Le Cookbook officiel d'OpenAI, en collaboration avec Fractional AI, a récemment publié un cas pratique extrêmement pointu : l'automatisation de la vérification des notes de frais par IA. Si cela ressemble à une simple tâche d'OCR au premier abord, le notebook révèle en réalité une véritable "bible" méthodologique sur la manière de faire passer une application IA du stade de prototype à celui de production. C'est l'exemple open-source le plus complet à ce jour sur l'Eval-Driven System Design (conception de système pilotée par l'évaluation), un sujet brûlant dans l'industrie.
Ce qui est fascinant, c'est que cette méthodologie ne résout pas seulement un problème technique, mais répond à la question fondamentale qui hante tous les ingénieurs IA : comment savoir si ma modification d'invite (prompt) a réellement amélioré le système, ou si elle donne seulement cette impression ? Cet article décortique cet exemple de vérification de reçus d'OpenAI pour en extraire 5 leçons d'ingénierie essentielles pour tout développeur d'applications IA.
🎯 Guide rapide : Ce cas provient du répertoire
eval_driven_system_designsur cookbook.openai.com, rédigé par l'équipe de Fractional AI (Hugh Wimberly, Joshua Marker, Eddie Siegel) et Shikhar Kwatra d'OpenAI. Le code complet est disponible sur le dépôt officiel du Cookbook d'OpenAI. Vous pouvez reproduire l'intégralité du processus sans aucune modification en utilisant une passerelle comme APIYI (apiyi.com), ce qui est idéal pour les développeurs francophones.
Contexte métier : pourquoi est-ce un vrai problème ?
Avant de plonger dans la technique, clarifions le contexte commercial. Il ne s'agit pas d'un projet gadget pour démontrer une API, mais d'un scénario d'entreprise réel avec un retour sur investissement (ROI) chiffré.
| Dimension métier | Chiffres clés | Signification |
|---|---|---|
| Volume annuel | ~ 1 million | Échelle typique d'une ETI |
| Coût IA par reçu | 0,20 $ | Frais d'invocation du modèle |
| Coût vérification humaine | 2,00 $ | Révision par un comptable |
| Amende par erreur | 30 $ / reçu | Sanctions fiscales/conformité |
| Taux de révision actuel | 5 % | Uniquement pour les cas complexes |
Si vous faites le calcul, vous verrez qu'une amélioration de seulement 1 % de la précision de la vérification, appliquée à un volume d'un million de reçus, représente plusieurs centaines de milliers de dollars d'économies annuelles. C'est ce que l'équipe de Fractional AI appelle "lier les indicateurs d'évaluation à l'impact financier (Dollar Impact)" : il ne s'agit pas de gonfler des scores, mais de s'assurer que chaque modification d'invite se traduit directement dans les comptes de l'entreprise.
L'objectif du système est clair : utiliser GPT-4o pour vérifier automatiquement la majorité des reçus et ne transmettre à l'humain que les cas à "faible confiance", afin de réduire à la fois les coûts de traitement et les risques d'erreurs. Cela semble simple, mais le diable se cache dans les détails.
Qu'est-ce que l'Eval-Driven Design : une méthodologie que l'on ne comprend qu'après avoir essuyé des plâtres
Si vous demandez à 100 ingénieurs en IA "comment vérifiez-vous que votre invite est correcte ?", 99 d'entre eux vous répondront : "je lance quelques exemples et je regarde si le résultat semble bon". C'est ce que l'équipe de Fractional AI critique sous le nom de vibe-coding (développement au feeling), et c'est précisément la méthode que l'Eval-Driven Design (ci-après EDD) cherche à remplacer totalement.

Les différences entre ces deux approches peuvent être résumées dans le tableau suivant :
| Dimension de comparaison | Vibe-Coding (au feeling) | Eval-Driven Design (piloté par l'évaluation) |
|---|---|---|
| Méthode de vérification | Exécuter 3-5 exemples et observer | Exécuter 20-100+ échantillons annotés et calculer des métriques |
| Jugement des changements | "Ça semble s'être amélioré" | "La précision est passée de 78 % à 85 %" |
| Alignement métier | Basé sur le ressenti | Converti directement en impact financier |
| Risque de régression | Modifier A peut casser B sans que personne ne le sache | Suite complète de métriques exécutée automatiquement |
| Scalabilité de la collaboration | Seul l'auteur original comprend | N'importe quel ingénieur peut déboguer |
Une phrase de Fractional AI est largement citée : "L'évaluation n'est pas un outil, c'est la seule façon de faire du développement IA professionnel". Cela peut sembler exagéré, mais dans des scénarios critiques comme la vérification de reçus, l'absence d'évaluations revient à jouer à la loterie en production. Personne n'ose déployer sereinement dans ces conditions.
💡 Analogie : L'Eval-Driven Design est comme un examen avec un corrigé : vous pouvez calculer précisément de combien chaque modification a augmenté votre "note globale". Le Vibe-Coding, c'est comme répondre aux questions au feeling : une fois terminé, vous ne savez pas si vous avez progressé ou régressé. Une IA de niveau production doit impérativement adopter la première approche.
Processus de mise en œuvre en trois étapes pour l'audit de reçus OpenAI
Le livre de recettes OpenAI (OpenAI Cookbook) décompose l'ensemble du cas d'utilisation en trois étapes très claires. Ce processus peut être appliqué à presque n'importe quelle application d'IA impliquant une « entrée image/document + décision structurée ».
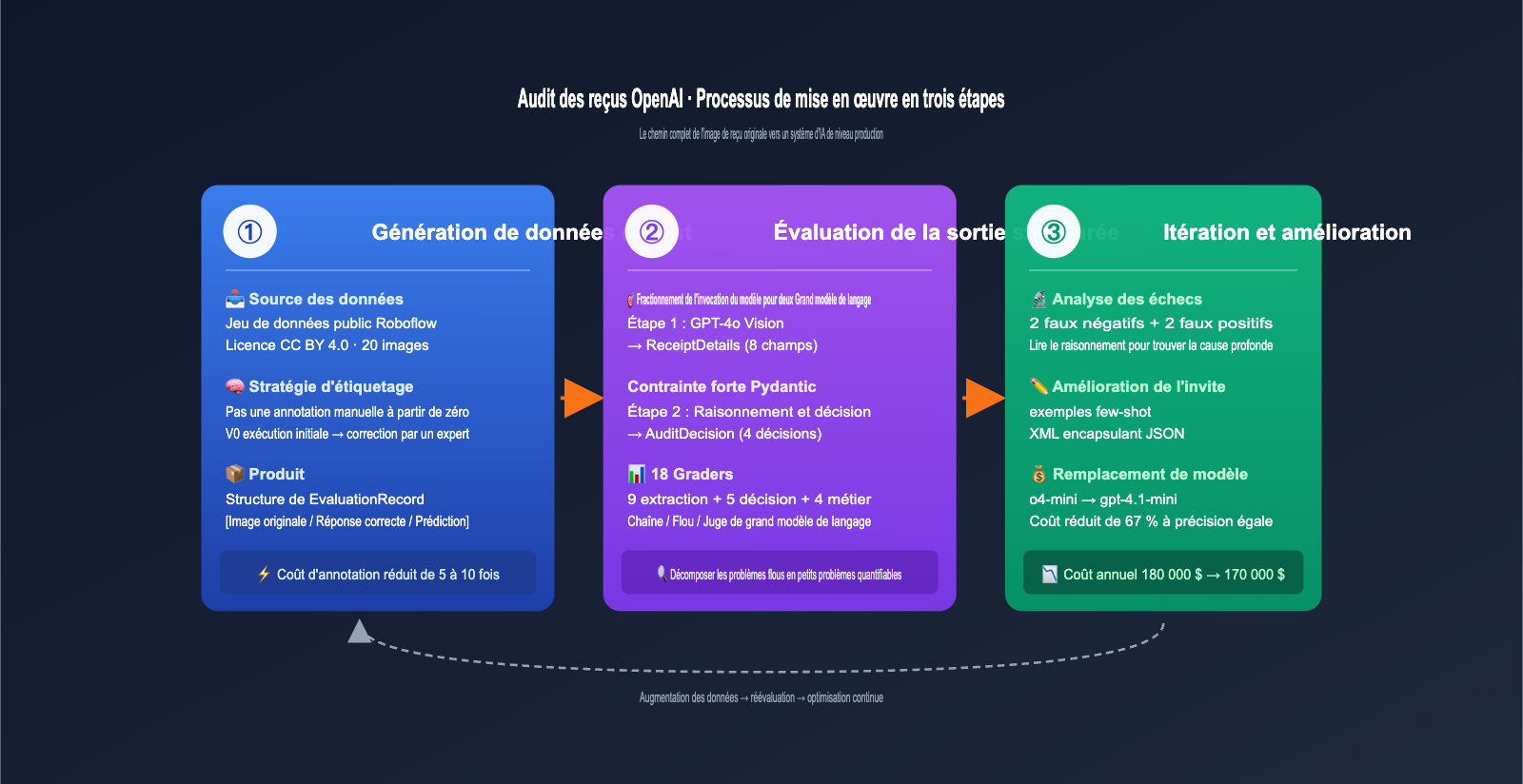
Voici une explication simple de chaque étape.
Étape 1 : Génération de données de test, économisez intelligemment 80 % des coûts d'annotation
Si vous pensez que l'équipe a commencé par annoter manuellement des milliers de reçus, vous sous-estimez la capacité des ingénieurs à optimiser leur travail. Fractional AI a utilisé une stratégie très astucieuse : laisser d'abord le modèle V0 traiter les données, puis laisser les experts corriger.
Le processus est le suivant : ils ont pris 20 reçus réels du jeu de données public Roboflow (licence CC BY 4.0) et les ont soumis à un flux d'extraction simple GPT-4o + Pydantic pour obtenir les résultats V0. Ensuite, ils ont demandé à des experts financiers de « corriger les erreurs » sur cette base, plutôt que de saisir les données de zéro.
Cette méthode « générer puis corriger » a multiplié par 5 à 10 l'efficacité des experts, car la plupart des champs étaient déjà correctement identifiés par la V0. La structure de données EvaluationRecord produite est également élégante : elle enregistre simultanément le chemin de l'image, les détails corrects, les prédictions du modèle, la décision d'audit correcte et la décision prédite, couvrant ainsi toute la chaîne de traitement.
🔧 Conseil de réutilisation : Cette stratégie d'annotation « V0 d'abord → correction par expert » peut être appliquée à presque toutes les phases de démarrage à froid d'une application d'IA. Il vous suffit d'exécuter rapidement une sortie V0 via une plateforme de service proxy API comme APIYI, afin de concentrer l'énergie de vos experts sur les jugements à haute valeur ajoutée.
Étape 2 : Évaluation de la sortie structurée, Pydantic est le véritable héros
L'ensemble du système d'IA est composé de deux invocations de LLM enchaînées. Cette conception de séparation des responsabilités est l'une des essences de l'EDD (Evaluation-Driven Development).
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Étape 1 : Extraire les informations structurées du reçu depuis l'image"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Contrainte forte du modèle Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Étape 2 : Prendre une décision d'audit basée sur les données structurées"""
# ... Appel du LLM pour sortir le modèle Pydantic AuditDecision
Pourquoi diviser cela en deux étapes ? Parce que ces deux tâches exigent des capacités totalement différentes : la première est la « lecture d'image » (vision + extraction d'informations), la seconde est le « raisonnement logique » (décision). Mélanger ces deux tâches dans une même invite (prompt) rend non seulement le modèle confus sur les limites de la tâche, mais rend également le débogage impossible.
La conception des champs des modèles Pydantic ReceiptDetails et AuditDecision est la partie la plus instructive de ce cas :
| Modèle | Champs clés | Signification métier |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Toutes les informations visibles sur le reçu |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 conditions d'audit + processus de raisonnement + conclusion finale |
Portez une attention particulière au champ reasoning dans AuditDecision : il force le modèle à rédiger son processus de raisonnement avant de donner sa décision finale. C'est la clé pour l'évaluation ultérieure de la chaîne de pensée (chain-of-thought). Notez également que needs_audit est un OU logique des quatre champs booléens précédents. Cette conception « noter d'abord, synthétiser ensuite » permet de décomposer les indicateurs d'évaluation très finement.
🚀 Conseil d'intégration : La fonction
client.responses.parse()ci-dessus est la toute dernière interface de sortie structurée d'OpenAI. Elle permet d'utiliser directement un modèle Pydantic comme contrainte de format de sortie, éliminant presque totalement le risque d'échec d'analyse JSON. Nous recommandons d'utiliser une plateforme de service proxy API comme APIYI pour ces appels, car cette interface nécessite des versions spécifiques du SDK, et la passerelle APIYI garantit une synchronisation constante avec les mises à jour des protocoles.
Étape 3 : Itération et amélioration, 18 évaluateurs pour quantifier chaque changement
C'est ici que l'EDD brille vraiment. L'équipe de Fractional AI a mis en place 18 indicateurs d'évaluation indépendants (graders) pour ce système d'audit, décomposant la question vague « le système est-il bon ? » en 18 questions quantifiables.
Ces 18 évaluateurs se divisent en trois catégories :
| Type d'évaluateur | Indicateurs représentatifs | Méthode d'évaluation |
|---|---|---|
| Précision d'extraction (9) | Nom du marchand / Adresse / Correspondance du montant total | Correspondance exacte / floue |
| Précision de la décision (5) | Détection de voyage / Dépassement de limite / Erreur de calcul / Identification manuscrite / Décision finale | Précision de classification binaire |
| Alignement métier (4) | Articles manquants / Articles en trop / Précision des articles / Qualité du raisonnement | LLM-as-Judge (note de 0 à 10) |
L'évaluation initiale sur 20 échantillons a révélé 2 faux négatifs + 2 faux positifs. Ce chiffre semble faible, mais à l'échelle d'un million de reçus par an, cela représente des milliers d'audits manqués. L'approche de l'équipe Fractional a été très rigoureuse :
- Analyse des causes profondes : Examiner le champ reasoning de chaque erreur pour identifier où le modèle bloque.
- Amélioration ciblée du prompt : Ajout d'exemples (few-shot), définition claire de ce qui est « lié au voyage », et encapsulation des exemples JSON dans des balises XML.
- Réexécution de l'ensemble d'évaluation : Vérifier que les changements corrigent réellement le bug sans en introduire de nouveaux.
- Expériences de remplacement de modèle : Exécuter le même prompt sur o4-mini et gpt-4.1-mini pour choisir le meilleur ROI.
Le résultat final est impressionnant : le passage de o4-mini à gpt-4.1-mini a réduit les coûts de 67 %, faisant passer le coût annuel d'environ 180 000 $ à 170 000 $, sans aucune perte de précision. Sans un ensemble d'évaluation complet, qui oserait prendre une telle décision de réduction des coûts ?
📊 Aperçu clé : Les 18 évaluateurs ne sont pas là pour faire du nombre, mais pour décomposer un problème apparemment inquantifiable (« l'IA est-elle précise ? ») en 18 petits problèmes mesurables et réparables individuellement. Vous pouvez également créer un système d'évaluateurs similaire en utilisant l'API OpenAI Evals via APIYI, avec une interface totalement compatible avec l'officielle.
5 enseignements techniques tirés du cas d'audit de reçus d'OpenAI
Après avoir analysé l'intégralité de ce cas, j'en ai extrait 5 enseignements universels pour toute application d'IA. Ce sont des leçons apprises à grands frais.
Enseignement 1 : Liez l'évaluation aux dollars, ne visez pas 100 % sur tous les indicateurs
Le cas révèle une découverte contre-intuitive : l'amélioration de la précision de reconnaissance du nom du commerçant n'a quasiment aucun impact sur la décision finale d'audit, car les règles d'audit ne dépendent pas du nom du commerçant. Si une équipe s'obstine à faire passer la reconnaissance du nom de 92 % à 98 %, elle gaspille des ressources d'ingénierie.
À l'inverse, les erreurs de reconnaissance des "X" manuscrits entraînent une perte annuelle d'environ 75 000 $ en audits manqués. C'est là que se situe la priorité absolue. Le choix des indicateurs doit donc toujours répondre à une question : "Combien d'argent puis-je économiser en corrigeant cette erreur ?"
Enseignement 2 : Commencez par le modèle le plus puissant, puis pensez aux économies
Dans la phase V0 du projet, l'équipe a choisi directement o4-mini, le modèle le plus performant à l'époque. Ce n'était pas par manque de souci du coût, mais parce qu'ils savaient qu'il est bien plus difficile de faire fonctionner un modèle sous-dimensionné que de faire fonctionner un modèle surdimensionné de manière économique. Validez d'abord la logique métier et établissez un système d'évaluation complet avant de lancer des tests de remplacement de modèle. L'ordre ne doit pas être inversé.
Enseignement 3 : Séparez l'extraction de la décision, ne cherchez pas à écrire une invite universelle
Beaucoup de débutants pensent : "Je peux obtenir la conclusion 'audit requis ou non' directement à partir de l'image en un seul appel, quelle économie !" Mais cette conception a deux défauts fatals : l'impossibilité de déboguer (en cas d'erreur, on ne sait pas si c'est l'analyse de l'image ou la logique de décision qui a échoué) et l'impossibilité de réutiliser (le résultat de l'extraction ne sert qu'à cette seule décision). Diviser le processus en deux étapes peut sembler ajouter un appel API, mais cela améliore considérablement la maintenabilité du système.
Enseignement 4 : L'évaluation par chaîne de pensée (Chain-of-Thought) permet de détecter les "bonnes réponses pour les mauvaises raisons"
Le champ reasoning dans AuditDecision, qui semble redondant, est utilisé lors de l'évaluation pour identifier une situation dangereuse : le modèle donne la bonne réponse finale, mais le processus de raisonnement est erroné. Cette "réussite par chance" est invisible sur de petits échantillons, mais elle provoque des échecs massifs dès que la distribution des données change légèrement. Forcer la sortie du raisonnement et utiliser une évaluation "LLM-as-Judge" sur la qualité de ce raisonnement est une assurance indispensable pour les applications d'IA en production.
Enseignement 5 : Le coût de l'étiquetage peut être réduit par l'ingénierie
Ne vous laissez pas effrayer par le cliché selon lequel "les projets d'IA nécessitent des quantités massives de données étiquetées". Une stratégie consistant à utiliser 20 exemples corrigés par des experts sur la sortie V0 suffit à construire un ensemble d'évaluation utile. L'essentiel est de s'assurer que l'ensemble d'évaluation correspond à la distribution réelle des données métier, plutôt que de viser la quantité. L'expérience de Fractional montre que l'utilisation des sorties V0 initiales comme "étiquettes de départ" est 5 à 10 fois plus efficace qu'un étiquetage manuel à partir de zéro.
Précautions pour reproduire le cas d'audit de reçus d'OpenAI en Chine
Pour reproduire ce cookbook, les développeurs en Chine doivent résoudre trois problèmes : l'accès aux nouveaux modèles comme o4-mini / gpt-4.1-mini, l'utilisation de l'interface la plus récente responses.parse, et la connectivité avec le point de terminaison de l'API Evals.
La connexion directe à OpenAI est très instable en Chine, surtout pour les interfaces liées aux images, car la charge utile (payload) est importante et le taux d'échec est plus élevé que pour les interfaces textuelles. L'utilisation d'une passerelle API proxy officielle permet de résoudre ces trois problèmes en une seule étape. Il suffit de modifier une ligne pour le base_url :
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # La seule ligne à modifier
api_key="Votre clé API APIYI"
)
# Tout le code suivant est identique au cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
C'est là que réside la différence clé entre une "passerelle API officielle OpenAI" et une "API compatible OpenAI" : la première garantit une synchronisation parfaite avec les interfaces officielles d'OpenAI, tandis que la seconde ne prend en charge que les interfaces de base. Des capacités avancées comme responses.parse ou l'API Evals peuvent ne pas être supportées par ces dernières. Lors de la reproduction de cas officiels comme ce cookbook, choisir une passerelle officielle permet d'éviter de nombreux problèmes de compatibilité.
FAQ sur le cas d'audit de reçus avec OpenAI
Q1 : Cette méthode est-elle limitée aux seuls reçus ?
Absolument pas. La conception pilotée par l'évaluation (Eval-Driven Design) s'applique à tout scénario où "l'entrée est relativement ouverte et la sortie nécessite une décision structurée" : audit de contrats, tri d'imagerie médicale, contrôle qualité du service client, filtrage de CV ou détection de fraude. Le principe reste le même : il suffit d'adapter le schéma Pydantic et la conception des évaluateurs (graders).
Q2 : 18 évaluateurs, n'est-ce pas trop pour une petite équipe ?
Vous pouvez commencer avec 5 à 6 évaluateurs clés, comme la précision de la décision finale et la précision de l'extraction des champs critiques. Ce qui compte n'est pas le nombre, mais le fait que chaque évaluateur corresponde à un mode d'échec spécifique. Nous vous suggérons de tester un petit échantillon avec GPT-4o sur la console apiyi.com, puis d'élargir les dimensions d'évaluation une fois le processus métier stabilisé.
Q3 : Utiliser o4-mini dès la version V0 ne coûte-t-il pas trop cher ?
Au stade V0, le volume d'appels est généralement de quelques dizaines à quelques centaines, pour un coût total de quelques dollars à quelques dizaines de dollars, ce qui est tout à fait abordable. Les économies réelles se font sur les millions d'appels en production ; à ce stade, vous disposerez d'un jeu d'évaluation complet pour tester le remplacement de modèles, comme dans l'exemple où le passage de o4-mini à gpt-4.1-mini a permis une réduction de 67 % des coûts.
Q4 : Quelle est l'efficacité de GPT-4o Vision sur les reçus manuscrits en chinois ?
La précision sur les reçus imprimés en anglais est très élevée (plus de 95 %), et elle est également bonne pour le chinois imprimé (plus de 90 %). Pour le chinois manuscrit, cela dépend de la lisibilité. Nous vous conseillons de constituer un jeu d'évaluation avec 100 échantillons réels plutôt que de vous fier aux vidéos de démonstration. Le coût de l'invocation de GPT-4o Vision via une API proxy est identique à celui de l'API officielle, ce qui est idéal pour les tests d'évaluation à grande échelle.
Q5 : Puis-je exécuter ce cookbook si je n'ai pas accès à l'API Evals ?
Oui. L'API Evals sert principalement à déléguer la configuration et la gestion des évaluateurs à OpenAI, mais la logique d'évaluation réelle peut être exécutée localement en Python avec le même résultat. Les fonctions d'évaluation du cookbook sont open source ; vous pouvez les copier et les utiliser localement. Si votre volume d'activité augmente, vous pourrez envisager une migration vers l'API Evals managée.
Q6 : Quelle est la différence entre utiliser ce cas via APIYI et passer par l'API officielle ?
Le protocole d'interface, les versions de modèle et la prise en charge des paramètres sont parfaitement synchronisés avec OpenAI, c'est l'engagement principal de notre "service proxy API". La différence réside principalement au niveau du réseau : les connexions directes vers OpenAI depuis la Chine rencontrent souvent des échecs de handshake SSL ou des délais d'attente, tandis que notre passerelle est déployée dans des centres de données locaux, ce qui améliore considérablement la stabilité des interfaces liées aux images. C'est crucial pour l'exécution de tâches d'évaluation prolongées.
Conclusion
Le cas de l'audit de reçus avec OpenAI mérite d'être étudié en profondeur car il transforme une problématique abstraite — "comment résoudre un problème métier réel avec l'IA" — en une pratique d'ingénierie concrète, décomposée en trois étapes, 18 indicateurs d'évaluation et un impact financier quantifiable. C'est actuellement l'un des meilleurs modèles d'ingénierie IA disponibles dans la communauté francophone.
Si vous développez une application IA qui traite des documents ou des images pour produire des décisions structurées, nous vous recommandons vivement de tester ce cookbook dans son intégralité. Ne vous contentez pas de lire, passez à l'action : la véritable valeur de la conception pilotée par l'évaluation ne se ressent qu'au moment où vous voyez vos indicateurs évoluer. Nous vous suggérons de reproduire ce cas via une plateforme de service proxy API comme apiyi.com pour éviter les tracas de configuration environnementale et vous concentrer sur la méthodologie.
En intégrant l'évaluation au cœur de votre processus de développement, votre système IA passera du statut de "jouet intéressant" à celui de "produit d'ingénierie prêt pour la production et rentable". L'écart entre les deux peut se chiffrer à 75 000 $.
📌 Auteur : L'équipe APIYI — Spécialistes du suivi des pratiques d'ingénierie des API multimodales OpenAI / Anthropic / Google. Retrouvez plus d'analyses pratiques de cookbooks et nos guides d'accès aux API sur le centre de documentation apiyi.com.