저자 주: Gemini Nano Banana Pro API의 overloaded 및 service unavailable 오류에 대한 심층 분석입니다. 오류 발생 원인, 시간대별 규칙, 실전 해결 방법 및 프로덕션 환경의 베스트 프렉티스를 포함하고 있습니다.
2026년 1월 16일 새벽 0시 18분, 많은 개발자가 Gemini Nano Banana Pro API(모델명 gemini-3-pro-image-preview) 사용 중 「The model is overloaded. Please try again later.」 또는 「The service is currently unavailable.」 오류를 보고했습니다. 이는 코드의 문제가 아니라 Google 서버 측의 연산 용량 병목 현상으로 인해 발생하는 시스템적인 장애입니다.
핵심 가치: 이 글을 읽고 나면, 이 두 가지 오류 유형의 근본 원인과 시간적 규칙, 기술적 메커니즘을 이해하게 될 것입니다. 또한 5가지 실전 해결책을 익히고 프로덕션 수준의 결함 허용(fault-tolerant) 전략을 구축하는 방법을 배우게 됩니다.
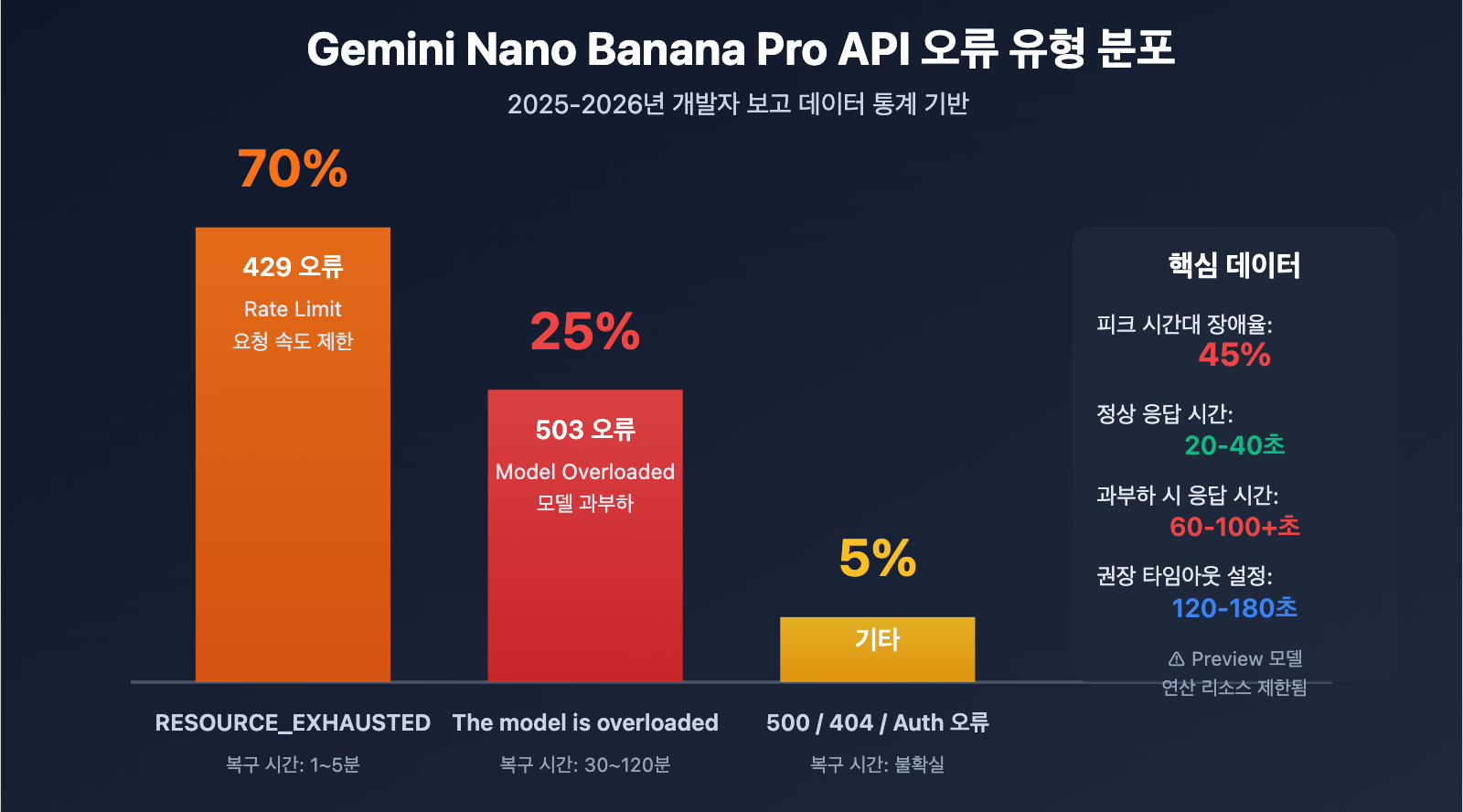
Gemini Nano Banana Pro API 오류 핵심 요점
| 요점 | 설명 | 영향 |
|---|---|---|
| 503 Overloaded 오류 | 서버 측 연산 리소스 부족, 코드 문제 아님 | 피크 시간대 API 호출의 45% 실패 가능성 |
| 503 vs 429 오류 | 503은 용량 문제, 429는 속도 제한 | 503 복구에 30 |
| Preview 모델 제한 | Gemini 3 시리즈는 여전히 프리뷰 단계 | 연산 리소스가 제한적이며 동적 용량 관리가 불안정함 |
| 시간적 규칙성 | 한국 시간 새벽 및 밤 피크 시간대에 장애율 최고 | 피크 시간대를 피하거나 폴백 전략 구현 필요 |
| 응답 시간 급증 | 정상 시 20 |
더 긴 타임아웃 설정 필요 (120s+) |
Gemini Nano Banana Pro 오류 중점 해설
Nano Banana Pro란 무엇인가요?
Gemini Nano Banana Pro는 Google의 최고 품질 이미지 생성 모델로, API 모델명은 gemini-2.0-flash-preview-image-generation 또는 gemini-3-pro-image-preview입니다. Gemini 3 시리즈의 플래그십 이미지 생성 모델로서 이미지 품질, 디테일 복원, 텍스트 렌더링 등에서 Gemini 2.5 Flash Image보다 훨씬 뛰어나지만, 그만큼 더 심각한 연산 리소스 병목 현상에 직면해 있습니다.
왜 빈번하게 오류가 발생하나요?
Google AI 개발자 포럼의 논의 데이터에 따르면, Nano Banana Pro의 오류 문제는 2025년 하반기부터 빈번해지기 시작하여 2026년 초까지도 완전히 해결되지 않은 상태입니다. 주요 원인은 다음과 같습니다:
- 프리뷰 단계의 리소스 제한: Gemini 3 시리즈 모델은 여전히 Pre-GA(일반 공개 전) 단계에 있어, Google이 할당한 연산 리소스가 제한적입니다.
- 동적 용량 관리: 사용자의 요청 속도 제한(Rate Limit)에 도달하지 않았더라도, 시스템 전체 부하가 너무 높으면 503 오류를 반환할 수 있습니다.
- 전 세계 사용자의 경쟁: 모든 개발자가 동일한 연산 리소스 풀을 공유하므로, 피크 시간대에는 수요가 공급을 훨씬 초과합니다.
- 연산 집약적 모델: 고품질 이미지 생성에는 막대한 GPU 연산이 필요하며, 단일 요청당 20~40초가 소요되어 텍스트 모델보다 훨씬 긴 시간이 걸립니다.
503 vs 429 오류의 차이점
| 오류 유형 | HTTP 상태 코드 | 오류 메시지 | 근본 원인 | 복구 시간 | 비중 |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
서버 측 연산 용량 부족 | 30~120분 | 약 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
사용자 할당량 초과 (RPM/TPM/RPD) | 1~5분 | 약 70% |
| Unavailable | 503 | Service unavailable |
시스템 장애 또는 점검 | 불확실 (수 시간 가능) | 약 5% |
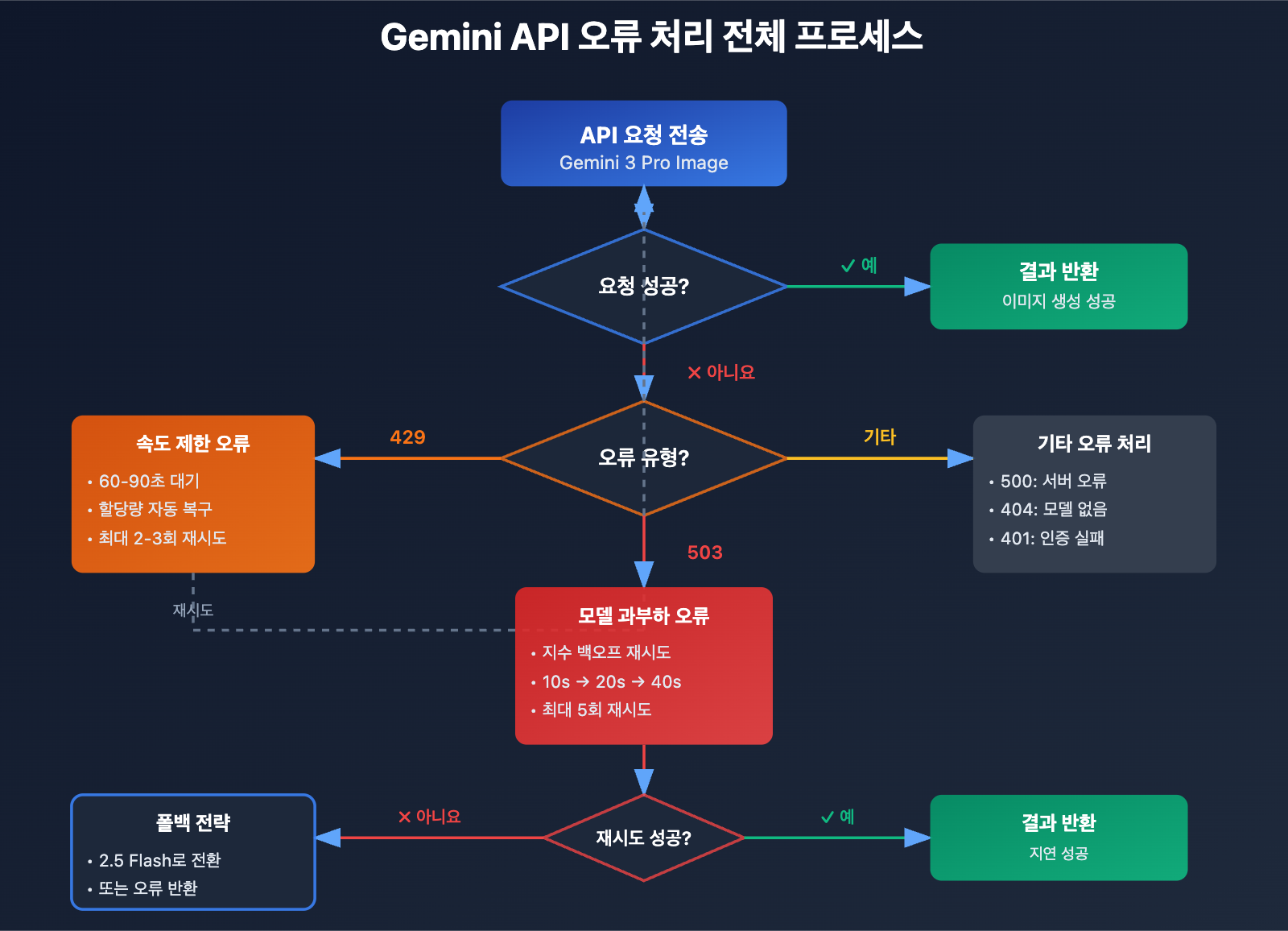
Gemini Nano Banana Pro 오류 발생 시간대 패턴 분석
주요 장애 시간대
여러 개발자의 보고 데이터에 따르면, Nano Banana Pro API의 장애 발생에는 뚜렷한 시간적 규칙이 있습니다.
한국 시간(KST) 기준 고위험 시간대:
- 01:00 – 03:00: 미국 서부 해안 업무 시간 (08:00-10:00 PST), 서구권 개발자 이용 피크
- 10:00 – 12:00: 아시아 지역 업무 시작 시간, 아시아 개발자 이용 피크
- 21:00 – 00:00: 아시아 저녁 피크 + 유럽 오후 시간대 중첩
상대적 안정 시간대:
- 04:00 – 09:00: 글로벌 사용자가 가장 적은 시간대
- 15:00 – 18:00: 아시아 오후 + 미국 심야 시간대, 부하가 낮은 편
사례 검증: 2026년 1월 16일 새벽 01:18(한국 시간)에 발생한 대규모 장애는 미국 서부 시간으로 출근 시간인 1월 15일 08:18 PST와 정확히 일치하여, 이러한 시간대별 패턴의 정확성을 뒷받침해 줍니다.
Gemini Nano Banana Pro 오류를 해결하는 5가지 방법
방법 1: 지수 백오프(Exponential Backoff) 재시도 전략 구현
이 방법은 503 오류에 대응하는 가장 기초적인 솔루션입니다. 아래는 권장하는 재시도 로직입니다.
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
지수 백오프가 적용된 이미지 생성 함수
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # 타임아웃 시간 증가
)
return response
except Exception as e:
error_msg = str(e)
# 503 오류: 지수 백오프로 재시도
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ 모델 과부하, {delay:.1f}초 후 재시도 (시도 {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ 최대 재시도 횟수 도달, 모델 과부하 상태 지속")
# 429 오류: 짧게 대기 후 재시도
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ 속도 제한(Rate Limit), 60초 후 재시도")
time.sleep(60)
continue
# 기타 오류: 즉시 예외 발생
else:
raise e
raise Exception("❌ 모든 재시도가 실패했습니다")
# 사용 예시
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
프로덕션급 전체 코드 보기
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
프로덕션급 Gemini 이미지 생성 클라이언트
재시도, 폴백(Fallback), 모니터링 지원
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
폴백 전략이 포함된 이미지 생성
"""
# 메인 모델 시도
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ 메인 모델 {primary_model} 실패: {str(e)}")
# 예비 모델로 자동 폴백
try:
print(f"🔄 예비 모델 {fallback_model}(으)로 전환")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""내부 재시도 로직"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""통계 데이터 가져오기"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# 사용 예시
client = GeminiImageClient(api_key="YOUR_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ 생성 성공, 사용된 모델: {result['model_used']}")
else:
print(f"❌ 생성 실패: {result['error']}")
# 통계 확인
print(client.get_stats())
기술 제언: 실제 프로덕션 환경에서는 APIYI(apiyi.com) 플랫폼을 통해 API를 호출하는 것을 권장합니다. 이 플랫폼은 통합 API 인터페이스를 제공하며 Gemini 3 Pro를 포함한 다양한 이미지 생성 모델을 지원합니다. Nano Banana Pro가 과부하 상태일 때 Gemini 2.5 Flash나 다른 예비 모델로 빠르게 전환할 수 있어 비즈니스 연속성을 보장할 수 있습니다.
방법 2: 타임아웃 시간 및 요청 설정 최적화
Nano Banana Pro의 정상 응답 시간은 2040초이지만, 부하가 걸릴 경우 60100초 또는 그 이상이 소요될 수 있습니다. 기본 설정인 30초 타임아웃은 많은 경우 오판으로 이어질 수 있습니다.
권장 설정:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # 글로벌 타임아웃을 120초로 증가
max_retries=3 # SDK 차원에서 3회 자동 재시도
)
# 또는 개별 요청에서 지정
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Your prompt here",
timeout=150 # 단일 요청 타임아웃 150초
)
주요 파라미터 설명:
timeout: 단일 요청의 최대 대기 시간, 120~180초 설정을 권장합니다.max_retries: SDK 레벨의 자동 재시도 횟수, 2~3회를 권장합니다.keep_alive: 연결을 활성 상태로 유지하여 장시간 요청이 중단되는 것을 방지합니다.
방법 3: 피크 시간대 피하기
비즈니스 성격상 비동기 처리가 가능하다면, 시간대별 패턴에 따라 작업을 예약하여 성공률을 크게 높일 수 있습니다.
권장 스케줄링 전략:
- 높은 우선순위 작업: 한국 시간 04:00-09:00 또는 15:00-18:00 사이에 배치
- 배치(Batch) 생성 작업: 작업 큐를 사용하여 부하가 낮은 시간대에 자동 실행
- 실시간 작업: 반드시 폴백 전략을 구현해야 하며, 단일 모델에만 의존해서는 안 됩니다.
Python 작업 스케줄링 예시:
from datetime import datetime
def is_peak_hour() -> bool:
"""현재가 피크 시간대인지 판단 (한국 시간 기준)"""
current_hour = datetime.now().hour
# 피크 시간대: 1-3, 10-12, 21-00
peak_hours = list(range(1, 4)) + list(range(10, 13)) + [21, 22, 23, 0]
return current_hour in peak_hours
def smart_generate(prompt: str):
"""지능형 생성: 피크 시간대 자동 폴백"""
if is_peak_hour():
print("⚠️ 현재 피크 시간대이므로 예비 모델을 사용합니다.")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
방법 4: 모델 폴백(Fallback) 전략 구현
Google 공식 가이드에서도 과부하 발생 시 Gemini 2.5 Flash로 전환할 것을 제안하고 있습니다. 아래는 두 모델의 비교 데이터입니다.
| 지표 | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| 이미지 품질 | 최고 수준 (9/10) | 우수함 (7.5/10) |
| 생성 속도 | 20-40초 | 10-20초 |
| 안정성 | 피크 타임 실패율 약 45% | 피크 타임 실패율 < 10% |
| 503 복구 시간 | 30-120분 | 5-15분 |
| API 비용 | 높은 편 | 낮은 편 |
전략 제안: 품질이 중요한 시나리오(마케팅 포스터, 제품 이미지 등)에서는 Gemini 3 Pro를 우선 사용하되, 실패 시 2.5 Flash로 폴백합니다. 높은 동시 접속이 필요한 시나리오(UGC 콘텐츠, 빠른 프로토타이핑)에서는 처음부터 2.5 Flash를 사용하여 안정성을 높이는 것이 좋습니다. APIYI(apiyi.com) 플랫폼을 통해 모델별 비교 테스트를 진행해 보세요. 원클릭 모델 전환은 물론 비용 및 품질 비교 데이터를 제공합니다.
방법 5: 모니터링 및 알림 시스템 구축
프로덕션 환경에서는 장애를 즉시 발견하고 대응할 수 있도록 완벽한 모니터링이 필수적입니다.
주요 모니터링 지표:
- 성공률: 최근 5분 / 1시간 / 24시간 동안의 성공률
- 응답 시간: P50 / P95 / P99 응답 시간
- 오류 분포: 503 / 429 / 500 등 오류 코드별 비중
- 폴백 트리거 횟수: 메인 모델 실패로 인해 폴백이 발생한 횟수
간단한 모니터링 구현 예시:
from collections import deque
from datetime import datetime
class APIMonitor:
"""API 호출 모니터링 도구"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""API 호출 기록"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""성공률 계산"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""알림 발생 여부 판단"""
success_rate = self.get_success_rate()
# 성공률이 70% 미만일 때 알림 트리거
if success_rate < 70:
return True
# 503 오류 비중이 전체 오류의 30%를 초과할 때 알림 트리거
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# 사용 예시
monitor = APIMonitor(window_size=100)
# 매 호출 후 기록
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# 정기적인 알림 체크
if monitor.should_alert():
print(f"🚨 알림: API 성공률이 {monitor.get_success_rate():.2f}%로 하락했습니다!")
Gemini API 할당량 및 속도 제한 상세 가이드
2025년 12월 할당량 조정 내역
2025년 12월 7일, Google이 Gemini API의 할당량(Quota) 제한을 조정하면서 많은 개발자가 예상치 못한 429 오류를 겪고 있습니다.
현재 할당량 기준 (2026년 1월):
| 할당량 항목 | 무료 등급 (Free Tier) | 유료 등급 Tier 1 | 설명 |
|---|---|---|---|
| RPM (분당 요청 수) | 5-15 (모델에 따라 다름) | 150-300 | Gemini 3 Pro는 더 엄격하게 제한됨 |
| TPM (분당 토큰 수) | 32,000 | 4,000,000 | 텍스트 모델 적용 |
| RPD (일일 요청 수) | 1,500 | 10,000+ | 공유 할당량 풀 사용 |
| IPM (분당 이미지 수) | 5-10 | 50-100 | 이미지 생성 모델 전용 |
꼭 확인해야 할 주의 사항:
- 할당량 제한은 개별 API 키가 아닌 Google Cloud 프로젝트(Project) 레벨을 기준으로 적용됩니다.
- 동일한 프로젝트 내에서 API 키를 여러 개 생성해도 전체 할당량은 늘어나지 않습니다.
- 어떤 항목이든 제한을 초과하면 즉시 429 오류가 발생합니다.
- 토큰 버킷(Token Bucket) 알고리즘을 통해 강제 적용되므로, 일시적으로 트래픽이 몰리는 '버스트(Burst)' 상황에서는 제한될 수 있습니다.
비용 최적화 팁: 예산이 민감한 프로젝트라면 APIYI(apiyi.com) 플랫폼을 통해 Gemini API를 호출하는 것도 좋은 방법입니다. 이 플랫폼은 별도의 Google Cloud 구독 없이도 유연한 종량제 방식을 제공하여, 중소 규모 팀이나 개인 개발자가 빠르게 테스트하고 소규모로 배포하기에 적합합니다.
자주 묻는 질문 (FAQ)
Q1: 503 overloaded와 429 rate limit 오류를 어떻게 구분하나요?
두 오류는 발생 원인과 복구 시간에서 큰 차이가 있습니다.
503 Overloaded (서버 과부하):
- 오류 메시지:
The model is overloaded. Please try again later. - HTTP 상태 코드: 503 Service Unavailable
- 발생 원인: 사용자의 할당량과는 관계없이 Google 서버 자체의 계산 자원이 부족할 때 발생합니다.
- 복구 시간: 약 30
120분 (Gemini 3 Pro), 515분 (Gemini 2.5 Flash) - 대응 전략: 지수 백오프(Exponential Backoff)를 적용해 재시도하거나, 예비 모델로 전환, 또는 피크 시간대를 피해서 사용하세요.
429 Rate Limit (속도 제한):
- 오류 메시지:
RESOURCE_EXHAUSTED또는Rate limit exceeded - HTTP 상태 코드: 429 Too Many Requests
- 발생 원인: 사용자의 API 호출이 할당량 제한(RPM/TPM/RPD/IPM)을 초과했을 때 발생합니다.
- 복구 시간: 1~5분 (할당량 풀이 자동으로 회복됨)
- 대응 전략: 요청 빈도를 낮추거나, 유료 등급으로 업그레이드, 또는 할당량 증설을 요청하세요.
빠른 판단 방법: Google AI Studio에서 할당량 사용 현황을 확인해 보세요. 상한선에 도달했다면 429 오류이고, 그렇지 않다면 503 오류일 가능성이 높습니다.
Q2: 왜 새벽 00:18에 대규모 장애가 자주 발생하나요?
2026년 1월 16일 베이징 시간 기준 새벽 00:18에 발생한 대규모 장애는 미국 서부 시간(PST)으로 1월 15일 08:18에 해당하며, 이는 미국 내 업무가 본격적으로 시작되는 시간대와 일치합니다.
시간대별 부하 분석:
- 미국 서부(실리콘밸리) 개발자 업무 시작: 08:00
10:00 PST (한국 시간 기준 01:0003:00) - 유럽 개발자 업무 피크: 14:00
18:00 CET (한국 시간 기준 22:0002:00) - 아시아권 개발자 활동 시간: 오전 및 저녁 피크 타임
이처럼 여러 지역의 사용 시간이 겹치는 시간대에는 Nano Banana Pro API의 부하가 처리 용량을 훨씬 초과하게 되어 대규모 503 오류가 발생하기 쉽습니다.
권장 사항: 만약 배치 작업(Batch Task)을 수행해야 한다면, 전 세계적으로 부하가 가장 적은 한국 시간 기준 04:00~09:00 사이로 스케줄링하는 것이 가장 안정적입니다.
Q3: 프로덕션 환경에서는 어떤 모델을 선택해야 할까요?
비즈니스 요구 사항에 따라 다음과 같은 모델 전략을 추천합니다.
전략 1: 품질 우선 (마케팅, 제품 이미지 생성 등)
- 주 모델: Gemini 3 Pro Image Preview (Nano Banana Pro)
- 예비 모델: Gemini 2.5 Flash Image
- 구현 방식: 주 모델 호출 실패 시 3회 재시도 후 자동으로 예비 모델로 전환(Fallback)
- 기대 성공률: 약 92~95% (다운그레이드 포함)
전략 2: 안정성 우선 (UGC, 높은 동시성 처리)
- 주 모델: Gemini 2.5 Flash Image
- 예비 모델: 타사 이미지 생성 모델 (DALL-E 3, Stable Diffusion XL 등)
- 구현 방식: 기본적으로 2.5 Flash를 사용하고, 장애 발생 시 즉시 제3의 모델로 전환
- 기대 성공률: 약 95~98%
전략 3: 비용 우선 (테스트, 프로토타입 개발)
- 무료 버전 Gemini 2.5 Flash 사용
- 간헐적인 429 및 503 오류 감수
- 복잡한 예외 처리 로직은 생략 가능
추천 솔루션: APIYI(apiyi.com) 플랫폼을 사용하면 다양한 모델의 효과와 비용을 빠르게 테스트할 수 있습니다. 통합 인터페이스를 통해 여러 이미지 생성 모델을 호출할 수 있어, 상황에 맞는 모델 비교와 전환이 매우 간편합니다.
요약
Gemini Nano Banana Pro API 오류의 핵심 포인트는 다음과 같습니다.
- 503 Overloaded는 시스템적인 문제입니다: 여러분의 코드 오류가 아니라 Google 서버 측의 컴퓨팅 자원 부족으로 인해 발생하는 현상입니다. 피크 시간대에는 호출의 약 45%가 실패할 수 있습니다.
- 뚜렷한 시간대별 패턴: 베이징 시간 기준 00:00
02:00, 09:0011:00, 20:00~23:00는 장애 위험이 높은 시간대입니다. 이 시간을 피해서 작업을 수행하거나 대체 전략을 마련해야 합니다. - 결함 허용(Fault Tolerance) 구현이 필수입니다: 지수 백오프(Exponential Backoff) 재시도, 타임아웃 시간 연장(120초 이상), 모델 강등(2.5 Flash를 예비용으로 사용) 등 3단계 방어 체계를 반드시 구축해야 합니다.
- 모니터링과 알림: 운영 환경에서는 성공률, 응답 시간, 오류 분포를 반드시 모니터링하여 장애를 즉시 감지하고 대응해야 합니다.
- 할당량 제한 이해: 429 오류는 사용자의 API 할당량과 관련이 있고, 503 오류는 Google의 전체 부하와 관련이 있습니다. 이 두 가지는 대응 전략이 서로 다릅니다.
Nano Banana Pro는 현재 프리뷰 단계 모델이기에 안정성 문제를 단기간에 근본적으로 해결하기는 어렵습니다. 이미지 생성 요구 사항을 빠르게 검증하고 싶다면 **APIYI(apiyi.com)**를 활용해 보시는 것을 추천합니다. 이 플랫폼은 무료 크레딧과 통합 인터페이스를 제공하며 Gemini 3 Pro, Gemini 2.5 Flash, DALL-E 3 등 주요 이미지 생성 모델을 모두 지원하여 비즈니스 연속성을 보장해 줍니다.
📚 참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는
자료명: domain.com형식을 사용합니다. 복사해서 사용하기 편리하지만, SEO 점수 유지를 위해 직접 클릭 이동은 지원하지 않습니다.
-
Nano Banana Errors & Troubleshooting Guide: 전체 오류 해결 가이드
- 링크:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - 설명: 429, 502, 403, 500 등 모든 Nano Banana Pro 오류 코드에 대한 종합적인 솔루션을 담고 있습니다.
- 링크:
-
Google AI 개발자 포럼: Gemini 3 Pro overloaded 오류 논의
- 링크:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - 설명: 503 오류에 대한 개발자 커뮤니티의 실시간 논의와 경험 공유를 확인할 수 있습니다.
- 링크:
-
Gemini API Rate Limits 공식 문서: 할당량 및 속도 제한 안내
- 링크:
ai.google.dev/gemini-api/docs/rate-limits - 설명: RPM/TPM/RPD/IPM에 대한 상세 설명을 포함한 Google 공식 API 할당량 문서입니다.
- 링크:
-
Gemini 3 Pro Image Preview Error Codes: 오류 코드 상세 가이드
- 링크:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - 설명: 2025~2026년 Gemini 3 Pro의 모든 오류 코드에 대한 원인 파악 및 해결 방법을 제공합니다.
- 링크:
작성자: 기술 팀
기술 교류: 댓글을 통해 Gemini API 사용 경험을 나누어 주세요. 더 많은 문제 해결 자료는 APIYI(apiyi.com) 기술 커뮤니티에서 확인하실 수 있습니다.