Kürzlich haben OpenAI und Fractional AI gemeinsam ein äußerst fundiertes Praxisbeispiel veröffentlicht: die automatisierte Prüfung von Spesenbelegen mittels KI. Was auf den ersten Blick wie eine einfache OCR-Aufgabe klingt, entpuppt sich beim Blick in das Notebook als eine Art „Bibel“ für die Überführung von KI-Anwendungen vom Demo-Status in die Produktion. Es ist zudem das vollständigste Open-Source-Beispiel für das derzeit heiß diskutierte Thema Eval-Driven System Design (Bewertungsgesteuertes Systemdesign).
Das Spannende an dieser Methodik ist, dass sie kein rein technisches Problem löst, sondern eine grundlegende Frage, die jeden KI-Entwickler umtreibt: Wie stelle ich sicher, dass meine Änderungen an der Eingabeaufforderung tatsächlich eine Verbesserung bewirken und nicht nur so aussehen? In diesem Artikel zerlegen wir das OpenAI-Beispiel zur Belegprüfung und destillieren fünf technische Erkenntnisse, die für jeden Entwickler von KI-Anwendungen wertvoll sind.
🎯 Kurzübersicht: Das Beispiel stammt aus dem Verzeichnis
eval_driven_system_designim offiziellen OpenAI-Cookbook. Die Autoren sind das Team von Fractional AI (Hugh Wimberly / Joshua Marker / Eddie Siegel) zusammen mit Shikhar Kwatra von OpenAI. Der vollständige Code befindet sich im offiziellen OpenAI-Cookbook-Repository. Über API-Proxy-Dienste wie APIYI (apiyi.com) lässt sich der gesamte Prozess ohne Änderungen am Code reproduzieren – ideal für Entwickler im deutschsprachigen Raum zum direkten Ausprobieren.
Der geschäftliche Hintergrund des OpenAI-Belegprüfungsbeispiels: Warum dies ein echtes Problem ist
Bevor wir uns der Technik widmen, betrachten wir den geschäftlichen Kontext. Dies ist kein Spielzeugprojekt zur Demonstration einer API, sondern ein reales Unternehmensszenario mit klaren ROI-Zahlen.
| Geschäftsdimension | Wert | Bedeutung |
|---|---|---|
| Jährliches Volumen | ca. 1 Mio. Belege | Typisch für mittelständische Unternehmen |
| KI-Kosten pro Beleg | $0,20 | Kosten für den Modellaufruf |
| Kosten manuelle Prüfung | $2,00 | Prüfung durch Finanzpersonal |
| Strafe bei Fehlprüfung | $30 / Beleg | Compliance-/Steuerstrafen |
| Aktuelle manuelle Quote | 5 % | Nur bei schwierigen Fällen |
Wenn man diese Zahlen hochrechnet, erkennt man: Selbst eine Steigerung der Prüfgenauigkeit um nur 1 % bei einem Volumen von einer Million Belegen bedeutet eine jährliche Ersparnis von mehreren hunderttausend Dollar. Das ist genau das, was das Team von Fractional AI mit „Dollar Impact“ meint – es geht nicht darum, Kennzahlen zu schönen, sondern jede Änderung an der Eingabeaufforderung direkt mit dem Geschäftsergebnis zu verknüpfen.
Das Ziel des KI-Systems ist klar definiert: Mit GPT-4o den Großteil der Belege automatisch prüfen und nur Belege mit „geringem Vertrauensgrad“ an menschliche Prüfer weiterleiten, um sowohl die Kosten als auch das Risiko von Fehlprüfungen zu minimieren. Das klingt einfach, aber der Teufel steckt im Detail.
Was ist Eval-Driven Design: Eine Methodik, die man erst durch schmerzhafte Erfahrung versteht
Wenn Sie 100 KI-Ingenieure fragen: „Wie überprüft ihr, ob eine Änderung an der Eingabeaufforderung korrekt ist?“, werden Ihnen 99 antworten: „Ich lasse ein paar Beispiele laufen und schaue, ob sich das Ergebnis richtig anfühlt.“ Genau das ist das von der Fractional-AI-Community kritisierte Vibe-Coding (Entwicklung nach Gefühl) – und genau das ist der Entwicklungsansatz, den das Eval-Driven Design (im Folgenden EDD genannt) grundlegend ersetzen will.
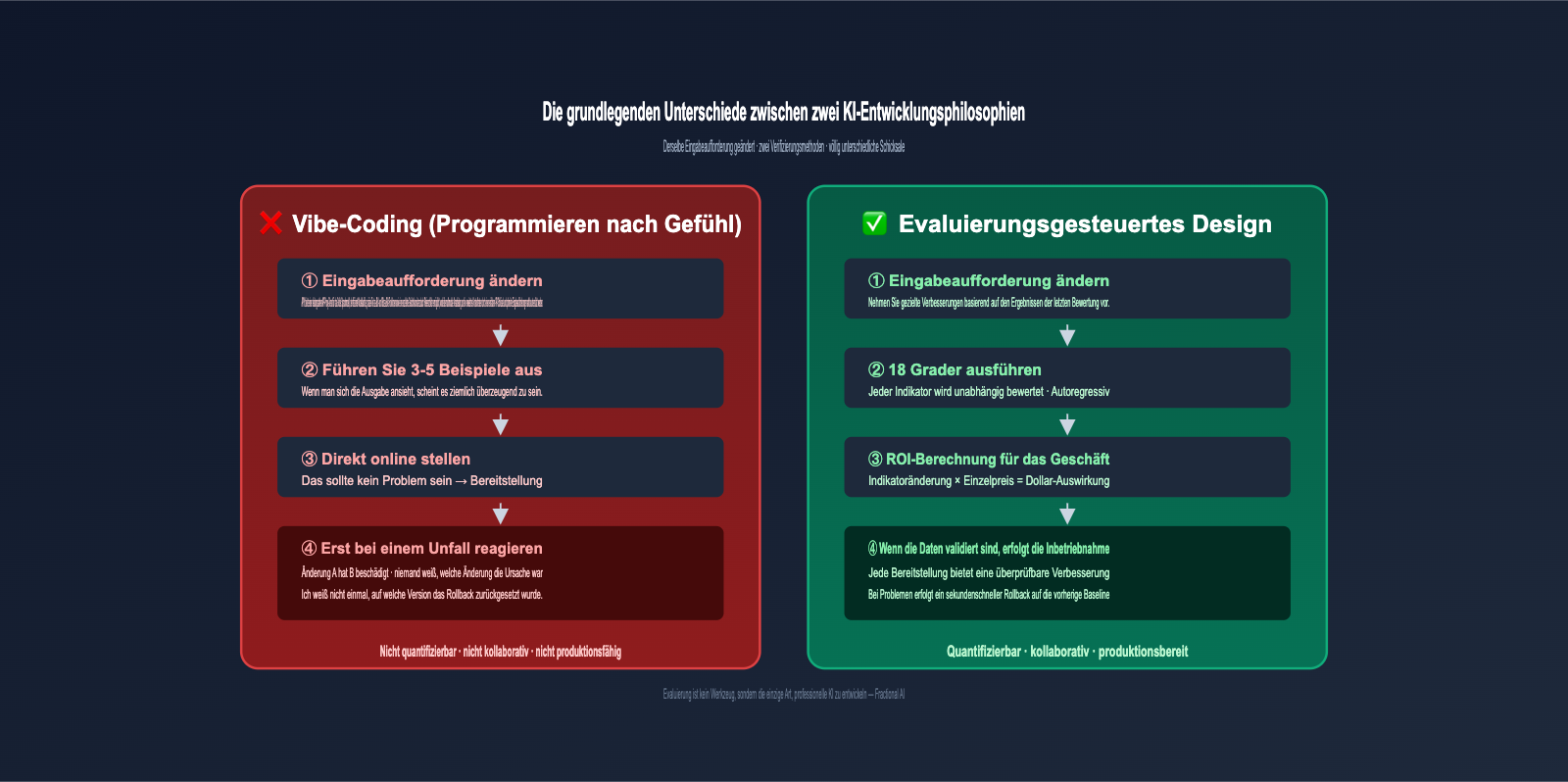
Die Unterschiede zwischen den beiden Entwicklungsansätzen lassen sich in der folgenden Tabelle verdeutlichen:
| Vergleichsdimension | Vibe-Coding (nach Gefühl) | Eval-Driven Design (evaluationsgesteuert) |
|---|---|---|
| Validierungsmethode | 3-5 Beispiele prüfen | 20-100+ annotierte Beispiele messen |
| Entscheidungsgrundlage | „Fühlt sich besser an“ | „Genauigkeit von 78 % auf 85 % gestiegen“ |
| Geschäftlicher Bezug | Subjektive Einschätzung | Direkte Auswirkung auf den Umsatz |
| Regressionsrisiko | Änderungen an A können B unbemerkt zerstören | Vollständige Metriken laufen automatisch durch |
| Kollaborative Skalierbarkeit | Nur für den Autor verständlich | Jeder Ingenieur kann debuggen |
Fractional AI hat in einem Artikel einen Satz geprägt, der häufig zitiert wird: „Evaluierung ist kein Werkzeug, sondern die einzige Art, professionelle KI zu entwickeln.“ Das klingt vielleicht übertrieben, aber in geschäftskritischen Szenarien wie der Rechnungsprüfung ist das Fehlen von Evals gleichbedeutend mit einem Glücksspiel in der Produktionsumgebung – niemand traut sich, so etwas guten Gewissens zu veröffentlichen.
💡 Analogie zum Verständnis: Eval-Driven Design ist wie eine Prüfung mit einem offiziellen Lösungsschlüssel: Sie können genau berechnen, um wie viel die „Gesamtpunktzahl“ durch jede Änderung gestiegen ist. Vibe-Coding hingegen ist wie das Beantworten von Fragen nach dem Bauchgefühl – nach der Änderung weiß man nicht, ob es besser oder schlechter geworden ist. KI auf Produktionsniveau muss zwingend dem ersten Ansatz folgen.
Der dreistufige Implementierungsprozess für die Prüfung von OpenAI-Belegen
Das OpenAI Cookbook unterteilt diesen Anwendungsfall in drei klare Phasen. Dieser Prozess lässt sich auf fast jede KI-Anwendung übertragen, die nach dem Schema „Eingabe von Bildern/Dokumenten + strukturierte Entscheidungsfindung“ arbeitet.
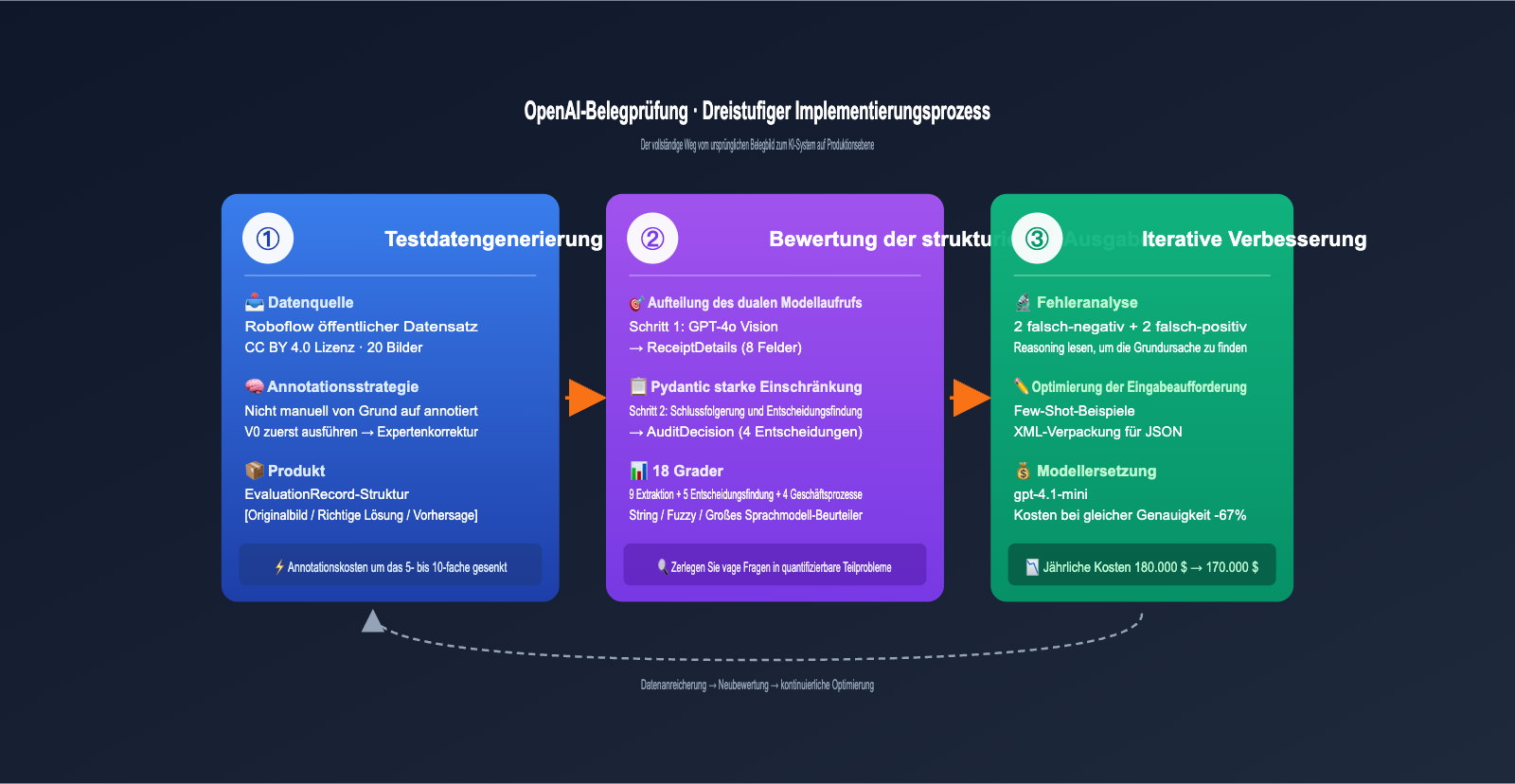
Im Folgenden erkläre ich die einzelnen Phasen auf verständliche Weise.
Phase 1: Generierung von Testdaten – 80 % der Annotationskosten clever einsparen
Wer glaubt, dass Teams bei Null anfangen und tausende Belegbilder manuell annotieren, unterschätzt die Effizienz von Ingenieuren. Fractional AI nutzte eine clevere Strategie: Erst das V0-Modell laufen lassen, dann durch Experten korrigieren.
Der Ablauf: Man nehme 20 echte Belegbilder aus einem öffentlichen Datensatz (Roboflow, CC BY 4.0), speise sie in einen einfachen GPT-4o + Pydantic-Extraktionsprozess ein und erhalte die V0-Ausgabe. Anschließend korrigiert ein Finanzexperte diese Ergebnisse, anstatt Daten von Grund auf neu einzugeben.
Diese „Erst generieren, dann korrigieren“-Methode steigert die Effizienz der Experten um das 5- bis 10-Fache, da die meisten Felder bereits korrekt erkannt wurden. Die resultierende Datenstruktur EvaluationRecord ist zudem elegant: Sie speichert Pfad zum Originalbild, korrekte Details, Modellvorhersagen, korrekte Prüfentscheidungen und die Modellentscheidung – ein Datensatz deckt die gesamte Pipeline ab.
🔧 Empfehlung: Diese Annotationsstrategie lässt sich auf fast jede Kaltstartphase einer KI-Anwendung übertragen. Nutzen Sie APIYI, um schnell V0-Ergebnisse zu erhalten und die Energie der Experten auf die kritischen Entscheidungen zu fokussieren.
Phase 2: Bewertung strukturierter Ausgaben – Pydantic ist der wahre Held
Das KI-System besteht aus zwei aufeinanderfolgenden LLM-Aufrufen. Diese Aufgabentrennung ist ein Kernaspekt von EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""Schritt 1: Strukturierte Beleginformationen aus dem Bild extrahieren"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # Starke Pydantic-Modell-Einschränkung
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""Schritt 2: Prüfentscheidung basierend auf strukturierten Daten treffen"""
# ... Aufruf des LLM zur Ausgabe des AuditDecision Pydantic-Modells
Warum zwei Schritte? Weil die Anforderungen grundverschieden sind: Schritt 1 ist „Bildlesen“ (Vision + Extraktion), Schritt 2 ist „logische Schlussfolgerung“ (Entscheidungsfindung). Mischt man beides in einem Prompt, verwirrt man das Modell und erschwert das Debugging.
Das Design der Pydantic-Modelle ReceiptDetails und AuditDecision ist besonders lehrreich:
| Modell | Schlüsselfelder | Geschäftliche Bedeutung |
|---|---|---|
| ReceiptDetails | merchant / location / time / items / subtotal / tax / total / handwritten_notes | Alle sichtbaren Informationen auf dem Beleg |
| AuditDecision | not_travel_related / amount_over_limit / math_error / handwritten_x / reasoning / needs_audit | 4 Prüfkriterien + Herleitung + Endergebnis |
Besonders das Feld reasoning in AuditDecision ist wichtig – es zwingt das Modell, den Gedankengang vor der Entscheidung zu formulieren, was für die „Chain-of-Thought“-Bewertung entscheidend ist. Auch needs_audit als logisches ODER der vier booleschen Felder erlaubt eine sehr feingliedrige Auswertung.
🚀 Hinweis:
client.responses.parse()ist die neueste Schnittstelle von OpenAI für strukturierte Ausgaben. Sie eliminiert das Risiko von JSON-Parsing-Fehlern fast vollständig. Wir empfehlen die Nutzung über APIYI, da diese API-Proxy-Dienste sicherstellen, dass die SDK-Protokolle stets aktuell sind.
Phase 3: Iterative Verbesserung – 18 Grader für quantifizierbare Änderungen
Hier glänzt EDD wirklich. Das Team von Fractional AI hat 18 unabhängige Bewertungsmetriken (Grader) definiert, um die vage Frage „Ist das System gut?“ in 18 kleine, messbare Probleme zu unterteilen.
Die 18 Grader lassen sich in drei Kategorien einteilen:
| Grader-Typ | Beispiel-Metriken | Bewertungsmethode |
|---|---|---|
| Extraktionsgenauigkeit (9) | Händlername / Adresse / Gesamtbetrag | Exakter String-Abgleich / Fuzzy-Matching |
| Prüfentscheidungsgenauigkeit (5) | Reisebezug / Limitüberschreitung / Rechenfehler / Handschrift-Erkennung / Endentscheidung | Binäre Klassifikationsgenauigkeit |
| Geschäftliche Ausrichtung (4) | Fehlende/zusätzliche Artikel / Artikelgenauigkeit / Qualität der Herleitung | LLM-as-Judge (0-10 Punkte) |
Die erste Evaluierung an 20 Stichproben ergab 2 falsch-negative und 2 falsch-positive Ergebnisse. Bei einer Million Belegen pro Jahr wären das tausende übersehene Fälle. Das Team ging methodisch vor:
- Ursachenanalyse: Prüfung des
reasoning-Feldes bei Fehlern. - Gezielte Prompt-Anpassung: Few-Shot-Beispiele hinzufügen, Definitionen schärfen, JSON-Beispiele in XML kapseln.
- Erneute Evaluierung: Sicherstellen, dass die Korrekturen keine neuen Fehler einführen.
- Modell-Experimente: Vergleich von
o4-miniundgpt-4.1-minihinsichtlich ROI.
Das Ergebnis war beeindruckend: Der Wechsel von o4-mini zu gpt-4.1-mini senkte die Kosten um 67 % (von ca. 180.000 $ auf 170.000 $ pro Jahr), ohne dass die Genauigkeit nennenswert sank. Ohne ein vollständiges Evaluierungsset hätte niemand diese Entscheidung treffen können.
📊 Erkenntnis: Die 18 Grader dienen nicht der Statistik, sondern der Zerlegung eines komplexen Problems in 18 einzeln korrigierbare und messbare Teilaspekte. Über APIYI können Sie ebenfalls auf die OpenAI Evals API zugreifen, die mit den offiziellen Schnittstellen kompatibel ist.
5 technische Erkenntnisse aus dem Fallbeispiel zur Belegprüfung von OpenAI
Nach der Lektüre des gesamten Fallbeispiels habe ich 5 Erkenntnisse destilliert, die für jede KI-Anwendung universell gültig sind – Erfahrungen, die buchstäblich mit echtem Geld bezahlt wurden.
Erkenntnis 1: Koppeln Sie die Evaluierung an den Dollar, streben Sie nicht bei allen Metriken 100 % an
Im Fallbeispiel gab es eine sehr kontraintuitive Entdeckung: Die Genauigkeit bei der Erkennung von Händlernamen hatte fast keinen Einfluss auf die endgültige Prüfentscheidung, da die Prüfregeln nicht vom Händlernamen abhängen. Wenn ein Team also verbissen versucht, die Erkennungsrate für Händlernamen von 92 % auf 98 % zu heben, verschwendet es wertvolle Entwicklungsressourcen.
Im Gegensatz dazu verursachten Fehler bei der Erkennung des handschriftlichen "X" jährliche Verluste von etwa 75.000 USD durch entgangene Prüfungen. Dies war die Metrik mit der höchsten Priorität. Die Wahl der Metriken sollte daher immer eine Frage beantworten: "Wie viel Geld spare ich, wenn ich diesen Fehler korrigiere?"
Erkenntnis 2: Nutzen Sie zuerst das leistungsfähigste Modell, denken Sie erst danach an Kosteneinsparungen
In der V0-Phase des Projekts wurde direkt o4-mini, das damals leistungsfähigste Modell, gewählt. Nicht, weil dem Team die Kosten egal waren, sondern weil sie wussten: Es ist weitaus schwieriger, ein unterdimensioniertes Modell mühsam zur Arbeit zu bewegen, als ein überdimensioniertes Modell kosteneffizient zu betreiben. Zuerst die Geschäftslogik zum Laufen bringen und ein vollständiges Evaluierungssystem aufbauen, dann erst Modell-Austausch-Experimente durchführen – diese Reihenfolge darf nicht vertauscht werden.
Erkenntnis 3: Trennen Sie Extraktion und Entscheidungsfindung, schreiben Sie keine "eierlegende Wollmilchsau"-Eingabeaufforderung
Viele Anfänger denken: "Wie kosteneffizient wäre es, wenn ein einziger Aufruf aus dem Bild direkt die Schlussfolgerung 'Prüfung erforderlich' liefert!" Doch dieses Design hat zwei fatale Schwächen: Nicht debuggbar – bei Fehlern weiß man nicht, ob das Bild falsch gelesen oder die Logik falsch angewendet wurde; Nicht wiederverwendbar – das Extraktionsergebnis kann nur für diese eine Entscheidung genutzt werden. Die Aufteilung in zwei Schritte mag nach einem zusätzlichen API-Aufruf aussehen, erhöht aber die Wartbarkeit des gesamten Systems um eine Größenordnung.
Erkenntnis 4: Chain-of-Thought-Evaluierung deckt das Risiko von "richtigem Ergebnis aus falschem Grund" auf
Das scheinbar redundante reasoning-Feld in der AuditDecision wurde bei der Evaluierung genutzt, um eine gefährliche Situation zu identifizieren: Das Modell liefert das richtige Endergebnis, aber der Schlussfolgerungsprozess ist falsch. Solche "Glückstreffer" fallen bei kleinen Stichproben nicht auf, führen aber bei der geringsten Änderung der Datenverteilung zu massiven Ausfällen. Die erzwungene Ausgabe von Schlussfolgerungen und die Nutzung von "LLM-as-Judge" zur Bewertung der Qualität dieser Schlussfolgerungen sind eine unverzichtbare Versicherung für KI-Anwendungen in der Produktion.
Erkenntnis 5: Annotationskosten können durch Engineering gesenkt werden
Lassen Sie sich nicht von dem Klischee abschrecken, dass KI-Projekte riesige Mengen an annotierten Daten benötigen. Die Strategie, 20 Beispiele plus Expertenkorrekturen der V0-Ausgabe zu nutzen, reichte aus, um einen nützlichen Evaluierungssatz zu erstellen. Der Schlüssel liegt darin, dass die Verteilung des Evaluierungssatzes mit den realen Geschäftsdaten übereinstimmt, anstatt nur die Anzahl der Stichproben zu maximieren. Die Erfahrung von Fractional zeigt, dass die Nutzung der anfänglichen V0-Ausgaben als "Seed-Annotationen" die Effizienz im Vergleich zur manuellen Annotation von Grund auf um das 5- bis 10-fache steigert.
Hinweise zur Reproduktion des OpenAI-Belegprüfungs-Falls in China
Entwickler in China, die dieses Kochbuch reproduzieren möchten, müssen drei Probleme lösen: Können die neuen Modelle wie o4-mini / gpt-4.1-mini aufgerufen werden?, Kann die neueste Schnittstelle responses.parse genutzt werden? und Ist der Evals-API-Endpunkt erreichbar?
Die direkte Verbindung zu OpenAI ist in China sehr instabil, insbesondere bei Bild-Schnittstellen, da die Fehlerrate aufgrund der großen Payloads höher ist als bei Text-Schnittstellen. Die Nutzung eines offiziellen API-Proxy-Dienstes (APIYI) löst diese drei Probleme meist mit einem Klick. Der entscheidende Code erfordert nur eine Änderung der base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # Die einzige Zeile, die geändert werden muss
api_key="Ihr APIYI-Schlüssel"
)
# Der gesamte nachfolgende Code ist identisch mit dem Kochbuch
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
Dies ist der entscheidende Unterschied zwischen einem "offiziellen OpenAI-API-Proxy" und einer "OpenAI-kompatiblen API" – Ersterer garantiert die Synchronität der Schnittstellen mit dem offiziellen OpenAI-Standard, während Letztere oft nur grundlegende Schnittstellen unterstützt und fortgeschrittene Funktionen wie responses.parse oder die Evals-API möglicherweise nicht bietet. Wenn Sie offizielle Anleitungen wie dieses Kochbuch reproduzieren, verhindert die Wahl eines offiziellen Proxy-Dienstes eine Vielzahl von Kompatibilitätsproblemen.
FAQ zum Fallbeispiel: Rechnungsprüfung mit OpenAI
F1: Kann diese Methode nur für Quittungen verwendet werden?
Keineswegs. Das „Eval-Driven Design“ eignet sich für jedes Szenario, bei dem die „Eingabe relativ offen ist, aber eine strukturierte Entscheidung als Ausgabe erforderlich ist“: Vertragsprüfung, Triage bei medizinischen Bildern, Qualitätskontrolle im Kundenservice, Screening von Bewerbungsunterlagen oder Betrugserkennung – all diese Bereiche lassen sich mit diesem dreistufigen Prozess abdecken. Das Grundprinzip bleibt gleich: Die Gestaltung des Pydantic-Schemas und der Evaluierungs-Grader.
F2: Sind 18 Grader nicht zu viel für ein kleines Team?
Sie können mit 5–6 Kern-Gradern beginnen, beispielsweise mit der Genauigkeit der endgültigen Entscheidung und der Extraktionsgenauigkeit für Schlüsselfelder. Wichtig ist nicht die Anzahl, sondern dass jeder Grader einem spezifischen Fehlermuster entspricht. Wir empfehlen, zunächst eine kleine Stichprobe mit GPT-4o über das APIYI-Dashboard zu testen und die Evaluierungsdimensionen erst zu erweitern, wenn der Prozess reibungslos läuft.
F3: Wird V0 nicht sehr teuer, wenn man direkt o4-mini verwendet?
In der V0-Phase liegt das Volumen normalerweise bei einigen Dutzend bis Hunderten von Aufrufen, was Gesamtkosten von wenigen bis einigen Dutzend Dollar verursacht – das ist absolut vertretbar. Einsparungen sind erst bei Millionen von Aufrufen in der Produktionsumgebung relevant. Zu diesem Zeitpunkt verfügen Sie bereits über einen vollständigen Evaluierungssatz für Modell-Austausch-Experimente, so wie im Beispiel der Wechsel von o4-mini zu gpt-4.1-mini, der die Kosten um 67 % senkte.
F4: Wie gut liest GPT-4o Vision handgeschriebene chinesische Quittungen?
Bei gedruckten englischen Quittungen ist die Genauigkeit sehr hoch (über 95 %), bei gedruckten chinesischen ebenfalls gut (über 90 %). Bei handschriftlichen chinesischen Texten hängt es von der Lesbarkeit ab. Wir empfehlen, zunächst einen Evaluierungssatz mit 100 echten Beispielen zu erstellen, anstatt sich nur auf Demo-Videos zu verlassen. Die Kosten für den Aufruf von GPT-4o Vision über die offizielle API sind identisch mit den offiziellen Preisen, was sie ideal für groß angelegte Evaluierungsexperimente macht.
F5: Kann ich dieses Cookbook auch ohne Evals-API-Zugriff ausführen?
Ja. Die Evals-API dient hauptsächlich dazu, die Konfiguration und Verwaltung der Grader an OpenAI auszulagern; die eigentliche Evaluierungslogik lässt sich jedoch genauso gut mit Python lokal ausführen. Die Grader-Funktionen im Cookbook sind vollständig quelloffen und können einfach lokal kopiert und verwendet werden. Sollte Ihr Geschäftsvolumen später wachsen, können Sie immer noch auf die verwalteten Evals migrieren.
F6: Was ist der Unterschied zwischen der Nutzung dieses Falls über APIYI und der offiziellen API?
Schnittstellenprotokolle, Modellversionen und Parameterunterstützung sind vollständig mit der offiziellen OpenAI-API synchronisiert – das ist das Kernversprechen unseres „offiziellen Proxy-Dienstes“. Der Unterschied liegt hauptsächlich auf der Netzwerkebene: Direkte Verbindungen zu OpenAI aus China führen häufig zu SSL-Handshake-Fehlern oder Timeouts. Unsere Gateways sind in lokalen Rechenzentren implementiert, was die Stabilität, insbesondere bei bildbasierten Schnittstellen, deutlich verbessert. Dies ist entscheidend für die Durchführung langwieriger Evaluierungsaufgaben.
Fazit
Das Fallbeispiel zur Rechnungsprüfung mit OpenAI ist deshalb so lesenswert, weil es die abstrakte Aufgabe „Wie löse ich ein reales Geschäftsproblem mit KI“ in drei Phasen, 18 Evaluierungsmetriken und konkrete technische Praktiken zerlegt, die sich in Dollar-Auswirkungen quantifizieren lassen. Dies ist derzeit das am meisten benötigte Beispiel für KI-Engineering in der chinesischsprachigen Community.
Wenn Sie eine KI-Anwendung entwickeln, die Dokumente/Bilder einliest und strukturierte Entscheidungen ausgibt, empfehlen wir Ihnen dringend, dieses Cookbook vollständig durchzuarbeiten. Nur Lesen reicht nicht – der wahre Wert des „Eval-Driven Design“ zeigt sich erst in dem Moment, in dem Sie die Veränderungen der Metriken sehen. Wir empfehlen, dies direkt über eine Plattform für offizielle OpenAI-API-Proxys wie apiyi.com zu replizieren. So sparen Sie sich die mühsame Einrichtung der Umgebung und können sich voll auf die Methodik konzentrieren.
Wenn Sie das Prinzip der „evaluierungsgetriebenen Entwicklung“ fest in Ihren Prozess integrieren, entwickelt sich Ihr KI-System von einem „Spielzeug, das ganz nett aussieht“ zu einem technischen Produkt, das Sie bedenkenlos in die Produktion bringen und dessen ROI Sie präzise berechnen können. Der Unterschied dazwischen kann bei 75.000 $ liegen.
📌 Autor: APIYI Team — Wir verfolgen langfristig die technischen Praxisbeispiele der multimodalen APIs von OpenAI, Anthropic und Google. Weitere Cookbook-Analysen und Anleitungen zur API-Anbindung finden Sie im Dokumentationszentrum unter apiyi.com.