作者注:モデルの正規料金を維持し、安価な代替手段に頼ることなく、OpenClaw がどのように入力トークン数を制御してコストを削減しているかを詳しく解説します。新会話の分離タスク、全文投入に代わるコードブロックの精密検索、コンテキストの剪定、QMDローカル検索など、6つの主要戦略を紹介します。
OpenClaw はトークン消費が激しいことで有名です。あるユーザーは1日で2,150万トークンを消費し、月額利用料が600ドルを超えたという例もあります。多くの人はまず「より安価なモデルへ乗り換える」ことを考えますが、それでは品質が犠牲になってしまいます。真のトークン節約術は、入力側を制御することにあります。モデルにどれだけのコンテキストを与えるかこそが、コストを決定づける要因なのです。本記事では、「モデルを変えず、品質も落とさず、いかにして『全文投入』から『精密な入力』へと切り替えるか」という核心的な問題に焦点を当てます。
核心的価値: 本記事を読み終える頃には、入力トークンを制御するための6つの実践的戦略を習得し、トークンコストを50〜90%削減できるようになるでしょう。
OpenClaw トークン節約の核心ポイント
まず前提として、この記事で解説するのはモデルを変更せず、品質も落とさないトークン節約術です。Claude Opus 3.5 Sonnet や GPT-4o といった高性能なモデルをそのまま使いつつ、入力側のコストを抑える方法を紹介します。
| 戦略 | 節約率 | 難易度 | 核心的な考え方 |
|---|---|---|---|
| タスクごとの新規チャット | 60-80% | 低 | タスクごとに会話を分け、履歴の蓄積を防ぐ |
| コードブロックの精密検索 | 40-95% | 中 | 全文ではなく関連するコード断片のみを渡す |
| コンテキストの剪定 | 30-50% | 低 | 不要な会話履歴を手動または自動で削除する |
| QMD ローカル検索 | 80-90% | 中 | ローカルのベクトル検索を行い、関連箇所のみ送信する |
| プロンプトキャッシュ | 80-90%(入力コスト) | 低 | キャッシュを活用し、システムプロンプトの再送を避ける |
| Thinkingモードのオフ | 10-50倍 | 低 | 推論が不要なタスクでは思考モードをオフにする |
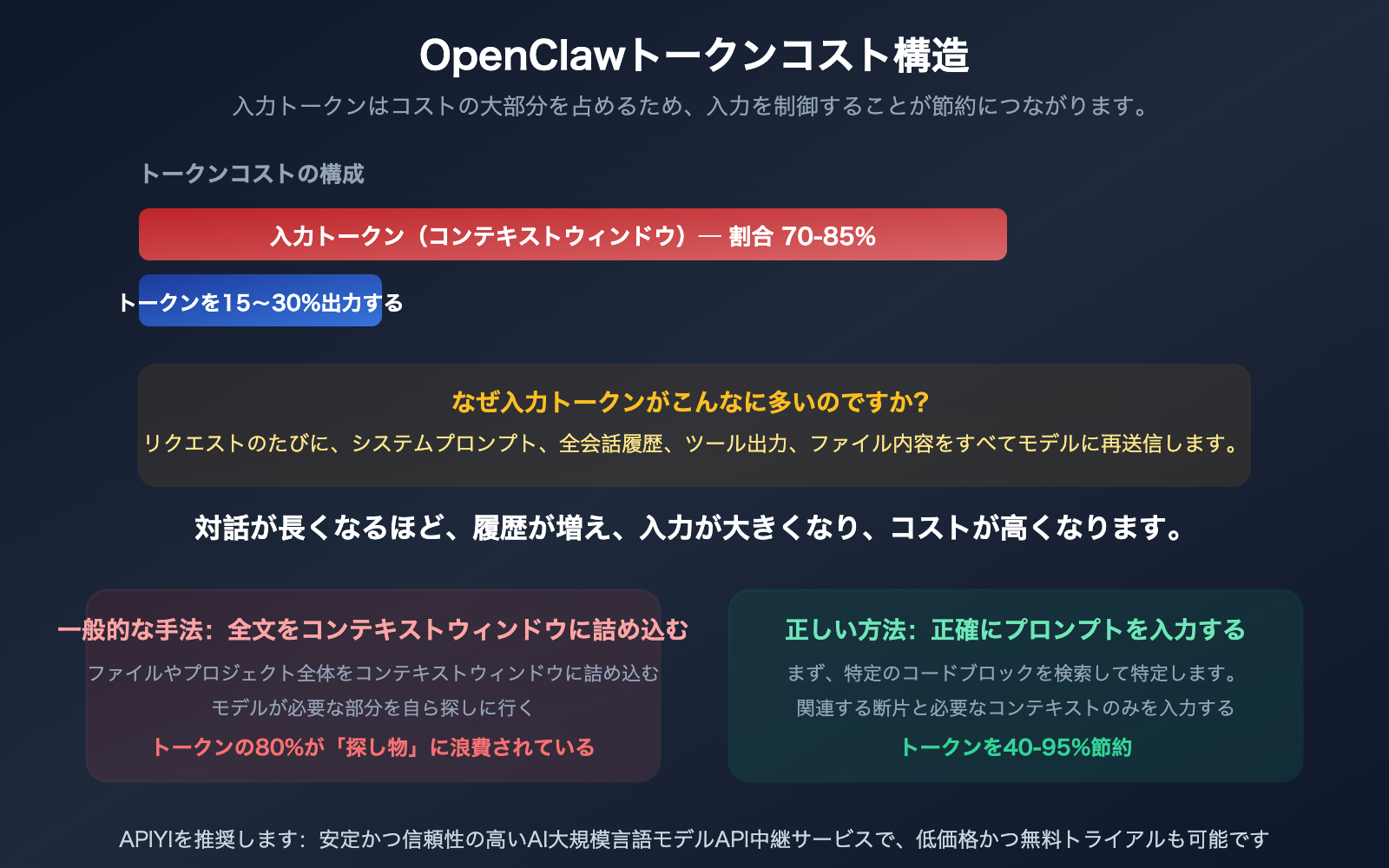
OpenClaw のトークン消費の仕組み
トークン節約の前提として、なぜ OpenClaw でトークンを消費してしまうのかを理解する必要があります。
OpenClaw でメッセージを送信する際、入力されるのは「そのメッセージだけ」ではありません。会話履歴のすべてがモデルに再送信されます。会話が長くなるほど、リクエストごとの入力トークン数は増大します。
具体的には、1回のリクエストには以下が含まれます:
- システムプロンプト:OpenClaw の核心的な指示。通常 2000〜5000 トークン
- AGENTS.md / SOUL.md:ワークスペースの設定ファイル
- 読み込まれたスキル:有効化されたスキルごとにトークンを消費
- 完全な会話履歴:開始から現在までのすべてのメッセージ
- ツール呼び出しの結果:ファイル読み込みやコマンド実行の出力
- メモリ検索結果:記憶ライブラリから検索された関連コンテンツ
30分間続いた OpenClaw のセッションでは、最後のメッセージの入力トークンが 10万〜100万に達することもあります。しかし、最初の29分間の内容のほとんどは、現在のタスクには不要なものです。
戦略1:OpenClaw でタスクごとに新規チャットを作成する
これは最もシンプルかつ効果的な戦略です。
なぜ新規チャットでトークンが節約できるのか
同じセッションで「バグAの修正 → 機能Bの実装 → モジュールCのリファクタリング」という3つのタスクを行ったとします。3つ目のタスクの時点で、モデルの入力には過去2つのタスクの全履歴とファイル読み込み結果が含まれてしまいますが、これらはモジュールCのリファクタリングには全く不要です。
同じセッションの場合:
タスクAの会話履歴(20K トークン)
+ タスクAのファイル内容(30K トークン)
+ タスクBの会話履歴(25K トークン)
+ タスクBのファイル内容(40K トークン)
+ タスクCの現在のメッセージ(5K トークン)
= 120K トークンの入力(うち 115K は不要な過去の遺産)
新規セッションの場合:
タスクCの現在のメッセージ(5K トークン)
+ システムプロンプト(3K トークン)
= 8K トークンの入力(93% 節約)
会話シーンにおけるベストプラクティス
| シーン | 新規チャットにするか? | 理由 |
|---|---|---|
| 全く異なるタスクへの切り替え | 新規作成 | 前のタスクのコンテキストは不要なため |
| 同一機能の反復調整 | 継続 | 前の議論のコンテキストが必要なため |
| 異なるファイルの別々のバグ修正 | 新規作成 | 各バグは独立しており、コンテキストの共有が不要なため |
| 同一モジュールの連続修正 | 継続 | 前の修正意図をモデルが理解する必要があるため |
| 会話が20往復を超えた場合 | 新規作成または圧縮 | 履歴が蓄積しすぎているため |
🎯 実践アドバイス: 簡単な判断基準は、「前のことは忘れて、別のことをしよう」と言いたくなったら、迷わず新規チャットを開くことです。
この原則は OpenClaw だけでなく、Claude Code や他の AI コーディングツールにも適用できます。APIYI (apiyi.com) を通じて呼び出す個別の API リクエストは、本質的に「新規セッション」であるため、コンテキスト蓄積の問題は発生しません。
戦略二:OpenClaw でコードブロックをピンポイント検索し、全文読み込みを避ける
これは本記事の核心です。AI にファイル全体やプロジェクト全体を読み込ませるのではなく、修正に必要なコードブロックだけを認識させるにはどうすればよいでしょうか?
問題の本質:「全文読み込み」がなぜ無駄なのか
調査データによると、AI コーディングエージェントが消費するトークンの 80% は「探し物」に浪費されています。典型的な例として、OpenClaw にある関数を修正するよう指示した際、AI は関連する 3 つの関数を見つけるためだけに 25 個ものファイルを読み込んでしまうことがあります。この 25 個分の読み込みトークンコストはすべてユーザーの負担となります。
1000 行のファイルは約 15,000〜25,000 トークンに相当します。もしそのうちの 20 行(約 300〜500 トークン)だけを修正すればよい場合、ファイル全体をモデルに渡すと、入力トークンの 96〜98% が無駄になっていることになります。
OpenClaw でコードブロックをピンポイント検索する 4 つの方法
方法一:ファイルと行番号を明示する
「ログイン機能を修正して」と指示するのではなく、「src/auth/login.ts の 45〜78 行目にある handleLogin 関数を修正して」と指示しましょう。指示が正確であればあるほど、OpenClaw が読み込むファイル数は少なくなります。
❌ 「ログインのバグを修正」
→ OpenClaw が 10 個以上のファイルを読み込み、200K 以上のトークンを消費
✅ 「src/auth/login.ts の 52 行目にある null ポインタチェックを修正」
→ OpenClaw が 1 ファイルの関連箇所のみを読み込み、約 20K トークンを消費
方法二:QMD ローカルセマンティック検索を活用する
OpenClaw の QMD(Quick Memory Database)は、ローカルでベクトルインデックスを作成できます。関連するコード断片を検索し、最も重要な内容だけをモデルに送信します。
有効化方法:OpenClaw の設定で QMD をオンにすると、プロジェクトファイルと会話履歴が自動的にインデックス化されます。その後のクエリでは、QMD がローカルで関連コードを特定し、正確に一致する断片のみをモデルに送信します。
方法三:@file 構文で直接参照する
OpenClaw では @file 構文を使用してファイルを正確に参照し、モデルによる無駄な検索を防ぐことができます。
@src/auth/login.ts 内の handleLogin 関数を修正し、
refreshToken の有効期限切れ処理ロジックを追加してください。
@src/auth/token.ts 内の isTokenExpired メソッドを参照してください。
このように指定すれば、OpenClaw は src/auth/ ディレクトリ全体をスキャンせず、指定した 2 つのファイルのみを読み込みます。
方法四:プロジェクト構造ファイルをガイドにする
AGENTS.md や SOUL.md にプロジェクト構造の概要を記載しておくと、OpenClaw が「どの機能がどのファイルにあるか」を把握でき、探索的なファイルスキャンを減らすことができます。
## プロジェクト構造
- 認証関連: src/auth/ (login.ts, token.ts, session.ts)
- ユーザー管理: src/user/ (profile.ts, settings.ts)
- API ルーティング: src/routes/ (auth.route.ts, user.route.ts)
この概要自体は数百トークン程度ですが、OpenClaw が数万トークンを消費するような盲目的なファイルスキャンを回避する助けになります。

戦略3〜6:OpenClawの高度なトークン節約テクニック
戦略3:コンテキスト剪定(Context Pruning)
OpenClawは、手動および自動のコンテキスト剪定をサポートしています。対話が長くなりすぎた場合、不要になった履歴メッセージを削除できます。
OpenClaw 2026.3.7では「Context Engine Plugins」が導入され、サードパーティ製プラグインによる代替のコンテキスト管理戦略が可能になりました(以前はコア機能にハードコードされていました)。lossless-clawプラグインを使用すれば、重要な情報を損なうことなく対話履歴を圧縮できます。
実践的なアドバイス:
- サブタスクが完了するたびに、不要なツール呼び出しの出力を手動でクリーンアップする
contextTokens: 50000を設定してコンテキストウィンドウのサイズを制限する- compact機能を使用して対話履歴を圧縮する
戦略4:QMDローカルセマンティック検索
QMD(Quick Memory Database)は、OpenClawのローカルベクトル検索機能です。ローカルデバイス上にベクトルデータベースを構築し、対話履歴やドキュメントをインデックス化します。クエリ実行時にまずローカルで関連コンテンツを検索し、最も関連性の高い断片のみをモデルに送信します。
効果:入力トークンコストを80〜90%削減できます。
戦略5:プロンプトキャッシュ(Prompt Caching)の活用
ClaudeおよびGPTモデルファミリーはプロンプトキャッシュをサポートしています。システムプロンプトや頻繁に使用するコンテキストに変更がない場合、APIは自動的にキャッシュされたバージョンを使用するため、入力トークンコストを80〜90%削減可能です。
ただし、重要な制限があります: OpenAI互換形式(/v1/chat/completions)経由でClaudeを呼び出す場合、プロンプトキャッシュはサポートされません。Anthropicのネイティブ形式(/v1/messages)を使用する必要があります。APIYI(apiyi.com)経由で呼び出す場合、プラットフォーム側でネイティブ形式のプロンプトキャッシュがサポートされています。
戦略6:非推論タスクでのThinkingモードのオフ
Thinking(推論)モードを有効にすると、トークン消費量が10〜50倍に急増します。現在のタスクに深い推論が不要な場合(単純なフォーマット調整、ファイルの移動、テキストの置換など)、Thinkingモードをオフにすることで大幅な節約が可能です。
| タスクタイプ | Thinkingの必要性 | トークンの違い |
|---|---|---|
| 複雑なバグ分析 | 必要 | 通常消費 |
| アーキテクチャ設計 | 必要 | 通常消費 |
| 単純なフォーマット調整 | 不要 | オフで10〜50倍節約 |
| ファイルの移動/名前変更 | 不要 | オフで10〜50倍節約 |
| ボイラープレートコード生成 | 場合による | 単純なテンプレートはオフ可 |
ヒント: Claude Codeの「Context Compaction」とOpenClawの「Context Pruning」は、どちらも「蓄積された入力トークンを制御する」という同じ課題を解決するためのものです。両方のツールを併用する場合は、APIYI(apiyi.com)を通じてAPI呼び出しの利用枠を一元管理できます。
OpenClawとClaude Codeのトークン節約比較
両ツールは同じ課題に直面していますが、解決策には違いがあります。

よくある質問
Q1: 新しいチャットを開始した際、モデルがプロジェクトの背景を理解していない場合はどうすればよいですか?
OpenClaw のメモリシステムと AGENTS.md ファイルを活用してください。メモリ機能は、新しいセッションにおいて関連するプロジェクトの背景情報を自動的に検索します(履歴全体ではなく、最も関連性の高い断片のみを送信します)。AGENTS.md にプロジェクトの構造や重要な規約を記述しておけば、新しいセッションごとに自動的に読み込まれます。これは、20ターン分の会話履歴をすべて引き継ぐよりもはるかに効率的です。
Q2: 現在のセッションでどれくらいのトークンを消費したか確認するには?
OpenClaw の会話ログは .openclaw/agents.main/sessions/ ディレクトリ内の JSONL ファイルに保存されており、リクエストごとのトークン数を確認できます。より便利な方法として、API プロバイダーの利用状況ダッシュボードを利用することをお勧めします。APIYI (apiyi.com) を経由して呼び出す場合、管理画面からリクエストごとの正確なトークン消費量と費用を確認できます。
Q3: QMD と grep による検索は何が違うのですか?
grep は完全一致検索です。「handleLogin」と検索すれば、その文字列が含まれる場所しか見つかりません。一方、QMD はセマンティック(意味的)検索です。「ユーザーログインのエラー処理」と検索すれば、たとえコード内に「ログイン」や「エラー処理」という文字列が含まれていなくても、意味的に関連するすべてのコードブロックを見つけ出します。セマンティック検索は精度が高く、モデルに渡す無関係なコンテンツを減らせるため、トークンの節約にもつながります。
Q4: なぜ Heartbeat(ハートビート)で大量のトークンが消費されるのですか?
OpenClaw の Heartbeat メカニズムは、定期的にタスクの状態を確認します。間隔を短く設定しすぎると(例:5分ごと)、心拍確認のたびに完全な会話コンテキストがモデルに送信されてしまいます。自動メールチェック機能で1日に50ドル消費してしまったというユーザーもいます。解決策は、心拍の間隔を長くすること、または自動監視が不要なときは Heartbeat を一時停止することです。
まとめ
モデルを変更せず、品質を落とさずに OpenClaw でトークンを節約するための核心ポイントは以下の通りです。
- 入力トークンがコストの大部分(70-85%)を占める: リクエストのたびに会話履歴全体を再送信すると、会話が長くなるほど高額になります。最も簡単な節約術は、タスクごとに新しいチャットを開始することです。
- コードブロックの正確な検索が最大のレバレッジ: 「全文を詰め込む」(120Kトークン)から「必要な部分だけを正確に与える」(4Kトークン)に変えるだけで、同じ修正でも96%の節約になります。具体的な方法は、ファイル行番号の指定、@file 参照、QMD セマンティック検索、AGENTS.md での構造宣言です。
- 3段階の最適化パス: 5分で効果が出る(新しいチャット + Thinkingをオフ、50%節約)→ 30分で効果が出る(正確な指示 + コンテキスト制限、80%節約)→ 長期的(QMD + キャッシュ活用、97%節約)。
OpenClaw の API 呼び出し管理には、APIYI (apiyi.com) を推奨します。プラットフォーム上で正確なトークン使用統計と費用監視ができるため、最適化のたびに実際の効果を数値で確認できます。
📚 参考資料
-
OpenClaw トークン使用とコスト管理ガイド: 公式トークン管理ドキュメント
- リンク:
docs.openclaw.ai/reference/token-use - 説明: contextTokens 設定およびハートビート最適化について解説
- リンク:
-
OpenClaw トークン節約の実践:$600 から $20 への削減: 3段階の完全最適化フレームワーク
- リンク:
blog.laozhang.ai/en/posts/openclaw-save-money-practical-guide - 説明: 具体的な設定パラメータと期待される削減率を掲載
- リンク:
-
AI コーディングエージェントのトークンの 80% は検索に浪費されている: コンテキスト精度の研究
- リンク:
medium.com/@jakenesler/context-compression-to-reduce-llm-costs - 説明: なぜコンテキストウィンドウを拡大するよりも、正確な検索の方が効果的であるかを解説
- リンク:
-
APIYI ドキュメントセンター: トークン使用量統計および費用監視
- リンク:
docs.apiyi.com - 説明: OpenClaw および Claude Code のモデル呼び出し管理をサポート
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料については、APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。