Recently, the official OpenAI Cookbook, in collaboration with Fractional AI, released a highly practical, "hardcore" case study: using AI to automatically audit expense receipts. At first glance, it seems like a standard OCR task, but once you dive into the notebook, you realize it’s actually a masterclass in "taking AI applications from demo to production." It’s the most comprehensive open-source example of Eval-Driven System Design, a topic currently generating a lot of buzz in the industry.
What makes this even more interesting is that this methodology doesn't just solve a technical hurdle; it addresses the fundamental question that haunts every AI engineer: How do I know if my prompt change actually made things better, or if it just looks better? In this article, I’ll break down this OpenAI receipt auditing case in the simplest terms and distill five engineering lessons that every AI application developer can use.
🎯 Quick Guide: This case study comes from the
eval_driven_system_designdirectory incookbook.openai.com, authored by the Fractional AI team (Hugh Wimberly, Joshua Marker, and Eddie Siegel) alongside OpenAI's Shikhar Kwatra. The complete code is available in the official OpenAI Cookbook repository. You can reproduce the entire workflow without changing a single line of code by using an API proxy service like APIYI (apiyi.com), making it perfect for local developers to learn from.
The Business Context of the OpenAI Receipt Audit: Why This Is a Real Problem
Before we jump into the tech, let’s clarify the business context. This isn't a toy project built just to show off an API; it’s a genuine enterprise scenario with clear ROI metrics.
| Business Dimension | Figure | Meaning |
|---|---|---|
| Annual Volume | ~1 Million receipts | Typical scale for a mid-sized company |
| AI Processing Cost | $0.20 | Model invocation fee |
| Manual Audit Cost | $2.00 | Financial staff review |
| Penalty for Missed Audit | $30 / receipt | Compliance/Tax penalties |
| Current Manual Audit Rate | 5% | Only for complex/suspicious cases |
If you crunch these numbers, you’ll see that even a 1% improvement in audit accuracy translates to hundreds of thousands of dollars in annual savings at a volume of 1 million receipts. This is why the Fractional AI team emphasizes "tying evaluation metrics to dollar impact"—it’s not about chasing vanity metrics; it’s about ensuring every prompt change directly impacts the bottom line.
The goal of the entire AI system is crystal clear: Use GPT-4o to automatically audit the majority of receipts, and only escalate "low-confidence" cases to human reviewers, thereby reducing both audit costs and the risk of missed errors. It sounds simple, but the devil is in the details.
What is Eval-Driven Design: A Methodology You Only Appreciate After Getting Burned
If you ask 100 AI engineers, "How do you verify if your prompt changes are correct?", 99 of them will tell you, "I run a few examples and see if the output feels right." This is what the Fractional AI team calls vibe-coding, and it's exactly the development approach that Eval-Driven Design (EDD) aims to replace.
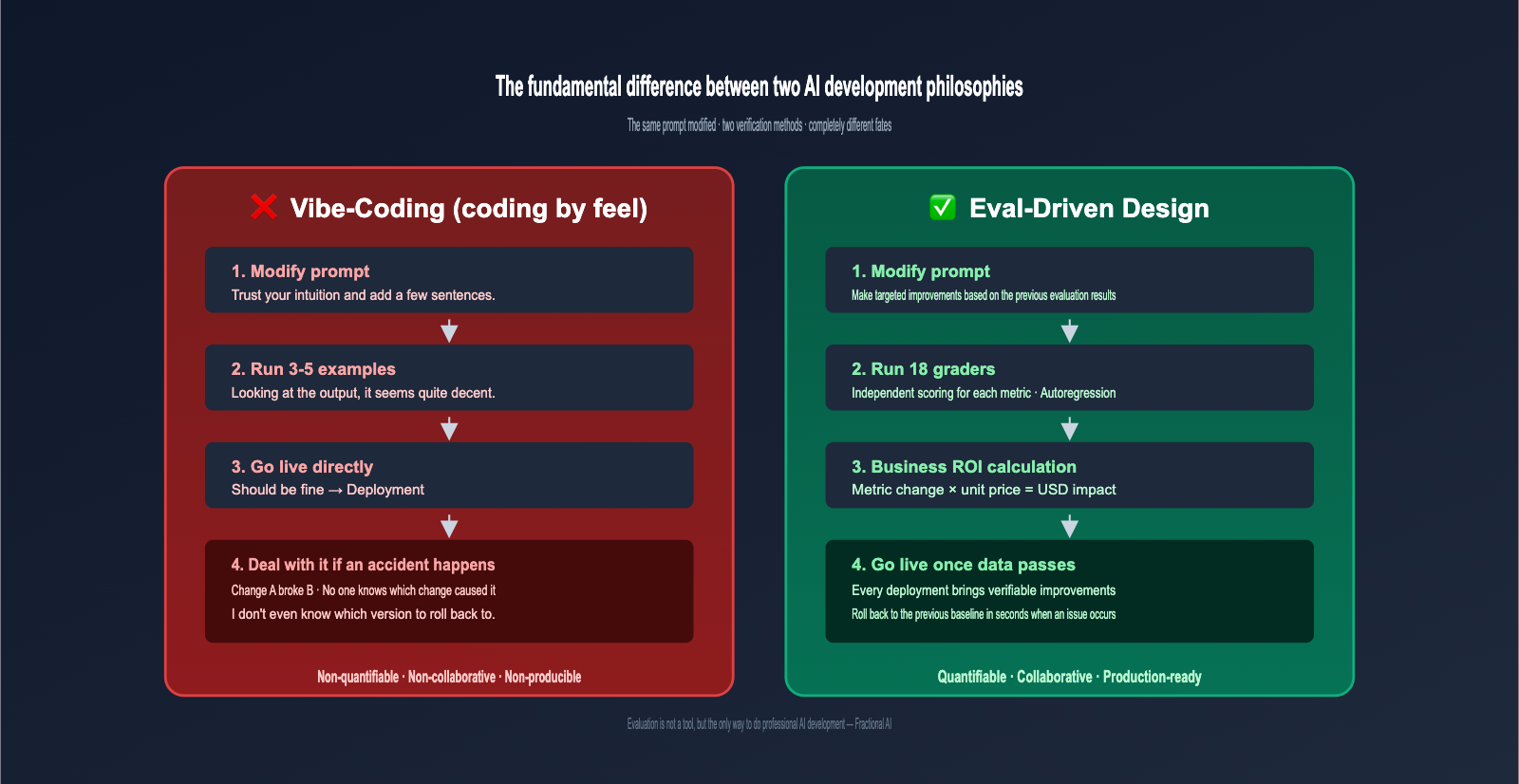
The differences between these two approaches are summarized in the table below:
| Comparison Dimension | Vibe-Coding | Eval-Driven Design |
|---|---|---|
| Verification Method | Run 3-5 examples and look | Run 20-100+ labeled samples for metrics |
| Judging Changes | "Feels like it got better" | "Accuracy improved from 78% to 85%" |
| Business Alignment | Subjective importance | Directly tied to dollar impact |
| Regression Risk | Changing A might break B unnoticed | Full suite of metrics runs automatically |
| Collaboration Scale | Only the author understands | Any engineer can debug |
Fractional AI has a widely cited quote: "Evaluation is not a tool; it is the only way to do professional AI development." This might sound dramatic, but in mission-critical scenarios like receipt auditing, having no evals is like playing the lottery in production—no one would dare ship it with confidence.
💡 Analogy: Eval-Driven Design is like taking an exam with an answer key; you can calculate exactly how much your "total score" improved with each change. Vibe-Coding is like answering questions based on a hunch, not knowing if you're getting better or worse. Production-grade AI must be the former.
The Three-Phase Implementation Process for OpenAI's Receipt Auditing Case
The OpenAI Cookbook breaks the entire case down into three clear phases. This workflow can be applied to almost any AI application involving "image/document input + structured decision output."
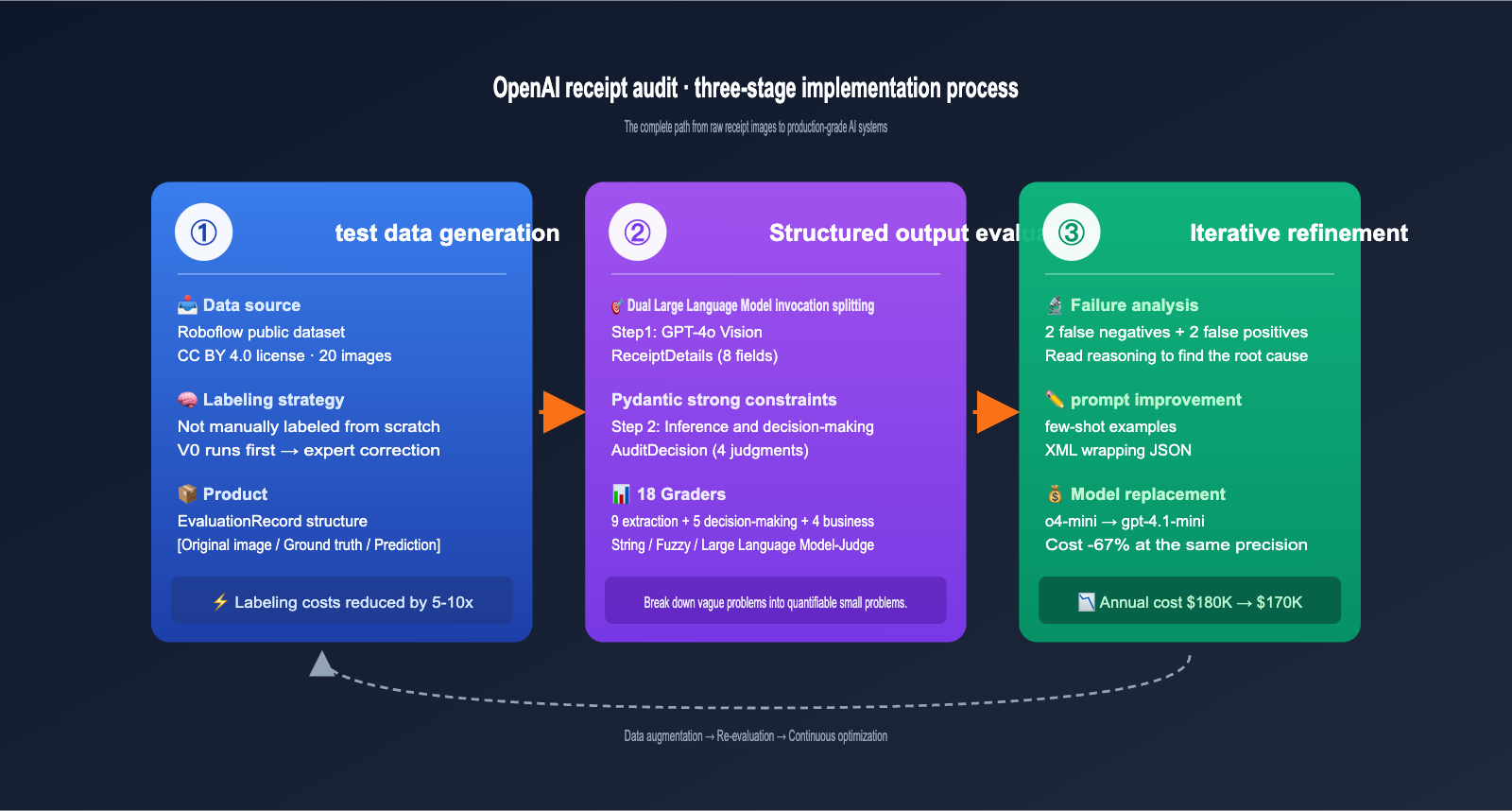
I'll break down each phase in the simplest terms possible.
Phase 1: Test Data Generation, Smartly Saving 80% of Labeling Costs
If you thought the team started by manually labeling thousands of receipt images from scratch, you're underestimating an engineer's knack for efficiency. Fractional AI used a clever strategy: Run a V0 model first, then have experts correct it.
The process: Take 20 real receipt images from a public Roboflow dataset (CC BY 4.0), feed them into a simple GPT-4o + Pydantic extraction pipeline to get V0 outputs. Then, have financial domain experts "find and fix" errors in those outputs, rather than typing data from scratch.
This "generate first, correct later" method boosted domain expert productivity by 5-10x because V0 already identified most fields correctly. The resulting EvaluationRecord data structure is elegant, capturing the "original image path, ground truth details, model prediction details, correct audit decision, and model-predicted audit decision"—one record covering the entire pipeline.
🔧 Reuse Tip: This "V0 run-through → expert correction" labeling strategy can be applied to the cold-start phase of almost any AI application. By using an OpenAI proxy service to quickly generate V0 outputs, you can focus your domain experts' energy on the high-value decision-making tasks.
Phase 2: Structured Output Evaluation, Pydantic is the Real Hero
The entire AI system is chained together by two LLM calls. This separation of concerns is one of the core tenets of EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Step 1: Extract structured receipt information from the image"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Pydantic model for strict constraints
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Step 2: Make audit decisions based on structured data"""
# ... Call LLM to output AuditDecision Pydantic model
Why split it into two steps? Because these tasks require completely different capabilities: Step 1 is "reading and extraction" (vision + information extraction), while Step 2 is "logical reasoning" (inference and decision-making). Mixing them in a single prompt makes it easy for the model to confuse task boundaries and makes debugging nearly impossible.
The field design of the ReceiptDetails and AuditDecision Pydantic models is the most valuable takeaway from this case:
| Model | Key Fields | Business Meaning |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | All information visible on the receipt |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 audit criteria + reasoning process + final conclusion |
Pay special attention to the reasoning field in AuditDecision—it forces the model to write out its thought process before providing a final decision, which is crucial for subsequent chain-of-thought evaluation. Also, note that needs_audit is a logical OR of the four preceding boolean fields. This "score individual items then synthesize the decision" design allows for granular evaluation metrics.
🚀 Integration Tip: The
client.responses.parse()method shown above is OpenAI's latest structured output interface. It allows you to use Pydantic models directly as output constraints, almost entirely eliminating the risk of JSON parsing failures. We recommend using an OpenAI proxy service like apiyi.com for these calls, as this interface requires specific SDK versions, and the proxy gateway ensures the protocol stays up-to-date.
Phase 3: Iterative Refinement, 18 Graders Make Changes Quantifiable
This phase is where EDD truly shines. The Fractional AI team set up 18 independent evaluation metrics (graders) for this receipt auditing system, breaking down the vague question of "is the system good?" into 18 quantifiable sub-problems.
These 18 graders fall into three categories:
| Grader Type | Representative Metrics | Evaluation Method |
|---|---|---|
| Extraction Accuracy (9) | Merchant name / Address / Total amount match | Exact string match / Fuzzy match |
| Audit Decision Accuracy (5) | Travel-related / Over-limit / Math error / Handwritten X / Final decision | Binary classification accuracy |
| Business Alignment (4) | Missing items / Extra items / Item accuracy / Reasoning quality | LLM-as-Judge (0-10 scale) |
Initial evaluation on 20 samples revealed 2 false negatives and 2 false positives. While that number seems small, at a scale of 1 million receipts per year, that's thousands of missed audits. The Fractional team's approach was highly engineering-focused:
- Root Cause Analysis: Examine the
reasoningfield for every error to see where the model got stuck. - Targeted Prompt Engineering: Add few-shot examples, clarify the definition of "travel-related," and wrap JSON examples in XML tags.
- Re-run Evaluation Set: Verify that the changes actually fixed the bug without introducing new ones.
- Model Comparison Experiments: Run the same prompt on
o4-miniandgpt-4.1-minito choose the one with better ROI.
The result of the final step was impressive: Switching from o4-mini to gpt-4.1-mini reduced costs by 67%—lowering annual costs from ~$180K to ~$170K—with almost no drop in accuracy. Without a comprehensive evaluation set, who would dare make such a cost-cutting decision?
📊 Key Insight: The 18 graders aren't just for show; they decompose an seemingly unquantifiable problem ("Is the AI accurate?") into 18 small, independently fixable, and measurable issues. You can create a similar grader system using the OpenAI Evals API via apiyi.com, which is fully compatible with the official interface.
5 Engineering Lessons from the OpenAI Receipt Audit Case
After reading through the entire case study, I’ve distilled five lessons that are applicable to any AI application. These are hard-won insights paid for in real dollars.
Lesson 1: Tie your evaluation to dollars; don't chase 100% on every metric
The case study highlights a counterintuitive finding: improving the accuracy of merchant name recognition had almost no impact on the final audit decision, because the audit rules don't rely on the merchant name. If a team obsesses over boosting merchant name recognition from 92% to 98%, they’re just wasting engineering resources.
Conversely, misidentifying handwritten "X" marks resulted in approximately $75,000 in missed audit losses annually. That is the highest priority metric. Therefore, your choice of metrics should always answer one question: "How much money will I save by fixing this error?"
Lesson 2: Get it working with the most powerful model first, then worry about cost
In the V0 phase, the team chose a top-tier model like o4-mini. This wasn't because they didn't care about costs, but because they knew that making an underpowered model work is far harder than making an overpowered model work cheaply. Get the business logic running and establish a complete evaluation system first, then run model replacement experiments. You can't reverse this order.
Lesson 3: Separate extraction from decision-making; don't try to write one "god-prompt"
Many beginners think: "I can get the 'needs audit' conclusion directly from the image in one call—how cost-effective!" But this design has two fatal flaws: it's not debuggable (if it fails, you don't know if it misread the image or if the logic was wrong), and it's not reusable (the extraction results can only be used for this one decision). Splitting it into two steps might look like an extra API call, but it actually increases the maintainability of the entire system by an order of magnitude.
Lesson 4: Chain-of-thought evaluation catches the "right answer for the wrong reason" trap
The seemingly redundant reasoning field in AuditDecision was used during evaluation to identify a dangerous scenario: the model gives the correct final answer, but the reasoning process is flawed. This "lucky correctness" isn't obvious in small samples, but it will cause massive failures as soon as the data distribution shifts slightly. Forcing the output of reasoning and using LLM-as-Judge to evaluate the quality of that reasoning is an essential insurance policy for production-grade AI applications.
Lesson 5: You can engineer your way to lower labeling costs
Don't be intimidated by the stereotype that "AI projects require massive amounts of labeled data." The strategy of using 20 samples plus expert corrections on V0 outputs was enough to build a useful evaluation set. The key is to ensure the evaluation set matches the distribution of your real business data, rather than chasing sample size. Fractional's experience shows that using initial V0 outputs as "seed labels" is 5-10 times more efficient than starting manual labeling from scratch.
Considerations for Replicating the OpenAI Receipt Audit Case in China
For developers in China looking to replicate this cookbook, there are three hurdles to clear: Can you access the latest models like o4-mini / gpt-4.1-mini? Can you use the latest responses.parse interface? And can you connect to the Evals API endpoints?
Directly connecting to OpenAI from within China is often unstable, especially for image-based interfaces where the large payload size leads to higher failure rates than text-only interfaces. Using an official API proxy service like APIYI can solve these three problems in one go. You only need to change one line for the base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # The only line you need to change
api_key="Your APIYI Key"
)
# All subsequent code is identical to the cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
This is the critical difference between an "Official OpenAI API Proxy" and a generic "OpenAI-compatible API"—the former ensures the interface is perfectly synchronized with OpenAI's official version, while the latter may only support basic interfaces and often lacks advanced capabilities like responses.parse or the Evals API. When replicating official case studies like this cookbook, choosing an official proxy service saves you from a mountain of compatibility headaches.
OpenAI Receipt Audit Case FAQ
Q1: Is this approach only for receipts?
Not at all. Eval-Driven Design is suitable for any scenario where the "input is relatively open-ended, but the output requires structured decision-making." Contract auditing, medical image triage, customer service quality inspection, resume screening, and fraud detection can all utilize this three-stage process. The core logic remains the same: designing Pydantic schemas and evaluation graders.
Q2: Aren't 18 graders too many for a small team to handle?
You can start with 5-6 core graders, such as final decision accuracy and key field extraction accuracy. The quantity isn't what matters; what matters is that each grader corresponds to a specific failure mode. We recommend running a small sample on GPT-4o via the apiyi.com console first, and then expanding your evaluation dimensions once the business logic is stable.
Q3: Won't using o4-mini directly in V0 be too expensive?
In the V0 stage, the number of model invocations is usually in the dozens or hundreds, costing anywhere from a few dollars to a few dozen dollars—it's completely manageable. The real cost-saving happens at the production scale with millions of calls. By that point, you'll already have a complete evaluation set for model replacement experiments, just like the case where switching from o4-mini to gpt-4.1-mini cut costs by 67%.
Q4: How does GPT-4o Vision perform with handwritten Chinese receipts?
Accuracy for printed English receipts is very high (95%+), and printed Chinese is also quite good (90%+). Performance on handwritten Chinese depends on legibility. We suggest building an evaluation set with 100 real-world samples rather than relying on demo videos. The cost of calling GPT-4o Vision via an API proxy service is the same as the official one, making it perfect for large-scale evaluation experiments.
Q5: Can I run this cookbook if I don't have Evals API access?
Yes. The Evals API mainly hosts your grader configurations and run management on OpenAI's side, but the actual evaluation logic can be run locally in Python with the exact same results. The grader functions in the cookbook are all open-source; you can copy them locally and use them immediately. If your business scales up later, you can consider migrating to managed Evals.
Q6: What's the difference between using APIYI for this case versus the official API?
The interface protocols, model versions, and parameter support are fully synchronized with OpenAI's official standards—that's the core promise of an "official API proxy service." The main difference is at the network level: direct connections to OpenAI from within China often suffer from SSL handshake failures and timeouts. APIYI's gateways are deployed in domestic data centers, which significantly improves stability, especially for image-based interfaces. This is critical for running long-duration evaluation tasks.
Summary
The OpenAI Receipt Audit case is worth studying repeatedly because it breaks down the abstract proposition of "how to use AI to solve a real business problem" into a concrete engineering practice involving three stages, 18 evaluation metrics, and quantifiable dollar impacts. This is exactly the kind of AI engineering blueprint that the community currently lacks.
If you're building any AI application that involves "inputting documents/images and outputting structured decisions," we highly recommend running through this cookbook in its entirety. Don't just read—get your hands dirty. The true value of eval-driven design is only felt the moment you see your metrics shift. We suggest reproducing this using an OpenAI API proxy service like apiyi.com to save yourself the hassle of environment debugging and focus your energy on the methodology itself.
By engraving "eval-driven" into your development process, your AI system evolves from a "looks like it works" toy into an engineering product you can confidently put into production and calculate ROI for. The gap between those two states might just be $75,000.
📌 Author: APIYI Team — Long-term observers of engineering practices for OpenAI / Anthropic / Google multimodal APIs. For more cookbook deep dives and API proxy service integration guides, visit the apiyi.com documentation center.