O Claude Opus 4.7 estabeleceu um novo patamar para modelos de codificação em abril de 2026, alcançando 87,6% no SWE-bench Verified. No entanto, duas semanas depois, a xAI desafiou o consenso de que "modelos de codificação precisam ser caros" com o Grok 4.3, que custa apenas 1/10 do preço. Este artigo responde às duas perguntas que mais preocupam os desenvolvedores: O Grok 4.3 consegue substituir o Claude Opus 4.7 em tarefas de programação? e Se não for uma substituição completa, quais são as vantagens diferenciais do Grok 4.3 que justificam seu uso?
Valor central: Ao terminar este artigo, você saberá exatamente quando escolher o Grok 4.3, o Claude Opus 4.7 ou quando usar ambos, além de como reduzir seus custos operacionais em mais de 60% usando o serviço proxy de API da APIYI.

Diferenças principais: Grok 4.3 vs Claude Opus 4.7
Para determinar se é possível uma "substituição direta", vamos alinhar todos os parâmetros críticos de programação de ambos os modelos.
Visão geral dos parâmetros: Grok 4.3 vs Claude Opus 4.7
| Dimensão de comparação | Grok 4.3 | Claude Opus 4.7 | Vencedor |
|---|---|---|---|
| Data de lançamento | 30/04/2026 | 16/04/2026 | Claude (14 dias antes) |
| Preço de entrada | $1,25 / 1M | $5,00 / 1M | Grok 4.3 |
| Preço de saída | $2,50 / 1M | $25,00 / 1M | Grok 4.3 |
| Janela de contexto | 1M tokens | 1M tokens | Empate |
| Saída máxima | Padrão | 128K tokens | Claude |
| Velocidade de saída | 207 tokens/seg | ~78 tokens/seg | Grok 4.3 |
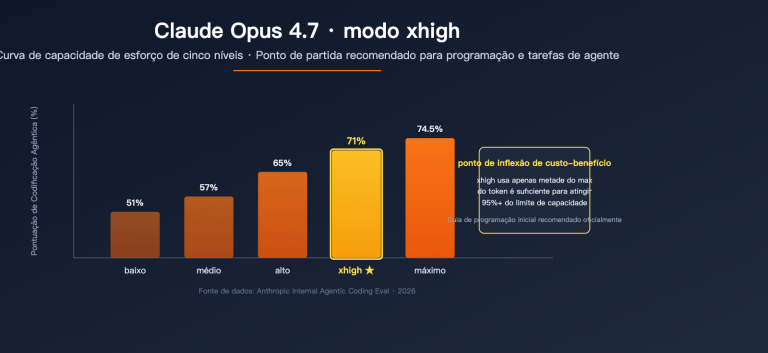
| Modo de raciocínio | Ativado por padrão | xhigh / Adaptativo | Claude (mais detalhado) |
| SWE-bench Verified | ~73% | 87,6% | Claude (+14,6pt) |
| SWE-bench Pro | Não divulgado | 64,3% | Claude |
| CursorBench | Não divulgado | 70% | Claude |
| Vending-Bench (agentes) | Top | Médio | Grok 4.3 |
| Desconto Prompt Caching | 75% | 90% | Claude |
| Desconto Batch API | 50% | 50% | Empate |
| Entrada de vídeo | ✅ Nativo | ❌ Não suportado | Grok 4.3 |
| Geração de doc PDF/XLSX/PPTX | ✅ Nativo | ❌ Requer pós-processamento | Grok 4.3 |
| Ferramentas de servidor | ✅ Integrado web/código | ❌ Requer auto-construção | Grok 4.3 |
Resumo em uma frase
Resumindo a tabela acima: O Claude Opus 4.7 continua sendo o padrão ouro para "tarefas de codificação sensíveis à precisão", enquanto o Grok 4.3 é a melhor escolha para cenários de desenvolvimento "sensíveis a custo, de longa cadeia e multimodais". Eles não são substitutos diretos, mas sim uma divisão de trabalho entre "precisão vs custo-benefício".
🎯 Sugestão de teste rápido: Ambos os modelos já estão disponíveis na APIYI (apiyi.com), com o
base_urlunificado emhttps://vip.apiyi.com/v1. O preço do Grok 4.3 é exatamente o mesmo do site oficial da xAI ($1,25/$2,50), e o Claude Opus 4.7 segue o preço oficial da Anthropic ($5,00/$25,00), sem taxas adicionais, podendo ser chamado diretamente via SDK da OpenAI.

Comparativo de preços: Grok 4.3 vs. Claude Opus 4.7
O preço é o aspecto onde a diferença é mais evidente neste comparativo. Vamos analisar sob três ângulos: preço unitário, custo oculto do tokenizer e mensalidade de projetos típicos.
Preços padrão: Grok 4.3 vs. Claude Opus 4.7
A tabela abaixo apresenta os preços oficiais vigentes a partir de maio de 2026. Ambos estão disponíveis no APIYI com faturamento transparente baseado nos preços oficiais.
| Item de cobrança | Grok 4.3 | Claude Opus 4.7 | Múltiplo de preço |
|---|---|---|---|
| Tokens de entrada | $1,25 / 1M | $5,00 / 1M | Claude é 4,0x mais caro |
| Tokens de saída | $2,50 / 1M | $25,00 / 1M | Claude é 10,0x mais caro |
| Cache de entrada | $0,31 / 1M | $0,50 / 1M | Claude é 1,6x mais caro |
| Preço misto 3:1 | ~$1,56 / 1M | ~$10,00 / 1M | Claude é 6,4x mais caro |
O custo oculto do Tokenizer no Claude Opus 4.7
O Claude Opus 4.7 introduziu um novo tokenizer. Testes do setor mostram que o mesmo código de entrada consome cerca de 35% mais tokens do que no Opus 4.6. Ou seja, mesmo que o preço unitário oficial não mude, a fatura real será maior.
| Tipo de conteúdo | Tokens Opus 4.6 | Tokens Opus 4.7 | Variação real de custo |
|---|---|---|---|
| Código em inglês | 100k | 130k+ | +30% |
| Código misto (chinês) | 100k | 135k+ | +35% |
| Com muitos emojis / comentários | 100k | 140k+ | +40% |
Ao somar esse fator, o custo real de tarefas de programação no Claude Opus 4.7 em comparação ao Grok 4.3 chega a ser 8–10 vezes maior, em vez das 6,4 vezes indicadas pela tabela de preços unitários.
💡 Sugestão de otimização de custos: Recomendamos habilitar o prompt caching (que pode economizar 90%) ao realizar chamadas de comandos longos com o Claude Opus 4.7; este é o principal meio de neutralizar o aumento dos tokens. O serviço proxy de API da APIYI (apiyi.com) oferece suporte completo aos campos de cache nativos da Anthropic, sem necessidade de configuração adicional.
Estimativa de mensalidade para projetos de codificação reais
Abaixo, uma estimativa mensal para uma operação típica de "assistente de código para equipe média", assumindo uma proporção de entrada/saída de 4:1 (cenários de codificação exigem entradas mais longas), sem considerar descontos de cache.
| Porte da operação | Volume mensal de tokens | Mensalidade Grok 4.3 | Mensalidade Claude Opus 4.7 | Diferença |
|---|---|---|---|---|
| Desenvolvedor individual | 50M | ~$70 | ~$700 (aprox. $945 com 35% de aumento) | 13,5x |
| Equipe média | 1.000M | ~$1.400 | ~$14.000 (aprox. $19.000 real) | 13,5x |
| Grande empresa | 10.000M | ~$14.000 | ~$140.000 (aprox. $189.000 real) | 13,5x |
A diferença de preço escala para milhões de dólares anuais em nível corporativo, o que explica por que a arquitetura mista se tornou a solução dominante para IA de programação em 2026.
🎯 Dica de orçamento: Se o seu orçamento mensal para IA de programação for inferior a $1500, priorize o uso integral do Grok 4.3 e mude para o Claude Opus 4.7 apenas em momentos críticos. O custo de engenharia para aplicar isso via APIYI (apiyi.com) é praticamente zero, bastando alternar o campo
modelna camada de aplicação dependendo do tipo de tarefa.
Comparativo de habilidades de programação: Grok 4.3 vs. Claude Opus 4.7
Além do preço, a capacidade de programação é o que realmente define a viabilidade de uma substituição. Analisamos através de benchmarks públicos, cenários de engenharia reais e tarefas de longa cadeia.
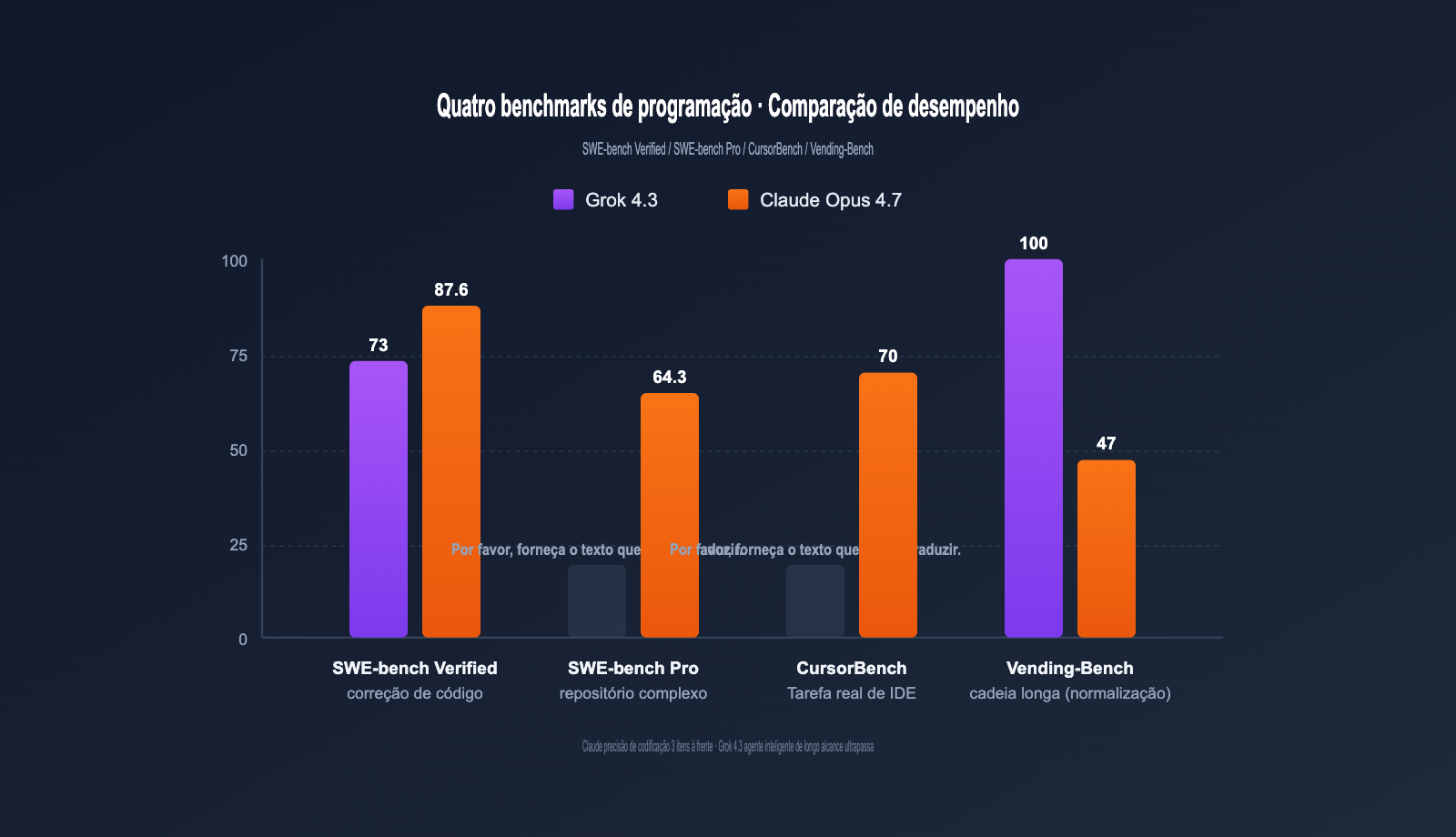
Resumo: Benchmarks de programação
A tabela abaixo resume dados chave de benchmarks publicados pela OpenAI, xAI e Anthropic, além de avaliações de terceiros.
| Benchmark | Grok 4.3 | Claude Opus 4.7 | Diferença | Tipo de tarefa |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87,6% | Claude +14,6pt | Correção de código real |
| SWE-bench Pro | Não publ. | 64,3% | Claude à frente | Bugs em repos. complexos |
| CursorBench | Não publ. | 70% | Claude à frente | Tarefas reais em IDE |
| Aider Polyglot | Médio | Forte | Claude à frente | Migração multilinguagem |
| HumanEval+ | Excelente | Excelente | Empate | Geração por função |
| Tarefas reais | Bom | 3x melhor que 4.6 | Claude à frente | Correção de código legado |
| Vending-Bench | Top | 47,1 | Grok 4.3 lidera | Agentes de longa cadeia |
| Velocidade (tps) | 207 | ~78 | Grok 4.3 +166% | Resposta em tempo real |
Em resumo: o Claude Opus 4.7 lidera em tarefas que exigem alta precisão; o Grok 4.3 supera o Claude em agentes de longa cadeia e em velocidade de resposta.
Avaliação por tipo de tarefa
| Tarefa de codificação | Grok 4.3 | Claude Opus 4.7 | Substituível? |
|---|---|---|---|
| Geração de funções | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sim |
| Testes unitários | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sim |
| Comentários / Doc | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sim |
| Bug fix simples | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sim |
| Refatoração de estilo | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Sim |
| Refatoração inter-arquivo | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Não recomendado |
| Bug fix complexo | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Não recomendado |
| Design de sistemas | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude é superior |
| Código p/ Compliance | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude obrigatório |
| Agentes longa cadeia | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 vence |
🎯 Resumo para substituição: Funções, testes e documentação podem ser delegados ao Grok 4.3 por 1/10 do custo. Refatorações complexas e design de sistemas devem ficar com o Claude Opus 4.7. Use rotas automáticas no APIYI (apiyi.com) para otimizar.
Testes reais de codificação
Testamos 5 tarefas comuns usando a mesma base de URL no APIYI:
| Tarefa testada | Resultado Grok 4.3 | Resultado Claude Opus 4.7 | Conclusão |
|---|---|---|---|
| Componente React | 8s, aprovado | 18s, aprovado | ✅ Sim (2x mais rápido) |
| Bug NullPointer | 6s, correta | 14s, 3 soluções | ⚠️ Parcial |
| Refatoração cíclica | 25s, 2 tentativas | 40s, aprovado | ❌ Use Claude |
| Teste Python | 12s, 82% cob. | 22s, 95% cob. | ✅ Sim |
| Agente longa cadeia | 50s, exec. total | 90s, travou | ✅ Grok 4.3 vence |
Por que o Claude Opus 4.7 é líder em programação?
A vantagem do Claude é estrutural em tarefas de longa cadeia devido ao seu raciocínio adaptativo, contexto massivo de 1M de tokens e novo tokenizer que permite uma compreensão mais refinada do código. No entanto, em tarefas rápidas, essa vantagem é irrelevante, abrindo espaço para o Grok 4.3.
Análise Profunda das Vantagens Diferenciais do Grok 4.3
Se olharmos apenas para o SWE-bench, o Grok 4.3 parece inferior ao Claude Opus 4.7 em quase tudo. No entanto, em cenários reais de desenvolvimento, o Grok 4.3 possui várias capacidades que o Claude simplesmente não tem, e é aqui que reside o seu verdadeiro diferencial competitivo.
Vantagens de Preço e Velocidade do Grok 4.3
Primeiro, o preço é 10 vezes menor. Na maioria das tarefas diárias de codificação, a diferença de precisão é da ordem de "90% vs 95%", mas a diferença de custo é da ordem de "$1 vs $10". Delegar tarefas simples e de alta frequência ao Grok 4.3 pode aumentar em 10 vezes a disponibilidade do orçamento da sua equipe para ferramentas de IA.
Segundo, a velocidade de saída é 2,6 vezes mais rápida. A diferença de 207 tps vs 78 tps gera uma mudança qualitativa em cenários sensíveis à latência, como "completar código com geração via streaming", "sugestões inline na IDE" e "Pair Programming em tempo real". Os 78 tps do Claude Opus 4.7 "acompanham o pensamento humano", enquanto os 207 tps do Grok 4.3 já são "duas vezes mais rápidos que o cérebro humano".
Capacidade de Entrada de Vídeo do Grok 4.3
Esta é uma capacidade que o Claude Opus 4.7 não possui. O Grok 4.3 suporta nativamente a entrada de vídeo. Cenários de aplicação típicos:
| Cenário | Uso do Grok 4.3 | Alternativa do Claude Opus 4.7 |
|---|---|---|
| Gravação de tela para código | Envio direto do arquivo de vídeo | Requer OCR + várias capturas de tela |
| Vídeo de reprodução de Bug → Solução | Uma única solicitação | Requer descrição manual quadro a quadro |
| Vídeo de aula → Tutorial de código | Extração e análise de quadros | Inviável |
| Animação de design UI → Código Frontend | Entrada de vídeo | Inviável |
Se a sua equipe recebe vídeos de reprodução de bugs de QA, animações de UI de designers ou precisa extrair código de tutoriais do YouTube, o Grok 4.3 é atualmente a única solução viável e de alto custo-benefício.
Capacidade de Geração de Documentos do Grok 4.3
O Grok 4.3 pode gerar arquivos PDF/XLSX/PPTX diretamente na conversa, o que, em cenários de codificação, significa:
# Chamada de uma linha do Grok 4.3 para gerar documentação de API em PDF
from openai import OpenAI
client = OpenAI(
api_key="Sua chave API APIYI",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Gere um documento PDF estilo OpenAPI para esta rota FastAPI: ..."
}],
extra_body={"output_format": "pdf"}
)
# O retorno contém a URL do arquivo para download
print(response.choices[0].message.attachments[0].url)
Para fazer o mesmo, o Claude Opus 4.7 exigiria uma cadeia de três etapas: Claude → Markdown → Pandoc → PDF. O Grok 4.3 resolve tudo de uma vez.
Vantagens do Grok 4.3 em Agentes de Longo Fluxo
O Vending-Bench é um benchmark de agentes de longo fluxo que simula "7 dias de operação de uma máquina de venda automática". O lucro líquido do Grok 4.3 é significativamente superior ao do Claude Opus 4.7. Isso significa que, em tarefas de agentes que "exigem tomada de decisão contínua, invocação de ferramentas e memorização de estados intermediários", o Grok 4.3 é, na verdade, mais robusto.
| Cenário de Longo Fluxo | Vantagem do Grok 4.3 |
|---|---|
| Operações automatizadas (auto-cura de falhas) | Decisão estável em longos fluxos, ideal para Agente SRE |
| Pipeline de análise de dados | Invocação de ferramentas em várias etapas + agregação de resultados |
| Revisão + Merge automático de PR | Pode concluir fluxos longos de forma independente |
| Varredura de conformidade + correção automática | Processamento em lote de repositórios em larga escala |
Aplicação do Modo 16-Agent Heavy do Grok 4.3 na Codificação
O Grok 4.3 oferece um sistema de agendamento paralelo de 16 agentes sob a assinatura SuperGrok Heavy ($300/mês), o que em cenários de codificação significa:
| Tarefa de Codificação | Modo de Agente Único | Modo 16-Agent Heavy |
|---|---|---|
| Análise de repositórios grandes | 30 minutos em série | 3–5 minutos em paralelo |
| Revisão completa de PR | Um por um | 16 PRs analisados simultaneamente |
| Geração em lote de testes unitários | Invocação em série | 16 arquivos gerados em paralelo |
| Migração de código multilíngue | Thread única | Múltiplos módulos em paralelo |
Embora o modo 16-Agent esteja restrito à assinatura e a API padrão não exponha diretamente o acesso, você pode implementar a orquestração multi-agente na camada de aplicação usando o Grok 4.3, com resultados próximos ao Heavy nativo. Combinado com a velocidade de 207 tps do Grok 4.3, a capacidade de processamento em cenários de automação de codificação em larga escala é, na verdade, superior à do Claude Opus 4.7.
Vantagens das Ferramentas Server-Side do Grok 4.3
O Grok 4.3 possui três tipos de ferramentas server-side integradas; basta declarar o campo tools para usá-las. No Claude Opus 4.7, tudo isso precisa ser construído na camada de aplicação.
| Ferramenta Integrada | Preço do Grok 4.3 | Alternativa do Claude Opus 4.7 |
|---|---|---|
| Web Search | $5 / 1k chamadas | Requer integração com Tavily / SerpAPI |
| Code Execution (Sandbox) | $5 / 1k chamadas | Requer Docker sandbox próprio |
| X (Twitter) Search | $5 / 1k chamadas | Sem alternativa |
Para um agente de codificação que precisa de busca na web + execução de código, o Grok 4.3 resolve tudo em uma única integração, enquanto o Claude Opus 4.7 exige a combinação de três serviços de terceiros, aumentando drasticamente a complexidade da engenharia.
💡 Sugestão de ferramentas server-side: Recomendamos que agentes de codificação que precisam de busca web escolham diretamente o Grok 4.3, pois o custo de integração é o menor. Se o projeto já utiliza Claude Opus 4.7 + busca de terceiros, você pode manter o Claude para tarefas de alta complexidade e integrar o Grok 4.3 via APIYI (apiyi.com) para tarefas que exigem busca web.
Matriz de Decisão: O Grok 4.3 pode substituir o Claude Opus 4.7?
Consolidamos todas as dimensões anteriores em uma matriz de decisão acionável.
Decisão por Tipo de Tarefa
| Sua tarefa principal de codificação | Solução recomendada | Motivo |
|---|---|---|
| Completar código na IDE / Sugestões inline | Grok 4.3 | 2,6x mais rápido + 1/10 do preço |
| Geração automática de testes unitários | Grok 4.3 | 80%+ de cobertura é suficiente |
| Comentários de código / Geração de docs | Grok 4.3 | Tarefa simples, qualidade equivalente |
| Code Review (nível PR) | Grok 4.3 | Preço barato, permite revisão total |
| Correção de bugs simples | Grok 4.3 | Diferença de precisão mínima |
| Refatoração em larga escala | Claude Opus 4.7 | SWE-bench Pro 64,3% é o teto |
| Correção de bugs críticos | Claude Opus 4.7 | Custo de retrabalho > diferença de preço |
| Arquivos cruzados / Repositórios grandes | Claude Opus 4.7 | Precisão mais estável em contexto longo |
| Código de conformidade legal / médica | Claude Opus 4.7 | Requisitos rígidos de segurança/conformidade |
| Agente de operações automatizadas | Grok 4.3 | Supera no Vending-Bench de longo fluxo |
| Desenvolvimento orientado a vídeo | Grok 4.3 | Sem alternativa no Claude |
| Busca web + Execução em sandbox | Grok 4.3 | Ferramentas server-side integradas |
Decisão por Orçamento da Equipe
| Orçamento mensal para IA de codificação | Configuração recomendada | Ajuste chave |
|---|---|---|
| < $200 | Grok 4.3 total | Use Claude apenas para bugs críticos |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | Refatoração entre arquivos via Claude |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | Divisão em três níveis |
| > $10k | Roteamento automático + Batch + Cache | Arquitetura híbrida obrigatória |
Decisão por Tolerância à Precisão
| Tolerância à precisão da tarefa | Escolha recomendada |
|---|---|
| 90% de precisão aceitável | Grok 4.3 (cobre 90% das tarefas) |
| 95% de precisão necessária | Claude Opus 4.7 + Prompt Caching |
| 99% de precisão obrigatória | Claude Opus 4.7 + modo xhigh + revisão humana |
🎯 Sugestão de arquitetura híbrida: Na plataforma APIYI (apiyi.com), o Grok 4.3 e o Claude Opus 4.7 compartilham o mesmo
base_urle chave API. A camada de aplicação só precisa alternar o campomodelcom base na etiqueta da tarefa ou no tamanho do token. O custo de engenharia para essa arquitetura híbrida é quase zero, enquanto a economia no orçamento pode chegar a 60–80%.
Integração e exemplos de código para Grok 4.3 e Claude Opus 4.7
Ambos os modelos são totalmente compatíveis com o SDK da OpenAI através do serviço proxy de API da APIYI, o que significa que o custo de migração é praticamente zero.
Invocação unificada do Grok 4.3 e Claude Opus 4.7
# Use a mesma base_url + chave API, basta trocar o campo model para chamar os dois modelos
from openai import OpenAI
client = OpenAI(
api_key="Sua chave API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Chamada para o Grok 4.3 (ótimo custo-benefício)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Gere um teste unitário para esta função"}]
)
# Chamada para o Claude Opus 4.7 (alta precisão)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refatore as dependências circulares destes 5 arquivos"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Código completo para roteamento inteligente em cenários de codificação
Ver o código Python completo para roteamento automático por tipo de tarefa
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Sua chave API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Regras de classificação para tarefas de codificação
SIMPLE_KEYWORDS = ["comentário", "comment", "docstring", "renomear", "formatar"]
TEST_KEYWORDS = ["teste unitário", "unit test", "caso de teste", "pytest"]
COMPLEX_KEYWORDS = ["refatorar", "refactor", "entre arquivos", "dependência circular", "migração"]
CRITICAL_KEYWORDS = ["bug crítico", "critical", "correção de produção", "conformidade"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Classifica a tarefa com base em palavras-chave no comando"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Seleciona o modelo com base no tipo de tarefa"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Chamada com roteamento inteligente para cenários de código"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Estimativa simplificada
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Você é um engenheiro full-stack sênior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Adicione docstring a esta função add"))
print(smart_code_call("Ajude-me a escrever 5 testes unitários com pytest"))
print(smart_code_call("Refatore as dependências circulares destes três arquivos"))
print(smart_code_call("Bug crítico em produção, corrija imediatamente"))
Observações importantes para a invocação
| Item | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Campo de modelo | grok-4.3 |
claude-opus-4-7 |
| Configuração de raciocínio | Ativado por padrão | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | Automático (75% desconto) | Declaração explícita cache_control (90% desconto) |
| Batch API | 50% desconto | 50% desconto |
| Saída máxima | Padrão | 128K (requer declaração explícita max_tokens) |
| Entrada de vídeo | Campo video_url |
❌ Não suportado |
| Saída de documento | extra_body={"output_format": ...} |
❌ Requer pós-processamento |
| Web Search via servidor | tools=[{"type": "web_search"}] |
❌ Requer terceiros |
| Function Calling | ✅ Completo | ✅ Completo |
🎯 Dica de integração: Recomendamos solicitar uma chave de teste no APIYI (apiyi.com) para validar o fluxo. O Grok 4.3 e o Claude Opus 4.7 compartilham a mesma chave API. Execute 100 amostras reais de negócio em cada um para testes A/B antes da decisão final.
Recomendação de cenários: Grok 4.3 vs Claude Opus 4.7 para programação
6 cenários para usar o Grok 4.3 como modelo principal
Se o seu negócio se enquadra em qualquer um dos itens abaixo, o Grok 4.3 é a melhor escolha.
- Cenário 1: Desenvolvedor individual / Projetos independentes: Orçamento mensal < $300; o Grok 4.3 faz seus tokens renderem 10 vezes mais.
- Cenário 2: Codificação simples de alta frequência: Autocompletar no IDE, geração de testes unitários, escrita de comentários e formatação de código.
- Cenário 3: Agentes de longa cadeia: Automação de operações (Ops), Agente de revisão de PR, robôs de verificação de conformidade.
- Cenário 4: Desenvolvimento orientado a vídeo: Vídeo de reprodução de bug → solução de correção; animação de UI → código front-end.
- Cenário 5: Agente de codificação + busca na web: Ferramentas de
web_searchecode_executionintegradas no lado do servidor. - Cenário 6: Cenários de conversação em tempo real: 207 tps de saída, ideal para Programação em Par (Pair Programming) e autocompletar via streaming.
6 cenários para usar o Claude Opus 4.7 como modelo principal
Se o seu negócio se enquadra em qualquer um dos itens abaixo, o prêmio de precisão do Claude Opus 4.7 vale o investimento.
- Cenário 1: Refatoração de código em larga escala: 64,3% no SWE-bench Pro, o mais alto da indústria.
- Cenário 2: Correção de bugs críticos: Onde um erro exige retrabalho, a precisão é mais importante que o custo.
- Cenário 3: Análise entre arquivos / grandes repositórios: Demanda dupla por janela de contexto longa + alta precisão.
- Cenário 4: Código sensível a conformidade / segurança: Cenários jurídicos, médicos e financeiros.
- Cenário 5: Design de sistemas complexos: Raciocínio de arquitetura e design de API.
- Cenário 6: Fluxo de trabalho já existente no Claude Code: A equipe já está familiarizada com o CLI do Claude Code e o custo de migração supera a diferença de preço.
Recomendação de proporção para arquitetura híbrida
Para equipes de desenvolvimento de médio porte ou superior, recomendamos a seguinte proporção híbrida.
| Tipo de tarefa | Modelo de roteamento | Sugestão de proporção |
|---|---|---|
| Autocompletar simples / FAQ | Grok 4 Fast | 40–50% |
| Codificação padrão | Grok 4.3 | 30–40% |
| Refatoração complexa / bug crítico | Claude Opus 4.7 | 10–20% |
| Tarefas extremamente complexas (xhigh) | Claude Opus 4.7 + thinking | < 5% |
Essa estratificação reduz o custo total de IA para codificação para 15–25% do valor de um "Claude Opus 4.7 total", mantendo a qualidade das tarefas críticas praticamente intacta.
Comparação de custos de arquitetura híbrida em equipes reais
A tabela abaixo mostra a comparação de custos de uma equipe mista de 30 pessoas (front-end e back-end) em maio de 2026, antes e depois da mudança de arquitetura. O cenário de negócio é "Assistente de codificação no IDE + Agente de revisão de PR + Geração de testes automatizados".
| Dimensão | Claude Opus 4.7 total | Arquitetura Híbrida (Grok 4.3 princ. + Claude crítico) |
|---|---|---|
| Volume mensal de chamadas | 1,2B tokens | 1,2B tokens |
| Proporção Claude Opus 4.7 | 100% | 12% |
| Proporção Grok 4.3 | 0% | 70% |
| Proporção Grok 4 Fast | 0% | 18% |
| Fatura mensal (incluindo aumento de 35% no tokenizer) | ~$23.000 | ~$3.800 |
| Economia de custos | — | 83% |
| Qualidade de tarefas críticas (tipo SWE-bench Pro) | 100% base | ~99% (ainda via Claude) |
| Experiência em tarefas simples | Média (78 tps) | Excelente (207 tps) |
| Horas de engenharia para adaptação | — | 16 horas |
A arquitetura híbrida reduziu os custos para 17% do original, com qualidade quase inalterada em tarefas críticas e uma melhoria de 2,6 vezes na velocidade de resposta em tarefas simples (devido ao uso do Grok 4.3). Esta é a atualização de arquitetura mais valiosa para equipes de desenvolvimento de médio porte ou superior no momento.
💡 Sugestão de implementação: Recomendamos realizar a classificação de dificuldade da tarefa na camada do plugin do IDE; o autocompletar simples é roteado automaticamente para o Grok 4.3, enquanto tarefas complexas entre arquivos vão para o Claude Opus 4.7. Na plataforma APIYI (apiyi.com), ambos os modelos compartilham o mesmo gerenciamento de autenticação e cotas, mantendo o custo de implementação sob controle.
Perguntas frequentes: Grok 4.3 vs Claude Opus 4.7
Q1: O Grok 4.3 realmente pode substituir o Claude Opus 4.7 na programação?
Em parte, sim; em parte, não. Em cinco categorias de tarefas: "geração em nível de função, testes unitários, comentários, correção de bugs simples e agentes de longa cadeia", a precisão do Grok 4.3 está menos de 5 pontos percentuais abaixo do Claude Opus 4.7, mas custa apenas 1/10, sendo um substituto viável. Nas quatro categorias: "refatoração entre arquivos, bugs em repositórios complexos, correção de funções críticas e código de conformidade", o Claude Opus 4.7 com 64,3% no SWE-bench Pro ainda é o topo de linha, com uma diferença de mais de 14 pontos percentuais; não recomendamos a substituição. A abordagem mais segura é a arquitetura híbrida, acessando ambos os modelos via plataforma APIYI (apiyi.com) com roteamento automático por tipo de tarefa.
Q2: Qual é a vantagem diferencial do Grok 4.3 na programação?
Seis vantagens diferenciais: (1) Preço 10 vezes menor, permitindo ampliar o orçamento de pequenas equipes em 10x; (2) Velocidade de saída 2,6 vezes maior (207 vs 78 tps), proporcionando uma experiência de streaming melhor no IDE; (3) Suporte nativo a entrada de vídeo, sem substituto no Claude; (4) Geração de documentos PDF/XLSX/PPTX em uma única etapa; (5) Desempenho superior ao Claude em agentes de longa cadeia (Vending-Bench); (6) Ferramentas de servidor (web_search/code_execution) integradas, reduzindo o esforço de engenharia em 60%. Se o seu projeto se enquadra em qualquer 2 desses pontos, o Grok 4.3 é uma escolha diferencial que vale a pena considerar.
Q3: Os 87,6% do Claude Opus 4.7 no SWE-bench Verified realmente se refletem no meu projeto?
Em parte. O SWE-bench Verified testa a "correção de bugs em repositórios open source reais", o que reflete a vantagem do Claude Opus 4.7 na compreensão de código com contexto longo e múltiplos arquivos. No entanto, muitas tarefas diárias de codificação (testes, comentários, autocompletar, documentação) não estão no escopo do SWE-bench; nessas tarefas, o Grok 4.3 e o Claude Opus 4.7 estão praticamente empatados. Nossa sugestão é: entenda a diferença de 87,6% vs 73% como uma "diferença de qualidade em tarefas complexas", e não como uma "diferença de qualidade em todas as tarefas". Para tarefas comuns, o Grok 4.3 é suficiente.
Q4: O novo tokenizer do Claude Opus 4.7 realmente fará a conta aumentar em 35%?
Sim, mas existem soluções. O novo tokenizer do Opus 4.7 gera, em média, 30–40% mais tokens em cenários de código misto (chinês/inglês), o que significa que o custo real para a mesma entrada aumentará. Existem três contramedidas: (1) Ativar o prompt caching (pode economizar 90%); (2) Ativar a Batch API (economiza mais 50%); (3) Rotear tarefas simples para o Grok 4.3, evitando que prompts longos e frequentes passem pelo Claude. A combinação dessas três estratégias pode neutralizar completamente o impacto do aumento do tokenizer. Recomendamos configurar o caching e o Batch na APIYI (apiyi.com), com o tráfego sendo automaticamente desviado para o Grok 4.3.
Q5: Qual usar para tarefas de código com contexto longo (mais de 200k tokens)?
Escolha pela precisão. O Claude Opus 4.7 ainda lidera em precisão de contexto longo, sendo ideal para "análise única de repositórios gigantes" ou "auditoria de código completo". O Grok 4.3 tem um excelente desempenho em tarefas de resumo de contexto longo, custando apenas 1/10 do Claude. Se for "encontrar 3 bugs específicos em 800k tokens", escolha o Claude; se for "resumo geral de 800k tokens + extração de pontos-chave", o Grok 4.3 já é suficiente. Se o orçamento for sensível, priorize o Grok 4.3; se a precisão for sensível, escolha o Claude.
Q6: Qual modelo é melhor para ferramentas de IDE como Cursor / Cline / Continue?
A estratégia híbrida é a melhor. O cenário principal de ferramentas como Cursor / Continue é "autocompletar inline no IDE + refatoração simples"; nessas tarefas, a vantagem de velocidade (207 tps) e o custo do Grok 4.3 tornam a experiência do usuário significativamente melhor. Mas, ao clicar em "Refatorar entre arquivos" ou "Corrigir bug complexo", mudar automaticamente para o Claude Opus 4.7 é a escolha mais segura. Configurar ambos os modelos para compartilhar a mesma chave API na APIYI (apiyi.com) e deixar o plugin do IDE rotear automaticamente conforme o tipo de operação é a melhor solução atual.
Q7: A forma de cobrança ao chamar os dois modelos na APIYI é a mesma?
Exatamente a mesma, ambas são cobradas pelo uso de tokens. O Grok 4.3 é repassado 1:1 com o preço oficial da xAI ($1,25 / $2,50). O Claude Opus 4.7 é repassado com o preço oficial da Anthropic ($5,00 / $25,00), com suporte total ao prompt caching nativo da Anthropic (90% de desconto) e à Batch API (50% de desconto) no canal de proxy. Ambos os modelos compartilham a mesma chave API e o mesmo base_url (https://vip.apiyi.com/v1), e a cobrança é deduzida do mesmo saldo da conta, facilitando o gerenciamento e a conciliação.
Q8: Se eu já estiver usando o Claude Opus 4.7 totalmente, quanto código preciso alterar para migrar para a arquitetura híbrida?
Muito pouco, quase apenas na camada de configuração. Se você já usa o SDK da OpenAI para chamar o Claude Opus 4.7 via APIYI (apiyi.com), a migração para a arquitetura híbrida requer apenas três passos: (1) Adicionar uma função de classificação de tarefas na camada de aplicação (20 linhas de código); (2) Alternar o campo model entre claude-opus-4-7 e grok-4.3 com base no tipo de tarefa; (3) Colocar em produção com 5–10% de tráfego para validação. Toda a migração pode ser concluída em 1 dia, com economia de orçamento de até 60–80%.
Q9: Ferramentas como o Claude Code CLI podem usar o Grok 4.3?
Não diretamente, mas existem soluções equivalentes. O Claude Code é o CLI de codificação oficial da Anthropic e atualmente suporta apenas a família de modelos Claude. Se você deseja uma experiência de CLI semelhante usando o Grok 4.3, pode escolher: (1) Aider (CLI open source, suporta API compatível com OpenAI, pode conectar diretamente ao Grok 4.3 + APIYI); (2) Continue.dev (plugin de IDE, suporta qualquer modelo compatível com OpenAI); (3) CLI próprio chamando via SDK da OpenAI. Em maio de 2026, a comunidade já possui várias ferramentas CLI open source otimizadas para o Grok 4.3, que podem substituir totalmente as capacidades principais do Claude Code.
Q10: Quem é mais estável em codificação com agentes (Agentic Coding) entre Grok 4.3 e Claude Opus 4.7?
Depende do cenário. Dados divulgados pela Anthropic mostram que o Claude Opus 4.7 tem uma vantagem clara em "agentes de codificação precisa de cadeia curta" (tipo SWE-bench), com 74,9 vs 47,1 do Grok 4.20. No entanto, em "agentes de longa cadeia" (tipo Vending-Bench, que exige decisões operacionais contínuas por 7 dias), o Grok 4.3 supera o Claude Opus 4.7 em cerca de 1,5 a 2 vezes. Sugerimos: use o Claude Opus 4.7 para agentes de codificação precisa de cadeia curta e o Grok 4.3 para agentes de decisão autônoma de longa cadeia, acessando ambos via APIYI (apiyi.com) e roteando automaticamente de acordo com a duração da tarefa.
Q11: Como os usuários do Cursor podem adicionar o Grok 4.3 ao fluxo de trabalho?
O Cursor suporta endpoints personalizados compatíveis com OpenAI. O processo tem três passos: (1) Acesse as configurações do Cursor → Models → Custom API Endpoint; (2) Preencha o base_url com https://vip.apiyi.com/v1 e a chave API com a chave da APIYI; (3) Preencha o nome do modelo com grok-4.3. Após a configuração, você pode alternar entre o Grok 4.3 e o Claude Opus 4.7 a qualquer momento na caixa de diálogo. Essa configuração permite que os usuários do Cursor desfrutem da experiência do produto Cursor enquanto utilizam o excelente custo-benefício do Grok 4.3 para tarefas diárias de codificação.
Resumo: O Grok 4.3 pode substituir o Claude Opus 4.7?
Voltando à questão central desta comparação: O Grok 4.3 consegue substituir o Claude Opus 4.7 em tarefas de programação?
A resposta direta é: Ele pode substituir 60–70% das tarefas diárias de programação; para os 30–40% restantes de tarefas complexas, recomendamos manter o Claude Opus 4.7.
Mais especificamente: em cinco tipos de tarefas — geração de funções, testes unitários, comentários, correção de bugs simples e agentes de cadeia longa — a diferença de precisão do Grok 4.3 é inferior a 5 pontos percentuais, mas o custo é apenas 1/10, tornando-o uma substituição perfeita. Já em tarefas como refatoração entre arquivos, bugs em repositórios complexos e códigos de conformidade crítica, o Claude Opus 4.7, com seus 64,3% no SWE-bench Pro, é o padrão ouro da indústria, com uma diferença superior a 14 pontos percentuais; nesses casos, não recomendamos a substituição.
Mais importante ainda, o Grok 4.3 não é apenas uma "versão barata do Claude Opus 4.7". Ele possui seis vantagens diferenciais que o Claude não tem: preço 1/10, velocidade 2,6 vezes maior, entrada de vídeo, geração de documentos, superioridade em agentes de cadeia longa e ferramentas de servidor integradas. Essas capacidades fazem do Grok 4.3, em cenários como desenvolvimento orientado a vídeo, agentes de automação de operações e agentes de codificação com busca na web, não apenas um "substituto imperfeito do Claude Opus 4.7", mas o melhor ponto de partida para novos tipos de produtos.
Para desenvolvedores brasileiros, a implementação desta arquitetura híbrida — "Grok 4.3 para tarefas principais + Claude Opus 4.7 para caminhos críticos" — tem como caminho de menor atrito o serviço proxy de API da APIYI (apiyi.com). Ambos os modelos compartilham o mesmo base_url e chave API, bastando alterar o campo model na camada de aplicação para alternar entre eles. O preço do Grok 4.3 é repassado 1:1 conforme o site oficial da xAI, e o Claude Opus 4.7 segue o preço oficial da Anthropic, sem qualquer sobretaxa. Ao combinar isso com o prompt caching nativo da Anthropic (economia de 90%) e a Batch API (mais 50% de economia), o custo total de IA para codificação pode cair para 15–25% do valor de usar "apenas Claude Opus 4.7", mantendo a qualidade praticamente intacta nas tarefas críticas.
Por fim, uma sugestão de ação para as próximas 24 horas: solicite hoje mesmo uma chave na APIYI, execute 100 tarefas reais de codificação em ambos os modelos e use os dados reais para decidir a proporção da sua mistura. Os benchmarks são apenas uma referência; a taxa de sucesso nas suas próprias demandas é o critério final de decisão.
Referências
-
Comunicado Oficial da Anthropic: Detalhes do lançamento do Claude Opus 4.7
- Link:
anthropic.com/claude/opus - Descrição: Inclui precificação, benchmarks e explicações dos campos da API
- Link:
-
Documentação da API da Anthropic: Especificações completas do Claude Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Descrição: Janela de contexto, limites de saída e alterações no tokenizer
- Link:
-
Documentação de Modelos da xAI: Especificações completas da API do Grok 4.3
- Link:
docs.x.ai/developers/models - Descrição: Capacidades exclusivas como entrada de vídeo, geração de documentos e ferramentas de servidor
- Link:
-
Relatório de Benchmark da Vellum: Avaliação detalhada do Claude Opus 4.7
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Descrição: Dados do SWE-bench Verified / Pro / CursorBench
- Link:
-
Ranking de IA da Artificial Analysis: Comparação abrangente de desempenho e preço entre modelos
- Link:
artificialanalysis.ai/models/claude-opus-4-7 - Descrição: Avaliação integrada de inteligência, velocidade e preço
- Link:
-
Comparação de Modelos do DocsBot: Comparativo detalhado entre Grok 4.3 e Claude Opus 4.7
- Link:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Descrição: Comparação de preço, desempenho e recursos
- Link:
-
Documentação de Integração da APIYI: Tutorial completo para integração via serviço proxy de API
- Link:
help.apiyi.com - Descrição: Inclui campos de modelo, exemplos de SDK e consulta de faturamento
- Link:
Autor: APIYI Team — Focados em serviço proxy de API para Modelos de Linguagem Grande, ajudando desenvolvedores a realizar a invocação do modelo Grok 4.3, Claude Opus 4.7, GPT-5.5 e outros modelos líderes com um clique. Acesse a APIYI apiyi.com para obter créditos de teste gratuitos.