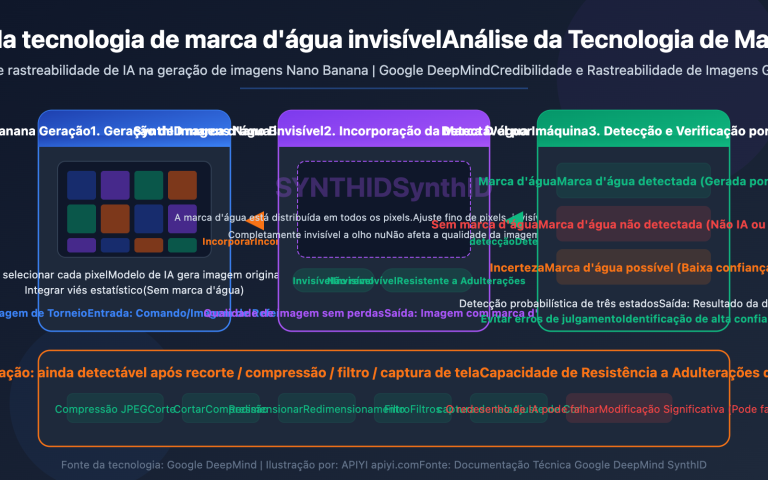
Nota do autor: Análise profunda dos erros "overloaded" e "service unavailable" da API Gemini Nano Banana Pro, incluindo causas dos erros, padrões temporais, soluções práticas e melhores práticas para ambiente de produção.
Em 16 de janeiro de 2026, à 00:18, um grande número de desenvolvedores relatou erros de 「The model is overloaded. Please try again later.」 e até mesmo 「The service is currently unavailable.」 na API Gemini Nano Banana Pro (nome do modelo gemini-3-pro-image-preview). Isso não é um problema no seu código, mas sim uma falha sistêmica causada por gargalos na capacidade computacional dos servidores do Google.
Valor central: Ao ler este artigo, você entenderá as causas fundamentais, os padrões de tempo e os mecanismos técnicos desses dois tipos de erros, dominará 5 soluções práticas e aprenderá a construir estratégias de tolerância a falhas de nível de produção.
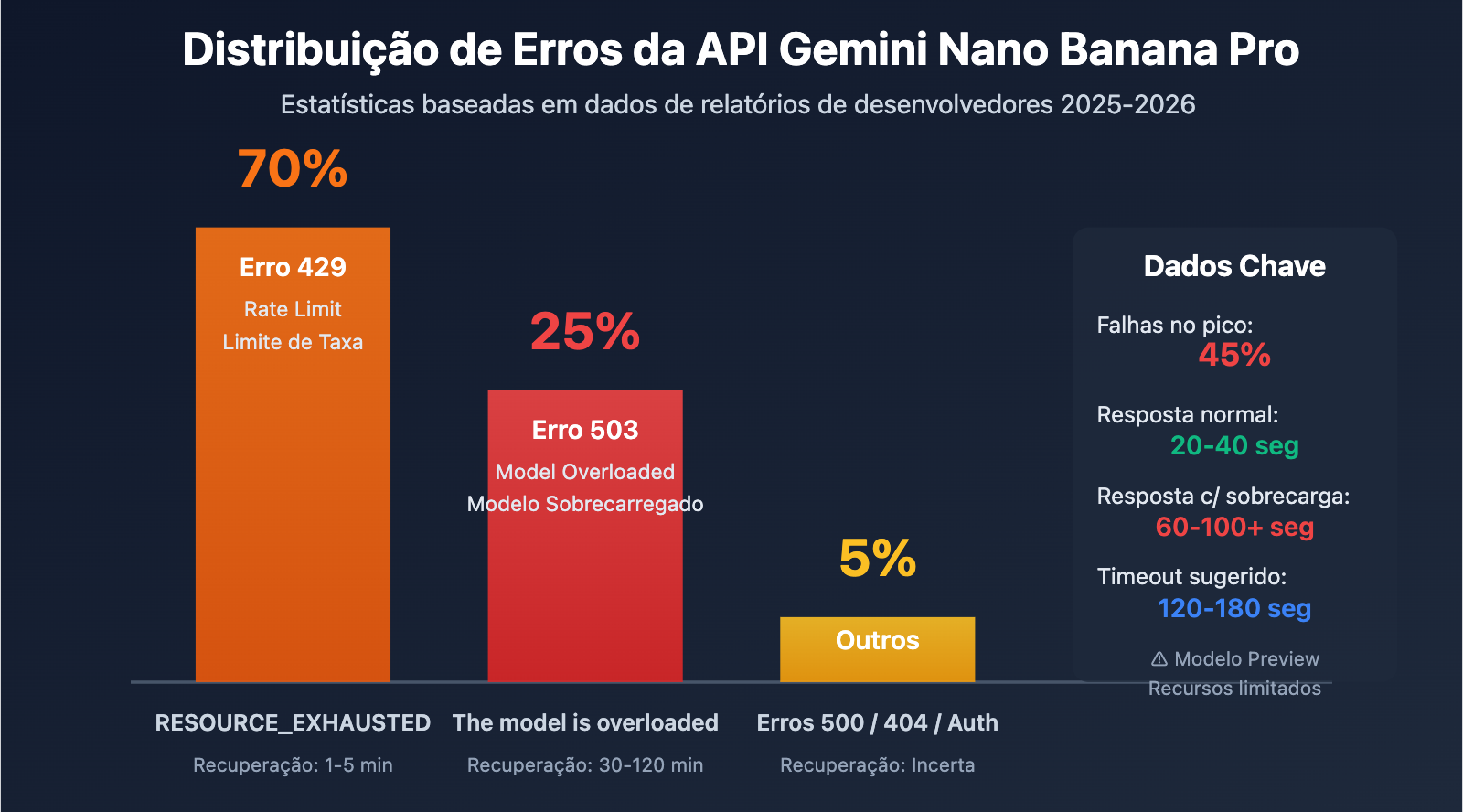
Pontos Chave dos Erros da API Gemini Nano Banana Pro
| Ponto | Descrição | Impacto |
|---|---|---|
| Erro 503 Overloaded | Recursos computacionais insuficientes no servidor, não é erro de código | Até 45% das chamadas de API podem falhar no horário de pico |
| Erro 503 vs 429 | 503 é problema de capacidade, 429 é limite de taxa | 503 leva 30-120 min para recuperar, 429 apenas 1-5 min |
| Limitação do Modelo Preview | A série Gemini 3 ainda está em fase de preview | Recursos limitados e gestão dinâmica de capacidade instável |
| Padrão Temporal | Taxas de falha mais altas durante picos noturnos (Horário de Pequim/Global) | Necessário evitar horários de pico ou implementar estratégias de fallback |
| Aumento no Tempo de Resposta | Normal 20-40s, em falha 60-100+s | Requer configuração de timeout mais longa (120s+) |
Detalhamento dos Erros do Gemini Nano Banana Pro
O que é o Nano Banana Pro?
O Gemini Nano Banana Pro é o modelo de geração de imagens de mais alta qualidade do Google, com nomes de modelo de API correspondentes como gemini-2.0-flash-preview-image-generation ou gemini-3-pro-image-preview. Como modelo principal de geração de imagens da série Gemini 3, ele supera significativamente o Gemini 2.5 Flash Image em qualidade de imagem, detalhes e renderização de texto, mas, por isso, enfrenta gargalos de recursos computacionais mais severos.
Por que os erros são frequentes?
De acordo com dados de discussões em fóruns de desenvolvedores de IA do Google, os problemas de erro do Nano Banana Pro tornaram-se frequentes a partir do segundo semestre de 2025 e ainda não foram totalmente resolvidos no início de 2026. As causas principais incluem:
- Limitações de recursos da fase Preview: Os modelos da série Gemini 3 ainda estão em fase Pre-GA (antes da Disponibilidade Geral), e o Google aloca recursos computacionais limitados para eles.
- Gestão Dinâmica de Capacidade: Mesmo que o limite de taxa (Rate Limit) não tenha sido atingido, o sistema pode retornar um erro 503 devido à alta carga global.
- Competição Global de Usuários: Todos os desenvolvedores compartilham o mesmo pool de recursos computacionais; nos horários de pico, a demanda supera em muito a oferta.
- Intensidade Computacional do Modelo: A geração de imagens de alta qualidade requer processamento massivo em GPU, levando de 20 a 40 segundos por solicitação, o que é muito superior aos modelos de texto.
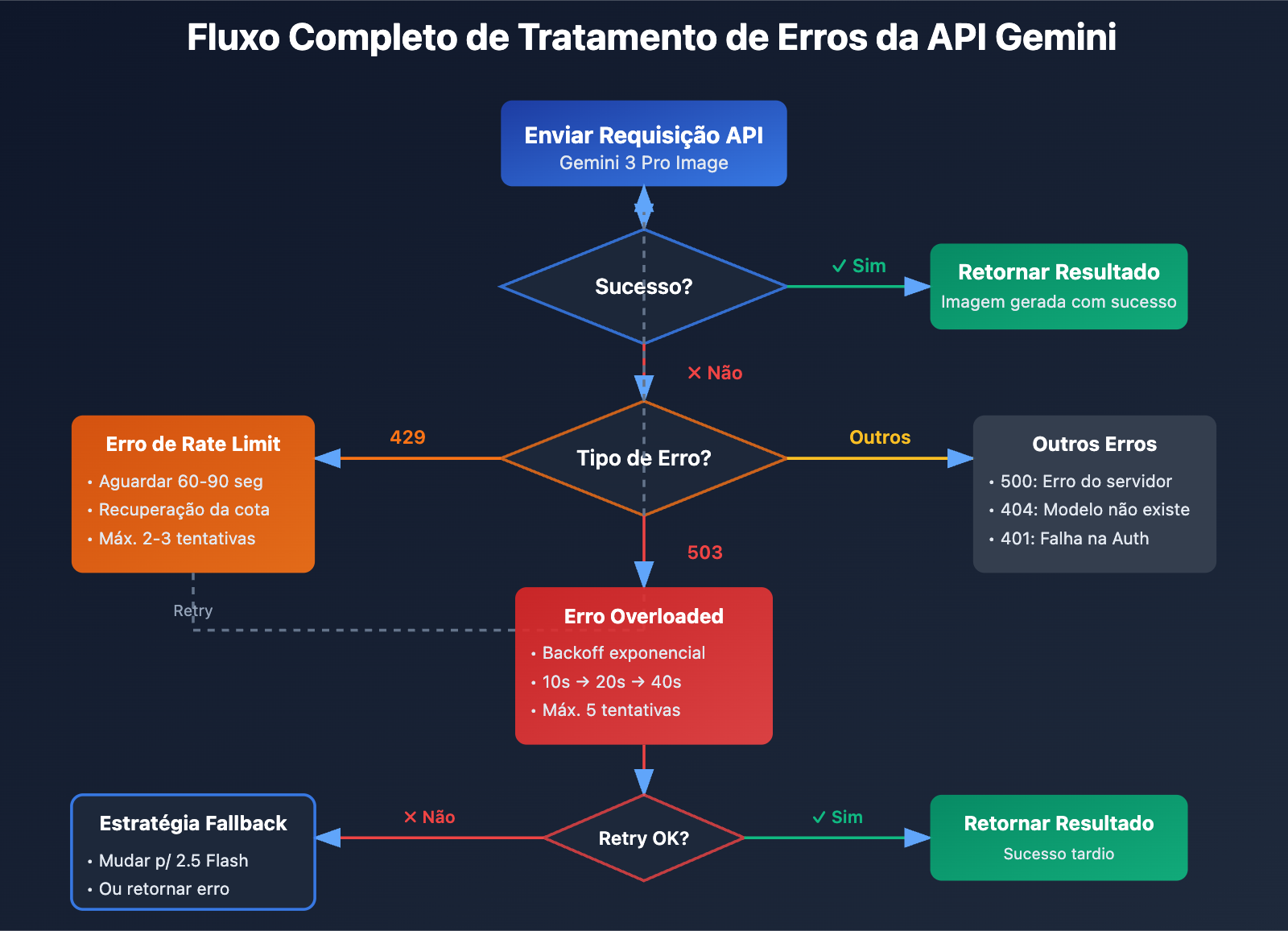
Diferença entre Erros 503 e 429
| Tipo de Erro | Código HTTP | Mensagem de Erro | Causa Raiz | Tempo de Recuperação | Proporção |
|---|---|---|---|---|---|
| Overloaded | 503 | The model is overloaded |
Capacidade computacional insuficiente no servidor | 30-120 minutos | aprox. 25% |
| Rate Limit | 429 | RESOURCE_EXHAUSTED |
Excedeu a cota do usuário (RPM/TPM/RPD) | 1-5 minutos | aprox. 70% |
| Unavailable | 503 | Service unavailable |
Falha sistêmica ou manutenção | Indeterminado (pode levar horas) | aprox. 5% |
Análise do padrão de horários de erro do Gemini Nano Banana Pro
Períodos de pico de falhas
Com base em dados relatados por vários desenvolvedores, as falhas na API do Nano Banana Pro seguem um padrão de tempo bem claro:
Períodos de alto risco (Horário de Pequim – UTC+8):
- 00:00 – 02:00: Horário comercial da Costa Oeste dos EUA (08:00-10:00 PST), pico de desenvolvedores ocidentais.
- 09:00 – 11:00: Início do expediente na China, pico de desenvolvedores asiáticos.
- 20:00 – 23:00: Pico noturno na China + sobreposição com o período da tarde na Europa.
Períodos relativamente estáveis:
- 03:00 – 08:00: Período com o menor número de usuários globais.
- 14:00 – 17:00: Tarde na China + madrugada nos EUA, carga de processamento mais baixa.
Validação de caso: A falha em larga escala ocorrida em 16 de janeiro de 2026 às 00:18 (horário de Pequim) coincidiu exatamente com o horário de início de expediente na Costa Oeste dos EUA (15 de janeiro, 08:18 PST), confirmando a precisão desse padrão temporal.

5 maneiras de resolver erros do Gemini Nano Banana Pro
Método 1: Implementar uma estratégia de repetição com Exponential Backoff
Esta é a solução mais básica para lidar com erros 503. Abaixo está a lógica de repetição recomendada:
import time
import random
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def generate_image_with_retry(
prompt: str,
model: str = "gemini-3-pro-image-preview",
max_retries: int = 5,
initial_delay: int = 10
):
"""
Função de geração de imagem com exponential backoff
"""
for attempt in range(max_retries):
try:
response = client.images.generate(
model=model,
prompt=prompt,
timeout=120 # Aumenta o tempo de timeout
)
return response
except Exception as e:
error_msg = str(e)
# Erro 503: Repetição com exponential backoff
if "overloaded" in error_msg.lower() or "503" in error_msg:
if attempt < max_retries - 1:
delay = initial_delay * (2 ** attempt) + random.uniform(0, 5)
print(f"⚠️ Modelo sobrecarregado, tentando novamente em {delay:.1f}s (Tentativa {attempt + 1}/{max_retries})")
time.sleep(delay)
continue
else:
raise Exception("❌ Limite de tentativas atingido, o modelo continua sobrecarregado")
# Erro 429: Aguardar brevemente para tentar de novo
elif "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg:
print("⚠️ Limite de taxa atingido, tentando novamente em 60s")
time.sleep(60)
continue
# Outros erros: lança a exceção diretamente
else:
raise e
raise Exception("❌ Todas as tentativas falharam")
# Exemplo de uso
result = generate_image_with_retry(
prompt="A futuristic city at sunset, cyberpunk style",
max_retries=5
)
Ver código completo nível de produção
import time
import random
from typing import Optional, Dict
from openai import OpenAI
from datetime import datetime, timedelta
class GeminiImageClient:
"""
Cliente de geração de imagens Gemini nível produção
Suporta repetições, fallback e monitoramento
"""
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.error_log = []
self.success_count = 0
self.failure_count = 0
def generate_with_fallback(
self,
prompt: str,
primary_model: str = "gemini-3-pro-image-preview",
fallback_model: str = "gemini-2.5-flash-image",
max_retries: int = 3
) -> Dict:
"""
Geração de imagem com estratégia de fallback
"""
# Tenta o modelo principal
try:
result = self._generate_with_retry(prompt, primary_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": primary_model,
"data": result
}
except Exception as e:
print(f"⚠️ Falha no modelo principal {primary_model}: {str(e)}")
# Fallback automático para o modelo reserva
try:
print(f"🔄 Fazendo fallback para o modelo reserva {fallback_model}")
result = self._generate_with_retry(prompt, fallback_model, max_retries)
self.success_count += 1
return {
"success": True,
"model_used": fallback_model,
"fallback": True,
"data": result
}
except Exception as fallback_error:
self.failure_count += 1
self.error_log.append({
"timestamp": datetime.now(),
"primary_error": str(e),
"fallback_error": str(fallback_error)
})
return {
"success": False,
"error": str(fallback_error)
}
def _generate_with_retry(self, prompt: str, model: str, max_retries: int):
"""Lógica de repetição interna"""
for attempt in range(max_retries):
try:
response = self.client.images.generate(
model=model,
prompt=prompt,
timeout=120
)
return response
except Exception as e:
if attempt < max_retries - 1:
delay = 10 * (2 ** attempt) + random.uniform(0, 5)
time.sleep(delay)
else:
raise e
def get_stats(self) -> Dict:
"""Obter dados estatísticos"""
total = self.success_count + self.failure_count
success_rate = (self.success_count / total * 100) if total > 0 else 0
return {
"total_requests": total,
"success_count": self.success_count,
"failure_count": self.failure_count,
"success_rate": f"{success_rate:.2f}%",
"recent_errors": self.error_log[-5:]
}
# Exemplo de uso
client = GeminiImageClient(api_key="YOUR_API_KEY")
result = client.generate_with_fallback(
prompt="A magical forest with glowing mushrooms",
primary_model="gemini-3-pro-image-preview",
fallback_model="gemini-2.5-flash-image"
)
if result["success"]:
print(f"✅ Gerado com sucesso usando o modelo: {result['model_used']}")
else:
print(f"❌ Falha na geração: {result['error']}")
# Ver estatísticas
print(client.get_stats())
Sugestão Técnica: Em ambientes de produção reais, recomenda-se usar a plataforma APIYI (apiyi.com) para as chamadas de interface. Essa plataforma oferece uma interface de API unificada, suportando o Gemini 3 Pro e vários outros modelos de geração de imagem. Quando o Nano Banana Pro está sobrecarregado, é possível alternar rapidamente para o Gemini 2.5 Flash ou outros modelos de reserva, garantindo a continuidade do negócio.
Método 2: Aumentar o timeout e configurar a requisição
O tempo de resposta normal do Nano Banana Pro é de 20 a 40 segundos, mas sob sobrecarga pode chegar a 60-100 segundos ou mais. Um timeout padrão de 30 segundos causará muitos falsos positivos.
Configuração recomendada:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=120, # Aumenta o timeout global para 120 segundos
max_retries=3 # O SDK tenta novamente automaticamente 3 vezes
)
# Ou especifique em uma única requisição
response = client.images.generate(
model="gemini-3-pro-image-preview",
prompt="Seu comando aqui",
timeout=150 # Timeout de 150 segundos para esta requisição
)
Explicação dos parâmetros chave:
timeout: Tempo máximo de espera para uma única requisição; recomenda-se configurar entre 120 e 180 segundos.max_retries: Número de repetições automáticas na camada do SDK; recomenda-se 2 a 3 vezes.keep_alive: Mantém a conexão ativa para evitar que requisições longas sejam interrompidas.
Método 3: Evitar horários de pico
Se o seu negócio permitir o processamento assíncrono, agendar tarefas de acordo com o padrão de horários pode aumentar significativamente a taxa de sucesso:
Estratégia de agendamento recomendada:
- Tarefas de alta prioridade: Executar entre 03:00-08:00 ou 14:00-17:00 (Horário de Pequim).
- Tarefas de geração em lote: Usar filas de tarefas para execução automática em períodos de baixa carga.
- Tarefas em tempo real: Devem obrigatoriamente implementar estratégias de fallback e não depender de um único modelo.
Exemplo de agendamento de tarefas em Python:
from datetime import datetime
def is_peak_hour() -> bool:
"""Verifica se o horário atual é de pico (Horário de Pequim)"""
current_hour = datetime.now().hour
# Horários de pico: 0-2, 9-11, 20-23
peak_hours = list(range(0, 3)) + list(range(9, 12)) + list(range(20, 24))
return current_hour in peak_hours
def smart_generate(prompt: str):
"""Geração inteligente: fallback automático em horários de pico"""
if is_peak_hour():
print("⚠️ Estamos no horário de pico, usando modelo reserva")
model = "gemini-2.5-flash-image"
else:
model = "gemini-3-pro-image-preview"
return generate_image(prompt, model)
Método 4: Implementar estratégia de fallback de modelo
A recomendação oficial do Google é alternar para o Gemini 2.5 Flash ao encontrar sobrecarga. Veja a comparação de dados:
| Métrica | Gemini 3 Pro (Nano Banana Pro) | Gemini 2.5 Flash Image |
|---|---|---|
| Qualidade da Imagem | Máxima (9/10) | Excelente (7.5/10) |
| Velocidade de Geração | 20-40 segundos | 10-20 segundos |
| Estabilidade | 45% de falhas no pico | <10% de falhas no pico |
| Recuperação de Erro 503 | 30-120 minutos | 5-15 minutos |
| Custo da API | Mais alto | Mais baixo |
Sugestão de abordagem: Para cenários sensíveis à qualidade (pôsteres de marketing, fotos de produtos, etc.), priorize o Gemini 3 Pro e faça o fallback para o 2.5 Flash em caso de falha. Para cenários de alta concorrência (conteúdo UGC, protótipos rápidos), use o 2.5 Flash diretamente para garantir maior estabilidade. Recomenda-se realizar testes comparativos através da plataforma APIYI (apiyi.com), que suporta a troca de modelos com um clique e fornece dados comparativos de custo e qualidade.
Método 5: Sistemas de monitoramento e alerta
Ambientes de produção precisam de um monitoramento robusto para detectar e responder a falhas rapidamente:
Principais métricas de monitoramento:
- Taxa de sucesso: Sucesso nos últimos 5 minutos / 1 hora / 24 horas.
- Tempo de resposta: Tempos de resposta P50 / P95 / P99.
- Distribuição de erros: Proporção de erros 503 / 429 / 500, etc.
- Acionamentos de fallback: Quantas vezes o modelo principal falhou e exigiu a troca.
Implementação simples de monitoramento:
from collections import deque
from datetime import datetime
class APIMonitor:
"""Monitor de chamadas de API"""
def __init__(self, window_size: int = 100):
self.recent_calls = deque(maxlen=window_size)
self.error_counts = {"503": 0, "429": 0, "500": 0, "other": 0}
def log_call(self, success: bool, response_time: float, error_code: str = None):
"""Registra uma chamada de API"""
self.recent_calls.append({
"timestamp": datetime.now(),
"success": success,
"response_time": response_time,
"error_code": error_code
})
if not success and error_code:
if error_code in self.error_counts:
self.error_counts[error_code] += 1
else:
self.error_counts["other"] += 1
def get_success_rate(self) -> float:
"""Calcula a taxa de sucesso"""
if not self.recent_calls:
return 0.0
success_count = sum(1 for call in self.recent_calls if call["success"])
return success_count / len(self.recent_calls) * 100
def should_alert(self) -> bool:
"""Verifica se é necessário emitir um alerta"""
success_rate = self.get_success_rate()
# Dispara alerta se a taxa de sucesso for inferior a 70%
if success_rate < 70:
return True
# Dispara alerta se erros 503 ultrapassarem 30% das falhas
total_errors = sum(self.error_counts.values())
if total_errors > 0 and self.error_counts["503"] / total_errors > 0.3:
return True
return False
# Exemplo de uso
monitor = APIMonitor(window_size=100)
# Registra após cada chamada
start_time = time.time()
try:
result = client.images.generate(...)
response_time = time.time() - start_time
monitor.log_call(success=True, response_time=response_time)
except Exception as e:
response_time = time.time() - start_time
error_code = "503" if "overload" in str(e) else "other"
monitor.log_call(success=False, response_time=response_time, error_code=error_code)
# Verificação periódica de alertas
if monitor.should_alert():
print(f"🚨 Alerta: Taxa de sucesso da API caiu para {monitor.get_success_rate():.2f}%")
Detalhes de Cotas e Limites de Taxa da Gemini API
Ajuste de Cotas em Dezembro de 2025
Em 7 de dezembro de 2025, o Google ajustou os limites de cota da Gemini API, o que fez com que muitos desenvolvedores encontrassem erros 429 inesperados.
Padrões de Cota Atuais (Janeiro de 2026):
| Dimensão da Cota | Versão Gratuita (Free Tier) | Versão Paga Tier 1 | Descrição |
|---|---|---|---|
| RPM (Requisições por Minuto) | 5-15 (dependendo do modelo) | 150-300 | Gemini 3 Pro tem limites mais rígidos |
| TPM (Tokens por Minuto) | 32.000 | 4.000.000 | Aplicável a modelos de texto |
| RPD (Requisições por Dia) | 1.500 | 10.000+ | Pool de cotas compartilhado |
| IPM (Imagens por Minuto) | 5-10 | 50-100 | Exclusivo para modelos de geração de imagem |
Observações Importantes:
- Os limites de cota são baseados no nível do Google Cloud Project, e não em uma única API Key.
- Criar várias API Keys no mesmo projeto não aumentará sua cota.
- Ultrapassar o limite de qualquer uma das dimensões disparará um erro 429.
- A aplicação dos limites utiliza o algoritmo Token Bucket; picos de tráfego repentinos serão limitados.
Otimização de Custos: Para projetos sensíveis ao orçamento, você pode considerar chamar a Gemini API através da plataforma APIYI (apiyi.com). A plataforma oferece formas de pagamento flexíveis sob demanda, sem a necessidade de assinar o Google Cloud, o que é ideal para pequenas e médias equipes ou desenvolvedores individuais realizarem testes rápidos e implantações em pequena escala.
Perguntas Frequentes
Q1: Como diferenciar os erros 503 (overloaded) e 429 (rate limit)?
A diferença entre os dois está na causa raiz e no tempo de recuperação:
503 Overloaded:
- Mensagem de erro:
The model is overloaded. Please try again later. - Código de status HTTP: 503 Service Unavailable
- Causa raiz: Recursos de computação insuficientes no lado do servidor do Google; não tem relação com a sua cota.
- Tempo de recuperação: 30-120 minutos (Gemini 3 Pro), 5-15 minutos (Gemini 2.5 Flash).
- Estratégia de resposta: Tentar novamente com exponential backoff, alternar para um modelo de reserva ou evitar horários de pico.
429 Rate Limit:
- Mensagem de erro:
RESOURCE_EXHAUSTEDouRate limit exceeded - Código de status HTTP: 429 Too Many Requests
- Causa raiz: Suas chamadas de API excederam os limites de cota (RPM/TPM/RPD/IPM).
- Tempo de recuperação: 1-5 minutos (o pool de cotas se recupera automaticamente).
- Estratégia de resposta: Reduzir a frequência de requisições, atualizar para a versão paga ou solicitar aumento de cota.
Método de julgamento rápido: Verifique o uso de cotas no Google AI Studio. Se estiver próximo ou no limite, é 429; caso contrário, é 503.
Q2: Por que ocorreu uma falha em larga escala às 00:18 da madrugada?
A falha em larga escala que ocorreu às 00:18 (horário de Pequim) em 16 de janeiro de 2026 corresponde às 08:18 PST do dia 15 de janeiro na costa oeste dos EUA, exatamente no início do horário comercial americano.
Análise dos padrões de horário:
- Desenvolvedores da Costa Oeste dos EUA (Vale do Silício) começam a trabalhar entre 08:00 e 10:00 PST, o que corresponde às 00:00-02:00 no horário de Pequim.
- Pico de trabalho dos desenvolvedores europeus entre 14:00 e 18:00 CET, correspondendo às 21:00-01:00 no horário de Pequim.
- Picos dos desenvolvedores chineses entre 09:00-11:00 CST e 20:00-23:00 CST.
A sobreposição desses três períodos fez com que a carga da API Nano Banana Pro excedesse muito a capacidade, disparando erros 503 em massa.
Sugestão: Se o seu negócio for voltado principalmente para usuários na China, você pode agendar tarefas em lote para o período entre 03:00 e 08:00 (horário de Pequim), que coincide com a madrugada nos EUA e Europa, quando a carga global é mais baixa.
Q3: Como escolher o modelo ideal para o ambiente de produção?
Escolha sua estratégia de modelo com base nas necessidades do seu negócio:
Estratégia 1: Prioridade na Qualidade (Marketing, fotos de produtos)
- Modelo principal: Gemini 3 Pro Image Preview (Nano Banana Pro)
- Modelo de reserva: Gemini 2.5 Flash Image
- Implementação: O sistema degrada automaticamente para o modelo de reserva após 3 falhas no principal.
- Taxa de sucesso esperada: 92-95% (incluindo a degradação).
Estratégia 2: Prioridade na Estabilidade (UGC, alta concorrência)
- Modelo principal: Gemini 2.5 Flash Image
- Modelo de reserva: Outros modelos de geração de imagem (DALL-E 3, Stable Diffusion XL)
- Implementação: Usa o 2.5 Flash diretamente e alterna para modelos de terceiros em caso de falha.
- Taxa de sucesso esperada: 95-98%.
Estratégia 3: Prioridade no Custo (Testes, protótipos)
- Usar a versão gratuita do Gemini 2.5 Flash.
- Aceitar erros ocasionais de 429 e 503.
- Não implementar lógicas complexas de tolerância a falhas.
Solução Recomendada: Use a plataforma APIYI (apiyi.com) para testar rapidamente o efeito e o custo de diferentes modelos. A plataforma oferece uma interface unificada para chamar vários modelos de geração de imagem, facilitando a comparação e a alternância.
Resumo
Pontos centrais sobre os erros da API Gemini Nano Banana Pro:
- 503 Overloaded é um problema sistêmico: Não tem a ver com o seu código, é causado pela falta de recursos computacionais nos servidores do Google. Em horários de pico, até 45% das chamadas podem falhar.
- Padrões de horário claros: Os períodos entre 00:00-02:00, 09:00-11:00 e 20:00-23:00 (horário de Pequim) são de alto risco. É recomendável evitar esses horários ou implementar estratégias de fallback.
- A tolerância a falhas é essencial: É indispensável implementar três camadas de proteção: tentativas de reprocessamento com recuo exponencial (exponential backoff), aumento do tempo de timeout (120s+) e fallback de modelo (usar o 2.5 Flash como reserva).
- Monitoramento e alertas: Em ambientes de produção, você precisa monitorar a taxa de sucesso, o tempo de resposta e a distribuição de erros para identificar e reagir a falhas rapidamente.
- Entenda os limites de cota: O erro 429 está relacionado à sua cota de API específica, enquanto o erro 503 tem a ver com a carga geral da infraestrutura do Google. As estratégias para lidar com cada um são diferentes.
Como o Nano Banana Pro ainda é um modelo em fase de preview, os problemas de instabilidade dificilmente serão resolvidos de forma definitiva no curto prazo. Recomendamos usar o APIYI (apiyi.com) para validar rapidamente suas necessidades de geração de imagens. A plataforma oferece créditos gratuitos e uma interface unificada para vários modelos, suportando Gemini 3 Pro, Gemini 2.5 Flash, DALL-E 3 e outros principais Modelos de Linguagem Grande e de geração de imagem, garantindo a continuidade do seu negócio.
📚 Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome da fonte: domain.com. Isso facilita a cópia, mas os links não são clicáveis para evitar a perda de autoridade de SEO.
-
Guia de Solução de Problemas e Erros do Nano Banana: Manual completo de referência de erros
- Link:
www.aifreeapi.com/en/posts/nano-banana-errors-troubleshooting-guide - Descrição: Abrange soluções completas para todos os códigos de erro do Nano Banana Pro, incluindo 429, 502, 403 e 500.
- Link:
-
Fórum de Desenvolvedores do Google AI: Discussão sobre o erro "Gemini 3 Pro overloaded"
- Link:
discuss.ai.google.dev/t/gemini-3-pro-nano-banana-tier-1-4k-image-503-unavailable-error-the-model-is-overloaded/110232 - Descrição: Discussões em tempo real e compartilhamento de experiências da comunidade de desenvolvedores sobre o erro 503.
- Link:
-
Documentação Oficial de Limites de Taxa da API Gemini: Explicação sobre cotas e limites de velocidade
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Descrição: Documentação oficial do Google sobre cotas de API, incluindo detalhes sobre RPM/TPM/RPD/IPM.
- Link:
-
Códigos de Erro do Gemini 3 Pro Image Preview: Guia completo de códigos de erro
- Link:
www.aifreeapi.com/en/posts/gemini-3-pro-image-preview-error-codes - Descrição: Guia de identificação e resolução para todos os códigos de erro do Gemini 3 Pro para os anos de 2025-2026.
- Link:
Autor: Equipe Técnica
Troca de Experiências: Sinta-se à vontade para discutir suas experiências com a API Gemini na seção de comentários. Para mais materiais de suporte técnico, visite a comunidade técnica do APIYI em apiyi.com.