Nota do autor: Comparação de Gemini 3.1 Pro e Claude Sonnet 4.6 em 5 dimensões: codificação, raciocínio, multimodalidade, trabalho de conhecimento e preço, para ajudar você a escolher o modelo de ponta com melhor custo-benefício.
O cenário dos modelos de IA em fevereiro de 2026 apresenta uma situação interessante: a verdadeira competição não é mais sobre "quem é o mais forte", mas sim "quem é o rei do custo-benefício". O Gemini 3.1 Pro da Google (lançado em 19 de fevereiro) e o Claude Sonnet 4.6 da Anthropic (lançado em 17 de fevereiro) chegaram quase ao mesmo tempo, com preços próximos e prometendo desempenho de nível flagship — a escolha para os desenvolvedores nunca foi tão difícil.
Valor central: Ao terminar de ler este artigo, você entenderá as diferenças reais entre os dois modelos em codificação, raciocínio, multimodalidade e trabalho de conhecimento, e saberá qual escolher para o seu cenário específico.
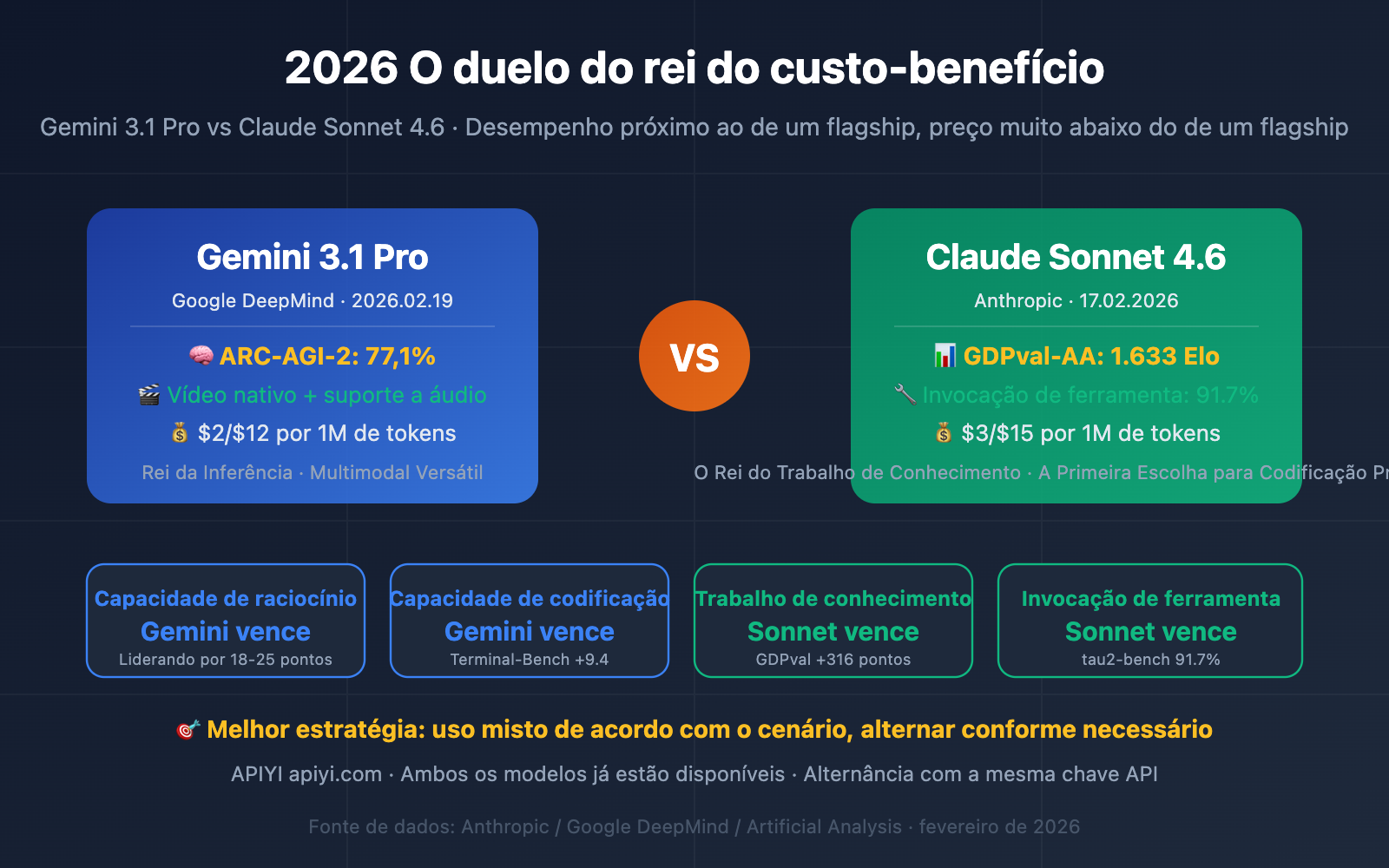
Comparação de Parâmetros Básicos: Gemini 3.1 Pro vs Claude Sonnet 4.6
O posicionamento de ambos os modelos é muito similar — são modelos de "alto desempenho próximo ao flagship, com preço muito inferior", mas com abordagens técnicas bem diferentes.
| Dimensão | Gemini 3.1 Pro | Claude Sonnet 4.6 | Observação |
|---|---|---|---|
| Data de lançamento | 19/02/2026 | 17/02/2026 | Apenas 2 dias de diferença |
| Janela de contexto | 1 Milhão (Padrão) | 200K Padrão / 1M Beta | Gemini com contexto milionário nativo |
| Saída máxima | 64K tokens | 64K tokens | Idênticos |
| Preço de entrada | $2/Milhão de Tokens | $3/Milhão de Tokens | ✅ Gemini 33% mais barato |
| Preço de saída | $12/Milhão de Tokens | $15/Milhão de Tokens | ✅ Gemini 20% mais barato |
| Preço entrada (longo) | $4 (>200K) | $3 (Inalterado) | ⚠️ Sonnet mais barato em contextos longos |
| Preço saída (longo) | $18 (>200K) | $15 (Inalterado) | ⚠️ Sonnet mais barato em contextos longos |
| Modalidades de entrada | Texto, Imagem, Áudio, Vídeo, PDF | Texto, Imagem, PDF | ✅ Gemini mais completo em multimodalidade |
| Modo de raciocínio | Três níveis (Baixo/Médio/Alto) | Raciocínio adaptativo (dinâmico) | Filosofias de design diferentes |
| Cache de comandos | Suportado | Leitura de cache por apenas $0.30/M (90% off) | ✅ Cache do Sonnet economiza mais |
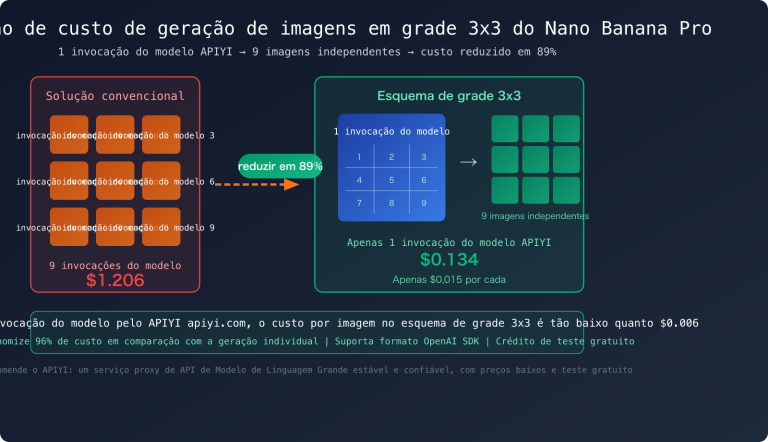
🎯 Detalhe crucial de preço: Em cenários comuns abaixo de 200K tokens, o Gemini 3.1 Pro é mais barato ($2/$12 vs $3/$15). No entanto, assim que o contexto ultrapassa 200K, o preço do Gemini sobe para $4/$18, tornando-se mais caro que os $3/$15 do Sonnet 4.6. O comprimento médio do seu contexto determinará qual é o mais econômico.
Comparativo Completo de Benchmarks: Gemini 3.1 Pro vs. Sonnet 4.6
Comparativo de Capacidade de Codificação
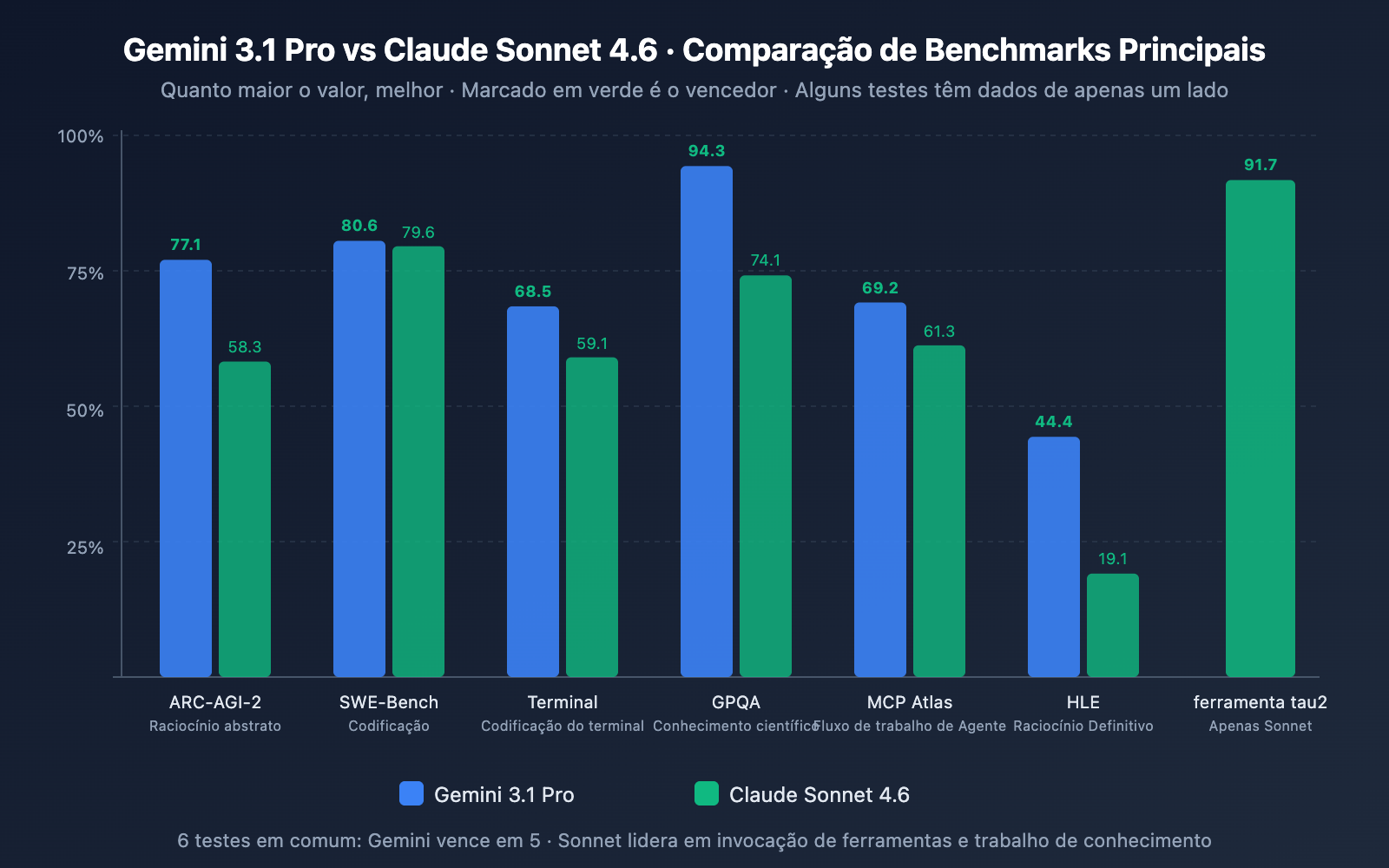
| Teste de Codificação | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vencedor |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 79.6% | ✅ Gemini (+1.0 pt) |
| SWE-Bench Pro | 54.2% | 42.7% | ✅ Gemini (+11.5 pts) |
| Terminal-Bench 2.0 | 68.5% | 59.1% | ✅ Gemini (+9.4 pts) |
Análise: O Gemini 3.1 Pro lidera em todos os três testes de codificação. Especialmente no SWE-Bench Pro (tarefas de código real mais complexas), a diferença chega a 11,5 pontos, e no Terminal-Bench (codificação em ambiente de terminal), a vantagem é de 9,4 pontos. No entanto, vale notar que o Sonnet 4.6 alcançou uma taxa de erro de 0% em testes internos de edição de código de produção da Replit e foi escolhido como o modelo base para o agente de codificação do GitHub Copilot — a experiência de codificação em ambientes de produção reais pode ser mais equilibrada do que os benchmarks sugerem.
Comparativo de Capacidade de Raciocínio
| Teste de Raciocínio | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vencedor |
|---|---|---|---|
| ARC-AGI-2 (Raciocínio Abstrato) | 77.1% | 58.3% | ✅ Gemini (+18.8 pts) |
| GPQA Diamond (Ciência) | 94.3% | 74.1% | ✅ Gemini (+20.2 pts) |
| HLE (Raciocínio de Alto Nível) | 44.4% | 19.1% | ✅ Gemini (+25.3 pts) |
| MATH-500 | – | 97.8% | Sonnet (Matemática superior) |
Análise: O raciocínio é a dimensão onde vemos a maior disparidade. O Gemini 3.1 Pro lidera com folga nos testes ARC-AGI-2, GPQA Diamond e HLE, com diferenças variando de 18 a 25 pontos. É importante ressaltar que as pontuações de raciocínio do Gemini 3.1 Pro foram obtidas em seu modo "High" do sistema de pensamento de três níveis, enquanto o pensamento adaptativo do Sonnet 4.6 não atinge a mesma profundidade de raciocínio que o Opus 4.6. Se o seu foco principal é raciocínio puro, o Gemini 3.1 Pro tem uma vantagem clara.
Trabalho de Conhecimento e Capacidades de Agente
| Teste | Gemini 3.1 Pro | Claude Sonnet 4.6 | Vencedor |
|---|---|---|---|
| GDPval-AA Elo (Trabalho Especializado) | 1.317 | 1.633 | ✅ Sonnet (+316 pts) |
| Finance Agent (Análise Financeira) | – | 63.3% | Sonnet (Dados superiores) |
| OSWorld (Controle de SO) | – | 72.5% | Sonnet (Dados superiores) |
| MCP Atlas (Fluxos Multi-etapa) | 69.2% | 61.3% | ✅ Gemini (+7.9 pts) |
| tau2-bench Retail (Uso de Ferramentas) | – | 91.7% | Sonnet (Dados superiores) |
Análise: Aqui temos a maior reviravolta. No GDPval-AA (que simula trabalho de conhecimento real em nível de especialista), o Sonnet 4.6, com 1.633 Elo, não apenas supera de longe o Gemini 3.1 Pro (1.317), mas também ultrapassa o próprio modelo topo de linha da Anthropic, o Opus 4.6 (1.559). Isso significa que em cenários de alto valor, como análise de pesquisa, redação de relatórios e estratégia de negócios, o Sonnet 4.6 é atualmente o melhor modelo disponível — superando até modelos que custam 5 vezes mais, como o Opus 4.6.
As vantagens e desvantagens dos dois modelos são muito complementares, por isso a escolha do cenário é mais importante do que decidir "qual é o melhor".

Cenários para escolher o Gemini 3.1 Pro
- Algoritmos e programação competitiva: Com um LiveCodeBench Elo de 2.887, ele possui uma liderança esmagadora em codificação algorítmica.
- Raciocínio complexo e pesquisa científica: ARC-AGI-2 77,1%, GPQA Diamond 94,3%. Sua capacidade de raciocínio puro está em outro patamar em relação ao Sonnet 4.6.
- Processamento multimodal: Suporte nativo para vídeo (1 hora) e áudio (8,4 horas), recursos que o Sonnet 4.6 não oferece.
- Fluxos de trabalho de Agentes MCP: MCP Atlas 69,2% (7,9 pontos à frente), sendo mais confiável na construção de sistemas de agentes multietapas.
- Invocação de alta frequência com contexto curto: Para janelas de até 200K, o preço de $2/$12 é a opção mais barata entre os dois.
Cenários para escolher o Claude Sonnet 4.6
- Trabalho de conhecimento de nível especialista: O GDPval-AA de 1.633 Elo é a pontuação mais alta entre todos os modelos atuais. Imbatível em relatórios de pesquisa, análise financeira e estratégia de negócios.
- Edição de código em produção: Taxa de erro de 0% em testes de ambiente de produção da Replit, escolhido pelo GitHub Copilot como base para agentes de codificação.
- Chamada de ferramentas e Computer Use: tau2-bench 91,7%, OSWorld 72,5%. Precisão altíssima em operações automatizadas e chamadas de função.
- Cenários de contexto longo: Para janelas acima de 200K, o preço de $3/$15 do Sonnet 4.6 é mais barato que os $4/$18 do Gemini.
- Aplicações de nível empresarial: Alinhamento de segurança mais maduro, cache de comandos (leitura a apenas $0,30/milhão de tokens, economia de 90%) e processamento em lote (batch) pela metade do preço.
Integração Rápida das APIs Gemini 3.1 Pro e Claude Sonnet 4.6
Exemplo Minimalista
Através da plataforma APIYI, os dois modelos utilizam uma interface unificada:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - Superior em raciocínio e multimodalidade
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Analise a complexidade de tempo deste código e otimize-o"}]
)
print(response.choices[0].message.content)
Ver exemplo de chamada do Sonnet 4.6 e alternância automática por cenário
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - Superior em trabalho de conhecimento e chamadas de ferramentas (tool calling)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Escreva um relatório de análise de mercado do Q1, incluindo comparação com concorrentes e sugestões de crescimento"}]
)
print(response.choices[0].message.content)
# Roteamento automático por cenário
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Sugestão: Através da plataforma APIYI (apiyi.com), você pode acessar ambos os modelos simultaneamente, alternando com a mesma chave API. A plataforma oferece créditos de teste gratuitos; recomendamos comparar os resultados no seu cenário real.
Comparação Profunda de Custos: Gemini 3.1 Pro vs. Sonnet 4.6
Estimativa de custo mensal baseada em três cenários típicos de uso:
| Cenário de Uso | Consumo Mensal de Tokens | Gemini 3.1 Pro | Claude Sonnet 4.6 | Opção Mais Barata |
|---|---|---|---|---|
| Uso Leve (5 mi entrada + 1 mi saída) | 6 milhões | $22 | $30 | Gemini economiza 27% |
| Uso Moderado (20 mi entrada + 5 mi saída) | 25 milhões | $100 | $135 | Gemini economiza 26% |
| Uso Intenso com Contexto Longo (50 mi entrada >200K + 10 mi saída) | 600 milhões | $380 | $300 | ⚠️ Sonnet economiza 21% |
🎯 Conclusão de Custos: Em uso convencional, o Gemini 3.1 Pro é cerca de 26%-27% mais barato. No entanto, se você utiliza frequentemente janelas de contexto longas acima de 200K (como análise de repositórios de código completos ou processamento de documentos extensos), o Sonnet 4.6 acaba saindo mais em conta — isso porque o preço do Gemini para contextos longos sobe para $4/$18, enquanto o Sonnet mantém $3/$15. Além disso, com o cache de comandos (Prompt Caching) do Sonnet (leitura a apenas $0,30/milhão de tokens), o custo real pode ser de 30% a 50% menor.
Ao acessar através da plataforma APIYI (apiyi.com), você pode aproveitar preços promocionais adicionais, reduzindo ainda mais o custo de uso de ambos os modelos.
Perguntas Frequentes
Q1: O GDPval-AA do Sonnet 4.6 é maior que o do próprio Opus 4.6, isso é normal?
Pois é, é isso mesmo. O Sonnet 4.6 alcançou 1.633 Elo no GDPval-AA, superando os .1559 do Opus 4.6. A própria Anthropic confirmou esses dados. O motivo provável é que o Sonnet 4.6 passou por uma otimização específica para cenários de trabalho de conhecimento corporativo, enquanto o Opus 4.6 é mais focado em raciocínio geral e processamento de contexto longo. A taxa de preferência dos desenvolvedores pelo Sonnet 4.6 também atingiu 70% (comparado ao Sonnet 4.5) e 59% (comparado ao Opus 4.5).
Q2: Qual modelo é melhor para criar AI Agents?
Depende do tipo de Agent. Se for um Agent de fluxo de trabalho de várias etapas baseado em MCP, o Gemini 3.1 Pro lidera com 69,2% no MCP Atlas (uma vantagem de 7,9 pontos). Se for um Agent intensivo em chamadas de ferramentas (como o OpenClaw), o Sonnet 4.6 é mais confiável com 91,7% no tau2-bench. Já para Agents do tipo "Computer Use" (que controlam navegador e desktop), o Sonnet 4.6 marcou 72,5% no OSWorld, um dos melhores resultados atuais. Ambos os modelos podem ser testados diretamente na plataforma APIYI (apiyi.com).
Q3: Atualmente uso o Sonnet 4.5, devo atualizar para o Sonnet 4.6 ou mudar para o Gemini 3.1 Pro?
Se você está satisfeito com a experiência de trabalho de conhecimento e codificação do Sonnet 4.5, atualizar para o Sonnet 4.6 é a escolha mais segura — a API é compatível, o preço é o mesmo e o desempenho melhorou em todos os aspectos (SWE-Bench subiu de 77,2% para 79,6%; ARC-AGI-2 saltou de 13,6% para 58,3%, um aumento de 4,3 vezes). Se suas necessidades principais pendem para raciocínio puro, multimodalidade ou codificação algorítmica, o Gemini 3.1 Pro tem vantagens significativas nessas áreas. Sugerimos testar ambos através da plataforma APIYI (apiyi.com).
Resumo
Conclusões principais entre Gemini 3.1 Pro e Claude Sonnet 4.6:
- Raciocínio e Multimodalidade: vá de Gemini 3.1 Pro: Liderança de 18,8 pontos no ARC-AGI-2 e 20,2 pontos no GPQA Diamond. Possui suporte nativo para vídeo/áudio e é mais barato em contextos curtos.
- Trabalho de Conhecimento e Codificação em Produção: vá de Claude Sonnet 4.6: O score de 1.633 Elo no GDPval-AA é o mais alto entre todos os modelos (incluindo o Opus 4.6). Taxa de erro de 0% no Replit e é a escolha preferida para o GitHub Copilot.
- Cenários de Contexto Longo: Sonnet é mais econômico: Acima de 200K de contexto, o Sonnet custa $3/$15 contra $4/$18 do Gemini. Com o uso de cache de comandos, é possível economizar de 30% a 50% adicionais.
Estes dois modelos são os de melhor custo-benefício entre os modelos de ponta em fevereiro de 2026. A melhor estratégia é usá-los de forma híbrida, dependendo do cenário. Recomendamos acessar ambos simultaneamente via APIYI (apiyi.com), alternando conforme a necessidade usando a mesma chave API.
📚 Referências
-
Anúncio de lançamento do Claude Sonnet 4.6: Blog oficial da Anthropic
- Link:
anthropic.com/news/claude-sonnet-4-6 - Descrição: Apresentação completa das funcionalidades do Sonnet 4.6, dados de benchmark e o recurso de pensamento adaptativo.
- Link:
-
Blog oficial do Gemini 3.1 Pro: Anúncio de lançamento do Google DeepMind
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Descrição: O sistema de pensamento em três níveis do Gemini 3.1 Pro e dados completos de desempenho.
- Link:
-
Teste comparativo do Tom's Guide: 7 desafios reais testando Gemini 3.1 Pro vs Sonnet 4.6
- Link:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Descrição: Comparação de desempenho prático em cenários de tarefas reais.
- Link:
-
Ranking da Artificial Analysis: Plataforma independente de avaliação de modelos
- Link:
artificialanalysis.ai/leaderboards/models - Descrição: Dados objetivos de comparação lateral de desempenho, velocidade e preço.
- Link:
Autor: Equipe Técnica
Troca de Conhecimento: Sinta-se à vontade para compartilhar sua experiência nos comentários. Para mais notícias sobre modelos de IA, visite APIYI em apiyi.com