Anmerkung des Autors: Tiefenanalyse der „Overloaded“- und „Service unavailable“-Fehler der Gemini Nano Banana Pro API, einschließlich Fehlerursachen, Zeitmustern, Praxislösungen und Best Practices für Produktionsumgebungen.
Am frühen Morgen des 16. Januar 2026 um 00:18 Uhr meldeten zahlreiche Entwickler, dass bei der Gemini Nano Banana Pro API (Modellname gemini-3-pro-image-preview) „The model is overloaded. Please try again later.“ oder sogar „The service is currently unavailable.“ Fehler auftraten. Dies ist kein Code-Problem, sondern eine systembedingte Störung aufgrund von Kapazitätsengpässen auf den Servern von Google.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die Ursachen, Zeitmuster und technischen Mechanismen dieser beiden Fehlertypen verstehen, 5 Praxislösungen beherrschen und lernen, wie man Fehlertoleranz-Strategien auf Produktionsniveau aufbaut.
Gemini Nano Banana Pro API Fehlermeldungen: Kernpunkte
| Punkt | Erläuterung | Auswirkung |
|---|---|---|
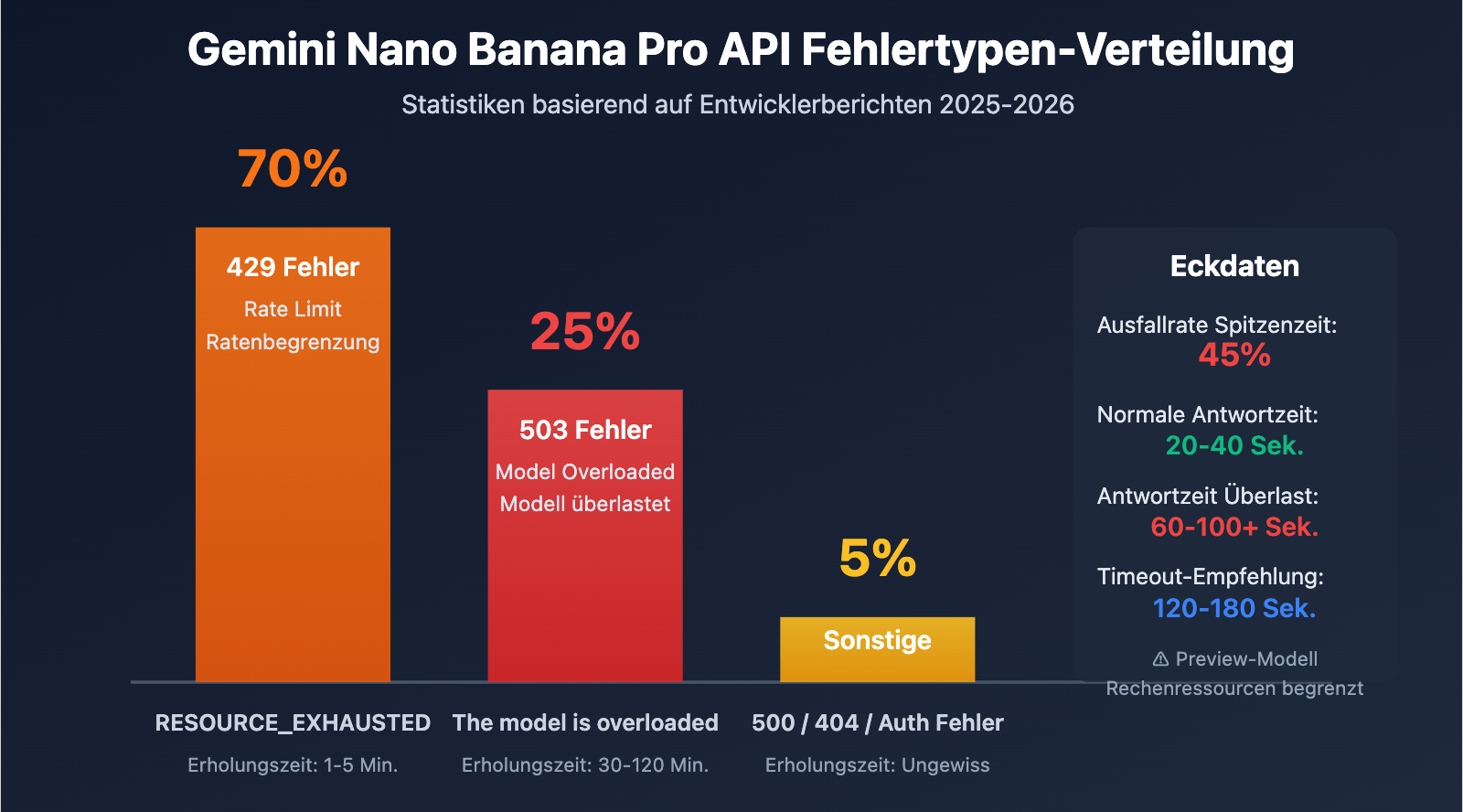
| 503 Overloaded Fehler | Unzureichende Rechenressourcen serverseitig, kein Code-Problem | In Spitzenzeiten scheitern 45 % der API-Aufrufe |
| 503 vs. 429 Fehler | 503 ist ein Kapazitätsproblem, 429 eine Ratenbegrenzung | 503-Erholung dauert 30-120 Min., 429 nur 1-5 Min. |
| Preview-Modell-Beschränkungen | Gemini 3 Serie befindet sich noch in der Vorschauphase | Ressourcen begrenzt, dynamisches Kapazitätsmanagement instabil |
| Zeitliche Regelmäßigkeit | Höchste Fehlerraten nachts und in Abend-Spitzenzeiten | Peak-Zeiten meiden oder Fallback-Strategien implementieren |
| Anstieg der Antwortzeit | Normal 20-40 Sek., bei Fehlern 60-100+ Sek. | Längere Timeout-Einstellungen (120s+) erforderlich |
Gemini Nano Banana Pro Fehlermeldungen im Detail
Was ist Nano Banana Pro?
Gemini Nano Banana Pro ist Googles hochwertigstes Modell zur Bilderzeugung. Die entsprechenden API-Modellnamen lauten gemini-2.0-flash-preview-image-generation oder gemini-3-pro-image-preview. Als Flaggschiff der Gemini 3-Serie für die Bilderzeugung ist es in puncto Bildqualität, Detailtreue und Textdarstellung deutlich leistungsfähiger als Gemini 2.5 Flash Image, sieht sich jedoch aufgrund dessen mit erheblichen Engpässen bei den Rechenressourcen konfrontiert.
Warum treten die Fehler so häufig auf?
Basierend auf Daten aus den Google AI Entwicklerforen treten die Probleme bei Nano Banana Pro seit der zweiten Jahreshälfte 2025 gehäuft auf und sind bis Anfang 2026 nicht vollständig gelöst. Die Hauptursachen sind:
- Ressourcenbeschränkung in der Vorschauphase: Die Modelle der Gemini 3-Serie befinden sich noch in der Pre-GA-Phase (vor der allgemeinen Verfügbarkeit), weshalb Google nur begrenzte Rechenressourcen bereitstellt.
- Dynamisches Kapazitätsmanagement: Selbst wenn das eigene Kontingent (Rate Limit) nicht ausgeschöpft ist, kann das System aufgrund der Gesamtauslastung einen 503-Fehler zurückgeben.
- Weltweiter Wettbewerb um Ressourcen: Alle Entwickler teilen sich denselben Pool an Rechenkapazitäten; in Stoßzeiten übersteigt die Nachfrage das Angebot bei Weitem.
- Rechenintensive Modelle: Die Erzeugung hochwertiger Bilder benötigt enorme GPU-Leistung. Ein einzelner Request dauert 20-40 Sekunden, was deutlich über der Zeit für Textmodelle liegt.
Unterschied zwischen 503 und 429 Fehlern
| Fehlertyp | HTTP-Statuscode | Fehlermeldung | Grundursache | Erholungszeit | Anteil |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
Kapazitätsengpass am Server | 30-120 Min. | ca. 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
Nutzerkontingent überschritten (RPM/TPM/RPD) | 1-5 Min. | ca. 70% |
| Unavailable | 503 | Service unavailable |
Systemstörung oder Wartung | Ungewiss (evtl. Stunden) | ca. 5% |
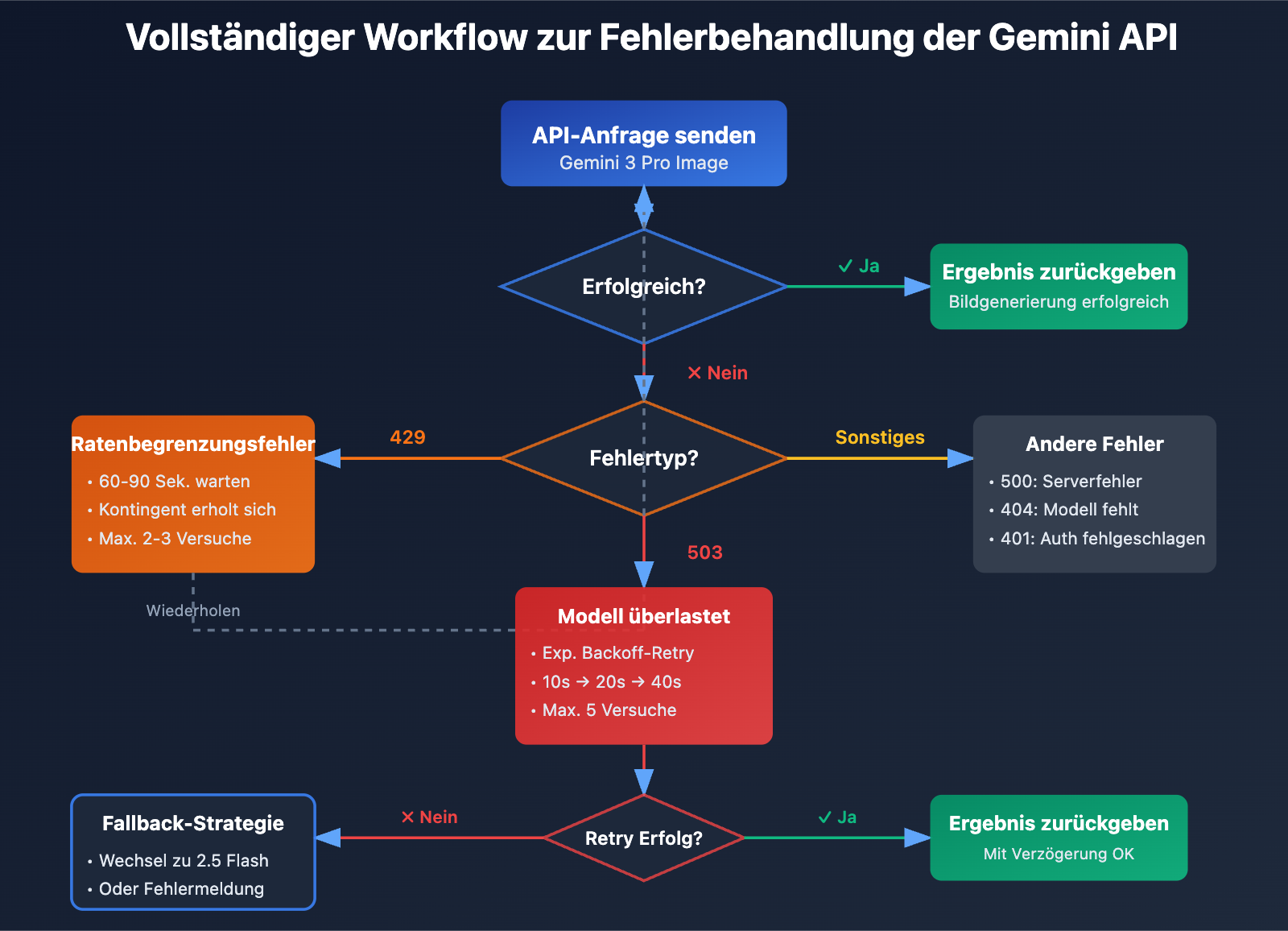
Analyse der Fehlermuster bei Gemini Nano Banana Pro
Hauptstörungszeiten
Basierend auf Berichten zahlreicher Entwickler weisen die Ausfälle der Nano Banana Pro API ein klares zeitliches Muster auf:
Hochrisiko-Zeitfenster (Pekinger Zeit – CST):
- 00:00 – 02:00: Arbeitszeit an der US-Westküste (08:00-10:00 PST), Peak für Entwickler aus den USA und Europa.
- 09:00 – 11:00: Arbeitsbeginn in Festlandchina, Peak für asiatische Entwickler.
- 20:00 – 23:00: Abend-Peak in China kombiniert mit dem europäischen Nachmittag.
Relativ stabile Zeitfenster:
- 03:00 – 08:00: Weltweit geringste Nutzerzahl.
- 14:00 – 17:00: Nachmittag in China + späte Nacht in den USA, geringere Last.
Fallstudie: Der großflächige Ausfall am 16. Januar 2026 um 00:18 Uhr Pekinger Zeit fiel genau in den Arbeitsbeginn an der US-Westküste (15. Januar, 08:18 PST), was die Genauigkeit dieses Zeitmusters bestätigt.

5 Wege zur Behebung von Gemini Nano Banana Pro Fehlern
Methode 1: Implementierung einer Exponential Backoff-Strategie
Dies ist die Basislösung für den Umgang mit 503-Fehlern. Hier ist die empfohlene Retry-Logik:
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
Bildgenerierungsfunktion mit Exponential Backoff
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # Timeout erhöhen
)
return response
except Exception as e:
error_msg = str(e)
# 503-Fehler: Exponential Backoff Retry
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ Modell überlastet, Retry in {delay:.1f} Sek. (Versuch {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ Maximale Retry-Anzahl erreicht, Modell dauerhaft überlastet")
# 429-Fehler: Kurz warten und erneut versuchen
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ Rate Limit erreicht, Retry in 60 Sek.")
time.sleep(60)
continue
# Andere Fehler: Direkt werfen
else:
raise e
raise Exception("❌ Alle Wiederholungsversuche fehlgeschlagen")
# Beispielnutzung
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
Vollständigen produktionsreifen Code anzeigen
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
Produktionsreifer Gemini-Bildgenerierungs-Client
Unterstützt Retries, Fallbacks und Monitoring
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
Bildgenerierung mit Fallback-Strategie
"""
# Primäres Modell versuchen
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ Primäres Modell {primary_model} fehlgeschlagen: {str(e)}")
# Automatischer Fallback auf Ersatzmodell
try:
print(f"🔄 Fallback auf Ersatzmodell {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""Interne Retry-Logik"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""Statistiken abrufen"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# Beispielnutzung
client = GeminiImageClient(api_key="YOUR_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ Generierung erfolgreich, Modell: {result['model_used']}")
else:
print(f"❌ Generierung fehlgeschlagen: {result['error']}")
# Statistiken anzeigen
print(client.get_stats())
Technischer Hinweis: In echten Produktionsumgebungen wird empfohlen, API-Aufrufe über die Plattform APIYI (apiyi.com) abzuwickeln. Die Plattform bietet ein einheitliches API-Interface und unterstützt Gemini 3 Pro sowie diverse andere Bildgenerierungsmodelle. Falls Nano Banana Pro überlastet ist, kann schnell auf Gemini 2.5 Flash oder andere Alternativen gewechselt werden, um die Geschäftskontinuität zu gewährleisten.
Methode 2: Timeout-Zeiten und Anfragekonfiguration erhöhen
Die normale Antwortzeit von Nano Banana Pro liegt bei 20–40 Sekunden, kann aber bei Überlastung 60–100 Sekunden oder länger erreichen. Ein Standard-Timeout von 30 Sekunden führt hier zu vielen fälschlichen Fehlermeldungen.
Empfohlene Konfiguration:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # Globales Timeout auf 120 Sek. erhöhen
max_retries=3 # SDK-seitig 3 automatische Retries
)
# Oder für eine einzelne Anfrage spezifizieren
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Dein Eingabeaufforderung hier",
timeout=150 # Einzelanfrage-Timeout 150 Sek.
)
Erklärung der Schlüsselparameter:
timeout: Maximale Wartezeit für eine einzelne Anfrage, empfohlen werden 120–180 Sekunden.max_retries: Automatische Wiederholungsversuche auf SDK-Ebene, empfohlen 2–3 Mal.keep_alive: Hält die Verbindung aktiv, um Abbrüche bei langen Anfragen zu vermeiden.
Methode 3: Stoßzeiten vermeiden
Wenn Ihr Business asynchrone Verarbeitung zulässt, kann die Zeitplanung der Aufgaben die Erfolgsquote massiv steigern:
Empfohlene Scheduling-Strategie:
- Hochpriorisierte Aufgaben: Ausführung zwischen 03:00–08:00 oder 14:00–17:00 Pekinger Zeit.
- Batch-Aufgaben: Nutzung von Queues zur automatischen Ausführung in lastarmen Zeiten.
- Echtzeit-Aufgaben: Müssen zwingend eine Fallback-Strategie implementieren und dürfen nicht von einem einzigen Modell abhängen.
Python-Beispiel für Task-Scheduling:
from datetime import datetime
def is_peak_hour() -> bool:
"""Prüft, ob aktuell Stoßzeit ist (Pekinger Zeit)"""
current_hour = datetime.now().hour
# Stoßzeiten: 0-2, 9-11, 20-23
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""Smart Generation: Automatisches Downgrade in Stoßzeiten"""
if is_peak_hour():
print("⚠️ Aktuell Stoßzeit, verwende Ersatzmodell")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
Methode 4: Implementierung einer Modell-Fallback-Strategie
Google empfiehlt offiziell, bei Überlastung auf Gemini 2.5 Flash zu wechseln. Hier ist der Datenvergleich:
| Metrik | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| Bildqualität | Höchste (9/10) | Hervorragend (7.5/10) |
| Generierungsgeschwindigkeit | 20–40 Sek. | 10–20 Sek. |
| Stabilität | ~45% Fehlerrate in Peaks | <10% Fehlerrate in Peaks |
| 503-Wiederherstellungszeit | 30–120 Min. | 5–15 Min. |
| API-Kosten | Höher | Niedriger |
Empfehlung: Für qualitätssensible Szenarien (Marketing-Poster, Produktbilder) nutzen Sie primär Gemini 3 Pro mit einem Fallback auf 2.5 Flash. Für High-Concurrency-Szenarien (UGC-Inhalte, schnelles Prototyping) nutzen Sie direkt 2.5 Flash für bessere Stabilität. Wir empfehlen Vergleichstests über die APIYI (apiyi.com) Plattform, die einen einfachen Modellwechsel sowie Kosten- und Qualitätsvergleiche ermöglicht.
Methode 5: Monitoring- und Alarmsysteme
In einer Produktionsumgebung ist ein lückenloses Monitoring essenziell, um Störungen rechtzeitig zu erkennen:
Wichtige Monitoring-Metriken:
- Erfolgsquote: Über die letzten 5 Min. / 1 Std. / 24 Std.
- Antwortzeit: P50 / P95 / P99 Latenz.
- Fehlerverteilung: Anteil von 503-, 429- und 500-Fehlern.
- Fallback-Trigger: Wie oft wurde aufgrund von Primärmodell-Fehlern auf das Ersatzmodell gewechselt.
Einfache Monitoring-Implementierung:
from collections import deque
from datetime import datetime
class APIMonitor:
"""API-Aufruf-Monitor"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""API-Aufruf protokollieren"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""Erfolgsquote berechnen"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""Prüfen, ob ein Alarm ausgelöst werden muss"""
success_rate = self.get_success_rate()
# Alarm bei Erfolgsquote unter 70%
if success_rate < 70:
return True
# Alarm, wenn 503-Fehler über 30% der Gesamtfehler ausmachen
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# Beispielnutzung
monitor = APIMonitor(window_size=100)
# Nach jedem Aufruf loggen
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# Regelmäßiger Alert-Check
if monitor.should_alert():
print(f"🚨 ALARM: API-Erfolgsquote auf {monitor.get_success_rate():.2f}% gesunken")
Gemini API Kontingente und Rate Limits im Detail
Kontingentanpassungen im Dezember 2025
Am 7. Dezember 2025 hat Google die Kontingentbeschränkungen (Quotas) für die Gemini API angepasst, was dazu führte, dass viele Entwickler unerwartet auf 429-Fehler stießen.
Aktuelle Kontingentstandards (Stand: Januar 2026):
| Quoten-Dimension | Kostenlose Version (Free Tier) | Bezahlversion Tier 1 | Beschreibung |
|---|---|---|---|
| RPM (Anfragen pro Minute) | 5-15 (je nach Modell) | 150-300 | Gemini 3 Pro ist strenger limitiert |
| TPM (Token pro Minute) | 32.000 | 4.000.000 | Gilt für Textmodelle |
| RPD (Anfragen pro Tag) | 1.500 | 10.000+ | Gemeinsamer Kontingentpool |
| IPM (Bilder pro Minute) | 5-10 | 50-100 | Speziell für Bildgenerierungsmodelle |
Wichtige Hinweise:
- Die Kontingentbeschränkungen basieren auf der Ebene des Google Cloud Projekts, nicht auf einzelnen API-Keys.
- Das Erstellen mehrerer API-Keys unter demselben Projekt erhöht das Kontingent nicht.
- Das Überschreiten einer beliebigen Dimension führt zu einem 429-Fehler.
- Die Durchsetzung erfolgt mittels Token-Bucket-Algorithmus; Traffic-Spitzen werden begrenzt.
Kostenoptimierung: Für budgetsensitive Projekte kann es sinnvoll sein, die Gemini API über die Plattform APIYI (apiyi.com) aufzurufen. Diese Plattform bietet flexible Pay-as-you-go-Optionen ohne die Notwendigkeit eines Google Cloud Abonnements, was ideal für kleine bis mittlere Teams sowie Einzelentwickler für schnelle Tests und kleine Bereitstellungen ist.
Häufig gestellte Fragen (FAQ)
F1: Wie unterscheide ich zwischen „503 overloaded“ und „429 rate limit“ Fehlern?
Der Unterschied liegt in der Ursache und der Erholungszeit:
503 Overloaded:
- Fehlermeldung:
The model is overloaded. Please try again later. - HTTP-Statuscode: 503 Service Unavailable
- Hauptursache: Die Rechenressourcen auf Google-Seite reichen nicht aus; das hat nichts mit Ihrem persönlichen Kontingent zu tun.
- Wiederherstellungszeit: 30-120 Minuten (Gemini 3 Pro), 5-15 Minuten (Gemini 2.5 Flash).
- Lösungsstrategie: Exponential Backoff bei Retries, Wechsel zu einem Fallback-Modell, Stoßzeiten vermeiden.
429 Rate Limit:
- Fehlermeldung:
RESOURCE_EXHAUSTEDoderRate limit exceeded - HTTP-Statuscode: 429 Too Many Requests
- Hauptursache: Ihre API-Aufrufe haben das Kontingentlimit (RPM/TPM/RPD/IPM) überschritten.
- Wiederherstellungszeit: 1-5 Minuten (der Quotenpool erholt sich automatisch).
- Lösungsstrategie: Anfragefrequenz reduzieren, Upgrade auf die Bezahlversion, Erhöhung des Kontingents beantragen.
Schnelltest: Überprüfen Sie die Kontingentnutzung in Google AI Studio. Wenn Sie nah am Limit sind, ist es ein 429-Fehler, andernfalls ein 503-Fehler.
F2: Warum kam es um 00:18 Uhr nachts zu massiven Ausfällen?
Der großflächige Ausfall am 16. Januar 2026 um 00:18 Uhr Pekinger Zeit entspricht 08:18 Uhr PST an der US-Westküste – also genau zum Arbeitsbeginn in den USA.
Analyse der Zeitmuster:
- Entwickler an der US-Westküste (Silicon Valley) beginnen zwischen 08:00 und 10:00 Uhr PST mit der Arbeit (entspricht 00:00 bis 02:00 Uhr Pekinger Zeit).
- Europäische Entwickler sind in ihrer Hauptarbeitszeit von 14:00 bis 18:00 Uhr CET (entspricht 21:00 bis 01:00 Uhr Pekinger Zeit).
- Chinesische Entwickler haben ihre Peaks zwischen 09:00–11:00 Uhr CST und 20:00–23:00 Uhr CST.
Das Zusammentreffen dieser drei Zeitfenster führte dazu, dass die Last der Nano Banana Pro API die Kapazitäten bei weitem überstieg und massive 503-Fehler auslöste.
Empfehlung: Wenn sich Ihr Geschäft hauptsächlich an Nutzer in China richtet, sollten Sie Batch-Aufgaben für den Zeitraum zwischen 03:00 und 08:00 Uhr Pekinger Zeit planen (späte Nacht in den USA + früher Morgen in Europa), da die globale Last dort am niedrigsten ist.
F3: Wie wähle ich das richtige Modell für die Produktionsumgebung aus?
Wählen Sie Ihre Modellstrategie basierend auf Ihren geschäftlichen Anforderungen:
Strategie 1: Qualität zuerst (Marketing, Produktfotos)
- Hauptmodell: Gemini 3 Pro Image Preview (Nano Banana Pro)
- Fallback-Modell: Gemini 2.5 Flash Image
- Umsetzung: Nach 3 Fehlversuchen des Hauptmodells automatisches Downgrade auf das Fallback-Modell.
- Erwartete Erfolgsquote: 92-95 % (inklusive Downgrade).
Strategie 2: Stabilität zuerst (UGC, hohe Parallelität)
- Hauptmodell: Gemini 2.5 Flash Image
- Fallback-Modell: Andere Bildgenerierungsmodelle (DALL-E 3, Stable Diffusion XL)
- Umsetzung: Direkt 2.5 Flash nutzen und bei Fehlern auf Drittanbieter-Modelle ausweichen.
- Erwartete Erfolgsquote: 95-98 %.
Strategie 3: Kosten zuerst (Tests, Prototypen)
- Nutzung der kostenlosen Version von Gemini 2.5 Flash.
- Gelegentliche 429- und 503-Fehler werden in Kauf genommen.
- Keine Implementierung komplexer Fehlertoleranz-Logik.
Empfohlene Lösung: Nutzen Sie die Plattform APIYI (apiyi.com), um die Effekte und Kosten verschiedener Modelle schnell zu testen. Die Plattform bietet eine einheitliche Schnittstelle für verschiedene Bildgenerierungsmodelle, was den Vergleich und den Wechsel erleichtert.
Zusammenfassung
Die wichtigsten Punkte zu den API-Fehlermeldungen von Gemini Nano Banana Pro:
- 503 Overloaded ist ein systemisches Problem: Dies liegt nicht an Ihrem Code, sondern an unzureichenden Rechenressourcen auf Seiten von Google. In Spitzenzeiten schlagen etwa 45 % der Aufrufe fehl.
- Deutliche zeitliche Muster: Die Zeiträume 00:00–02:00, 09:00–11:00 und 20:00–23:00 Uhr (Peking-Zeit) sind Hochrisiko-Phasen. Diese sollten gemieden oder durch Fallback-Strategien abgesichert werden.
- Fehlertoleranz ist entscheidend: Es ist zwingend erforderlich, eine dreistufige Absicherung zu implementieren: Exponential Backoff für Retries, Erhöhung des Timeouts (120s+) und ein Modell-Fallback (z. B. 2.5 Flash als Reserve).
- Monitoring und Alarmierung: In Produktionsumgebungen müssen Erfolgsraten, Antwortzeiten und die Fehlerverteilung überwacht werden, um Störungen rechtzeitig zu erkennen und darauf zu reagieren.
- Quotenbeschränkungen verstehen: Ein 429-Fehler hängt mit Ihrem persönlichen API-Kontingent zusammen, während ein 503-Fehler durch die allgemeine Last bei Google verursacht wird. Die Strategien zur Bewältigung beider Fehler unterscheiden sich grundlegend.
Da es sich um ein Modell in der Preview-Phase handelt, lassen sich die Stabilitätsprobleme von Nano Banana Pro kurzfristig kaum vollständig beheben. Wir empfehlen, Ihre Anforderungen an die Bildgenerierung schnell über APIYI (apiyi.com) zu validieren. Die Plattform bietet kostenloses Guthaben sowie eine einheitliche Schnittstelle für verschiedene Modelle und unterstützt gängige Bildgenerierungsmodelle wie Gemini 3 Pro, Gemini 2.5 Flash und DALL-E 3, um die Geschäftskontinuität zu gewährleisten.
📚 Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name der Quelle: domain.com. Dies erleichtert das Kopieren, verhindert jedoch den direkten Klick, um den SEO-Wert (Link Juice) zu erhalten.
-
Nano Banana Errors & Troubleshooting Guide: Vollständiges Handbuch zur Fehlerbehebung
- Link:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - Beschreibung: Deckt alle Fehlercodes für Nano Banana Pro ab, einschließlich 429, 502, 403 und 500.
- Link:
-
Google AI Developer Forum: Diskussion zum Fehler "Gemini 3 Pro overloaded"
- Link:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - Beschreibung: Echtzeit-Diskussionen und Erfahrungswerte aus der Entwickler-Community zum 503-Fehler.
- Link:
-
Gemini API Rate Limits Offizielle Dokumentation: Erläuterungen zu Quoten und Ratelimits
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Beschreibung: Offizielle Dokumentation von Google zu API-Quoten, inklusive Details zu RPM, TPM, RPD und IPM.
- Link:
-
Gemini 3 Pro Image Preview Error Codes: Vollständiger Leitfaden zu Fehlercodes
- Link:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - Beschreibung: Diagnose und Behebung aller Gemini 3 Pro Fehlercodes für den Zeitraum 2025–2026.
- Link:
Autor: Technik-Team
Technischer Austausch: Diskutieren Sie gerne Ihre Erfahrungen mit der Gemini API in den Kommentaren. Weitere Ressourcen zur Fehlerbehebung finden Sie in der APIYI (apiyi.com) Tech-Community.