Недавно OpenAI совместно с Fractional AI выпустили крайне содержательный практический кейс: автоматическая проверка квитанций и чеков с помощью ИИ. На первый взгляд это кажется обычной задачей OCR, но если заглянуть в ноутбук, становится ясно: это настоящая «библия» методологии того, как превратить ИИ-проект из демо-версии в полноценный рабочий продукт. Это самый полный пример Eval-Driven System Design (проектирования систем на основе оценки), который сейчас активно обсуждается в индустрии.
Самое интересное, что эта методология решает не столько техническую задачу, сколько фундаментальную проблему, с которой сталкивается каждый ИИ-инженер: как понять, что изменения в промпте действительно улучшили результат, а не просто создали иллюзию улучшения? В этой статье мы простыми словами разберем кейс OpenAI по проверке квитанций и выделим 5 инженерных принципов, полезных для любого разработчика ИИ-приложений.
🎯 Краткий обзор: Кейс взят из репозитория
eval_driven_system_designв официальном Cookbook от OpenAI. Авторы — команда Fractional AI (Хью Уимберли, Джошуа Маркер, Эдди Сигел) и Шикхар Кватра из OpenAI. Полный код доступен в официальном репозитории OpenAI Cookbook. Вы можете воспроизвести весь процесс без единого изменения кода, используя сервисы-прокси API, такие как APIYI (apiyi.com), что делает этот кейс идеальным для изучения российскими разработчиками.
{Глубокий разбор кейса проверки квитанций OpenAI}
{Проектирование на основе оценки · 1 млн запросов/год · экономия $75K в год}
{ЧЕК}
{Продавец: ___}
{Дата: ____}
{Пункт 1 …….. $}
{Пункт 2 …….. $}
{Пункт 3 …….. $}
{Промежуточный итог …… $}
{Налог ……….. $}
{ИТОГО ……… $}
{рукописный}
{изображение реальной квитанции}
{GPT-4o Vision}
{+ Схема Pydantic}
{① Детали квитанции}
{Извлечь 8 структурированных полей}
{② Решение об аудите}
{4 критерия оценки + рассуждение}
{✓ Автоматическое прохождение}
{95% документов}
{$0.20/запрос}
{⚠ Перевод на ручную проверку}
{5% документ}
{$2.00/за единицу}
{📊 18 Graders}
{🔄 Трехэтапная итерация}
{💰 Выравнивание бизнес-KPI}
{✂️ 67% снижение затрат}
{OpenAI Cookbook × Fractional AI · Методология разработки на основе оценки}
Бизнес-контекст кейса проверки квитанций OpenAI: почему это реальная проблема
Прежде чем переходить к технической части, давайте разберемся с бизнес-составляющей. Это не «игрушечная» задача, придуманная ради демонстрации API, а вполне реальный корпоративный сценарий с четкими показателями ROI.
| Бизнес-показатель | Конкретные цифры | Значение |
|---|---|---|
| Годовой объем | ~ 1 млн документов | Типичный масштаб для среднего бизнеса |
| Стоимость обработки (AI) | $0.20 | Расходы на вызов модели |
| Стоимость ручной проверки | $2.00 | Проверка финансовым специалистом |
| Штраф за пропуск ошибки | $30 / шт. | Санкции регуляторов/налоговой |
| Текущая доля ручной проверки | 5% | Только сложные случаи |
Если перемножить эти цифры, станет очевидно: даже повышение точности проверки всего на 1% при объеме в миллион документов дает сотни тысяч долларов годовой прибыли. Именно это команда Fractional AI называет «привязкой метрик к долларовому эквиваленту» (Dollar Impact) — это делается не ради красивых графиков, а чтобы каждое изменение промпта отражалось в финансовой отчетности компании.
Цель всей AI-системы предельно ясна: автоматически проверять большинство документов с помощью GPT-4o, передавая человеку только малую часть с «низкой степенью уверенности», тем самым снижая затраты на проверку и риски пропустить ошибку. Звучит просто, но дьявол кроется в деталях.
Что такое Eval-Driven Design: методология, которую понимаешь, только когда «обожжешься»
Если вы спросите 100 AI-инженеров, как они проверяют, правильно ли изменен промпт, 99 ответят: «Запускаю пару примеров и смотрю, выглядит ли результат адекватным». Это то, что команда Fractional AI называет vibe-coding (настройка по ощущениям), и именно этот подход Eval-Driven Design (далее EDD) призван полностью заменить.

Разницу между двумя подходами можно увидеть в этой таблице:
| Сравнение | Vibe-Coding (по ощущениям) | Eval-Driven Design (оценка) |
|---|---|---|
| Метод проверки | Запуск 3-5 примеров | Запуск 20-100+ размеченных примеров |
| Оценка изменений | «Кажется, стало лучше» | «Точность выросла с 78% до 85%» |
| Бизнес-результат | Субъективно | Прямая конверсия в доллары |
| Риск регрессии | Высокий (никто не знает, что сломалось) | Автоматическая проверка по всем метрикам |
| Масштабируемость | Только автор понимает логику | Любой инженер может провести отладку |
У Fractional AI есть фраза, которую часто цитируют: «Оценка (evals) — это не просто инструмент, это единственный способ профессиональной разработки AI». Звучит громко, но в таких критически важных задачах, как проверка квитанций, отсутствие полноценных тестов — это лотерея в продакшене, на которую никто не решится.
💡 Аналогия: Eval-Driven Design похож на экзамен со стандартными ответами: вы точно знаете, насколько каждое изменение повысило ваш «итоговый балл». Vibe-Coding — это попытка угадать ответы, не понимая, стали ли вы отвечать лучше или хуже. Продакшн-уровень AI требует первого подхода.
Трехэтапный процесс внедрения системы проверки квитанций на базе OpenAI
OpenAI Cookbook разбивает весь кейс на три четких этапа. Этот процесс можно применить практически к любому AI-приложению, где на входе — изображение или документ, а на выходе — структурированное решение.
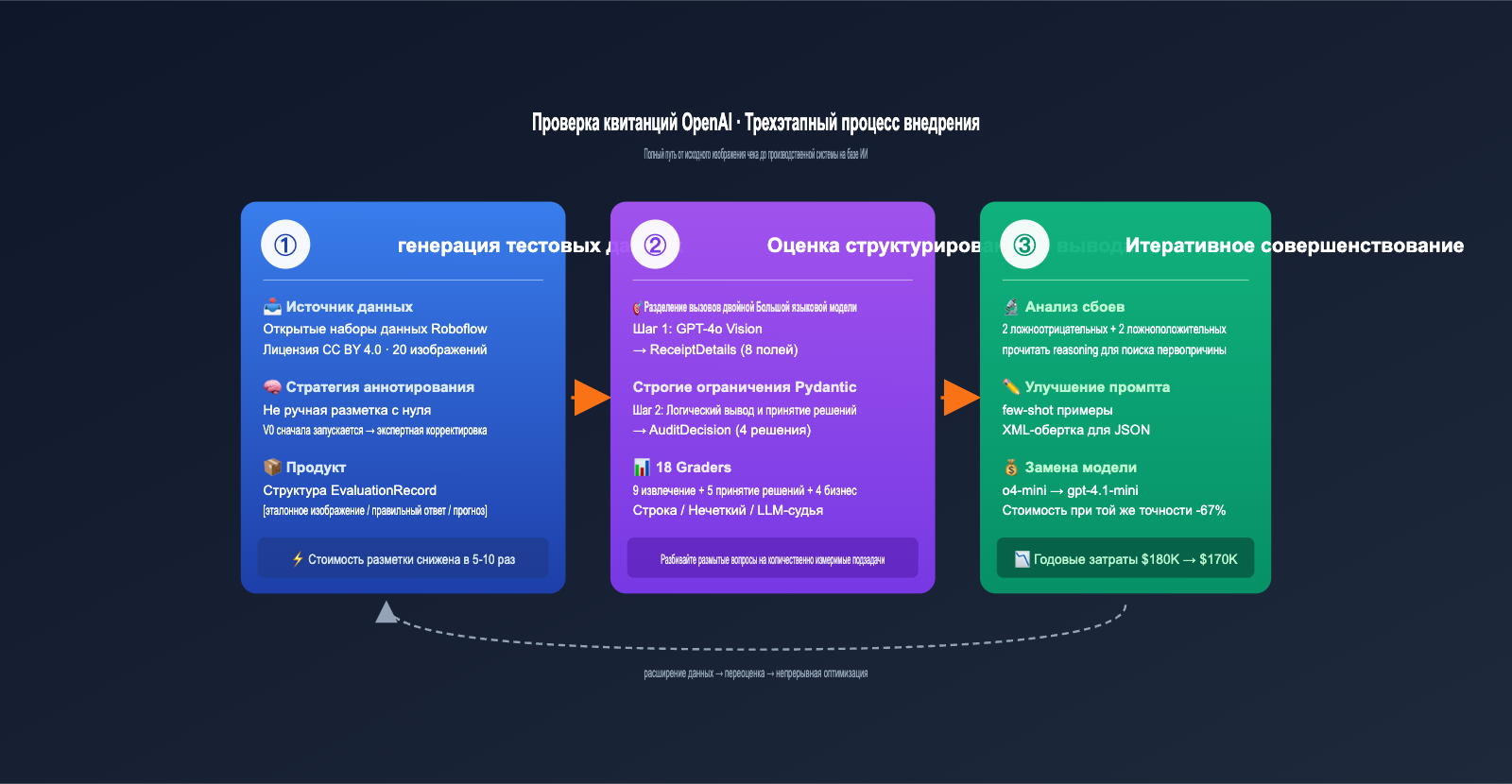
Ниже я простыми словами разберу каждый этап.
Этап 1: Генерация тестовых данных — экономим 80% затрат на разметку
Если вы думали, что команда вручную размечала тысячи квитанций, то вы недооцениваете изобретательность инженеров. Fractional AI применили умную стратегию: сначала прогон через V0-модель, затем — исправление экспертом.
Процесс выглядит так: берем 20 реальных квитанций из открытого датасета Roboflow (лицензия CC BY 4.0), скармливаем их базовой версии GPT-4o + Pydantic для извлечения данных, получаем результат V0. Затем финансовый эксперт просто «проверяет и правит» этот результат, а не вбивает данные с нуля.
Такой подход «сначала генерация, потом правка» повышает эффективность работы эксперта в 5-10 раз, ведь большую часть полей модель уже распознала верно. Итоговая структура данных EvaluationRecord получилась очень элегантной: она хранит путь к исходному изображению, правильные данные, предсказания модели и логику принятия решений.
🔧 Совет: Эта стратегия «V0 прогнали → эксперт поправил» подходит для холодного старта любого AI-проекта. Используя сервис-прокси API, например APIYI, вы можете быстро получить V0-результаты и сфокусировать внимание экспертов только на самых сложных моментах.
Этап 2: Оценка структурированного вывода — Pydantic как главный герой
Вся система состоит из двух последовательных вызовов LLM. Такое разделение ответственности — основа методологии EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Шаг 1: Извлечение структурированных данных из изображения"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Строгое ограничение через модель Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Шаг 2: Принятие решения на основе структурированных данных"""
# ... вызов LLM для получения модели AuditDecision Pydantic
Зачем разделять? Потому что задачи требуют разных навыков: первая — это «чтение и распознавание» (vision + извлечение), вторая — «логический вывод» (принятие решения). Если смешать их в одном промпте, модель начнет путаться, а вам будет сложно отлаживать ошибки.
Дизайн полей в Pydantic-моделях ReceiptDetails и AuditDecision — это то, чему стоит поучиться:
| Модель | Ключевые поля | Бизнес-смысл |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Вся информация с квитанции |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 критерия проверки + логика + вердикт |
Особое внимание уделите полю reasoning в AuditDecision — оно заставляет модель прописать логику рассуждений перед вынесением вердикта. Это критически важно для оценки по методу chain-of-thought. Также поле needs_audit является логическим OR для четырех предыдущих булевых полей — такой подход позволяет детализировать метрики оценки.
🚀 Подсказка: Метод
client.responses.parse()— это новейший интерфейс OpenAI для структурированного вывода. Он исключает ошибки парсинга JSON. Рекомендуем использовать для вызовов платформы вроде APIYI: они обеспечивают актуальность SDK и стабильную работу протоколов.
Этап 3: Итеративное улучшение — 18 метрик для количественной оценки
На этом этапе методология EDD раскрывается по полной. Команда Fractional AI внедрила 18 независимых метрик (грейдеров), превратив абстрактное «хорошо ли работает система» в набор измеримых показателей.
Эти 18 грейдеров делятся на три типа:
| Тип грейдера | Примеры метрик | Метод оценки |
|---|---|---|
| Точность извлечения (9) | Название продавца / Адрес / Сумма | Точное совпадение / Fuzzy match |
| Точность решений (5) | Связь с поездкой / Превышение лимита / Ошибки в расчетах / Рукописные пометки | Точность бинарной классификации |
| Бизнес-соответствие (4) | Пропущенные товары / Лишние товары / Качество логики | LLM-as-Judge (оценка 0-10) |
Первичная оценка на 20 образцах выявила 2 ложноотрицательных и 2 ложноположительных результата. Кажется, немного, но в масштабах миллиона чеков в год — это тысячи пропущенных нарушений. Команда действовала системно:
- Анализ причин: Изучение поля
reasoningв ошибочных кейсах. - Корректировка промпта: Добавление few-shot примеров, уточнение определений, обертка JSON в XML.
- Повторный прогон: Проверка, что исправления не сломали что-то другое.
- Эксперименты с моделями: Сравнение o4-mini и gpt-4.1-mini для выбора лучшего ROI.
Результат впечатляет: переход с o4-mini на gpt-4.1-mini снизил затраты на 67% (с $180K до $170K в год) при практически неизменной точности. Без полной системы оценки кто бы решился на такое сокращение расходов?
📊 Инсайт: 18 грейдеров нужны не для галочки, а для того, чтобы разбить сложную проблему «насколько точен AI» на 18 маленьких задач, которые можно чинить и измерять отдельно. Вы можете создать аналогичную систему грейдеров через APIYI, используя API, полностью совместимые с официальными инструментами OpenAI Evals.
5 инженерных уроков из кейса OpenAI по проверке чеков
Изучив этот кейс, я выделил 5 уроков, применимых к любому AI-приложению. Это опыт, оплаченный реальными деньгами.
Урок 1: Привязывайте метрики к деньгам, не гонитесь за 100% точностью во всем
В кейсе есть контринтуитивное открытие: повышение точности распознавания названия магазина почти не влияет на итоговое решение, так как правила проверки не зависят от названия. Если команда будет тратить ресурсы на то, чтобы поднять точность распознавания магазина с 92% до 98%, это будет пустой тратой инженерных усилий.
Напротив, ошибки в распознавании рукописного «X» приводят к убыткам около $75 000 в год из-за пропущенных проверок. Вот где находится наивысший приоритет. Поэтому при выборе метрик всегда задавайте вопрос: «Сколько денег я сэкономлю, исправив эту ошибку?»
Урок 2: Сначала запустите решение на самой мощной модели, а потом думайте об экономии
На этапе V0 команда сразу выбрала мощную модель вроде o4-mini. И не потому, что им было все равно на расходы, а потому, что они знали: заставить слабую модель работать корректно гораздо сложнее, чем оптимизировать работу избыточно мощной модели. Сначала отладьте бизнес-логику и создайте полноценную систему оценки, а уже потом экспериментируйте с заменой моделей. Этот порядок менять нельзя.
Урок 3: Разделяйте извлечение данных и принятие решений, не пытайтесь написать «универсальный промпт»
Многие новички думают: «Как здорово сэкономить, получив ответ "нужна ли проверка" прямо из картинки за один вызов!». Но у такого подхода два фатальных недостатка: невозможность отладки (если возникла ошибка, непонятно — это ошибка зрения модели или логики принятия решения) и невозможность повторного использования (результат извлечения данных пригоден только для этого конкретного решения). Разделение на два этапа выглядит как лишний вызов API, но на деле повышает ремонтопригодность системы на порядок.
Урок 4: Оценка цепочки рассуждений (Chain-of-Thought) помогает выявить скрытые угрозы «правильного ответа по неверной причине»
Поле reasoning в AuditDecision, которое на первый взгляд кажется избыточным, при оценке используется для выявления опасной ситуации: модель выдала верный итоговый ответ, но процесс рассуждения был ошибочным. Такие «случайные попадания» незаметны на малых выборках, но при малейшем изменении распределения данных система начнет массово давать сбои. Принудительный вывод рассуждений + оценка их качества с помощью LLM-as-Judge — это обязательная страховка для AI-приложений промышленного уровня.
Урок 5: Стоимость разметки можно снизить инженерными методами
Не пугайтесь стереотипа, что AI-проектам нужны колоссальные объемы размеченных данных. Стратегия «20 примеров + экспертная корректировка вывода V0» уже позволяет создать полезный набор для оценки. Главное — чтобы набор для оценки соответствовал распределению реальных бизнес-данных, а не гнаться за количеством образцов. Опыт Fractional показывает, что использование вывода V0 в качестве «затравочной разметки» повышает эффективность в 5–10 раз по сравнению с ручной разметкой с нуля.
Нюансы воспроизведения кейса OpenAI по проверке чеков в РФ
Чтобы воспроизвести этот cookbook, российским разработчикам нужно решить три задачи: доступность новых моделей (o4-mini / gpt-4.1-mini), поддержка новейшего интерфейса responses.parse и работа с эндпоинтами Evals API.
Прямое подключение к OpenAI из РФ работает крайне нестабильно, особенно с интерфейсами для работы с изображениями, где из-за большого объема полезной нагрузки (payload) процент ошибок выше, чем при работе с текстом. Использование сервиса-прокси API (APIYI) решает эти проблемы практически «из коробки». Достаточно изменить всего одну строку base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # Единственная строка, которую нужно изменить
api_key="Ваш API-ключ APIYI"
)
# Весь последующий код идентичен cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
В этом и заключается ключевое различие между «официальным прокси-сервисом OpenAI» и «совместимым API»: первый гарантирует синхронизацию интерфейсов с официальными обновлениями OpenAI, тогда как второй поддерживает только базовые функции. Продвинутые возможности, такие как responses.parse или Evals API, в обычных API могут быть недоступны. При воспроизведении официальных кейсов вроде этого, выбор прокси-сервиса с полной поддержкой избавит вас от множества проблем с совместимостью.
FAQ по кейсу проверки квитанций с помощью OpenAI
Q1: Этот метод подходит только для квитанций?
Вовсе нет. Проектирование на основе оценки (Eval-Driven Design) применимо к любому сценарию, где «входные данные относительно открыты, а на выходе требуется структурированное решение»: проверка контрактов, сортировка медицинских изображений, контроль качества обслуживания клиентов, отбор резюме, обнаружение мошенничества — всё это можно реализовать с помощью данного трехэтапного процесса. Суть остается прежней: это проектирование схемы Pydantic и создание оценщиков (grader).
Q2: 18 оценщиков — это не слишком много для небольшой команды?
Можно начать с 5–6 ключевых оценщиков, например: точность итогового решения + точность извлечения ключевых полей. Важно не количество, а то, что каждый оценщик соответствует конкретному типу ошибки. Мы рекомендуем сначала прогнать небольшую выборку через GPT-4o в консоли APIYI, а после отладки бизнес-процесса расширять количество критериев оценки.
Q3: Не будет ли слишком дорого использовать o4-mini на этапе V0?
На этапе V0 объем вызовов обычно составляет от нескольких десятков до сотен, а общие затраты — от нескольких до пары десятков долларов, что вполне приемлемо. Экономить нужно на этапе промышленной эксплуатации с миллионными вызовами, когда у вас уже есть полный набор данных для оценки и проведения экспериментов по замене моделей, как в примере с переходом o4-mini → gpt-4.1-mini, который позволил снизить расходы на 67%.
Q4: Как GPT-4o Vision справляется с рукописными квитанциями на китайском?
Точность распознавания печатных квитанций на английском очень высока (95%+), на китайском — тоже неплоха (90%+), а вот с рукописным китайским всё зависит от разборчивости почерка. Рекомендуем сначала создать оценочный набор из 100 реальных образцов, а не верить демо-видео. Стоимость вызова GPT-4o Vision через официальный прокси-API такая же, как у официального провайдера, что отлично подходит для масштабных оценочных экспериментов.
Q5: Могу ли я запустить этот cookbook, если у меня нет доступа к Evals API?
Да. Evals API в основном предназначен для делегирования настройки и управления оценщиками компании OpenAI, но логика оценки, которую вы запускаете на Python самостоятельно, абсолютно эквивалентна. Функции оценщиков в cookbook полностью открыты, их можно скопировать и использовать локально. Если масштаб бизнеса вырастет, можно будет рассмотреть переход на управляемые Evals.
Q6: В чем разница между использованием этого кейса через APIYI и официальный API?
Протоколы интерфейсов, версии моделей и поддержка параметров полностью синхронизированы с OpenAI — это ключевое обязательство нашего «официального прокси-сервиса». Разница заключается в сетевом уровне: при прямом подключении к OpenAI из Китая часто возникают ошибки SSL-рукопожатия или тайм-ауты, в то время как наш шлюз развернут в локальных дата-центрах, что значительно повышает стабильность, особенно для интерфейсов обработки изображений. Это критически важно для выполнения длительных задач оценки.
Итог
Кейс проверки квитанций с помощью OpenAI стоит изучить детально, потому что он превращает абстрактную задачу «как использовать ИИ для решения реальной бизнес-задачи» в конкретную инженерную практику, разбитую на три этапа, 18 метрик оценки и измеримое влияние на бюджет. Это именно тот пример ИИ-инженерии, которого сейчас больше всего не хватает в сообществе.
Если вы работаете над любым ИИ-приложением, которое «принимает документы/изображения и выдает структурированные решения», настоятельно рекомендуем полностью пройти этот cookbook. Не просто читайте, а пробуйте: истинная ценность Eval-Driven Design ощущается в тот момент, когда вы видите изменение метрик. Мы рекомендуем воспроизвести это через платформу APIYI, чтобы избежать проблем с настройкой окружения и сосредоточиться на самой методологии.
Сделайте «оценку на основе данных» неотъемлемой частью процесса разработки, и ваша ИИ-система превратится из «игрушки, которая выглядит неплохо» в инженерный продукт, который не страшно внедрять в производство и для которого можно рассчитать ROI. Разница между этими двумя состояниями может составлять $75,000.
📌 Автор: Команда APIYI — мы постоянно отслеживаем инженерные практики использования мультимодальных API от OpenAI, Anthropic и Google. Больше разборов cookbook и руководств по подключению к прокси-API можно найти в центре документации APIYI.