En avril 2026, Claude Opus 4.7 a redéfini les standards des modèles de codage avec un score de 87,6 % au benchmark SWE-bench Verified. Deux semaines plus tard, xAI a bousculé l'idée reçue selon laquelle « un modèle de codage doit être coûteux » avec Grok 4.3, proposé à un dixième du prix. Cet article répond aux deux questions qui préoccupent le plus les développeurs : Grok 4.3 peut-il remplacer Claude Opus 4.7 pour les tâches de programmation ? et s'il ne peut pas le remplacer totalement, quels sont ses avantages différenciateurs ?
Valeur ajoutée : À la fin de cet article, vous saurez exactement quand choisir Grok 4.3, Claude Opus 4.7, ou comment combiner les deux pour vos projets, tout en réduisant vos coûts globaux de plus de 60 % grâce au service proxy API APIYI.

Différences fondamentales : Grok 4.3 vs Claude Opus 4.7
Pour déterminer s'il est possible de « remplacer » l'un par l'autre, comparons d'abord tous les paramètres clés liés à la programmation.
Vue d'ensemble des paramètres
| Dimension de comparaison | Grok 4.3 | Claude Opus 4.7 | Gagnant |
|---|---|---|---|
| Date de sortie | 30/04/2026 | 16/04/2026 | Claude (14 jours plus tôt) |
| Prix d'entrée | 1,25 $ / 1M | 5,00 $ / 1M | Grok 4.3 |
| Prix de sortie | 2,50 $ / 1M | 25,00 $ / 1M | Grok 4.3 |
| Fenêtre de contexte | 1M tokens | 1M tokens | Égalité |
| Sortie maximale | Standard | 128K tokens | Claude |
| Vitesse de sortie | 207 tokens/s | ~78 tokens/s | Grok 4.3 |
| Mode raisonnement | Activé par défaut | xhigh / Adaptatif | Claude (plus fin) |
| SWE-bench Verified | ~73 % | 87,6 % | Claude (+14,6 pts) |
| SWE-bench Pro | Non public | 64,3 % | Claude |
| CursorBench | Non public | 70 % | Claude |
| Vending-Bench (Agents) | Top niveau | Moyen | Grok 4.3 |
| Remise Prompt Caching | 75 % | 90 % | Claude |
| Remise Batch API | 50 % | 50 % | Égalité |
| Entrée vidéo | ✅ Natif | ❌ Non supporté | Grok 4.3 |
| Génération doc PDF/XLSX/PPTX | ✅ Natif | ❌ Post-traitement requis | Grok 4.3 |
| Outils serveur | ✅ Intégrés (web/code) | ❌ À construire soi-même | Grok 4.3 |
Résumé en une phrase
Pour résumer ce tableau : Claude Opus 4.7 reste la référence absolue pour les « tâches de codage exigeant une haute précision », tandis que Grok 4.3 est le meilleur choix pour les scénarios de développement « sensibles aux coûts, aux longues chaînes d'exécution et au multimodal ». Il ne s'agit pas d'une relation de substitution, mais plutôt d'une spécialisation entre « précision » et « rapport qualité-prix ».
🎯 Conseil pour un essai rapide : Les deux modèles sont disponibles sur APIYI (apiyi.com), avec une
base_urlunifiée :https://vip.apiyi.com/v1. Les prix de Grok 4.3 sont strictement identiques à ceux du site officiel de xAI (1,25 $/2,50 $), et ceux de Claude Opus 4.7 sont répercutés sans aucune majoration (5,00 $/25,00 $). Vous pouvez les appeler directement via le SDK OpenAI.

Comparatif tarifaire : Grok 4.3 vs Claude Opus 4.7
Le prix est le facteur le plus différenciateur dans cette comparaison. Analysons cela sous trois angles : le prix unitaire, les coûts cachés liés aux jetons (tokens) et les frais mensuels pour un projet typique.
Prix standards : Grok 4.3 vs Claude Opus 4.7
Le tableau ci-dessous présente les tarifs officiels publics en vigueur en mai 2026. Les deux modèles sont facturés au prix du site officiel via le service proxy API d'APIYI.
| Élément de facturation | Grok 4.3 | Claude Opus 4.7 | Ratio de prix |
|---|---|---|---|
| Tokens en entrée | 1,25 $ / 1M | 5,00 $ / 1M | Claude 4,0x plus cher |
| Tokens en sortie | 2,50 $ / 1M | 25,00 $ / 1M | Claude 10,0x plus cher |
| Entrée en cache | 0,31 $ / 1M | 0,50 $ / 1M | Claude 1,6x plus cher |
| Prix mixte 3:1 | ~1,56 $ / 1M | ~10,00 $ / 1M | Claude 6,4x plus cher |
Les coûts cachés du nouveau tokenizer de Claude Opus 4.7
Lors de son lancement, Claude Opus 4.7 a introduit un nouveau tokenizer. Les tests industriels montrent que pour le même code, la requête consomme environ 35 % de jetons en plus par rapport à Opus 4.6. En clair, même si le prix unitaire officiel reste le même, votre facture réelle augmentera.
| Type de contenu | Jetons Opus 4.6 | Jetons Opus 4.7 | Variation réelle du coût |
|---|---|---|---|
| Code en anglais pur | 100k | 130k+ | +30% |
| Code mixte (chinois) | 100k | 135k+ | +35% |
| Avec emojis/commentaires | 100k | 140k+ | +40% |
En intégrant ce facteur, le coût réel des tâches de programmation avec Claude Opus 4.7 par rapport à Grok 4.3 grimpe à 8–10 fois plus cher, au lieu des 6,4 fois indiqués par la grille tarifaire.
💡 Conseil d'optimisation des coûts : Nous recommandons d'activer le prompt caching (jusqu'à 90 % d'économie) lors des appels avec des invites longues sur Claude Opus 4.7 ; c'est le levier clé pour contrer la hausse liée au tokenizer. Le service proxy API d'APIYI (apiyi.com) prend en charge nativement les champs de mise en cache d'Anthropic, sans travail d'intégration supplémentaire.
Estimation mensuelle des coûts pour un projet de développement réel
Voici une estimation mensuelle pour une équipe de taille moyenne utilisant un assistant de code, basée sur un ratio entrée/sortie de 4:1, sans remise liée au cache.
| Volume d'activité | Volume de jetons/mois | Coût mensuel Grok 4.3 | Coût mensuel Claude Opus 4.7 | Écart |
|---|---|---|---|---|
| Développeur solo | 50M | ~70 $ | ~700 $ (env. 945 $ avec hausse) | 13,5x |
| Équipe moyenne | 1 000M | ~1 400 $ | ~14 000 $ (env. 19 000 $ réel) | 13,5x |
| Grande entreprise | 10 000M | ~14 000 $ | ~140 000 $ (env. 189 000 $ réel) | 13,5x |
L'écart de prix à l'échelle d'une entreprise se transforme en une ligne budgétaire de plusieurs millions de dollars par an. C'est pourquoi l'architecture hybride est devenue la norme en 2026 pour l'IA dédiée au code.
🎯 Conseil budgétaire : Si votre budget mensuel pour l'IA est inférieur à 1 500 $, nous recommandons d'utiliser principalement Grok 4.3 et de basculer vers Claude Opus 4.7 uniquement pour les tâches critiques. Cette stratégie via APIYI est quasi gratuite à mettre en place : il suffit de basculer le champ model au niveau applicatif en fonction de la tâche.
Comparaison des capacités de programmation : Grok 4.3 vs Claude Opus 4.7
Au-delà du prix, c'est la capacité de programmation qui détermine le remplacement possible. Analysons cela via les benchmarks publics, les scénarios d'ingénierie réels et les tâches complexes.
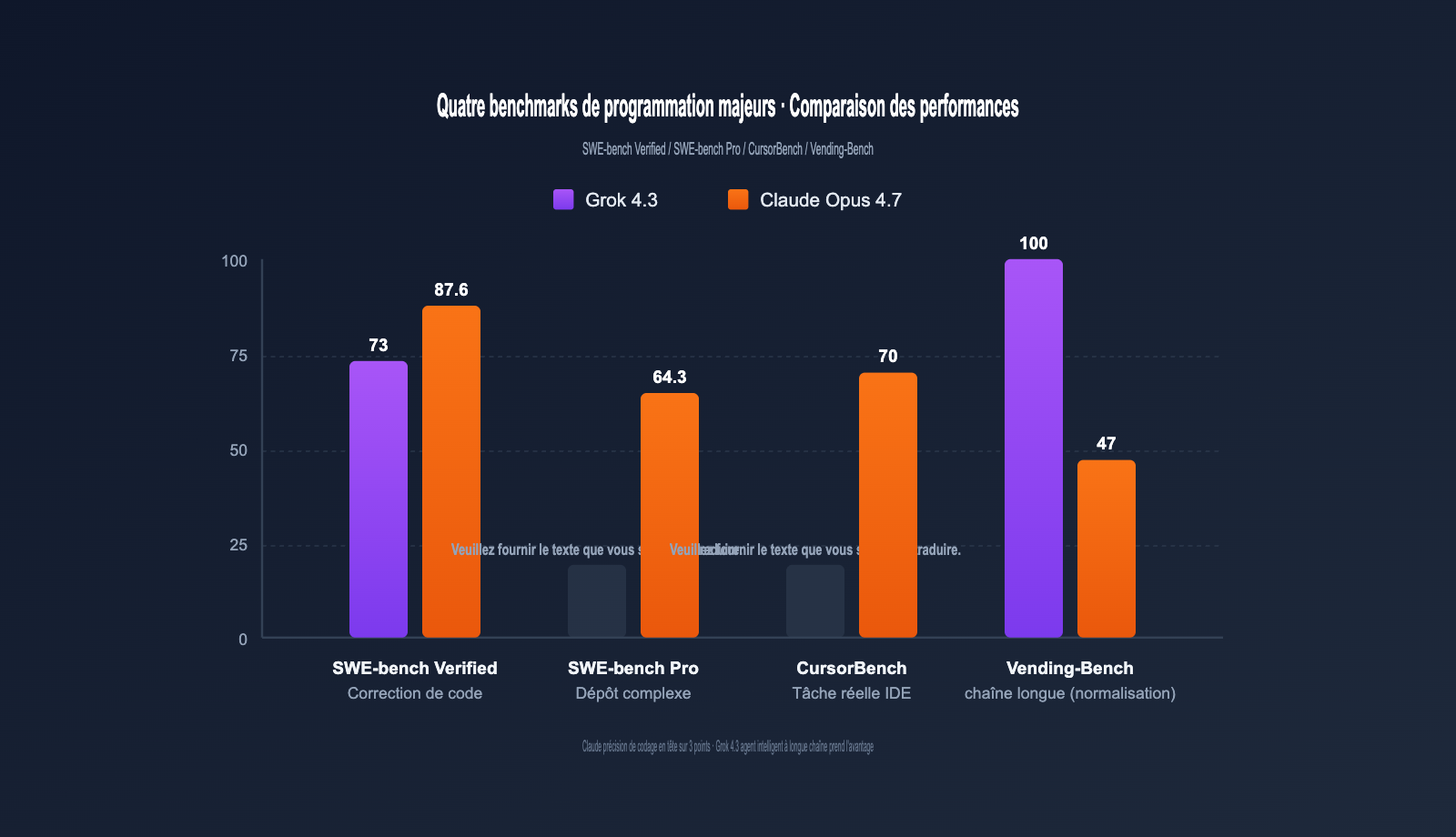
Tableau récapitulatif des benchmarks de programmation
Ce tableau résume les données clés provenant d'OpenAI, xAI, Anthropic et d'évaluateurs tiers (Vellum, Vals.ai, Artificial Analysis).
| Benchmark | Grok 4.3 | Claude Opus 4.7 | Écart | Type de tâche |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | Correction de code réel |
| SWE-bench Pro | Non publié | 64.3% | Claude en tête | Bugs complexes |
| CursorBench | Non publié | 70% | Claude en tête | Tâches IDE |
| Aider Polyglot | Moyen | Solide | Claude en tête | Migration multi-langage |
| HumanEval+ | Excellent | Excellent | Égalité | Génération par fonction |
| Tâches prod réelles | Bon | 3x Opus 4.6 | Claude en tête | Correction code existant |
| Vending-Bench (ROI) | Top | 47.1 | Grok 4.3 en tête | Agents longue chaîne |
| Vitesse (tps) | 207 | ~78 | Grok 4.3 +166% | Temps réel |
En résumé : Claude Opus 4.7 domine les tâches nécessitant une grande précision, tandis que Grok 4.3 excelle dans les agents à longue chaîne et affiche une vitesse de réponse 2,6 fois supérieure.
Score par type de tâche de programmation
| Tâche de programmation | Grok 4.3 | Claude Opus 4.7 | Remplacement possible ? |
|---|---|---|---|
| Génération par fonction | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Oui |
| Génération de tests unitaires | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Oui |
| Commentaires / Docs | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Oui |
| Correction bug simple | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Oui |
| Refactor style de code | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Oui |
| Refactor inter-fichiers | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Déconseillé |
| Correction bug complexe | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Déconseillé |
| Design système large échelle | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude recommandé |
| Code juridique / médical | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude impératif |
| Agents longue chaîne | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 supérieur |
🎯 Mémo pour le remplacement : Pour les tâches simples (fonctions, tests, docs, petits bugs), Grok 4.3 remplace parfaitement Claude pour 1/10ème du prix. Pour les tâches complexes (refactoring, bugs critiques), gardez Claude Opus 4.7. Utilisez le routage automatique via APIYI.
Tests en conditions réelles
| Tâche testée | Performance Grok 4.3 | Performance Claude Opus 4.7 | Conclusion |
|---|---|---|---|
| Composant React | 8s, 1 essai | 18s, 1 essai | ✅ Remplacement (Grok 2x plus rapide) |
| Fix bug NullPointer | 6s, cible correcte | 14s, 3 solutions | ⚠️ Remplacement partiel |
| Refactor dépendances croisées | 25s, 2 essais | 40s, 1 essai | ❌ Claude recommandé |
| Génération tests Python | 12s, 82% couvr. | 22s, 95% couvr. | ✅ Remplacement (écart acceptable) |
| Agent longue chaîne (10 étapes) | 50s, complet | 90s, bloqué partiellement | ✅ Grok 4.3 vainqueur |
Pourquoi Claude Opus 4.7 domine la programmation ?
- Mode "xhigh reasoning" : Alloue plus de jetons de réflexion interne pour les problèmes complexes.
- Thinking adaptatif : Optimise la réflexion selon la difficulté.
- Fenêtre de contexte 1M : Permet de traiter des projets entiers en une seule passe.
- Nouveau tokenizer : Segmentation plus fine du code.
- Entraînement sur données de production : Plus efficace sur le code réel que sur les benchmarks théoriques.
Ces avantages sont structurels pour les tâches de longue haleine, mais le gain est négligeable pour les petites tâches, laissant une fenêtre de tir parfaite pour Grok 4.3.
Analyse approfondie des avantages différentiels de Grok 4.3
Si l'on s'en tient uniquement au SWE-bench, Grok 4.3 semble partout inférieur à Claude Opus 4.7. Pourtant, dans des scénarios de développement réels, Grok 4.3 possède des capacités absentes chez Claude, qui constituent son véritable avantage concurrentiel.
Avantages de coût et de vitesse de Grok 4.3
Premièrement, il est 10 fois moins cher. Pour la plupart des tâches de codage quotidiennes, la différence de précision est de l'ordre de « 90 % contre 95 % », mais l'écart de coût est de « 1 $ contre 10 $ ». En confiant les tâches simples et répétitives à Grok 4.3, vous pouvez multiplier par 10 le budget disponible pour les outils d'IA de votre équipe.
Deuxièmement, la vitesse de sortie est 2,6 fois plus rapide. L'écart entre 207 tps et 78 tps représente une expérience qualitativement différente pour des scénarios sensibles à la latence comme la « complétion de code en streaming », les « suggestions en ligne dans l'IDE » ou le « pair programming en temps réel ». Les 78 tps de Claude Opus 4.7 « suivent le rythme de la pensée humaine », tandis que les 207 tps de Grok 4.3 sont « deux fois plus rapides que le cerveau humain ».
Capacité d'entrée vidéo de Grok 4.3
C'est une capacité totalement absente chez Claude Opus 4.7. Grok 4.3 prend en charge nativement l'entrée vidéo. Voici des scénarios d'application types :
| Scénario | Utilisation avec Grok 4.3 | Alternative avec Claude Opus 4.7 |
|---|---|---|
| Conversion d'enregistrement d'écran en code | Transmission directe du fichier vidéo | OCR nécessaire + multiples captures d'écran |
| Vidéo de reproduction de bug → Correctif | Une seule requête | Découpage manuel des trames et description |
| Tutoriel vidéo → Code source | Analyse par extraction de trames | Non réalisable |
| Animation de maquette UI → Code front-end | Entrée vidéo | Non réalisable |
Si votre équipe reçoit des vidéos de reproduction de bugs de la part du QA, des animations d'interface de la part des designers, ou si vous devez faire de l'ingénierie inverse à partir de tutoriels YouTube, Grok 4.3 est actuellement la seule solution viable au meilleur rapport coût-efficacité.
Capacité de génération de documents de Grok 4.3
Grok 4.3 peut générer directement des fichiers PDF/XLSX/PPTX au sein d'une conversation, ce qui, dans le contexte du codage, signifie :
# Grok 4.3 génère un PDF de documentation d'API en un seul appel
from openai import OpenAI
client = OpenAI(
api_key="Votre clé API APIYI",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Génère une documentation au format OpenAPI en PDF pour cette route FastAPI : ..."
}],
extra_body={"output_format": "pdf"}
)
# La réponse contient l'URL de téléchargement du fichier
print(response.choices[0].message.attachments[0].url)
Pour faire la même chose avec Claude Opus 4.7, il faudrait une chaîne complexe : Claude → Markdown → Pandoc → PDF. Grok 4.3 le fait en une seule étape.
Avantages de Grok 4.3 pour les agents à long cycle
Vending-Bench est un benchmark pour agents à long cycle simulant la « gestion d'un distributeur automatique sur 7 jours ». Les bénéfices nets de Grok 4.3 surpassent nettement ceux de Claude Opus 4.7. Cela signifie que pour les tâches d'agent nécessitant des « décisions continues, des appels d'outils et la mémorisation d'états intermédiaires », Grok 4.3 est en réalité plus performant.
| Scénario à long cycle | Avantage de Grok 4.3 |
|---|---|
| Automatisation des opérations (auto-réparation) | Décision stable sur long cycle, idéal pour un agent SRE |
| Pipeline d'analyse de données | Appels d'outils en plusieurs étapes + agrégation |
| Revue de PR automatique + fusion | Capable de gérer un long processus de bout en bout |
| Scan de conformité + auto-correction | Traitement par lots sur des dépôts à grande échelle |
Application du mode 16-Agent Heavy de Grok 4.3 au codage
L'abonnement SuperGrok Heavy (300 $/mois) permet d'accéder à un système de planification parallèle à 16 agents. Dans le cadre du développement, cela implique :
| Tâche de codage | Mode agent unique | Mode 16-Agent Heavy |
|---|---|---|
| Analyse de grands dépôts | 30 minutes en série | 3–5 minutes en parallèle |
| Revue de PR complète | Lecture une par une | 16 PR traitées simultanément |
| Génération de tests unitaires par lots | Appel en série | 16 fichiers générés en parallèle |
| Migration de code multi-langage | Monothread | Multithreadé par module |
Bien que le mode 16-Agent soit réservé à l'abonnement et que l'API standard n'expose pas directement cette entrée, vous pouvez implémenter une orchestration multi-agent au niveau applicatif avec Grok 4.3 pour obtenir des résultats proches du mode Heavy natif. Avec la vitesse de 207 tps de Grok 4.3, sa capacité de traitement dépasse celle de Claude Opus 4.7 pour l'automatisation à grande échelle.
Avantages des outils côté serveur de Grok 4.3
Grok 4.3 intègre trois types d'outils côté serveur ; il suffit de déclarer le champ tools pour les utiliser, alors que pour Claude Opus 4.7, tout doit être construit au niveau applicatif.
| Outil intégré | Prix de Grok 4.3 | Alternative pour Claude Opus 4.7 |
|---|---|---|
| Recherche Web | 5 $ / 1k appels | Nécessite Tavily / SerpAPI |
| Exécution de code (bac à sable) | 5 $ / 1k appels | Nécessite un bac à sable Docker auto-hébergé |
| Recherche X (Twitter) | 5 $ / 1k appels | Aucune alternative |
Pour un agent de codage nécessitant une recherche en ligne et l'exécution de code, Grok 4.3 offre une intégration complète, là où Claude Opus 4.7 nécessiterait l'assemblage de trois services tiers, augmentant considérablement la complexité d'ingénierie.
💡 Conseil sur les outils serveur : Nous recommandons Grok 4.3 pour les agents de codage nécessitant une recherche web, car c'est la solution la moins coûteuse à intégrer. Si votre projet utilise déjà Claude Opus 4.7 avec des outils de recherche tiers, vous pouvez conserver Claude pour les tâches complexes et intégrer Grok 4.3 via APIYI (apiyi.com) pour les tâches nécessitant une recherche web.
Matrice de décision : Grok 4.3 peut-il remplacer Claude Opus 4.7 ?
Voici une matrice de décision actionnable basée sur les dimensions évoquées.
Décision selon le type de tâche
| Votre tâche de codage principale | Solution recommandée | Raison |
|---|---|---|
| Complétion IDE / suggestions en ligne | Grok 4.3 | 2,6x plus rapide + 1/10 du prix |
| Génération automatique de tests unitaires | Grok 4.3 | Couverture de 80%+ suffisante |
| Commentaires de code / documentation | Grok 4.3 | Tâche simple, qualité équivalente |
| Code Review (niveau PR) | Grok 4.3 | Prix bas, permet une revue complète |
| Correction de bugs simples | Grok 4.3 | Écart de précision minime |
| Refactorisation à grande échelle | Claude Opus 4.7 | SWE-bench Pro à 64,3 % reste inégalé |
| Correction de bugs critiques | Claude Opus 4.7 | Le coût d'un échec dépasse l'écart de prix |
| Multi-fichiers / Grands dépôts | Claude Opus 4.7 | Précision plus stable sur long contexte |
| Code légal / médical | Claude Opus 4.7 | Exigences de sécurité strictes |
| Agent d'automatisation des opérations | Grok 4.3 | Supérieur sur Vending-Bench |
| Développement guidé par vidéo | Grok 4.3 | Aucune alternative pour Claude |
| Recherche web + exécution bac à sable | Grok 4.3 | Outils intégrés côté serveur |
Décision selon le budget de l'équipe
| Budget mensuel IA | Configuration recommandée | Ajustement clé |
|---|---|---|
| < 200 $ | 100% Grok 4.3 | Claude réservé aux bugs critiques |
| 200 $ – 1500 $ | 80% Grok 4.3 + 20% Claude | Refactorisation multi-fichiers via Claude |
| 1500 $ – 10k $ | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | Trois niveaux de segmentation |
| > 10k $ | Routage auto + Batch + Cache | Architecture hybride obligatoire |
Décision selon la tolérance à l'erreur
| Tolérance à la précision | Choix recommandé |
|---|---|
| 90 % suffisant | Grok 4.3 (couvre 90 % des tâches) |
| 95 % nécessaire | Claude Opus 4.7 + Prompt Caching |
| 99 % impératif | Claude Opus 4.7 + mode xhigh + revue humaine |
🎯 Conseil sur l'architecture hybride : Sur la plateforme APIYI (apiyi.com), Grok 4.3 et Claude Opus 4.7 partagent la même
base_urlet clé API. Au niveau applicatif, il suffit de basculer le champmodelen fonction du tag de la tâche ou de la longueur des jetons. Le coût d'ingénierie pour cette architecture hybride est proche de zéro, tandis que les économies budgétaires peuvent atteindre 60 à 80 %.
Intégration et exemples de code pour Grok 4.3 et Claude Opus 4.7
Ces deux modèles sont entièrement compatibles avec le SDK OpenAI via le service proxy API APIYI, ce qui rend la migration quasi immédiate.
Appel unifié pour Grok 4.3 et Claude Opus 4.7
# Utilisez la même base_url + clé API, changez simplement le champ model pour appeler les deux modèles
from openai import OpenAI
client = OpenAI(
api_key="Votre clé API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Appel de Grok 4.3 (excellent rapport performance/prix)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Génère des tests unitaires pour cette fonction"}]
)
# Appel de Claude Opus 4.7 (haute précision)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactorise les dépendances circulaires de ces 5 fichiers"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Code complet pour le routage intelligent des scénarios de codage
Voir le code Python complet pour le routage automatique par type de tâche
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Votre clé API APIYI",
base_url="https://vip.apiyi.com/v1"
)
# Règles de classification des tâches de codage
SIMPLE_KEYWORDS = ["注释", "comment", "docstring", "rename", "format"]
TEST_KEYWORDS = ["单测", "unit test", "测试用例", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "重构", "跨文件", "循环依赖", "迁移"]
CRITICAL_KEYWORDS = ["关键 bug", "critical", "production fix", "合规"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Classifie la tâche selon les mots-clés de l'invite"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Sélectionne le modèle en fonction du type de tâche"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Appel avec routage intelligent pour le codage"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Estimation simplifiée
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Tu es un ingénieur full-stack senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Ajoute une docstring à cette fonction add"))
print(smart_code_call("Aide-moi à écrire 5 tests unitaires pytest"))
print(smart_code_call("Refactorise les dépendances circulaires de ces trois fichiers"))
print(smart_code_call("Bug critique en production, à corriger immédiatement"))
Points d'attention pour l'appel de Grok 4.3 et Claude Opus 4.7
| Point d'attention | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Champ modèle | grok-4.3 |
claude-opus-4-7 |
| Configuration reasoning | Activé par défaut | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | Automatique (75% de remise) | Déclaration explicite cache_control (90% de remise) |
| Batch API | 50% de remise | 50% de remise |
| Sortie maximale | Standard | 128K (nécessite max_tokens explicite) |
| Entrée vidéo | Champ video_url |
❌ Non supporté |
| Sortie document | extra_body={"output_format": ...} |
❌ Nécessite un post-traitement |
| Recherche web serveur | tools=[{"type": "web_search"}] |
❌ Nécessite un tiers |
| Function Calling | ✅ Complet | ✅ Complet |
🎯 Conseil d'intégration : Nous vous recommandons de demander une clé de test sur APIYI (apiyi.com) pour valider le flux complet. Grok 4.3 et Claude Opus 4.7 partagent la même clé API. Testez chacun sur 100 échantillons réels pour effectuer un test A/B avant de prendre votre décision finale.
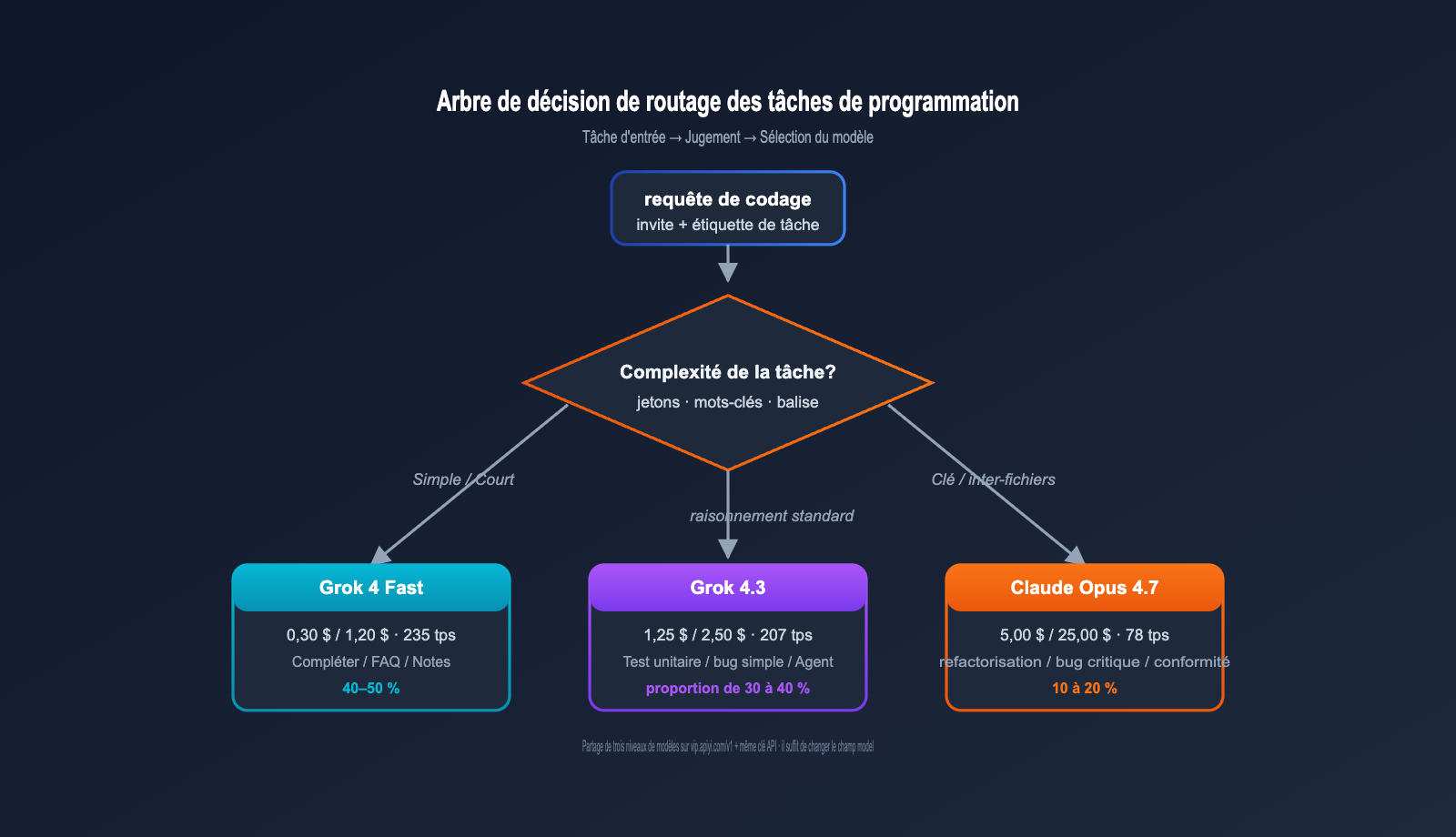
Grok 4.3 vs Claude Opus 4.7 : Recommandations pour vos scénarios de programmation
6 scénarios où privilégier Grok 4.3 comme modèle principal
Si votre activité correspond à l'un des cas suivants, Grok 4.3 est la solution la plus pertinente.
- Scénario 1 : Développeur indépendant / Projets personnels : Budget mensuel < 300 $, Grok 4.3 vous permet de multiplier vos tokens par 10.
- Scénario 2 : Codage simple à haute fréquence : Autocomplétion IDE, génération de tests unitaires, rédaction de commentaires, formatage de code.
- Scénario 3 : Agents à longue chaîne d'exécution : DevOps automatisé, agent de revue de PR, robot de scan de conformité.
- Scénario 4 : Développement piloté par la vidéo : Vidéo de reproduction de bug → solution de correction, animation UI → code frontend.
- Scénario 5 : Agent de codage + recherche sur le web : Outils
web_searchetcode_executionintégrés côté serveur. - Scénario 6 : Scénarios de conversation en temps réel : Débit de 207 tokens/s (tps), idéal pour le pair programming et l'autocomplétion en flux.
6 scénarios où privilégier Claude Opus 4.7 comme modèle principal
Si votre activité exige une haute précision, l'investissement dans Claude Opus 4.7 est justifié.
- Scénario 1 : Refactoring de code à grande échelle : 64,3 % sur SWE-bench Pro, le score le plus élevé du secteur.
- Scénario 2 : Correction de bugs critiques : Quand une erreur implique une reprise coûteuse, la précision l'emporte sur le coût.
- Scénario 3 : Analyse inter-fichiers / Grands dépôts : Besoin combiné d'une fenêtre de contexte étendue et d'une haute précision.
- Scénario 4 : Code sensible (conformité / sécurité) : Domaines juridique, médical et financier.
- Scénario 5 : Conception de systèmes complexes : Raisonnement architectural, conception d'API.
- Scénario 6 : Flux de travail Claude Code existant : L'équipe maîtrise déjà le CLI Claude Code, le coût de migration dépasse l'écart de prix.
Architecture hybride recommandée
Pour les équipes de développement de taille moyenne à grande, nous recommandons la répartition hybride suivante :
| Type de tâche | Modèle de routage | Suggestion de répartition |
|---|---|---|
| Complétion simple / FAQ | Grok 4 Fast | 40–50 % |
| Codage standard | Grok 4.3 | 30–40 % |
| Refactoring complexe / Bugs critiques | Claude Opus 4.7 | 10–20 % |
| Tâches extrêmement complexes (xhigh) | Claude Opus 4.7 + thinking | < 5 % |
Cette stratification réduit le coût global de l'IA de codage à 15–25 % de celui d'une utilisation « 100 % Claude Opus 4.7 », tout en maintenant la qualité des tâches critiques.
Comparaison des coûts pour une équipe de développement réelle
Le tableau suivant compare les coûts avant et après la transition vers une architecture hybride pour une équipe mixte de 30 personnes (backend/frontend) en mai 2026, basée sur des scénarios d'assistance IDE, d'agent de revue de PR et de génération de tests automatisés.
| Dimension | 100 % Claude Opus 4.7 | Architecture hybride (Grok 4.3 + Claude) |
|---|---|---|
| Volume mensuel | 1,2B de tokens | 1,2B de tokens |
| Part de Claude Opus 4.7 | 100 % | 12 % |
| Part de Grok 4.3 | 0 % | 70 % |
| Part de Grok 4 Fast | 0 % | 18 % |
| Facture mensuelle (incl. 35 % hausse tokenizer) | ~23 000 $ | ~3 800 $ |
| Économies réalisées | — | 83 % |
| Qualité tâches critiques (type SWE-bench Pro) | Base 100 % | ~99 % (via Claude) |
| Expérience tâches simples | Moyenne (78 tps) | Excellente (207 tps) |
| Temps de travail ingénierie requis | — | 16 heures-homme |
L'architecture hybride réduit les coûts à 17 % du montant initial sans perte notable de qualité, tout en multipliant par 2,6 la vitesse de réponse sur les tâches simples (grâce à Grok 4.3). C'est la mise à niveau architecturale la plus rentable pour les équipes de taille intermédiaire.
💡 Conseil d'implémentation : Nous recommandons de définir le niveau de difficulté au niveau du plugin IDE. La complétion simple est automatiquement routée vers Grok 4.3, tandis que les tâches complexes inter-fichiers vont vers Claude Opus 4.7. Sur la plateforme APIYI (apiyi.com), les deux modèles partagent la même gestion d'authentification et de quotas.
Foire aux questions (FAQ)
Q1 : Grok 4.3 peut-il vraiment remplacer Claude Opus 4.7 pour la programmation ?
En partie. Pour la génération de fonctions, les tests unitaires, les commentaires, les bugs simples et les agents à longue chaîne, la précision de Grok 4.3 est à moins de 5 points de Claude Opus 4.7 pour un prix 10 fois inférieur. Pour le refactoring complexe ou les bugs critiques, Claude Opus 4.7 reste la référence. L'approche la plus stable consiste à utiliser une architecture hybride via la plateforme APIYI apiyi.com pour router les tâches automatiquement.
Q2 : Quels sont les avantages différenciateurs de Grok 4.3 pour le codage ?
Six avantages majeurs : (1) 10 fois moins cher ; (2) 2,6 fois plus rapide (207 vs 78 tps) pour une meilleure fluidité IDE ; (3) Support natif de l'entrée vidéo ; (4) Génération de documents (PDF/XLSX/PPTX) en une seule étape ; (5) Supériorité sur les agents longue durée (Vending-Bench) ; (6) Outils intégrés (recherche web/exécution de code) réduisant de 60 % l'effort d'intégration.
Q3 : Le score de 87,6 % de Claude Opus 4.7 sur SWE-bench Verified est-il représentatif pour mes projets ?
En partie. Ce score mesure la réparation de bugs dans des dépôts open-source réels. C'est pertinent pour la compréhension de contextes longs. Cependant, les tâches quotidiennes (tests, commentaires, complétion) ne sont pas couvertes par ces benchmarks. Pour ces tâches, Grok 4.3 et Claude Opus 4.7 sont quasi équivalents.
Q4 : Le nouveau tokenizer de Claude Opus 4.7 va-t-il augmenter ma facture de 35 % ?
Oui, mais des solutions existent. Le nouveau tokenizer génère effectivement plus de tokens pour le code mixte. Solutions : (1) Activer le cache d'invites (prompt caching) ; (2) Utiliser l'API Batch ; (3) Router les tâches simples vers Grok 4.3 via APIYI apiyi.com. Ces mesures permettent de compenser intégralement cette hausse.
Q5 : Quel modèle pour les contextes longs (> 200k tokens) ?
Choisissez selon la précision requise. Claude Opus 4.7 domine pour l'analyse intégrale de dépôts massifs. Grok 4.3 est excellent pour le résumé de contexte long à un prix 10 fois moindre. Si vous devez trouver 3 bugs précis parmi 800k tokens, prenez Claude. Pour un résumé global, Grok 4.3 suffit.
Q6 : Quel modèle privilégier pour Cursor / Cline / Continue ?
La stratégie hybride. Pour l'autocomplétion en ligne, la vitesse de Grok 4.3 (207 tps) offre une meilleure expérience. Pour le refactoring entre fichiers, basculez sur Claude Opus 4.7. Configurez vos deux modèles sur APIYI apiyi.com avec une seule clé API pour un routage transparent.
Q7 : La facturation est-elle identique sur APIYI pour les deux modèles ?
Oui, la facturation est basée sur la consommation de tokens. Nous répercutons les tarifs officiels (Grok 4.3 : 1,25 $/2,50 $ ; Claude Opus 4.7 : 5,00 $/25,00 $). Le prompt caching et l'API Batch sont entièrement supportés sur notre service proxy API. Tout est centralisé sur un même solde pour une gestion comptable simplifiée.
Q8 : Quel effort pour migrer d’une solution 100 % Claude vers une architecture hybride ?
C'est très rapide. (1) Ajoutez une fonction de classification des tâches (environ 20 lignes) ; (2) Basculez le champ model entre claude-opus-4-7 et grok-4.3 selon la tâche ; (3) Déployez progressivement. Une journée suffit pour des économies de 60 à 80 %.
Q9 : Peut-on utiliser Grok 4.3 avec des outils comme Claude Code CLI ?
Pas directement, mais il existe des alternatives. Pour Grok 4.3, utilisez Aider (CLI open-source compatible avec les API type OpenAI) ou Continue.dev (plugin IDE). La communauté dispose déjà de plusieurs outils CLI optimisés pour Grok 4.3 en 2026.
Q10 : Qui est le plus stable pour l’Agentic Coding ?
Cela dépend du scénario. Pour des agents de codage précis à chaîne courte (type SWE-bench), Claude Opus 4.7 l'emporte. Pour les agents autonomes à longue chaîne (type Vending-Bench sur plusieurs jours), Grok 4.3 surpasse Claude de 1,5 à 2 fois. Utilisez les deux via APIYI en fonction du type de tâche.
Q11 : Comment intégrer Grok 4.3 dans Cursor ?
Cursor accepte des endpoints personnalisés : (1) Allez dans Paramètres > Models > Custom API Endpoint ; (2) Entrez https://vip.apiyi.com/v1 comme base_url et utilisez votre clé APIYI ; (3) Ajoutez le modèle grok-4.3. Vous pourrez ainsi basculer instantanément entre les deux modèles.
Résumé : Grok 4.3 peut-il remplacer Claude Opus 4.7 ?
Revenons à la question centrale de ce comparatif : Grok 4.3 peut-il remplacer Claude Opus 4.7 pour la programmation au quotidien ?
La réponse courte : Oui, il peut remplacer Claude Opus 4.7 pour 60 à 70 % des tâches de programmation courantes. Pour les 30 à 40 % de tâches complexes restantes, nous vous conseillons de garder Claude Opus 4.7.
Concrètement : pour la génération de fonctions, les tests unitaires, les commentaires, la correction de bugs simples et les agents à chaîne longue, l'écart de précision de Grok 4.3 est inférieur à 5 points de pourcentage, mais son prix ne représente qu'un dixième de celui de Claude, ce qui en fait un remplaçant parfait. En revanche, pour le refactoring multi-fichiers, les bugs dans les dépôts complexes et le code de conformité critique, Claude Opus 4.7 reste la référence du marché avec 64,3 % sur SWE-bench Pro, surpassant Grok de plus de 14 points. Pour ces cas, le remplacement n'est pas recommandé.
Plus important encore, Grok 4.3 n'est pas seulement une « version bon marché de Claude Opus 4.7 ». Il possède six avantages différenciateurs que Claude n'offre pas : un prix divisé par 10, une vitesse 2,6 fois supérieure, l'entrée vidéo, la génération de documents, des performances supérieures pour les agents à chaîne longue et des outils intégrés côté serveur. Ces capacités font de Grok 4.3, dans des scénarios tels que le développement piloté par vidéo, les agents d'exploitation automatisés ou les agents de codage avec accès au web, non pas un simple substitut, mais le point de départ idéal pour de nouveaux types d'applications.
Pour les développeurs, la mise en œuvre de cette architecture hybride « Grok 4.3 pour les tâches principales + Claude Opus 4.7 pour les chemins critiques » est facilitée par le service proxy API APIYI (apiyi.com). Les deux modèles partagent la même base_url et la même clé API ; il suffit de modifier le champ model au niveau de l'application pour basculer. Le prix de Grok 4.3 est répercuté à l'identique par rapport au site officiel xAI, et celui de Claude Opus 4.7 par rapport à Anthropic, sans aucune majoration. En ajoutant le prompt caching natif d'Anthropic (économie de 90 %) et la Batch API (économie supplémentaire de 50 %), le coût total de votre environnement de développement IA peut être réduit de 15 à 25 % par rapport à un usage « 100 % Claude Opus 4.7 », sans perte de qualité sur les tâches critiques.
Enfin, voici notre conseil pour les prochaines 24 heures : demandez une clé sur APIYI dès aujourd'hui, testez 100 tâches de codage réelles sur les deux modèles et laissez vos données réelles décider de la répartition hybride. Les benchmarks sont une référence, mais le taux de réussite sur vos propres projets est votre seul indicateur fiable.
Références
-
Annonce officielle d'Anthropic : Détails du lancement de Claude Opus 4.7
- Lien :
anthropic.com/claude/opus - Description : Inclut les tarifs, les benchmarks et les explications des champs API.
- Lien :
-
Documentation API d'Anthropic : Spécifications complètes de Claude Opus 4.7
- Lien :
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Description : Fenêtre de contexte, limites de sortie, changements de tokenizer.
- Lien :
-
Documentation des modèles xAI : Spécifications API complètes de Grok 4.3
- Lien :
docs.x.ai/developers/models - Description : Capacités exclusives comme l'entrée vidéo, la génération de documents et les outils côté serveur.
- Lien :
-
Rapport de référence Vellum : Évaluation détaillée de Claude Opus 4.7
- Lien :
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Description : Données SWE-bench Verified / Pro / CursorBench.
- Lien :
-
Classement Artificial Analysis : Comparaison des performances et des prix entre modèles
- Lien :
artificialanalysis.ai/models/claude-opus-4-7 - Description : Évaluation globale de l'intelligence, de la vitesse et des tarifs.
- Lien :
-
Comparateur de modèles DocsBot : Comparaison détaillée entre Grok 4.3 et Claude Opus 4.7
- Lien :
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Description : Tableau comparatif des prix, performances et caractéristiques.
- Lien :
-
Documentation d'intégration APIYI : Tutoriel complet pour l'accès aux deux modèles via un proxy
- Lien :
help.apiyi.com - Description : Inclut les noms de modèles, exemples de SDK et consultation de facturation.
- Lien :
Auteur : Équipe APIYI — Spécialiste du service proxy API pour grands modèles de langage, aidant les développeurs à invoquer en un clic les modèles leaders tels que Grok 4.3, Claude Opus 4.7, GPT-5.5, etc. Visitez apiyi.com pour obtenir un crédit de test gratuit.