OpenClawを日常のワークフローで活用しているものの、毎月のAPI請求額を見て驚愕していませんか?——$300、$500、あるいは $600 以上?
それはあなたの使い方のせいではありません。OpenClawのアーキテクチャ設計によるものです。最適化されていないOpenClawインスタンスは、タスクを実行するたびに大量の「不要なコンテンツ」をAIモデルに送信し、無駄にトークンを消費してしまいます。
朗報があります。いくつかの重要な設定を行うだけで、請求額を80〜90%削減できるのです。そして、ほとんどの人が知らない最も効果的な方法が、OpenAI互換モードではなく、Claudeネイティブ形式のインターフェースを使用することです。
この記事では、OpenClawのトークン消費量が高くなる根本的な原因を深く掘り下げ、正しいインターフェースの使用法、キャッシュの設定、そして適切なAPIチャネルの選択方法をステップバイステップで解説します。毎月の請求額を $600 から $60 にまで引き下げましょう。
1. OpenClawのToken消費が激しい3つの核心的理由
理由 1:リクエストのたびに対話履歴をすべて再送信している
これは最も見落とされがちですが、最も影響が大きい原因です。
OpenClawは設計上「完全なコンテキスト」の原則に従っています。AIモデルにリクエストを送る際、対話開始時からのすべての履歴メッセージをまとめて送信します。これにより、モデルは「以前に何をしたか、何を話したか」を「覚える」ことができるのです。
例を挙げてみましょう:
第1ラウンド:ユーザーが50 tokens送信、AIが200 tokens返信 → 今回の送信量は250 tokens
第2ラウンド:ユーザーが50 tokens送信、AIが200 tokens返信 → 今回の送信量は500 tokens(第1ラウンド分を含む)
第3ラウンド:ユーザーが50 tokens送信、AIが200 tokens返信 → 今回の送信量は750 tokens(第1+2ラウンド分を含む)
...
第10ラウンド:実際には250 tokens増えただけですが、送信量はすでに2,500 tokensに達しています
複雑なタスクを処理するOpenClawのワークフローでは、この「雪だるま式」の効果により、Token消費が幾何級数的に増加します。通常、コンテキスト履歴は総Token消費の40〜50%を占めます。
理由 2:システムプロンプトが毎回再送信される
OpenClawのシステムプロンプト(System Prompt)は、Agentの役割、能力の境界、利用可能なツールリスト、行動規範などの核心的な内容を定義しており、通常 5,000〜10,000 tokens ほどになります。
重要な問題:この巨大なシステムプロンプトは、APIを呼び出すたびに毎回完全に送信されます。
例えば、毎日OpenClawで50件のタスクを処理し、1回あたりのシステムプロンプトが8,000 tokensだと仮定します:
1日のシステムプロンプト消費 = 50 × 8,000 = 400,000 tokens
1ヶ月の消費 ≈ 12,000,000 tokens(システムプロンプトのみ!)
Claude 3.5 Sonnetの入力料金($3/100万 tokens)で計算すると、システムプロンプトだけで毎月 $36 かかることになります。これには対話内容や出力結果は含まれていません。
理由 3:推論モードによるTokenの10〜50倍の急増
OpenClawが複雑なタスクに直面すると、「思考の連鎖(CoT)」や「推論モード(Thinking/Reasoning)」が有効になります。このモードでは、AIが「まず考えてから話す」ため、出力の質は高まりますが、代償としてToken消費が爆発的に増加します。
推論Token消費の特徴:
- 思考プロセスで大量の中間Tokenが発生する(通常は見えませんが、課金対象です)
- 複雑なタスクの推論プロセスでは、10,000〜50,000 tokensが発生することがある
- 制御しないと、わずか数件の複雑なタスクで1日の予算を使い果たしてしまう可能性があります
| Token消費シナリオ | 通常モード | 推論モード | 倍率の差 |
|---|---|---|---|
| 簡単なQ&Aタスク | 〜500 tokens | 〜2,000 tokens | 4倍 |
| メール処理フロー | 〜2,000 tokens | 〜15,000 tokens | 7.5倍 |
| コード分析タスク | 〜5,000 tokens | 〜80,000 tokens | 16倍 |
| 複雑な多段階調査 | 〜10,000 tokens | 〜200,000 tokens | 20倍以上 |
🎯 クイック診断: OpenClawの請求額が異常に高い場合は、まずTokenログで推論モードの使用状況を確認してください。
不要なタスクの推論モードをオフにすることは、最も即効性のある節約手段の一つです。
また、より適切なモデルに切り替えることでもコストを大幅に削減できます。 APIYI (apiyi.com) を利用すれば、異なるモデル間での切り替えテストを素早く行えます。
3大原因の消費割合
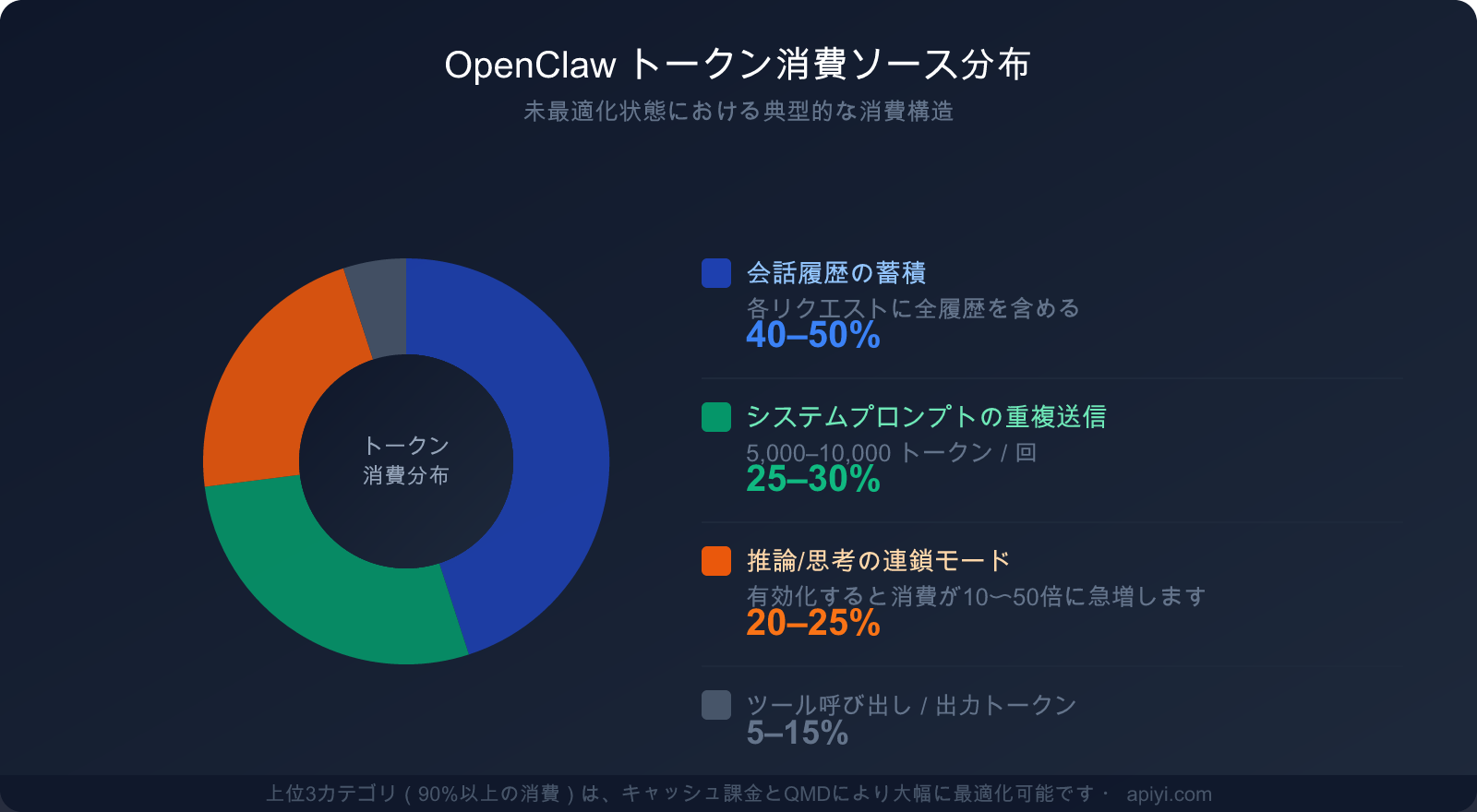
これら3つの主要な消費源を理解することが、節約戦略を立てるための前提条件となります:
| 消費源 | 総消費に占める割合 | 最適化の可否 | 主な最適化手段 |
|---|---|---|---|
| 会話履歴(コンテキストの蓄積) | 40-50% | ✅ 高度に可能 | キャッシュ、定期的なクリーンアップ、QMD |
| システムプロンプトの繰り返し送信 | 25-30% | ✅ 高度に可能 | コンテキストキャッシュ(最大90%節約) |
| 推論/思考の連鎖モード | 20-25% | ✅ 必要に応じて | 複雑なタスクのみに限定して有効化 |
| ツール呼び出しと出力 | 5-15% | ⚡ 限定的 | ツール説明の簡素化 |
2. 最も見落とされがちな最強の節約術:Claude プロンプトキャッシュ
Claude プロンプトキャッシュとは
Claude の Prompt Caching(プロンプトキャッシュ)は、Anthropic が2024年末に導入したネイティブ機能です。その核心的なロジックは、頻繁に繰り返される送信内容をサーバー側にキャッシュし、次回の呼び出し時に再処理することなく直接キャッシュを読み取るというものです。
キャッシュ読み取りの価格:通常の入力価格のわずか 10%(90% オフ)
これは、例えば毎回 8,000 トークンのシステムプロンプトを送信する場合、キャッシュが有効であれば、2回目以降のヒット時には 800 トークン分として計算されることを意味します。毎日数十回のモデル呼び出しを行う OpenClaw ユーザーにとって、この最適化だけで月に数百ドルを節約できる可能性があります。
プロンプトキャッシュの料金体系
| キャッシュタイプ | 料金倍率 | 有効期間 | 適用シーン |
|---|---|---|---|
| 通常の入力トークン | 1× 基本価格 | キャッシュなし | 毎回新規処理 |
| キャッシュ書き込み(初回) | 1.25× | 5分間 TTL | キャッシュの構築 |
| キャッシュ書き込み(長期) | 2× | 1時間 TTL | 頻繁な呼び出しシーン |
| キャッシュ読み取り(ヒット) | 0.1×(90%オフ) | 有効期間内 | 繰り返しのリクエスト |
実際の節約額の計算例:
シナリオ:OpenClaw システムプロンプト 8,000 トークン
1日 50 回呼び出し、そのうち 48 回がキャッシュにヒット
キャッシュ未使用:50 × 8,000 = 400,000 トークン
費用 = 400,000 × $3/1M = $1.20/日 = $36/月
キャッシュ使用: 書き込み 2 回:2 × 8,000 × 1.25 = 20,000 トークン = $0.06
ヒット 48 回:48 × 8,000 × 0.1 = 38,400 トークン = $0.12
1日の費用 ≈ $0.18 → 1ヶ月 ≈ $5.40
節約額:$36 - $5.40 = $30.60/月(システムプロンプト 1 つのみの計算)
節約率:85%
OpenClaw でキャッシュ機能を有効にする方法
キャッシュ機能を有効にするには、必須条件があります。それは、OpenAI 互換モード(/v1/chat/completions)ではなく、Anthropic ネイティブ形式のインターフェース(/v1/messages)を使用することです。
正しい設定方法(Python SDK の例):
import anthropic
# OpenAI SDK ではなく、Anthropic ネイティブ SDK を使用する必要があります
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI は Anthropic ネイティブ形式をサポートしています
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "あなたはプロの AI アシスタントです...[8000 トークンのシステムプロンプト]",
"cache_control": {"type": "ephemeral"} # ← 重要:この内容をキャッシュ候補としてマーク
}
],
messages=[
{"role": "user", "content": "今日のメールを整理して"}
]
)
キャッシュの技術的制約:
- 最大 4 つのキャッシュ・ブレイクポイント(
cache_controlマーク)を設定可能 - Sonnet シリーズ:最小キャッシュ対象内容 ≥ 1,024 トークン
- Opus / Haiku 4.5:最小キャッシュ対象内容 ≥ 4,096 トークン
- キャッシュ対応モデル:Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3 など
🎯 重要ポイント: APIYI (apiyi.com) は、
cache_controlパラメータを含む Anthropic ネイティブ形式の呼び出しを完全にサポートしています。APIYI でネイティブ形式を使用して Claude モデルを呼び出すことで、キャッシュによる節約(最大 90% オフ)+ APIYI の 20% オフ特典という、強力なダブル割引を享受できます。
3. 重要な認識:なぜ OpenAI 互換モードではトークンを節約できないのか
これは、多くの OpenClaw ユーザーが最も陥りやすい落とし穴です。
2 つのインターフェース形式の本質的な違い
多くのサードパーティ AI ツールや中継サービスは、ユーザーの利便性のために OpenAI 互換モードを提供しています。これは、OpenAI の /v1/chat/completions 形式を使って、Claude などの非 OpenAI モデルを呼び出せるようにするものです。
一見すると、「1 つのコードですべてのモデルを呼び出せる」ため便利に思えますが、致命的な欠点があります。
/v1/chat/completions 形式には cache_control パラメータを置く場所がありません。なぜなら、これは Anthropic 独自のネイティブ機能だからです。
OpenAI 互換形式で Claude を呼び出すと、以下のことが起こります:
- リクエストが OpenAI 形式に変換される
- 中継サーバーやプロキシがそれを Anthropic ネイティブ形式に再変換する
- しかし、
cache_control情報は最初のステップですでに失われている - Claude サーバーに届くリクエストにはキャッシュフラグがないため、毎回フル料金で計算される
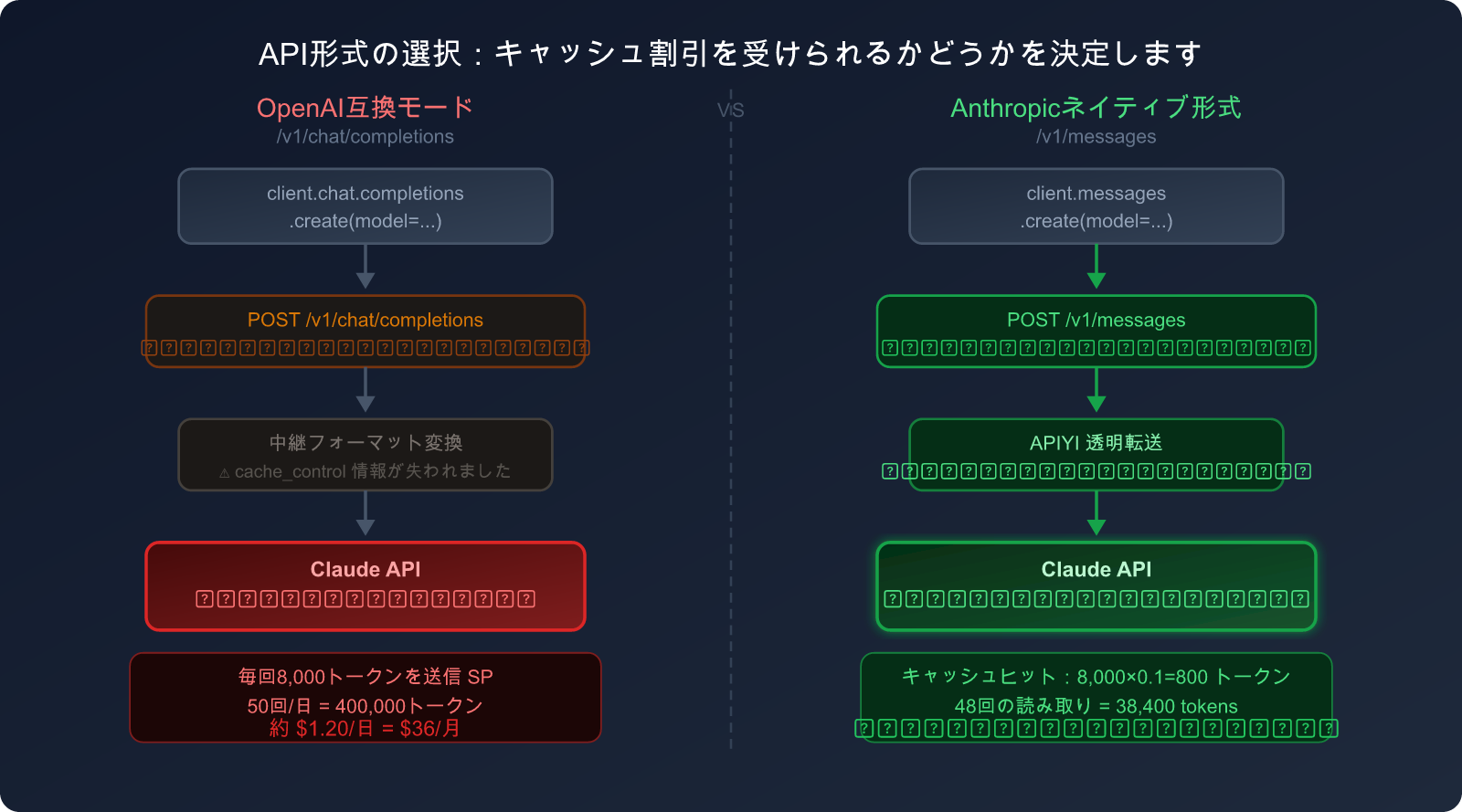
OpenAI 互換モード vs Anthropic ネイティブ形式の比較
| 比較項目 | OpenAI 互換モード | Anthropic ネイティブ形式 |
|---|---|---|
| インターフェースパス | /v1/chat/completions |
/v1/messages |
| Claude キャッシュ対応 | ❌ 非対応 | ✅ 完全対応 |
cache_control パラメータ |
❌ フィールドなし | ✅ 4つのブレイクポイントをサポート |
| システムプロンプトの課金 | 💸 全額(1× 価格) | 💰 キャッシュ読み取り(0.1× 価格) |
| コードの複雑さ | 低(汎用コード) | 中(Anthropic SDKが必要) |
| 節約効果(高頻度シーン) | 0% | 最大 90% |
非公式 API デプロイにおける追加の問題
インターフェース形式の問題以外にも、混同しやすいケースがあります。それは、クラウドベンダーがデプロイしている「同名」モデルは、必ずしも開発元(原厂)と同じではないということです。
GLM-4(智譜 AI)を例に挙げます:
- z.ai 公式 API:智譜が自社開発したキャッシュ計量機能をサポートしています。
- Alibaba Cloud / Tencent Cloud などにデプロイされた GLM-4:クラウドベンダーの API ゲートウェイを使用しているため、開発元独自のキャッシュ計量機能は備わっていません。
これは GLM-4 自体の問題ではなく、非公式デプロイ(マネージドサービス)に共通する特性です。クラウドベンダーがモデルをホストする場合、通常は標準的な対話 API のみを公開し、モデル開発元独自のプライベートな機能(キャッシュ計量など)までは透過させないのが一般的です。
例え話:代理店を通じて購入した商品では、メーカー公式の特別なアフターサービスが受けられないのと似ています。
実際のインパクト:
シナリオ:1日 50 回呼び出し、システムプロンプト 6,000 トークン
開発元公式 API(キャッシュ対応):
書き込み:2 回 × 6,000 × 1.25 = 15,000 トークン
読み取り:48 回 × 6,000 × 0.1 = 28,800 トークン
等価消費 ≈ 43,800 トークン/日
非公式 API(キャッシュなし):
全額:50 回 × 6,000 = 300,000 トークン/日
差:キャッシュなしの消費量は、キャッシュありの約 6.85 倍
4. 公式APIの比較:OpenClawに最適な接続プランの選び方
4つの接続プランの比較
| 接続プラン | 価格(定価比) | キャッシュ対応 | マルチモデル対応 | 活用シーン |
|---|---|---|---|---|
| Anthropic 公式 API | 100%(定価) | ✅ 完全対応 | ❌ Claudeのみ | 予算が潤沢なClaude専業ユーザー |
| APIYI(Anthropic原生フォーマット) | 80%(20%OFF) | ✅ 完全対応 | ✅ マルチモデル | 推奨:コスト削減 + 柔軟な切り替え |
| 一般的な中継サービス(OpenAI互換) | 85-95%程度 | ❌ 非対応 | ✅ マルチモデル | Claudeのキャッシュを使用しない場合 |
| クラウドプロバイダー経由 | 90-110%程度 | ❌ 非対応 | ❌ 単一モデル | 企業のコンプライアンス要件がある場合 |
APIYI の2つの節約ロジック
APIYI を Claude モデルで使用するメリットは、Anthropic原生フォーマットへの対応と20%OFFの価格設定を両立している点にあります。
これらが組み合わさることで、以下のような劇的な差が生まれます:
一般ユーザー(定価 + OpenAI互換、キャッシュなし):
月間システムプロンプトのトークン消費量:12,000,000 tokens
費用 = 12,000,000 × $3/1M = $36
APIYI ユーザー(20%OFF + 原生フォーマット + キャッシュ利用):
実際の課金トークン ≈ 1,440,000 tokens(キャッシュ適用後)
費用 = 1,440,000 × $3×0.8/1M = $3.46
総合的な節約率 = ($36 - $3.46) / $36 ≈ 90%
🎯 選定のアドバイス: OpenClaw を使用し、主に Claude モデルを選択している場合は、
APIYI (apiyi.com) を通じて Anthropic 原生フォーマットで接続することを強くお勧めします。
20%OFFの基本料金 + キャッシュによる90%の節約が重なることで、請求額を85〜90%削減できます。
また、APIYI は GLM-5 や GPT などのマルチモデルもサポートしているため、いつでも効果を比較しながら切り替えることが可能です。
5. OpenClaw 節約完全攻略:すぐに実行できる5つのステップ
ステップ 1:Anthropic 原生フォーマットのインターフェースに切り替える
これは最も重要なステップであり、キャッシュによる課金メリットを享受できるかどうかを直接左右します。
OpenClaw での設定方法:
OpenClaw のモデル設定(config.json)内の models.providers フィールドを見つけ、以下の形式で APIYI をプロバイダーとして追加します。ポイントは api フィールドを "anthropic-messages" に設定することです。これにより、Anthropic 原生フォーマットが使用され、キャッシュ課金が有効になります。
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "ここにAPIキーを入力",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
設定のポイント解説:
"api": "anthropic-messages"← 最重要。/v1/chat/completions(互換形式)ではなく、/v1/messages(原生形式)の使用を指定します。"baseUrl": "https://api.apiyi.com"← APIYI のベースURL(/v1を付ける必要はありません。OpenClaw が自動で補完します)。"anthropic-version": "2023-06-01"← Anthropic API のバージョンヘッダー。これがないとリクエストが失敗します。contextWindow: 200000← Claude Sonnet 4.6 は 200K のコンテキストウィンドウをサポートしています。
キャッシュが有効かどうかの確認:
API レスポンスヘッダーまたはログ内の cache_read_input_tokens と cache_creation_input_tokens フィールドを確認してください。値が入っていれば、キャッシュが有効に機能しています。
# キャッシュレスポンスの検証
response = client.messages.create(...)
# usage フィールドを確認
print(response.usage)
# 出力例:
# Usage(
# input_tokens=150, # 今回新しく追加されたトークン
# cache_creation_input_tokens=8000, # 初回キャッシュ書き込み(1.25倍で課金)
# cache_read_input_tokens=0, # 以降のキャッシュヒット(0.1倍で課金)
# output_tokens=300
# )
🎯 接続方法: APIYI (apiyi.com) で登録して API キーを取得した後、
base_urlをhttps://api.apiyi.com/v1に設定するだけで Anthropic 原生フォーマットが利用可能になります。
他のコードを修正する必要はなく、Claude のキャッシュ課金が即座に適用されます。
ステップ 2:キャッシュブレークポイントを適切に配置する
キャッシュブレークポイント(cache_control)を置く場所は非常に重要です。「容量が大きく、かつ固定されている内容」をキャッシュすべきです:
# ベストプラクティス:システムプロンプト + ツール定義をキャッシュする
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # 5,000-10,000 トークンのメインシステムプロンプト
"cache_control": {"type": "ephemeral"} # ブレークポイント1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # ツール定義リスト(通常これも大きい)
"cache_control": {"type": "ephemeral"} # ブレークポイント2
}
],
messages=conversation_history, # 会話履歴(毎回変わるためキャッシュしない)
...
)
キャッシュ戦略のポイント:
- ✅ キャッシュに適しているもの:システムプロンプト、ツール定義、大規模な静的ドキュメント、RAG で取得したドキュメント内容。
- ❌ キャッシュに適さないもの:現在のユーザーメッセージ、動的に生成されるコンテンツ、毎回変化するデータ。
- ⚠️ 順序に注意:キャッシュは前方一致で適用されます。静的なコンテンツは必ずメッセージシーケンスの前方に配置してください。
ステップ 3:QMD を有効にしてコンテキスト長を削減する
QMD(Quick Memory Database)は、OpenClaw のローカルセマンティック検索機能です。その仕組みは以下の通りです:
従来の方法:
毎回 [すべての会話履歴] を送信 → 大量のトークンを消費
QMD 方式:
ローカルにベクトルデータベースを構築 → 最も関連性の高い履歴の断片を検索
毎回 [最も関連性の高い3〜5件の履歴] のみを送信 → トークンを 60-97% 節約
QMD の実際の節約効果:OpenClaw の公式ドキュメントによると、QMD を使用することで 60〜97% のトークン削減が可能です。具体的な割合は、会話履歴の量とタスクの種類に依存します。
有効化の方法(OpenClaw 設定画面):
- Settings → Memory → Enable QMD をオンにする
- QMD の保存パスを設定(ローカル保存。データはアップロードされません)
- 関連性しきい値を設定(ノイズとなる履歴を避けるため、0.7以上を推奨)
ステップ 4:タスクの種類に応じて適切なモデルを選択する
すべてのタスクに最強のモデルが必要なわけではありません。正しいモデルの割り当てがコスト管理の鍵となります:
タスク階層化戦略:
簡単なタスク(スケジュールのリマインド、フォーマット変換、単純な検索)
→ Claude Haiku 4.5 を使用(最速、最安)
→ Sonnet の約 1/5 の価格
中程度のタスク(メール処理、ファイル整理、コードレビュー)
→ Claude Sonnet 4.6 を使用(バランス型)
→ 成功率 86.9%(PinchBench 1位)
複雑なタスク(アーキテクチャ分析、多段階のリサーチ、複雑な推論)
→ Claude Opus 4.6 を使用(最強の推論能力)
→ 本当に必要な時だけ推論モードを有効にする
ステップ 5:定期的なコンテキストのクリア
会話履歴はトークン消費の最大の要因の一つ(40〜50%)です。以下の運用を推奨します:
- 最大コンテキストターン数の設定:15〜20ターンを超えたら自動的に要約して履歴をクリアする。
- タスク完了後の手動クリア:新しいタスクを始める前にコンテキストをリセットする。
- OpenClaw のセッション圧縮機能の有効化:AI を使って長い履歴を要約に圧縮する。
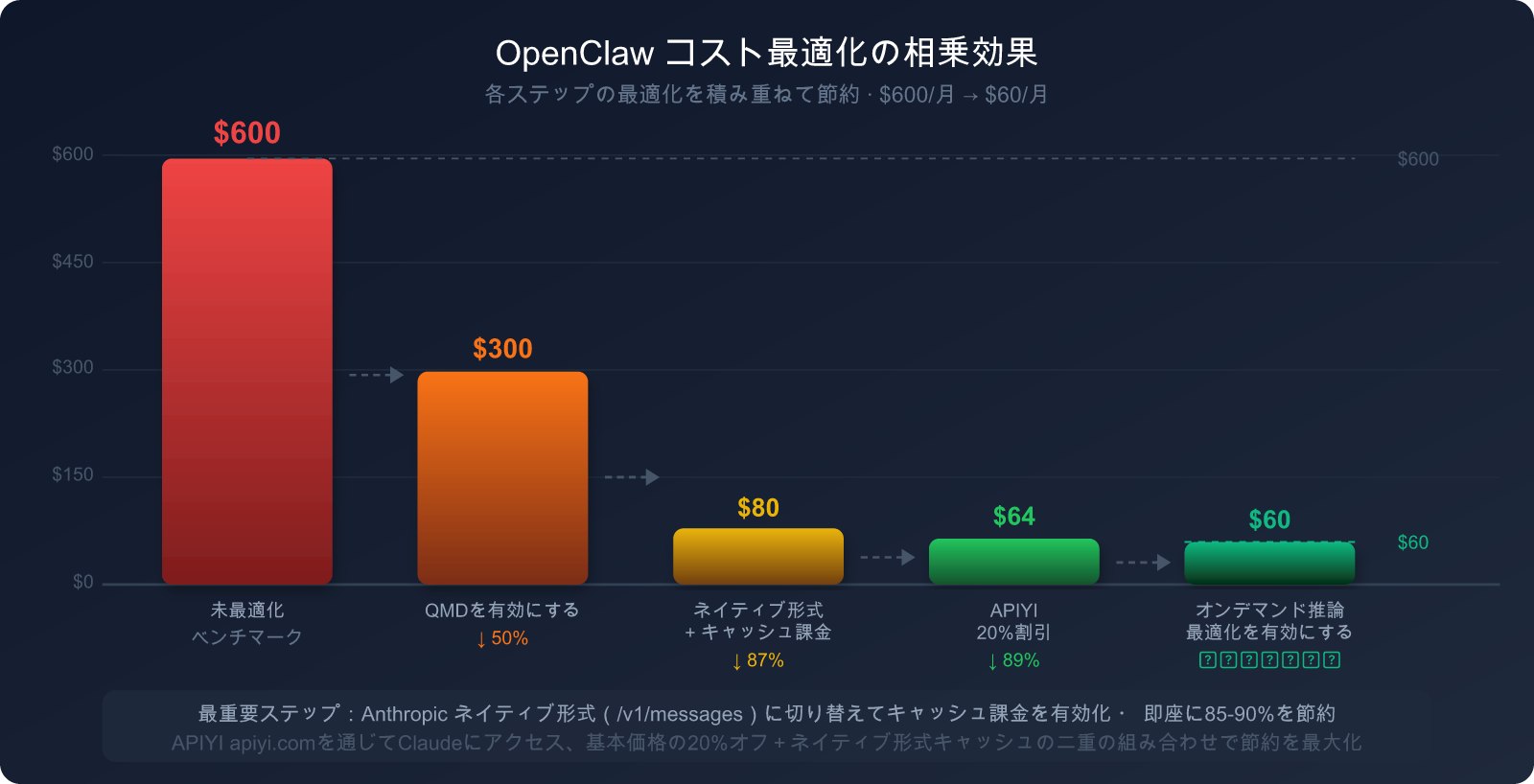
5つの最適化による総合的な効果予測
OpenClaw を中程度に使用するユーザーを基準とした場合(最適化前の月額が約 $300-600)、上記の5つのステップを実行した後の期待効果は以下の通りです:
| 最適化ステップ | 削減対象のコスト源 | 期待される節約率 | 実行の難易度 |
|---|---|---|---|
| 1. 原生フォーマットへの切り替え | システムプロンプトの重複課金 | 85-90% 節約 (SP部分) | ⭐ 低(base_urlの変更のみ) |
| 2. キャッシュブレークポイントの設定 | ツール定義 + 静的ドキュメント | 80-90% 節約 (ツール部分) | ⭐⭐ 低〜中 |
| 3. QMD の有効化 | 会話履歴トークン | 60-97% 節約 (履歴部分) | ⭐⭐ 低〜中 |
| 4. タスク別モデルの使い分け | 全トークンコスト | 30-70% 節約 (モデル単価差) | ⭐⭐⭐ 中 |
| 5. 定期的なコンテキストクリア | 履歴の累積(雪だるま式増加) | 20-40% 節約 (長期的メリット) | ⭐ 低 |
🎯 実行優先度のアドバイス: ステップ 1(原生フォーマットへの切り替え)とステップ 3(QMD の有効化)は、最もリターンが大きく、かつ操作が簡単な2つのステップです。
まずはこの2つを完了させることをお勧めします。これだけで通常、請求額を 60〜80% 即座に下げることができます。
APIYI (apiyi.com) を通じて Claude に接続すれば、ステップ 1 はbase_urlの設定を1行変更するだけで、5分以内に完了します。
六、実践設定:OpenClaw + APIYI + Claude キャッシュの完全な例
以下は、ほとんどのユーザーがそのまま再利用できる、最適化された OpenClaw 設定の完全な例です。
import anthropic
# APIYI を通じて Anthropic ネイティブ形式を使用
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # APIYIのキー(apiyi.com で登録して取得)
base_url="https://api.apiyi.com/v1"
)
# システムプロンプトの定義(大容量のコンテンツ、キャッシュに適しています)
SYSTEM_PROMPT = """
あなたは OpenClaw プラットフォーム上で動作するプロフェッショナルな AI アシスタントです。
あなたの職務には、スケジュールの管理、メールの処理、ファイルの整理、コード開発の支援などが含まれます...
[通常 5,000〜10,000 トークンの詳細な説明]
"""
# ツールリストの定義(これも大容量の固定コンテンツで、キャッシュに適しています)
TOOL_DEFINITIONS = """
利用可能なツール:calendar_api, email_api, file_system, code_runner...
[ツールの詳細説明、通常 2,000〜5,000 トークン]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""キャッシュを有効化した、最適化済みの OpenClaw API 呼び出し"""
response = client.messages.create(
model="claude-sonnet-4-6", # PinchBench で1位のモデル
max_tokens=4096,
# システムプロンプト:キャッシュブレークポイントをマーク
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # キャッシュブレークポイント1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # キャッシュブレークポイント2
}
],
# 会話履歴 + 新規メッセージ
messages=[
*conversation_history, # 履歴メッセージ(キャッシュせず、毎回変化する)
{"role": "user", "content": user_message}
]
)
# トークンの使用状況を出力(最適化効果のモニタリング用)
usage = response.usage
print(f"入力トークン: {usage.input_tokens}")
print(f"キャッシュ書き込み: {usage.cache_creation_input_tokens}")
print(f"キャッシュ読み取り: {usage.cache_read_input_tokens}")
print(f"出力トークン: {usage.output_tokens}")
return response.content[0].text
🎯 クイックスタート: 上記コードの
api_keyを、APIYI(apiyi.com)で登録後に取得したキーに置き換えるだけで、他の修正は不要です。Anthropic ネイティブ形式 + キャッシュ課金 + APIYI の20%オフ特典の組み合わせをすぐに利用できます。
よくある質問(FAQ)
Q: APIYI は本当に Anthropic ネイティブ形式(/v1/messages)をサポートしていますか?
はい、APIYI(apiyi.com)は以下の2つのインターフェース形式を同時にサポートしています:
- Anthropic ネイティブ形式:
/v1/messages(キャッシュ課金をサポート) - OpenAI 互換形式:
/v1/chat/completions(汎用コードに便利)
Claude モデルについては、キャッシュ課金の恩恵を受けるために Anthropic ネイティブ形式の使用を強く推奨します。anthropic Python SDK を使用し、base_url を APIYI に向けるだけで利用可能です。
🎯 APIYI(apiyi.com)にアクセスしてアカウントを登録すると、コンソールで両方の形式の接続サンプルコードを確認できます。
Q: キャッシュの TTL(有効期限)5分は十分ですか?1時間の TTL が必要かどうかはどう判断すればいいですか?
これは呼び出しの頻度によります:
- OpenClaw の呼び出し間隔が5分未満の場合(タスクフローを継続的に処理する場合など)は、デフォルトの5分 TTL で十分です。
- 呼び出し間隔が5分から1時間の間の場合(一連のタスクを処理した後に一時停止する場合など)は、1時間の TTL を検討してください(費用は書き込み価格の2倍になりますが、キャッシュヒット率が高まります)。
- 呼び出し間隔が1時間を超える場合、キャッシュのメリットは限定的なので、毎回書き直す形で問題ありません。
Q: GLM-5 などの中国産モデルを使用する場合、節約のアドバイスはありますか?
GLM-5 のキャッシュ機能は、Zhipu AI 公式(z.ai)のネイティブ API 呼び出しを通じて行う必要があり、Aliyun などのサードパーティデプロイでは使用できません。
APIYI も GLM-5 などのモデルをサポートしており、価格は公式の8割以下に設定されています。テスト段階で統一されたインターフェースを使用して各モデルの効果を比較するのに便利です。特定のシーンに適したモデルが確定した後に、引き続き APIYI を使うか、直接メーカーに接続するかを決定すると良いでしょう。
Q: すでに他の API 中継サービスを使っていますが、ネイティブ形式をサポートするプラットフォームへの移行は難しいですか?
移行コストは非常に低いです。修正が必要なのはコード内の2つのパラメータだけです:
# 移行前(OpenAI 互換形式)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="旧中継サービスのURL")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# 移行後(Anthropic ネイティブ形式、キャッシュ対応)
import anthropic
client = anthropic.Anthropic(
api_key="sk-新APIYIキー", # ← APIYI のキーに変更
base_url="https://api.apiyi.com/v1" # ← APIYI のアドレスに変更
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# その後、system パラメータに cache_control を追加するだけでキャッシュが有効になります
主な作業は chat.completions.create を messages.create に変更することです。メッセージ形式に僅かな違いはありますが(role/content の構造は同じですが、system が文字列からオブジェクトのリストに変わります)、通常は半日もあれば移行を完了できます。
Q: 自分の OpenClaw インスタンスでキャッシュが正常に有効になっているか、どうすれば確認できますか?
最も直接的な方法は、2回連続で呼び出した際に、API レスポンス内の usage オブジェクトを観察することです:
- 1回目の呼び出し:
cache_creation_input_tokensに値がある(キャッシュの書き込み) - 2回目の呼び出し:
cache_read_input_tokensに値がある(キャッシュのヒット)
2回目の呼び出しの cache_read_input_tokens がシステムプロンプトのトークン数と一致していれば、キャッシュが完全に機能している証拠です。
Q: 推論/思考モード(Extended Thinking)は必ずオフにする必要がありますか?
完全にオフにする必要はありませんが、必要に応じて使用するべきです。推奨される戦略は以下の通りです:
- 単純なタスク(メールの分類、スケジュールの調整):推論モードをオフにする
- 中程度のタスク(コードレビュー、情報の要約):デフォルトはオフ、困難な場合にオンにする
- 複雑なタスク(アーキテクチャの決定、多段階の調査):オンにするが、適切な
budget_tokens上限を設定する
Claude API では、thinking: {"type": "enabled", "budget_tokens": 5000} のように指定することで、推論モードの最大トークン消費量を制限できます。
まとめ:OpenClaw 節約のコアロジック
すべての節約手法を1枚の図にまとめました:
本記事の重要ポイントを振り返ります:
コストが高騰する3つの主な原因:
- 会話履歴の毎回再送(消費の 40-50% を占める)
- システムプロンプトの毎回再送(25-30% を占める)
- 推論モードの無制限な使用(20-25% を占める)
最も効果的な節約手法:
- 🥇 Claude キャッシュ課金:最大 90% 削減(Anthropic ネイティブ形式の使用が必須)
- 🥈 QMD ローカルセマンティック検索:履歴コンテキストのトークンを 60-97% 削減
- 🥉 タスクに応じたモデルの階層化:軽いタスクは Haiku、重いタスクは Sonnet/Opus を使用
- API チャンネルは APIYI を選択:20%OFF の基本料金 + ネイティブ形式のサポート
最も重要な認識:
OpenAI 互換形式(/v1/chat/completions)では
cache_controlを渡すことができません。
たとえ API 中継サービス経由で Claude を呼び出したとしても、キャッシュ割引を享受することは不可能です。
節約するためには、必ず Anthropic ネイティブ形式(/v1/messages)を使用する必要があります。
🎯 今すぐ行動: APIYI(apiyi.com)にアクセスして登録し、Anthropic ネイティブ形式をサポートする API キーを取得しましょう。
base_url をhttps://api.apiyi.com/v1に変更するだけで、3 分以内に切り替えが完了し、
その日のうちにトークン料金が大幅に下がるのを実感できるはずです。Claude モデルが 20%OFF、多モデル統一インターフェースを備えた APIYI は、
OpenClaw ユーザーにとってコスト削減と効率向上のための最適な選択肢です。
本記事のすべての API 価格データは 2026 年 3 月時点の公開資料に基づいています。実際の価格は各プラットフォームの公式発表をご確認ください。
著者:APIYI Team | OpenClaw のさらなる活用テクニックについては、APIYI(apiyi.com)ヘルプセンターをご覧ください。