Baru-baru ini, OpenAI Cookbook bekerja sama dengan Fractional AI merilis sebuah studi kasus praktis yang sangat mendalam: penggunaan AI untuk verifikasi otomatis dokumen pengeluaran (reimbursement). Sekilas, ini tampak seperti tugas OCR biasa, namun setelah membuka Notebook-nya, Anda akan menyadari bahwa ini sebenarnya adalah "kitab suci" metodologi tentang "bagaimana membawa aplikasi AI dari demo ke produksi", sekaligus contoh open-source paling lengkap dari topik yang sedang hangat dibicarakan di industri saat ini: Eval-Driven System Design (Desain Sistem Berbasis Evaluasi).
Yang lebih menarik, metodologi ini tidak menyelesaikan masalah teknis semata, melainkan menjawab pertanyaan mendasar yang menghantui setiap insinyur AI: Bagaimana cara memastikan bahwa perubahan prompt yang saya lakukan benar-benar menjadi lebih baik, atau hanya terlihat lebih baik? Artikel ini akan membedah kasus verifikasi tanda terima OpenAI ini dengan cara yang paling mudah dipahami, serta merangkum 5 pengalaman teknis yang bermanfaat bagi semua pengembang aplikasi AI.
🎯 Panduan Cepat: Kasus ini berasal dari direktori
eval_driven_system_designdi cookbook.openai.com, ditulis oleh tim Fractional AI (Hugh Wimberly / Joshua Marker / Eddie Siegel) bersama Shikhar Kwatra dari OpenAI. Kode lengkapnya tersedia di repositori Cookbook resmi OpenAI, dan Anda dapat mereplikasi seluruh alur kerjanya tanpa perubahan apa pun melalui layanan proksi API seperti APIYI (apiyi.com), yang sangat cocok untuk dipelajari langsung oleh pengembang di Indonesia.
Latar Belakang Bisnis Kasus Verifikasi Tanda Terima OpenAI: Mengapa Ini Masalah Nyata
Sebelum masuk ke teknis, mari kita pahami latar belakang bisnisnya. Ini bukan masalah mainan yang dibuat hanya untuk mendemonstrasikan API, melainkan skenario perusahaan yang sangat nyata dengan angka ROI yang jelas.
| Dimensi Bisnis | Angka Spesifik | Makna |
|---|---|---|
| Volume Tahunan | Sekitar 1 juta lembar | Skala tipikal perusahaan menengah |
| Biaya Pemrosesan AI per Lembar | $0,20 | Biaya pemanggilan model |
| Biaya Verifikasi Manual per Lembar | $2,00 | Tinjauan staf keuangan |
| Denda Kelalaian Verifikasi | $30 / lembar | Sanksi kepatuhan/pajak |
| Tingkat Verifikasi Manual Saat Ini | 5% | Hanya untuk dokumen sulit |
Jika Anda mengalikan angka-angka ini, Anda akan menemukan bahwa peningkatan akurasi verifikasi sebesar 1% saja, pada volume 1 juta lembar, berarti penghematan tahunan senilai ratusan ribu dolar. Inilah yang ditekankan oleh tim Fractional AI sebagai "mengaitkan metrik evaluasi dengan dampak dolar (Dollar Impact)"—bukan sekadar mengejar angka, tetapi memastikan setiap perubahan prompt memiliki dampak langsung pada neraca keuangan bisnis.
Tujuan dari sistem AI ini sangat jelas: Menggunakan GPT-4o untuk memverifikasi sebagian besar dokumen secara otomatis, dan hanya menyerahkan dokumen dengan "tingkat kepercayaan rendah" kepada manusia, sehingga biaya verifikasi dan risiko kelalaian dapat ditekan. Terdengar sederhana, namun iblis selalu bersembunyi di balik detailnya.
Apa itu Eval-Driven Design: Metodologi yang Hanya Dipahami Setelah Mengalami Kegagalan
Jika Anda bertanya kepada 100 insinyur AI, "Bagaimana cara kalian memverifikasi apakah perubahan prompt sudah benar?", 99 di antaranya akan menjawab, "Jalankan beberapa contoh, lalu lihat apakah hasilnya terasa benar." Inilah yang dikritik oleh tim Fractional AI sebagai vibe-coding (penyesuaian berdasarkan perasaan), dan ini juga merupakan cara pengembangan yang ingin digantikan sepenuhnya oleh Eval-Driven Design (selanjutnya disebut EDD).

Perbedaan antara kedua metode pengembangan ini dapat dijelaskan melalui tabel berikut:
| Dimensi Perbandingan | Vibe-Coding (Berdasarkan Perasaan) | Eval-Driven Design (Berbasis Evaluasi) |
|---|---|---|
| Metode Verifikasi | Jalankan 3-5 contoh, lihat output | Jalankan 20-100+ sampel berlabel, hitung metrik |
| Penilaian Perubahan | "Rasanya jadi lebih baik" | "Akurasi meningkat dari 78% ke 85%" |
| Penyelarasan Bisnis | Berdasarkan perasaan apakah itu penting | Dikonversi langsung ke dampak dolar |
| Risiko Regresi | Mengubah A mungkin merusak B, tidak ada yang tahu | Seluruh rangkaian metrik dijalankan otomatis |
| Skalabilitas Kolaborasi | Hanya penulis asli yang mengerti | Insinyur mana pun bisa melakukan debug |
Ada satu kalimat dari Fractional AI yang sering dikutip: "Evaluasi bukanlah alat, melainkan satu-satunya cara untuk melakukan pengembangan AI yang profesional." Kalimat ini terdengar berlebihan, namun dalam skenario bisnis kritis seperti audit tanda terima, tanpa evaluasi, itu sama saja dengan bermain lotre di lingkungan produksi; tidak ada yang berani merilisnya dengan tenang.
💡 Analogi: Eval-Driven Design seperti ujian yang memiliki kunci jawaban, di mana Anda bisa menghitung berapa banyak peningkatan "total skor" dari setiap perubahan. Sementara Vibe-Coding seperti menjawab soal berdasarkan perasaan, setelah selesai Anda tidak tahu apakah hasilnya menjadi lebih baik atau lebih buruk. AI tingkat produksi harus menggunakan metode yang pertama.
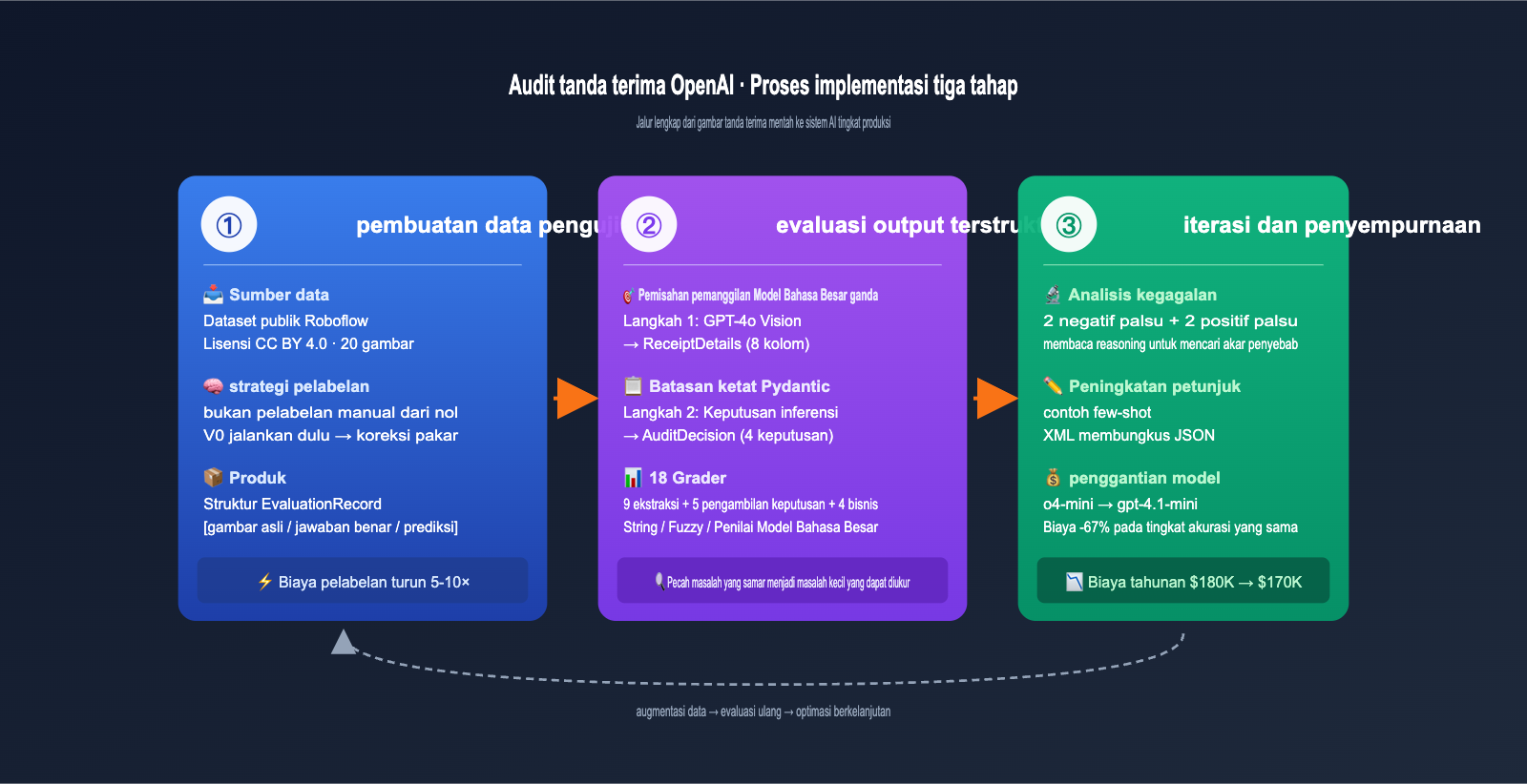
Proses Implementasi Tiga Tahap untuk Kasus Audit Tanda Terima OpenAI
OpenAI Cookbook membagi seluruh kasus ini menjadi tiga tahap yang sangat jelas. Proses ini hampir bisa diterapkan pada aplikasi AI apa pun yang melibatkan "input gambar/dokumen + output keputusan terstruktur".
Berikut adalah penjelasan setiap tahap dengan cara yang paling sederhana.
Tahap 1: Pembuatan Data Uji, Menghemat 80% Biaya Pelabelan dengan Cerdas
Jika Anda berpikir tim melakukan pelabelan manual ribuan gambar tanda terima dari nol, Anda meremehkan kemampuan insinyur untuk mencari jalan pintas. Fractional AI menggunakan strategi yang sangat cerdas: Biarkan model V0 berjalan terlebih dahulu, lalu minta ahli untuk memperbaikinya.
Prosesnya adalah sebagai berikut: Ambil 20 gambar tanda terima asli dari dataset publik Roboflow (lisensi CC BY 4.0), berikan langsung ke alur ekstraksi GPT-4o + Pydantic versi sederhana, dan dapatkan output V0. Kemudian, minta pakar di bidang keuangan untuk melakukan "koreksi kesalahan" berdasarkan output tersebut, alih-alih mengetik data dari nol kata demi kata.
Metode "buat dulu baru perbaiki" ini meningkatkan efisiensi waktu pakar bidang sebesar 5-10 kali lipat, karena sebagian besar kolom sudah diidentifikasi dengan benar oleh V0, dan pakar hanya perlu memperbaiki bagian yang salah. Struktur data EvaluationRecord yang dihasilkan juga sangat elegan, mencatat "jalur gambar asli, detail yang benar, detail prediksi model, keputusan audit yang benar, dan keputusan audit prediksi model", satu catatan mencakup seluruh alur kerja.
🔧 Saran Penggunaan Kembali: Strategi pelabelan "V0 berjalan dulu → pakar memperbaiki" ini hampir bisa diterapkan pada tahap cold start dari semua aplikasi AI. Anda hanya perlu menjalankan output V0 dengan cepat melalui platform APIYI, sehingga Anda dapat memusatkan energi pakar bidang pada tahap pengambilan keputusan yang paling berharga.
Tahap 2: Evaluasi Output Terstruktur, Pydantic adalah Pahlawan Sejati
Seluruh sistem AI terdiri dari dua pemanggilan LLM yang dirangkai, desain pemisahan tanggung jawab ini adalah salah satu inti dari EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Langkah pertama: Ekstraksi informasi tanda terima terstruktur dari gambar"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Batasan ketat model Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Langkah kedua: Membuat keputusan audit berdasarkan data terstruktur"""
# ... Panggil LLM untuk mengeluarkan model Pydantic AuditDecision
Mengapa dipisah menjadi dua langkah? Karena kedua tugas ini membutuhkan kemampuan yang sangat berbeda: Langkah pertama adalah "membaca gambar dan mengenali teks" (visi + ekstraksi informasi), langkah kedua adalah "penilaian logis" (penalaran dan pengambilan keputusan). Jika Anda mencampurnya dalam satu prompt, model tidak hanya akan mudah bingung dengan batasan tugas, tetapi Anda juga akan kesulitan melakukan debug karena tidak tahu di bagian mana kesalahan terjadi.
Desain kolom dari model Pydantic ReceiptDetails dan AuditDecision adalah bagian yang paling layak dipelajari dari kasus ini:
| Model | Kolom Kunci | Makna Bisnis |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Semua informasi yang terlihat pada tanda terima |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 kondisi penilaian audit + proses penalaran + kesimpulan akhir |
Perhatikan secara khusus kolom reasoning dalam AuditDecision—ini memaksa model untuk menuliskan proses penalaran sebelum memberikan keputusan akhir, yang merupakan kunci untuk evaluasi chain-of-thought di kemudian hari. Perhatikan juga bahwa needs_audit adalah logika OR dari empat kolom boolean sebelumnya. Desain "skor per item lalu sintesis menjadi keputusan" ini memungkinkan metrik evaluasi dipecah dengan sangat rinci.
🚀 Tips Integrasi:
client.responses.parse()di atas adalah antarmuka output terstruktur terbaru dari OpenAI, yang dapat secara langsung menggunakan model Pydantic sebagai batasan format output, hampir sepenuhnya menghilangkan risiko kegagalan penguraian JSON. Kami menyarankan untuk memanggilnya melalui platform APIYI, karena antarmuka ini memiliki persyaratan versi SDK, dan gateway APIYI memastikan protokol diperbarui secara sinkron.
Tahap 3: Iterasi dan Penyempurnaan, 18 Grader Membuat Perubahan Dapat Dikuantifikasi
Tahap ini adalah tempat di mana EDD benar-benar bersinar. Tim Fractional AI menetapkan 18 metrik evaluasi independen (grader) untuk sistem audit tanda terima ini, memecah pertanyaan samar "apakah sistem ini baik?" menjadi 18 pertanyaan kecil yang dapat dikuantifikasi.
18 grader ini secara garis besar dibagi menjadi tiga kategori:
| Tipe Grader | Metrik Representatif | Metode Evaluasi |
|---|---|---|
| Akurasi Ekstraksi (9) | Nama pedagang / Alamat / Pencocokan total | Pencocokan string tepat / pencocokan fuzzy |
| Akurasi Keputusan Audit (5) | Penentuan perjalanan / Penentuan batas / Deteksi kesalahan hitung / Identifikasi tulisan tangan X / Keputusan akhir | Akurasi klasifikasi biner |
| Metrik Penyelarasan Bisnis (4) | Barang hilang / Barang berlebih / Akurasi barang / Kualitas penalaran | LLM-as-Judge (skor 0-10) |
Evaluasi awal pada 20 sampel menemukan 2 negatif palsu + 2 positif palsu. Angka ini terlihat kecil, tetapi jika dikalikan dengan skala 1 juta transaksi per tahun, itu berarti ribuan kasus audit yang terlewat. Cara tim Fractional menanganinya sangat teknis:
- Analisis Akar Masalah: Lihat kolom reasoning dari setiap contoh yang salah, temukan di mana model terjebak dalam penilaian.
- Modifikasi Prompt yang Ditargetkan: Tambahkan contoh few-shot, perjelas definisi "terkait perjalanan", bungkus contoh JSON dengan XML.
- Jalankan Ulang Kumpulan Evaluasi: Verifikasi apakah perubahan tersebut benar-benar memperbaiki bug dan tidak memperkenalkan bug baru.
- Eksperimen Penggantian Model: Jalankan prompt yang sama pada o4-mini dan gpt-4.1-mini secara terpisah, pilih yang memiliki ROI lebih baik.
Hasil langkah terakhir sangat mengejutkan: Beralih dari o4-mini ke gpt-4.1-mini, biaya berkurang 67%, biaya tahunan turun dari sekitar $180K menjadi $170K, sementara akurasi hampir tidak menurun. Tanpa kumpulan evaluasi yang lengkap, siapa yang berani membuat keputusan penghematan biaya seperti ini?
📊 Wawasan Kunci: 18 grader tersebut bukan sekadar untuk memenuhi jumlah, melainkan untuk memecah masalah yang tampaknya tidak dapat dikuantifikasi, yaitu "apakah AI akurat atau tidak", menjadi 18 masalah kecil yang dapat diperbaiki dan diukur secara independen. Anda juga dapat membuat sistem grader serupa dengan memanggil OpenAI Evals API melalui APIYI, karena antarmukanya sepenuhnya kompatibel dengan versi resmi.
5 Pelajaran Rekayasa dari Kasus Audit Kuitansi OpenAI
Setelah membaca keseluruhan kasus tersebut, saya menyarikan 5 pelajaran yang berlaku untuk aplikasi AI apa pun. Ini adalah pengalaman yang dibayar dengan uang sungguhan.
Pelajaran 1: Kaitkan evaluasi dengan dolar, jangan mengejar akurasi 100% untuk semua metrik
Dalam kasus tersebut, ada temuan yang sangat berlawanan dengan intuisi—peningkatan akurasi pengenalan nama pedagang hampir tidak berpengaruh pada keputusan audit akhir, karena aturan audit tidak bergantung pada nama pedagang. Jika tim bersikeras meningkatkan pengenalan nama pedagang dari 92% menjadi 98%, itu adalah pemborosan sumber daya teknik.
Sebaliknya, kesalahan pengenalan tanda "X" tulisan tangan menyebabkan kerugian audit yang terlewat sekitar $75.000 per tahun, dan inilah metrik dengan prioritas tertinggi. Jadi, pemilihan metrik harus selalu menjawab satu pertanyaan: "Jika saya memperbaiki kesalahan ini, berapa banyak uang yang bisa saya hemat?"
Pelajaran 2: Gunakan model terkuat terlebih dahulu untuk menjalankan sistem, baru pikirkan penghematan
Pada tahap V0 kasus tersebut, tim langsung memilih model terkuat saat itu seperti o4-mini. Bukan karena tim tidak peduli dengan biaya, tetapi karena mereka tahu bahwa membuat model yang kurang mampu bekerja dengan paksa jauh lebih sulit daripada membuat model yang terlalu mampu bekerja dengan murah. Jalankan logika bisnis terlebih dahulu, bangun sistem evaluasi yang lengkap, baru lakukan eksperimen penggantian model. Urutan ini tidak boleh dibalik.
Pelajaran 3: Ekstraksi dan pengambilan keputusan harus dipisah, jangan serakah membuat satu petunjuk (prompt) serba guna
Banyak pemula berpikir: "Satu panggilan API bisa langsung mendapatkan kesimpulan 'apakah perlu diaudit' dari gambar, bukankah itu hemat biaya?" Namun, desain ini memiliki dua kelemahan fatal: tidak dapat didebug—jika terjadi kesalahan, Anda tidak tahu apakah model salah membaca gambar atau salah dalam logika penilaian; tidak dapat digunakan kembali—hasil ekstraksi hanya bisa digunakan untuk keputusan ini saja. Membaginya menjadi dua langkah memang terlihat seperti memanggil API satu kali lebih banyak, tetapi sebenarnya meningkatkan pemeliharaan seluruh sistem hingga satu tingkat lipat.
Pelajaran 4: Evaluasi chain-of-thought dapat menangkap risiko "jawaban benar tapi alasan salah"
Kolom reasoning yang tampak redundan dalam AuditDecision digunakan selama evaluasi untuk mengidentifikasi situasi berbahaya: model memberikan jawaban akhir yang benar, tetapi proses penalarannya salah. "Kebenaran karena keberuntungan" seperti ini tidak terlihat pada sampel kecil, tetapi akan gagal total begitu distribusi data sedikit berubah. Mewajibkan output penalaran + menggunakan LLM-as-Judge untuk mengevaluasi kualitas penalaran adalah asuransi wajib untuk aplikasi AI tingkat produksi.
Pelajaran 5: Biaya pelabelan dapat dikurangi melalui rekayasa
Jangan takut dengan stereotip bahwa "proyek AI membutuhkan data pelabelan dalam jumlah besar". Strategi 20 sampel + koreksi ahli terhadap output V0 sudah cukup untuk mendukung kumpulan evaluasi yang berguna. Kuncinya adalah memastikan kumpulan evaluasi konsisten dengan distribusi data bisnis yang sebenarnya, bukan mengejar jumlah sampel. Pengalaman Fractional adalah menggunakan output V0 awal sebagai "pelabelan benih", yang meningkatkan efisiensi 5-10 kali lipat dibandingkan pelabelan manual dari nol.
Hal-hal yang perlu diperhatikan saat mereplikasi kasus audit kuitansi OpenAI di Indonesia
Pengembang di Indonesia yang ingin mereplikasi buku panduan (cookbook) ini perlu menyelesaikan tiga masalah: apakah bisa memanggil model baru seperti o4-mini / gpt-4.1-mini, apakah bisa menggunakan antarmuka terbaru responses.parse, dan apakah bisa memanggil titik akhir Evals API.
Koneksi langsung ke OpenAI di Indonesia seringkali tidak stabil, terutama antarmuka gambar yang memiliki payload besar, sehingga tingkat kegagalannya lebih tinggi daripada antarmuka teks. Menggunakan layanan proksi API resmi pada dasarnya dapat menyelesaikan ketiga masalah ini dalam satu langkah. Kode kuncinya hanya perlu mengubah satu baris base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # Satu-satunya baris yang perlu diubah
api_key="Kunci APIYI Anda"
)
# Semua kode selanjutnya sama persis dengan cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
Inilah perbedaan utama antara "API proksi resmi OpenAI" dan "API yang kompatibel dengan OpenAI"—yang pertama menjamin antarmuka tetap sinkron dengan OpenAI resmi, sedangkan yang terakhir hanya kompatibel dengan antarmuka dasar. Kemampuan tingkat lanjut seperti responses.parse atau Evals API mungkin tidak didukung. Saat mereplikasi kasus resmi seperti cookbook ini, memilih layanan proksi resmi dapat menghindari banyak masalah kompatibilitas.
FAQ Kasus Audit Kuitansi OpenAI
Q1: Apakah metode ini hanya bisa digunakan untuk kuitansi?
Tentu saja tidak. Eval-Driven Design (desain berbasis evaluasi) cocok untuk skenario apa pun di mana "input relatif terbuka dan output memerlukan keputusan terstruktur": audit kontrak, triase citra medis, kontrol kualitas layanan pelanggan, penyaringan resume rekrutmen, hingga deteksi penipuan, semuanya bisa menggunakan alur tiga tahap ini. Inti yang tidak berubah hanyalah desain skema Pydantic dan grader evaluasi.
Q2: Apakah 18 grader terlalu banyak untuk tim kecil?
Anda bisa mulai dengan 5-6 grader inti, misalnya akurasi keputusan akhir + akurasi ekstraksi kolom kunci. Yang penting bukan jumlahnya, melainkan setiap grader harus sesuai dengan pola kegagalan yang spesifik. Kami menyarankan untuk menjalankan sampel kecil GPT-4o di konsol apiyi.com terlebih dahulu, dan setelah alur bisnis berjalan lancar, barulah Anda memperluas dimensi evaluasi.
Q3: Apakah menggunakan o4-mini secara langsung di V0 tidak mahal?
Pada tahap V0, volume pemanggilan biasanya hanya puluhan hingga ratusan kali, dengan total biaya beberapa dolar hingga puluhan dolar, yang sangat terjangkau. Penghematan biaya yang sebenarnya dilakukan pada lingkungan produksi dengan jutaan pemanggilan. Saat itu, Anda sudah memiliki set evaluasi lengkap untuk melakukan eksperimen penggantian model, seperti kasus o4-mini → gpt-4.1-mini yang memangkas biaya hingga 67%.
Q4: Bagaimana performa GPT-4o Vision dalam membaca kuitansi tulisan tangan berbahasa Mandarin?
Akurasi untuk kuitansi cetak berbahasa Inggris sangat tinggi (95%+), kuitansi cetak Mandarin juga cukup baik (90%+), sedangkan untuk tulisan tangan Mandarin, itu tergantung pada kejelasan tulisan. Kami sarankan untuk menggunakan 100 sampel nyata guna membangun set evaluasi, daripada hanya percaya pada video demo. Biaya pemanggilan GPT-4o Vision melalui API resmi sama dengan harga resmi, sehingga cocok untuk eksperimen evaluasi skala besar.
Q5: Jika saya tidak memiliki izin Evals API, bisakah saya menjalankan cookbook ini?
Bisa. Evals API utamanya berfungsi untuk mengelola konfigurasi dan manajemen grader di OpenAI, namun logika evaluasi yang sebenarnya bisa Anda jalankan sendiri menggunakan Python dengan hasil yang setara. Fungsi grader dalam cookbook semuanya bersifat open-source, Anda cukup menyalinnya ke lingkungan lokal untuk digunakan. Jika skala bisnis Anda meningkat di kemudian hari, barulah pertimbangkan untuk bermigrasi ke Evals yang terkelola.
Q6: Apa perbedaan antara menggunakan APIYI untuk kasus ini dengan API resmi?
Protokol antarmuka, versi model, dan dukungan parameter semuanya sepenuhnya sinkron dengan OpenAI resmi, itulah komitmen utama dari "layanan proksi API" kami. Perbedaannya terutama pada aspek jaringan: koneksi langsung ke OpenAI dari dalam negeri sering mengalami kegagalan handshake SSL atau timeout, sedangkan gateway APIYI disebarkan di IDC dalam negeri, sehingga stabilitas antarmuka berbasis gambar meningkat secara signifikan. Hal ini sangat krusial untuk menjalankan tugas evaluasi yang memakan waktu lama.
Kesimpulan
Kasus Audit Kuitansi OpenAI ini layak dipelajari berulang kali karena berhasil membedah proposisi abstrak tentang "bagaimana menggunakan AI untuk memecahkan masalah bisnis nyata" menjadi tiga tahap, 18 indikator evaluasi, dan praktik rekayasa konkret yang dapat diukur dampaknya dalam dolar. Ini adalah contoh rekayasa AI yang paling dibutuhkan oleh komunitas saat ini.
Jika Anda sedang mengerjakan aplikasi AI apa pun yang melibatkan "input dokumen/gambar dan output keputusan terstruktur", kami sangat menyarankan Anda untuk menjalankan cookbook ini secara menyeluruh. Jangan hanya melihat tanpa mempraktikkan; nilai sebenarnya dari eval-driven design baru bisa dirasakan saat Anda melihat perubahan pada indikator. Kami menyarankan untuk mereproduksinya secara langsung melalui platform API proksi resmi seperti apiyi.com, yang dapat menghemat waktu dari kerumitan pengaturan lingkungan dan memungkinkan Anda fokus pada metodologinya sendiri.
Dengan menanamkan prinsip "evaluasi berbasis data" ke dalam alur pengembangan, sistem AI Anda akan bertransformasi dari sekadar mainan yang "terlihat meyakinkan" menjadi produk rekayasa yang "layak masuk ke produksi dan memiliki ROI yang jelas". Perbedaan di antara keduanya mungkin bernilai $75.000.
📌 Penulis: Tim APIYI — Melacak praktik rekayasa API multimodal OpenAI / Anthropic / Google dalam jangka panjang. Untuk panduan praktis cookbook lainnya dan panduan akses API proksi resmi, kunjungi pusat dokumentasi apiyi.com.