, GPT-4o-mini, o3 |
| Anthropic | anthropic/ |
Claude Opus 4, Sonnet 4, Haiku | |
gemini/ |
Gemini 2.0 Flash, Gemini 2.5 Pro | ||
| Plataformas em nuvem | Azure OpenAI | azure/ |
Série GPT implantada no Azure |
| AWS Bedrock | bedrock/ |
Claude/Llama hospedado no Bedrock | |
| Google Vertex AI | vertex_ai/ |
Gemini hospedado no Vertex | |
| Aceleração de inferência | Groq | groq/ |
Llama 3.1 70B (inferência ultra rápida) |
| Together AI | together_ai/ |
Diversos modelos open source | |
| Fireworks AI | fireworks_ai/ |
Inferência de alto desempenho | |
| Implantação local | Ollama | ollama/ |
Llama/Mistral rodando localmente |
| vLLM | openai/ (base customizada) |
Motor de inferência auto-hospedado | |
| Modelos nacionais | Deepseek | deepseek/ |
Deepseek Chat/Coder |
| Busca aprimorada | Perplexity | perplexity/ |
Sonar Pro |
| Plataformas agregadoras | OpenRouter | openrouter/ |
Diversos modelos |
🎯 Sugestão de escolha: A escolha do modelo depende do cenário específico. Se você não tiver certeza de qual modelo usar, pode testar rapidamente os resultados de diferentes modelos através da plataforma APIYI (apiyi.com), que também suporta a invocação via interface compatível com OpenAI para a maioria dos modelos mencionados acima.
FAQ de Perguntas Frequentes sobre o LiteLLM
Q1: Qual é a diferença entre o LiteLLM e usar o SDK da OpenAI diretamente?
O SDK da OpenAI só permite invocar modelos da OpenAI. O LiteLLM estende essa funcionalidade, permitindo que você utilize o mesmo formato de código para invocar mais de 100 provedores de modelos, como Anthropic, Google, Azure, entre outros. Se o seu projeto utiliza apenas modelos da OpenAI, o SDK da OpenAI é suficiente. No entanto, se você precisa de suporte a múltiplos modelos, failover ou controle de custos, o LiteLLM é a melhor escolha.
Q2: O LiteLLM é gratuito?
As funcionalidades principais do LiteLLM são totalmente open-source e gratuitas (licença MIT). Mas atenção: o LiteLLM em si é gratuito, porém as APIs dos modelos que ele invoca são pagas. Você precisa obter sua própria chave API diretamente com a OpenAI, Anthropic, etc., e pagar pelos custos da invocação do modelo. Se não quiser gerenciar várias chaves API separadamente, você também pode usar plataformas de interface unificada como a APIYI (apiyi.com) para simplificar o gerenciamento de chaves.
Q3: Que tipo de configuração de servidor o LiteLLM Proxy exige?
O LiteLLM Proxy é bastante leve; um servidor com 1 núcleo e 1 GB de RAM é suficiente para rodá-lo. No entanto, se você precisar de funcionalidades completas (rastreamento de custos, gerenciamento de chaves virtuais), precisará de um banco de dados PostgreSQL e Redis. Para ambientes de produção, recomendamos pelo menos 2 núcleos, 4 GB de RAM, PostgreSQL e Redis.
Q4: Qual é a diferença entre o LiteLLM e o OpenRouter?
A maior diferença é: o LiteLLM é uma solução open-source para auto-hospedagem, enquanto o OpenRouter é um serviço gerenciado.
- LiteLLM: Gratuito, você mesmo hospeda, gerencia suas próprias chaves API e tem controle total sobre o fluxo de dados.
- OpenRouter: Pronto para uso, mas com um acréscimo no preço da invocação da API, e os dados passam por terceiros.
Se você valoriza a privacidade dos dados ou já possui suas próprias chaves API, escolha o LiteLLM. Se deseja usar algo rapidamente sem precisar de implantação, considere soluções gerenciadas como a APIYI (apiyi.com).
Q5: O LiteLLM suporta streaming?
Sim. Tanto no modo SDK quanto no modo Proxy, o LiteLLM suporta totalmente o streaming SSE. As respostas em streaming de todos os provedores são convertidas uniformemente para o formato de chunk da OpenAI, garantindo uma experiência de streaming consistente.
# Exemplo de streaming com LiteLLM
stream = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Escreva uma história"}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
Q6: Como iniciante, devo escolher o modo SDK ou o modo Proxy?
Se você é um desenvolvedor Python e está começando agora, o modo SDK é o mais simples — basta um pip install litellm e algumas linhas de código para começar. Quando precisar de colaboração em equipe, integração com múltiplas linguagens ou implantação em produção, você pode migrar para o modo Proxy. A forma principal de invocação é consistente entre os dois modos, tornando a migração muito simples.
Q7: Onde devo colocar o arquivo de configuração config.yaml do LiteLLM?
Não há um local fixo. Ao iniciar o Proxy, basta especificar o caminho através do parâmetro --config:
litellm --config /caminho/para/seu/config.yaml
Geralmente, recomendamos colocá-lo no diretório raiz do projeto ou em uma pasta de configuração dedicada. Se estiver usando Docker, monte o arquivo no container via volume.
Guia de Decisão Rápida do LiteLLM
Escolha a solução mais adequada de acordo com a sua situação:
| Sua situação | Solução recomendada | Motivo |
|---|---|---|
| Desenvolvedor individual, projeto Python | LiteLLM SDK | Sem implantação, pronto em 5 minutos |
| Desenvolvimento em equipe, precisa de controle de orçamento | LiteLLM Proxy | Chaves virtuais + rastreamento de custos |
| Não quer gerenciar infraestrutura própria | APIYI (apiyi.com) | Serviço gerenciado, pronto para usar |
| Sistema com múltiplos Agentes | LiteLLM Proxy | Roteamento unificado + balanceamento de carga |
| Usa apenas modelos da OpenAI | SDK da OpenAI direto | Sem camadas adicionais |
| Foco em privacidade de dados | LiteLLM auto-hospedado | Dados não passam por terceiros |
Resumo
O LiteLLM é uma ferramenta de infraestrutura extremamente prática no desenvolvimento de aplicações de IA. O seu valor central pode ser resumido em uma frase: use um único formato de código compatível com OpenAI para invocar APIs de mais de 100 provedores de modelos.
Para quem está começando, vale a pena guardar estes pontos principais:
- O LiteLLM é um "tradutor": ele ajuda a traduzir solicitações em um formato unificado para o formato de API específico de cada modelo.
- Dois modos de operação: SDK (pacote Python leve) e Proxy (servidor de gateway independente).
- Valor central: interface unificada + Fallback + balanceamento de carga + rastreamento de custos.
- Padrão em frameworks de agentes: LangChain, CrewAI, AutoGen e outros oferecem suporte nativo ao LiteLLM.
- Totalmente open source e gratuito: licença MIT, sem custos para auto-hospedagem.
Se você acha que o custo operacional de manter um Proxy LiteLLM próprio é muito alto, também pode utilizar serviços de interface unificada gerenciados, como o APIYI (apiyi.com). Eles permitem alcançar o mesmo resultado — usar uma única chave para invocar todos os modelos principais — eliminando a carga de implantação e manutenção.
Autor do artigo: Equipe técnica da APIYI
Troca de conhecimentos: Acesse o APIYI em apiyi.com para obter mais tutoriais de invocação de modelos de IA e suporte técnico.
Data de atualização: Abril de 2026
Versão aplicável: LiteLLM v1.x+
Referências:
- Documentação oficial do LiteLLM: docs.litellm.ai
- Repositório GitHub do LiteLLM: github.com/BerriAI/litellm
- Site oficial do LiteLLM: litellm.ai
- Site oficial da BerriAI: berri.ai