GitHub で最近注目を集めているオープンソースプロジェクト ARIS-Code が、8,400以上のスターと783のフォークを獲得し、大きな話題となっています。開発者の wanshuiyin 氏が Claude Code のオープンソース版をベースに改良したこのプロジェクトは、「Auto-Research-In-Sleep(寝ている間に自動研究)」の名の通り、まさに「寝ている間に研究を進める」ためのツールです。これは単なる宣伝文句ではなく、Claude Code を活用して、あなたが眠っている間に実験の実行、文献調査、論文の修正を自動で行い、翌朝には研究が大きく前進しているという体験を実現します。
ARIS-Code が学術界で注目されている理由は、その実用性にあります。作者が公開した3つのコミュニティ論文事例では、AIによる査読スコアで10点満点中7〜8点を獲得し、CSトップカンファレンス、AAAI 2026、IEEE TGRSへそれぞれ投稿済みとのことです。これは、AIによる全自動研究が単なるデモ段階を超え、実際に投稿可能なレベルの論文を作成できる能力を備えていることを意味しています。
本記事では、ARIS-Code のコアアーキテクチャ、42個の組み込みスキル(Skills)、そして国内環境からAPI中継サービスを介して Claude モデルを接続する方法を詳しく解説し、このツールがあなたの研究ワークフローに適しているかどうかを判断するための情報を提供します。
🎯 特記事項: ARIS-Code は Claude Code のオープンソース版をベースにしているため、実行エンジンとして接続できるのは Claude シリーズのモデル(Sonnet/Opus/Haiku)のみです。GPT や Gemini シリーズをメインエンジンとして使用することはできません。国内から安定してアクセスでき、海外クレジットカード不要で従量課金が可能な APIYI (apiyi.com) プラットフォーム経由で Claude モデルを接続することをお勧めします。
ARIS-Code: Auto-Research-In-Sleep プロジェクトとは
ARIS (Auto-Research-In-Sleep) は、機械学習やAI分野の研究者向けに設計された自律型研究ワークフローシステムです(GitHub プロジェクトページ: github.com/wanshuiyin/Auto-claude-code-research-in-sleep)。その設計目標は明確で、研究者の介入を最小限に抑え、「文献調査 → アイデア生成 → 実験実行 → 論文執筆 → リバッタル対応」という全プロセスを自動化し、研究者を単純作業から解放することにあります。
ARIS-Code の本質は「方法論のライブラリ」です。システム全体が純粋な Markdown ファイル(SKILL.md)で構成されており、インストールが必要なフレームワークや、管理が必要なデータベース、設定が必要な Docker コンテナなどは一切ありません。各スキルは、どのような LLM エージェントでも読み取れるワークフローの指示書となっているため、実行エンジンを Claude Code から Codex CLI、OpenClaw、Cursor、Trae など、エージェントモードをサポートする任意のツールに切り替えても、ワークフローはそのまま機能します。
この「ゼロ依存・ゼロロックイン」という設計こそが、他の研究用AIツールと一線を画す ARIS-Code 最大の特徴です。これは、研究プロセスをブラックボックス化するのではなく、実行可能なプロンプトエンジニアリングとして「可視化」したものです。研究者にとって、ワークフローが可読であり、修正や移行が可能であることは非常に重要であり、特定の商用製品に依存せずに済むという大きなメリットがあります。
特筆すべき点として、ARIS-Code リポジトリはすでに719回のコミットを重ねており、現在も急速に進化しています。直近3ヶ月間だけでも、paper-talk(会議用プレゼン原稿生成)、resubmit-pipeline(不採択後の再投稿パイプライン)、kill-argument(対抗的な反論生成)など、価値の高いスキルが次々と追加されており、非常に活発なエコシステムが形成されています。
ARIS-Codeの核心アーキテクチャ:Executor-Reviewer 二重モデル対抗型レビュー
ARIS-Codeの最も重要なエンジニアリング上の価値は、その二重モデル対抗型アーキテクチャにあります。これは、市場に出回っている他の研究支援ツールと一線を画す最大の特徴です。プロジェクトの著者はREADMEの中で、「単一モデルによる自己レビューには構造的な弱点がある」という非常に鋭い指摘をしています。同じモデルがタスクの実行と出力の評価を両方行うと、自身の盲点を体系的に再現してしまい、「局所最適の罠」に陥ってしまうからです。
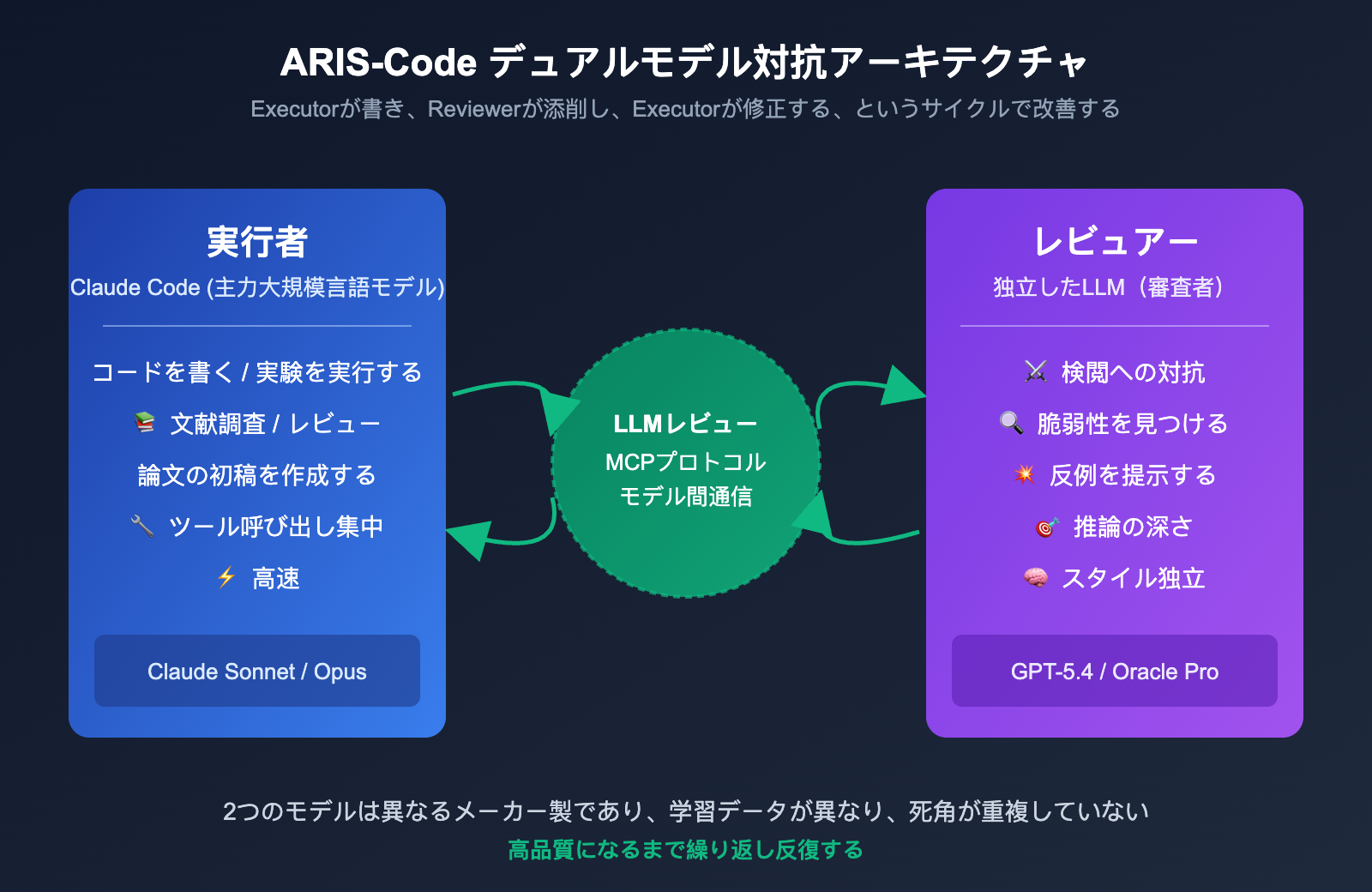
ARIS-Codeは、レビュー権限を完全に独立したモデルに委ねることでこの問題を解決しました。具体的な役割分担は以下の通りです:
| 役割 | モデル選定 | 役割の定義 | 推奨される能力傾向 |
|---|---|---|---|
| Executor (実行者) | Claude Sonnet / Opus | 主力実行:コード作成、文献調査、実験実行、論文草案作成 | 高速、長コンテキスト、ツール呼び出しの安定性 |
| Reviewer (審査者) | GPT-5.4 (Codex MCP) / Oracle Pro | 対抗レビュー:脆弱性の発見、結論への疑問提示、反例の提示 | 深い推論、批判的思考、独立したスタイル |
| 調整メカニズム | LlmReview ツールチェーン | モデル間通信、状態の永続化 | MCPプロトコルによる透過的な連携 |
ワークフロー全体は、「Executorが書き、Reviewerが添削し、Executorが修正する。これをReviewerが合格と判定するまで繰り返す」というシンプルなサイクルに集約されます。このサイクルが有効なのは、両モデルが異なるベンダーから提供され、学習データや推論スタイルが異なるため、盲点が重ならないからです。
LLMのハルシネーションが研究結果を汚染するのを防ぐため、ARIS-Codeには多層的な証拠監査チェーンが設計されています:experiment-audit(コードの完全性)→ result-to-claim(結果と主張の整合性)→ paper-claim-audit(論文主張の監査)→ citation-audit(引用の検証)。各層には独立したJSON判定とSHA256ハッシュによる再現性検証が含まれており、このようなエンジニアリングの厳密さは研究用AIツールとしては極めて珍しいものです。
🔧 設定のアドバイス: ARIS-Codeの二重モデルアーキテクチャを完全に再現したい場合、国内環境であればAPIYI(apiyi.com)を通じてClaudeとGPTシリーズのAPIキーを同時に取得することをおすすめします。一つのプラットフォームで両方のインターフェースに対応できるため、海外口座の開設やクレジットカードの紐付けを個別に行う手間が省けます。
ARIS-Codeに組み込まれた42のスキルによる全研究パイプライン
ARIS-Codeで最も印象的なのは、組み込まれている42以上のスキルです。これらは単なる独立したツールではなく、研究ライフサイクル全体をカバーするパイプラインを形成しています。ワークフローの段階別に分類すると以下のようになります:
| ワークフロー段階 | 代表的なスキル | 核心能力 |
|---|---|---|
| テーマ選定 (Idea Discovery) | research-lit / novelty-check / idea-creator / idea-discovery | 多ソース文献検索、モデル間での新規性検証、8〜12個のアイデア案生成 |
| 実験段階 (Experimentation) | experiment-bridge / experiment-queue / run-experiment | コードレビュー → GPUデプロイ → マルチシード実行 → OOM自動処理 |
| 自動レビュー (Auto Review) | auto-review-loop / research-review / experiment-audit | 4ラウンドの反復改善、構造化された査読、コード完全性検証 |
| 論文執筆 (Paper Writing) | paper-writing / paper-claim-audit / proof-checker / citation-audit | 構成 → LaTeX → PDF、主張監査、証明チェック、引用検証 |
| リバッタル対応 (Rebuttal) | rebuttal | 査読コメントの解析 → 回答草案作成 → 圧力テスト |
| メタ能力 | research-wiki / meta-optimize / deepxiv | 永続的な知識ベース、外環最適化、代替文献ソース |
実戦で最も価値があるのは experiment-bridge です。これは「コードレビュー → GPUリモートデプロイ → 実験開始 → 結果回収」を一気通貫のパイプラインに統合します。Reviewerが「ここでアブレーション実験が必要だ」と指摘すると、Executorが自動的にスクリプトを作成し、GPUノードへrsyncし、学習を開始し、ログを監視して結果を収集します。このプロセス全体に研究者が手動で介入する必要はありません。
もう一つ注目すべきスキルは citation-audit です。これはDBLPやCrossRefの信頼できるデータベースと連携することで、LLMによる論文執筆時の最大の弱点である「引用のハルシネーション」を排除します。すべてのBibTeXはモデルが捏造したものではなく、実在するデータベースに基づいています。これは学術論文において最低限必要な要件であり、虚偽の引用が一つでもあれば即座にリジェクトされる可能性があるため、非常に重要です。
また、研究者から特に好評なのが、セッションをまたいで利用できる知識ベース research-wiki です。これは研究者の論文読解メモ、アイデアの草案、失敗した実験記録などを蓄積し、成長し続ける「個人の研究記憶」を形成します。3ヶ月後に中断していたプロジェクトに戻った際も、すべての関連論文を読み直す必要はなく、AIアシスタントがコンテキストを保持してくれています。
💡 使用上のヒント: スキルを呼び出す際は、特にpaper-writingのような長文生成タスクにおいて、大量のClaude APIトークンを消費します。apiyi.comを通じてClaudeモデルに接続することをおすすめします。このプラットフォームは従量課金に対応しており、詳細なトークン使用量モニタリングも提供されているため、論文1本あたりのコストを容易に見積もることができます。
ARIS-Code を APIYI に接続するための完全設定ガイド
ARIS-Code のエグゼキューターは Claude Code のオープンソース版をベースに改良されているため、Anthropic のネイティブ API プロトコルのみを受け付けます。つまり、GPT や Gemini シリーズのモデルをエグゼキューターとして直接使用することはできません。これは厳格な制約であり、多くの開発者が導入時に最も戸惑うポイントでもあります。
APIYI を介して Claude モデルを接続する設定手順は非常にシンプルで、以下の5ステップで完了します。
# ステップ 1: プロジェクトリポジトリをクローン
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# ステップ 2: Skills をローカルの Claude Code 設定ディレクトリにインストール
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# ステップ 3: APIYI 中継アドレスを設定 (最重要)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="あなたの APIYI キー"
# ステップ 4: Claude Code を起動
claude
# ステップ 5: Claude Code 内で任意の Skill を呼び出す
# 例: /research-pipeline "factorized gap in discrete diffusion LMs"
ここで最も重要なのは、ステップ 3 で ANTHROPIC_BASE_URL 環境変数を設定することです。これにより、Claude Code は Anthropic の公式エンドポイントではなく、APIYI の中継ゲートウェイへリクエストを送るようになります。このゲートウェイは Anthropic のネイティブプロトコルと完全に互換性があるため、ARIS-Code 内蔵の Skill はコードを一切変更することなく、ツール呼び出し、ストリーミング出力、思考チェーン(thinking)を含むすべての機能を透過的に利用可能です。
Reviewer 側(Codex MCP)もデプロイする必要がある場合の手順は以下の通りです:
# 審査用の Codex MCP をインストール
npm install -g @openai/codex
codex setup # ここでも GPT モデル用に中継アドレスを入力可能
claude mcp add codex -s user -- codex mcp-server
ARIS-Code の論文レベルの効果を完全に再現したい研究者向けに、プロジェクトでは GPT-5.4 Pro を高度な Reviewer として接続する Oracle MCP のスキームも提供されています。このスキームは、論文投稿直前の追い込み段階で非常に役立ちます。Pro バージョンは、基礎モデルと比較して批判の深さや反例の構築能力が大幅に向上しているためです。
🚀 統合接続スキーム: APIYI (apiyi.com) プラットフォームは、Claude シリーズ (Sonnet 4.5/Opus 4)、GPT シリーズ (GPT-5/o4)、Gemini シリーズ (Gemini 3 Pro) などの主要モデルをすべてサポートしています。1 つのキーで ARIS-Code のエグゼキューターと Reviewer の両方を駆動できるため、研究チームの費用管理や呼び出し履歴の集計に非常に便利です。
ARIS-Code の Effort Level と GPU 設定戦略
ARIS-Code は、コストと品質のバランスを取るために 4 段階の Effort Level を提供しており、非常にエンジニアリングに優れた設計となっています。研究の段階によって求められる深さは大きく異なるため、初期の探索段階ではトークンを節約し、投稿前の追い込み段階では品質を極限まで高めることが可能です。
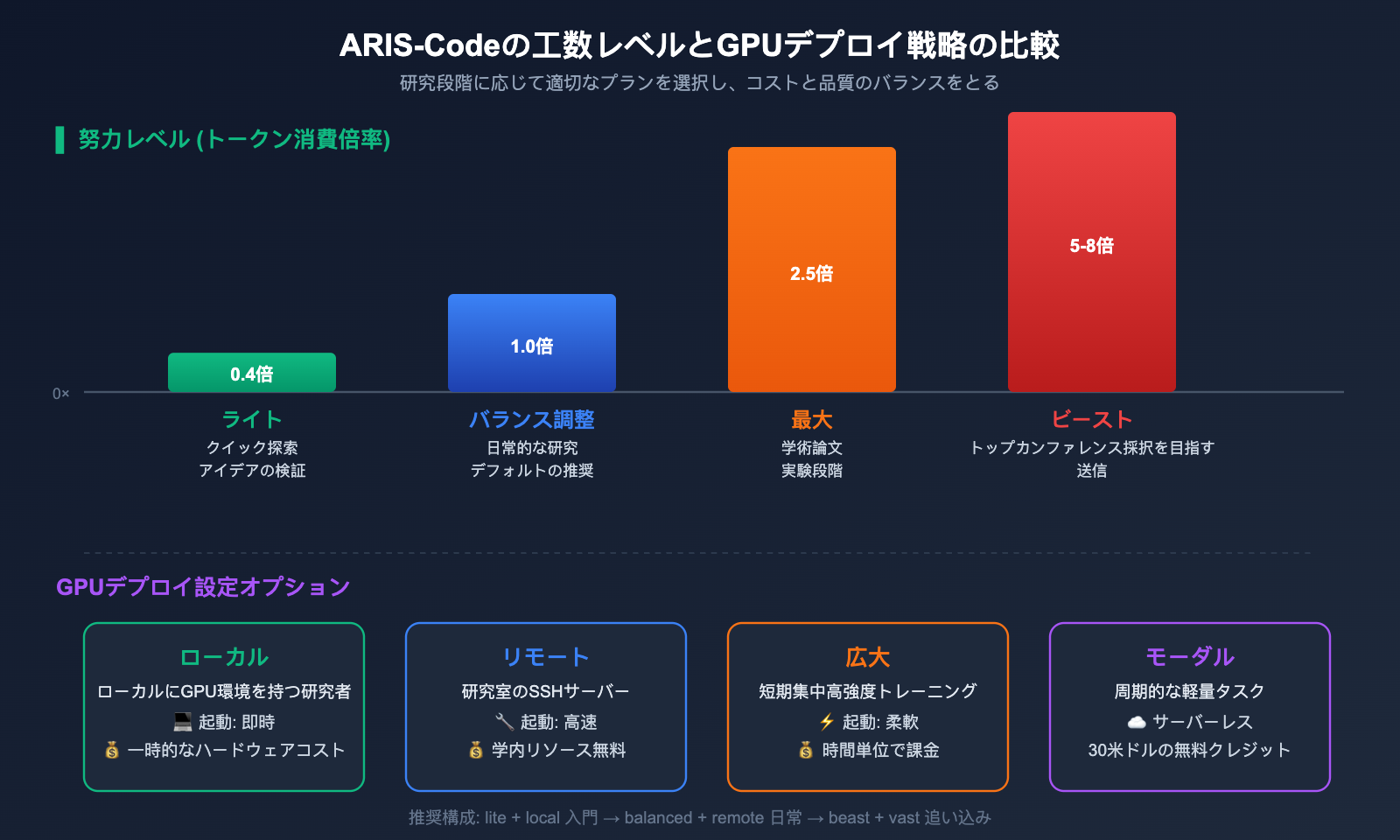
| Effort Level | トークン倍率 | 適用シーン | 単回呼び出しコスト |
|---|---|---|---|
| lite | 0.4× | 迅速な探索、アイデア検証 | 非常に低い |
| balanced | 1.0× | 標準的な日常の研究プロセス | 標準 |
| max | 2.5× | 本格的な論文実験段階 | 中〜高 |
| beast | 5-8× | トップカンファレンス投稿前、Submission Mode | 高 |
GPU 側でも、ARIS-Code はローカル環境とクラウド環境の両方を考慮した 4 つの設定オプションを提供しています:
| GPU 設定 | 適用シーン | コスト特性 |
|---|---|---|
| local | ローカルに GPU を持つ研究者 | 一時的なハードウェアコスト |
| remote | 研究室の SSH サーバー | 学内リソースのため無料 |
| vast | 短期間の高負荷トレーニング | 時間単位の課金、柔軟 |
| modal | 定期的な軽量タスク | Serverless、30 ドル分の無料枠あり |
💰 コスト管理のアドバイス: ARIS-Code を使い始めたばかりであれば、まずは lite + local でプロセスを構築し、モデル呼び出しを apiyi.com 経由にしてトークン使用量を把握することをお勧めします。プロセスが安定してから max や beast モードにアップグレードして本格的な研究を行うことで、初期設定のミスによる高額なトークンコストの浪費を防ぐことができます。
ARIS-Code 実践ワークフロー:一言から論文へ
ARIS-Code で最も驚かされるのは、そのエンドツーエンドのパイプライン /research-pipeline です。このスキルは、前述のすべての段階を1つのコマンドに統合しています。研究の方向性を記述するだけで、システムが自動的に8〜24時間以内に初稿を出力します。
典型的な呼び出し方は以下の通りです。
# シナリオ 1: 全く新しい方向性、ゼロからのスタート
/research-pipeline "factorized gap in discrete diffusion LMs"
# シナリオ 2: 既存の論文の改善
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# シナリオ 3: リバッタル(反論)のみ
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
実際に実行されると、ARIS-Code は文献レビュー → アイデア生成 → 新規性チェック → 実験設計 → GPUスケジューリング → 結果回収 → 論文執筆 → 引用監査 → フォーマットパッケージングという手順を順次こなしていきます。曖昧な意思決定ポイントに遭遇すると、システムは一時停止し、人間のチェックポイントを待ちます。デフォルト設定の --AUTO_PROCEED false を使用すれば、査読者からのフィードバックがあるたびに人間が介入できます。
ARIS-Code には非常に実用的な style-ref パラメータも用意されています。スタイル参照用の論文(例:同じ会議の過去のベストペーパー)を指定すると、システムはその構造や叙述のリズムを模倣しますが、特定の段落をコピーすることはありません。これは「採択率」を追求する研究者にとって、まさに次元の異なる武器となります。トップカンファレンスの査読者は、内容そのものよりも論文のスタイルに対する暗黙の要求を重視することが多いためです。
もう一つ注目すべきエンジニアリングの詳細は、ARIS-Code が Overleaf との双方向同期、W&B による学習曲線モニタリング、Lark(飛書)のモバイルプッシュ通知など、複数の外部システムと統合されている点です。GPU上の実験で重要な転換点が発生すると、即座にスマートフォンに通知が届き、まさに「寝ている間も研究が進む」環境を実現できます。
📊 パフォーマンスデータ: プロジェクト作者が公開した3つのコミュニティ論文事例によると、ARIS-Code が作成した論文は AI 査読スコアで 7-8/10(CS会議、AAAI 2026、IEEE TGRS)を達成しました。ただし、作者は**「人間の査読者は AI 査読システムが捉えられない視点をもたらす」**と明示しており、人間による最終確認を完全に代替できるわけではないと警告しています。
ARIS-Code FAQ(よくある質問)
Q1: ARIS-Code で GPT-5 を Executor(実行エンジン)として使えないのはなぜですか?
ARIS-Code は Claude Code のオープンソース版からフォークして反復開発されているため、その実行エンジン層は Anthropic のネイティブ API プロトコルに完全に固定されています。ツール呼び出し形式、ストリーミング出力形式、思考チェーンの形式などが Claude モデルと深く結びついているためです。実行エンジンを変更したい場合は、OpenClaw や Codex CLI のディストリビューションを使用する必要がありますが、それはもはやオリジナルの ARIS-Code ではありません。最も手軽な方法として、apiyi.com を通じて Claude モデルに直接接続することを推奨します。
Q2: 論文を1本完成させるのにどれくらいのトークンが必要ですか?
beast モードで /research-pipeline を1回実行すると、約500万〜1500万の入力+出力トークンを消費します。Claude Sonnet の料金に換算すると、数十ドルから数百ドルの範囲です。balanced モードであれば、200万〜500万トークンまで削減可能です。具体的な費用は、実験の複雑さと反復回数に依存します。
Q3: ローカルに GPU がなくても ARIS-Code は使えますか?
もちろんです。ARIS-Code は vast や modal といったクラウド GPU モードを設計しており、modal には30ドルの無料枠もあるため、軽量な実験であれば十分です。理論論文(/proof-writer + /formula-derivation)のみを行う場合は、GPU は全く必要ありません。
Q4: デュアルモデルアーキテクチャにおいて、Reviewer(査読者)は必ず GPT-5.4 を使う必要がありますか?
必須ではありません。プロジェクトは GLM、MiniMax、Kimi など、OpenAI プロトコルと互換性のあるあらゆるモデルへの置き換えをサポートしています。apiyi.com のようなアグリゲーションプラットフォームを通じて複数の Reviewer 候補モデルを取得し、自分の研究分野に最も適した批判的 LLM を見つけるための A/B テストを行うことをお勧めします。一部の研究者からは、数学的推論系の論文では Gemini 3 Pro を Reviewer にすると予想以上に良い結果が出る、エンジニアリング最適化系の論文では GPT-5.4 が依然として最適であるといったフィードバックが寄せられています。
Q5: ARIS-Code は学部生や初心者にも適していますか?
ある程度の研究経験がある大学院生以上の方に適しています。その理由は、出力の品質が研究者の分野に対する判断力に大きく依存するためです。例えば、Reviewer が反例を提示した際、それが本当に致命的な欠陥なのか、それとも些末な問題なのかを判断する必要があるからです。経験のない方は、AI によって方向性を誤らされる可能性があります。
Q6: 国内(中国など)で ARIS-Code を実行する際、ネットワークが不安定な場合はどうすればよいですか?
Anthropic 公式インターフェースへの直接接続は、国内では接続リセットやタイムアウトが頻発し、長時間の research-pipeline タスクが途中で失敗する原因となります。一つの成熟した解決策は、ANTHROPIC_BASE_URL を国内 IDC にデプロイされた API 中継サービスに切り替えることです。これにより、ARIS-Code がスリープモードで8時間連続稼働してもネットワークの揺らぎで中断されることがなくなり、beast モードでの連続実験において特に重要となります。
まとめ
ARIS-Code の登場は、一つの重要なトレンドを証明しています。それは、大規模言語モデル時代の科学研究における生産性向上ツールが、「単一機能の補助」から「全ワークフローの自動化」へと進化しているという点です。Executor-Reviewer(実行者とレビュー担当)というデュアルモデルアーキテクチャ、42ものワークフロースキル、そして依存関係ゼロのMarkdown設計は、非常に完成度の高い方法論的フレームワークを構成しています。
国内の研究者にとって、ARIS-Codeを導入する際の最大のハードルは技術的な学習曲線ではなく、Claudeモデルの安定した呼び出しです。私たちは、apiyi.com プラットフォームを通じてClaudeシリーズのモデルにアクセスし、同時にReviewer用としてGPTシリーズのモデルも併用することをお勧めします。これにより、一つのプラットフォームでARIS-Codeワークフローに必要なすべてのモデルをカバーでき、費用精算や呼び出しログの管理も効率的になります。また、国内IDCノードの安定性により、「寝ている間に実験を回す」という重要なユースケースにおいても、ネットワークトラブルによる中断を心配する必要がありません。
トップカンファレンスへの投稿を準備している方や、検証したい研究テーマはあるものの手動で反復作業を行う時間がないという方は、ぜひ週末を使ってARIS-Codeを試してみてください。朝起きたときに初稿が出来上がっていれば、この時間投資は非常に価値のあるものになるはずです。
📌 著者: APIYIチーム — AI大規模言語モデルのAPIサービスと開発者エコシステムを長期的に追跡しています。Claude/GPT/Geminiなどのマルチモデル活用事例については、apiyi.comのドキュメントセンターをご覧ください。