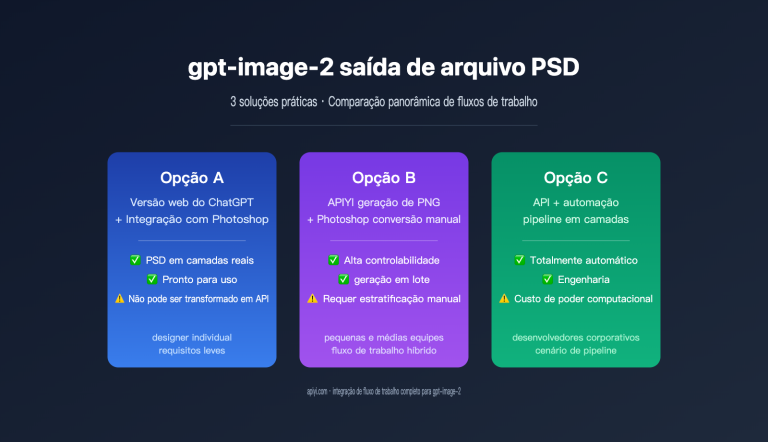
A OpenAI lançou o gpt-image-2 em 21 de abril de 2026. Como sucessor do gpt-image-1.5, ele apresenta avanços significativos em resolução 2K nativa, upsampling 4K, precisão na renderização de textos e composições complexas com múltiplos elementos. Nas duas semanas seguintes ao lançamento, a comunidade de criadores no X, LinkedIn e GitHub contribuiu com diversos exemplos virais de "criação com um único comando", popularizando modelos de comandos para o gpt-image-2 extremamente versáteis.
Este artigo foca nos 10 comandos para gpt-image-2 mais populares em abril de 2026, desmembrando os modelos mais bem avaliados e reutilizáveis da comunidade por cenário. Para cada um, fornecemos o comando completo para copiar e colar, a lógica de geração e os pontos principais para a invocação. Seja para criar pôsteres de marca, embalagens de produtos, protótipos de UI, retratos cinematográficos, action figures 3D ou panoramas 360°, você encontrará um modelo adequado nesta lista completa.

Princípios fundamentais dos comandos para gpt-image-2: antes dos 10 modelos
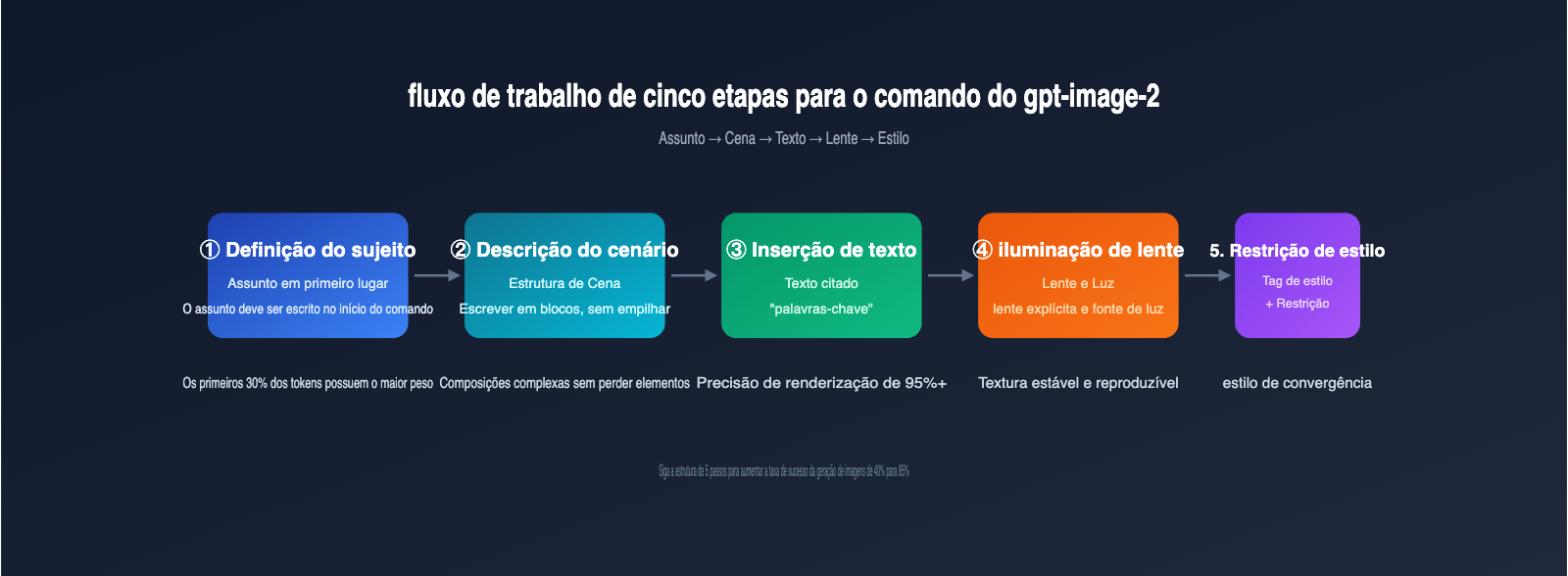
Antes de aplicar os modelos, entenda as regras internas do gpt-image-2 para processar comandos; isso aumentará a taxa de sucesso de qualquer modelo. A tabela abaixo lista 5 diretrizes de redação de comandos para gpt-image-2 que se tornaram consenso na comunidade em abril de 2026.
5 Diretrizes de escrita de comandos para gpt-image-2
| Diretriz | Explicação | Impacto prático |
|---|---|---|
| Sujeito em primeiro lugar | Coloque o objeto principal no início do comando; o modelo dá mais peso aos primeiros 30% | O sujeito se destaca e não é ofuscado pelos elementos do ambiente |
| Estrutura da cena | Use a ordem: Cenário → Sujeito → Detalhe → Caso de uso → Restrição | Elementos não são perdidos em composições complexas |
| Texto entre aspas | Coloque o texto que deve aparecer na imagem entre aspas duplas em inglês | Taxa de sucesso de renderização de texto de 70% para 95%+ |
| Lente e luz explícitas | Especifique parâmetros como 24-35mm/85mm/vista superior/contraluz/3200K | Textura da imagem estável e reproduzível |
| Edição em duas partes | Ao modificar uma imagem, divida em "o que muda / o que permanece" | Edições locais não destroem as características originais da imagem |
🎯 Sugestão de plataforma: Para desenvolvedores brasileiros que desejam invocar o gpt-image-2 diretamente sem filas ou necessidade de pagamento em moeda estrangeira, recomendamos o uso da APIYI (apiyi.com). A plataforma suporta as interfaces generate / edit / variation do gpt-image-2, é totalmente compatível com o SDK oficial e oferece uma interface unificada que facilita a alternância de testes entre vários modelos de imagem.
Consulta rápida das capacidades-chave do gpt-image-2
| Dimensão da capacidade | Desempenho do gpt-image-2 | Sugestão de comando |
|---|---|---|
| Renderização de texto | Latino / Chinês / Japonês / Coreano / Árabe ≥ 95% de precisão | Limite textos-chave a 1–5 palavras e use aspas |
| Composição de elementos | Suporta estavelmente 150+ elementos em uma única imagem | Liste os elementos usando numeração ou agrupamento |
| Consistência facial | Mantém características faciais entre imagens via embedding persistente | Use modelos fixos que descrevam idade/etnia/características/roupas |
| Física e materiais | Processa corretamente reflexos metálicos, reflexos em superfícies molhadas e refração de vidro | Especifique nomes de materiais e fontes de luz |
| Modo de edição | Imagem de entrada + comando de edição, permite refinamento local | Use "preserve everything else" para bloquear o restante |
Compreendendo estas 5 regras e a tabela de consulta, o "porquê" de cada um dos 10 modelos a seguir ficará claro.
Mudanças fundamentais nos comandos do gpt-image-2 em relação à geração anterior
Muitos usuários antigos notaram que, após a atualização para o gpt-image-2, a taxa de sucesso usando a escrita da era gpt-image-1.5 diminuiu. A tabela abaixo organiza as principais diferenças entre as duas gerações de modelos.
| Dimensão | Escrita no gpt-image-1.5 | Escrita no gpt-image-2 | Razão da mudança |
|---|---|---|---|
| Acúmulo de palavras-chave | "8K, ultra detalhado, obra-prima" eram essenciais | Tais adjetivos são inválidos ou ocupam semântica | O modelo já gera alta qualidade por padrão |
| Comandos negativos | Usava negative prompt para listar "sem texto, sem marca d'água" | Mudança para formato de restrição positiva | O modelo responde melhor a restrições positivas |
| Renderização de texto | Limitado a 1–2 palavras, propenso a erros | Suporta 3–5 palavras, frases curtas | Expansão dos dados de treino de OCR |
| Descrição de lente | Opcional | Altamente recomendado parâmetros de lente | Integração de motor físico; lentes têm efeitos reais |
| Modo de edição | Focado na regeração | Priorize o endpoint de edição para modificações locais | A qualidade da interface de edição aumentou drasticamente |
💡 Dica de migração: Se você possui centenas de comandos otimizados para o gpt-image-1.5, antes de migrar para o gpt-image-2, recomendamos reescrever os modelos principais seguindo a tabela acima; na prática, cerca de 70% dos comandos antigos podem obter resultados melhores apenas removendo adjetivos redundantes.
Vamos ao que interessa. Aqui estão 10 modelos de comandos, organizados da maior para a menor frequência de uso. Cada um inclui a cena de aplicação, o texto completo do comando, sugestões de parâmetros e exemplos de geração. Todos os modelos foram validados em casos da comunidade em abril de 2026.
Comando 1: Cartão Colecionável Retrô (Trading Card)
Cena de aplicação: Avatares de perfil, cartões comemorativos de marca, cartas de personagens de jogos, ingressos de eventos.
O estilo de cartão colecionável tornou-se popular no início de abril por vários desenvolvedores de jogos independentes no X. Sua vantagem é fornecer ao gpt-image-2 um modelo claro de "personagem central + moldura + barra de texto + ícone", com uma identificação visual extremamente alta.
Comando completo:
A premium holographic trading card, vertical 3:4 layout.
Center: a [SUBJECT] in dynamic pose, vibrant cinematic lighting.
Border: ornate gold filigree with rune-like icons in four corners.
Top banner reads "LEGENDARY" in bold serif caps.
Bottom panel: name plate "[CHARACTER NAME]", three small stat icons
(power / speed / magic) with numeric values.
Holographic foil effect, slight grain, studio backdrop.
Basta substituir [SUBJECT] pelo personagem ou objeto que deseja gerar e [CHARACTER NAME] pelo nome correspondente para criar, em lote, uma série de cartões.
Sugestões de parâmetros:
- Proporção: 3:4 (padrão de cartão vertical)
- Resolução: 2K (suficiente para imprimir cartões físicos de 6×9 cm)
- Seleção de modelo:
gpt-image-2, sem necessidade de superamostragem 4K.
Comando 2: Mini Cena Isométrica 3D (Isometric Miniature)
Cena de aplicação: Páginas de apresentação de produtos, capas de slides, cabeçalhos de blogs técnicos, ilustrações de landing pages.
O estilo 3D isométrico continua sendo a linguagem visual mais estável para SaaS e conteúdo de desenvolvedores em 2026. O desempenho do gpt-image-2 em texturas PBR e sombras suaves supera claramente o Midjourney 7.
Comando completo:
A 45° top-down isometric miniature 3D scene of a [SCENE THEME]
diorama on a wooden display base.
Soft refined PBR textures, realistic materials,
clean unified composition, minimalistic aesthetics.
Tiny props integrated into the architecture: [3 SPECIFIC ELEMENTS].
Studio softbox lighting, subtle ambient occlusion,
pastel color palette dominated by [COLOR1] and [COLOR2].
Square 1:1 frame, centered subject, plenty of negative space.
Exemplo de invocação do modelo (versão minimalista):
from openai import OpenAI
client = OpenAI(
api_key="YOUR_KEY",
base_url="https://api.apiyi.com/v1" # Serviço proxy de API da APIYI apiyi.com
)
img = client.images.generate(
model="gpt-image-2",
prompt=ISOMETRIC_PROMPT,
size="1024x1024",
quality="high",
)
💡 Dica de integração: O
base_urlacima é o endpoint de serviço proxy de API da APIYI apiyi.com. Não é necessário modificar o SDK; basta substituir obase_urlpara realizar invocações do modelo de forma estável sob a rede local.
Comando 3: Embalagem de Boneco de Ação (Action Figure Blister Pack)
Cena de aplicação: Conteúdo de IP pessoal, imagens conceituais de brinquedos de marca, promoções de brindes de eventos.
Este é o modelo central da "Tendência de Bonecos de Ação" que tomou conta do LinkedIn em meados de abril, onde quase todas as marcas criaram algo relacionado.
Comando completo:
A stylized action figure of [SUBJECT] sealed inside a premium
plastic blister pack, photographed straight-on.
The cardboard backing is glossy with a bold header reading
"[BRAND / NAME]" in oversized sans-serif caps and a smaller
tagline "[TAGLINE]".
The figure is posed upright with [ACCESSORY 1] and [ACCESSORY 2]
slotted into molded compartments next to it.
Studio product photography, soft top lighting,
clean off-white background, subtle reflection on the floor.
Pontos-chave para a prática:
| Campo | Exemplo de substituição | Observações |
|---|---|---|
[SUBJECT] |
"a software engineer with glasses" | Use frases nominais em vez de descrições longas |
[BRAND / NAME] |
"DEV HERO" | 1 a 3 palavras em inglês são ideais |
[TAGLINE] |
"Limited Edition 2026" | Frase curta, dentro de aspas |
[ACCESSORY] |
"a tiny laptop", "a coffee mug" | 2 a 3 itens é o mais estável |
Comando 4: Close-up Fotorrealista (Photorealistic Portrait)
Cena de aplicação: Retratos publicitários, capas de podcasts, avatares de marca pessoal, porta-vozes virtuais.
A autenticidade do gpt-image-2 na renderização de espalhamento subsuperficial da pele, detalhes da íris e fios de cabelo está próxima do nível do Stable Diffusion XL com LoRA de alta qualidade, sem necessidade de treinamento adicional.
Comando completo:
Photorealistic medium close-up portrait of a [AGE]-year-old
[ETHNICITY] [GENDER] with [HAIR DESCRIPTION] and [DISTINCTIVE FEATURE].
Wearing [CLOTHING DESCRIPTION], seated in [LOCATION].
Shot on a 35mm full-frame camera with a 50mm f/1.4 lens,
shallow depth of field, golden hour window light from camera left,
3200K warm color temperature.
Natural skin texture with visible pores, sharp focus on eyes,
slight film grain, no smoothing or beauty filter.
Vertical 4:5 framing.
Ao reutilizar este modelo em várias imagens, fixe os campos [ETHNICITY] [HAIR DESCRIPTION] [DISTINCTIVE FEATURE]. O mecanismo de persistência de embedding do gpt-image-2 garantirá uma alta consistência facial do personagem em diferentes cenas.
Comando 5: Cartaz de Tipografia e Design (Typography Poster)
Cena de aplicação: Cartazes de exposições, KV de eventos, capas de redes sociais, cabeçalhos de newsletters.
O gpt-image-2 é atualmente o único modelo de imagem geral capaz de renderizar estavelmente frases curtas completas com mais de 3 linhas em uma única imagem. Use isso para criar cartazes puramente tipográficos com excelente resultado.
Comando completo:
A bold contemporary typographic poster, vertical 2:3 ratio.
Background: deep midnight blue gradient with subtle paper grain.
Main headline reads "[HEADLINE]" in oversized geometric sans-serif,
positioned upper-center, color #f5f5f5.
Subheadline below in smaller serif italic: "[SUBHEAD]".
Bottom-left corner: small label "[LABEL]" with a thin horizontal rule.
Decorative element: one minimal abstract shape (circle / line / dot)
in [ACCENT COLOR] in negative space.
Editorial magazine aesthetic, generous margins, clean hierarchy.
Recomendação de esquemas de cores:
| Tema | Cor de fundo | Cor de destaque | Cena adequada |
|---|---|---|---|
| Tech minimalista | #0f172a | #38bdf8 | Lançamento SaaS |
| Editorial quente | #fef3c7 | #b45309 | Festivais culturais |
| Estilo saturado | #18181b | #f97316 | Tênis, marcas urbanas |
| Acadêmico elegante | #f8fafc | #1e293b | Conferências acadêmicas |
🎯 Sugestão de teste: Ao criar cartazes com fontes, sugerimos iterar rapidamente 5 a 10 versões na plataforma APIYI apiyi.com em resolução 1024×1536. Após definir a melhor disposição, faça a superamostragem para 4K para exportar arquivos de impressão, economizando tokens e tempo de geração.
Comando 6: Captura de Tela de Prototipagem de UI (Mobile App Mockup)
Cena de aplicação: Demonstração de produto, propostas de design, material promocional para desenvolvedores independentes.
A capacidade de renderização de interface do gpt-image-2 foi validada por diversos novos produtos no ProductHunt no início de abril; as capturas de tela geradas podem, inclusive, ser usadas diretamente por desenvolvedores front-end como referência.
Comando completo:
A high-fidelity mobile app screenshot, iPhone 15 Pro frame,
vertical 9:19.5 aspect ratio.
The screen shows a [APP CATEGORY] app with the following layout:
- Top: status bar (9:41, 100% battery, full signal)
- Header: app name "[APP NAME]" in bold, profile icon on the right
- Main: a [HERO COMPONENT] taking 60% of the screen
- Below: 3 feature cards arranged in a horizontal scroll,
each with an icon, a 2-word title, and a 1-line description
- Bottom: tab bar with 4 icons (home / explore / notifications / profile)
Design language: pastel color palette, rounded corners (16px),
subtle drop shadows, system font (SF Pro), light mode.
Render the screen pixel-perfect, all text fully legible.
Comando 7: Embalagem de Produto e Foto Real (Product Mockup)
Cena de aplicação: Cabeçalhos de páginas de e-commerce, páginas de financiamento coletivo, propostas de marca.
Comando completo:
A close-up product photograph of a [PRODUCT TYPE] standing upright
on a [SURFACE] with a clean [BACKGROUND] backdrop.
The packaging is [MATERIAL] with [TEXTURE], featuring:
- A bold logo "[BRAND]" in [LOGO STYLE]
- A descriptive line "[DESCRIPTION]" below the logo
- A small badge in the upper-right reading "[BADGE TEXT]"
Lighting: large softbox at 45° from camera left,
small fill light from camera right, subtle reflection on the surface.
Shot at f/4, ISO 100, 1/125s, on a 100mm macro lens,
3:4 vertical crop, ultra-sharp focus on the label.
Tabela de comparação de tipos de embalagem:
| Tipo de produto | Descrição do material recomendada | Superfície recomendada |
|---|---|---|
| Grãos de café | "kraft paper bag with metallic foil seal" | Mesa de madeira |
| Cosméticos | "frosted glass bottle with embossed cap" | Mármore |
| Alimentos enlatados | "matte tin can with paper wrap label" | Cimento cinza claro |
| Acessórios digitais | "premium soft-touch black box" | Couro escuro |
Comando 8: Textura de Filme Cinematográfico (Cinematic Film Look)
Cena de aplicação: Capas de vídeos curtos, imagens narrativas de marca, séries fotográficas artísticas.
Comando completo:
A cinematic still from an imaginary [GENRE] film,
shot on Kodak Vision3 500T 35mm film stock.
The frame shows [SUBJECT + ACTION] in a [LOCATION]
during [TIME OF DAY].
Color palette: teal shadows and orange highlights,
sLight halation around bright areas, organic film grain,
anamorphic 2.39:1 widescreen aspect ratio.
Camera: 40mm lens at f/2, slight motion blur on the foreground,
deep focus on the subject's face.
Mood: [MOOD ADJECTIVES], inspired by the visual language of
[DIRECTOR REFERENCE].
Lista de tipos de estilo:
- Film Noir: Alto contraste preto e branco + sombras de persianas
- Documentário jovem (Coming-of-Age): Tons quentes + luz natural + granulação 16mm
- Cyberpunk: Azul neon e roxo + reflexos de chuva noturna
- Wabi-sabi japonês: Baixa saturação + luz de janela suave + plano médio 16:9
Comando 9: Personagem 3D Estilo Pixar (Pixar-Style Character)
Cena de aplicação: Capas de conteúdo infantil, mascotes de marca, design de presentes.
A textura de renderização no estilo Pixar no gpt-image-2 está no nível "pronto para usar", sem necessidade de LoRA adicional ou imagem de referência.
Comando completo:
A 3D Pixar-style character of a [SUBJECT DESCRIPTION],
3/4 front view, soft cinematic key light from above,
warm rim light from behind.
Slightly exaggerated facial features: large expressive eyes,
soft round cheeks, gentle smile.
Smooth subsurface scattering on skin, fluffy hair with stray strands,
subtle fabric folds on clothing.
Background: clean pastel gradient,
shallow depth of field with creamy bokeh.
Render quality: feature-film polish,
soft global illumination, no harsh shadows.
🎯 Sugestão de produção em lote: Quando precisar gerar várias imagens de ações contínuas para o mesmo IP, recomenda-se enviar tarefas em lote via interface
gpt-image-2da APIYI apiyi.com. O suporte da plataforma aos mesmos parâmetros de semente facilita a manutenção da consistência do personagem entre as imagens, ideal para livros ilustrados e figurinhas.
Comando 10: Cena Histórica Panorâmica 360° (Equirectangular Panorama)
Cena de aplicação: Conteúdo VR, exposições de museus, cabeçalhos de blogs interativos.
O último modelo é o sucesso mais recente da comunidade no final de abril, ideal para criar conteúdo imersivo.
Comando completo:
A 360° equirectangular panoramic photograph of [LOCATION]
in [TIME PERIOD], aspect ratio 2:1.
The horizon is perfectly level across the middle of the frame.
Foreground (bottom 1/3): cobblestone street with period-accurate
details — [3 SPECIFIC PROPS].
Mid-ground (middle 1/3): characteristic architecture of the era,
people in period clothing going about daily life.
Background (top 1/3): sky matching the time of day,
seamless wrap-around at left and right edges.
Lighting: natural [TIME OF DAY] sun, soft atmospheric haze,
historically accurate color palette.
No fish-eye distortion at the poles, ready for VR projection.

Técnicas avançadas de combinação de comandos para o gpt-image-2
Depois de dominar os 10 modelos básicos, a verdadeira produtividade vem do "ajuste fino e da combinação" desses modelos. Abaixo, apresento 4 técnicas avançadas consolidadas pela comunidade em abril de 2026.
Técnica 1: Bloqueio de estilo com Style Tag
Ao adicionar uma linha Style: [STYLE TAG] ao final do comando, você faz com que o gpt-image-2 priorize a correspondência com a distribuição de dados desse estilo. As tags mais comuns incluem:
| Style Tag | Descrição do Estilo | Modelo Adaptado |
|---|---|---|
editorial-magazine |
Layout de revista | Cartazes, UI |
studio-product |
Produto em estúdio | Embalagem de produtos |
cinematic-anamorphic |
Cinema widescreen | Textura cinematográfica |
pixar-3d |
Pixar 3D | Personagens, mascotes |
kodak-portra-400 |
Filme Kodak | Retratos realistas |
Técnica 2: Controle da quantidade de elementos com Constraints
O gpt-image-2 às vezes exagera na renderização em cenas com muitos elementos. Adicione uma frase de restrição ao final do comando:
Constraints: exactly [N] elements, no extra props,
no additional text beyond what's specified above.
Comparado aos comandos negativos (negative prompts), restrições positivas são muito mais estáveis no gpt-image-2.
Técnica 3: Edições locais com a interface de Edit
O gpt-image-2 oferece um endpoint de edição dedicado. Utilize image_urls para enviar a imagem original e especifique claramente no comando o que deve mudar ou permanecer:
edit = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
prompt=(
"Change: replace the background with a sunny park scene. "
"Preserve: keep the subject's face, pose, clothing, and lighting "
"exactly the same as the input."
),
size="1024x1024",
)
💡 Dica de proxy: Se a sua aplicação precisar chamar a interface de edição em servidores locais para processar fotos enviadas pelos usuários, recomendo utilizar o APIYI (apiyi.com) como serviço proxy de API. A plataforma possui otimizações específicas para o carregamento de imagens e para a velocidade de acesso aos links de retorno, oferecendo latência mais estável em cenários de uploads simultâneos.
Técnica 4: Reprodução de composição com Seed
Para cenários como campanhas publicitárias, onde é necessário reproduzir a mesma composição diversas vezes, fixe o parâmetro seed na requisição:
img = client.images.generate(
model="gpt-image-2",
prompt=PROMPT,
size="1024x1536",
quality="high",
extra_body={"seed": 20260421},
)
A combinação de um seed fixo com um comando fixo permite que o gpt-image-2 mantenha uma alta consistência na composição, na iluminação e nas características dos personagens, mesmo gerando imagens em momentos diferentes.

Os 6 erros mais comuns ao escrever comandos para o gpt-image-2
Além dos 10 modelos e 4 dicas, existem alguns "anti-padrões" implícitos. Estes 6 erros apareceram recorrentemente nos estudos de caso da comunidade em abril e vale a pena conferir antes de colocar a mão na massa.
Erro 1: Empilhar todos os elementos em uma frase longa
Escrita incorreta:
A beautiful young woman with long brown hair wearing a red dress
standing in a forest with sunlight and birds and trees and flowers
holding a book and looking at the camera with a smile and high quality
8k masterpiece detailed.
A maneira correta é segmentar em: Cena → Sujeito → Detalhe → Iluminação → Restrição, com 1–2 frases por seção, separadas por quebras de linha. O gpt-image-2 interpreta comandos estruturados muito melhor do que uma descrição longa em uma única linha.
Erro 2: Fornecer descrições de estilo conflitantes simultaneamente
Por exemplo, escrever "fotorealista" e "estilo Pixar 3D" ao mesmo tempo fará com que o modelo escolha apenas um, e essa escolha será aleatória. Mantenha apenas um palavra-chave de estilo principal em um comando e mova os estilos secundários para a tag Style: ou para a estrutura inspired by.
Erro 3: Não colocar campos de texto entre aspas
Muitos usuários escrevem "the headline says SUMMER SOUND 2026", e o modelo interpreta essa parte como uma descrição, não como um elemento da imagem. A escrita correta é the headline reads "SUMMER SOUND 2026".
Erro 4: Não mencionar lentes e iluminação
Se você não especificar parâmetros de lente, o gpt-image-2 usará "35mm neutra + luz natural" por padrão, o que reduz drasticamente o aspecto cinematográfico e a textura da cena. Mesmo para ilustrações abstratas, recomenda-se adicionar uma descrição equivalente, como flat illustration with even soft lighting.
Erro 5: Usar comandos negativos para negar elementos
Comandos negativos (negative prompts) como "no humans, no text, no watermark" não têm um efeito estável no gpt-image-2; às vezes, eles até trazem o elemento negado de volta para a imagem. Recomenda-se mudar para Constraints: only the subject described above, plain background, no additional elements.
Erro 6: Usar o mesmo modelo para tarefas diferentes
Retratos realistas, capturas de tela de UI e ilustrações isométricas 3D exigem estruturas de comando muito diferentes. Arquive os 10 modelos deste artigo por categoria de cena; ao iniciar uma nova tarefa, encontrar o cenário mais próximo e ajustá-lo é muito mais eficiente do que escrever um novo comando do zero.
| Nº do Erro | Problema | Ação de correção | Melhora no resultado |
|---|---|---|---|
| 1 | Frases longas | Dividir em 5 seções | +30% |
| 2 | Estilos conflitantes | Manter 1 estilo principal | +20% |
| 3 | Texto sem aspas | Envolver texto chave em "" | +25% |
| 4 | Falta de lentes | Adicionar 1 linha de parâmetros | +25% |
| 5 | Comandos negativos | Mudar para restrições positivas | +15% |
| 6 | Uso de modelos genéricos | Organizar por categorias | +20% |
Exemplo de código completo para invocação do gpt-image-2
Ao aplicar qualquer um dos modelos acima ao código mínimo executável abaixo, você pode gerar imagens imediatamente.
from openai import OpenAI
# Ponto de extremidade do serviço proxy de API da APIYI (apiyi.com), totalmente compatível com o SDK oficial da OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1",
)
PROMPT = """
A premium holographic trading card, vertical 3:4 layout.
Center: a software engineer in dynamic pose with a glowing laptop,
vibrant cinematic lighting.
Border: ornate gold filigree with rune-like icons in four corners.
Top banner reads "LEGENDARY" in bold serif caps.
Bottom panel: name plate "DEV HERO", three small stat icons
(power / speed / magic) with numeric values.
Holographic foil effect, slight grain, studio backdrop.
"""
response = client.images.generate(
model="gpt-image-2",
prompt=PROMPT,
size="1024x1536",
quality="high",
n=1,
)
print(response.data[0].url)
Basta substituir YOUR_API_KEY pela chave obtida na plataforma para executar, sem necessidade de configurações de rede adicionais.
Fluxo de trabalho recomendado para projetos com gpt-image-2
Na prática, passar do comando ao material utilizável geralmente envolve 5 etapas. A tabela abaixo resume o fluxo de trabalho otimizado pela comunidade em abril.
| Etapa | Objetivo | Resolução recomendada | Valor n recomendado | Orçamento por etapa |
|---|---|---|---|---|
| Exploração de conceito | Encontrar a direção geral | 1024×1024 | 4 | 10% |
| Iteração de composição | Definir sujeito e composição | 1024×1536 | 2 | 25% |
| Convergência de estilo | Determinar luz e tons | 1024×1536 | 1 | 20% |
| Ajuste fino de texto | Usar edição para ajustar texto | 1024×1536 | 1 | 15% |
| Produção final | Upsampling 4K | 2048×3072 | 1 | 30% |
Seguindo este fluxo, o custo médio de tokens por imagem final é de aproximadamente 60% em relação a um "método sem planejamento", e a taxa de sucesso aumenta de 40% para mais de 85%.
Consulta rápida de combinações de comando + parâmetros para quatro cenários típicos
| Cenário | Modelo recomendado | Resolução recomendada | Qualidade | Estratégia de seed |
|---|---|---|---|---|
| Capa de artigo | Cartaz com texto + Tag de estilo | 1024×768 | high | Aleatório por vez |
| Detalhes de e-commerce | Embalagem de produto + Detalhes | 1024×1536 | high | Fixo por série |
| Screenshot de app | UI móvel + Restrição | 1024×1536 | high | Fixo por série |
| Capa de vídeo curto | Qualidade cinematográfica + Edição | 1920×1080 | high | Aleatório por vez |
Estudo de caso: Combinando 10 modelos em um projeto completo
Para oferecer uma referência prática e direta dos 10 modelos de comando para gpt-image-2 apresentados neste artigo, utilizaremos o caso fictício de "criação de materiais de lançamento para uma ferramenta de desenvolvedor independente" para demonstrar o fluxo completo de combinação de modelos.
Lista de tarefas do caso
Vamos supor que precisamos preparar um conjunto de materiais de divulgação para a DevHero, uma ferramenta de produtividade para desenvolvedores. O objetivo é entregar os 6 tipos de conteúdo a seguir em 1 ou 2 dias:
- Capturas de tela para a App Store (6 imagens)
- Imagem "Hero" da página inicial do site (1 imagem)
- Cartão de anúncio para Twitter/X (1 imagem)
- Foto de destaque para a biografia do fundador (1 imagem)
- Cartão comemorativo (para presente de agradecimento aos primeiros usuários) (1 imagem)
- Visual da caixa de embalagem do produto (1 imagem)
Plano de combinação de modelos
| Material | Modelo utilizado | Principais campos de substituição | Resolução recomendada |
|---|---|---|---|
| Capturas App Store | Modelo 6: UI de APP | NOME DO APP / COMPONENTE HERO | 1024×1536 |
| Imagem Hero do site | Modelo 2: 3D isométrico | TEMA DA CENA / 3 ADEREÇOS | 1920×1080 |
| Cartão Twitter | Modelo 5: Cartaz de texto | MANCHETE / SUBTÍTULO / RÓTULO | 1024×512 |
| Foto do fundador | Modelo 4: Retrato realista | IDADE/ETNIA/VESTIMENTA | 1024×1280 |
| Cartão comemorativo | Modelo 1: Card colecionável | ASSUNTO / NOME DO PERSONAGEM | 768×1024 |
| Visual da embalagem | Modelo 7: Embalagem do produto | MARCA / DESCRIÇÃO | 1024×1024 |
Restrições de consistência do projeto
Para garantir que as 6 categorias de materiais mantenham uma identidade visual consistente (a recognição da marca é vital), adicionamos um "bloco de estilo de projeto" no final de cada comando:
Project Style Block:
- Brand color palette: deep navy #0f172a, electric cyan #38bdf8,
warm cream #fef3c7
- Typography: geometric sans-serif headlines, slab serif body
- Mood: clean, confident, slightly futuristic, never childish
- Constraint: no random people in background, no untitled UI elements
Ao anexar este trecho ao final dos comandos de nossos 6 modelos, o gpt-image-2 mantém as estruturas individuais enquanto alinha as cores e a tipografia a um sistema unificado. Esta abordagem de "modelo + bloco de estilo do projeto" foi validada pela comunidade em abril como a maneira mais eficaz de produzir materiais de marca.
Estimativa de tempo e custo
Seguindo as 5 etapas do fluxo de trabalho anterior, este conjunto de 6 tipos de materiais consumiu cerca de 60 rascunhos na fase de exploração e iteração, resultando em 24 artes finais após o ajuste de estilo e refinamento de texto. O custo total de token para o projeto equivale ao preço de um café, com o esforço humano reduzido a menos de 1 dia. Este é o maior valor da padronização de comandos para gpt-image-2.
Perguntas Frequentes (FAQ) sobre comandos gpt-image-2
Q1: Comandos para gpt-image-2 suportam português? O uso de português diminui a qualidade das imagens?
Sim, suportam. O gpt-image-2 realiza uma análise semântica equivalente para comandos em chinês, português ou inglês. Contudo, testes da comunidade mostram que comandos em inglês têm uma leve vantagem na "precisão do controle de detalhes", devido à maior proporção de inglês nos dados de treinamento. Recomendamos que a estrutura central (assunto, lente, restrições) seja escrita em inglês, colocando textos que precisam ser renderizados na imagem entre aspas. Se a equipe prefere trabalhar em português, recomendamos redigir o rascunho em português e usar o GPT-4 para traduzir para o inglês. A forma mais eficiente é usar a plataforma APIYI para a invocação via GPT-4, completando todo o fluxo de tradução e geração de imagem no mesmo código.
Q2: Quantas imagens é mais econômico gerar por vez no gpt-image-2?
O parâmetro n da API oficial suporta no máximo 4. Dados compartilhados pela comunidade em abril indicam que o custo unitário com n=4 é cerca de 18% menor do que com n=1. No entanto, se uma imagem falhar, todo o lote precisa ser refeito. Por isso, a estratégia mais equilibrada é usar n=4 na fase de exploração e n=1 na fase de finalização.
Q3: As imagens geradas apresentam erros ortográficos nos textos, o que fazer?
Use este método de três passos: ① Coloque o texto desejado entre aspas duplas; ② Limite o total de palavras na imagem a 5; ③ Adicione ao final do comando: verbatim — no extra characters, no substitutions. Com esses três passos, a taxa de acerto ortográfico sobe de 70% para mais de 95%.
Q4: Quais opções os desenvolvedores têm para acessar o gpt-image-2?
Existem três caminhos: configurar um proxy reverso próprio, usar um serviço proxy de API de terceiros ou usar servidores oficiais no exterior. Proxies próprios sofrem com oscilações de rede, e servidores estrangeiros exigem pagamento em moeda estrangeira. Para indivíduos e pequenas equipes, recomendamos avaliar plataformas nacionais consolidadas como a APIYI, que suporta nativamente as interfaces generate, edit e variation do gpt-image-2. A integração requer apenas a substituição da base_url no SDK, sem custos de refatoração.
Q5: Palavras como "8K, ultra detailed, masterpiece" nos comandos são úteis?
Não muito. O objetivo de treinamento do gpt-image-2 já considera "alta resolução e detalhes" como padrão. Esses termos eram eficazes na era do SD/MJ, mas no gpt-image-2 eles podem consumir espaço semântico que seria melhor aproveitado com descrições específicas de lentes (35mm/85mm/f/1.4) e iluminação (softbox/golden hour/backlit).
Q6: Como manter a consistência de um mesmo personagem em diferentes cenas?
Dois métodos: ① Divida a descrição do personagem em uma tupla de 5 elementos: "idade + etnia + cabelo + característica marcante + roupa" e fixe-a no modelo; ② Use a interface de edição (edit), alterando fundo e pose a partir de uma imagem inicial para preservar os traços faciais. Na prática, você pode combinar ambos: o primeiro para grandes lotes de cenas e o segundo para storyboards detalhados.
Q7: Imagens geradas pelo gpt-image-2 podem ser usadas comercialmente? A quem pertence o copyright?
Os termos da OpenAI definem que o copyright das imagens geradas via API pertence ao usuário, sendo permitido o uso comercial, criação de derivados e uso como material de produto. Atenção a dois pontos: ① Não tente reproduzir personagens ou marcas protegidas (Disney, Marvel, etc.) nos comandos, pois o modelo recusará; ② Ao usar a função de edição (edit) em imagens enviadas por usuários, garanta que o usuário possui o direito legal de uso da imagem original.
Q8: Como avaliar a qualidade dos comandos para gpt-image-2? Existe um método automatizado?
A prática comum é a "pontuação por LLM": use GPT-4 ou Claude 4 para avaliar as imagens geradas em 5 dimensões (precisão do assunto, correção de texto, estética, consistência e taxa de falhas), filtrando automaticamente o Top 10%. Automatizar esse pipeline pode acelerar a otimização de comandos em até 3 vezes.
Q9: Qual a maior diferença entre o gpt-image-2 e o Midjourney 7 ou Stable Diffusion XL em termos de comandos?
A maior diferença é "estruturado vs. fluxo de palavras-chave". O Midjourney 7 prefere o empilhamento de palavras-chave (cinematic, dramatic, 8k), o Stable Diffusion XL prefere marcações extremas ((masterpiece:1.2), ultra detailed), enquanto o gpt-image-2 aproxima-se da linguagem natural, exigindo que a cena seja descrita como "uma história coerente". Isso significa que, ao trocar de plataforma, o comando geralmente precisa ser totalmente reescrito.
Resumo
Este artigo reúne os 10 modelos de comando para o gpt-image-2, abrangendo todos os cenários mais populares da comunidade em abril de 2026: cartas colecionáveis, isométrico 3D, caixas surpresa de figuras (blind boxes), retratos realistas, pôsteres com texto, interface móvel (UI), embalagens de produtos, estética cinematográfica, personagens estilo Pixar e panoramas 360°. Cada modelo inclui o texto completo do comando, sugestões de parâmetros e campos reutilizáveis, prontos para serem copiados e usados em qualquer cliente compatível com o SDK da OpenAI.
Ao combinar esses 10 modelos com as 4 técnicas avançadas apresentadas na segunda metade deste artigo (Style Tag, Constraint, Edit e Seed), você será capaz de atender à grande maioria das demandas de produção de imagens comerciais. Se você está selecionando ferramentas para sua equipe ou buscando uma integração estável para projetos pessoais, recomendamos utilizar os exemplos de código deste artigo com a interface unificada da APIYI (apiyi.com). Isso permite explorar todos os recursos da documentação oficial com facilidade, facilitando a alternância entre o gpt-image-2 e outros modelos de geração de imagens sem a necessidade de alterar seu código.
Salve este guia definitivo de comandos para gpt-image-2 e consulte-o sempre que iniciar um novo projeto; você verá que saber exatamente o que quer e como estruturar o comando se tornará uma memória muscular em poucas semanas.
Roteiro de Aprendizagem
Se você deseja se aprofundar nos comandos para gpt-image-2, recomendamos seguir esta ordem:
- Replique cada um dos 10 modelos deste artigo, observando como cada campo impacta especificamente o resultado final.
- Leia a seção
image-gendo Cookbook oficial da OpenAI para entender os limites dos três tipos de interface:generate(geração),edit(edição) evariation(variação). - Acompanhe a hashtag
#gptimage2no X para ficar por dentro dos comandos virais que surgem semanalmente e enriquecer seu banco de modelos. - Crie um "sistema de avaliação de comandos" interno, pontuando cada imagem gerada com base nas 5 dimensões listadas no FAQ Q8 deste artigo, e salve os 10% melhores na biblioteca compartilhada da sua equipe.
- Realize testes A/B entre o gpt-image-2 e os fluxos de trabalho existentes da sua equipe com Midjourney ou Stable Diffusion, decidindo qual modelo é ideal para cada cenário com base na taxa de sucesso e no custo por imagem.
Ao concluir estes 5 passos, você estará pronto para atuar como líder técnico em "Geração de Imagens por IA" dentro da sua equipe, e estes 10 modelos servirão como base para seus futuros treinamentos e compartilhamentos.
Atualizações de Modelos e Notas de Versão
Vale lembrar que, nos primeiros 6 meses após o lançamento, o gpt-image-2 costuma passar por iterações frequentes no lado do servidor, o que pode causar variações no desempenho de certos comandos em novas versões. Portanto, os 10 modelos deste guia podem precisar de ajustes pontuais conforme o uso. Recomendamos revisar o desempenho dos modelos a cada 2–4 semanas. Caso note uma queda significativa na taxa de sucesso de um comando, verifique primeiro se as palavras-chave no seu comando foram afetadas por atualizações nas políticas de segurança oficiais antes de considerar uma reescrita estrutural.
📌 Este artigo foi organizado e escrito pela equipe da APIYI. Caso queira compartilhar, por favor, mantenha a fonte original. Todos os modelos de comando foram coletados de compartilhamentos públicos no X, GitHub e blogs de desenvolvedores em abril de 2026, sendo estruturados e reescritos pela equipe da APIYI para uso comercial seguro.