最近、OpenAIの公式CookbookがFractional AIと共同で、非常に本格的な実戦ケーススタディを公開しました。それは「AIによる経費精算書の自動審査」です。一見すると単純なOCRタスクのように思えますが、Notebookを開いてみると、これは「AIアプリケーションをデモから本番環境へ移行させる」ための方法論のバイブルであり、現在業界で最も注目されている**Eval-Driven System Design(評価駆動型システム設計)**の最も完全なオープンソース事例であることがわかります。
さらに興味深いのは、この方法論が解決しようとしているのが単なる技術的な問題ではなく、すべてのAIエンジニアを悩ませる根本的な問いであるという点です。それは、「自分が修正したプロンプトは、本当に改善されたのか? それとも改善されたように見えているだけなのか?」という問いです。本記事では、このOpenAIの領収書審査ケースを最も分かりやすい形で分解し、すべてのAIアプリケーション開発者に役立つ5つのエンジニアリングの知見を抽出します。
🎯 クイックガイド: この事例は、cookbook.openai.com の
eval_driven_system_designディレクトリにあります。著者はFractional AIチーム(Hugh Wimberly氏、Joshua Marker氏、Eddie Siegel氏)とOpenAIのShikhar Kwatra氏です。完全なコードはOpenAIの公式Cookbookリポジトリにあり、APIYI(apiyi.com)のようなOpenAI公式中継サービスを利用すれば、コードを一切変更することなくプロセス全体を再現できるため、国内の開発者が学習するのに最適です。
OpenAIの領収書審査ケースのビジネス背景:なぜこれが「本質的な問題」なのか
技術的な話に入る前に、このケースのビジネス背景を明確にしておきましょう。これはAPIをデモするためだけに作られたおもちゃのような問題ではなく、明確なROI(投資利益率)の数字を持つ、非常に現実的な企業シナリオです。
| ビジネス指標 | 具体的な数値 | 意味 |
|---|---|---|
| 年間処理量 | 約100万枚 | 中堅企業の典型的な規模 |
| AI処理単価 | $0.20 | モデル呼び出し費用 |
| 人手による審査単価 | $2.00 | 財務担当者による再確認 |
| 審査漏れ罰金 | $30 / 件 | コンプライアンス/税務上のペナルティ |
| 現在の人手審査率 | 5% | 難易度の高い書類のみ |
これらの数字を掛け合わせると、わずか1%の審査精度向上であっても、100万件という規模では年間数十万ドルの利益に直結することがわかります。これこそが、Fractional AIチームが繰り返し強調する「評価指標をドル(Dollar Impact)に結びつける」という考え方です。単に指標を競うのではなく、プロンプトの変更がビジネスの収支にどう影響するかを明確にするためです。
AIシステム全体の目標も非常に明確です。**「GPT-4oを使って大部分の書類を自動審査し、『信頼度が低い』少数の書類だけを人手に回す」**ことで、審査コストと審査漏れのリスクを同時に削減することです。シンプルに聞こえますが、悪魔は細部に宿るものです。
Eval-Driven Design とは:失敗から学ぶべき方法論
もし 100 人の AI エンジニアに「プロンプトの修正が正しいかどうか、どうやって検証していますか?」と聞いたら、99 人は「いくつか例を動かしてみて、出力の感じが良いか確認する」と答えるでしょう。これは Fractional AI チームが「vibe-coding(感覚ベースのコーディング)」と呼んで批判している手法であり、Eval-Driven Design(以下、EDD)が完全に取って代わろうとしている開発スタイルです。
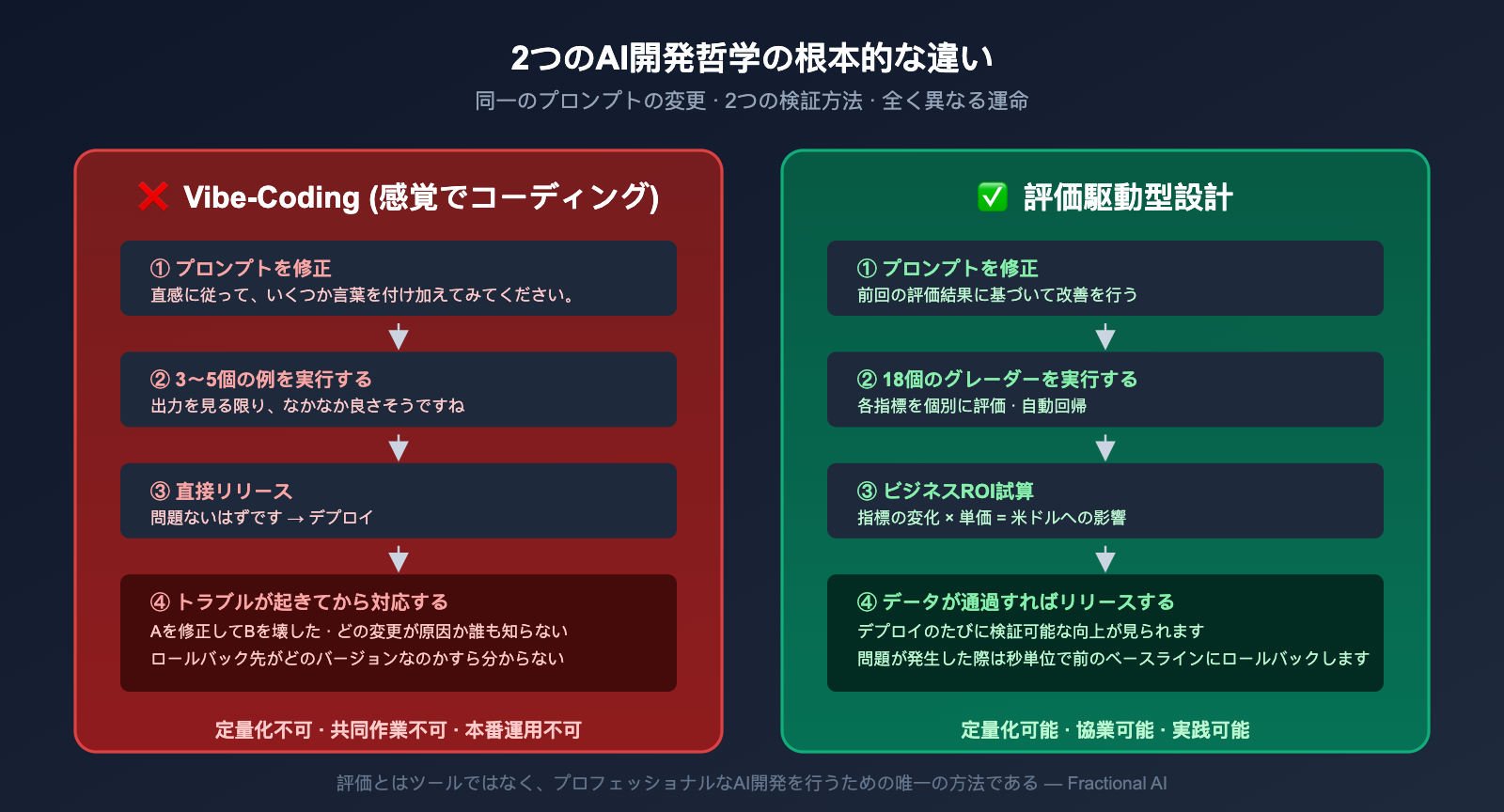
2 つの開発手法の違いは、以下の表で明確になります。
| 比較項目 | Vibe-Coding (感覚ベース) | Eval-Driven Design (評価駆動) |
|---|---|---|
| 検証方法 | 3~5 例の出力を見る | 20~100+ 件のラベル付きデータで指標算出 |
| 修正の判断 | 「良くなった気がする」 | 「正解率が 78% から 85% に向上」 |
| ビジネス整合性 | 重要かどうかは感覚次第 | 直接的にドル換算で影響を評価 |
| 回帰リスク | A の修正が B を壊しても気づかない | 全指標を自動で回帰テスト |
| 協調・拡張性 | 作成者しか理解できない | どのエンジニアでもデバッグ可能 |
Fractional AI の記事で広く引用されている言葉があります:「評価(Eval)はツールではなく、プロフェッショナルな AI 開発における唯一の道である」。大げさに聞こえるかもしれませんが、領収書審査のようなビジネスの核心に関わるシナリオでは、評価なしで運用することは「本番環境でのギャンブル」に等しく、誰も安心してリリースできません。
💡 例え話: Eval-Driven Design は試験に解答用紙があるようなものです。修正によって「合計点」がどれだけ上がったかを算出できます。一方、Vibe-Coding は勘で回答するようなもので、修正後に良くなったのか悪くなったのかさえ分かりません。プロダクションレベルの AI には、前者が必要です。
OpenAI の領収書審査ケースにおける 3 段階のプロセス
OpenAI Cookbook は、このケーススタディを 3 つの明確な段階に分けています。このプロセスは、「画像/ドキュメント入力 + 構造化された意思決定出力」というあらゆる AI アプリケーションに適用可能です。
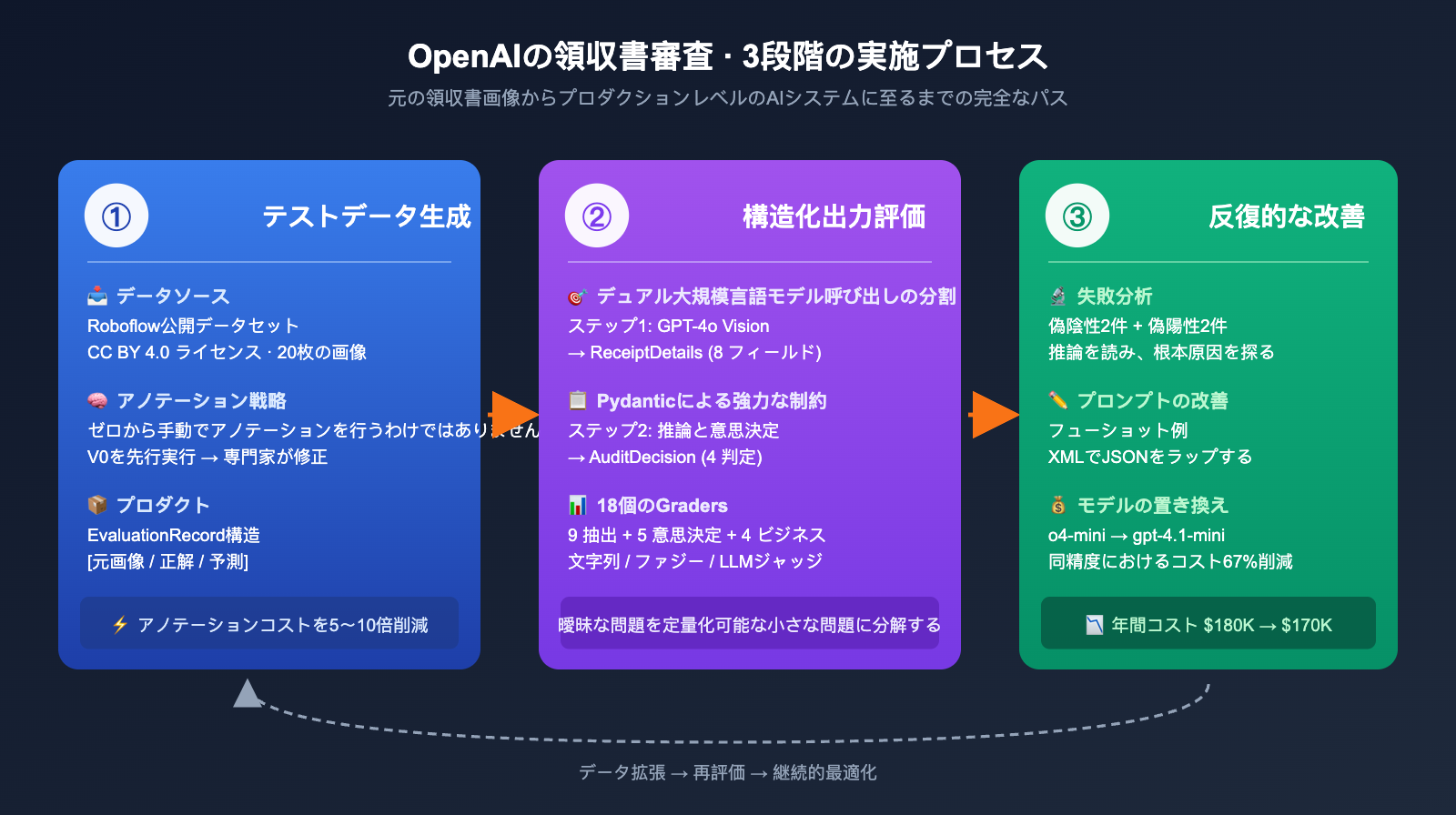
各段階を分かりやすく解説します。
段階一:テストデータの生成、賢く 80% のアノテーションコストを削減
もしチームがゼロから数千枚の領収書を手作業でアノテーションしていると思ったら、エンジニアの「効率化への執念」を過小評価しています。Fractional AI は非常に賢い戦略をとりました。まず V0 モデルで一度実行し、専門家が修正するという方法です。
具体的なフローはこうです:Roboflow の公開データセット(CC BY 4.0)から 20 枚の実際の領収書画像を取得し、シンプルな GPT-4o + Pydantic による抽出フローに流して V0 の出力を得ます。その後、財務の専門家がその出力に対して「間違い探しと修正」を行うことで、ゼロから入力する手間を省きました。
この「先に生成して後から修正する」手法により、専門家の作業効率は 5~10 倍に向上しました。ほとんどの項目は V0 が正しく認識できているため、専門家は間違っている部分だけを直せば良いためです。最終的に作成された EvaluationRecord のデータ構造も洗練されており、「画像のパス、正解の詳細、モデルの予測詳細、正しい審査結果、モデルの予測審査結果」を網羅し、パイプライン全体をカバーしています。
🔧 再利用のヒント: この「V0 で一度実行 → 専門家が修正」というアノテーション戦略は、ほぼすべての AI アプリケーションのコールドスタート期に適用可能です。APIYI のような OpenAI 官転 API プラットフォームを通じて素早く V0 出力を得ることで、専門家のリソースを最も価値のある判断プロセスに集中させることができます。
段階二:構造化出力の評価、Pydantic は真の英雄
AI システム全体は 2 回の LLM 呼び出しで構成されています。このような責務の分離は EDD の真髄の一つです。
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""ステップ1: 画像から構造化された領収書情報を抽出"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Pydantic モデルによる強力な制約
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""ステップ2: 構造化データに基づき審査の意思決定を行う"""
# ... LLM を呼び出し AuditDecision Pydantic モデルを出力
なぜ 2 ステップに分けるのでしょうか?それは、これらのタスクに求められる能力が全く異なるからです。**ステップ 1 は「画像認識と情報抽出」、ステップ 2 は「論理判断と意思決定」**です。これらを一つのプロンプトに混ぜると、モデルがタスクの境界を混同しやすくなるだけでなく、デバッグ時にどこでエラーが起きたのか特定できなくなります。
ReceiptDetails と AuditDecision という 2 つの Pydantic モデルのフィールド設計は、このケーススタディで最も学ぶべき点です。
| モデル | 主要フィールド | ビジネス上の意味 |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | 領収書から読み取れる全情報 |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 つの審査条件 + 推論プロセス + 最終結論 |
特に AuditDecision 内の reasoning フィールドに注目してください。これはモデルに対し、最終決定を下す前に推論プロセスを記述するよう強制するもので、後の Chain-of-Thought 評価において鍵となります。また、needs_audit は前述の 4 つの bool フィールドの論理 OR であり、このように「項目ごとに採点してから最終判断を合成する」設計にすることで、評価指標を細かく分解できます。
🚀 導入のヒント: 上記の
client.responses.parse()は OpenAI の最新の構造化出力インターフェースであり、Pydantic モデルを直接出力形式として指定できるため、JSON 解析失敗のリスクをほぼ完全に排除できます。SDK のバージョン要件があるため、APIYI のような OpenAI 官転 API プラットフォーム経由での呼び出しを推奨します。ゲートウェイがプロトコルの同期更新を保証します。
段階三:反復的な改善、18 個の Grader で修正を定量化
この段階こそ、EDD が真価を発揮する場所です。Fractional AI チームは、この領収書審査システムのために **18 個の独立した評価指標(Grader)**を設定し、「システムが良いか悪いか」という曖昧な問題を 18 個の定量化可能な小さな問題に分解しました。
これら 18 個の Grader は大きく 3 つに分類されます。
| Grader の種類 | 代表的な指標 | 評価方法 |
|---|---|---|
| 抽出精度 (9 個) | 店舗名 / 住所 / 合計金額の照合 | 文字列の完全一致 / あいまい一致 |
| 審査判断精度 (5 個) | 出張関連 / 上限超過 / 計算ミス / 手書きX検出 / 最終決定 | 二値分類の正解率 |
| ビジネス整合性 (4 個) | 商品の欠落 / 余剰商品 / 商品精度 / 推論品質 | LLM-as-Judge (0~10 点) |
初期評価では 20 件のサンプルで 2 件の偽陰性と 2 件の偽陽性が見つかりました。この数字は小さく見えますが、年間 100 万件の規模では数千件の審査漏れに相当します。Fractional チームはこれを非常にエンジニアリング的なアプローチで解決しました。
- 根本原因分析: 各エラーケースの reasoning フィールドを確認し、モデルがどの判断で詰まっているかを特定する。
- プロンプトの最適化: Few-shot 例の追加、「出張関連」の定義の明確化、JSON 例を XML で囲むなどの工夫を行う。
- 評価セットの再実行: 修正によって新たなバグが混入していないか検証する。
- モデルの入れ替え実験: 同じプロンプトを o4-mini と gpt-4.1-mini で実行し、ROI が高い方を選択する。
最後の結果は衝撃的でした。o4-mini から gpt-4.1-mini に切り替えることで、コストを 67% 削減し、年間コストを約 18 万ドルから 17 万ドルに下げつつ、精度はほとんど低下しませんでした。完全な評価セットがなければ、誰がこのようなコスト削減の決断を下せるでしょうか?
📊 重要な洞察: 18 個の Grader は数合わせではありません。「AI が正確かどうか」という測定不能に見える問題を、個別に修正・測定可能な 18 個の小さな問題に分解するためのものです。APIYI 上で OpenAI Evals API を呼び出すことで、同様の Grader システムを構築可能です。インターフェースは公式と完全に互換性があります。
OpenAI 領収書審査事例から学ぶ5つのエンジニアリングの教訓
この事例全体を通して、あらゆるAIアプリケーションに共通する5つの教訓を抽出しました。これらは、実際にコストをかけて得られた貴重な経験です。
教訓1:評価指標をドル(コスト)と紐付ける。すべての指標で100%を目指さない
事例の中には、非常に直感に反する発見がありました。それは、**「店舗名の認識精度を上げても、最終的な審査決定にはほとんど影響しない」**という点です。審査ルールが店舗名に依存していないためです。もしチームが店舗名の認識率を92%から98%に上げることに執着していたら、それはエンジニアリングリソースの無駄遣いになっていたでしょう。
対照的に、手書きの「X」の認識ミスは、年間約75,000ドルの審査漏れ損失を引き起こしていました。これこそが最優先すべき指標です。したがって、指標を選択する際は常に「このミスを修正することで、いくら節約できるのか?」という問いに答える必要があります。
教訓2:まずは最強のモデルで動かし、その後にコスト削減を考える
事例のV0フェーズでは、当時最強だったo4-miniが直接選ばれました。これはチームがコストを軽視していたからではなく、**「能力不足のモデルを無理やり動かすことは、能力過剰なモデルを安く動かすことよりも遥かに難しい」**と理解していたからです。まずはビジネスロジックを動かし、完全な評価体系を構築してからモデルの置き換え実験を行う。この順序を逆にしてはいけません。
教訓3:抽出と決定は必ず分離する。万能なプロンプトを欲張らない
多くの初心者は、「一度の呼び出しで画像から直接『審査が必要か否か』の結論を得れば、コストが節約できる」と考えがちです。しかし、この設計には2つの致命的な欠陥があります。デバッグができない(エラー時に画像の読み取りミスなのか、判断ロジックのミスなのかが不明)、再利用ができない(抽出結果がその一つの決定にしか使えない)という点です。2ステップに分けるとAPI呼び出し回数は増えますが、実際にはシステム全体の保守性が桁違いに向上します。
教訓4:Chain-of-Thought(思考の連鎖)評価で「正解だが理由は間違い」というリスクを摘み取る
AuditDecision内の冗長に見える reasoning フィールドは、評価時に危険な状況を特定するために使われます。それは、**「モデルは正しい最終回答を出したが、推論プロセスが間違っている」**というケースです。このような「まぐれ当たり」は小規模なサンプルでは見抜けませんが、データ分布が少し変わるだけで大規模な失敗につながります。推論結果の出力を強制し、LLM-as-Judge(LLMによる評価)で推論の質を評価することは、本番環境のAIアプリケーションにとって不可欠な保険です。
教訓5:アノテーションコストはエンジニアリングで削減できる
「AIプロジェクトには膨大なアノテーションデータが必要」という固定観念に縛られないでください。20件のデータ+専門家によるV0出力の修正という戦略で、有用な評価セットを構築できます。重要なのは評価セットと実際のビジネスデータの分布を一致させることであり、サンプル数を追求することではありません。Fractionalの経験では、初期のV0出力を「シードアノテーション」として活用することで、ゼロから手作業でアノテーションを行うよりも5〜10倍の効率向上が見込めます。
国内でOpenAIの領収書審査事例を再現する際の注意点
国内のエンジニアがこのクックブックを再現する場合、3つの問題を解決する必要があります。o4-mini / gpt-4.1-mini などの最新モデルが呼び出せるか、responses.parse という最新のインターフェースが使えるか、そしてEvals API エンドポイントが呼び出せるかです。
OpenAIに直接接続する場合、国内では通信が非常に不安定です。特に画像系のインターフェースはペイロードが大きいため、テキスト系インターフェースよりも失敗率が高くなります。APIYIのようなAPI中継サービスを利用すれば、これら3つの問題を一括で解決できます。必要なコードの変更は base_url の1行だけです。
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # 変更が必要なのはこの1行だけ
api_key="あなたの APIYI キー"
)
# 以降のすべてのコードはクックブックと完全に同一
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
これが「OpenAI公式転送API」と「OpenAI互換API」の決定的な違いです。前者はインターフェースがOpenAI公式と同期していることを保証しますが、後者は基本的なインターフェースのみの互換性にとどまることが多く、responses.parseやEvals APIのような高度な機能はサポートされていない場合があります。クックブックのような公式事例を再現する際は、公式転送ゲートウェイを選ぶことで、互換性による多くのトラブルを回避できます。
OpenAI 領収書審査ケーススタディ FAQ
Q1: この手法は領収書にしか使えませんか?
全くそんなことはありません。Eval-Driven Design(評価駆動設計)は、「入力が比較的オープンで、出力に構造化された意思決定が必要」なあらゆるシナリオに適用可能です。契約書審査、医療画像診断、カスタマーサポートの品質チェック、採用時の履歴書選別、不正検知など、すべてこの3段階のプロセスを応用できます。本質は Pydantic スキーマと評価用 Grader の設計にあります。
Q2: 18個の Grader は多すぎませんか?小規模チームでは手に負えません。
まずは5〜6個のコア Grader(例:最終的な意思決定の精度 + 主要フィールドの抽出精度など)から始めるのがおすすめです。重要なのは数ではなく、各 Grader が具体的な失敗パターンに対応していることです。まずは apiyi.com のコンソールで GPT-4o を使用し、少量のサンプルでテストを行い、ビジネスフローが確立してから評価項目を拡張していくことを推奨します。
Q3: V0 から o4-mini を使うと高くつきませんか?
V0 段階での呼び出し回数は通常数十〜数百回程度であり、総コストは数ドルから数十ドルに収まるため、十分に許容範囲内です。コスト削減を真剣に検討すべきなのは、本番環境での数百万回規模の呼び出し時です。その段階になれば、すでに完全な評価セットが構築されているため、モデルの置き換え実験が可能です。ケーススタディにあるように、o4-mini から gpt-4.1-mini へ移行することでコストを67%削減したような事例が参考になります。
Q4: GPT-4o Vision は手書きの中国語領収書を読み取れますか?
英語の印刷領収書の精度は非常に高く(95%以上)、中国語の印刷物も良好(90%以上)です。中国語の手書き文字については、筆跡の明瞭さに依存します。デモ動画を鵜呑みにせず、まずは100枚の実際のサンプルで評価セットを作成することをお勧めします。API を経由した GPT-4o Vision の呼び出しコストは公式と同一であり、大規模な評価実験に適しています。
Q5: Evals API の権限がない場合、このクックブックは実行できますか?
可能です。Evals API は主に Grader の設定と実行管理を OpenAI に委託するものですが、実際の評価ロジックは Python を使えばローカルでも全く同じように実行できます。クックブック内の Grader 関数はすべてオープンソースですので、コピーしてそのまま使用可能です。ビジネス規模が拡大した段階で、マネージドな Evals への移行を検討すれば問題ありません。
Q6: APIYI でこのケースを実行する場合、公式と何が違いますか?
インターフェースプロトコル、モデルバージョン、パラメータサポートはすべて OpenAI 公式と完全に同期しており、これが「公式転送(官転)」の核心的な約束です。主な違いはネットワーク層にあります。国内から OpenAI に直接接続すると、SSL ハンドシェイクの失敗やタイムアウトが頻発しますが、公式転送ゲートウェイは国内の IDC にデプロイされているため、特に画像関連のインターフェースにおいて安定性が大幅に向上します。これは長時間にわたる評価タスクを実行する上で非常に重要です。
まとめ
OpenAI 領収書審査のケーススタディが繰り返し読む価値があるのは、「AI でビジネス上の課題を解決する」という抽象的な命題を、3つの段階、18の評価指標、そしてドル単位で算出可能な具体的なエンジニアリング実践へと分解しているからです。これは現在の中国語圏コミュニティにおいて最も不足している AI エンジニアリングの模範例です。
「文書や画像の入力から構造化された意思決定を出力する」AI アプリケーションを開発しているなら、このクックブックを最初から最後まで実行することを強くお勧めします。見るだけでなく実際に手を動かしてください。Eval-Driven Design の真の価値は、指標が変化する瞬間を目の当たりにした時に初めて実感できます。apiyi.com のような OpenAI 公式転送 API プラットフォームを活用して再現すれば、環境構築の手間を省き、方法論そのものに集中することができます。
「評価駆動」という言葉を開発プロセスに刻み込めば、あなたの AI システムは「それっぽく動くおもちゃ」から、「本番環境に投入し、ROI を算出できる」エンジニアリング成果物へと進化します。その差は、75,000ドルに相当するかもしれません。
📌 著者: APIYI Team — OpenAI / Anthropic / Google のマルチモーダル API のエンジニアリング実践を長期的に追跡しています。その他のクックブックの実践解説や公式転送 API の接続ガイドは apiyi.com のドキュメントセンターをご覧ください。





