في أبريل 2026، حطم نموذج Claude Opus 4.7 سقف نماذج البرمجة محققاً نتيجة 87.6% في معيار SWE-bench Verified. وبعد أسبوعين فقط، تحدت شركة xAI هذا الإجماع القائل بأن "نماذج البرمجة يجب أن تكون باهظة الثمن" بإطلاق نموذج Grok 4.3 الذي يكلف عُشر السعر فقط. تجيب هذه المقالة على أهم سؤالين لدى المطورين: هل يمكن لـ Grok 4.3 أن يحل محل Claude Opus 4.7 في مهام البرمجة؟ وإذا لم يكن بديلاً كاملاً، فما هي المزايا التنافسية التي تجعلنا نستخدم Grok 4.3؟
القيمة الجوهرية: بنهاية هذا المقال، ستعرف بوضوح ما إذا كان عليك اختيار Grok 4.3 أو Claude Opus 4.7 أو دمجهما معاً في سيناريوهات البرمجة الخاصة بك، وكيفية خفض التكاليف الإجمالية بأكثر من 60% عبر خدمة وكيل APIYI.

الفروق الجوهرية بين Grok 4.3 و Claude Opus 4.7
للحكم على "إمكانية الاستبدال"، سنقوم أولاً بمطابقة جميع المعلمات الرئيسية للنموذجين في الأبعاد المتعلقة بالبرمجة.
نظرة عامة على معلمات Grok 4.3 و Claude Opus 4.7
| بُعد المقارنة | Grok 4.3 | Claude Opus 4.7 | الفائز |
|---|---|---|---|
| تاريخ الإصدار | 2026-04-30 | 2026-04-16 | Claude (أسبق بـ 14 يوماً) |
| سعر الإدخال | $1.25 / 1M | $5.00 / 1M | Grok 4.3 |
| سعر الإخراج | $2.50 / 1M | $25.00 / 1M | Grok 4.3 |
| نافذة السياق | 1M tokens | 1M tokens | تعادل |
| الحد الأقصى للمخرجات | قياسي | 128K tokens | Claude |
| سرعة الإخراج | 207 tokens/ثانية | ~78 tokens/ثانية | Grok 4.3 |
| نمط التفكير (Reasoning) | مفعل افتراضياً | xhigh / تكيفي | Claude (أكثر دقة) |
| SWE-bench Verified | ~73% | 87.6% | Claude (+14.6pt) |
| SWE-bench Pro | غير معلن | 64.3% | Claude |
| CursorBench | غير معلن | 70% | Claude |
| Vending-Bench (العملاء الذكيون) | متفوق | متوسط | Grok 4.3 |
| خصم تخزين الموجه (Prompt Caching) | 75% | 90% | Claude |
| خصم Batch API | 50% | 50% | تعادل |
| إدخال الفيديو | ✅ أصلي | ❌ غير مدعوم | Grok 4.3 |
| إنشاء ملفات PDF/XLSX/PPTX | ✅ أصلي | ❌ يتطلب معالجة لاحقة | Grok 4.3 |
| أدوات الخادم | ✅ مدمجة (web/code) | ❌ يتطلب بناء ذاتي | Grok 4.3 |
الخلاصة في جملة واحدة
إذا أردنا اختصار الجدول أعلاه: يظل Claude Opus 4.7 هو المعيار الأعلى في "مهام البرمجة الحساسة للدقة"، بينما يعتبر Grok 4.3 الخيار الأمثل لسيناريوهات التطوير "الحساسة للتكلفة، والمسارات الطويلة، والوسائط المتعددة". العلاقة بينهما ليست استبدالية، بل هي أقرب إلى تقسيم العمل بين "الدقة مقابل كفاءة التكلفة".
🎯 اقتراح للتجربة السريعة: كلا النموذجين متاحان الآن على APIYI (apiyi.com)، و
base_urlالموحد هوhttps://vip.apiyi.com/v1. سعر Grok 4.3 مطابق تماماً للموقع الرسمي لشركة xAI ($1.25/$2.50)، وسعر Claude Opus 4.7 هو نفس السعر الرسمي لـ Anthropic ($5.00/$25.00) بدون أي زيادات، ويمكنك استدعاء النماذج مباشرة عبر OpenAI SDK.

مقارنة الأسعار: Grok 4.3 مقابل Claude Opus 4.7
يُعد السعر هو البعد الأكثر تباينًا في هذه المقارنة، وسنوضح ذلك من خلال ثلاثة مستويات: سعر الوحدة، التكاليف الخفية لـ tokenizer، والرسوم الشهرية للمشاريع النموذجية.
الأسعار القياسية: Grok 4.3 مقابل Claude Opus 4.7
يوضح الجدول أدناه الأسعار الرسمية المعلنة السارية في مايو 2026، حيث يتم تمرير تكاليف كلا النموذجين عبر خدمة وكيل APIYI وفقًا لأسعار الموقع الرسمي.
| عنصر التكلفة | Grok 4.3 | Claude Opus 4.7 | مضاعف السعر |
|---|---|---|---|
| tokens الإدخال | $1.25 / 1M | $5.00 / 1M | Claude أغلى بـ 4.0 مرات |
| tokens الإخراج | $2.50 / 1M | $25.00 / 1M | Claude أغلى بـ 10.0 مرات |
| الإدخال المخزن مؤقتًا | $0.31 / 1M | $0.50 / 1M | Claude أغلى بـ 1.6 مرة |
| السعر المختلط 3:1 | ~$1.56 / 1M | ~$10.00 / 1M | Claude أغلى بـ 6.4 مرات |
التكاليف الخفية لـ Tokenizer في Claude Opus 4.7
عند إطلاق Claude Opus 4.7، تم تغيير الـ tokenizer، وتشير الاختبارات الفعلية في الصناعة إلى أن نفس مدخلات الكود البرمجي تستهلك حوالي 35% من الـ tokens أكثر مقارنة بـ Opus 4.6. وهذا يعني أنه حتى لو لم يتغير سعر الوحدة الرسمي، فإن فاتورة الطلب الفعلية ستظل في ارتفاع.
| نوع المحتوى | tokens لـ Opus 4.6 | tokens لـ Opus 4.7 | تغير التكلفة الفعلي |
|---|---|---|---|
| كود إنجليزي بحت | 100k | 130k+ | +30% |
| كود مختلط (صيني/إنجليزي) | 100k | 135k+ | +35% |
| يحتوي على رموز تعبيرية / تعليقات | 100k | 140k+ | +40% |
بإضافة هذا العامل إلى مقارنة الأسعار، نجد أن تكلفة مهام البرمجة الفعلية لـ Claude Opus 4.7 مقارنة بـ Grok 4.3 تصل إلى 8–10 أضعاف، وليس 6.4 ضعفًا كما يظهر في جدول الأسعار.
💡 نصيحة لتحسين التكلفة: نوصي بتفعيل ميزة prompt caching عند إجراء استدعاءات طويلة لـ Claude Opus 4.7 (يمكن أن توفر 90%)، وهي الوسيلة الأساسية لمواجهة ارتفاع تكاليف الـ tokenizer. تدعم خدمة وكيل APIYI (apiyi.com) حقول التخزين المؤقت الأصلية لـ Anthropic بالكامل، دون الحاجة إلى عمل إضافي.
تقدير الرسوم الشهرية لمشاريع البرمجة الفعلية
فيما يلي تقدير شهري لعمل "مساعد برمجة لفريق متوسط الحجم"، بافتراض أن نسبة الإدخال إلى الإخراج هي 4:1 (حيث تكون المدخلات أطول في سيناريوهات البرمجة)، ودون احتساب خصومات التخزين المؤقت.
| حجم العمل | حجم الـ tokens شهريًا | رسوم Grok 4.3 الشهرية | رسوم Claude Opus 4.7 الشهرية | الفارق |
|---|---|---|---|---|
| مطور فردي | 50M | ~$70 | ~$700 (مع زيادة 35% في الـ tokens تصبح ~$945) | 13.5 ضعف |
| فريق متوسط | 1,000M | ~$1,400 | ~$14,000 (فعليًا ~$19,000) | 13.5 ضعف |
| مؤسسة كبيرة | 10,000M | ~$14,000 | ~$140,000 (فعليًا ~$189,000) | 13.5 ضعف |
يتضخم فارق السعر على مستوى المؤسسات ليصل إلى بنود ميزانية بملايين الدولارات سنويًا، وهذا هو السبب في أن البنية التحتية المختلطة أصبحت الحل السائد للذكاء الاصطناعي في البرمجة عام 2026.
🎯 نصيحة للميزانية: إذا كانت ميزانيتك الشهرية للذكاء الاصطناعي البرمجي أقل من 1500 دولار، نوصي باستخدام Grok 4.3 بشكل كامل، والتحويل إلى Claude Opus 4.7 فقط في اللحظات الحاسمة. تكلفة تنفيذ هذه الاستراتيجية على منصة APIYI (apiyi.com) تقترب من الصفر، حيث تحتاج فقط إلى تبديل حقل النموذج (model) في طبقة التطبيق بناءً على نوع المهمة.
مقارنة القدرات البرمجية: Grok 4.3 مقابل Claude Opus 4.7
بعيدًا عن السعر، ما يحدد القدرة على الاستبدال هو الكفاءة البرمجية. سننظر إليها من ثلاثة جوانب: معايير القياس العامة، سيناريوهات الهندسة الواقعية، ومهام السلاسل الطويلة.
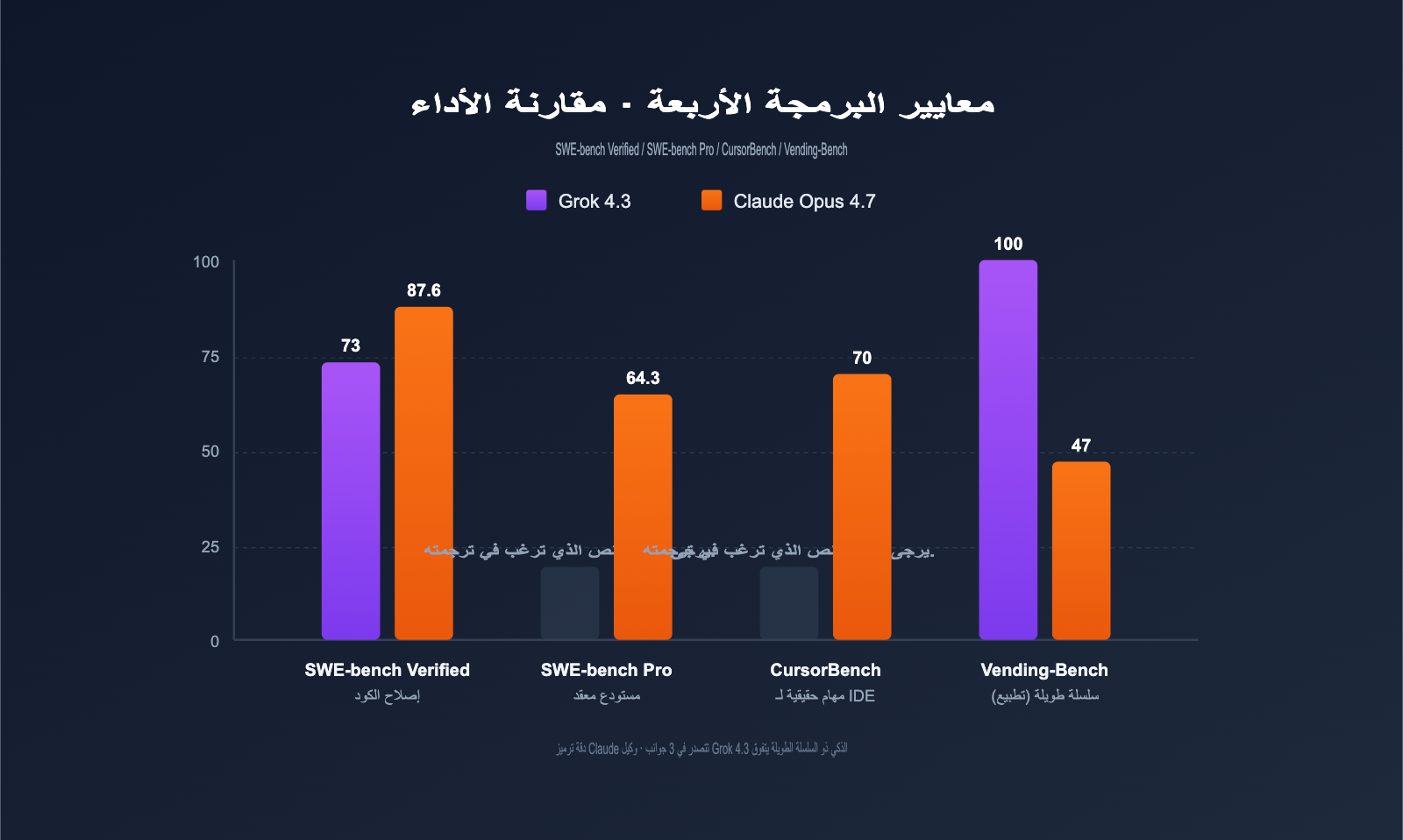
ملخص المقارنة البرمجية
| معيار البرمجة | Grok 4.3 | Claude Opus 4.7 | الفارق | نوع المهمة |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | إصلاح الكود الفعلي |
| SWE-bench Pro | غير معلن | 64.3% | Claude متفوق بوضوح | أخطاء المستودعات المعقدة |
| CursorBench | غير معلن | 70% | Claude متفوق بوضوح | مهام IDE الواقعية |
| Aider Polyglot | متوسط | قوي | Claude متفوق | نقل الكود متعدد اللغات |
| HumanEval+ | ممتاز | ممتاز | تعادل | توليد على مستوى الدالة |
| المهام الإنتاجية | جيد | 3 أضعاف Opus 4.6 | Claude متفوق | إصلاح الكود القديم |
| Vending-Bench (صافي الربح) | الأفضل | 47.1 | Grok 4.3 يتفوق | وكلاء السلاسل الطويلة |
| سرعة الإخراج (tps) | 207 | ~78 | Grok 4.3 أسرع بـ 166% | استجابة فورية |
باختصار: يتفوق Claude Opus 4.7 في المهام البرمجية التي تتطلب دقة عالية، بينما يتفوق Grok 4.3 في مهام الوكلاء ذات السلاسل الطويلة، ويعد أسرع بـ 2.6 مرة في الاستجابة الفورية.
تقييم المهام البرمجية (بالنجوم)
| المهمة البرمجية | Grok 4.3 | Claude Opus 4.7 | هل يمكن الاستبدال؟ |
|---|---|---|---|
| توليد كود على مستوى الدالة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ نعم |
| توليد اختبارات الوحدة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ نعم |
| تعليقات الكود / التوثيق | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ نعم |
| إصلاح الأخطاء البسيطة | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ نعم (فارق دقة ضئيل) |
| إعادة هيكلة نمط الكود | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ نعم |
| إعادة هيكلة عبر ملفات متعددة | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ لا يُنصح |
| إصلاح أخطاء المستودعات المعقدة | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ لا يُنصح |
| تصميم الأنظمة واسعة النطاق | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude يتفوق بوضوح |
| كود الامتثال القانوني / الطبي | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ يجب استخدام Claude |
| مهام الوكلاء (Agentic) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 يتفوق |
🎯 قاعدة الاستبدال: بالنسبة لمهام (الدوال + الاختبارات + التعليقات + الأخطاء البسيطة)، يمكن لـ Grok 4.3 استبدال Claude Opus 4.7 تمامًا وبتكلفة عُشر السعر. أما المهام المعقدة، فننصح بالبقاء مع Claude Opus 4.7. البنية المختلطة هي الحل الأمثل، ونوصي باستخدام التوجيه التلقائي عبر APIYI.
اختبارات المهام البرمجية الواقعية
| المهمة المختبرة | أداء Grok 4.3 | أداء Claude Opus 4.7 | نتيجة الاستبدال |
|---|---|---|---|
| كتابة مكون React | 8 ثوانٍ، نجاح من مرة | 18 ثانية، نجاح من مرة | ✅ استبدال (Grok أسرع بمرتين) |
| إصلاح خطأ NullPointer | 6 ثوانٍ، تحديد صحيح | 14 ثانية، تحديد + 3 حلول | ⚠️ استبدال جزئي |
| إعادة هيكلة تبعيات دائرية | 25 ثانية، محاولتان | 40 ثانية، نجاح من مرة | ❌ يُنصح بـ Claude |
| توليد اختبارات Python | 12 ثانية، تغطية 82% | 22 ثانية، تغطية 95% | ✅ استبدال (فارق مقبول) |
| وكيل طويل السلسلة (10 خطوات) | 50 ثانية، تنفيذ كامل | 90 ثانية، تعليق جزئي | ✅ Grok 4.3 يتفوق |
الأسباب التقنية لتفوق Claude Opus 4.7
يعود تفوق Claude Opus 4.7 في SWE-bench إلى استثمارات تقنية في:
- نمط التفكير (Reasoning): تخصيص tokens تفكير داخلية أكثر للمسائل المعقدة.
- التفكير التكيفي: تحديد الحاجة للتفكير الطويل أو القصير تلقائيًا.
- نافذة سياق 1M: معالجة ملفات كاملة أو مشاريع صغيرة دفعة واحدة.
- Tokenizer جديد: فهم أدق للكود البرمجي.
- بيانات التدريب الإنتاجية: قدرة أعلى على التعامل مع "الكود الحقيقي" مقارنة بـ "معايير القياس".
هذه المزايا تجعل تفوق Claude Opus 4.7 "هيكليًا" في المهام التي تتطلب استنتاجًا دقيقًا وسياقًا واسعًا، بينما تظل نافذة Grok 4.3 مفتوحة للمهام البرمجية اليومية والمهام السريعة.
تحليل معمق للمزايا التنافسية لنموذج Grok 4.3
إذا نظرنا فقط إلى معيار SWE-bench، فقد يبدو أن Grok 4.3 أقل شأناً من Claude Opus 4.7 في كل شيء. ولكن في سيناريوهات التطوير الفعلية، يمتلك Grok 4.3 قدرات لا يمتلكها Claude على الإطلاق، وهي تمثل نقاط القوة الحقيقية التي تميزه عن غيره.
مزايا السعر والسرعة في Grok 4.3
أولاً، السعر أرخص بـ 10 أضعاف. في معظم مهام البرمجة اليومية، يكون الفرق في الدقة بمستوى "90% مقابل 95%"، لكن الفرق في التكلفة بمستوى "1 دولار مقابل 10 دولارات". إن إسناد المهام البسيطة والمتكررة إلى Grok 4.3 يمكن أن يضاعف ميزانية أدوات الذكاء الاصطناعي لفريقك بمقدار 10 أضعاف.
ثانياً، سرعة المخرجات أسرع بـ 2.6 مرة. الفارق بين 207 tps و 78 tps يمثل تحولاً نوعياً في سيناريوهات حساسة للتأخير مثل "الإكمال التلقائي للكود عبر البث"، "اقتراحات IDE المضمنة"، و"البرمجة الثنائية الفورية". بينما سرعة 78 tps لنموذج Claude Opus 4.7 "تواكب سرعة تفكير الإنسان"، فإن 207 tps لنموذج Grok 4.3 هي "أسرع بمرتين من سرعة تفكير الإنسان".
قدرة Grok 4.3 على معالجة مدخلات الفيديو
هذه ميزة لا يمتلكها Claude Opus 4.7 على الإطلاق. يدعم Grok 4.3 مدخلات الفيديو بشكل أصلي، وإليك سيناريوهات التطبيق النموذجية:
| السيناريو | طريقة استخدام Grok 4.3 | البديل في Claude Opus 4.7 |
|---|---|---|
| تحويل تسجيل الشاشة إلى كود | إرسال ملف الفيديو مباشرة | يتطلب OCR + لقطات شاشة متعددة |
| فيديو إعادة إنتاج الخطأ → حل | طلب واحد | يتطلب تقسيم الفيديو يدوياً ووصفه |
| فيديو تعليمي → دروس برمجية | استخراج الإطارات والتحليل المباشر | غير ممكن |
| تصميم واجهة متحرك → كود واجهة | مدخلات الفيديو | غير ممكن |
إذا كان فريقك يتلقى فيديوهات لإعادة إنتاج الأخطاء من قسم ضمان الجودة (QA)، أو يرسل المصممون رسوماً متحركة للواجهات، أو تحتاج إلى استخراج الكود من دروس يوتيوب، فإن Grok 4.3 هو الحل الوحيد المتاح حالياً بفعالية عالية من حيث التكلفة.
قدرة Grok 4.3 على إنشاء المستندات
يمكن لـ Grok 4.3 إنشاء ملفات PDF/XLSX/PPTX مباشرة داخل المحادثة، وهذا يعني في سياق البرمجة:
# استدعاء سطر واحد في Grok 4.3 لإنشاء مستند واجهة برمجة التطبيقات بصيغة PDF
from openai import OpenAI
client = OpenAI(
api_key="مفتاح APIYI الخاص بك",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "قم بإنشاء مستند PDF بأسلوب OpenAPI لمسار FastAPI هذا: ..."
}],
extra_body={"output_format": "pdf"}
)
# الاستجابة تحتوي على رابط الملف القابل للتحميل
print(response.choices[0].message.attachments[0].url)
للقيام بنفس الشيء باستخدام Claude Opus 4.7، ستحتاج إلى سلسلة خطوات: Claude → Markdown → Pandoc → PDF. أما Grok 4.3 فيقوم بذلك في خطوة واحدة.
ميزة الوكيل (Agent) طويل المسار في Grok 4.3
يعد Vending-Bench معياراً للوكلاء طويلي المسار الذين يحاكيون "تشغيل آلة بيع لمدة 7 أيام"، ويتفوق Grok 4.3 بشكل ملحوظ على Claude Opus 4.7 في صافي الأرباح. وهذا يعني أنه في المهام التي تتطلب "اتخاذ قرارات مستمرة، استدعاء أدوات، وتذكر الحالة المتوسطة"، فإن Grok 4.3 أقوى في الواقع.
| سيناريو المسار الطويل | ميزة Grok 4.3 |
|---|---|
| التشغيل الآلي (التعافي الذاتي من الأعطال) | قرارات مستقرة في المسارات الطويلة، مناسب لوكلاء SRE |
| خط أنابيب تحليل البيانات | استدعاء أدوات متعدد الخطوات + تجميع النتائج |
| مراجعة ودمج PR تلقائياً | يمكنه إكمال سير عمل طويل بشكل مستقل |
| فحص الامتثال + الإصلاح التلقائي | معالجة جماعية للمستودعات الكبيرة |
تطبيق نمط 16-Agent Heavy في Grok 4.3 على البرمجة
يوفر Grok 4.3 نظام جدولة متوازٍ لـ 16 وكيلاً ضمن اشتراك SuperGrok Heavy (300 دولار/شهر)، وهذا يعني في سياق البرمجة:
| مهمة البرمجة | نمط الوكيل الفردي | نمط 16-Agent Heavy |
|---|---|---|
| تحليل مستودع كبير | 30 دقيقة تسلسلياً | 3–5 دقائق بالتوازي |
| مراجعة PR كاملة | مراجعة واحدة تلو الأخرى | 16 PR في وقت واحد |
| إنشاء اختبارات الوحدة | استدعاء تسلسلي | إنشاء متوازٍ لـ 16 ملفاً |
| ترحيل كود متعدد اللغات | خيط واحد | وحدات متعددة بالتوازي |
على الرغم من أن نمط 16-Agent محصور في فئة الاشتراك، ولا تعرض واجهة API القياسية مدخلاً مباشراً له، إلا أنه يمكنك تنفيذ تنسيق الوكلاء المتعددين (multi-agent) بنفسك في طبقة التطبيق باستخدام Grok 4.3، وستكون النتائج قريبة من نمط Heavy الأصلي. وبالاقتران مع سرعة 207 tps لـ Grok 4.3، فإن قدرة المعالجة في سيناريوهات أتمتة البرمجة واسعة النطاق تتفوق في الواقع على Claude Opus 4.7.
ميزة أدوات الخادم في Grok 4.3
يحتوي Grok 4.3 على ثلاث فئات من أدوات جانب الخادم مدمجة، يمكنك استخدامها بمجرد التصريح عن حقل tools، بينما يحتاج Claude Opus 4.7 إلى بناء هذه الأدوات في طبقة التطبيق.
| أداة مدمجة | سعر Grok 4.3 | بديل Claude Opus 4.7 |
|---|---|---|
| البحث عبر الويب | 5 دولارات / 1000 مرة | يتطلب الربط بـ Tavily / SerpAPI |
| تنفيذ الكود (Sandbox) | 5 دولارات / 1000 مرة | يتطلب بناء Docker Sandbox ذاتياً |
| البحث في X (Twitter) | 5 دولارات / 1000 مرة | لا يوجد بديل |
بالنسبة لوكيل برمجة يحتاج إلى بحث متصل بالإنترنت + تنفيذ كود، فإن Grok 4.3 يوفر حلاً متكاملاً، بينما يحتاج Claude Opus 4.7 إلى دمج ثلاث خدمات خارجية، مما يزيد من تعقيد الهندسة بشكل كبير.
💡 نصيحة حول أدوات الخادم: ننصح باختيار Grok 4.3 مباشرة لوكلاء البرمجة الذين يحتاجون إلى بحث عبر الويب، حيث أن تكلفة الدمج هي الأقل. إذا كان مشروعك يستخدم بالفعل Claude Opus 4.7 + بحث خارجي، يمكنك الاحتفاظ بـ Claude للمهام عالية الصعوبة، واستخدام APIYI (apiyi.com) للوصول إلى Grok 4.3 في نفس الوقت للمهام التي تتطلب بحثاً عبر الويب.
مصفوفة القرار: هل يمكن لـ Grok 4.3 أن يحل محل Claude Opus 4.7؟
إليك مصفوفة قرار قابلة للتنفيذ تلخص جميع الأبعاد السابقة.
القرار حسب نوع المهمة
| مهمة البرمجة الأساسية | الحل الموصى به | السبب |
|---|---|---|
| إكمال الكود / اقتراحات IDE | Grok 4.3 | سرعة أكبر بـ 2.6 مرة + سعر 1/10 |
| إنشاء اختبارات الوحدة تلقائياً | Grok 4.3 | تغطية 80%+ كافية |
| تعليقات الكود / إنشاء المستندات | Grok 4.3 | مهام بسيطة، جودة متساوية |
| مراجعة الكود (PR) | Grok 4.3 | سعر رخيص، يمكن مراجعة الكل |
| إصلاح الأخطاء البسيطة | Grok 4.3 | فرق دقة ضئيل |
| إعادة هيكلة واسعة النطاق | Claude Opus 4.7 | SWE-bench Pro 64.3% هو السقف |
| إصلاح أخطاء الوظائف الحرجة | Claude Opus 4.7 | تكلفة إعادة العمل أكبر من فرق السعر |
| عبر الملفات / مستودعات كبيرة | Claude Opus 4.7 | دقة نافذة السياق الطويل أكثر استقراراً |
| كود الامتثال القانوني / الطبي | Claude Opus 4.7 | متطلبات أمان/امتثال عالية |
| وكيل التشغيل الآلي | Grok 4.3 | تفوق في Vending-Bench للمسارات الطويلة |
| التطوير المعتمد على الفيديو | Grok 4.3 | لا يوجد بديل لـ Claude |
| بحث متصل + تنفيذ Sandbox | Grok 4.3 | أدوات خادم مدمجة |
القرار حسب ميزانية الفريق
| ميزانية الذكاء الاصطناعي الشهرية | التكوين الموصى به | التعديل الرئيسي |
|---|---|---|
| < 200 دولار | Grok 4.3 بالكامل | استخدم Claude للأخطاء الحرجة فقط |
| 200 – 1500 دولار | 80% Grok 4.3 + 20% Claude | إعادة الهيكلة عبر الملفات تستخدم Claude |
| 1500 – 10 آلاف دولار | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | تقسيم إلى ثلاث فئات |
| > 10 آلاف دولار | توجيه تلقائي + Batch + Cache | ضرورة اعتماد بنية هجينة |
القرار حسب تحمل نسبة الخطأ
| تحمل دقة المهمة | الخيار الموصى به |
|---|---|
| دقة 90% مقبولة | Grok 4.3 (تغطية 90% من المهام) |
| دقة 95% مطلوبة | Claude Opus 4.7 + Prompt Caching |
| دقة 99% ضرورية | Claude Opus 4.7 + نمط xhigh + مراجعة بشرية |
🎯 نصيحة حول البنية الهجينة: على منصة APIYI (apiyi.com)، يتشارك Grok 4.3 و Claude Opus 4.7 في نفس
base_urlوAPI Key. تحتاج طبقة التطبيق فقط إلى تبديل حقلmodelبناءً على تصنيف المهمة أو طول الرموز (token). تكلفة التعديل الهندسي لهذه البنية الهجينة تقترب من الصفر، بينما يمكن أن تصل وفورات الميزانية إلى 60–80%.
تتوافق كل من Grok 4.3 و Claude Opus 4.7 تماماً مع OpenAI SDK عبر خدمة وكيل API من APIYI، مما يجعل تكلفة الانتقال إليهما شبه معدومة.
الاستدعاء الموحد لـ Grok 4.3 و Claude Opus 4.7
# استخدم نفس base_url ومفتاح API، فقط قم بتبديل حقل model لاستدعاء أي من النموذجين
from openai import OpenAI
client = OpenAI(
api_key="مفتاح API الخاص بك من APIYI",
base_url="https://vip.apiyi.com/v1"
)
# استدعاء Grok 4.3 (فعالية عالية من حيث التكلفة)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "أنشئ اختبارات وحدة (unit tests) لهذه الدالة"}]
)
# استدعاء Claude Opus 4.7 (دقة عالية)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "قم بإعادة هيكلة الاعتمادات الدورية (circular dependencies) لهذه الملفات الخمسة"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
الكود الكامل للتوجيه الذكي في مهام البرمجة
عرض كود بايثون الكامل للتوجيه التلقائي بناءً على نوع المهمة
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="مفتاح API الخاص بك من APIYI",
base_url="https://vip.apiyi.com/v1"
)
# قواعد تصنيف مهام البرمجة
SIMPLE_KEYWORDS = ["تعليق", "comment", "docstring", "إعادة تسمية", "تنسيق"]
TEST_KEYWORDS = ["اختبار وحدة", "unit test", "حالات اختبار", "pytest"]
COMPLEX_KEYWORDS = ["إعادة هيكلة", "refactor", "عبر الملفات", "اعتماد دوري", "نقل"]
CRITICAL_KEYWORDS = ["خطأ حرج", "critical", "إصلاح إنتاج", "امتثال"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""تصنيف المهام بناءً على الكلمات المفتاحية في الموجه"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""اختيار النموذج بناءً على نوع المهمة"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""استدعاء التوجيه الذكي لمهام البرمجة"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # تقدير مبسط
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "أنت مهندس برمجيات محترف وشامل"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("أضف docstring لدالة الجمع هذه"))
print(smart_code_call("ساعدني في كتابة 5 اختبارات وحدة باستخدام pytest"))
print(smart_code_call("أعد هيكلة الاعتمادات الدورية في هذه الملفات الثلاثة"))
print(smart_code_call("خطأ حرج في بيئة الإنتاج، أصلحه فوراً"))
ملاحظات حول استدعاء Grok 4.3 و Claude Opus 4.7
| ملاحظة | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| حقل النموذج | grok-4.3 |
claude-opus-4-7 |
| إعداد التفكير (reasoning) | مفعل افتراضياً | extra_body={"thinking": {"type": "enabled"}} |
| التخزين المؤقت للموجه | تلقائي (خصم 75%) | تصريح صريح cache_control (خصم 90%) |
| واجهة برمجة الدفعات | خصم 50% | خصم 50% |
| الحد الأقصى للمخرجات | قياسي | 128 ألف (يتطلب تصريح max_tokens) |
| إدخال الفيديو | حقل video_url |
❌ غير مدعوم |
| مخرجات المستندات | extra_body={"output_format": ...} |
❌ يتطلب معالجة لاحقة |
| بحث الويب | tools=[{"type": "web_search"}] |
❌ يتطلب طرف ثالث |
| استدعاء الدوال | ✅ متكامل | ✅ متكامل |
🎯 نصيحة الربط: نوصي بطلب مفتاح اختبار من منصة APIYI على apiyi.com لتجربة دورة العمل بالكامل. يشترك كل من Grok 4.3 و Claude Opus 4.7 في نفس مفتاح API، لذا جرب 100 عينة عمل حقيقية لكل منهما لإجراء اختبار A/B قبل اتخاذ قرار الاختيار النهائي.
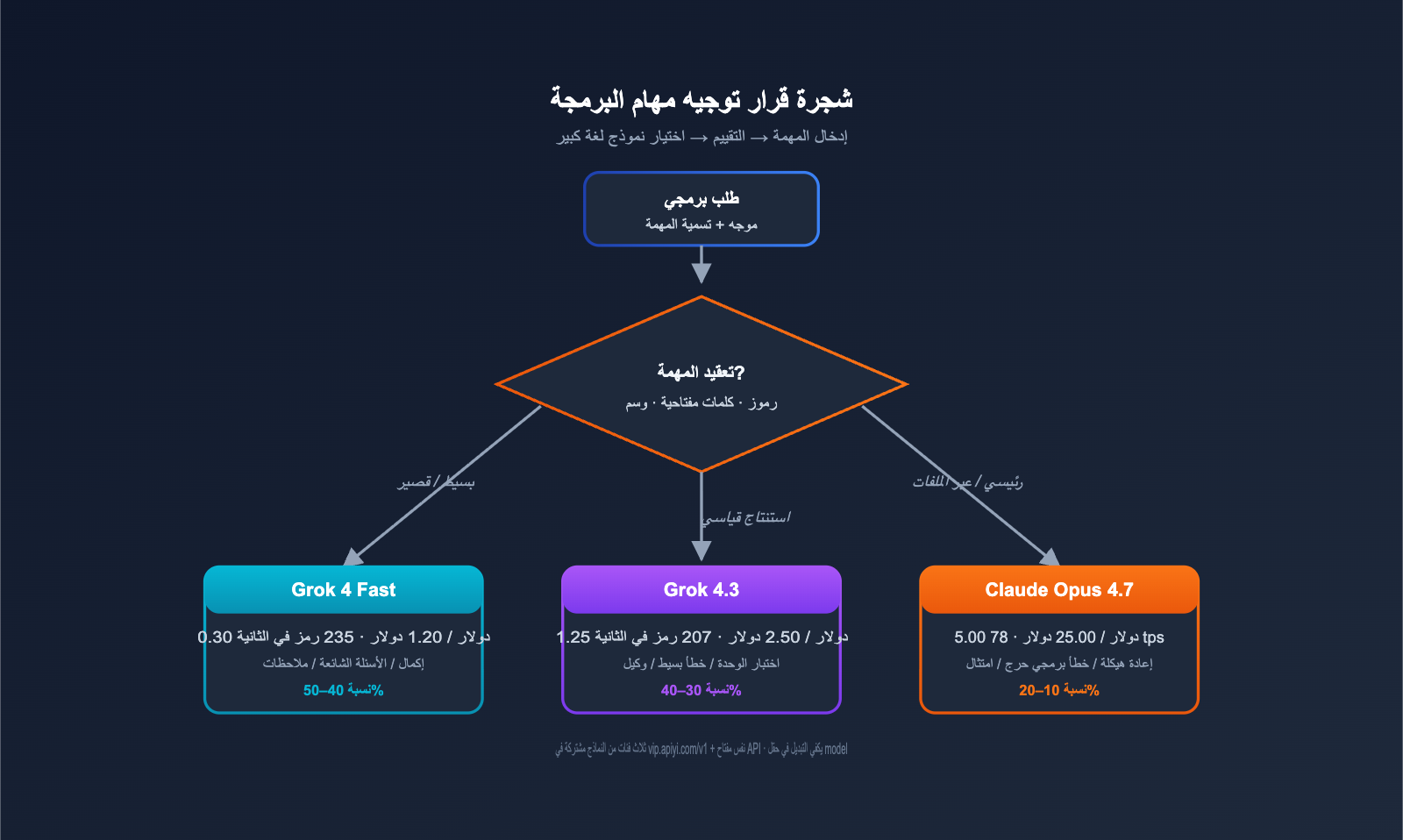
مقارنة بين Grok 4.3 و Claude Opus 4.7 في مهام البرمجة: التوصيات
6 سيناريوهات تجعل Grok 4.3 هو الخيار الأفضل كنموذج أساسي
إذا كان عملك يندرج تحت أي من الحالات التالية، فإن Grok 4.3 يمثل الخيار الأمثل:
- السيناريو 1: المطورون الأفراد / المشاريع المستقلة: إذا كانت ميزانيتك الشهرية أقل من 300 دولار، يمنحك Grok 4.3 قدرة على مضاعفة استخدام الـ tokens بـ 10 أضعاف.
- السيناريو 2: البرمجة البسيطة عالية التردد: الإكمال التلقائي في بيئة التطوير (IDE)، إنشاء اختبارات الوحدات (Unit Tests)، كتابة التعليقات، وتنسيق الكود.
- السيناريو 3: الوكلاء الأذكياء (Agents) ذوو السلاسل الطويلة: عمليات التشغيل والتحكم المؤتمتة، وكلاء مراجعة طلبات السحب (PR review)، وروبوتات فحص الامتثال.
- السيناريو 4: التطوير المعتمد على الفيديو: تحويل فيديوهات إعادة إنتاج الأخطاء (Bug reproduction) إلى حلول برمجية، أو تحويل رسوم واجهات المستخدم المتحركة إلى كود واجهة أمامية.
- السيناريو 5: وكيل برمجي مع بحث متصل بالإنترنت: مع أدوات بحث
web_searchوcode_executionمدمجة من جهة الخادم. - السيناريو 6: سيناريوهات المحادثة الفورية: بمعدل مخرجات يصل إلى 207 tokens في الثانية، وهو مثالي للبرمجة الثنائية (Pair Programming) والإكمال التلقائي المتدفق.
6 سيناريوهات تجعل Claude Opus 4.7 هو الخيار الأفضل كنموذج أساسي
إذا كانت طبيعة عملك تتطلب دقة فائقة، فإن Claude Opus 4.7 يستحق القيمة الإضافية:
- السيناريو 1: إعادة هيكلة الكود (Refactor) على نطاق واسع: بنسبة نجاح 64.3% في معيار SWE-bench Pro، وهو الأعلى في الصناعة.
- السيناريو 2: إصلاح الأخطاء البرمجية الحرجة: حيث تكون الدقة أهم من التكلفة لتجنب إعادة العمل.
- السيناريو 3: التحليل عبر ملفات متعددة / المستودعات الضخمة: الحاجة المزدوجة لسياق طويل ودقة عالية.
- السيناريو 4: الكود الحساس للأمان والامتثال: في مجالات القانون، الطب، والتمويل.
- السيناريو 5: تصميم الأنظمة المعقدة: استنتاج البنية التحتية وتصميم واجهات برمجة التطبيقات (API).
- السيناريو 6: سير عمل يعتمد بالفعل على Claude Code: إذا كان فريقك معتاداً على واجهة أوامر Claude Code، فإن تكلفة الانتقال أعلى من فارق السعر.
التوصية بتوزيع المهام (الهيكلية المختلطة)
بالنسبة لفرق التطوير متوسطة الحجم فما فوق، نوصي بالتوزيع التالي:
| نوع المهمة | النموذج الموجه إليه | النسبة المقترحة |
|---|---|---|
| إكمال تلقائي بسيط / أسئلة شائعة | Grok 4 Fast | 40–50% |
| البرمجة القياسية | Grok 4.3 | 30–40% |
| إعادة هيكلة معقدة / أخطاء حرجة | Claude Opus 4.7 | 10–20% |
| المهام شديدة التعقيد (xhigh) | Claude Opus 4.7 + thinking | < 5% |
هذا التوزيع يقلل تكاليف الذكاء الاصطناعي البرمجي الإجمالية إلى 15-25% من تكلفة استخدام "Claude Opus 4.7 بالكامل"، مع الحفاظ على جودة المهام الحرجة دون تغيير تقريباً.
مقارنة تكاليف الهيكلية المختلطة لفريق برمجي حقيقي
يوضح الجدول التالي مقارنة التكاليف لفريق مكون من 30 مطوراً (واجهات أمامية وخلفية) في مايو 2026 قبل وبعد التحول الهيكلي، حيث كانت المهام تشمل: "مساعد برمجة في IDE + وكيل مراجعة PR + إنشاء اختبارات مؤتمتة".
| البعد | Claude Opus 4.7 بالكامل | الهيكلية المختلطة (Grok 4.3 أساسي + Claude للمهام الحرجة) |
|---|---|---|
| حجم الاستدعاء الشهري | 1.2 مليار tokens | 1.2 مليار tokens |
| نسبة Claude Opus 4.7 | 100% | 12% |
| نسبة Grok 4.3 | 0% | 70% |
| نسبة Grok 4 Fast | 0% | 18% |
| الفاتورة الشهرية (مع زيادة 35% في الـ tokenizer) | ~$23,000 | ~$3,800 |
| توفير التكاليف | — | 83% |
| جودة المهام الحرجة (معيار SWE-bench Pro) | 100% (أساس) | ~99% (لا تزال تُنفذ عبر Claude) |
| تجربة المهام البسيطة | متوسطة (78 tps) | ممتازة (207 tps) |
| ساعات العمل الهندسية للتحول | — | 16 ساعة عمل |
تُقلل الهيكلية المختلطة التكلفة إلى 17% من التكلفة الأصلية، مع الحفاظ على جودة المهام الحرجة، وتحسين سرعة استجابة المهام البسيطة بمقدار 2.6 ضعف.
💡 نصيحة تنفيذية: نوصي بتحديد درجة صعوبة المهمة في إضافات IDE، بحيث تتوجه المهام البسيطة تلقائياً إلى Grok 4.3، بينما تتوجه المهام المعقدة إلى Claude Opus 4.7. على منصة APIYI apiyi.com، يستخدم كلا النموذجين نظاماً موحداً للمصادقة وإدارة الحصص، مما يجعل التكلفة الهندسية تحت السيطرة.
الأسئلة الشائعة حول Grok 4.3 و Claude Opus 4.7
Q1: هل يمكن لـ Grok 4.3 فعلياً أن يحل محل Claude Opus 4.7 في البرمجة؟
جزئياً، نعم. في مهام مثل "توليد الدوال، اختبارات الوحدات، التعليقات، إصلاح الأخطاء البسيطة، والوكلاء ذوي السلاسل الطويلة"، فإن الفرق في الدقة يقل عن 5% بينما السعر هو عُشر التكلفة. أما في "إعادة الهيكلة عبر ملفات، أخطاء المستودعات المعقدة، إصلاح الوظائف الحرجة، والكود الحساس"، يظل Claude Opus 4.7 هو الأفضل. الطريقة الأكثر استقراراً هي الهيكلية المختلطة عبر APIYI apiyi.com.
Q2: ما هي الميزات التنافسية لـ Grok 4.3 في البرمجة؟
ست ميزات رئيسية: (1) أرخص 10 مرات؛ (2) أسرع 2.6 مرة (207 مقابل 78 tps) لتجربة أفضل؛ (3) دعم أصلي لإدخال الفيديو؛ (4) إنشاء مستندات PDF/XLSX/PPTX بضغطة واحدة؛ (5) تفوقه في الوكلاء ذوي السلاسل الطويلة (Vending-Bench)؛ (6) أدوات خادم مدمجة (بحث/تنفيذ كود) مما يقلل مجهود الربط بنسبة 60%.
Q3: هل نسبة 87.6% التي حققها Claude Opus 4.7 في SWE-bench Verified تنطبق فعلياً على مشروعي؟
جزئياً. يقيس هذا المعيار "إصلاح الأخطاء في المستودعات مفتوحة المصدر"، وهو ما يعكس قوة Claude في فهم السياقات الطويلة. لكن المهام اليومية (اختبارات، تعليقات، إكمال تلقائي) لا تغطيها هذه الاختبارات، وفيها يتساوى Grok 4.3 مع Claude Opus 4.7 تقريباً.
Q4: هل سيؤدي الـ tokenizer الجديد في Claude Opus 4.7 إلى زيادة فاتورتي بـ 35%؟
نعم، لكن هناك حلول: (1) تفعيل التخزين المؤقت للموجه (Prompt Caching) الذي يوفر 90%؛ (2) تفعيل Batch API لتوفير 50% إضافية؛ (3) توجيه المهام البسيطة إلى Grok 4.3. يمكن دمج هذه الطرق عبر APIYI apiyi.com لإلغاء أثر زيادة الأسعار.
Q5: أي نموذج أستخدم للمهام ذات السياق الطويل (أكثر من 200 ألف tokens)؟
يعتمد ذلك على الدقة المطلوبة. يتفوق Claude Opus 4.7 في تحليل المستودعات العملاقة بالكامل. إذا كنت بحاجة لـ "البحث عن 3 أخطاء دقيقة في 800 ألف token"، اختر Claude؛ أما إذا كنت تحتاج إلى "ملخص شامل مع طرح أسئلة رئيسية"، فـ Grok 4.3 يكفي.
Q6: أي نموذج أفضل لأدوات مثل Cursor / Cline / Continue؟
استراتيجية هجينة هي الأمثل. استخدم Grok 4.3 للإكمال التلقائي وإعادة الهيكلة البسيطة لسرعته وتوفيره، وClaude Opus 4.7 للمهام المعقدة. APIYI apiyi.com يتيح لك مشاركة مفتاح API واحد لهذين النموذجين.
Q7: هل طرق المحاسبة متطابقة لنموذجيّ APIYI؟
نعم، كلاهما يحاسب بناءً على استخدام الـ tokens. نحن نوفر نفس أسعار المواقع الرسمية (xAI و Anthropic) مع دعم كامل للميزات مثل Prompt Caching و Batch API عبر رابط موحد: https://vip.apiyi.com/v1.
Q8: كم سأحتاج لتعديل الكود للتحول إلى الهيكلية المختلطة إذا كنت أستخدم Claude Opus 4.7 بالفعل؟
بسيط جداً؛ (1) أضف دالة تصنيف مهام (20 سطراً)؛ (2) بدل بين claude-opus-4-7 و grok-4.3 بناءً على نوع المهمة؛ (3) قم بتشغيل تجريبي لـ 5-10% من حركة المرور. يمكنك الانتهاء خلال يوم واحد وتوفير 60-80% من الميزانية.
Q9: هل يمكن استخدام Grok 4.3 مع أدوات CLI مثل Claude Code؟
لا يمكن مباشرة، ولكن يمكنك استخدام بدائل متوافقة مثل Aider أو Continue.dev أو تطوير أداة CLI خاصة عبر OpenAI SDK، حيث توجد بالفعل أدوات مفتوحة المصدر محسنة لـ Grok 4.3 في مجتمع المطورين.
Q10: أيهما أكثر استقراراً في برمجة الوكلاء (Agentic Coding)؟
لـ "الوكلاء دقيقي البرمجة" (مثل SWE-bench)، يتفوق Claude Opus 4.7. أما لـ "الوكلاء ذوي السلاسل الطويلة" (الذين يتخذون قرارات مستمرة لعدة أيام)، فإن Grok 4.3 يتفوق بمقدار 1.5 إلى 2 ضعف.
Q11: كيف يمكن لمستخدمي Cursor إضافة Grok 4.3 إلى سير عملهم؟
عبر Custom API Endpoint في إعدادات Cursor، أدخل https://vip.apiyi.com/v1 في خانة base_url مع مفتاح API من منصة APIYI، ثم حدد grok-4.3 كاسم للنموذج. هذا يتيح لك التنقل بحرية بين النموذجين داخل نافذة المحادثة.
الخلاصة: هل يمكن لـ Grok 4.3 أن يكون بديلاً لـ Claude Opus 4.7؟
بالعودة إلى السؤال الجوهري في هذه المقارنة: هل يمكن لـ Grok 4.3 أن يحل محل Claude Opus 4.7 في مهام البرمجة؟
الإجابة المباشرة هي: يمكنه استبدال 60–70% من مهام البرمجة اليومية، أما الـ 30–40% المتبقية من المهام المعقدة، فننصح بالاحتفاظ بـ Claude Opus 4.7 لها.
بشكل أكثر تحديداً: في مهام مثل توليد الدوال، كتابة اختبارات الوحدة (Unit Tests)، إضافة التعليقات، إصلاح الأخطاء البرمجية البسيطة، ووكلاء المهام ذات السلاسل الطويلة، فإن فجوة الدقة لدى Grok 4.3 تقل عن 5%، بينما تبلغ تكلفته عُشر (1/10) تكلفة Claude، لذا فهو بديل مثالي تماماً. أما في مهام إعادة هيكلة الكود عبر ملفات متعددة، إصلاح أخطاء المستودعات البرمجية المعقدة، والأكواد الحساسة المتعلقة بالامتثال، فإن Claude Opus 4.7 لا يزال يتصدر المشهد بفضل تحقيقه 64.3% في اختبار SWE-bench Pro، متفوقاً بفارق يزيد عن 14%، لذا لا ننصح بالاستبدال في هذه الحالات.
والأهم من ذلك، أن Grok 4.3 ليس مجرد "نسخة رخيصة من Claude Opus 4.7"، بل يتمتع بست ميزات تنافسية لا يملكها Claude: تكلفة أقل بـ 10 مرات، سرعة أكبر بـ 2.6 مرة، دعم مدخلات الفيديو، توليد المستندات، تفوق في وكلاء المهام ذات السلاسل الطويلة، وأدوات مدمجة على جانب الخادم. هذه القدرات تجعل من Grok 4.3 "بديلاً غير مثالي لـ Claude Opus 4.7، ولكنه نقطة الانطلاق الأفضل للمنتجات الجديدة" في مجالات مثل التطوير المعتمد على الفيديو، وكلاء التشغيل الآلي (Ops)، ووكلاء البرمجة المعتمدين على البحث عبر الإنترنت.
بالنسبة للمطورين العرب، فإن تنفيذ بنية هجينة تعتمد على "Grok 4.3 للمهام الأساسية + Claude Opus 4.7 للمسارات الحرجة" يتم بأقل احتكاك ممكن عبر خدمة وكيل APIYI (apiyi.com). حيث يشترك النموذجان في نفس base_url و مفتاح API واحد، ولا يتطلب الأمر سوى تغيير حقل model في طبقة التطبيق للتبديل بينهما. توفر APIYI أسعار Grok 4.3 بنسبة 1:1 كما في موقع xAI الرسمي، وأسعار Claude Opus 4.7 كما في موقع Anthropic الرسمي دون أي إضافات. وبالاستفادة من ميزات Anthropic الأصلية مثل التخزين المؤقت للموجه (Prompt Caching) التي توفر 90%، و Batch API التي توفر 50% إضافية، يمكن خفض تكاليف البرمجة بالذكاء الاصطناعي إلى 15–25% من تكلفة الاعتماد الكلي على Claude Opus 4.7، مع الحفاظ على جودة المهام الحرجة دون خسارة تذكر.
أخيراً، إليك نصيحة للتنفيذ خلال 24 ساعة: اطلب مفتاحاً من APIYI اليوم، وقم بتشغيل 100 مهمة برمجية فعلية على كلا النموذجين، واستخدم البيانات الحقيقية لتحديد نسبة الدمج المثالية. النتائج القياسية هي مجرد مرجع، أما معدل النجاح في أعمالك الخاصة هو المعيار النهائي لاتخاذ القرار.
مراجع
-
إعلان Anthropic الرسمي: تفاصيل إطلاق Claude Opus 4.7
- الرابط:
anthropic.com/claude/opus - توضيح: يتضمن التسعير، معايير الأداء (Benchmark)، وشرح حقول API.
- الرابط:
-
وثائق Anthropic API: المواصفات الكاملة لـ Claude Opus 4.7
- الرابط:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - توضيح: نافذة السياق، حدود المخرجات، وتغييرات الـ Tokenizer.
- الرابط:
-
وثائق نماذج xAI: مواصفات API الكاملة لـ Grok 4.3
- الرابط:
docs.x.ai/developers/models - توضيح: القدرات الحصرية مثل مدخلات الفيديو، توليد المستندات، وأدوات الخادم.
- الرابط:
-
تقرير Vellum المرجعي: تقييم مفصل لـ Claude Opus 4.7
- الرابط:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - توضيح: بيانات SWE-bench Verified / Pro / CursorBench.
- الرابط:
-
قائمة Artificial Analysis: مقارنة الأداء والسعر الشاملة بين النماذج
- الرابط:
artificialanalysis.ai/models/claude-opus-4-7 - توضيح: تقييم شامل لمؤشر الذكاء، السرعة، والسعر.
- الرابط:
-
مقارنة نماذج DocsBot: مقارنة تفصيلية بين Grok 4.3 و Claude Opus 4.7
- الرابط:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - توضيح: مقارنة السعر، الأداء، والخصائص.
- الرابط:
-
وثائق ربط APIYI: دليل كامل للربط مع النموذجين عبر خدمة الوكيل
- الرابط:
help.apiyi.com - توضيح: يتضمن حقول النماذج، أمثلة SDK، والاستعلام عن الفواتير.
- الرابط:
الكاتب: فريق APIYI — متخصصون في خدمات وكيل API لنماذج اللغة الكبيرة، نساعد المطورين على استدعاء نماذج مثل Grok 4.3، Claude Opus 4.7، و GPT-5.5 بضغطة زر. قم بزيارة APIYI على apiyi.com للحصول على رصيد تجريبي مجاني.