Claude Opus 4.7 在 2026 年 4 月以 SWE-bench Verified 87.6% 的成绩刷新了编码模型天花板,而两周后 xAI 用价格只有它 1/10 的 Grok 4.3 直接挑战「编码模型必须贵」的共识。本文回答开发者最关心的两个问题: Grok 4.3 在编程任务上能不能平替 Claude Opus 4.7? 以及 如果不能完全平替,Grok 4.3 还有什么差异化优势值得我们用?
核心价值: 看完本文,你将明确在你具体的编码场景下,该选择 Grok 4.3、Claude Opus 4.7,还是两者混用,以及如何通过 API易 中转通道把整体成本压低 60% 以上。

Grok 4.3 vs Claude Opus 4.7 核心差异
要判断「能否平替」,我们先把两款模型在编程相关维度上的全部关键参数对齐。
Grok 4.3 vs Claude Opus 4.7 参数总览
| 对比维度 | Grok 4.3 | Claude Opus 4.7 | 胜出方 |
|---|---|---|---|
| 发布时间 | 2026-04-30 | 2026-04-16 | Claude (早 14 天) |
| 输入价格 | $1.25 / 1M | $5.00 / 1M | Grok 4.3 |
| 输出价格 | $2.50 / 1M | $25.00 / 1M | Grok 4.3 |
| 上下文窗口 | 1M tokens | 1M tokens | 平 |
| 最大输出 | 标准 | 128K tokens | Claude |
| 输出速度 | 207 tokens/秒 | ~78 tokens/秒 | Grok 4.3 |
| reasoning 模式 | 默认开启 | xhigh / 自适应 | Claude (更细) |
| SWE-bench Verified | ~73% | 87.6% | Claude (+14.6pt) |
| SWE-bench Pro | 未公开 | 64.3% | Claude |
| CursorBench | 未公开 | 70% | Claude |
| Vending-Bench (智能体) | 顶级 | 中等 | Grok 4.3 |
| Prompt Caching 折扣 | 75% | 90% | Claude |
| Batch API 折扣 | 50% | 50% | 平 |
| 视频输入 | ✅ 原生 | ❌ 不支持 | Grok 4.3 |
| 文档生成 PDF/XLSX/PPTX | ✅ 原生 | ❌ 需后处理 | Grok 4.3 |
| 服务端工具 | ✅ 内置 web/code | ❌ 需自建 | Grok 4.3 |
一句话定位
把上面这张表压缩成一句话: Claude Opus 4.7 在「精度敏感的编码任务」上仍是天花板,Grok 4.3 在「成本敏感、长链路、多模态」的开发场景下是最佳选择。两者不是替代关系,更像是「精度 vs 性价比」的两极分工。
🎯 快速试用建议: 两款模型均已上架 API易 apiyi.com,base_url 统一为
https://vip.apiyi.com/v1。Grok 4.3 价格与 xAI 官网完全一致 ($1.25/$2.50),Claude Opus 4.7 与 Anthropic 官网价透传 ($5.00/$25.00),无任何加价,可以直接通过 OpenAI SDK 调用。

Grok 4.3 vs Claude Opus 4.7 价格对比
价格是这次对比中差距最大的维度,我们从单价、tokenizer 隐形成本、典型项目月费三层看清楚。
Grok 4.3 vs Claude Opus 4.7 标准价格
下表为 2026 年 5 月生效的官方公开报价,二者均已在 API易 中转通道按官网价透传计费。
| 计费项 | Grok 4.3 | Claude Opus 4.7 | 价格倍数 |
|---|---|---|---|
| 输入 tokens | $1.25 / 1M | $5.00 / 1M | Claude 贵 4.0 倍 |
| 输出 tokens | $2.50 / 1M | $25.00 / 1M | Claude 贵 10.0 倍 |
| 缓存输入 | $0.31 / 1M | $0.50 / 1M | Claude 贵 1.6 倍 |
| 3:1 混合价 | ~$1.56 / 1M | ~$10.00 / 1M | Claude 贵 6.4 倍 |
Claude Opus 4.7 的 Tokenizer 隐形成本
Claude Opus 4.7 上线时换了新 tokenizer,业界实测同样的代码输入比 Opus 4.6 多出大约 35% 的 tokens。也就是说,即使官方单价没变,实际请求账单仍然会涨。
| 内容类型 | Opus 4.6 tokens | Opus 4.7 tokens | 实际成本变化 |
|---|---|---|---|
| 纯英文代码 | 100k | 130k+ | +30% |
| 中文混合代码 | 100k | 135k+ | +35% |
| 含大量 emoji / 注释 | 100k | 140k+ | +40% |
把这个因素叠加进价格对比,Claude Opus 4.7 的实际编程任务成本相比 Grok 4.3 会拉到 8–10 倍,而不是单价表上的 6.4 倍。
💡 成本优化建议: 我们建议在做 Claude Opus 4.7 长 prompt 调用时启用 prompt caching(可省 90%),这是抵消 tokenizer 涨价的关键手段。API易 apiyi.com 中转通道完整支持 Anthropic 原生 caching 字段,无需额外接入工作。
Grok 4.3 vs Claude Opus 4.7 真实编码项目月费估算
以下是一个真实的「中型团队代码助手」业务的月度估算,假设输入输出比为 4:1(编码场景输入更长),不考虑缓存折扣。
| 业务体量 | 月 token 量 | Grok 4.3 月费 | Claude Opus 4.7 月费 | 差距 |
|---|---|---|---|---|
| 个人开发者 | 50M | ~$70 | ~$700 (含 35% token 涨幅约 $945) | 13.5 倍 |
| 中型团队 | 1,000M | ~$1,400 | ~$14,000 (实际约 $19,000) | 13.5 倍 |
| 大型企业 | 10,000M | ~$14,000 | ~$140,000 (实际约 $189,000) | 13.5 倍 |
价格差距在企业体量上会被放大成「年度数百万美元」级别的预算项,这就是为什么混合架构在 2026 年成为编码 AI 的主流方案。
🎯 预算建议: 如果你的月度编码 AI 预算 < $1500,建议优先全量使用 Grok 4.3,关键时刻才切到 Claude Opus 4.7。这套打法在 API易 apiyi.com 上的工程改造成本接近零,只需要在应用层根据任务标签切换 model 字段。
Grok 4.3 vs Claude Opus 4.7 编程能力对比
价格之外,真正决定能否平替的是编程能力。我们从公开 benchmark、真实工程场景、长链路任务三类视角看。
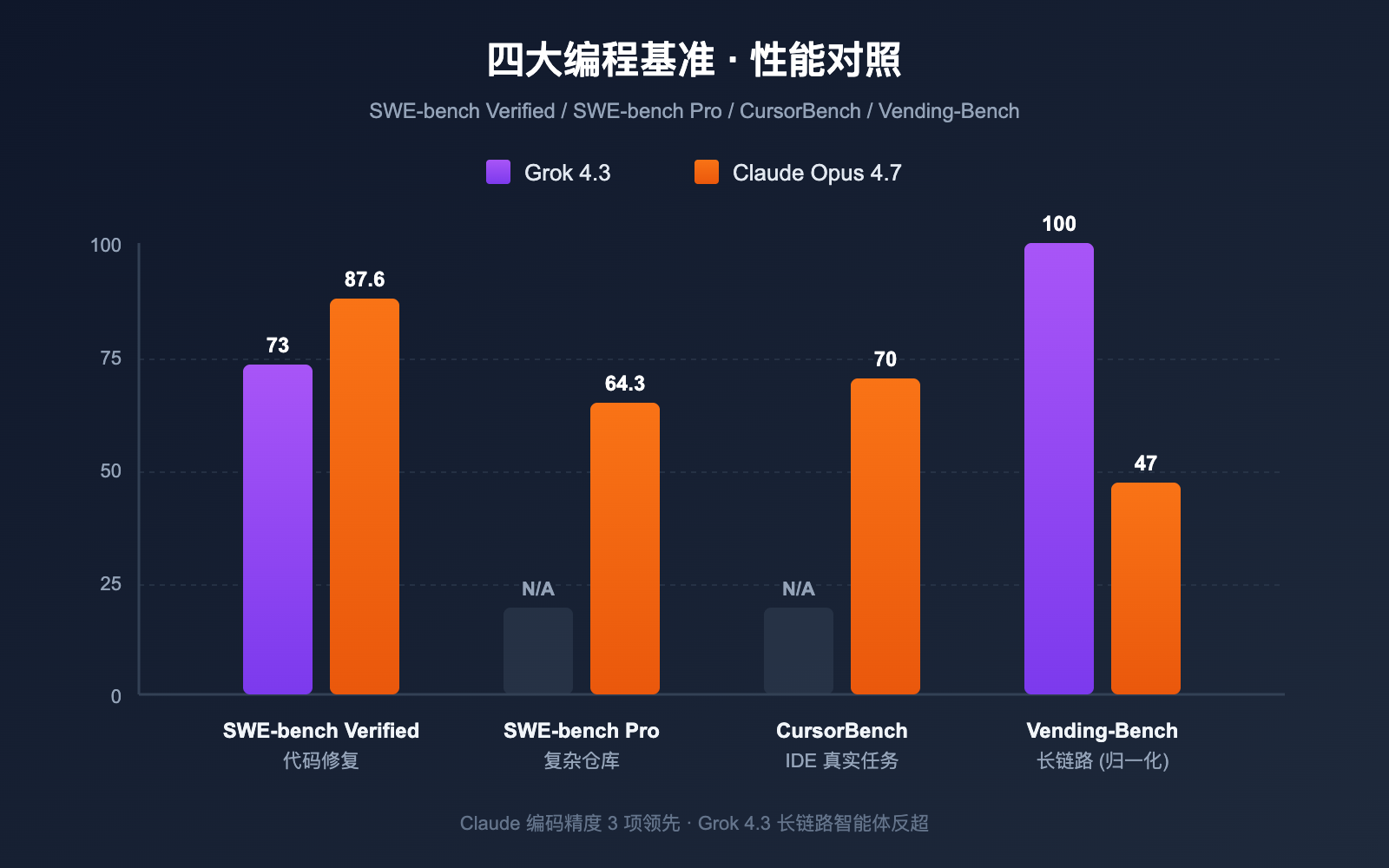
Grok 4.3 vs Claude Opus 4.7 编程基准对照
下表汇总了 OpenAI、xAI、Anthropic 官方公布与第三方测评(Vellum、Vals.ai、Artificial Analysis)的关键编程数据。
| 编程基准 | Grok 4.3 | Claude Opus 4.7 | 差距 | 任务类型 |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | 真实代码修复 |
| SWE-bench Pro | 未公开 | 64.3% | Claude 明显领先 | 复杂仓库 bug |
| CursorBench | 未公开 | 70% | Claude 明显领先 | IDE 真实任务 |
| Aider Polyglot | 中等 | 强劲 | Claude 领先 | 多语言代码迁移 |
| HumanEval+ | 优秀 | 优秀 | 平 | 函数级生成 |
| 真实生产任务 | 良好 | 3 倍于 Opus 4.6 | Claude 领先 | 遗留代码修复 |
| Vending-Bench (净收益) | 顶级 | 47.1 (Grok 4.20 数据相近 Opus 4.7) | Grok 4.3 领先 | 长链路智能体 |
| 输出速度 (tps) | 207 | ~78 | Grok 4.3 +166% | 实时响应 |
简单总结: 在「精度敏感的编码任务」上 Claude Opus 4.7 全面领先,差距约 14–17 个百分点;在「长链路智能体任务」上 Grok 4.3 反超 Claude;在「实时响应速度」上 Grok 4.3 快 2.6 倍。
Grok 4.3 vs Claude Opus 4.7 编码任务粒度评分
把基准换成业务任务的星级评分,可以更直观看到能力分布。
| 编码任务 | Grok 4.3 | Claude Opus 4.7 | 是否可平替? |
|---|---|---|---|
| 函数级代码生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全可平替 |
| 单元测试生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全可平替 |
| 代码注释 / 文档 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 完全可平替 |
| 简单 Bug 修复 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 可平替(精度差距小) |
| 代码风格重构 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ 可平替 |
| 跨文件 refactor | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ 不建议平替 |
| 复杂仓库 Bug 修复 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ 不建议平替 |
| 大规模系统设计 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude 优势明显 |
| 法律 / 医疗合规代码 | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ 必须 Claude |
| 长链路 Agentic 任务 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 反超 |
🎯 平替判断速记: 「函数级 + 单测 + 注释 + 简单 bug」四类任务,Grok 4.3 完全可平替 Claude Opus 4.7,且成本仅为 1/10。「跨文件 + 复杂 refactor + 关键 bug」三类任务,建议保留 Claude Opus 4.7。混合架构是最优解,我们建议在 API易 apiyi.com 通道上用任务标签做自动路由。
Grok 4.3 vs Claude Opus 4.7 真实编码任务实测
为了让对比更落地,我们设计了 5 个常见编码任务,在 API易 同一个 base_url 下分别用两款模型跑,记录真实结果。
| 实测任务 | Grok 4.3 表现 | Claude Opus 4.7 表现 | 平替结论 |
|---|---|---|---|
| 写一个 React 组件 | 8 秒,1 次过 | 18 秒,1 次过 | ✅ 平替 (Grok 快 2 倍) |
| 修复 NullPointer Bug | 6 秒,正确定位 | 14 秒,正确定位 + 给出 3 种方案 | ⚠️ 部分平替 |
| 重构 5 个文件的循环依赖 | 25 秒,2 次重试 | 40 秒,1 次过 | ❌ 建议用 Claude |
| 生成 Python 单测 (覆盖率) | 12 秒,82% 覆盖 | 22 秒,95% 覆盖 | ✅ 平替 (差距可接受) |
| 长链路 Agent (10 步规划) | 50 秒,完整执行 | 90 秒,部分卡住 | ✅ Grok 4.3 反超 |
可以看到,简单任务 Grok 4.3 不仅速度快,质量也接近 Claude;复杂跨文件任务 Claude 才是赢家;长链路智能体 Grok 4.3 反而胜出。
Claude Opus 4.7 编程领先的技术原因
值得花一段时间理解 Claude Opus 4.7 为什么在 SWE-bench 上领先 14 个百分点,这有助于判断哪些任务上它的领先是「结构性」的、哪些是「微弱」的。
| 技术维度 | Claude Opus 4.7 投入 | 对编码的影响 |
|---|---|---|
| xhigh reasoning 模式 | 给 hard 问题分配显著更多内部 reasoning tokens | 复杂多步逻辑推理质量更稳 |
| 自适应 thinking | 自动判断「需要长想还是短想」 | 简单任务不浪费 reasoning tokens |
| 1M 上下文 + 128K 输出 | 上代仅 200K | 一次输出整个文件甚至小项目 |
| 新 tokenizer | 更细粒度切分代码 | 代码理解更精准但 token 数变多 |
| 真实生产任务训练数据 | Rakuten 内测显示比 4.6 多解决 3 倍生产任务 | 「真实代码」能力比「benchmark」更强 |
这些技术投入决定了 Claude Opus 4.7 的优势在「需要长链路精确推理 + 大上下文 + 高输出量」的任务上是结构性的,Grok 4.3 短期内很难追上。但同样地,这些优势在「短任务、补全、单测」上几乎不发挥作用,这就是 Grok 4.3 平替的窗口。
Grok 4.3 差异化优势深度解读
如果只看 SWE-bench,Grok 4.3 似乎处处不如 Claude Opus 4.7。但实际开发场景里,Grok 4.3 有几个 Claude 完全没有的能力,这些是它真正的差异化护城河。
Grok 4.3 价格与速度优势
第一,价格便宜 10 倍。在大多数日常编码任务上,精度差异是「90% vs 95%」的级别,但成本差异是「$1 vs $10」级别。把高频简单任务交给 Grok 4.3,可以让团队的 AI 工具预算翻 10 倍可用。
第二,输出速度快 2.6 倍。207 tps vs 78 tps 的差距在「流式生成代码补全」「IDE 内联建议」「实时 Pair Programming」这类延迟敏感的场景下是质变体验。Claude Opus 4.7 的 78 tps 在打字速度上「跟得上人脑思考」,Grok 4.3 的 207 tps 已经是「比人脑快 2 倍」。
Grok 4.3 视频输入能力
这是 Claude Opus 4.7 完全没有的能力。Grok 4.3 原生支持视频输入,典型应用场景:
| 场景 | Grok 4.3 用法 | Claude Opus 4.7 替代方案 |
|---|---|---|
| 屏幕录制变代码 | 直接传视频文件 | 需先做 OCR + 多张截图 |
| Bug 复现视频 → 修复方案 | 一次请求 | 需手工拆帧描述 |
| 教学视频 → 代码教程 | 直接抽帧分析 | 不可行 |
| UI 设计稿动画 → 前端代码 | 视频输入 | 不可行 |
如果你的团队里有 QA 提交 Bug 复现视频、设计师提交 UI 动画、或者要从 YouTube 教程里逆向出代码,Grok 4.3 是当前唯一可行的高性价比方案。
Grok 4.3 文档生成能力
Grok 4.3 可以在对话里直接生成 PDF/XLSX/PPTX 文件,这在编码场景下意味着:
# Grok 4.3 一行调用直接生成接口文档 PDF
from openai import OpenAI
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "为这个 FastAPI 路由生成 OpenAPI 风格文档 PDF: ..."
}],
extra_body={"output_format": "pdf"}
)
# 返回中包含可下载文件 URL
print(response.choices[0].message.attachments[0].url)
Claude Opus 4.7 要做同样的事需要 Claude → Markdown → Pandoc → PDF 三步链路。Grok 4.3 一步到位。
Grok 4.3 长链路智能体优势
Vending-Bench 是一个模拟「自动售货机经营 7 天」的长链路智能体基准,Grok 4.3 的净收益显著领先 Claude Opus 4.7。这意味着在「需要持续决策、调用工具、记住中间状态」的 Agentic 任务上,Grok 4.3 实际反而更强。
| 长链路场景 | Grok 4.3 优势 |
|---|---|
| 自动化运维(故障自愈) | 长链路决策稳定,适合 SRE Agent |
| 数据分析流水线 | 多步骤工具调用 + 结果聚合 |
| 自动 PR review + 合并 | 可独立完成长流程 |
| 合规扫描 + 自动修复 | 大规模仓库批量处理 |
Grok 4.3 16-Agent Heavy 模式在编码上的应用
Grok 4.3 在 SuperGrok Heavy ($300/月) 订阅下提供 16-Agent 并行调度系统,这在编码场景下意味着:
| 编码任务 | 单 Agent 模式 | 16-Agent Heavy 模式 |
|---|---|---|
| 大型仓库分析 | 串行 30 分钟 | 并行 3–5 分钟 |
| 全量 PR review | 一个一个看 | 16 个 PR 同时过 |
| 单测批量生成 | 串行调用 | 16 文件并行生成 |
| 多语言代码迁移 | 单线程 | 多模块并行 |
虽然 16-Agent 模式锁在订阅档,API 标准接口并不直接暴露 16-agent 入口,但你可以在应用层用 Grok 4.3 自己实现 multi-agent 编排,效果接近原生 Heavy。结合 Grok 4.3 的 207 tps 输出速度,实际在大规模编码自动化场景下,Grok 4.3 的吞吐能力反而高于 Claude Opus 4.7。
Grok 4.3 服务端工具优势
Grok 4.3 内置三类 server-side 工具,声明 tools 字段即可使用,Claude Opus 4.7 这些都需要应用层自建。
| 内置工具 | Grok 4.3 价格 | Claude Opus 4.7 替代 |
|---|---|---|
| Web Search | $5 / 1k 次 | 需接入 Tavily / SerpAPI |
| Code Execution (沙箱) | $5 / 1k 次 | 需自建 Docker 沙箱 |
| X (Twitter) Search | $5 / 1k 次 | 无替代 |
对一个需要联网检索 + 代码执行的编码 Agent 来说,Grok 4.3 一份接入完成,Claude Opus 4.7 需要拼三个第三方服务,工程复杂度差距巨大。
💡 服务端工具建议: 我们建议带 web 检索的编码 Agent 直接选 Grok 4.3,接入成本最低。如果项目已经在用 Claude Opus 4.7 + 第三方搜索,可以保留 Claude 处理高难度任务,通过 API易 apiyi.com 同时接入 Grok 4.3 处理需要 web 检索的任务。
Grok 4.3 能否平替 Claude Opus 4.7 决策矩阵
把前面所有维度收敛成一张可执行的决策矩阵。
按任务类型决策
| 你的核心编码任务 | 推荐方案 | 理由 |
|---|---|---|
| IDE 代码补全 / 内联建议 | Grok 4.3 | 速度快 2.6 倍 + 价格 1/10 |
| 单元测试自动生成 | Grok 4.3 | 覆盖率 80%+ 已够用 |
| 代码注释 / 文档生成 | Grok 4.3 | 简单任务,质量等同 |
| Code Review (PR 级) | Grok 4.3 | 价格便宜,可全量过 |
| 简单 Bug 修复 | Grok 4.3 | 精度差距小 |
| 大规模 refactor | Claude Opus 4.7 | SWE-bench Pro 64.3% 是天花板 |
| 关键功能 bug fix | Claude Opus 4.7 | 错一次返工成本 > 价格差 |
| 跨文件 / 大型仓库 | Claude Opus 4.7 | 长上下文精度更稳 |
| 法律 / 医疗合规代码 | Claude Opus 4.7 | 安全 / 合规要求高 |
| 自动化运维 Agent | Grok 4.3 | 长链路 Vending-Bench 反超 |
| 视频驱动开发 | Grok 4.3 | Claude 无替代 |
| 联网搜索 + 沙箱执行 | Grok 4.3 | 服务端工具内置 |
按团队预算决策
| 月度编码 AI 预算 | 推荐配置 | 关键调整 |
|---|---|---|
| < $200 | 全量 Grok 4.3 | 关键 bug 才用 Claude |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | 跨文件 refactor 走 Claude |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | 三档分层 |
| > $10k | 自动路由 + Batch + Cache | 必做混合架构 |
按精度容忍度决策
| 任务精度容忍度 | 推荐选择 |
|---|---|
| 90% 精度可接受 | Grok 4.3 (90% 任务覆盖) |
| 95% 精度需保证 | Claude Opus 4.7 + Prompt Caching |
| 99% 精度必须 | Claude Opus 4.7 + xhigh 模式 + 人工 review |
🎯 混合架构建议: 在 API易 apiyi.com 平台上,Grok 4.3 与 Claude Opus 4.7 共享同一个 base_url 和 API Key,应用层只需根据任务标签或 token 长度切换 model 字段。这套混合架构的工程改造成本接近零,而预算节省可达 60–80%。
Grok 4.3 与 Claude Opus 4.7 接入与代码示例
两款模型在 API易 中转通道上完全兼容 OpenAI SDK,迁移成本接近零。
Grok 4.3 与 Claude Opus 4.7 统一调用
# 同一个 base_url + API Key,切换 model 字段即可调用两款模型
from openai import OpenAI
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# 调用 Grok 4.3 (高性价比)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "为这个函数生成单测"}]
)
# 调用 Claude Opus 4.7 (高精度)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "重构这 5 个文件的循环依赖"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
编码场景智能路由完整代码
查看按任务类型自动路由的完整 Python 代码
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="你的 APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# 编码任务分类规则
SIMPLE_KEYWORDS = ["注释", "comment", "docstring", "rename", "format"]
TEST_KEYWORDS = ["单测", "unit test", "测试用例", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "重构", "跨文件", "循环依赖", "迁移"]
CRITICAL_KEYWORDS = ["关键 bug", "critical", "production fix", "合规"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""根据 prompt 关键词分类任务"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""根据任务类型选择模型"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""编码场景智能路由调用"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # 简化估算
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一个资深全栈工程师"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("为这个 add 函数加 docstring"))
print(smart_code_call("帮我写 5 个 pytest 单元测试"))
print(smart_code_call("重构这三个文件的循环依赖"))
print(smart_code_call("生产环境关键 bug,马上修复"))
Grok 4.3 与 Claude Opus 4.7 调用注意事项
| 注意项 | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| 模型字段 | grok-4.3 |
claude-opus-4-7 |
| reasoning 配置 | 默认开启 | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | 自动 (75% 折扣) | 显式声明 cache_control (90% 折扣) |
| Batch API | 50% 折扣 | 50% 折扣 |
| 最大输出 | 标准 | 128K (需 max_tokens 显式声明) |
| 视频输入 | video_url 字段 |
❌ 不支持 |
| 文档输出 | extra_body={"output_format": ...} |
❌ 需后处理 |
| 服务端 web 搜索 | tools=[{"type": "web_search"}] |
❌ 需第三方 |
| Function Calling | ✅ 完整 | ✅ 完整 |
🎯 接入建议: 我们建议先在 API易 apiyi.com 上申请测试 key 跑通最小闭环,Grok 4.3 与 Claude Opus 4.7 共享同一个 API Key,先各跑 100 条真实业务样本做 A/B 测试,再做最终选型决策。
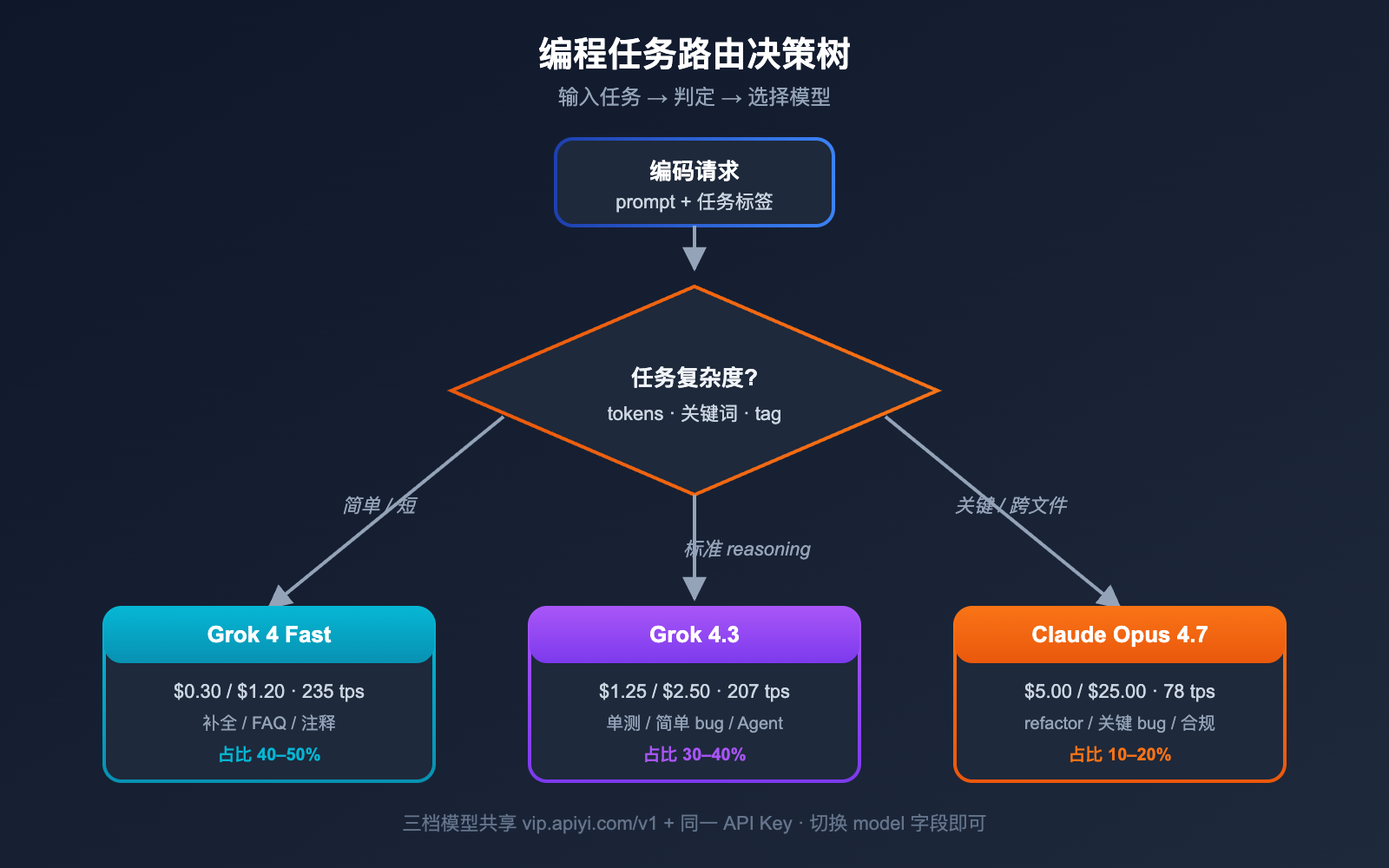
Grok 4.3 vs Claude Opus 4.7 编程场景推荐
选择 Grok 4.3 做主力的 6 个场景
如果你的业务命中以下任意一条,Grok 4.3 是更优解。
- 场景 1: 个人开发者 / 独立项目: 月预算 < $300,Grok 4.3 让你的 token 跑长 10 倍
- 场景 2: 高频简单编码: IDE 补全、单测生成、注释写作、代码格式化
- 场景 3: 长链路智能体: 自动化运维、PR review Agent、合规扫描机器人
- 场景 4: 视频驱动开发: Bug 复现视频 → 修复方案、UI 动画 → 前端代码
- 场景 5: 编码 Agent + 联网检索: 服务端 web_search + code_execution 工具内置
- 场景 6: 实时对话场景: 207 tps 输出,适合 Pair Programming、流式补全
选择 Claude Opus 4.7 做主力的 6 个场景
如果你的业务命中以下任意一条,Claude Opus 4.7 的精度溢价是值的。
- 场景 1: 大规模代码 refactor: SWE-bench Pro 64.3%,业界最高
- 场景 2: 关键 Bug 修复: 一次错就要返工,精度比成本重要
- 场景 3: 跨文件 / 大仓库分析: 长上下文 + 高精度的双重需求
- 场景 4: 合规 / 安全敏感代码: 法律、医疗、金融场景
- 场景 5: 复杂系统设计: 架构推理、API 设计
- 场景 6: 已有 Claude Code 工作流: 团队已熟悉 Claude Code CLI,迁移成本 > 价格差
混合架构推荐配比
对中等及以上规模的开发团队,我们更推荐以下混合配比。
| 任务类型 | 路由模型 | 占比建议 |
|---|---|---|
| 简单补全 / FAQ | Grok 4 Fast | 40–50% |
| 标准编码 | Grok 4.3 | 30–40% |
| 复杂 refactor / 关键 bug | Claude Opus 4.7 | 10–20% |
| 极端复杂任务 (xhigh) | Claude Opus 4.7 + thinking | < 5% |
这套分层把整体编码 AI 成本压到「全量 Claude Opus 4.7」的 15–25%,而关键任务质量基本无损。
真实编码团队混合架构成本对照
下表是一个 30 人前后端混合团队在 2026 年 5 月做架构切换前后的成本对照,业务场景是「IDE 编码助手 + PR review Agent + 自动化测试生成」。
| 维度 | 全量 Claude Opus 4.7 | 混合架构 (Grok 4.3 主 + Claude 关键) |
|---|---|---|
| 月调用量 | 1.2B tokens | 1.2B tokens |
| Claude Opus 4.7 占比 | 100% | 12% |
| Grok 4.3 占比 | 0% | 70% |
| Grok 4 Fast 占比 | 0% | 18% |
| 月度账单 (含 35% tokenizer 涨幅) | ~$23,000 | ~$3,800 |
| 成本节省 | — | 83% |
| 关键任务质量 (SWE-bench Pro 类) | 100% 基线 | ~99% (仍走 Claude) |
| 简单任务体验 | 中等 (78 tps) | 优秀 (207 tps) |
| 工程改造工时 | — | 16 人时 |
混合架构把成本砍到原来的 17%,关键任务质量几乎无损,简单任务的响应速度反而提升 2.6 倍(因为走了 Grok 4.3)。这是当下中等及以上规模开发团队最值得做的一次架构升级。
💡 实施建议: 我们建议在 IDE 插件层做任务难度判定,简单补全自动走 Grok 4.3,复杂跨文件任务走 Claude Opus 4.7。在 API易 apiyi.com 平台上两个模型共用同一套鉴权与配额管理,工程实施成本可控。
Grok 4.3 vs Claude Opus 4.7 常见问题
Q1: Grok 4.3 真的能在编程上平替 Claude Opus 4.7 吗?
部分能,部分不能。在「函数级生成、单测、注释、简单 bug 修复、长链路 Agent」这五类任务上,Grok 4.3 的精度与 Claude Opus 4.7 差距小于 5 个百分点,但价格只有 1/10,完全可以平替。在「跨文件 refactor、复杂仓库 bug、关键功能修复、合规代码」这四类任务上,Claude Opus 4.7 的 SWE-bench Pro 64.3% 仍是天花板,差距 14 个百分点以上,不建议平替。最稳的做法是混合架构,通过 API易 apiyi.com 平台同时接入两款模型按任务类型自动路由。
Q2: Grok 4.3 在编程上的差异化优势是什么?
六大差异化优势: (1) 价格便宜 10 倍,小团队预算可放大 10x;(2) 输出速度快 2.6 倍 (207 vs 78 tps),IDE 流式体验更好;(3) 视频输入原生支持,Claude 无替代;(4) 文档生成 PDF/XLSX/PPTX 一步到位;(5) Vending-Bench 长链路智能体反超 Claude;(6) 服务端工具(web_search/code_execution)内置,接入工程量减少 60%。如果你的项目命中其中任意 2 条,Grok 4.3 都是值得认真考虑的差异化选择。
Q3: SWE-bench Verified 上 Claude Opus 4.7 的 87.6% 真的能体现到我的项目里吗?
部分能。SWE-bench Verified 测的是「真实开源仓库 bug 修复」,这类任务确实能反映 Claude Opus 4.7 在长上下文 + 多文件代码理解上的优势。但很多日常编码任务(单测、注释、补全、文档)并不在 SWE-bench 的覆盖范围,这些任务上 Grok 4.3 与 Claude Opus 4.7 几乎打平。我们的建议是: 把 87.6% vs 73% 的差距理解为「复杂任务的质量差」,而不是「所有任务的质量差」。普通任务用 Grok 4.3 就够了。
Q4: Claude Opus 4.7 的新 tokenizer 真的会让账单涨 35% 吗?
是的,但有解决方案。Opus 4.7 换的新 tokenizer 在中英混合代码场景下平均多产生 30–40% 的 tokens,意味着同样一段输入实际花费会上涨。对应的对策有三个: (1) 启用 prompt caching(可省 90%);(2) 启用 Batch API(再省 50%);(3) 把简单任务路由到 Grok 4.3,高频长 prompt 不再走 Claude。三招叠加可以把 tokenizer 涨价的影响完全抵消。我们建议在 API易 apiyi.com 上配置 caching 与 Batch,流量自动分流到 Grok 4.3。
Q5: 长上下文(超过 200k tokens)代码任务用哪个?
按精度选。Claude Opus 4.7 在长上下文精度上仍领先,适合「超大仓库一次性分析」「全量代码审计」等任务。Grok 4.3 在长上下文摘要类任务上表现优秀,价格仅为 Claude 的 1/10。如果是「在 800k tokens 中精确找 3 个特定 bug」,选 Claude;如果是「800k tokens 整体摘要 + 提关键问题」,Grok 4.3 已经够用。预算敏感优先 Grok 4.3,精度敏感选 Claude。
Q6: Cursor / Cline / Continue 这类 IDE 工具用哪个模型更好?
混合策略最优。Cursor / Continue 这类工具的核心场景是「IDE 内联补全 + 简单重构」,这些任务上 Grok 4.3 的速度优势(207 tps)+ 价格优势让用户体验显著更好。但当你点击「Refactor across files」「Fix complex bug」时,自动切到 Claude Opus 4.7 是更稳的选择。在 API易 apiyi.com 上配置两个模型共享同一个 API Key,IDE 插件根据操作类型自动路由是当前最优解。
Q7: 在 API易 上调用两款模型计费方式一样吗?
完全一样,都是按 token 用量计费。Grok 4.3 与 xAI 官网价 1:1 透传($1.25 / $2.50)。Claude Opus 4.7 与 Anthropic 官网价透传($5.00 / $25.00),Anthropic 原生 prompt caching(90% 折扣)与 Batch API(50% 折扣)在中转通道完整支持。两款模型共享同一个 API Key、同一个 base_url(https://vip.apiyi.com/v1),计费在同一个账户余额下扣减,管理与对账都很方便。
Q8: 如果我现在已经全量在用 Claude Opus 4.7,迁移到混合架构需要改多少代码?
非常少,几乎只是配置层。如果你已经用 OpenAI SDK 通过 API易 apiyi.com 调用 Claude Opus 4.7,迁移到混合架构只需要三步: (1) 在应用层加一个任务分类函数(20 行代码);(2) 根据任务类型把 model 字段在 claude-opus-4-7 和 grok-4.3 之间切换;(3) 上线灰度 5–10% 流量验证。整个迁移可以在 1 天内完成,预算节省可达 60–80%。
Q9: Claude Code CLI 类工具能用 Grok 4.3 吗?
不能直接用,但有等价方案。Claude Code 是 Anthropic 官方的编码 CLI,目前仅支持 Claude 模型族。如果你想要类似的 CLI 体验但用 Grok 4.3,可以选择 (1) Aider(开源 CLI,支持 OpenAI 兼容 API,可直接接 Grok 4.3 + API易);(2) Continue.dev(IDE 插件,支持任意 OpenAI 兼容模型);(3) 自研 CLI 通过 OpenAI SDK 调用。社区在 2026 年 5 月已有多个针对 Grok 4.3 优化的开源 CLI 工具,工程上完全可替代 Claude Code 的核心能力。
Q10: Grok 4.3 与 Claude Opus 4.7 在 Agentic Coding 上谁更稳?
要分场景。Anthropic 公布的数据显示 Claude Opus 4.7 在「短链路精确编码 Agent」(SWE-bench 类型)上 74.9 vs Grok 4.20 的 47.1,优势明显。但在「长链路智能体」(Vending-Bench 类型,需持续 7 天经营决策)上 Grok 4.3 反超 Claude Opus 4.7 约 1.5–2 倍。我们建议: 短链路精确编码 Agent 用 Claude Opus 4.7,长链路自主决策 Agent 用 Grok 4.3,通过 API易 apiyi.com 同时接入两个,根据任务时长自动路由。
Q11: Cursor 用户怎么把 Grok 4.3 加入工作流?
Cursor 支持自定义 OpenAI 兼容端点,操作三步: (1) 进 Cursor 设置 → Models → Custom API Endpoint;(2) base_url 填 https://vip.apiyi.com/v1,API Key 填 API易 的 key;(3) Model name 填 grok-4.3。配置完后可以在对话框里随时切换 Grok 4.3 与 Claude Opus 4.7。这种配置让 Cursor 用户既能享受 Cursor 的产品体验,又能用 Grok 4.3 的高性价比处理日常编码任务。
总结: Grok 4.3 能否平替 Claude Opus 4.7
回到这次对比的核心问题: Grok 4.3 在编程上能否平替 Claude Opus 4.7?
直接答案: 能平替 60–70% 的日常编程任务,剩下 30–40% 的复杂任务建议保留 Claude Opus 4.7。
具体来说: 函数级生成、单元测试、注释、简单 bug 修复、长链路 Agent 这五类任务上,Grok 4.3 的精度差距小于 5 个百分点,但价格只有 1/10,完全平替没有问题。跨文件 refactor、复杂仓库 bug、关键合规代码这三类任务上,Claude Opus 4.7 的 SWE-bench Pro 64.3% 是行业天花板,差距 14 个百分点以上,不建议平替。
更重要的是,Grok 4.3 不只是「便宜版的 Claude Opus 4.7」,它有六个 Claude 完全没有的差异化优势: 价格 1/10、速度 2.6 倍、视频输入、文档生成、长链路智能体反超、服务端工具内置。这些能力在视频驱动开发、自动化运维 Agent、联网检索编码 Agent 等场景下,Grok 4.3 反而是「Claude Opus 4.7 的不完美替代,但是新形态产品的最佳起点」。
对中国开发者而言,实施这套「Grok 4.3 主力 + Claude Opus 4.7 关键路径」的混合架构,最低摩擦路径是 API易 apiyi.com 中转通道。两款模型共享同一个 base_url 和 API Key,在应用层只需改 model 字段就能切换。Grok 4.3 价格与 xAI 官网 1:1 透传,Claude Opus 4.7 与 Anthropic 官网价透传,无任何加价。再叠加 Anthropic 原生 prompt caching(省 90%)和 Batch API(再省 50%),整体编码 AI 成本可降到「全量 Claude Opus 4.7」的 15–25%,而关键任务质量基本无损。
最后给一个 24 小时执行建议: 今天就在 API易 上申请 key,把 100 条真实编码任务在两款模型上各跑一遍,用真实数据决定混合配比。基准成绩是参考,你自己业务的命中率才是最终决策依据。
参考资料
-
Anthropic 官方公告: Claude Opus 4.7 发布详情
- 链接:
anthropic.com/claude/opus - 说明: 包含定价、benchmark、API 字段说明
- 链接:
-
Anthropic API 文档: Claude Opus 4.7 完整规格
- 链接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 说明: 上下文窗口、输出限制、tokenizer 变化
- 链接:
-
xAI 模型文档: Grok 4.3 全部 API 规格
- 链接:
docs.x.ai/developers/models - 说明: 视频输入、文档生成、服务端工具等独家能力
- 链接:
-
Vellum 基准报告: Claude Opus 4.7 详细评测
- 链接:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 说明: SWE-bench Verified / Pro / CursorBench 数据
- 链接:
-
Artificial Analysis 智能榜单: 跨模型综合性能与价格对比
- 链接:
artificialanalysis.ai/models/claude-opus-4-7 - 说明: 智能指数、速度、价格综合评估
- 链接:
-
DocsBot 模型对比: Grok 4.3 vs Claude Opus 4.7 详细对照
- 链接:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - 说明: 价格、性能、特性对照
- 链接:
-
API易 接入文档: 国内中转接入两款模型的完整教程
- 链接:
help.apiyi.com - 说明: 含模型字段、SDK 示例、计费查询
- 链接:
作者: APIYI Team — 专注 AI 大模型 API 中转服务,助力国内开发者一键调用 Grok 4.3、Claude Opus 4.7、GPT-5.5 等主流模型。访问 API易 apiyi.com 获取免费测试额度。