Claude Opus 4.7 setzte im April 2026 mit einem beeindruckenden SWE-bench Verified-Ergebnis von 87,6 % neue Maßstäbe für Coding-Modelle. Doch nur zwei Wochen später forderte xAI mit dem Grok 4.3 – das nur ein Zehntel kostet – den Konsens heraus, dass „leistungsstarke Coding-Modelle zwingend teuer sein müssen“. Dieser Artikel beantwortet die zwei brennendsten Fragen für Entwickler: Kann Grok 4.3 bei Programmieraufgaben als vollwertiger Ersatz für Claude Opus 4.7 dienen? und Welche Differenzierungsvorteile bietet Grok 4.3, falls ein kompletter Ersatz nicht möglich ist?
Kernwert: Nach diesem Artikel wissen Sie genau, wann Sie für Ihre Coding-Szenarien Grok 4.3, Claude Opus 4.7 oder eine Kombination aus beiden wählen sollten und wie Sie Ihre Kosten über den APIYI API-Proxy-Dienst um mehr als 60 % senken können.

Grok 4.3 vs. Claude Opus 4.7 Kernunterschiede
Um zu beurteilen, ob ein „Ersatz möglich ist“, vergleichen wir zunächst alle wichtigen Parameter beider Modelle in Bezug auf die Programmierung.
Grok 4.3 vs. Claude Opus 4.7 Parameterübersicht
| Vergleichsdimension | Grok 4.3 | Claude Opus 4.7 | Gewinner |
|---|---|---|---|
| Erscheinungsdatum | 30.04.2026 | 16.04.2026 | Claude (14 Tage früher) |
| Input-Preis | $1,25 / 1M | $5,00 / 1M | Grok 4.3 |
| Output-Preis | $2,50 / 1M | $25,00 / 1M | Grok 4.3 |
| Kontextfenster | 1M Token | 1M Token | Gleichstand |
| Maximale Ausgabe | Standard | 128K Token | Claude |
| Ausgabegeschwindigkeit | 207 Token/Sek. | ~78 Token/Sek. | Grok 4.3 |
| Reasoning-Modus | Standard an | xhigh / adaptiv | Claude (feiner) |
| SWE-bench Verified | ~73 % | 87,6 % | Claude (+14,6 Pkt.) |
| SWE-bench Pro | nicht veröffentlicht | 64,3 % | Claude |
| CursorBench | nicht veröffentlicht | 70 % | Claude |
| Vending-Bench (Agent) | Top-Tier | mittel | Grok 4.3 |
| Prompt Caching Rabatt | 75 % | 90 % | Claude |
| Batch API Rabatt | 50 % | 50 % | Gleichstand |
| Video-Input | ✅ nativ | ❌ nicht unterstützt | Grok 4.3 |
| Dok.-Gen. PDF/XLSX/PPTX | ✅ nativ | ❌ benötigt Nachb. | Grok 4.3 |
| Server-seitige Tools | ✅ integriert web/code | ❌ selbst zu bauen | Grok 4.3 |
Kurzfazit
Zusammengefasst lässt sich sagen: Claude Opus 4.7 bleibt das Maß der Dinge bei „präzisionssensiblen Coding-Aufgaben“, während Grok 4.3 die beste Wahl für „kostensensible, langkettige und multimodale“ Entwicklungsszenarien darstellt. Es ist kein Entweder-oder, sondern eine funktionale Arbeitsteilung zwischen „Präzision vs. Preis-Leistungs-Verhältnis“.
🎯 Schnellstart-Empfehlung: Beide Modelle sind über APIYI (apiyi.com) verfügbar; die
base_urlist einheitlichhttps://vip.apiyi.com/v1. Die Preise für Grok 4.3 entsprechen exakt den xAI-Listenpreisen ($1,25/$2,50) und Claude Opus 4.7 wird ohne Aufschlag zum Originalpreis von Anthropic ($5,00/$25,00) durchgereicht. Sie können die Modelle direkt über das OpenAI SDK aufrufen.

Grok 4.3 vs. Claude Opus 4.7 Preisvergleich
Der Preis ist der Faktor, der bei diesem Vergleich am stärksten ins Gewicht fällt. Wir betrachten ihn auf drei Ebenen: Einzelpreise, implizite Tokenizer-Kosten und die monatlichen Kosten für typische Projekte.
Grok 4.3 vs. Claude Opus 4.7 Standardpreise
Die folgende Tabelle zeigt die offiziellen Listenpreise (Stand: Mai 2026). Beide Modelle werden über den API-Proxy-Dienst von APIYI zum offiziellen Herstellerpreis abgerechnet.
| Abrechnungsposten | Grok 4.3 | Claude Opus 4.7 | Preisfaktor |
|---|---|---|---|
| Input-Tokens | 1,25 $ / 1M | 5,00 $ / 1M | Claude ist 4,0-mal teurer |
| Output-Tokens | 2,50 $ / 1M | 25,00 $ / 1M | Claude ist 10,0-mal teurer |
| Input-Caching | 0,31 $ / 1M | 0,50 $ / 1M | Claude ist 1,6-mal teurer |
| 3:1 Mischpreis | ~1,56 $ / 1M | ~10,00 $ / 1M | Claude ist 6,4-mal teurer |
Die impliziten Tokenizer-Kosten von Claude Opus 4.7
Mit der Einführung von Claude Opus 4.7 wurde ein neuer Tokenizer eingeführt. Branchenmessungen zeigen, dass bei identischem Code-Input ca. 35 % mehr Tokens anfallen als bei Opus 4.6. Das bedeutet: Auch wenn der offizielle Einzelpreis unverändert bliebe, steigen die tatsächlichen Kosten pro Anfrage.
| Inhaltstyp | Opus 4.6 Tokens | Opus 4.7 Tokens | Tatsächliche Kostenänderung |
|---|---|---|---|
| Reiner englischer Code | 100k | 130k+ | +30% |
| Chinesisch-gemischter Code | 100k | 135k+ | +35% |
| Mit vielen Emojis / Kommentaren | 100k | 140k+ | +40% |
Berücksichtigt man diesen Faktor im Preisvergleich, liegen die tatsächlichen Kosten für Programmieraufgaben bei Claude Opus 4.7 im Vergleich zu Grok 4.3 beim 8- bis 10-fachen, nicht nur beim 6,4-fachen laut Preisliste.
💡 Tipp zur Kostenoptimierung: Wir empfehlen, bei langen Eingabeaufforderungen für Claude Opus 4.7 das Prompt-Caching zu aktivieren (bis zu 90 % Ersparnis), um die höheren Tokenizer-Kosten auszugleichen. Der API-Proxy-Dienst von APIYI (apiyi.com) unterstützt die nativen Caching-Felder von Anthropic vollständig – eine zusätzliche Implementierung ist nicht erforderlich.
Grok 4.3 vs. Claude Opus 4.7 monatliche Projektkosten-Schätzung
Hier ist eine Schätzung für ein „Code-Assistent-Team mittlerer Größe“, basierend auf einem Input-Output-Verhältnis von 4:1 (längere Inputs bei Programmieraufgaben), ohne Berücksichtigung von Caching-Rabatten.
| Geschäftsvolumen | Monatliches Token-Volumen | Monatliche Kosten Grok 4.3 | Monatliche Kosten Claude Opus 4.7 | Differenz |
|---|---|---|---|---|
| Einzelentwickler | 50M | ~70 $ | ~700 $ (inkl. 35% Token-Zuwachs ca. 945 $) | 13,5-fach |
| Mittleres Team | 1.000M | ~1.400 $ | ~14.000 $ (tatsächlich ca. 19.000 $) | 13,5-fach |
| Großunternehmen | 10.000M | ~14.000 $ | ~140.000 $ (tatsächlich ca. 189.000 $) | 13,5-fach |
Der Preisunterschied summiert sich bei Unternehmenskunden schnell auf Budgets im Bereich von mehreren Millionen Dollar pro Jahr. Deshalb ist eine hybride Architektur im Jahr 2026 der Standard für Coding-KI.
🎯 Budget-Empfehlung: Wenn Ihr monatliches Budget für Coding-KI unter 1.500 $ liegt, nutzen Sie bevorzugt Grok 4.3 und wechseln Sie nur in kritischen Fällen auf Claude Opus 4.7. Dank APIYI (apiyi.com) ist der technische Aufwand dafür minimal – Sie müssen lediglich auf Anwendungsebene das
model-Feld je nach Aufgabenstellung anpassen.
Grok 4.3 vs. Claude Opus 4.7 Programmierfähigkeiten
Jenseits des Preises entscheidet die Programmierleistung darüber, ob ein Modell ein vollwertiger Ersatz sein kann. Wir betrachten dies aus drei Perspektiven: öffentliche Benchmarks, echte Engineering-Szenarien und Langketten-Aufgaben.
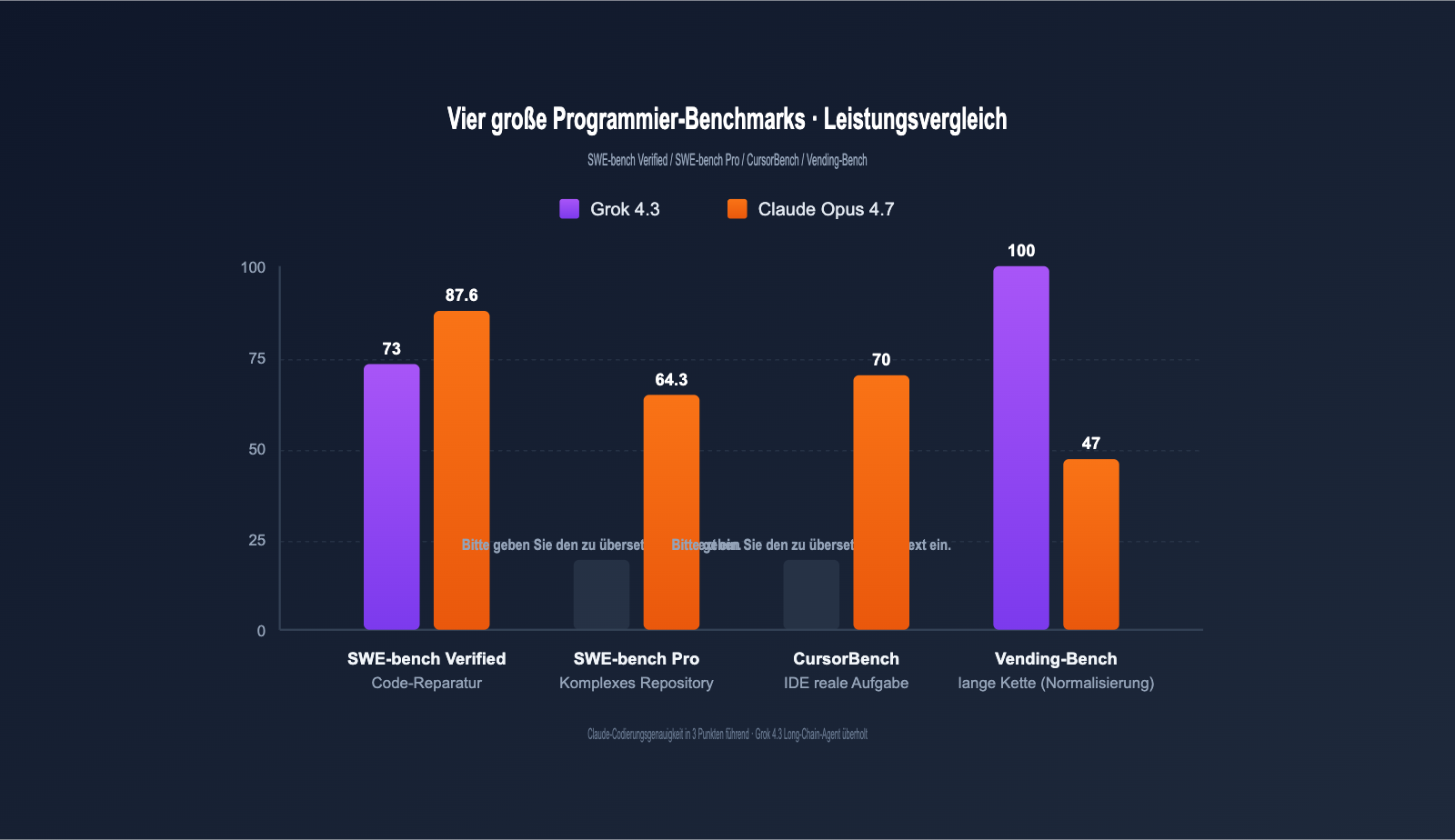
Zusammenfassung der Programmier-Benchmarks
In präzisionskritischen Aufgaben führt Claude Opus 4.7 mit einem Vorsprung von ca. 14–17 Prozentpunkten. Bei Langketten-Agenten-Aufgaben überholt Grok 4.3 jedoch, und bei der Echtzeit-Antwortgeschwindigkeit ist Grok 4.3 etwa 2,6-mal schneller.
Coding-Aufgaben: Bewertung nach Komplexität
| Coding-Aufgabe | Grok 4.3 | Claude Opus 4.7 | Als Ersatz geeignet? |
|---|---|---|---|
| Funktionsgenerierung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Ja, vollwertig |
| Unit-Test-Erstellung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Ja, vollwertig |
| Dokumentation/Kommentare | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Ja, vollwertig |
| Einfache Bug-Fixes | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Ja, (geringe Differenz) |
| Refactoring (Code-Stil) | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Ja, gut geeignet |
| Dateiübergreifendes Refactoring | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Nicht empfohlen |
| Komplexe Bug-Fixes | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Nicht empfohlen |
| Skalierbares Systemdesign | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude klar überlegen |
| Recht/Medizin-Code | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Nur Claude |
| Agenten-Langketten | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 besser |
🎯 Fazit zum Ersatz: Für Aufgaben wie „Funktionen + Tests + Kommentare + einfache Bugs“ ist Grok 4.3 bei 1/10 der Kosten ein idealer Ersatz. Für „dateiübergreifende Arbeiten + komplexes Refactoring + kritische Bugs“ sollte Claude Opus 4.7 beibehalten werden. Wir empfehlen das Routing nach Aufgaben-Labeln über den APIYI-Kanal.
Zusammenfassung der technischen Gründe für Claudes Vorsprung
Der technologische Vorsprung von Claude Opus 4.7 bei komplexen Aufgaben (wie auf dem SWE-bench) beruht auf:
- xHigh Reasoning Modus: Mehr interne Reasoning-Tokens für komplexe logische Fragen.
- Adaptives Denken: Intelligente Steuerung der Rechenressourcen.
- 1M Kontext + 128K Output: Ermöglicht die Verarbeitung ganzer Dateien oder kleiner Projekte in einem Rutsch.
- Optimiertes Training: Durch reale Produktionsdaten („Echter Code“ übertrifft Benchmark-Optimierung).
Diese Stärken sind strukturell – für kurze Aufgaben, Code-Vervollständigung oder Tests bietet Grok 4.3 jedoch das bessere Preis-Leistungs-Verhältnis.
Tiefenanalyse der differenzierten Vorteile von Grok 4.3
Betrachtet man nur den SWE-bench, scheint Grok 4.3 in fast allen Belangen hinter Claude Opus 4.7 zurückzubleiben. Doch in realen Entwicklungsszenarien bietet Grok 4.3 einige Fähigkeiten, die Claude schlichtweg fehlen – und genau das sind seine echten Alleinstellungsmerkmale.
Preis- und Geschwindigkeitsvorteile von Grok 4.3
Erstens ist es 10-mal günstiger. Bei den meisten alltäglichen Programmieraufgaben liegt der Genauigkeitsunterschied im Bereich von „90 % zu 95 %“, aber der Kostenunterschied bewegt sich im Bereich von „1 $ zu 10 $“. Wenn Sie hochfrequente, einfache Aufgaben an Grok 4.3 delegieren, lässt sich das Budget für KI-Tools im Team effektiv verzehnfachen.
Zweitens ist die Ausgabegeschwindigkeit 2,6-mal höher. Der Unterschied zwischen 207 tps und 78 tps ist bei latenzempfindlichen Szenarien wie „Streaming-Code-Vervollständigung“, „IDE-Inline-Vorschlägen“ oder „Echtzeit-Pair-Programming“ ein qualitativer Sprung. Während die 78 tps von Claude Opus 4.7 beim Tippen gerade so „mit dem menschlichen Denken mithalten“, sind die 207 tps von Grok 4.3 bereits „doppelt so schnell wie das menschliche Gehirn“.
Video-Eingabefähigkeiten von Grok 4.3
Dies ist eine Fähigkeit, die Claude Opus 4.7 überhaupt nicht besitzt. Grok 4.3 unterstützt nativ die Videoeingabe. Typische Anwendungsszenarien:
| Szenario | Grok 4.3 Vorgehensweise | Claude Opus 4.7 Alternative |
|---|---|---|
| Bildschirmaufnahme zu Code | Direkter Upload der Videodatei | Erfordert OCR + mehrere Screenshots |
| Bug-Reproduktionsvideo → Fix | Eine einzige Anfrage | Manuelles Zerlegen in Frames nötig |
| Lehrvideo → Code-Tutorial | Direkte Frame-Analyse | Nicht möglich |
| UI-Design-Animation → Frontend-Code | Videoeingabe | Nicht möglich |
Wenn Ihr Team Bug-Reproduktionsvideos von der Qualitätssicherung erhält, Designer UI-Animationen einreichen oder Sie Code aus YouTube-Tutorials rekonstruieren müssen, ist Grok 4.3 derzeit die einzige praktikable und kosteneffiziente Lösung.
Dokumentenerstellung mit Grok 4.3
Grok 4.3 kann direkt im Chat PDF-, XLSX- oder PPTX-Dateien erstellen. Im Programmierkontext bedeutet das:
# Grok 4.3 generiert mit einem API-Aufruf direkt ein API-Dokument als PDF
from openai import OpenAI
client = OpenAI(
api_key="Ihr APIYI API-Schlüssel",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Erstelle für diese FastAPI-Route eine OpenAPI-Dokumentation als PDF: ..."
}],
extra_body={"output_format": "pdf"}
)
# Die Antwort enthält die URL zum Download der Datei
print(response.choices[0].message.attachments[0].url)
Um dasselbe mit Claude Opus 4.7 zu erreichen, wäre eine Kette aus Claude → Markdown → Pandoc → PDF erforderlich. Grok 4.3 erledigt dies in einem Schritt.
Vorteile bei Agenten mit langen Prozessketten
Vending-Bench ist ein Benchmark für Agenten mit langen Prozessketten, der den „7-tägigen Betrieb eines Verkaufsautomaten“ simuliert. Hier liegt der Nettoertrag von Grok 4.3 deutlich vor Claude Opus 4.7. Das bedeutet, dass Grok 4.3 bei Agenten-Aufgaben, die „kontinuierliche Entscheidungsfindung, Werkzeugnutzung und das Speichern von Zwischenzuständen“ erfordern, tatsächlich stärker ist.
| Szenario mit langer Kette | Vorteil von Grok 4.3 |
|---|---|
| Automatisierter Betrieb (Selbstheilung bei Fehlern) | Stabile Entscheidungsfindung, ideal für SRE-Agenten |
| Datenanalyse-Pipelines | Mehrstufiger Werkzeugaufruf + Ergebnisaggregation |
| Automatisches PR-Review + Merge | Kann lange Prozesse eigenständig abschließen |
| Compliance-Scans + automatische Korrektur | Batch-Verarbeitung großer Repositories |
Anwendung des 16-Agent Heavy-Modus von Grok 4.3 beim Programmieren
Grok 4.3 bietet im SuperGrok Heavy-Abonnement (300 $/Monat) ein System zur parallelen Planung von 16 Agenten. Beim Programmieren bedeutet das:
| Programmieraufgabe | Einzel-Agent-Modus | 16-Agent Heavy-Modus |
|---|---|---|
| Analyse großer Repositories | Seriell 30 Minuten | Parallel 3–5 Minuten |
| Vollständiges PR-Review | Nacheinander | 16 PRs gleichzeitig |
| Batch-Generierung von Unit-Tests | Serieller Aufruf | 16 Dateien parallel |
| Sprachübergreifende Code-Migration | Single-Threaded | Modulübergreifend parallel |
Obwohl der 16-Agent-Modus an das Abonnement gebunden ist und die Standard-API-Schnittstelle den 16-Agent-Einstieg nicht direkt offenlegt, können Sie auf Anwendungsebene mit Grok 4.3 selbst eine Multi-Agenten-Orchestrierung implementieren, die dem nativen Heavy-Modus nahekommt. In Kombination mit der Ausgabegeschwindigkeit von 207 tps ist die Durchsatzleistung von Grok 4.3 bei groß angelegter Programmierautomatisierung tatsächlich höher als die von Claude Opus 4.7.
Serverseitige Werkzeuge von Grok 4.3
Grok 4.3 verfügt über drei integrierte serverseitige Werkzeuge, die durch Deklaration des tools-Feldes genutzt werden können. Bei Claude Opus 4.7 müsste all dies auf Anwendungsebene selbst gebaut werden.
| Integriertes Werkzeug | Grok 4.3 Preis | Claude Opus 4.7 Alternative |
|---|---|---|
| Web-Suche | 5 $ / 1k Anfragen | Erfordert Tavily / SerpAPI |
| Code-Ausführung (Sandbox) | 5 $ / 1k Anfragen | Erfordert eigene Docker-Sandbox |
| X (Twitter) Suche | 5 $ / 1k Anfragen | Keine Alternative |
Für einen Programmier-Agenten, der Web-Recherche und Code-Ausführung benötigt, ist Grok 4.3 eine Komplettlösung. Bei Claude Opus 4.7 müssten Sie drei Drittanbieterdienste kombinieren, was die technische Komplexität massiv erhöht.
💡 Empfehlung für serverseitige Werkzeuge: Wir empfehlen für Programmier-Agenten mit Web-Recherche direkt Grok 4.3, da die Integrationskosten am niedrigsten sind. Falls Ihr Projekt bereits Claude Opus 4.7 + Drittanbieter-Suche nutzt, können Sie Claude für komplexe Aufgaben beibehalten und über APIYI (apiyi.com) zusätzlich Grok 4.3 für Aufgaben einbinden, die eine Web-Suche erfordern.
Entscheidungsmatrix: Kann Grok 4.3 Claude Opus 4.7 ersetzen?
Hier ist eine zusammenfassende Entscheidungsmatrix für alle zuvor genannten Dimensionen.
Entscheidung nach Aufgabentyp
| Ihre Kernaufgabe | Empfohlene Lösung | Grund |
|---|---|---|
| IDE-Code-Vervollständigung | Grok 4.3 | 2,6x schneller + 1/10 Preis |
| Automatisierte Unit-Tests | Grok 4.3 | 80%+ Abdeckung reicht aus |
| Code-Kommentare / Dokumentation | Grok 4.3 | Einfache Aufgabe, gleiche Qualität |
| Code Review (PR-Ebene) | Grok 4.3 | Günstig, vollständige Prüfung möglich |
| Einfache Bug-Fixes | Grok 4.3 | Geringer Genauigkeitsunterschied |
| Großflächiges Refactoring | Claude Opus 4.7 | SWE-bench Pro 64,3 % ist das Limit |
| Kritische Bug-Fixes | Claude Opus 4.7 | Nachbesserungskosten bei Fehlern > Preisdifferenz |
| Dateiübergreifend / Große Repos | Claude Opus 4.7 | Höhere Präzision bei langem Kontext |
| Rechtliche / Medizinische Compliance | Claude Opus 4.7 | Hohe Sicherheits-/Compliance-Anforderungen |
| Automatisierte SRE-Agenten | Grok 4.3 | Überlegen bei langen Ketten (Vending-Bench) |
| Video-gestützte Entwicklung | Grok 4.3 | Keine Claude-Alternative |
| Web-Suche + Sandbox-Ausführung | Grok 4.3 | Integrierte serverseitige Werkzeuge |
Entscheidung nach Teambudget
| Monatliches KI-Budget | Empfohlene Konfiguration | Wichtige Anpassung |
|---|---|---|
| < 200 $ | Vollständig Grok 4.3 | Claude nur für kritische Bugs |
| 200 $ – 1500 $ | 80 % Grok 4.3 + 20 % Claude | Dateiübergreifendes Refactoring mit Claude |
| 1500 $ – 10k $ | 50 % Grok 4.3 + 30 % Claude + 20 % Grok 4 Fast | Dreistufige Schichtung |
| > 10k $ | Automatisches Routing + Batch + Cache | Hybride Architektur zwingend |
Entscheidung nach Genauigkeitstoleranz
| Genauigkeitstoleranz | Empfohlene Wahl |
|---|---|
| 90 % Genauigkeit akzeptabel | Grok 4.3 (90 % Aufgabenabdeckung) |
| 95 % Genauigkeit erforderlich | Claude Opus 4.7 + Prompt Caching |
| 99 % Genauigkeit zwingend | Claude Opus 4.7 + xhigh-Modus + manuelle Prüfung |
🎯 Empfehlung zur hybriden Architektur: Auf der Plattform APIYI (apiyi.com) teilen sich Grok 4.3 und Claude Opus 4.7 denselben
base_urlund API-Schlüssel. Auf Anwendungsebene müssen Sie lediglich dasmodel-Feld basierend auf dem Aufgaben-Tag oder der Token-Länge umschalten. Die technischen Anpassungskosten für diese hybride Architektur sind nahezu null, während die Budgeteinsparungen 60–80 % erreichen können.
Integration und Codebeispiele für Grok 4.3 und Claude Opus 4.7
Beide Modelle sind über den APIYI API-Proxy-Dienst vollständig mit dem OpenAI SDK kompatibel, wodurch die Migrationskosten nahezu bei null liegen.
Einheitlicher Modellaufruf für Grok 4.3 und Claude Opus 4.7
# Dasselbe base_url + API-Schlüssel, einfach das Feld 'model' für den jeweiligen Aufruf anpassen
from openai import OpenAI
client = OpenAI(
api_key="Dein APIYI API-Schlüssel",
base_url="https://vip.apiyi.com/v1"
)
# Grok 4.3 aufrufen (hohe Kosteneffizienz)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Generiere Unit-Tests für diese Funktion"}]
)
# Claude Opus 4.7 aufrufen (hohe Präzision)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refaktoriere die Zirkelbezüge in diesen 5 Dateien"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Vollständiger Code für intelligentes Routing bei Programmieraufgaben
Vollständigen Python-Code für aufgabenbasiertes automatisches Routing anzeigen
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Dein APIYI API-Schlüssel",
base_url="https://vip.apiyi.com/v1"
)
# Klassifizierungsregeln für Programmieraufgaben
SIMPLE_KEYWORDS = ["注释", "comment", "docstring", "rename", "format"]
TEST_KEYWORDS = ["单测", "unit test", "测试用例", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "重构", "跨文件", "循环依赖", "迁移"]
CRITICAL_KEYWORDS = ["关键 bug", "critical", "production fix", "合规"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Klassifiziert Aufgaben basierend auf Schlüsselwörtern im Prompt"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Wählt das Modell basierend auf dem Aufgabentyp aus"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Intelligenter Modellaufruf für Programmieraufgaben"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Vereinfachte Schätzung
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "Du bist ein erfahrener Full-Stack-Entwickler"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Füge dieser add-Funktion einen Docstring hinzu"))
print(smart_code_call("Schreibe 5 Pytest-Unit-Tests für mich"))
print(smart_code_call("Refaktoriere die Zirkelbezüge in diesen drei Dateien"))
print(smart_code_call("Kritischer Bug in Produktion, sofort beheben"))
Hinweise zum Aufruf von Grok 4.3 und Claude Opus 4.7
| Hinweis | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Modellfeld | grok-4.3 |
claude-opus-4-7 |
| Reasoning-Konfiguration | Standardmäßig aktiviert | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | Automatisch (75 % Rabatt) | Explizite Deklaration von cache_control (90 % Rabatt) |
| Batch API | 50 % Rabatt | 50 % Rabatt |
| Maximale Ausgabe | Standard | 128K (max_tokens muss explizit definiert werden) |
| Video-Eingabe | Feld video_url |
❌ Nicht unterstützt |
| Dokumentenausgabe | extra_body={"output_format": ...} |
❌ Erfordert Nachbearbeitung |
| Web-Suche (Server-seitig) | tools=[{"type": "web_search"}] |
❌ Erfordert Drittanbieter |
| Function Calling | ✅ Vollständig | ✅ Vollständig |
🎯 Integrations-Tipp: Wir empfehlen, zunächst einen Testschlüssel bei APIYI (apiyi.com) anzufordern, um den kleinstmöglichen Kreislauf zu testen. Grok 4.3 und Claude Opus 4.7 teilen sich denselben API-Schlüssel. Führen Sie A/B-Tests mit jeweils 100 realen Geschäftsbeispielen durch, bevor Sie eine endgültige Entscheidung treffen.
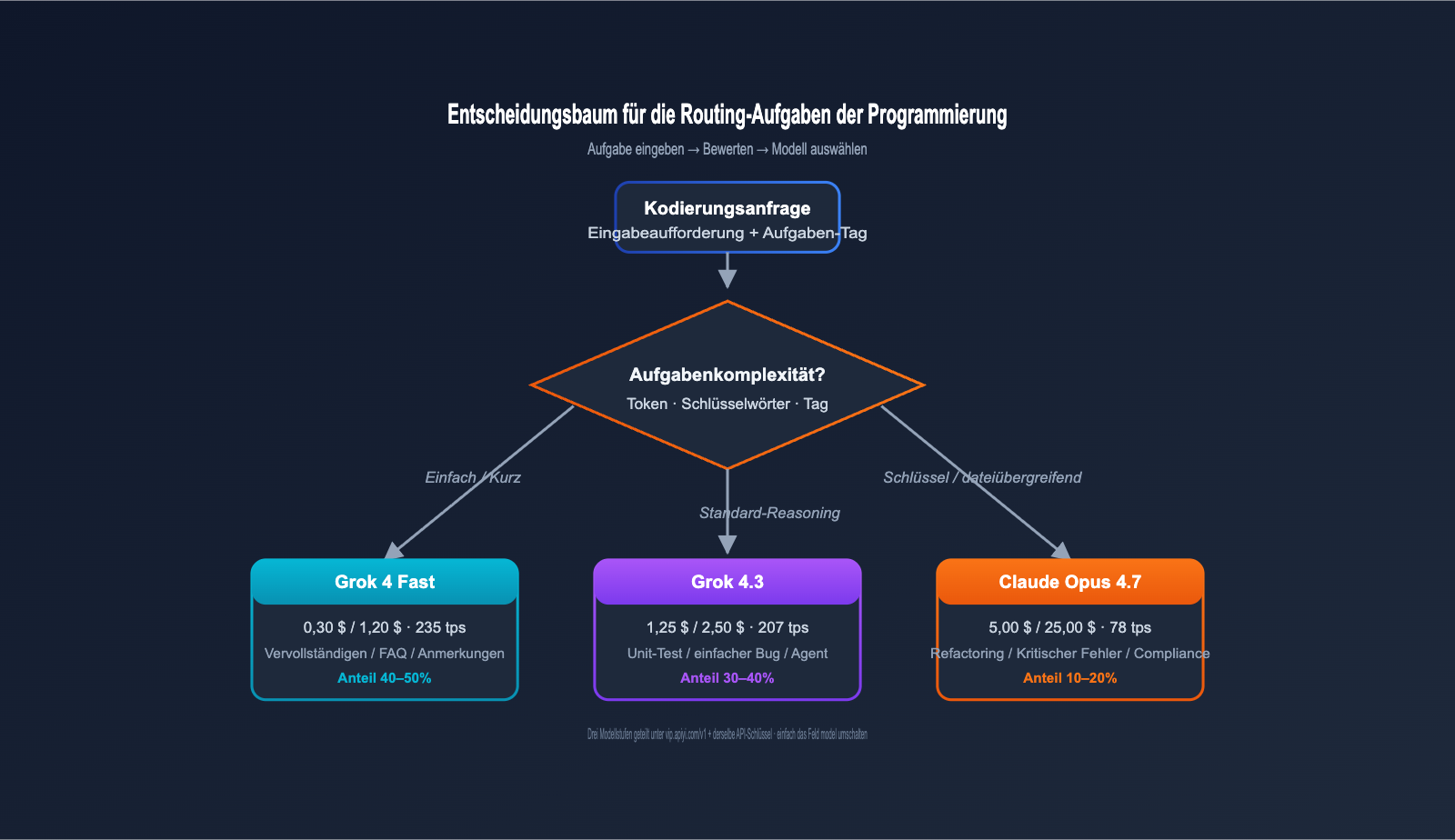
Grok 4.3 vs. Claude Opus 4.7: Empfehlungen für Programmierszenarien
6 Szenarien, in denen Grok 4.3 die erste Wahl ist
Wenn Ihr Unternehmen eines der folgenden Kriterien erfüllt, ist Grok 4.3 die bessere Lösung:
- Szenario 1: Einzelentwickler / Unabhängige Projekte: Bei einem Monatsbudget von < 300 $ lässt Grok 4.3 Ihre Token 10-mal weiter reichen.
- Szenario 2: Hochfrequente einfache Programmierung: IDE-Vervollständigung, Generierung von Unit-Tests, Schreiben von Kommentaren, Code-Formatierung.
- Szenario 3: Langkettige Agenten: Automatisierte Wartung (DevOps), PR-Review-Agenten, Compliance-Scan-Bots.
- Szenario 4: Videogestützte Entwicklung: Bug-Reproduktionsvideo → Reparaturvorschlag, UI-Animation → Frontend-Code.
- Szenario 5: Coding-Agent + Websuche: Serverseitige Integration von
web_searchundcode_execution-Tools. - Szenario 6: Echtzeit-Dialoge: 207 tps (Tokens pro Sekunde) Ausgabe, ideal für Pair Programming und Streaming-Vervollständigung.
6 Szenarien, in denen Claude Opus 4.7 die erste Wahl ist
Wenn Ihr Unternehmen eines der folgenden Kriterien erfüllt, rechtfertigt die höhere Präzision von Claude Opus 4.7 den Aufpreis:
- Szenario 1: Großflächiges Code-Refactoring: SWE-bench Pro 64,3 %, der höchste Wert in der Branche.
- Szenario 2: Kritische Bug-Fixes: Wenn ein Fehler teure Nacharbeit bedeutet, ist Präzision wichtiger als Kosten.
- Szenario 3: Analyse über mehrere Dateien / große Repositories: Bedarf an langem Kontext kombiniert mit hoher Präzision.
- Szenario 4: Compliance / sicherheitskritischer Code: Rechtliche, medizinische oder finanzielle Bereiche.
- Szenario 5: Komplexe Systemarchitektur: Architektonische Schlussfolgerungen, API-Design.
- Szenario 6: Bestehender Claude-Code-Workflow: Das Team ist bereits mit der Claude Code CLI vertraut; die Migrationskosten übersteigen die Preisdifferenz.
Empfohlene Mischarchitektur
Für Entwicklungsteams mittlerer bis großer Größe empfehlen wir die folgende Mischkonfiguration:
| Aufgabentyp | Routing-Modell | Empfohlener Anteil |
|---|---|---|
| Einfache Vervollständigung / FAQ | Grok 4 Fast | 40–50 % |
| Standard-Programmierung | Grok 4.3 | 30–40 % |
| Komplexes Refactoring / kritische Bugs | Claude Opus 4.7 | 10–20 % |
| Extrem komplexe Aufgaben (xhigh) | Claude Opus 4.7 + Thinking | < 5 % |
Diese Schichtung senkt die gesamten Kosten für KI-Programmierung auf 15–25 % im Vergleich zu einer reinen „Claude Opus 4.7“-Nutzung, während die Qualität bei kritischen Aufgaben nahezu unverändert bleibt.
Kostenvergleich einer echten Entwickler-Mischarchitektur
Die folgende Tabelle zeigt den Kostenvergleich eines 30-köpfigen Frontend/Backend-Teams im Mai 2026 vor und nach der Architekturumstellung. Das Szenario umfasst „IDE-Coding-Assistent + PR-Review-Agent + automatisierte Testgenerierung“.
| Dimension | Nur Claude Opus 4.7 | Mischarchitektur (Grok 4.3 Haupt + Claude kritisch) |
|---|---|---|
| Monatliches Volumen | 1,2 Mrd. Token | 1,2 Mrd. Token |
| Anteil Claude Opus 4.7 | 100 % | 12 % |
| Anteil Grok 4.3 | 0 % | 70 % |
| Anteil Grok 4 Fast | 0 % | 18 % |
| Monatliche Rechnung (inkl. 35 % Tokenizer-Anstieg) | ~23.000 $ | ~3.800 $ |
| Kosteneinsparung | — | 83 % |
| Qualität kritischer Aufgaben (SWE-bench Pro) | 100 % Basislinie | ~99 % (weiterhin über Claude) |
| Erfahrung bei einfachen Aufgaben | Mittel (78 tps) | Exzellent (207 tps) |
| Arbeitsaufwand für Umstellung | — | 16 Personenstunden |
Die Mischarchitektur senkt die Kosten auf 17 % des ursprünglichen Niveaus, bei nahezu gleichbleibender Qualität kritischer Aufgaben und einer 2,6-fachen Beschleunigung bei einfachen Aufgaben (durch Grok 4.3). Dies ist derzeit das lohnendste Architektur-Upgrade für Entwicklerteams ab mittlerer Größe.
💡 Implementierungshinweis: Wir empfehlen, die Aufgabenschwierigkeit direkt im IDE-Plugin zu bewerten. Einfache Vervollständigungen werden automatisch an Grok 4.3 geleitet, komplexe Aufgaben über mehrere Dateien an Claude Opus 4.7. Auf der Plattform APIYI (apiyi.com) nutzen beide Modelle dieselbe Authentifizierung und Kontingentverwaltung, was den Implementierungsaufwand kontrollierbar hält.
Häufig gestellte Fragen zu Grok 4.3 vs. Claude Opus 4.7
Q1: Kann Grok 4.3 Claude Opus 4.7 bei der Programmierung wirklich ersetzen?
Teilweise ja, teilweise nein. Bei Aufgaben wie „funktionsbasierte Generierung, Unit-Tests, Kommentare, einfache Bug-Fixes und langkettige Agenten“ liegt die Präzision von Grok 4.3 weniger als 5 Prozentpunkte hinter Claude Opus 4.7, kostet aber nur ein Zehntel – ein vollwertiger Ersatz. Bei „Refactoring über mehrere Dateien, komplexe Repository-Bugs, kritische Funktionsreparaturen und Compliance-Code“ bleibt Claude Opus 4.7 mit 64,3 % bei SWE-bench Pro das Maß aller Dinge (Abstand > 14 Prozentpunkte). Der sicherste Weg ist die Mischarchitektur über APIYI (apiyi.com).
Q2: Was sind die differenzierten Vorteile von Grok 4.3 beim Programmieren?
Sechs Vorteile: (1) 10-mal günstiger; (2) 2,6-mal schnellere Ausgabe (207 vs. 78 tps); (3) native Videoeingabe; (4) Dokumentengenerierung (PDF/XLSX/PPTX) in einem Schritt; (5) übertrifft Claude bei langkettigen Agenten (Vending-Bench); (6) integrierte serverseitige Tools (Websuche/Code-Ausführung), was den Engineering-Aufwand um 60 % reduziert.
Q3: Spiegelt sich der Wert von 87,6 % von Claude Opus 4.7 auf SWE-bench Verified in meinem Projekt wider?
Teilweise. SWE-bench Verified misst die Reparatur von Bugs in echten Open-Source-Repositories. Das spiegelt die Stärke von Claude Opus 4.7 bei langem Kontext und Code-Verständnis wider. Viele tägliche Aufgaben (Tests, Kommentare, Vervollständigung) sind dort nicht abgedeckt – hier liegen Grok 4.3 und Claude Opus 4.7 fast gleichauf. Betrachten Sie den Unterschied als „Qualitätslücke bei komplexen Aufgaben“, nicht als generelle Lücke.
Q4: Führt der neue Tokenizer von Claude Opus 4.7 wirklich zu 35 % höheren Kosten?
Ja, aber es gibt Lösungen. Der neue Tokenizer erzeugt bei gemischtem Code 30–40 % mehr Token. Gegenmaßnahmen: (1) Prompt Caching aktivieren (spart 90 %); (2) Batch API nutzen (spart weitere 50 %); (3) einfache Aufgaben an Grok 4.3 routen. Über APIYI (apiyi.com) können Sie Caching und Batching konfigurieren und den Traffic automatisch verteilen.
Q5: Welches Modell für Aufgaben mit langem Kontext (> 200k Token)?
Wählen Sie nach Präzisionsbedarf. Claude Opus 4.7 führt bei der Präzision im langen Kontext. Grok 4.3 ist exzellent bei Zusammenfassungen und kostet nur ein Zehntel. Wenn Sie „3 spezifische Bugs in 800k Token finden“ müssen, wählen Sie Claude. Wenn Sie „800k Token zusammenfassen und Kernfragen klären“ wollen, reicht Grok 4.3.
Q6: Welches Modell für IDE-Tools wie Cursor / Cline / Continue?
Die Mischstrategie ist optimal. Für „IDE-Inline-Vervollständigung + einfaches Refactoring“ bietet Grok 4.3 durch Geschwindigkeit und Preis ein besseres Erlebnis. Bei „Refactor across files“ oder „Fix complex bug“ ist der automatische Wechsel zu Claude Opus 4.7 über APIYI (apiyi.com) die stabilste Wahl.
Q7: Ist die Abrechnung für beide Modelle auf APIYI gleich?
Ja, beide werden nach Token-Verbrauch abgerechnet. Grok 4.3 wird 1:1 zu den xAI-Preisen durchgereicht, Claude Opus 4.7 zu den Anthropic-Preisen. Prompt Caching und Batch API werden voll unterstützt. Alles läuft über einen API-Schlüssel und ein Guthaben.
Q8: Wie viel Code muss ich ändern, um auf eine Mischarchitektur umzusteigen?
Sehr wenig, meist nur Konfiguration. Wenn Sie bereits das OpenAI SDK über APIYI nutzen, benötigen Sie nur: (1) eine Klassifizierungsfunktion für Aufgaben (ca. 20 Zeilen); (2) das Umschalten des model-Feldes zwischen claude-opus-4-7 und grok-4.3; (3) ein Rollout mit 5–10 % Traffic.
Q9: Kann ich Tools wie Claude Code CLI mit Grok 4.3 nutzen?
Nicht direkt, aber es gibt Äquivalente. Für eine ähnliche Erfahrung nutzen Sie: (1) Aider (Open-Source-CLI, unterstützt OpenAI-kompatible APIs); (2) Continue.dev (IDE-Plugin); (3) eine eigene CLI über das OpenAI SDK.
Q10: Wer ist bei Agentic Coding stabiler?
Es kommt auf das Szenario an. Für „kurzkettige, präzise Coding-Agenten“ (SWE-bench) ist Claude Opus 4.7 überlegen. Bei „langkettigen Agenten“ (Vending-Bench, langfristige Entscheidungsfindung) übertrifft Grok 4.3 Claude Opus 4.7 um das 1,5- bis 2-fache.
Q11: Wie binde ich Grok 4.3 in Cursor ein?
Cursor unterstützt benutzerdefinierte OpenAI-kompatible Endpunkte: (1) Cursor-Einstellungen → Models → Custom API Endpoint; (2) base_url auf https://vip.apiyi.com/v1 setzen, API-Schlüssel von APIYI eintragen; (3) Modellname grok-4.3. Danach können Sie im Chat jederzeit zwischen den Modellen wechseln.
Fazit: Kann Grok 4.3 Claude Opus 4.7 ersetzen?
Kommen wir zur Kernfrage unseres Vergleichs: Kann Grok 4.3 im Bereich Programmierung als vollwertiger Ersatz für Claude Opus 4.7 dienen?
Die kurze Antwort lautet: Es kann 60–70 % der täglichen Programmieraufgaben abdecken. Für die verbleibenden 30–40 % komplexer Aufgaben empfehlen wir, bei Claude Opus 4.7 zu bleiben.
Im Detail: Bei Aufgaben wie der funktionsbasierten Generierung, dem Erstellen von Unit-Tests, der Kommentierung, einfachen Fehlerbehebungen sowie bei langkettigen Agents ist der Genauigkeitsunterschied von Grok 4.3 zu Claude Opus 4.7 geringer als 5 Prozentpunkte. Da Grok 4.3 jedoch nur einen Bruchteil des Preises kostet (1/10), ist ein Ersatz hier problemlos möglich. Bei komplexeren Szenarien wie dateiübergreifendem Refactoring, Fehlersuche in umfangreichen Repositories oder der Arbeit an kritischem, regelkonformem Code ist Claude Opus 4.7 mit seinem SWE-bench Pro Score von 64,3 % branchenweit führend – hier liegt der Leistungsabstand bei über 14 Prozentpunkten, weshalb ein Ersatz nicht empfohlen wird.
Noch wichtiger ist jedoch: Grok 4.3 ist nicht einfach nur eine „günstige Version von Claude Opus 4.7“. Es bietet sechs entscheidende Alleinstellungsmerkmale, die Claude völlig fehlen: 1/10 des Preises, 2,6-fache Geschwindigkeit, Video-Input, Dokumentenerstellung, überlegene Leistung bei langkettigen Agents sowie integrierte serverseitige Tools. In Bereichen wie der videobasierten Entwicklung, automatisierten Wartungs-Agents oder vernetzten Coding-Agents ist Grok 4.3 zwar kein „perfekter Ersatz für Claude Opus 4.7“, aber definitiv der optimale Ausgangspunkt für neue Produktformen.
Für Entwickler im deutschsprachigen Raum ist der API-Proxy-Dienst APIYI (apiyi.com) der reibungsärmste Weg, um diese hybride Architektur aus „Grok 4.3 als Hauptmodell + Claude Opus 4.7 für kritische Pfade“ umzusetzen. Beide Modelle teilen sich denselben base_url und API-Schlüssel; in der Anwendung muss lediglich das Feld model gewechselt werden. Die Preise für Grok 4.3 werden 1:1 von der xAI-Website übernommen, ebenso wie die Preise von Claude Opus 4.7 direkt von Anthropic – ohne Aufschläge. Durch die zusätzliche Nutzung des nativen Prompt Caching von Anthropic (90 % Ersparnis) und der Batch API (weitere 50 % Ersparnis) lassen sich die gesamten Kosten für Coding-KI auf 15–25 % im Vergleich zur alleinigen Nutzung von Claude Opus 4.7 senken, ohne dass die Qualität bei kritischen Aufgaben nennenswert leidet.
Abschließend ein praktischer Rat für die nächsten 24 Stunden: Beantragen Sie noch heute einen Schlüssel bei APIYI und lassen Sie 100 Ihrer realen Programmieraufgaben von beiden Modellen bearbeiten. Die Benchmarks sind ein guter Anhaltspunkt, aber die Erfolgsquote bei Ihren eigenen Projekten ist das einzige, was zählt.
Referenzen
-
Offizielle Ankündigung von Anthropic: Details zur Veröffentlichung von Claude Opus 4.7
- Link:
anthropic.com/claude/opus - Hinweis: Enthält Preisgestaltung, Benchmarks und Erklärungen zu API-Feldern.
- Link:
-
Anthropic API-Dokumentation: Spezifikationen von Claude Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Hinweis: Informationen zu Kontextfenstern, Ausgabebeschränkungen und Tokenizer-Änderungen.
- Link:
-
xAI Modell-Dokumentation: Alle API-Spezifikationen für Grok 4.3
- Link:
docs.x.ai/developers/models - Hinweis: Dokumentation zu Video-Input, Dokumentenerstellung und serverseitigen Tools.
- Link:
-
Vellum Benchmark-Bericht: Detaillierte Bewertung von Claude Opus 4.7
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Hinweis: Daten zu SWE-bench Verified / Pro / CursorBench.
- Link:
-
Artificial Analysis Leaderboard: Umfassender Vergleich von Modellleistung und Preis
- Link:
artificialanalysis.ai/models/claude-opus-4-7 - Hinweis: Ganzheitliche Bewertung von Intelligenz, Geschwindigkeit und Kosten.
- Link:
-
DocsBot Modellvergleich: Detaillierter Vergleich zwischen Grok 4.3 und Claude Opus 4.7
- Link:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Hinweis: Direkte Gegenüberstellung von Preis, Leistung und Funktionen.
- Link:
-
APIYI Integrationsdokumentation: Anleitung zur Einbindung beider Modelle über den API-Proxy-Dienst
- Link:
help.apiyi.com - Hinweis: Beinhaltet Informationen zu Modellfeldern, SDK-Beispielen und Kostenabfragen.
- Link:
Autor: APIYI Team — Spezialisiert auf API-Proxy-Dienste für große Sprachmodelle. Wir unterstützen Entwickler dabei, Grok 4.3, Claude Opus 4.7, GPT-5.5 und andere führende Modelle mit einem Klick zu integrieren. Besuchen Sie APIYI unter apiyi.com, um kostenloses Testguthaben zu erhalten.