Note de l'auteur : Analyse approfondie des erreurs « overloaded » (surchargé) et « service unavailable » (service indisponible) de l'API Gemini Nano Banana Pro, incluant les causes, la récurrence temporelle, des solutions concrètes et les meilleures pratiques en environnement de production.
Le 16 janvier 2026 à 00h18, de nombreux développeurs ont signalé que l'API Gemini Nano Banana Pro (nom du modèle gemini-3-pro-image-preview) renvoyait des erreurs « The model is overloaded. Please try again later. » (Le modèle est surchargé. Veuillez réessayer plus tard) ou même « The service is currently unavailable. » (Le service est actuellement indisponible). Il ne s'agit pas d'un problème de code, mais d'une défaillance systémique due à des goulots d'étranglement de la capacité de calcul côté serveur de Google.
Valeur ajoutée : En lisant cet article, vous comprendrez les causes fondamentales, la récurrence temporelle et les mécanismes techniques de ces deux types d'erreurs. Vous maîtriserez 5 solutions concrètes et apprendrez à construire des stratégies de tolérance aux pannes de niveau production.
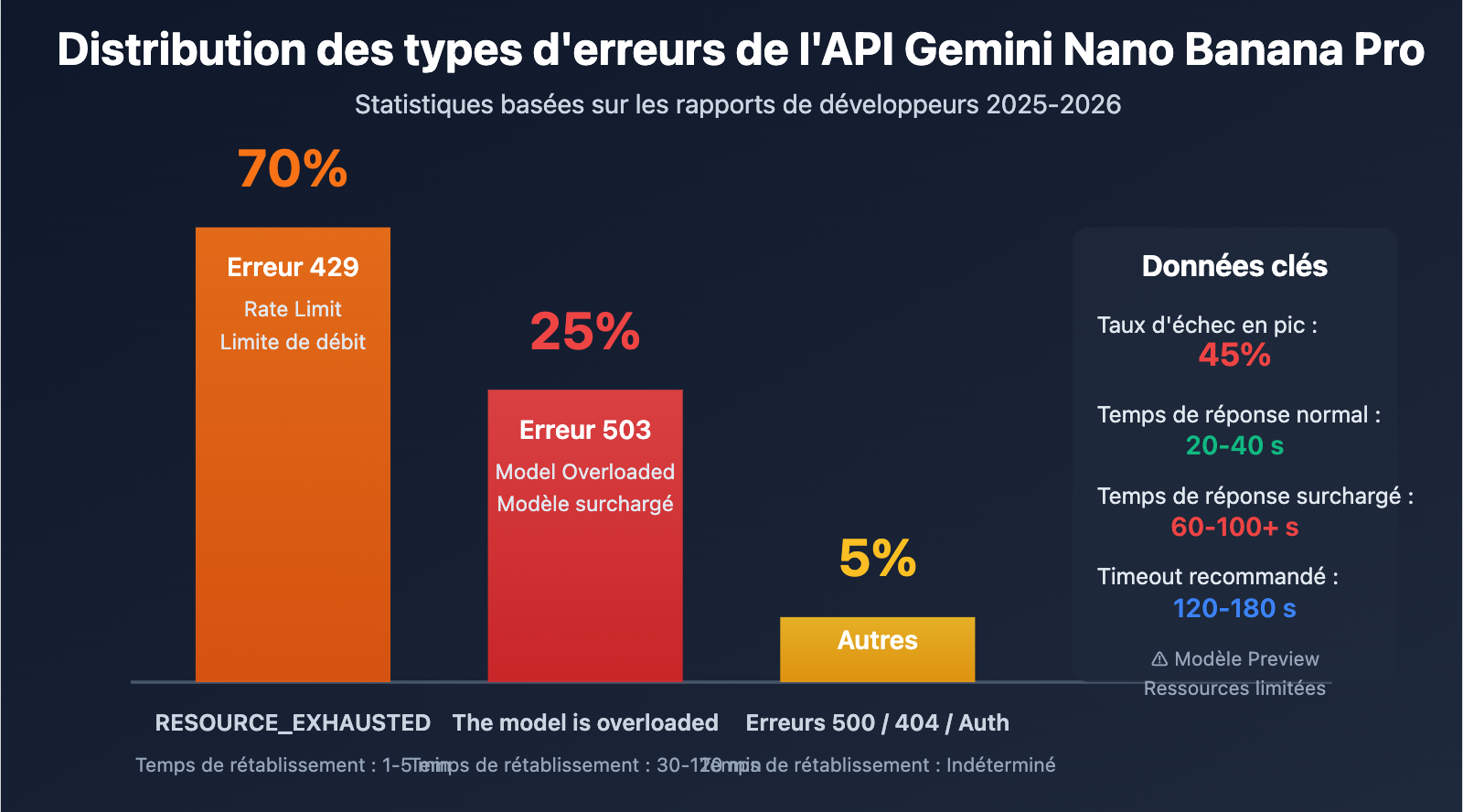
Points clés des erreurs de l'API Gemini Nano Banana Pro
| Point | Description | Impact |
|---|---|---|
| Erreur 503 Overloaded | Ressources de calcul insuffisantes côté serveur, pas un problème de code | Jusqu'à 45% des appels API peuvent échouer en période de pointe |
| Erreur 503 vs 429 | 503 est un problème de capacité, 429 est une limite de débit | Le rétablissement d'une 503 prend 30-120 min, contre 1-5 min pour une 429 |
| Limites du modèle Preview | La série Gemini 3 est encore en phase d'aperçu | Ressources limitées, gestion de la capacité dynamique instable |
| Récurrence temporelle | Taux d'échec maximal lors des pics de soirée et au milieu de la nuit (heure de Pékin) | Nécessité d'éviter les pics ou d'implémenter des stratégies de dégradation |
| Hausse du temps de réponse | 20-40s en normal, 60-100s+ en cas de problème | Nécessité de configurer un timeout plus long (120s+) |
Détails sur les erreurs Gemini Nano Banana Pro
C'est quoi Nano Banana Pro ?
Gemini Nano Banana Pro est le modèle de génération d'images de la plus haute qualité de Google, correspondant aux noms de modèles API gemini-2.0-flash-preview-image-generation ou gemini-3-pro-image-preview. En tant que fleuron de la génération d'images de la série Gemini 3, il surpasse nettement Gemini 2.5 Flash Image en termes de qualité, de détails et de rendu de texte, mais il est par conséquent confronté à des goulots d'étranglement de ressources de calcul plus sévères.
Pourquoi ces erreurs fréquentes ?
D'après les données des forums de développeurs Google AI, les erreurs sur Nano Banana Pro sont devenues fréquentes depuis le second semestre 2025 et ne sont toujours pas totalement résolues début 2026. Les causes principales incluent :
- Ressources limitées en phase Preview : La série Gemini 3 est encore en phase Pre-GA (avant la disponibilité générale), et les ressources de calcul allouées par Google sont limitées.
- Gestion dynamique de la capacité : Même si vous n'avez pas atteint votre limite de débit (Rate Limit), le système peut renvoyer une erreur 503 si la charge globale est trop élevée.
- Concurrence mondiale des utilisateurs : Tous les développeurs partagent le même pool de ressources de calcul, et la demande dépasse largement l'offre pendant les pics.
- Calcul intensif du modèle : La génération d'images de haute qualité nécessite énormément de calcul GPU, chaque requête prenant 20 à 40 secondes, soit bien plus qu'un modèle textuel.
Différence entre les erreurs 503 et 429
| Type d'erreur | Code HTTP | Message d'erreur | Cause fondamentale | Temps de rétablissement | Proportion |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
Capacité de calcul serveur insuffisante | 30-120 minutes | env. 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
Dépassement du quota utilisateur (RPM/TPM/RPD) | 1-5 minutes | env. 70% |
| Unavailable | 503 | Service unavailable |
Panne systémique ou maintenance | Indéterminé (parfois plusieurs heures) | env. 5% |
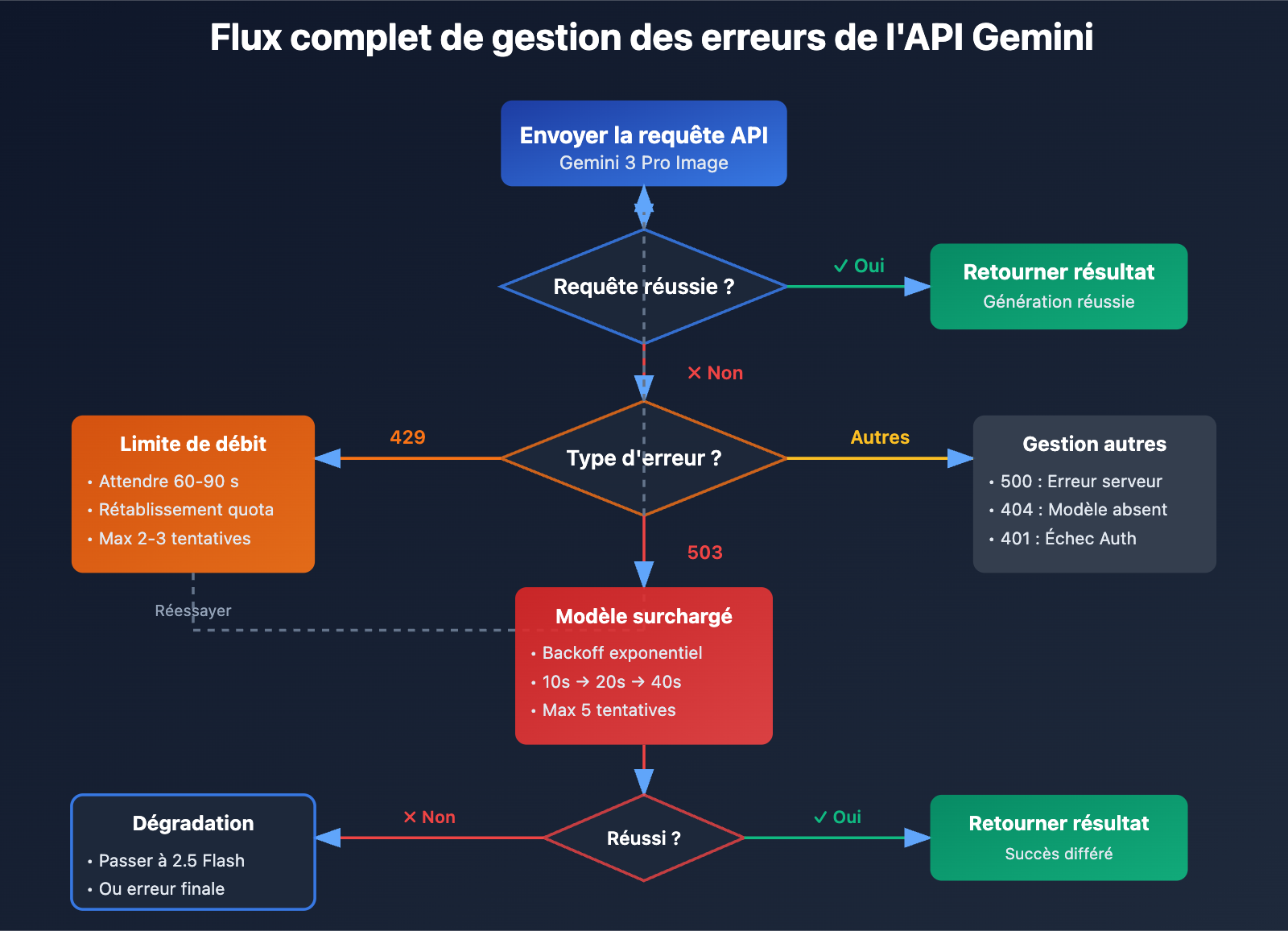
Analyse des cycles d'erreurs de Gemini Nano Banana Pro
Périodes de pannes critiques
Selon les rapports de nombreux développeurs, les pannes de l'API Nano Banana Pro suivent des cycles temporels bien précis :
Créneaux à haut risque (Heure de Pékin – UTC+8) :
- 00h00 – 02h00 : Heures de bureau sur la côte ouest des États-Unis (08h00-10h00 PST), pic d'activité des développeurs occidentaux.
- 09h00 – 11h00 : Début de la journée de travail en Chine continentale, pic des développeurs asiatiques.
- 20h00 – 23h00 : Pic de soirée en Chine cumulé à l'après-midi en Europe.
Créneaux relativement stables :
- 03h00 – 08h00 : Période où le nombre d'utilisateurs mondiaux est au plus bas.
- 14h00 – 17h00 : Après-midi en Chine et fin de nuit aux États-Unis, charge réseau plus faible.
Validation par les faits : La panne massive du 16 janvier 2026 à 00h18 (heure de Pékin) a eu lieu exactement au moment de l'arrivée au bureau sur la côte ouest américaine (15 janvier, 08h18 PST), confirmant la pertinence de ces cycles.

5 méthodes pour résoudre les erreurs de Gemini Nano Banana Pro
Méthode 1 : Implémenter une stratégie de re-tentative avec backoff exponentiel
C'est la solution de base pour gérer les erreurs 503. Voici la logique de re-tentative recommandée :
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
Fonction de génération d'image avec backoff exponentiel
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # Augmentation du timeout
)
return response
except Exception as e:
error_msg = str(e)
# Erreur 503 : re-tentative avec backoff exponentiel
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ Modèle surchargé, nouvelle tentative dans {delay:.1f}s (Essai {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ Nombre maximal de tentatives atteint, le modèle est toujours surchargé")
# Erreur 429 : attente courte avant re-tentative
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ Limite de débit atteinte, re-tentative dans 60s")
time.sleep(60)
continue
# Autres erreurs : on lève l'exception directement
else:
raise e
raise Exception("❌ Toutes les tentatives ont échoué")
# Exemple d'utilisation
result = generate_image_with_retry(
prompt="Une ville futuriste au coucher du soleil, style cyberpunk",
max_retries=5
)
Voir le code complet prêt pour la production
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
Client de génération d'images Gemini pour la production
Gère les re-tentatives, le repli (fallback) et le monitoring
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
Génération d'image avec stratégie de repli
"""
# Tentative avec le modèle principal
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ Échec du modèle principal {primary_model} : {str(e)}")
# Repli automatique vers le modèle de secours
try:
print(f"🔄 Passage au modèle de secours {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""Logique interne de re-tentative"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""Récupère les statistiques d'utilisation"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# Exemple d'utilisation
client = GeminiImageClient(api_key="VOTRE_CLE_API")
result = client.generate_with_fallback(
prompt="Une forêt magique avec des champignons luminescents",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ Génération réussie via le modèle : {result['model_used']}")
else:
print(f"❌ Échec de la génération : {result['error']}")
# Affichage des statistiques
print(client.get_stats())
Conseil technique : Pour vos projets en production, il est fortement recommandé d'utiliser la plateforme APIYI (apiyi.com). Elle fournit une interface API unifiée pour Gemini 3 Pro et de nombreux autres modèles de génération d'images. Si Nano Banana Pro est surchargé, vous pouvez basculer instantanément vers Gemini 2.5 Flash ou un autre modèle pour assurer la continuité de votre service.
Méthode 2 : Augmenter le timeout et configurer les requêtes
Le temps de réponse normal de Nano Banana Pro est de 20 à 40 secondes, mais en cas de forte charge, il peut grimper à 60-100 secondes. Un timeout par défaut à 30 secondes provoquera de nombreux échecs injustifiés.
Configuration recommandée :
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1",
timeout=120, # Augmentation du timeout global à 120s
max_retries=3 # Le SDK tente automatiquement 3 fois
)
# Ou spécifier par requête unique
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Votre invite ici",
timeout=150 # Timeout de 150s pour cette requête
)
Paramètres clés :
timeout: Temps d'attente maximum par requête. Réglez-le entre 120 et 180 secondes.max_retries: Nombre de re-tentatives automatiques au niveau du SDK (conseillé : 2-3).keep_alive: Maintient la connexion active pour éviter les coupures sur les requêtes longues.
Méthode 3 : Éviter les périodes de pointe
Si votre application permet un traitement asynchrone, planifier vos tâches en fonction des cycles de charge peut drastiquement améliorer votre taux de réussite :
Stratégie de planification recommandée :
- Tâches prioritaires : À exécuter entre 03h00-08h00 ou 14h00-17h00 (heure de Pékin).
- Générations par lots : Utiliser une file d'attente pour une exécution automatique pendant les heures creuses.
- Tâches en temps réel : Doivent impérativement inclure une stratégie de repli et ne pas dépendre d'un seul modèle.
Exemple de planification en Python :
from datetime import datetime
def is_peak_hour() -> bool:
"""Vérifie si on est en période de pointe (Heure de Pékin)"""
current_hour = datetime.now().hour
# Pics : 0-2h, 9-11h, 20-23h
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""Génération intelligente : repli automatique pendant les pics"""
if is_peak_hour():
print("⚠️ Période de pointe détectée, utilisation du modèle de secours")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
Méthode 4 : Implémenter une stratégie de repli (Fallback)
Google recommande officiellement de basculer vers Gemini 2.5 Flash en cas de surcharge. Voici les données comparatives :
| Indicateur | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| Qualité d'image | Maximale (9/10) | Excellente (7.5/10) |
| Vitesse | 20-40 sec | 10-20 sec |
| Stabilité | ~45% d'échec en pic | <10% d'échec en pic |
| Récupération 503 | 30-120 min | 5-15 min |
| Coût API | Plus élevé | Plus bas |
Conseil de stratégie : Pour les besoins exigeants en qualité (affiches marketing, photos produits), utilisez Gemini 3 Pro en priorité, avec un repli vers 2.5 Flash en cas d'échec. Pour les scénarios à haute concurrence (contenu utilisateur, prototypes rapides), utilisez directement 2.5 Flash pour garantir la stabilité. Vous pouvez tester et comparer ces modèles via APIYI (apiyi.com), qui permet de changer de modèle en un clic.
Méthode 5 : Système de surveillance et d'alerte
En production, un monitoring robuste est essentiel pour réagir rapidement aux incidents :
Indicateurs clés à surveiller :
- Taux de réussite : Sur les dernières 5 min / 1h / 24h.
- Temps de réponse : Latences P50 / P95 / P99.
- Répartition des erreurs : Proportion de 503, 429, 500, etc.
- Fréquence de repli : Nombre de fois où le modèle principal a échoué.
Implémentation d'un monitoring simple :
from collections import deque
from datetime import datetime
class APIMonitor:
"""Moniteur d'appels API"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""Enregistre un appel API"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""Calcule le taux de réussite"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""Détermine si une alerte doit être déclenchée"""
success_rate = self.get_success_rate()
# Alerte si le taux de réussite tombe sous 70%
if success_rate < 70:
return True
# Alerte si les erreurs 503 dépassent 30% des erreurs totales
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# Exemple d'utilisation
monitor = APIMonitor(window_size=100)
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# Vérification régulière des alertes
if monitor.should_alert():
print(f"🚨 ALERTE : Le taux de réussite de l'API est tombé à {monitor.get_success_rate():.2f}%")
Détails sur les quotas et les limites de débit de l'API Gemini
Ajustement des quotas de décembre 2025
Le 7 décembre 2025, Google a ajusté les limites de quota de l'API Gemini, ce qui a provoqué de nombreuses erreurs 429 inattendues chez de nombreux développeurs.
Standards de quotas actuels (janvier 2026) :
| Dimension du quota | Version gratuite (Free Tier) | Version payante Tier 1 | Description |
|---|---|---|---|
| RPM (Requêtes par minute) | 5-15 (selon le modèle) | 150-300 | Restrictions plus strictes pour Gemini 3 Pro |
| TPM (Tokens par minute) | 32 000 | 4 000 000 | S'applique aux modèles textuels |
| RPD (Requêtes par jour) | 1 500 | 10 000+ | Pool de quotas partagé |
| IPM (Images par minute) | 5-10 | 50-100 | Spécifique aux modèles de génération d'images |
Points d'attention cruciaux :
- Les limites de quota sont basées sur le niveau du Projet Google Cloud et non sur une clé API individuelle.
- Créer plusieurs clés API sous le même projet n'augmentera pas votre quota.
- Dépasser n'importe laquelle de ces dimensions déclenchera une erreur 429.
- L'application des limites se fait via l'algorithme Token Bucket ; les pics de trafic soudains seront limités.
Optimisation des coûts : Pour les projets sensibles au budget, vous pouvez envisager de passer par la plateforme APIYI (apiyi.com) pour appeler l'API Gemini. Cette plateforme offre un mode de paiement à l'usage flexible sans nécessiter d'abonnement Google Cloud, ce qui est idéal pour les petites et moyennes équipes ainsi que pour les développeurs indépendants souhaitant effectuer des tests rapides ou des déploiements à petite échelle.
Questions Fréquentes (FAQ)
Q1 : Comment différencier l’erreur 503 (overloaded) de l’erreur 429 (rate limit) ?
La différence réside dans la cause profonde et le temps de récupération :
503 Overloaded (Surcharge) :
- Message d'erreur :
The model is overloaded. Please try again later. - Code d'état HTTP : 503 Service Unavailable
- Cause profonde : Ressources de calcul insuffisantes du côté des serveurs Google, cela n'a rien à voir avec votre quota.
- Temps de récupération : 30-120 minutes (Gemini 3 Pro), 5-15 minutes (Gemini 2.5 Flash).
- Stratégie : Réessais avec backoff exponentiel, bascule vers un modèle de secours, éviter les heures de pointe.
429 Rate Limit (Limite de débit) :
- Message d'erreur :
RESOURCE_EXHAUSTEDouRate limit exceeded. - Code d'état HTTP : 429 Too Many Requests.
- Cause profonde : Vos appels API ont dépassé les limites de quota (RPM/TPM/RPD/IPM).
- Temps de récupération : 1-5 minutes (récupération automatique du pool de quotas).
- Stratégie : Réduire la fréquence des requêtes, passer à la version payante, demander une augmentation de quota.
Méthode de diagnostic rapide : Vérifiez l'utilisation des quotas dans Google AI Studio. Si vous êtes proche ou au-dessus de la limite, c'est une 429. Sinon, c'est probablement une 503.
Q2 : Pourquoi y a-t-il eu une panne massive à 00h18 ?
La panne massive du 16 janvier 2026 à 00h18 (heure de Pékin) correspond à 08h18 PST le 15 janvier sur la côte ouest des États-Unis, soit pile au début de la journée de travail américaine.
Analyse des cycles horaires :
- Les développeurs de la côte ouest américaine (Silicon Valley) commencent à travailler entre 08h00 et 10h00 PST (soit 00h00-02h00 heure de Pékin).
- Les développeurs européens sont en plein pic d'activité entre 14h00 et 18h00 CET (soit 21h00-01h00 heure de Pékin).
- Les développeurs chinois ont leurs pics entre 09h00-11h00 et 20h00-23h00 CST.
La superposition de ces trois zones géographiques fait que la charge de l'API Nano Banana Pro dépasse largement sa capacité, déclenchant des erreurs 503 massives.
Conseil : Si votre activité cible principalement les utilisateurs en Asie, essayez de planifier vos tâches de traitement par lots entre 03h00 et 08h00 heure de Pékin (fin de nuit aux USA + petit matin en Europe), car c'est là que la charge mondiale est la plus faible.
Q3 : Quel modèle choisir pour un environnement de production ?
Choisissez votre stratégie de modèle en fonction des besoins de votre entreprise :
Stratégie 1 : Priorité à la qualité (Marketing, photos de produits)
- Modèle principal : Gemini 3 Pro Image Preview (Nano Banana Pro)
- Modèle de secours : Gemini 2.5 Flash Image
- Implémentation : Rétrogradation automatique vers le modèle de secours après 3 échecs du modèle principal.
- Taux de réussite attendu : 92-95 % (incluant la rétrogradation).
Stratégie 2 : Priorité à la stabilité (UGC, haute concurrence)
- Modèle principal : Gemini 2.5 Flash Image
- Modèle de secours : Autres modèles de génération d'images (DALL-E 3, Stable Diffusion XL)
- Implémentation : Utilisation directe de 2.5 Flash, bascule vers un modèle tiers en cas de panne.
- Taux de réussite attendu : 95-98 %.
Stratégie 3 : Priorité au coût (Tests, prototypes)
- Utilisation de la version gratuite de Gemini 2.5 Flash.
- Acceptation des erreurs 429 et 503 occasionnelles.
- Pas de logique complexe de tolérance aux pannes.
Solution recommandée : Utilisez la plateforme APIYI (apiyi.com) pour tester rapidement l'efficacité et le coût de différents modèles. Elle fournit une interface unifiée pour appeler plusieurs modèles de génération d'images, facilitant ainsi la comparaison et le basculement.
Résumé
Points clés concernant les erreurs de l'API Gemini Nano Banana Pro :
- Le 503 Overloaded est un problème systémique : Cela n'a rien à voir avec votre code. C'est dû à un manque de ressources de calcul côté serveurs Google. Aux heures de pointe, environ 45 % des appels peuvent échouer.
- Une cyclicité temporelle marquée : Les créneaux 00h00-02h00, 09h00-11h00 et 20h00-23h00 (heure de Pékin) sont des périodes à haut risque. Il est préférable de les éviter ou de mettre en place des stratégies de repli.
- La gestion des erreurs est cruciale : Il est impératif d'implémenter trois couches de protection : des tentatives de reconnexion avec backoff exponentiel (retrait exponentiel), une augmentation du timeout (120s+) et une stratégie de repli vers un modèle inférieur (Gemini 2.5 Flash en secours).
- Surveillance et alertes : En environnement de production, vous devez impérativement surveiller le taux de réussite, les temps de réponse et la répartition des erreurs pour détecter et réagir rapidement aux pannes.
- Comprendre les limites de quota : Les erreurs 429 sont liées à votre propre quota API, tandis que les erreurs 503 dépendent de la charge globale de Google. Les stratégies pour y faire face sont différentes.
S'agissant d'un modèle en phase de prévisualisation (preview), les problèmes de stabilité de Nano Banana Pro seront difficiles à résoudre radicalement à court terme. Pour valider rapidement vos besoins en génération d'images, nous vous recommandons de passer par APIYI (apiyi.com). La plateforme offre des crédits gratuits et une interface unifiée pour plusieurs modèles, supportant les standards comme Gemini 3 Pro, Gemini 2.5 Flash ou DALL-E 3, garantissant ainsi la continuité de votre activité.
📚 Références
⚠️ Note sur le format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com. C'est pratique pour le copier-coller mais évite les redirections directes pour préserver le référencement (SEO).
-
Nano Banana Errors & Troubleshooting Guide : Le manuel complet de référence sur les erreurs.
- Lien :
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - Description : Couvre les solutions complètes pour tous les codes d'erreur Nano Banana Pro (429, 502, 403, 500, etc.).
- Lien :
-
Forum des développeurs Google AI : Discussion sur les erreurs "overloaded" de Gemini 3 Pro.
- Lien :
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - Description : Discussions en temps réel et partages d'expériences de la communauté de développeurs sur les erreurs 503.
- Lien :
-
Documentation officielle Gemini API Rate Limits : Instructions sur les quotas et les limites de débit.
- Lien :
ai.google.dev/gemini-api/docs/rate-limits - Description : Documentation officielle de Google détaillant les limites RPM/TPM/RPD/IPM.
- Lien :
-
Gemini 3 Pro Image Preview Error Codes : Guide complet des codes d'erreur.
- Lien :
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - Description : Guide de dépannage pour tous les codes d'erreur de Gemini 3 Pro pour la période 2025-2026.
- Lien :
Auteur : Équipe technique
Échanges techniques : N'hésitez pas à partager votre expérience avec l'API Gemini dans les commentaires. Pour plus de ressources sur le dépannage, visitez la communauté technique de APIYI (apiyi.com).