作者注:深度解析 Gemini Nano Banana Pro API 的 overloaded 和 service unavailable 错误,包括报错原因、时间规律、实战解决方案和生产环境最佳实践
2026 年 1 月 16 日凌晨 00:18,大量开发者报告 Gemini Nano Banana Pro API (模型名 gemini-3-pro-image-preview) 出现 「The model is overloaded. Please try again later.」 甚至 「The service is currently unavailable.」 错误。这并非代码问题,而是 Google 服务端计算容量瓶颈导致的系统性故障。
核心价值: 读完本文,你将理解这两类报错的根本原因、时间规律和技术机制,掌握 5 种实战解决方案,并学会构建生产级容错策略。
Gemini Nano Banana Pro API 报错核心要点
| 要点 | 说明 | 影响 |
|---|---|---|
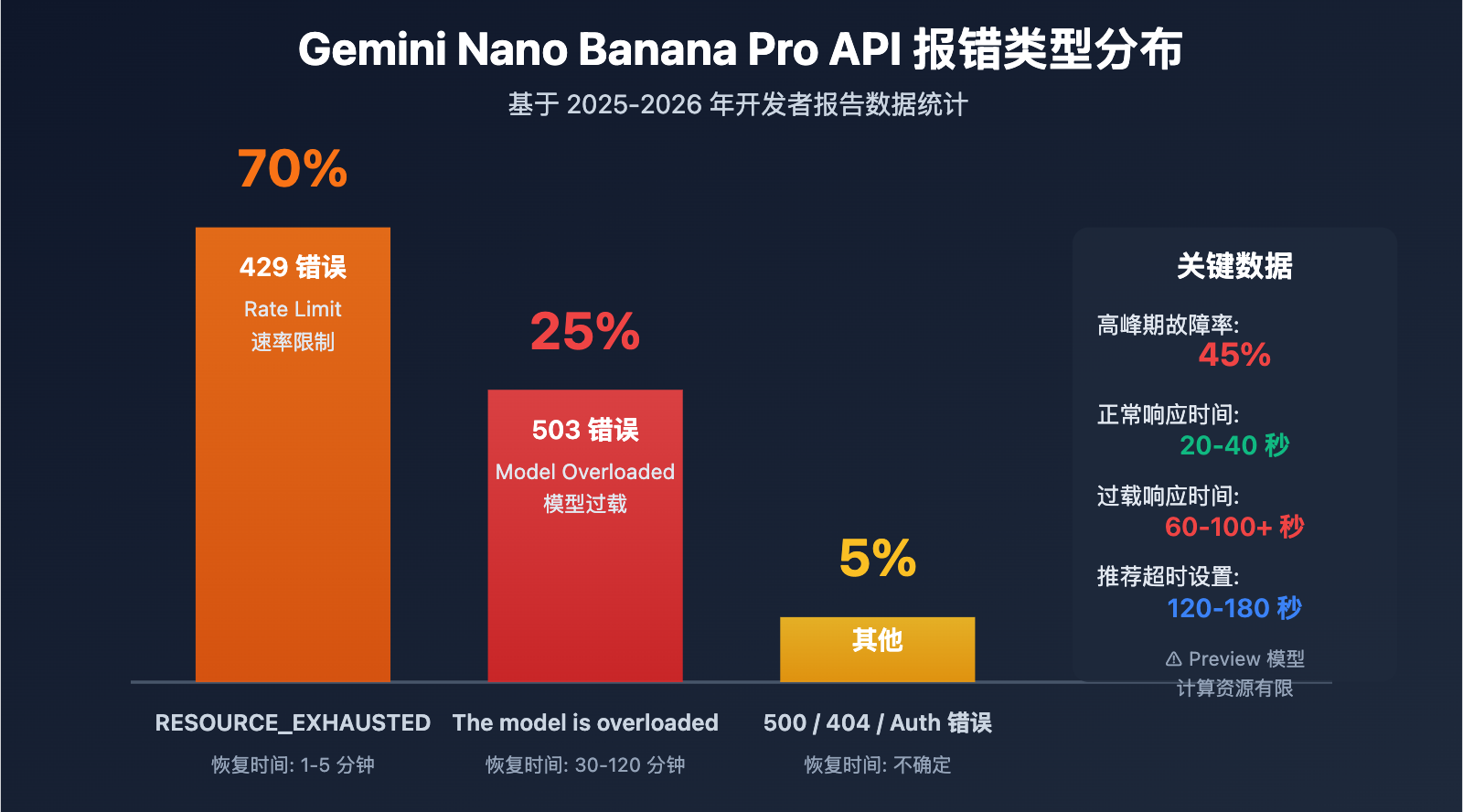
| 503 Overloaded 错误 | 服务端计算资源不足,非代码问题 | 高峰期 45% 的 API 调用会失败 |
| 503 vs 429 错误 | 503 是容量问题,429 是速率限制 | 503 恢复需 30-120 分钟,429 仅需 1-5 分钟 |
| Preview 模型限制 | Gemini 3 系列仍处于预览阶段 | 计算资源有限,动态容量管理不稳定 |
| 时间规律性 | 北京时间凌晨和晚高峰故障率最高 | 需避开高峰期或实现降级策略 |
| 响应时间激增 | 正常 20-40 秒,故障时 60-100+ 秒 | 需设置更长的超时时间 (120s+) |
Gemini Nano Banana Pro 报错重点详解
什么是 Nano Banana Pro?
Gemini Nano Banana Pro 是 Google 最高质量的图像生成模型,对应的 API 模型名为 gemini-3-pro-image-preview。作为 Gemini 3 系列的旗舰图像生成模型,它在图像质量、细节还原、文字渲染等方面显著优于 Gemini 2.5 Flash Image,但也因此面临更严重的计算资源瓶颈。
为什么频繁报错?
根据 Google AI 开发者论坛的讨论数据,Nano Banana Pro 的报错问题从 2025 年下半年开始频繁出现,至 2026 年初仍未完全解决。核心原因包括:
- 预览阶段资源限制: Gemini 3 系列模型仍处于 Pre-GA (General Availability 之前) 阶段,Google 分配的计算资源有限
- 动态容量管理: 即使未达到速率限制 (Rate Limit),系统也可能因整体负载过高返回 503 错误
- 全球用户竞争: 所有开发者共享同一计算资源池,高峰期需求远超供给
- 模型计算密集: 高质量图像生成需要大量 GPU 计算,单次请求耗时 20-40 秒,远超文本模型
503 vs 429 错误的区别
| 错误类型 | HTTP 状态码 | 错误信息 | 根本原因 | 恢复时间 | 占比 |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
服务端计算容量不足 | 30-120 分钟 | 约 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
超过用户配额 (RPM/TPM/RPD) | 1-5 分钟 | 约 70% |
| Unavailable | 503 | Service unavailable |
系统性故障或维护 | 不确定 (可能数小时) | 约 5% |
Gemini Nano Banana Pro 报错时间规律分析
高峰故障时段
根据多位开发者的报告数据,Nano Banana Pro API 的故障存在明显的时间规律:
北京时间高风险时段:
- 00:00 – 02:00: 美国西海岸工作时间 (08:00-10:00 PST),欧美开发者高峰
- 09:00 – 11:00: 中国大陆工作开始时间,亚洲开发者高峰
- 20:00 – 23:00: 中国大陆晚高峰 + 欧洲下午时段叠加
相对稳定时段:
- 03:00 – 08:00: 全球用户最少时段
- 14:00 – 17:00: 中国下午 + 美国深夜,负载较低
案例验证: 2026 年 1 月 16 日凌晨 00:18 的大规模故障,正好处于美国西海岸上班时间 (1 月 15 日 08:18 PST),印证了时间规律的准确性。

5 种解决 Gemini Nano Banana Pro 报错的方法
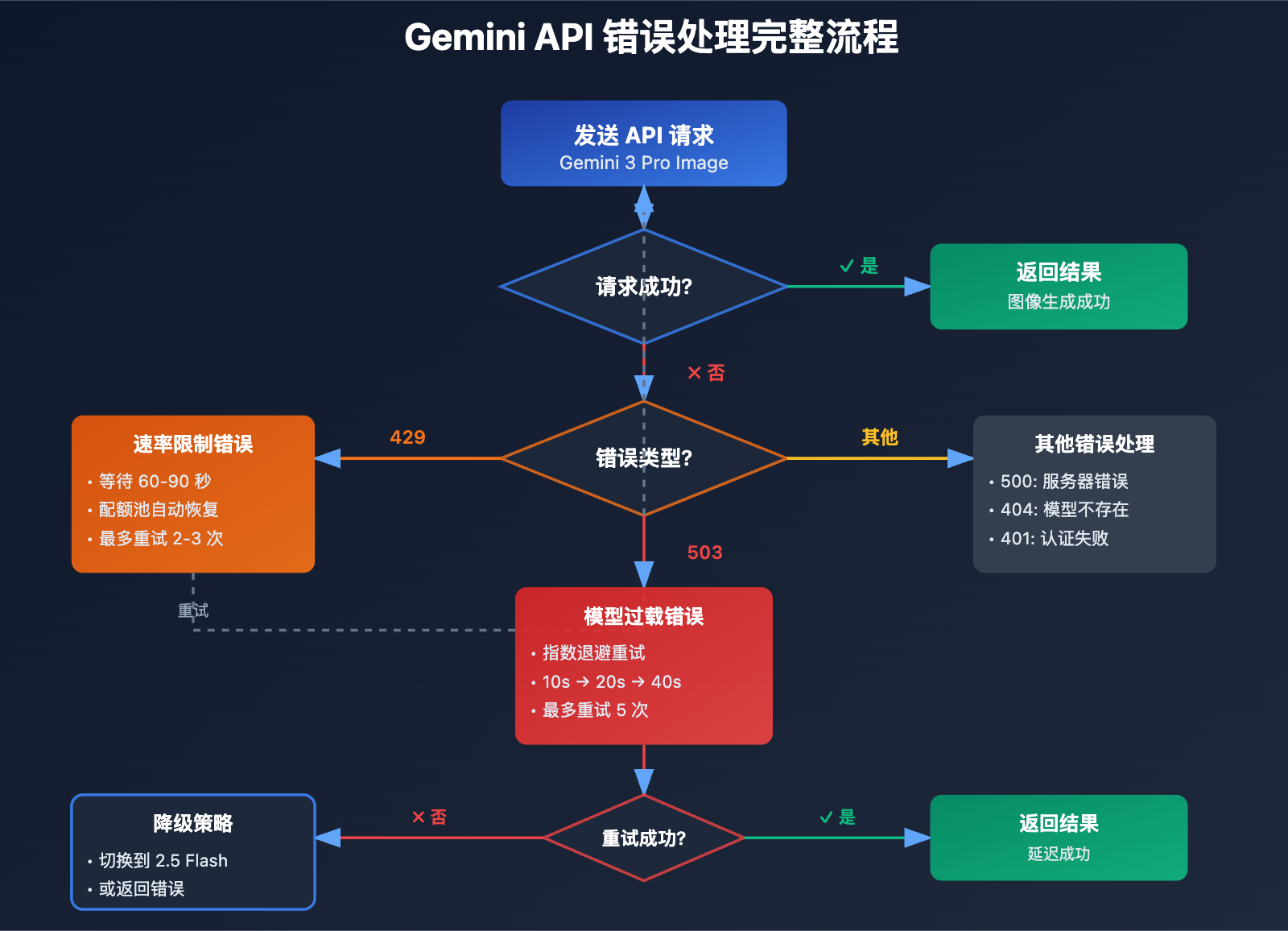
方法 1: 实现指数退避重试策略
这是应对 503 错误的最基础方案。以下是推荐的重试逻辑:
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
带指数退避的图像生成函数
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # 增加超时时间
)
return response
except Exception as e:
error_msg = str(e)
# 503 错误: 指数退避重试
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ 模型过载,{delay:.1f}秒后重试 (尝试 {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ 达到最大重试次数,模型持续过载")
# 429 错误: 短暂等待重试
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ 速率限制,60秒后重试")
time.sleep(60)
continue
# 其他错误: 直接抛出
else:
raise e
raise Exception("❌ 所有重试均失败")
# 使用示例
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
查看生产级完整代码
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
生产级 Gemini 图像生成客户端
支持重试、降级、监控
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
带降级策略的图像生成
"""
# 尝试主模型
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ 主模型 {primary_model} 失败: {str(e)}")
# 自动降级到备用模型
try:
print(f"🔄 降级到备用模型 {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""内部重试逻辑"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""获取统计数据"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# 使用示例
client = GeminiImageClient(api_key="YOUR_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ 生成成功,使用模型: {result['model_used']}")
else:
print(f"❌ 生成失败: {result['error']}")
# 查看统计
print(client.get_stats())
技术建议: 在实际生产环境中,建议通过 API易 apiyi.com 平台进行接口调用。该平台提供统一的 API 接口,支持 Gemini 3 Pro 和多种图像生成模型,当 Nano Banana Pro 过载时可快速切换到 Gemini 2.5 Flash 或其他备用模型,确保业务连续性。
方法 2: 增加超时时间和请求配置
Nano Banana Pro 的正常响应时间为 20-40 秒,但在过载时可能达到 60-100 秒甚至更长。默认的 30 秒超时设置会导致大量误判。
推荐配置:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # 增加全局超时到 120 秒
max_retries=3 # SDK 自动重试 3 次
)
# 或在单次请求中指定
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Your prompt here",
timeout=150 # 单次请求超时 150 秒
)
关键参数说明:
timeout: 单次请求的最大等待时间,建议设置为 120-180 秒max_retries: SDK 层面的自动重试次数,建议 2-3 次keep_alive: 保持连接活跃,避免长请求中断
方法 3: 避开高峰时段
如果业务允许异步处理,根据时间规律调度任务可显著提高成功率:
推荐调度策略:
- 高优先级任务: 部署在北京时间 03:00-08:00 或 14:00-17:00
- 批量生成任务: 使用任务队列在低峰期自动执行
- 实时任务: 必须实现降级策略,不能依赖单一模型
Python 任务调度示例:
from datetime import datetime
def is_peak_hour() -> bool:
"""判断当前是否为高峰时段 (北京时间)"""
current_hour = datetime.now().hour
# 高峰时段: 0-2, 9-11, 20-23
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""智能生成: 高峰期自动降级"""
if is_peak_hour():
print("⚠️ 当前为高峰时段,使用备用模型")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
方法 4: 实现模型降级策略
Google 官方建议在遇到过载时切换到 Gemini 2.5 Flash。以下是对比数据:
| 指标 | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| 图像质量 | 最高 (9/10) | 优秀 (7.5/10) |
| 生成速度 | 20-40 秒 | 10-20 秒 |
| 稳定性 | 高峰期 45% 失败率 | 高峰期 <10% 失败率 |
| 503 恢复时间 | 30-120 分钟 | 5-15 分钟 |
| API 成本 | 较高 | 较低 |
方案建议: 对于质量敏感场景 (营销海报、产品图等),优先使用 Gemini 3 Pro,失败后降级到 2.5 Flash。对于高并发场景 (UGC 内容、快速原型),直接使用 2.5 Flash 提高稳定性。建议通过 API易 apiyi.com 平台进行模型对比测试,该平台支持一键切换模型并提供成本和质量对比数据。
方法 5: 监控和告警系统
生产环境必须实现完善的监控,及时发现和响应故障:
关键监控指标:
- 成功率: 过去 5 分钟 / 1 小时 / 24 小时的成功率
- 响应时间: P50 / P95 / P99 响应时间
- 错误分布: 503 / 429 / 500 等错误的占比
- 降级触发次数: 主模型失败导致的降级次数
简单监控实现:
from collections import deque
from datetime import datetime
class APIMonitor:
"""API 调用监控器"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""记录 API 调用"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""计算成功率"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""判断是否需要告警"""
success_rate = self.get_success_rate()
# 成功率低于 70% 触发告警
if success_rate < 70:
return True
# 503 错误超过 30% 触发告警
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# 使用示例
monitor = APIMonitor(window_size=100)
# 每次调用后记录
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# 定期检查告警
if monitor.should_alert():
print(f"🚨 告警: API 成功率降至 {monitor.get_success_rate():.2f}%")
Gemini API 配额和速率限制详解
2025 年 12 月配额调整
2025 年 12 月 7 日,Google 调整了 Gemini API 的配额限制,导致大量开发者遇到意外的 429 错误。
当前配额标准 (2026 年 1 月):
| 配额维度 | 免费版 (Free Tier) | 付费版 Tier 1 | 说明 |
|---|---|---|---|
| RPM (每分钟请求数) | 5-15 (视模型而定) | 150-300 | Gemini 3 Pro 限制更严格 |
| TPM (每分钟 Token 数) | 32,000 | 4,000,000 | 文本模型适用 |
| RPD (每天请求数) | 1,500 | 10,000+ | 共享配额池 |
| IPM (每分钟图像数) | 5-10 | 50-100 | 图像生成模型专用 |
关键注意事项:
- 配额限制基于 Google Cloud Project 级别,而非单个 API Key
- 同一项目下创建多个 API Key 不会增加配额
- 超过任何一个维度的限制都会触发 429 错误
- 使用 Token Bucket 算法强制执行,突发流量会被限制
成本优化: 对于预算敏感的项目,可以考虑通过 API易 apiyi.com 平台调用 Gemini API。该平台提供灵活的按需付费方式,无需购买 Google Cloud 订阅,适合中小团队和个人开发者快速测试和小规模部署。
常见问题
Q1: 如何区分 503 overloaded 和 429 rate limit 错误?
两者的区别在于根本原因和恢复时间:
503 Overloaded:
- 错误信息:
The model is overloaded. Please try again later. - HTTP 状态码: 503 Service Unavailable
- 根本原因: Google 服务端计算资源不足,与你的配额无关
- 恢复时间: 30-120 分钟 (Gemini 3 Pro),5-15 分钟 (Gemini 2.5 Flash)
- 应对策略: 指数退避重试、切换到备用模型、避开高峰时段
429 Rate Limit:
- 错误信息:
RESOURCE_EXHAUSTED或Rate limit exceeded - HTTP 状态码: 429 Too Many Requests
- 根本原因: 你的 API 调用超过了配额限制 (RPM/TPM/RPD/IPM)
- 恢复时间: 1-5 分钟 (配额池自动恢复)
- 应对策略: 降低请求频率、升级到付费版、请求提高配额
快速判断方法: 检查 Google AI Studio 的配额使用情况,如果接近或达到上限则是 429,否则是 503。
Q2: 为什么凌晨 00:18 会出现大规模故障?
2026 年 1 月 16 日北京时间凌晨 00:18 的大规模故障,对应美国西海岸时间 1 月 15 日 08:18 PST,正好是美国工作日上班时间。
时间规律分析:
- 美国西海岸 (硅谷) 开发者在 08:00-10:00 PST 开始工作,对应北京时间 00:00-02:00
- 欧洲开发者在 14:00-18:00 CET 工作高峰,对应北京时间 21:00-01:00
- 中国开发者在 09:00-11:00 CST 和 20:00-23:00 CST 高峰
这三个时段叠加,导致 Nano Banana Pro API 负载远超容量,触发大规模 503 错误。
建议: 如果你的业务主要面向中国用户,可以将批量任务调度到北京时间 03:00-08:00 (美国深夜 + 欧洲凌晨),此时全球负载最低。
Q3: 生产环境应该如何选择模型?
根据业务需求选择合适的模型策略:
策略 1: 质量优先 (营销、产品图)
- 主模型: Gemini 3 Pro Image Preview (Nano Banana Pro)
- 备用模型: Gemini 2.5 Flash Image
- 实现: 主模型失败 3 次后自动降级到备用模型
- 预期成功率: 92-95% (含降级)
策略 2: 稳定性优先 (UGC、高并发)
- 主模型: Gemini 2.5 Flash Image
- 备用模型: 其他图像生成模型 (DALL-E 3, Stable Diffusion XL)
- 实现: 直接使用 2.5 Flash,故障时切换到第三方模型
- 预期成功率: 95-98%
策略 3: 成本优先 (测试、原型)
- 使用免费版 Gemini 2.5 Flash
- 接受偶尔的 429 和 503 错误
- 不实现复杂的容错逻辑
推荐方案: 通过 API易 apiyi.com 平台快速测试不同模型的效果和成本,该平台提供统一接口调用多种图像生成模型,便于对比和切换。
总结
Gemini Nano Banana Pro API 报错的核心要点:
- 503 Overloaded 是系统性问题: 与你的代码无关,是 Google 服务端计算资源不足导致,高峰期 45% 的调用会失败
- 时间规律明显: 北京时间 00:00-02:00、09:00-11:00、20:00-23:00 是高风险时段,需避开或实现降级策略
- 实现容错至关重要: 必须实现指数退避重试、增加超时时间 (120s+)、模型降级 (2.5 Flash 备用) 三层防护
- 监控和告警: 生产环境必须监控成功率、响应时间、错误分布,及时发现和响应故障
- 理解配额限制: 429 错误与你的 API 配额有关,503 错误与 Google 整体负载有关,两者应对策略不同
作为预览阶段模型,Nano Banana Pro 的稳定性问题在短期内难以根本解决。推荐通过 API易 apiyi.com 快速验证你的图像生成需求,平台提供免费额度和多模型统一接口,支持 Gemini 3 Pro、Gemini 2.5 Flash、DALL-E 3 等主流图像生成模型,确保业务连续性。
📚 参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
- Nano Banana Errors & Troubleshooting Guide: 完整的报错参考手册
- 链接:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - 说明: 涵盖 429、502、403、500 等所有 Nano Banana Pro 错误代码的完整解决方案
- 链接:
- Google AI 开发者论坛: Gemini 3 Pro overloaded 错误讨论
- 链接:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - 说明: 开发者社区关于 503 错误的实时讨论和经验分享
- 链接:
- Gemini API Rate Limits 官方文档: 配额和速率限制说明
- 链接:
ai.google.dev/gemini-api/docs/rate-limits - 说明: Google 官方的 API 配额文档,包含 RPM/TPM/RPD/IPM 详细说明
- 链接:
- Gemini 3 Pro Image Preview Error Codes: 错误代码完整指南
- 链接:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - 说明: 2025-2026 年 Gemini 3 Pro 所有错误代码的排查和解决方法
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论 Gemini API 使用经验,更多故障排查资料可访问 API易 apiyi.com 技术社区