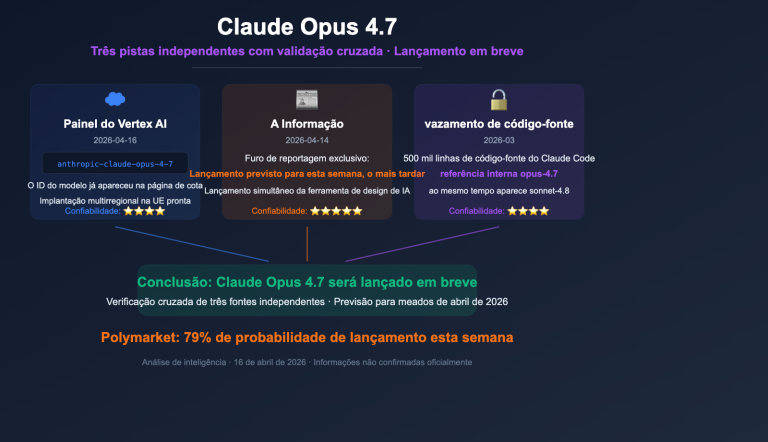
O Claude Opus 4.7 foi lançado oficialmente em 16 de abril de 2026 e, logo no dia seguinte, a comunidade já estava dividida. Enquanto os benchmarks oficiais afirmam que ele supera a versão 4.6 em 12 dos 14 testes, muitos desenvolvedores no GitHub e no X reclamam que o desempenho está inferior ao da 4.6, com alguns chegando a chamá-lo de "um 4.6 pré-ajustado disfarçado de nova versão".
Este artigo baseia-se em dados oficiais da Anthropic, testes independentes de terceiros e feedback direto da comunidade para avaliar o Claude Opus 4.7 em 8 dimensões, incluindo capacidade de codificação, reconhecimento visual, janela de contexto, mudanças no Tokenizer e Task Budgets, ajudando você a decidir se vale a pena migrar imediatamente.
Valor central: Ao final deste artigo, você saberá se o Claude Opus 4.7 representa uma atualização ou um retrocesso para o seu cenário de negócios, além de como evitar riscos na migração.

Contexto de lançamento e informações principais do Claude Opus 4.7
O Claude Opus 4.7 é o modelo carro-chefe lançado pela Anthropic em 16 de abril de 2026, mantendo o preço de $5/$25 por milhão de tokens do Opus 4.6 e estabelecendo novos recordes em vários benchmarks. No entanto, ele traz consigo mudanças sistêmicas, como a reestruturação do Tokenizer, uma queda acentuada no benchmark de contexto longo MRCR e o novo nível de inferência xhigh, mudanças que impactam diretamente o desempenho em cenários reais de negócios.
Resumo do lançamento do Claude Opus 4.7
| Item de informação | Detalhes |
|---|---|
| Data de lançamento | 16 de abril de 2026 |
| Desenvolvedor | Anthropic |
| Preço de entrada | $5 / milhão de tokens (igual ao 4.6) |
| Preço de saída | $25 / milhão de tokens (igual ao 4.6) |
| Janela de contexto | 1M de tokens (preço padrão) |
| Resolução máxima de imagem | 2576px no lado maior / 3,75 megapixels |
| Novo nível de inferência | xhigh (entre high e max) |
| Novo recurso experimental | Task Budgets (em teste beta) |
| Canais disponíveis | Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry |
🎯 Dica técnica: Antes de migrar oficialmente para o Claude Opus 4.7, recomendamos usar a plataforma APIYI (apiyi.com) para realizar testes comparativos paralelos entre o 4.6 e o 4.7. A plataforma oferece uma interface unificada onde a troca de modelos exige apenas a alteração de parâmetros, permitindo identificar rapidamente as diferenças de desempenho.
Principais melhorias do Claude Opus 4.7
As melhorias anunciadas oficialmente pela Anthropic concentram-se principalmente em quatro áreas:
- Capacidade de engenharia de software significativamente aprimorada: O SWE-bench Verified subiu de 80,8% para 87,6%, e o SWE-bench Pro saltou de 53,4% para 64,3%.
- Salto na capacidade de compreensão visual: Suporte para imagens de alta resolução de 3,75 megapixels, com o benchmark visual subindo de 54,5% para 98,5%.
- Fortalecimento do uso de ferramentas Agentic: O benchmark MCP-Atlas obteve o maior ganho individual, com um aumento de 13 pontos em condições sem ferramentas.
- Seguimento de comandos mais preciso: Processamento mais robusto de comandos ambíguos e execução mais completa.
No entanto, o feedback real da comunidade conta uma história diferente.
Detalhes das principais funcionalidades do Claude Opus 4.7
As mudanças fundamentais no Claude Opus 4.7 não se refletem apenas na capacidade do modelo, mas também em ajustes importantes no nível de entrega. Compreender essas mudanças é crucial para avaliar corretamente o desempenho do modelo.
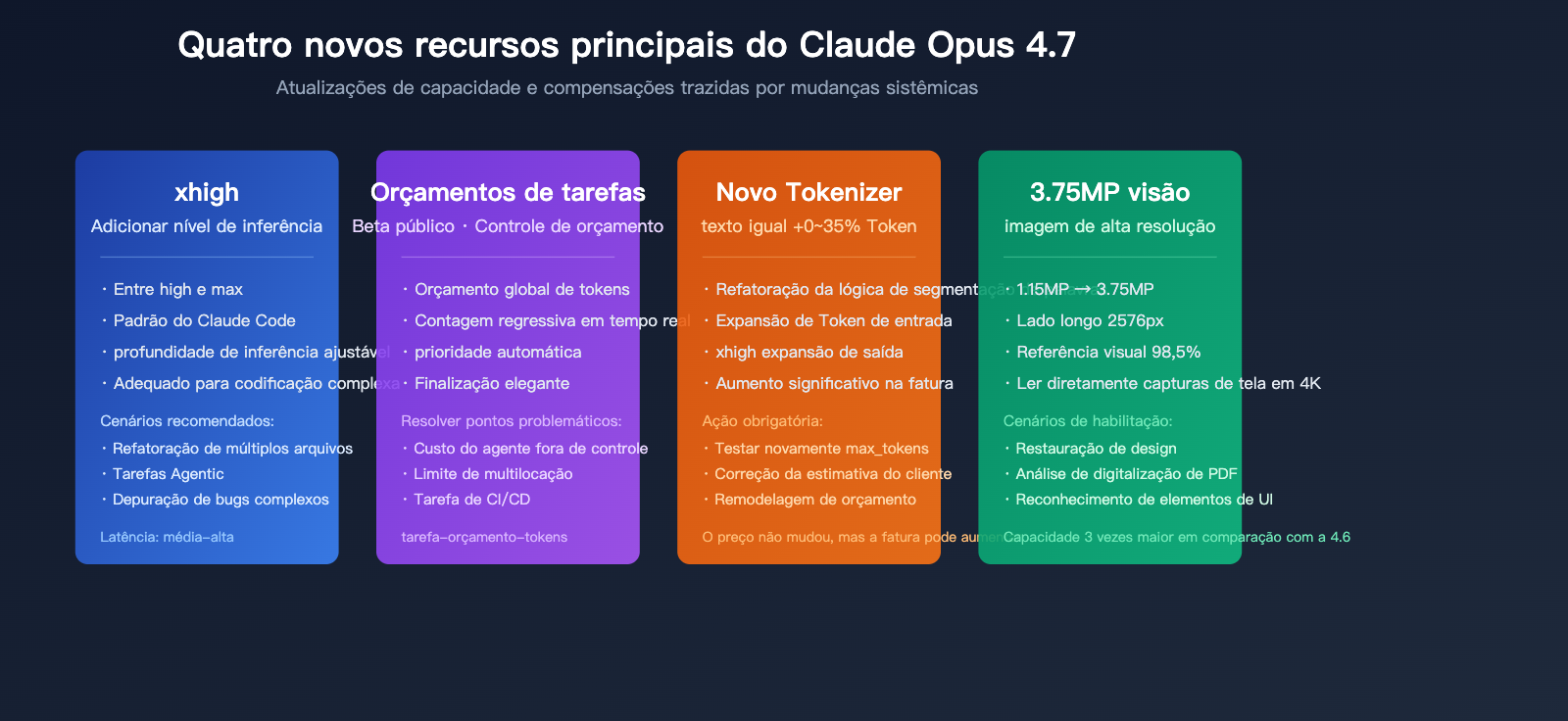
As quatro mudanças sistêmicas do Claude Opus 4.7
| Módulo de função | Desempenho 4.6 | Mudança 4.7 | Impacto no negócio |
|---|---|---|---|
| Tokenizer | Tokenização original | Produz 1,0–1,35× mais Tokens | A fatura real pode subir 35% |
| Níveis de inferência | low / medium / high / max | Adicionado xhigh (padrão do Claude Code) | Profundidade e latência mais refinadas |
| Orçamentos de tarefa | N/A | Beta público, controle de orçamento de Token | Custo de loop do Agente controlável |
| Entrada visual | ~ 1,15 MP | ~ 3,75 MP (3×) | Pode processar prints e desenhos em alta resolução |
| MRCR de longa janela de contexto | 78,3% | 32,2% | Queda significativa na recuperação de documentos longos |
| SWE-bench Verified | 80,8% | 87,6% | Melhora drástica em tarefas de código reais |
Custos implícitos da mudança no Tokenizer
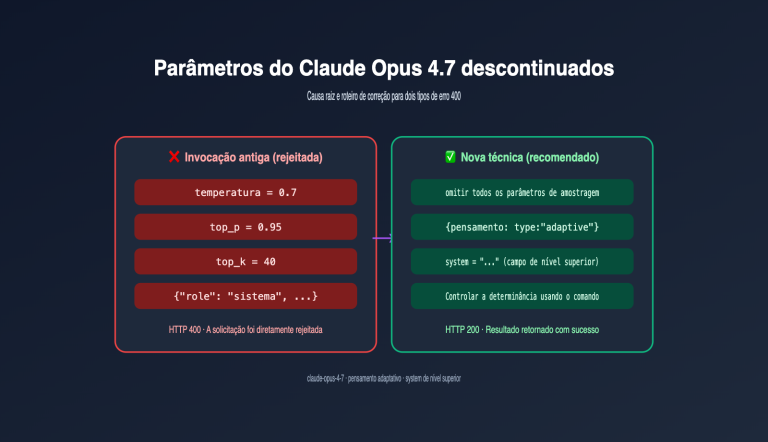
A mudança mais importante, porém frequentemente ignorada, no Claude Opus 4.7 é a reestruturação do Tokenizer. A documentação oficial afirma claramente: o mesmo texto de entrada é mapeado para 1,0 a 1,35 vezes a quantidade de Tokens do 4.6 no modelo 4.7. Isso significa que:
- O comprimento do seu comando não mudou, mas a cobrança de Tokens de entrada pode ser 35% maior.
- Nos níveis de inferência xhigh ou max, os Tokens de saída também podem aumentar significativamente.
- Os limites de
max_tokensdefinidos anteriormente para o 4.6 precisam de testes completos. - A lógica do lado do cliente para estimar Tokens com base na contagem de caracteres precisa ser reescrita.
💰 Otimização de custos: Para ambientes de produção sensíveis aos custos de Tokens, antes de migrar para o Claude Opus 4.7, recomendamos fortemente realizar uma rodada de comparação de faturas com tráfego real na plataforma APIYI (apiyi.com). A plataforma oferece suporte a consultas flexíveis de faturamento e monitoramento em tempo real, facilitando a quantificação do aumento de custo real trazido pela migração.
Estratégia de uso do nível de inferência xhigh
O xhigh é um nível de inferência introduzido no Opus 4.7, posicionado entre o high e o max. A Anthropic recomenda o uso do xhigh como padrão em tarefas de codificação e tarefas de Agente; este é também o nível padrão para todos os planos do Claude Code.
Cenários de aplicação para diferentes níveis de inferência:
| Nível de inferência | Tarefas aplicáveis | Latência | Cenários de uso recomendados |
|---|---|---|---|
low |
Perguntas simples, conversão de formato | Mínima | Tarefas de baixa complexidade e alta simultaneidade |
medium |
Geração comum de código | Baixa | Auxílio ao desenvolvimento convencional |
high |
Código complexo, design técnico | Média | Tarefas de Agente convencionais |
xhigh |
Depuração difícil, refatoração em larga escala | Média-alta | Recomendado: cenários de codificação como Claude Code |
max |
Inferência extremamente complexa | Alta | Pesquisa e tarefas não sensíveis ao tempo |
Orçamentos de tarefa (Task Budgets): O fim dos custos descontrolados de loops de Agentes
O Task Budgets é um recurso em versão beta pública introduzido no Opus 4.7, que resolve o problema antigo do controle de consumo total de Tokens em loops de Agentes. Como funciona:
- O desenvolvedor define um orçamento total de Tokens antes de iniciar o loop do Agente.
- O modelo consegue ver a contagem regressiva do orçamento em cada resposta.
- O modelo ajusta automaticamente a profundidade de pensamento e o número de chamadas de ferramentas de acordo com o saldo do orçamento.
- Antes que o orçamento acabe, o modelo prioriza a conclusão da tarefa principal e finaliza o processo de forma elegante.
Este recurso, combinado com a nova interface redact-thinking-2026-02-12, representa uma melhoria substancial na gestão de custos de Agentes.
Panorama de Dados de Testes Reais do Claude Opus 4.7
Esta seção é o núcleo deste artigo. Reunimos benchmarks oficiais da Anthropic, avaliações independentes de terceiros e dados de retestes da comunidade para apresentar a diferença real entre o Claude Opus 4.7 e o 4.6.
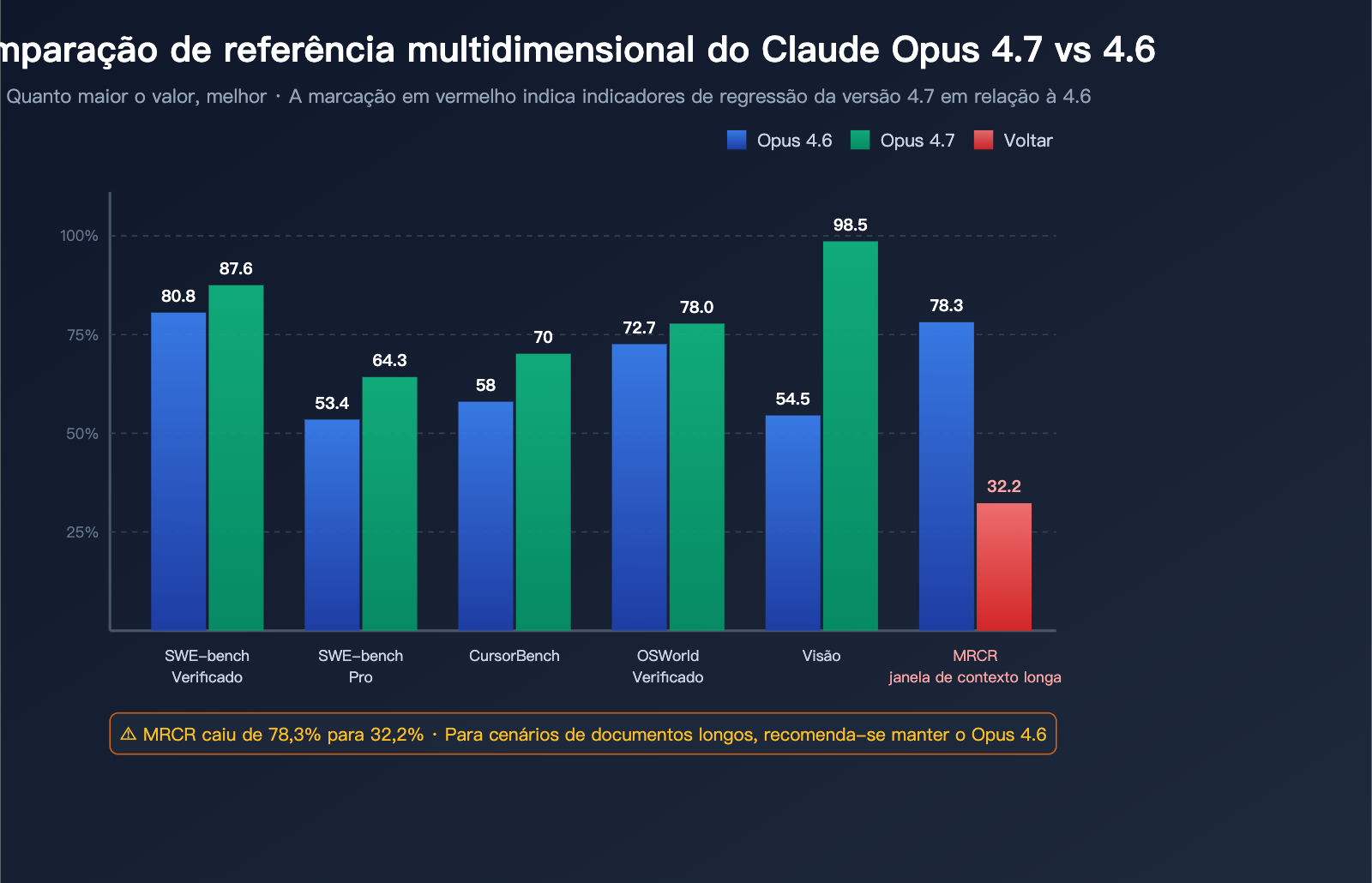
Benchmarks de Capacidade de Codificação: 4.7 na Liderança
| Benchmark de Código | Opus 4.6 | Opus 4.7 | Melhora | Notas |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pt | Tarefas reais de correção de Issues no GitHub |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pt | Variante mais difícil com múltiplos idiomas |
| CursorBench | 58% | 70% | +12pt | Tarefas de codificação reais dentro do IDE |
| OSWorld-Verified | 72.7% | 78.0% | +5.3pt | Operações de desktop e uso de computador |
| MCP-Atlas (sem ferramentas) | — | +13pt | Maior melhora individual | Tarefas com cadeia de ferramentas Agentic |
| MCP-Atlas (com ferramentas) | — | +6pt | Melhora notável | Precisão de invocação de modelo |
Na área de codificação, o Claude Opus 4.7 é, sem dúvida, o modelo público mais forte do segundo trimestre de 2026. A pontuação de 64,3% no SWE-bench Pro permitiu que ele recuperasse o topo do ranking de codificação Agentic.
🚀 Comece rápido: Se você deseja experimentar imediatamente a capacidade de codificação do Claude Opus 4.7, pode usar a plataforma APIYI (apiyi.com), que oferece uma interface totalmente compatível com a API oficial do Claude, suporta o formato padrão do SDK da OpenAI e possui um custo de migração baixíssimo.
Benchmarks de Visão e Contexto Longo: Polarização
| Benchmark | Opus 4.6 | Opus 4.7 | Mudança | Avaliação |
|---|---|---|---|---|
| Reconhecimento visual (geral) | 54.5% | 98.5% | +44pt | Próximo a uma mudança qualitativa |
| Resolução máxima de imagem | ~1.15 MP | ~3.75 MP | 3× | Suporta prints 4K |
| Recuperação de contexto longo MRCR | 78.3% | 32.2% | -46.1pt | Regressão grave |
O MRCR (Multi-Round Context Recall) é o padrão para avaliar a capacidade de recuperação de contexto longo. O Opus 4.7 teve uma queda drástica de 78,3% para 32,2% neste indicador; não se trata de uma oscilação comum, mas de uma regressão estrutural.
Esse número explica por que muitos desenvolvedores reclamam que "o modelo diz ter lido o documento de fluxo de trabalho de 800 linhas, mas a resposta não tem nada a ver com o conteúdo".
Benchmarks vs. Experiência Real: Por que a avaliação é tão polarizada?
Ter bons resultados em benchmarks não garante um desempenho superior em cenários de uso reais. O Opus 4.7 gerou muitos feedbacks negativos na comunidade por motivos como:
- Inflação de Tokenizer: O consumo de tokens aumentou para a mesma tarefa, mas a melhora na capacidade nem sempre compensa o custo.
- Seguimento de comandos muito literal: O 4.6 tinha o hábito de "entender a intenção", enquanto o 4.7 executa as instruções de forma estritamente literal, podendo invalidar comandos (prompts) antigos.
- Colapso do MRCR: A capacidade de recuperar informações de documentos longos caiu, tornando-se evidente ao lidar com grandes bases de código ou contratos.
- Falsos positivos no Claude Code: Alguns desenvolvedores relataram que o 4.7 classifica erroneamente códigos normais como maliciosos e se recusa a editá-los.
💡 Sugestão de escolha: A decisão entre usar o Claude Opus 4.7 ou continuar no 4.6 depende do seu cenário de negócio principal. Recomendamos realizar testes de estresse em paralelo com ambos os modelos através da plataforma APIYI (apiyi.com), que suporta a invocação via interface unificada, facilitando comparações e trocas rápidas.
Experiência real com o Claude Opus 4.7
Além dos dados de referência, a Anthropic e a comunidade de desenvolvedores forneceram feedbacks bastante distintos sobre o desempenho do Opus 4.7 em fluxos de trabalho reais.
Posicionamento oficial da Anthropic
Em seu anúncio de lançamento, a Anthropic destacou quatro melhorias principais do Opus 4.7 em relação à versão 4.6:
- Desempenho mais robusto em pipelines de engenharia: os usuários podem delegar com segurança tarefas complexas que antes exigiam supervisão rigorosa.
- Melhor capacidade de lidar com problemas ambíguos: maior estabilidade para requisitos mal definidos.
- Resolução de problemas mais completa: o modelo não desiste no meio do caminho.
- Seguimento de instruções mais preciso: maior rigor com detalhes.
Boris Cherny, responsável pelo Claude Code, afirmou publicamente após o lançamento que o Opus 4.7 é "mais inteligente, mais capaz de agir como um agente e mais preciso" que o 4.6, embora tenha admitido que são necessários alguns dias de adaptação para aproveitar ao máximo suas novas capacidades.
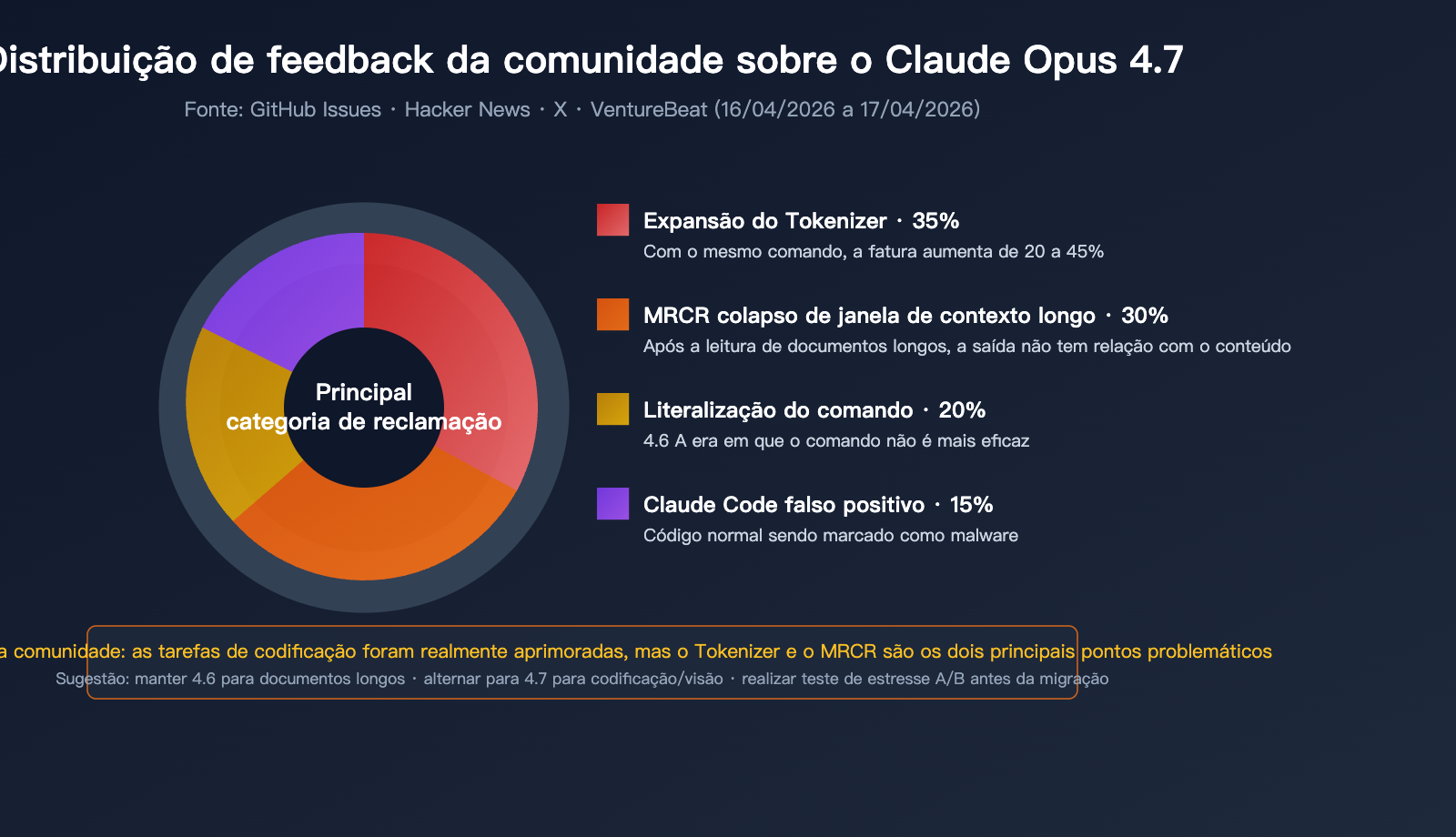
Feedback real da comunidade de desenvolvedores
Em plataformas como GitHub, Hacker News e X, o feedback dos desenvolvedores tem sido visivelmente negativo:
Reclamação 1: Consumo de tokens disparou
Devido ao novo tokenizador, a mesma entrada é decomposta em mais tokens no Opus 4.7. Somado ao aumento de tokens de saída no nível xhigh, alguns usuários relataram aumentos na fatura de até 40%. Isso foi apelidado de "AI Shrinkflation" (inflação por encolhimento da IA).
Reclamação 2: Desastre no processamento de documentos longos
Vários desenvolvedores relataram que, ao inserir documentos longos no Opus 4.7, o modelo afirma ter lido, mas o conteúdo gerado não tem relação substancial com o documento. Isso coincide com a queda do MRCR de 78,3% para 32,2%.
Reclamação 3: Claude Code classifica código normal como malicioso
No Issue #47483, vários engenheiros relataram que o Claude Opus 4.7 marca trechos de código de leitura/escrita de arquivos normais como malware, recusando-se a concluir solicitações básicas de edição.
Reclamação 4: Compatibilidade de comandos (prompts) reduzida
Comandos que funcionavam bem no 4.6 tiveram a qualidade de saída reduzida ao serem migrados para o 4.7. O motivo é que o 4.7 executa as instruções estritamente ao pé da letra, enquanto o 4.6 costumava "ler nas entrelinhas" automaticamente.
Pontuação por cenário do Claude Opus 4.7
Com base em dados de testes e feedback da comunidade, aqui está a pontuação do Opus 4.7 em diferentes cenários:
| Cenário de uso | Pontuação Opus 4.6 | Pontuação Opus 4.7 | Mudança | Recomendação |
|---|---|---|---|---|
| Refatoração de código (arquivos curtos/médios) | 8/10 | 9/10 | ↑ | Migrar agora |
| Fluxos de trabalho de agentes complexos | 7.5/10 | 9/10 | ↑ | Migrar agora |
| Revisão de código em grandes repositórios | 8/10 | 6.5/10 | ↓ | Continuar no 4.6 |
| Resumo e perguntas sobre documentos longos | 8.5/10 | 5/10 | ↓↓ | Continuar no 4.6 |
| Compreensão de imagens em alta definição | 6.5/10 | 9.5/10 | ↑↑ | Migrar agora |
| Conversação e escrita convencional | 9/10 | 9/10 | → | Qualquer um |
| Produção sensível a custos | 9/10 | 7/10 | ↓ | Continuar no 4.6 |
| Desenvolvimento de protótipos e experimentos | 8/10 | 8.5/10 | ↑ | Migrar |
Análise profunda das vantagens e desvantagens do Claude Opus 4.7
Após comparar dados e experiências, podemos resumir os pontos fortes e fracos.
As quatro principais vantagens do Claude Opus 4.7
Vantagem 1: Melhoria significativa na capacidade real de codificação
Os resultados de 87,6% no SWE-bench Verified e 64,3% no SWE-bench Pro não são apenas números, mas tarefas reais de correção de Issues no GitHub. Isso significa que o Opus 4.7 realmente pode substituir mais trabalho humano em tarefas de codificação de pequeno e médio porte.
Vantagem 2: Salto de qualidade na compreensão visual
A entrada de imagens em alta resolução (3,75 megapixels) permite que o Opus 4.7 processe diretamente capturas de tela em 4K, diagramas de design, PDFs digitalizados e outros conteúdos visuais densos. Este é um grande avanço para a série Claude.
Vantagem 3: Orçamentos de tarefas (Task Budgets) resolvem o controle de custos de agentes
Por muito tempo, o consumo descontrolado de tokens em loops de agentes foi o principal obstáculo para a adoção empresarial. Os orçamentos de tarefas oferecem aos desenvolvedores, pela primeira vez, uma capacidade de controle orçamentário global e refinado.
Vantagem 4: Nível xhigh oferece melhor equilíbrio entre raciocínio e latência
Ter uma opção extra entre "high" e "max" significa que os desenvolvedores podem ajustar a performance de forma flexível de acordo com os requisitos de SLA no mesmo cenário.
As quatro principais limitações do Claude Opus 4.7
Limitação 1: Inflação do tokenizador aumenta o custo real
Mesmo com o preço unitário inalterado, a inflação de 35% nos tokens, somada à expansão da saída no nível xhigh, pode tornar a fatura real de 20% a 45% mais cara que a do 4.6.
Solução: Teste novamente todos os caminhos de código usando a interface de contagem de tokens antes de migrar.
Limitação 2: Colapso na capacidade de recuperação de contexto longo (MRCR)
Este é o problema mais crítico. Ao processar documentos longos, grandes bases de código ou conversas extensas, a precisão de recuperação do Opus 4.7 cai drasticamente.
Solução: Continue usando o Opus 4.6 para cenários de documentos longos ou utilize estratégias de RAG + segmentação.
Limitação 3: Seguimento de instruções excessivamente literal
Prompts originais podem apresentar mudanças de saída inesperadas.
Solução: Reescreva os prompts de forma sistemática, removendo intenções implícitas e utilizando restrições explícitas.
Limitação 4: Aumento de julgamentos errôneos e alucinações em alguns cenários
Problemas como o Claude Code classificando código erroneamente e alucinações em documentos longos foram amplamente relatados pela comunidade.
Solução: Combine tarefas críticas com revisão humana e use validação cruzada entre múltiplos modelos para lógicas essenciais.
🎯 Recomendação de migração: Se o seu negócio envolve tanto codificação de tarefas curtas quanto processamento de documentos longos, recomendamos rotear diferentes versões do Claude por cenário através da plataforma APIYI (apiyi.com). A plataforma suporta a invocação unificada de múltiplos modelos, permitindo combinar de forma flexível o Opus 4.6 (contexto longo) e o 4.7 (codificação/visual) no mesmo projeto, evitando a regressão de desempenho causada por uma migração "única para todos".
Prática de invocação da API do Claude Opus 4.7
Além da análise teórica, apresentamos exemplos de código prontos para execução para ajudar você a começar a usar o Claude Opus 4.7 rapidamente.
Exemplo Minimalista (Compatível com o SDK da OpenAI)
import openai
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[
{"role": "user", "content": "Por favor, escreva um exemplo de crawler concorrente em Python"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Ver código completo (incluindo nível de raciocínio xhigh, Task Budgets e tratamento de erros)
import openai
import time
from typing import Optional
class ClaudeOpusClient:
"""Encapsulamento completo para invocação do Claude Opus 4.7"""
def __init__(self, api_key: str, base_url: str = "https://api.apiyi.com/v1"):
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url
)
def generate(
self,
prompt: str,
model: str = "claude-opus-4-7",
effort: str = "xhigh",
task_budget: Optional[int] = None,
max_retries: int = 3
) -> str:
"""Invoca o Claude Opus 4.7 com suporte a novos recursos"""
extra_headers = {}
if task_budget:
extra_headers["task-budget-tokens"] = str(task_budget)
if effort:
extra_headers["reasoning-effort"] = effort
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=8192,
extra_headers=extra_headers,
timeout=120
)
return response.choices[0].message.content
except openai.RateLimitError:
wait = 2 ** attempt
print(f"Limite de taxa atingido, aguardando {wait}s...")
time.sleep(wait)
except openai.APIError as e:
print(f"Erro na API: {e}")
if attempt == max_retries - 1:
raise
time.sleep(1)
raise RuntimeError("Número máximo de tentativas excedido")
def compare_versions(self, prompt: str) -> dict:
"""Invoca as versões 4.6 e 4.7 simultaneamente para comparação"""
results = {}
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
start = time.time()
results[model] = {
"output": self.generate(prompt, model=model),
"latency": time.time() - start
}
return results
if __name__ == "__main__":
client = ClaudeOpusClient(api_key="SUA_CHAVE_API")
result = client.generate(
prompt="Refatore este código Python para suportar concorrência assíncrona",
effort="xhigh",
task_budget=50000
)
print(result)
🚀 Início Rápido: O
base_urlno código acima aponta para a plataforma APIYI (apiyi.com). Esta plataforma fornece um formato de interface totalmente compatível com o Claude oficial, suportando a invocação paralela do Claude Opus 4.7 e 4.6, o que facilita testes A/B durante o período de migração.
Checklist de Migração Crucial
Passos obrigatórios ao migrar do Opus 4.6 para o 4.7:
# 1. Teste novamente o limite de max_tokens (mudanças no Tokenizer)
from openai import OpenAI
client = OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
# Invoque os dois modelos para o mesmo Prompt principal e registre o consumo real de tokens
for model in ["claude-opus-4-6", "claude-opus-4-7"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": SEU_PROMPT}],
max_tokens=4096
)
print(f"{model}: entrada={resp.usage.prompt_tokens}, saída={resp.usage.completion_tokens}")
# 2. Teste novamente cenários de documentos longos (colapso de MRCR)
# Sugere-se manter tarefas de documentos longos no 4.6 ou usar particionamento RAG
# 3. Audite a intenção implícita dos Prompts
# O 4.7 segue comandos literalmente, sendo necessário trocar a "leitura de intenção" por restrições explícitas
FAQ de Perguntas Frequentes sobre o Claude Opus 4.7
Q1: O Claude Opus 4.7 é realmente melhor que o 4.6?
Depende do cenário:
- Tarefas de codificação de curta a média extensão: O 4.7 é claramente melhor (SWE-bench Verified +6.8pt, CursorBench +12pt).
- Tarefas visuais de alta definição: O 4.7 supera em muito o 4.6 (benchmark visual de 54,5% para 98,5%).
- Cadeia de ferramentas Agentic: O 4.7 é mais robusto (MCP-Atlas com aumento de 13pt).
- Recuperação de contexto longo: O 4.6 é visivelmente melhor (MRCR 78,3% vs 32,2%).
- Sensibilidade a custos: O 4.6 é superior (a expansão de tokens no 4.7 pode chegar a 35%).
Se você precisa invocar as duas versões em paralelo para diferentes cenários, recomendamos usar a plataforma APIYI (apiyi.com) para rotear as versões conforme a necessidade de negócio; ela suporta a invocação de toda a série Claude com uma única chave API.
Q2: Por que algumas pessoas dizem que o Claude Opus 4.7 é inferior ao 4.6?
Existem quatro razões principais:
- Refatoração do Tokenizer: O consumo de tokens para a mesma tarefa pode aumentar até 35%, mas o ganho de capacidade nem sempre compensa o custo.
- Queda em contexto longo MRCR: Caiu de 78,3% para 32,2%, representando um retrocesso grave no processamento de documentos extensos.
- Seguimento de instruções literal demais: Prompts da era 4.6 que "lêem a intenção" tendem a falhar no 4.7.
- Falsos positivos no Claude Code: Alguns desenvolvedores relatam que códigos normais foram marcados como maliciosos.
Isso não é uma ilusão, mas sim diferenças reais de experiência trazidas por mudanças estruturais.
Q3: Como migrar do Opus 4.6 para o 4.7 de forma segura?
Método de migração em três etapas:
- Testes de carga paralelos: Invoque o 4.6 e o 4.7 simultaneamente em 5–10% do tráfego de produção, comparando a qualidade da saída, latência e custo.
- Roteamento por cenário: Mantenha o 4.6 para documentos longos e bases de código grandes; alterne para o 4.7 em codificação de média/curta extensão e tarefas visuais.
- Liberação gradual: Suba de 10% → 30% → 50% → 100%, observando cada etapa por 3–7 dias.
Recomendamos usar a plataforma APIYI (apiyi.com) para esse tipo de teste de migração, já que ela suporta roteamento flexível de modelos e distribuição de tráfego.
Q4: Quando devo usar o nível xhigh do Claude Opus 4.7?
A Anthropic recomenda usar o xhigh por padrão em tarefas de codificação e tarefas Agentic. Cenários aplicáveis:
- Refatoração de código complexo.
- Depuração de bugs em múltiplos arquivos.
- Geração de testes unitários em larga escala.
- Tarefas de cadeia de ferramentas Agentic de múltiplos passos.
Cenários não recomendados:
- Perguntas e respostas simples (o nível "medium" é suficiente).
- Requisições de alta concorrência (o xhigh tem latência elevada).
- Tarefas sensíveis ao custo (o xhigh aumenta significativamente os tokens de saída).
Q5: Como usar Task Budgets? Para quais cenários são adequados?
Task Budgets é uma funcionalidade em teste público, passada através de HTTP Header:
task-budget-tokens: 50000
Cenários aplicáveis:
- Ciclos de agentes de longa duração (para controlar o custo total).
- SaaS multi-inquilino (limitar o orçamento por usuário).
- Automação de CI/CD (definir um teto de tokens para cada Job).
O modelo ajusta automaticamente a profundidade do raciocínio com base no orçamento restante, finalizando graciosamente antes de esgotá-lo, evitando falhas no meio do processo.
Q6: A capacidade visual do Claude Opus 4.7 é realmente tão forte assim?
Sim, e essa é uma das atualizações mais significativas do 4.7:
- Resolução máxima: Aumentou de 1,15 megapixels para 3,75 megapixels (3x).
- Benchmark visual: Saltou de 54,5% para 98,5%.
- Capacidade prática: Consegue ler diretamente capturas de tela 4K, diagramas de arquitetura, designs de interface e PDFs digitalizados.
Para equipes que fazem desenvolvimento front-end, implementação de design ou digitalização de documentos, este é um avanço que pode transformar o fluxo de trabalho.
Para quem o Claude Opus 4.7 é indicado? Recomendações de decisão
Com base na análise completa, apresentamos sugestões claras de uso:
Cenários para migrar imediatamente para o Claude Opus 4.7
- ✅ Codificação e refatoração de arquivos de tamanho médio a curto: Os dados do SWE-bench e CursorBench não deixam dúvidas.
- ✅ Fluxos de trabalho complexos de agentes: O suporte duplo do MCP-Atlas e Task Budgets faz toda a diferença.
- ✅ Processamento de imagens em alta definição: A capacidade visual de 3,75 MP representa uma mudança qualitativa.
- ✅ Desenvolvimento rápido de protótipos: O nível "xhigh" apresenta um desempenho excelente em tarefas de complexidade média.
Cenários para continuar usando o Claude Opus 4.6
- 🔒 Resumo e perguntas e respostas de documentos longos: O colapso do MRCR é inevitável.
- 🔒 Revisão de código em nível de repositório grande: A capacidade de recuperação em contextos longos é mais estável.
- 🔒 Extrema sensibilidade ao custo de tokens: O tokenizador do 4.6 é mais econômico.
- 🔒 Produção estável já em funcionamento: Não recomendamos introduzir riscos de regressão apenas para acompanhar novidades.
Estratégia recomendada de uso híbrido
Para a maioria das equipes, rotear por cenário é mais prático do que uma "migração total":
- Relacionado a documentos longos → Opus 4.6
- Codificação/Visual/Agentes → Opus 4.7
- Gerencie ambas as versões através de um gateway unificado para reduzir riscos de migração.
💡 Sugestão final: A escolha entre o Claude Opus 4.7 ou a permanência no 4.6 depende principalmente dos seus casos de uso específicos. Recomendamos realizar testes comparativos práticos através da plataforma APIYI apiyi.com. A plataforma suporta chamadas de interface unificadas para diversos modelos convencionais, facilitando a comparação e a alternância rápida, permitindo que você mantenha a flexibilidade do negócio durante o processo de migração.
Resumo
O Claude Opus 4.7 é uma "atualização de concessões" típica: ele alcançou um verdadeiro salto em codificação, visão e capacidades de agentes, mas pagou um preço claro em termos de recuperação de contexto longo, eficiência de tokens e compatibilidade de comando.
A discussão na comunidade no primeiro dia de lançamento não surgiu do nada — o Opus 4.7 é um novo modelo poderoso, mas também um ajuste arquitetural que traz custos. Para os desenvolvedores, a questão não é "migrar ou não", mas sim "em quais cenários migrar".
- Se você trabalha com tarefas complexas de código ou análise visual de alta definição, o 4.7 é a melhor escolha para o segundo trimestre de 2026.
- Se o seu negócio principal é o processamento de documentos longos ou inferência sensível a custos, mantenha o 4.6 por enquanto.
- Durante o processo de migração, recomendamos fortemente a realização de testes de estresse em paralelo para evitar regressões ocultas causadas por uma abordagem única.
Recomendamos experimentar rapidamente o Claude Opus 4.7 e o 4.6 através da plataforma APIYI apiyi.com. A plataforma oferece interface unificada, monitoramento de faturas em tempo real e capacidade de roteamento entre múltiplos modelos, sendo a escolha ideal para testes de migração e implementação em produção.
Referências
-
Comunicado oficial da Anthropic: Apresentação oficial do Claude Opus 4.7
- Link:
anthropic.com/news/claude-opus-4-7 - Descrição: Capacidades principais e detalhes de precificação da versão oficial.
- Link:
-
Documentação oficial da API Claude: Guia de migração do Claude Opus 4.7
- Link:
platform.claude.com/docs/en/about-claude/models/migration-guide - Descrição: Recomendações oficiais de migração e explicações sobre mudanças no Tokenizer.
- Link:
-
Blog de lançamento do AWS Bedrock: O Claude Opus 4.7 chega ao Amazon Bedrock
- Link:
aws.amazon.com/blogs/aws/introducing-anthropics-claude-opus-4-7-model-in-amazon-bedrock - Descrição: Instruções de implementação em nuvem de terceiros.
- Link:
-
Análise de benchmark da Vellum AI: Interpretação detalhada dos benchmarks do Claude Opus 4.7
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Descrição: Avaliação de benchmark independente de terceiros.
- Link:
-
GitHub Issue #47483: Feedback da comunidade sobre o Claude Opus
- Link:
github.com/anthropics/claude-code/issues/47483 - Descrição: Feedback direto da experiência de desenvolvedores.
- Link:
Autor: Equipe técnica da APIYI
Data de publicação: 17/04/2026
Modelos aplicáveis: Claude Opus 4.7 / Claude Opus 4.6
Troca de conhecimento: Acesse a APIYI em apiyi.com para obter créditos de teste e comparar você mesmo as diferenças entre as versões do Claude.