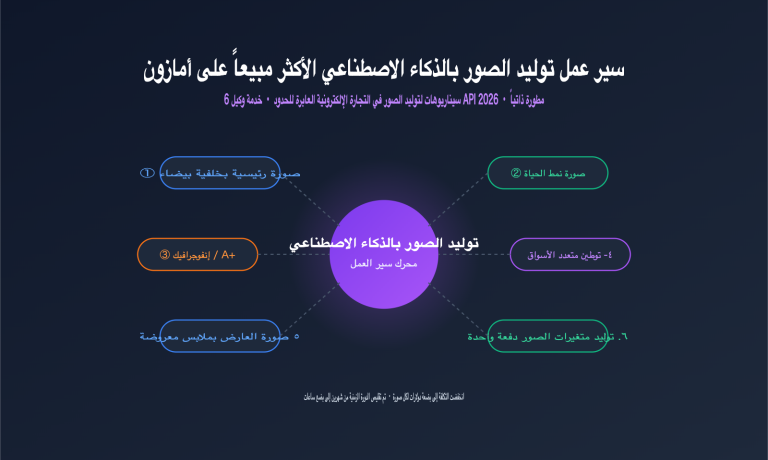
نشرت OpenAI مؤخراً بالتعاون مع Fractional AI حالة دراسية عملية وعميقة للغاية: استخدام الذكاء الاصطناعي لأتمتة مراجعة فواتير المصروفات. قد يبدو الأمر للوهلة الأولى مجرد مهمة بسيطة للتعرف الضوئي على الحروف (OCR)، ولكن عند الاطلاع على دفتر الملاحظات (Notebook) الخاص بالمشروع، ستكتشف أنه يمثل "دليلاً منهجياً" حول كيفية نقل تطبيقات الذكاء الاصطناعي من مجرد نموذج أولي (Demo) إلى بيئة الإنتاج، وهو أيضاً المثال المفتوح المصدر الأكثر اكتمالاً لما يُعرف حالياً في الصناعة بـ تصميم النظام القائم على التقييم (Eval-Driven System Design).
والأكثر إثارة للاهتمام هو أن هذه المنهجية لا تحل مشكلة تقنية فحسب، بل تعالج معضلة جوهرية تؤرق كل مهندس ذكاء اصطناعي: كيف أتأكد أن التعديلات التي أجريتها على الموجه (Prompt) قد حسنت الأداء فعلياً، أم أنها مجرد تحسين ظاهري؟ في هذا المقال، سنقوم بتفكيك حالة مراجعة الإيصالات من OpenAI بأبسط الطرق، لاستخلاص 5 تجارب هندسية ستفيد كل مطور تطبيقات ذكاء اصطناعي.
🎯 جولة سريعة: الحالة الدراسية مأخوذة من دليل cookbook.openai.com تحت مسار eval_driven_system_design، من إعداد فريق Fractional AI (هيو ويمبرلي / جوشوا ماركر / إيدي سيجل) بالتعاون مع شيكار كواترا من OpenAI. الكود الكامل متاح في مستودع OpenAI Cookbook الرسمي، ويمكنك إعادة تنفيذ العملية بالكامل دون أي تغيير باستخدام خدمات وكيل API مثل APIYI (apiyi.com)، مما يجعله مثالياً للمطورين العرب للتعلم والتطبيق المباشر.
سياق الأعمال لحالة مراجعة الإيصالات في OpenAI: لماذا تعد هذه مشكلة حقيقية؟
قبل الخوض في الجوانب التقنية، دعونا نوضح سياق الأعمال لهذه الحالة. هذه ليست مجرد مشكلة مصطنعة لاستعراض واجهة برمجة التطبيقات (API)، بل هي سيناريو تجاري حقيقي وملموس ذو أرقام واضحة فيما يخص العائد على الاستثمار (ROI).
| بُعد العمل | الرقم التقديري | المعنى |
|---|---|---|
| حجم المعالجة السنوي | حوالي مليون إيصال | حجم نموذجي للشركات المتوسطة |
| تكلفة المعالجة بالذكاء الاصطناعي | 0.20 دولار | رسوم استدعاء النموذج |
| تكلفة المراجعة البشرية | 2.00 دولار | تكلفة المراجعة من قبل الموظفين |
| غرامة عدم المراجعة | 30 دولاراً / إيصال | عقوبات الامتثال أو الضرائب |
| معدل المراجعة البشرية الحالي | 5% | للإيصالات المعقدة فقط |
عند ضرب هذه الأرقام، ستكتشف أن تحسين دقة المراجعة بنسبة 1% فقط، عند حجم مليون إيصال، يعني مكاسب سنوية بمئات الآلاف من الدولارات. وهذا ما يؤكد عليه فريق Fractional AI مراراً وتكراراً: "ربط مقاييس التقييم بالأثر المالي (Dollar Impact)"؛ فالهدف ليس مجرد تحسين الأرقام، بل ضمان أن كل تعديل في "الموجه" (Prompt) ينعكس بشكل مباشر على سجلات الأعمال.
الهدف من نظام الذكاء الاصطناعي بأكمله واضح جداً: استخدام GPT-4o لمراجعة معظم الإيصالات تلقائياً، وإحالة الإيصالات ذات "الثقة المنخفضة" فقط إلى المراجعة البشرية، مما يقلل من تكاليف المراجعة ومخاطر الأخطاء. يبدو الأمر بسيطاً، لكن الشيطان يكمن في التفاصيل.
ما هو التصميم القائم على التقييم (Eval-Driven Design)؟ منهجية لا تدرك قيمتها إلا بعد تجربة الفشل
إذا سألت 100 مهندس ذكاء اصطناعي "كيف تتحققون من صحة تعديلات الموجه؟"، سيقول لك 99 منهم "نقوم بتجربة بضعة أمثلة ونرى ما إذا كانت المخرجات تبدو صحيحة". هذا ما ينتقده فريق Fractional AI ويطلق عليه vibe-coding (الضبط بناءً على الشعور)، وهو أسلوب التطوير الذي يسعى "التصميم القائم على التقييم" (المشار إليه بـ EDD) لاستبداله تماماً.

يمكن تلخيص الفرق بين نهجي التطوير في الجدول التالي:
| بُعد المقارنة | الضبط بناءً على الشعور (Vibe-Coding) | التصميم القائم على التقييم (Eval-Driven Design) |
|---|---|---|
| طريقة التحقق | تجربة 3-5 أمثلة ورؤية المخرجات | تشغيل 20-100+ عينة مصنفة لحساب المقاييس |
| الحكم على التعديلات | "أشعر أن الأمر أصبح أفضل" | "ارتفعت الدقة من 78% إلى 85%" |
| مواءمة الأعمال | يعتمد على الشعور بالأهمية | تحويل مباشر إلى أثر مالي بالدولار |
| مخاطر التراجع | تعديل A قد يفسد B دون علمنا | تشغيل مجموعة كاملة من المقاييس تلقائياً |
| قابلية التعاون | يفهمها المؤلف الأصلي فقط | يمكن لأي مهندس تصحيح الأخطاء (debug) |
هناك جملة لفريق Fractional AI يتم اقتباسها على نطاق واسع: "التقييم ليس مجرد أداة، بل هو الطريقة الوحيدة لتطوير ذكاء اصطناعي احترافي". قد تبدو هذه الجملة مبالغاً فيها، ولكن في سيناريوهات الأعمال الحساسة مثل مراجعة الإيصالات، فإن غياب التقييمات يعني أنك تلعب "يانصيب" في بيئة الإنتاج، ولا أحد يجرؤ على إطلاق (Ship) مثل هذا النظام وهو مطمئن.
💡 للتوضيح بالمقارنة: التصميم القائم على التقييم يشبه الامتحانات التي لها إجابات نموذجية، حيث يمكنك حساب مقدار التحسن في "الدرجة الكلية" بعد كل تعديل. أما الضبط بناءً على الشعور، فيشبه الإجابة على الأسئلة بناءً على الحدس، حيث لا تعرف بعد الانتهاء ما إذا كان أداؤك قد تحسن أم تراجع. الذكاء الاصطناعي في بيئة الإنتاج يجب أن يعتمد على النهج الأول.
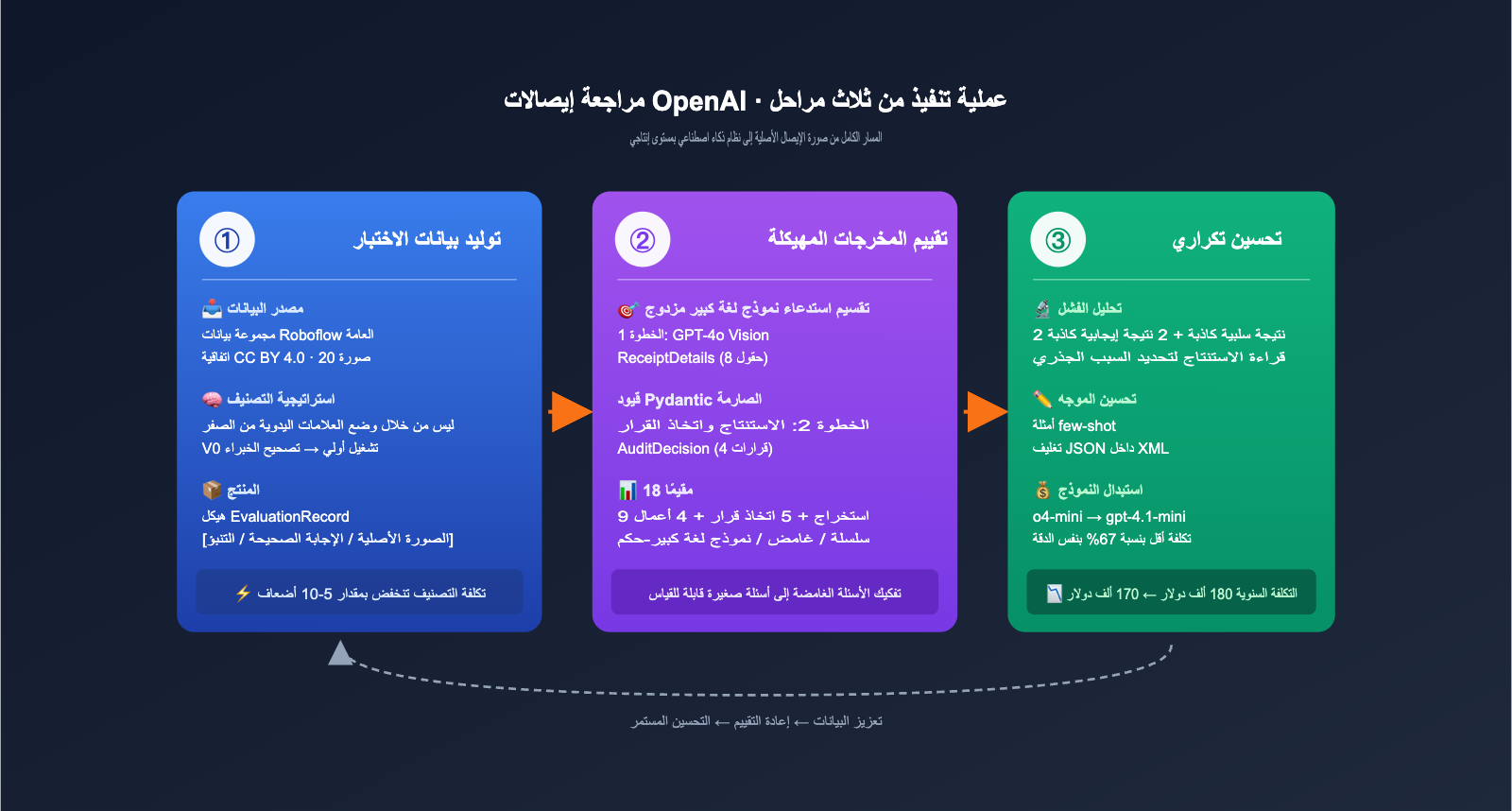
عملية التنفيذ المكونة من ثلاث مراحل لمراجعة الإيصالات باستخدام OpenAI
يقوم "كتاب طبخ OpenAI" (OpenAI Cookbook) بتقسيم هذه الحالة بأكملها إلى ثلاث مراحل واضحة للغاية، ويمكن تطبيق هذا المسار تقريبًا على أي تطبيق ذكاء اصطناعي يعتمد على "إدخال صور/مستندات + مخرجات قرارات هيكلية".
فيما يلي سأشرح كل مرحلة بأبسط طريقة ممكنة.
المرحلة الأولى: توليد بيانات الاختبار، وتوفير 80% من تكاليف التصنيف بذكاء
إذا كنت تظن أن الفريق بدأ من الصفر في تصنيف آلاف صور الإيصالات يدويًا، فأنت تقلل من قدرة المهندسين على "الاختصار الذكي". استخدمت شركة Fractional AI استراتيجية ذكية للغاية: دع نموذج V0 يعمل أولاً، ثم اطلب من الخبراء التصحيح.
تتمثل العملية في الآتي: أخذ 20 صورة إيصال حقيقية من مجموعة بيانات Roboflow العامة (بروتوكول CC BY 4.0)، وتغذيتها مباشرة في عملية استخراج تعتمد على نسخة بسيطة من GPT-4o + Pydantic، للحصول على مخرجات V0. بعد ذلك، يقوم خبير في المجال المالي بـ "البحث عن الأخطاء وتصحيحها" بناءً على هذه المخرجات، بدلاً من كتابة البيانات من الصفر حرفًا بحرف.
هذه الطريقة "التوليد أولاً ثم التصحيح" رفعت كفاءة وقت الخبراء بمقدار 5 إلى 10 أضعاف، لأن نموذج V0 كان قد تعرف بشكل صحيح على معظم الحقول، ولم يحتج الخبير إلا لتصحيح الأجزاء الخاطئة. هيكل بيانات EvaluationRecord الناتج كان أنيقًا أيضًا، حيث سجل في الوقت نفسه "مسار الصورة الأصلية، تفاصيل البيانات الصحيحة، تفاصيل توقعات النموذج، قرار المراجعة الصحيح، وقرار مراجعة النموذج"، بحيث تغطي سجل واحد كامل خط الإنتاج.
🔧 نصيحة لإعادة الاستخدام: يمكن تطبيق استراتيجية التصنيف هذه "تشغيل V0 أولاً ← تصحيح الخبير" على مرحلة الانطلاق البارد (Cold Start) لأي تطبيق ذكاء اصطناعي تقريبًا. ما عليك سوى تشغيل مخرجات V0 بسرعة عبر منصة وكيل API لـ OpenAI، لتتمكن من تركيز طاقة خبراء المجال على أكثر جوانب القرار قيمة.
المرحلة الثانية: تقييم المخرجات الهيكلية، Pydantic هو البطل الحقيقي
يتكون نظام الذكاء الاصطناعي بالكامل من استدعاءين لنموذج اللغة الكبير (LLM)، ويعد هذا التصميم القائم على فصل المسؤوليات أحد جوهر منهجية EDD.
async def extract_receipt_details(
image_path: str, model: str = "o4-mini"
) -> ReceiptDetails:
"""الخطوة الأولى: استخراج معلومات الإيصال الهيكلية من الصورة"""
response = await client.responses.parse(
model=model,
input=[{"role": "user", "content": [
{"type": "input_text", "text": prompt},
{"type": "input_image", "image_url": data_url}
]}],
text_format=ReceiptDetails # قيد صارم باستخدام نموذج Pydantic
)
return response.output_parsed
async def evaluate_receipt_for_audit(
receipt_details: ReceiptDetails, model: str = "o4-mini"
) -> AuditDecision:
"""الخطوة الثانية: اتخاذ قرار المراجعة بناءً على البيانات الهيكلية"""
# ... استدعاء LLM لإخراج نموذج AuditDecision Pydantic
لماذا نقسمها إلى خطوتين؟ لأن متطلبات القدرة لهاتين المهمتين مختلفة تمامًا: الخطوة الأولى هي "قراءة الصور وفهم النصوص" (الرؤية + استخراج المعلومات)، والخطوة الثانية هي "الاستنتاج المنطقي" (اتخاذ القرار). إن خلطهما في موجه (Prompt) واحد لا يجعل النموذج يخلط بين حدود المهام فحسب، بل يجعل عملية تصحيح الأخطاء (Debug) مستحيلة.
تصميم حقول نموذجي Pydantic (ReceiptDetails و AuditDecision) هو الجزء الأكثر قيمة للتعلم في هذه الحالة:
| النموذج | الحقول الرئيسية | المعنى التجاري |
|---|---|---|
| ReceiptDetails | التاجر / الموقع / الوقت / العناصر / الإجمالي الفرعي / الضريبة / الإجمالي / ملاحظات مكتوبة بخط اليد | كل المعلومات التي يمكن رؤيتها على الإيصال |
| AuditDecision | غير متعلق بالسفر / المبلغ يتجاوز الحد / خطأ حسابي / علامة X مكتوبة بخط اليد / الاستنتاج / الحاجة للمراجعة | 4 شروط للمراجعة + عملية الاستنتاج + النتيجة النهائية |
لاحظ بشكل خاص حقل reasoning في AuditDecision—فهو يجبر النموذج على كتابة عملية الاستنتاج قبل تقديم القرار النهائي، وهذا هو مفتاح تقييم "سلسلة الأفكار" (Chain-of-thought) لاحقًا. لاحظ أيضًا أن needs_audit هو نتيجة منطقية (OR) للحقول الأربعة السابقة، وهذا التصميم الذي يعتمد على "التقييم الجزئي ثم التجميع" يسمح بتفكيك مؤشرات التقييم بدقة عالية.
🚀 نصيحة للربط: واجهة
client.responses.parse()أعلاه هي أحدث واجهة لمخرجات OpenAI الهيكلية، والتي يمكنها فرض نموذج Pydantic مباشرة كصيغة للمخرجات، مما يقضي تمامًا على مخاطر فشل تحليل JSON. نوصي بالاتصال عبر منصات وكيل API مثل apiyi.com، لأن هذه الواجهة تتطلب إصدارات محددة من SDK، وتضمن بوابات الوكيل تحديث البروتوكولات بشكل متزامن.
المرحلة الثالثة: التحسين التكراري، 18 مقياس تقييم تجعل التغييرات قابلة للقياس
هذه المرحلة هي المكان الذي تتألق فيه منهجية EDD حقًا. فقد وضع فريق Fractional AI 18 مؤشر تقييم (Grader) مستقلاً لنظام مراجعة الإيصالات، مما حول السؤال الغامض "هل النظام جيد؟" إلى 18 سؤالًا صغيرًا قابلاً للقياس.
تنقسم هذه المقاييس الـ 18 تقريبًا إلى ثلاث فئات:
| نوع المقياس | المؤشرات التمثيلية | طريقة التقييم |
|---|---|---|
| دقة الاستخراج (9) | مطابقة اسم التاجر / العنوان / إجمالي المبلغ | مطابقة نصية دقيقة / مطابقة تقريبية |
| دقة قرار المراجعة (5) | تحديد السفر / تحديد تجاوز الحد / كشف الخطأ الحسابي / التعرف على خط اليد / القرار النهائي | دقة التصنيف الثنائي |
| مؤشرات مواءمة الأعمال (4) | العناصر المفقودة / العناصر الزائدة / دقة العناصر / جودة الاستنتاج | LLM-as-Judge (تقييم من 0-10) |
كشف التقييم الأولي على 20 عينة عن حالتين إيجابيتين كاذبتين + حالتين سلبيتين كاذبتين. قد يبدو هذا الرقم صغيرًا، لكن على نطاق مليون طلب سنويًا، يعني ذلك آلاف المراجعات الفائتة. تعامل فريق Fractional مع الأمر بطريقة هندسية بحتة:
- تحليل السبب الجذري: النظر في حقل
reasoningلكل حالة خطأ، لمعرفة أين تعثر النموذج في اتخاذ القرار. - تعديل الموجه (Prompt) بشكل مستهدف: إضافة أمثلة (Few-shot)، وتحديد تعريف "متعلق بالسفر" بوضوح، وتغليف أمثلة JSON باستخدام XML.
- إعادة تشغيل مجموعة التقييم: للتحقق من أن التعديلات أصلحت الخطأ فعليًا دون إدخال أخطاء جديدة.
- تجارب استبدال النماذج: تشغيل نفس الموجه على o4-mini و gpt-4.1-mini، واختيار النموذج ذو العائد الأفضل على الاستثمار (ROI).
كانت نتيجة الخطوة الأخيرة مذهلة: التحول من o4-mini إلى gpt-4.1-mini أدى لخفض التكاليف بنسبة 67%، وانخفضت التكلفة السنوية من حوالي 180 ألف دولار إلى 170 ألف دولار، بينما لم تنخفض الدقة تقريبًا. بدون مجموعة تقييم كاملة، من يجرؤ على اتخاذ قرار خفض التكاليف هذا؟
📊 رؤية جوهرية: المقاييس الـ 18 ليست لمجرد العدد، بل لتحويل مشكلة تبدو غير قابلة للقياس مثل "هل الذكاء الاصطناعي دقيق أم لا؟" إلى 18 مشكلة صغيرة قابلة للإصلاح والقياس بشكل مستقل. يمكنك أيضًا إنشاء نظام مقاييس مشابه عبر استدعاء OpenAI Evals API على apiyi.com، حيث تتوافق الواجهات تمامًا مع الواجهات الرسمية.
5 دروس هندسية من تجربة OpenAI في تدقيق الإيصالات
بعد قراءة الحالة الدراسية بالكامل، استخلصت 5 دروس عامة تنطبق على أي تطبيق ذكاء اصطناعي، وهي خبرات مستفادة من تجارب عملية حقيقية:
الدرس الأول: اربط التقييم بالدولار، ولا تسعَ لتحقيق دقة 100% في كل المؤشرات
هناك اكتشاف غير بديهي في هذه الحالة: تحسين دقة التعرف على أسماء المتاجر لا يكاد يؤثر على قرار التدقيق النهائي، لأن قواعد التدقيق لا تعتمد على اسم المتجر. إذا أصر الفريق على رفع دقة التعرف على اسم المتجر من 92% إلى 98%، فهذا يعتبر إهداراً للموارد الهندسية.
في المقابل، أخطاء التعرف على علامة "X" المكتوبة بخط اليد تؤدي إلى خسائر تقدر بـ 75,000 دولار سنوياً بسبب فشل التدقيق، وهذا هو المؤشر ذو الأولوية القصوى. لذا، يجب أن يجيب اختيار المؤشرات دائماً على سؤال واحد: "كم من المال سأوفر إذا صححت هذا الخطأ؟"
الدرس الثاني: ابدأ باستخدام أقوى نموذج، ثم فكر في توفير التكاليف
في مرحلة V0 من الحالة الدراسية، تم اختيار نموذج مثل o4-mini، وهو الأقوى في ذلك الوقت. لم يكن ذلك لأن الفريق لا يهتم بالتكلفة، بل لأنهم يدركون أن جعل نموذج ضعيف القدرات يعمل بصعوبة هو أصعب بكثير من جعل نموذج فائق القدرات يعمل بتكلفة منخفضة. ابدأ بتشغيل منطق العمل وبناء نظام تقييم متكامل، ثم قم بتجارب استبدال النماذج؛ لا تعكس هذا الترتيب.
الدرس الثالث: افصل بين الاستخراج واتخاذ القرار، ولا تحاول كتابة "موجه" واحد لكل شيء
يعتقد الكثير من المبتدئين أن إجراء استدعاء واحد للحصول على نتيجة "هل يحتاج للتدقيق" مباشرة من الصورة هو أمر موفر للتكاليف! لكن هذا التصميم له عيبان قاتلان: صعوبة التصحيح (إذا حدث خطأ، لا تعرف هل السبب هو قراءة الصورة أم منطق القرار)؛ وعدم القابلية لإعادة الاستخدام (نتائج الاستخراج لا يمكن استخدامها إلا لهذا القرار فقط). تقسيم العملية إلى خطوتين قد يبدو وكأنه استدعاء إضافي لـ API، لكنه في الواقع يرفع مستوى صيانة النظام بأكمله بمقدار درجة كاملة.
الدرس الرابع: تقييم "سلسلة الأفكار" (Chain-of-Thought) يكشف مخاطر "الإجابة الصحيحة لسبب خاطئ"
حقل reasoning الذي يبدو زائداً في AuditDecision، تم استخدامه أثناء التقييم لتحديد حالة خطيرة: النموذج قدم الإجابة النهائية الصحيحة، لكن عملية الاستدلال كانت خاطئة. هذا النوع من "الصحة بالصدفة" لا يظهر في العينات الصغيرة، ولكن بمجرد تغير توزيع البيانات قليلاً، سيحدث انهيار واسع النطاق. إن فرض إخراج الاستدلال + استخدام LLM-as-Judge لتقييم جودة الاستدلال هو تأمين ضروري لتطبيقات الذكاء الاصطناعي في بيئة الإنتاج.
الدرس الخامس: يمكن تقليل تكاليف التصنيف (Annotation) هندسياً
لا تدع الصورة النمطية القائلة بأن "مشاريع الذكاء الاصطناعي تتطلب كميات هائلة من البيانات المصنفة" تخيفك. استراتيجية استخدام 20 عينة + تصحيحات الخبراء لمخرجات V0 كافية لدعم مجموعة تقييم مفيدة. المفتاح هو جعل مجموعة التقييم متوافقة مع توزيع بيانات العمل الحقيقية، وليس السعي وراء كمية العينات. تجربة Fractional تعتمد على استخدام مخرجات V0 الأولية كـ "تصنيف بذور"، مما يرفع الكفاءة بمقدار 5-10 أضعاف مقارنة بالتصنيف اليدوي من الصفر.
ملاحظات حول إعادة تطبيق حالة OpenAI لتدقيق الإيصالات محلياً
يحتاج المطورون الذين يرغبون في إعادة تطبيق هذه الوصفة (Cookbook) إلى حل ثلاث مشكلات: هل يمكن الوصول إلى النماذج الجديدة مثل o4-mini / gpt-4.1-mini؟، هل يمكن استخدام واجهة responses.parse الأحدث؟، وهل يمكن استدعاء نقاط نهاية Evals API؟
الاتصال المباشر بـ OpenAI من داخل الصين غير مستقر للغاية، خاصة مع واجهات الصور بسبب حجم البيانات (payload)، حيث تكون نسبة الفشل أعلى من واجهات النصوص. استخدام خدمة وكيل API (APIYI) يمكنه حل هذه المشكلات الثلاث بضغطة زر، حيث تحتاج فقط إلى تعديل سطر واحد في base_url:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # السطر الوحيد الذي يحتاج للتعديل
api_key="مفتاح APIYI الخاص بك"
)
# بقية الكود مطابق تماماً لما ورد في الـ cookbook
response = await client.responses.parse(
model="gpt-4.1-mini",
input=[...],
text_format=ReceiptDetails
)
هذا هو الفرق الجوهري بين "خدمة وكيل API لـ OpenAI" و"API متوافق مع OpenAI"؛ فالأولى تضمن مزامنة الواجهات مع OpenAI الرسمية، بينما الثانية تدعم الواجهات الأساسية فقط، وقد لا تدعم القدرات المتقدمة مثل responses.parse أو Evals API. عند إعادة تطبيق حالات رسمية مثل هذه، فإن اختيار خدمة وكيل API يجنبك الكثير من مشاكل التوافق.
الأسئلة الشائعة حول حالة استخدام مراجعة الإيصالات عبر OpenAI
س1: هل تقتصر هذه الطريقة على الإيصالات فقط؟
بالتأكيد لا. التصميم المعتمد على التقييم (Eval-Driven Design) مناسب لأي سيناريو يتضمن "مدخلات مفتوحة نسبياً ومخرجات تتطلب اتخاذ قرارات مهيكلة": مثل مراجعة العقود، فرز الصور الطبية، مراقبة جودة خدمة العملاء، فحص السير الذاتية، وكشف الاحتيال. الجوهر الذي لا يتغير هو تصميم مخطط Pydantic ومقيم (Grader) التقييم.
س2: هل 18 مقيماً (Grader) عدد كبير جداً، وهل يصعب على الفرق الصغيرة التعامل معه؟
يمكنك البدء بـ 5-6 مقيمين أساسيين، مثل دقة القرار النهائي + دقة استخراج الحقول الرئيسية. الأهم ليس العدد، بل أن كل مقيم يقابل نمط فشل محدداً. ننصح بتجربة عينات صغيرة باستخدام GPT-4o عبر لوحة تحكم APIYI، وبعد التأكد من سير العمل، يمكنك توسيع أبعاد التقييم.
س3: ألا يعد استخدام o4-mini مباشرة في النسخة V0 مكلفاً؟
في مرحلة V0، عادة ما يكون حجم الاستدعاءات عشرات أو مئات المرات، والتكلفة الإجمالية تتراوح بين بضعة دولارات إلى عشرات الدولارات، وهي تكلفة مقبولة تماماً. التوفير الحقيقي يكون في بيئة الإنتاج التي تتطلب ملايين الاستدعاءات، حيث ستكون حينها قد امتلكت مجموعة تقييم كاملة لإجراء تجارب استبدال النماذج، تماماً كما حدث في الحالة المذكورة عند الانتقال من o4-mini إلى gpt-4.1-mini، حيث انخفضت التكلفة بنسبة 67%.
س4: كيف هو أداء GPT-4o Vision في قراءة الإيصالات الصينية المكتوبة بخط اليد؟
دقة الإيصالات الإنجليزية المطبوعة عالية جداً (أكثر من 95%)، والإيصالات الصينية المطبوعة جيدة أيضاً (أكثر من 90%)، أما الصينية المكتوبة بخط اليد فتعتمد على وضوح الخط. ننصح بإنشاء مجموعة تقييم باستخدام 100 عينة حقيقية بدلاً من الاعتماد على فيديوهات العروض التوضيحية. تكلفة استدعاء GPT-4o Vision عبر خدمة وكيل API هي نفس التكلفة الرسمية، مما يجعلها مناسبة لإجراء تجارب تقييم واسعة النطاق.
س5: هل يمكنني تشغيل هذا الدليل (Cookbook) إذا لم تكن لدي صلاحية الوصول إلى Evals API؟
نعم، يمكن ذلك. تهدف Evals API بشكل أساسي إلى استضافة إعدادات وإدارة تشغيل المقيمين لدى OpenAI، أما منطق التقييم الفعلي فيمكنك تشغيله بنفسك باستخدام بايثون وهو يعطي نفس النتائج تماماً. دوال المقيمين في هذا الدليل مفتوحة المصدر بالكامل، ويمكنك نسخها وتشغيلها محلياً. إذا توسع نطاق عملك لاحقاً، يمكنك التفكير في الانتقال إلى خدمة Evals المستضافة.
س6: ما الفرق بين استخدام هذه الحالة عبر APIYI وبين الاستخدام الرسمي؟
بروتوكول الواجهة، إصدارات النماذج، ودعم المعلمات متزامنة تماماً مع OpenAI الرسمية، وهذا هو الوعد الجوهري لـ "خدمة وكيل API". يكمن الفرق بشكل رئيسي في مستوى الشبكة: فالاتصال المباشر بـ OpenAI من داخل الصين غالباً ما يواجه فشلاً في مصافحة SSL أو تجاوزاً للمدة الزمنية، بينما يتم نشر بوابة وكيل API في مراكز بيانات محلية، مما يحسن استقرار واجهات الصور بشكل ملحوظ، وهو أمر بالغ الأهمية لتشغيل مهام التقييم الطويلة.
الخلاصة
تستحق حالة مراجعة الإيصالات عبر OpenAI القراءة المتكررة لأنها فككت القضية المجردة "كيفية استخدام الذكاء الاصطناعي لحل مشكلة تجارية حقيقية" إلى ثلاث مراحل، و18 مؤشر تقييم، وممارسات هندسية ملموسة يمكن قياس تأثيرها بالدولار. هذا هو النموذج الهندسي للذكاء الاصطناعي الذي تفتقر إليه المجتمعات التقنية حالياً.
إذا كنت تعمل على أي تطبيق ذكاء اصطناعي يتضمن "إدخال مستندات/صور وإخراج قرارات مهيكلة"، فإننا ننصح بشدة بتجربة هذا الدليل بالكامل. لا تكتفِ بالمشاهدة دون تطبيق؛ فالقيمة الحقيقية للتصميم المعتمد على التقييم (eval-driven design) لا تُدرك إلا في اللحظة التي ترى فيها تغير المؤشرات. ننصح بإعادة تنفيذ ذلك عبر منصات وكيل API مثل APIYI، مما يوفر عليك عناء إعداد البيئة ويركز جهودك على المنهجية نفسها.
اجعل "التقييم الموجه" جزءاً لا يتجزأ من عملية التطوير، وسوف يتحول نظام الذكاء الاصطناعي الخاص بك من مجرد "لعبة تبدو جيدة" إلى "منتج هندسي جاهز للإنتاج ومحسوب العائد على الاستثمار". الفارق بينهما قد يصل إلى 75,000 دولار.
📌 المؤلف: فريق APIYI — نتابع عن كثب الممارسات الهندسية لواجهات برمجة التطبيقات متعددة الوسائط من OpenAI / Anthropic / Google. لمزيد من تفسيرات التطبيقات العملية وأدلة الوصول إلى خدمة وكيل API، تفضل بزيارة مركز وثائق apiyi.com.