很多設計師第一次接觸 GPT-Image-2 時都會有一個疑問:當我上傳一張照片讓它"把人物的衣服換成藍色",AI 究竟是在像 Photoshop 那樣精準地塗改像素,還是在背地裏重新畫了一張圖?這個問題的答案直接關係到我們如何使用 AI 圖片編輯工具,以及如何理解輸出結果的可預測性。
事實上,這是一個被嚴重誤解的技術細節。本文將從 AI 圖片編輯原理 出發,深入解析 GPT-Image-2、Nano Banana 等新一代自迴歸圖像模型的工作機制,回答"是局部修改還是重新繪製"這一核心問題,並揭示它們如何在整圖重繪的前提下依然保持驚人的視覺一致性。
| 核心問題 | 直覺答案 | 真實答案 |
|---|---|---|
| 編輯方式 | PS 式局部覆蓋 | 整圖 token 重繪 |
| 一致性來源 | 保留未修改像素 | 自注意力錨定原圖特徵 |
| 主流架構 | 擴散去噪 | 自迴歸 Transformer |
| 多輪編輯 | 容易累積僞影 | GPT-Image-2 無明顯漂移 |
理解這套原理之後,你會發現 prompt 的寫法、mask 的使用、參考圖的傳入策略都有了新的理論依據。我們建議讀者結合 API易 apiyi.com 平臺上的 GPT-Image-2 接口邊讀邊測,把原理落到實際效果上。
AI 圖片編輯原理:不是 PS 局部修改,而是智能重繪
很多用戶根據 ChatGPT 網頁端的交互體驗,會想當然地認爲 AI 編輯圖片就像 Photoshop 的"局部修改":系統識別到你要修改的區域,在原圖上覆蓋幾個像素,其餘部分原封不動。這種心智模型很直觀,卻完全錯誤。
**所有主流 AI 圖片編輯模型本質上都是"重新繪製"邏輯。**無論是 GPT-Image-2、Nano Banana,還是 Stable Diffusion 系列,都需要把原圖先編碼成某種內部表示(token 或 latent),再由模型"想象"出新圖的完整內部表示,最後解碼回像素。這中間不存在任何"在原圖上動筆"的步驟。
這就是爲什麼有時候你只讓 AI 改一隻眼睛的顏色,結果發現頭髮的髮絲、背景的紋理也都發生了細微變化。模型並沒有偷懶,它確實是在"重畫"整張圖,只是在大多數區域畫得非常接近原圖。
那麼問題來了:既然是重畫,爲什麼 GPT-Image-2 編輯過的圖片看起來又和原圖高度一致,甚至允許多輪反覆編輯而不"跑偏"?答案藏在它的架構裏。如果你希望第一手驗證這種行爲,可以在 API易 apiyi.com 上調用 gpt-image-2 的 /v1/images/edits 接口,使用相同 prompt 反覆編輯同一張圖,觀察細節變化。
PS 局部修改與 AI 重繪的本質差異
| 對比維度 | Photoshop 局部修改 | GPT-Image-2 智能重繪 |
|---|---|---|
| 操作單位 | 像素 | 視覺 token (8×8 或 16×16 像素塊) |
| 未編輯區域 | 物理上保持不變 | 經過編碼-解碼,理論上有微小重構 |
| 一致性保障 | 100%(直接複製原像素) | 由模型注意力機制保障 |
| 語義理解 | 無,只看像素值 | 理解"衣服""背景""光照"等語義 |
| 邊界過渡 | 需手動羽化 | 自動按語義自然過渡 |
PS 是基於像素的"機械修改",AI 是基於語義的"理解後再畫"。這就是爲什麼 AI 能完成"把白天改成黃昏"這種 PS 永遠做不到的整體性編輯——它修改的是圖像的語義表示,而不是像素的 RGB 值。
gpt-image-2 編輯原理:自迴歸 Transformer 如何"看懂"原圖
要真正理解 gpt-image-2 編輯原理,繞不開 OpenAI 在 2026 年 4 月 21 日發佈這個模型時做出的一項關鍵架構選擇:拋棄 DALL-E 系列使用的擴散模型,改用自迴歸 Transformer。這個決定直接借鑑自 GPT-4o 的多模態架構。
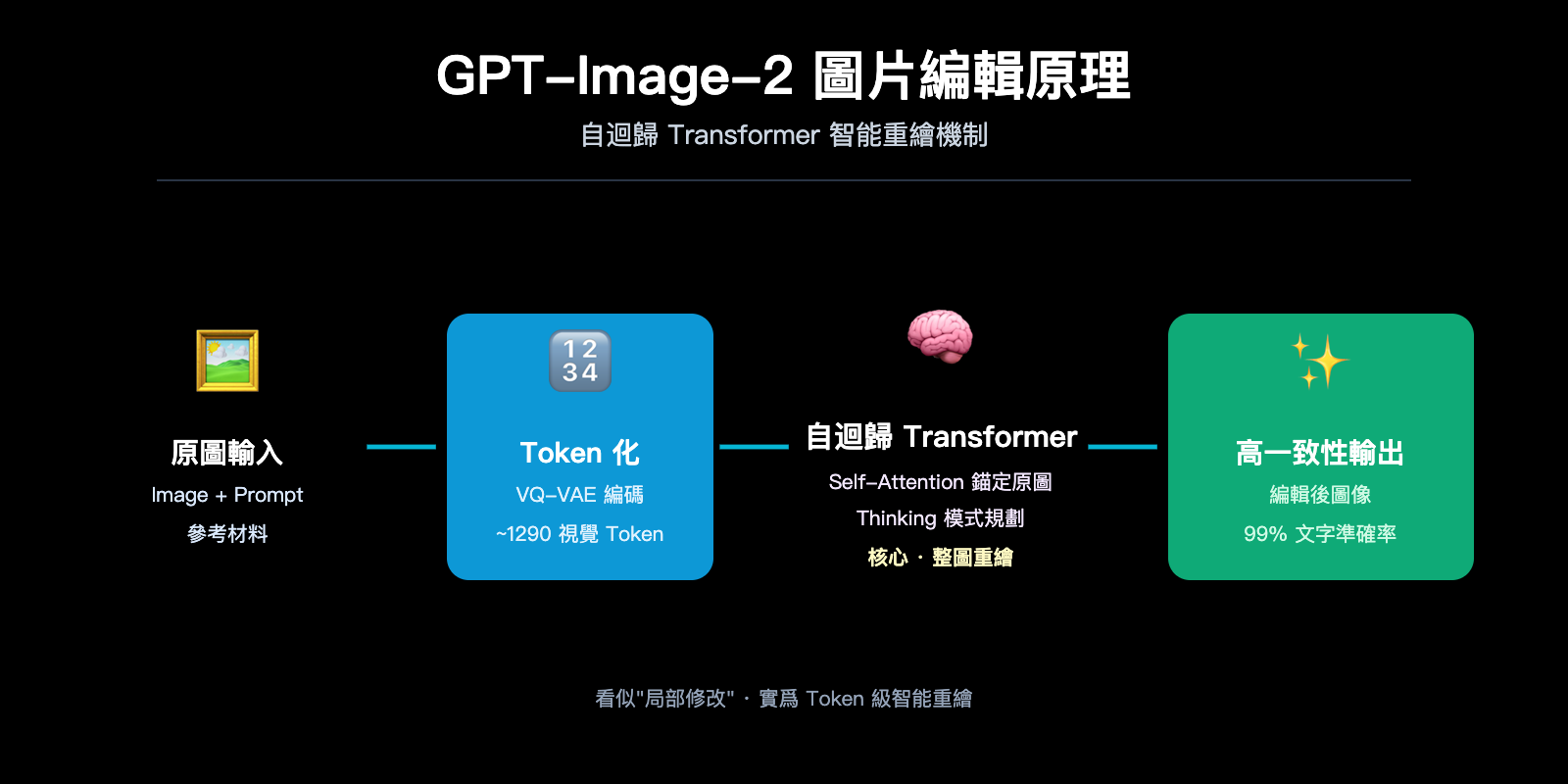
自迴歸生成本質上和 ChatGPT 寫文章是同一套機制——預測下一個 token。區別在於,這裏的"token"不是文字,而是視覺 token。模型會:
- 圖像 token 化:通過類似 VQ-VAE 的離散化機制,把一張圖片切分成約 1024-1290 個視覺 token,每個 token 大致對應原圖的 8×8 或 16×16 像素塊。
- 序列拼接:把用戶的文本 prompt token 和原圖的視覺 token 拼成一個長序列,送入統一的 Transformer。
- 逐 token 生成:模型從左到右(或按光柵掃描順序)逐一預測輸出圖像的每個視覺 token,每生成一個新 token 都能"看到"之前所有的輸入和已生成內容。
- 解碼回像素:所有視覺 token 生成完畢後,通過解碼器還原成最終的像素圖像。

這裏的關鍵洞察是:GPT-Image-2 在生成新圖時,原圖的全部 token 都在它的"視野"內。這跟你跟 ChatGPT 對話時,它能看到之前所有消息的原理完全相同。Self-Attention 機制讓每一個新生成的 token 都可以"參考"原圖任意位置的特徵。
OpenAI 官方還在 GPT-Image-2 中引入了"Thinking 模式",讓模型在真正開始生成視覺 token 之前,先用一段內部推理梳理:用戶想改什麼、哪些部分該保留、空間佈局如何安排。這進一步提高了複雜編輯指令的執行準確率,達到 99% 的文字準確率和精準的多對象佈局。如果你需要在生產環境測試這些能力,可以通過 API易 apiyi.com 接入 gpt-image-2,該平臺提供與官方一致的接口規範和便捷的多模型切換。
視覺 Tokenizer:壓縮與信息保留的平衡
視覺 Tokenizer 是整個 自迴歸圖像生成 系統的關鍵瓶頸。它需要在兩個目標之間做權衡:
- 壓縮率要高:token 數量越少,Transformer 處理越快,成本越低。
- 重建質量要高:解碼出來的像素要儘可能還原原圖,不損失細節。
主流做法是 VQ-VAE (Vector Quantized Variational Autoencoder):用編碼器把圖像區域壓縮到一個連續向量,再映射到一個有限的"碼本"中找最接近的碼字索引,這個索引就是 token。1024×1024 的圖像通常被壓縮成約 1024 個 token,信息密度極高。
正因爲這種壓縮本身有損,任何 AI 編輯工具都無法做到"100% 保留原圖未修改區域的像素值"。這就引出了下一個關鍵問題——一致性。
AI 圖像一致性的核心機制:視覺 token 化與注意力錨定
既然 GPT-Image-2 是整圖重繪,AI 圖像一致性 又是怎麼實現的?爲什麼用它修一張人像照片,你的五官、膚色、髮型不會變成另一個人?答案有四層。
第一層:視覺 token 本身的高度抽象。 一張人臉經過 tokenizer 之後,生成的 token 序列已經編碼了"這個人"的核心特徵——臉型、五官比例、膚色色調等。只要這些"身份 token"在生成新圖時被基本保留,人物就不會變樣。
第二層:Self-Attention 的全局參考。 自迴歸 Transformer 在生成每個新 token 時都會計算它與所有輸入 token (包括原圖 token) 的注意力權重。如果某個新 token 對應的區域用戶沒有指定修改,模型就會給原圖對應位置的 token 高權重,實際上是在"抄"原圖。
第三層:訓練數據的歸納偏置。 OpenAI 用了海量的"原圖-編輯圖"配對數據來訓練 GPT-Image-2,模型在訓練中學到了一個隱式規則:除非 prompt 明確要求,否則儘量保持其他區域不變。這種偏置在權重裏固化下來,推理時自然生效。
第四層:Thinking 模式的顯式規劃。 GPT-Image-2 會先用一段內部思考梳理出"哪些區域需要改、哪些保留",然後再生成,等於在生成前給自己列了一份保留清單。

一致性機制的四層防護對比
| 機制層 | 作用範圍 | 失效場景 |
|---|---|---|
| Token 抽象 | 全局身份特徵 | 人臉過遠導致 token 不足 |
| Self-Attention | 局部細節錨定 | prompt 與原圖語義衝突 |
| 訓練偏置 | 默認保留未提及區域 | prompt 過於激進 |
| Thinking 規劃 | 複雜編輯指令 | 需多次試錯調優 |
理解了這四層防護,你就能更精準地寫出避免"漂移"的 prompt。比如,與其說"重畫這個人的衣服",不如說"保持人物身份不變,僅將衣服顏色由白色改爲藍色"。我們在 API易 apiyi.com 上測試 GPT-Image-2 時發現,加入"保持其他元素不變"這類顯式約束,可以讓 Thinking 模式生效得更徹底。
mask 模式:讓重繪"假裝"成局部修改
如果用戶想要更確定的"局部修改"體驗,GPT-Image-2 提供了 /v1/images/edits 端點的 mask 參數。用戶可以傳入一張二值化的 mask 圖像:白色區域允許 AI 生成,黑色區域必須保留原圖。
但需要強調的是,mask 模式不改變重繪的本質。它的作用是在生成 token 時增加一個硬約束:對應黑色區域的 token 必須完全等於原圖 token。這是在自迴歸生成框架內做的一種"約束生成",而不是 PS 式的像素覆蓋。
擴散模型 vs 自迴歸圖像生成:兩種實現原理對比
要充分理解 GPT-Image-2 的優勢,需要把它和上一代的擴散模型(Stable Diffusion、DALL-E 3、Midjourney)做一次系統對比。兩套體系在 AI 圖片編輯原理 上有本質區別。
擴散模型的工作流程是從一張純噪聲圖開始,經過幾十步迭代去噪,逐漸顯現出最終圖像。做編輯時,它會先把原圖壓縮到 latent 空間,在 latent 上加部分噪聲,然後用 prompt 引導去噪過程,最終解碼回像素。inpainting 模式會在每一步去噪時,把 mask 之外的 latent 重置爲原圖 latent,從而"鎖住"未編輯區域。
自迴歸模型的工作流程完全不同:把圖編碼成 token,然後像寫文章一樣逐 token 預測輸出。沒有迭代去噪,沒有 latent 噪聲,一遍生成完成。

兩種範式在圖片編輯場景下的表現差異巨大,具體對比如下表:
| 對比項 | 擴散模型 (SD/DALL-E 3) | 自迴歸模型 (GPT-Image-2/Nano Banana) |
|---|---|---|
| 生成方式 | 多步去噪迭代 | 單次 token 序列預測 |
| Mask 實現 | 每步重置 unmasked latent | token 級硬約束 |
| 邊界處理 | 易出現 latent 縫合 artifact | 自然過渡(語義級) |
| 文字渲染 | 經常失敗 | 準確率約 99% |
| 多輪編輯 | 累積重編碼損失 | 幾乎無漂移 |
| 複雜指令 | 難以精準佈局 | 支持 100+ 對象佈局 |
| 速度 | 通常 10-30 秒 | 比擴散快約 60% |
| 長文字渲染 | 困難 | 任意語言/腳本 |
擴散模型的核心痛點在於 VAE 編解碼的重編碼損失 ——即便理論上 unmasked 區域被鎖住,但 latent 與像素之間的來回轉換會帶來微小色差。多次編輯後,損失累積成肉眼可見的僞影。GPT-Image-2 用自迴歸架構繞過了這個問題,Token 解碼只發生一次。
但自迴歸也不是沒有代價。它的生成成本更高,主要是因爲 token 數量大且每個 token 都需要完整的 Transformer forward。我們建議追求極致一致性和文字渲染的場景使用 GPT-Image-2 (可通過 API易 apiyi.com 接入),而對成本敏感的高併發場景仍可保留 Stable Diffusion 系列作爲補充。
gpt-image-2 編輯原理實戰:API 調用與一致性優化
理解了 gpt-image-2 編輯原理,我們來看怎麼把這套機制用到位。下面是一個最小可運行示例,通過 API易兼容端點調用 GPT-Image-2 的編輯接口:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="保持人物身份與背景不變,僅將上衣顏色由白色改爲深藍色",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
注意 prompt 寫法:顯式說明哪些保留、哪些修改,這能直接觸發 GPT-Image-2 的 Thinking 模式按你預期的方式規劃生成。如果想做精準的區域編輯,可以追加 mask 參數:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="將白色衣服改爲深藍色西裝",
size="1024x1024"
)
mask 是一張同尺寸的 PNG,白色區域是允許修改的範圍,黑色區域強制保留原圖 token。
一致性優化的 5 條實操建議
針對 AI 圖像一致性 的實際調試,我們總結了 5 條來自真實測試的經驗:
- prompt 中明確"保留什麼":不要只說"改 X",要說"保持 Y 不變,改 X"。
- 參考圖分辨率適中:OpenAI 推薦參考圖長邊不超過 1024px,過大反而稀釋 token 注意力。
- 多輪編輯使用同一基準圖:不要把上一次編輯結果當作下一輪的輸入,而是基於原圖做不同維度的編輯,最後再合併 prompt。
- 複雜場景拆分指令:把"把人物換成黃昏背景的日系風格"拆成兩步,每步只動一個變量。
- 質量參數選 high:低質量會減少 token 數量,直接削弱一致性。
gpt-image-2 價格與一致性的權衡
| 參數組合 | 單圖成本 | 適用場景 |
|---|---|---|
| 1024×1024 low | $0.006 | 創意草圖/快速預覽 |
| 1024×1024 medium | $0.053 | 社交媒體配圖 |
| 1024×1024 high | $0.211 | 商業級編輯/反覆迭代 |
| 4K high | $0.50+ | 印刷/高分辨率展示 |
成本與一致性是正相關的——高質量模式給模型分配更多 token,自然能保留更多原圖特徵。我們建議在生產環境優先使用 high 模式,通過 API易 apiyi.com 的 Batch API 還能進一步降低 50% 成本。
AI 圖片編輯原理 FAQ 與未來趨勢
Q1: GPT-Image-2 是 PS 局部修改還是重新繪製?
A: 是重新繪製。所有自迴歸圖像模型都需要把原圖編碼成 token,再生成完整的輸出 token 序列,最後解碼成新圖。即使開啓 mask,也只是在重繪過程中加約束,不是真的局部覆蓋像素。
Q2: 既然是重繪,爲什麼編輯後的圖看起來幾乎一樣?
A: 靠四層一致性機制:視覺 token 的特徵抽象、Self-Attention 對原圖的全局參考、訓練數據的歸納偏置、Thinking 模式的顯式規劃。這些機制讓 AI"主動選擇"保留未提及的區域。
Q3: 擴散模型的 inpainting 算不算真的局部修改?
A: 不算。Stable Diffusion 的 inpainting 也要把 unmasked 區域過一遍 VAE 編解碼,會帶來微小重編碼損失。多輪編輯會累積成可見僞影,這正是 GPT-Image-2 改用自迴歸的核心動機之一。可通過 API易 apiyi.com 同時調用兩種模型做對比驗證。
Q4: 爲什麼 GPT-Image-2 能多輪編輯而不漂移?
A: 因爲自迴歸架構在每次生成時都參考完整的原圖 token 序列,沒有迭代去噪的累積誤差。結合 Thinking 模式的顯式保留規劃,多輪編輯的穩定性遠超擴散模型。
Q5: 我應該用 mask 還是純 prompt 編輯?
A: 優先用 prompt + 明確的保留指令,這能利用 Thinking 模式自動規劃。需要修改的區域邊界清晰且必須精準(如人臉特定部位)時,再加 mask 做硬約束。
Q6: 未來 AI 圖片編輯會怎麼發展?
A: 三個趨勢:(1) Tokenizer 信息密度持續提升,降低 token 數和成本;(2) 多模態統一,文本/圖像/視頻共享同一 Transformer;(3) Thinking 推理能力增強,支持更長的多步編輯鏈。我們建議持續關注 API易 apiyi.com 上的新模型上線動態,以便第一時間評估升級路徑。
總結:理解原理,才能用好工具
GPT-Image-2 等自迴歸圖像模型顛覆了我們對 "AI 編輯圖片" 的直覺認知。它們不是 Photoshop 式的局部修改,而是基於 自迴歸圖像生成 的智能重繪。一致性來自 token 化的語義抽象、Self-Attention 的全局錨定、訓練偏置以及 Thinking 模式四重機制的協作。
理解這套原理,你才能寫出真正能觸發 Thinking 規劃的 prompt、避開多輪編輯的陷阱、在成本和質量之間找到平衡點。我們建議通過 API易 apiyi.com 平臺進行實際測試與對比,該平臺支持 GPT-Image-2、Nano Banana、Stable Diffusion 等多種主流模型的統一接口調用,便於快速驗證本文提到的所有原理與優化技巧。
本文由 APIYI Team 撰寫,基於 OpenAI、Google DeepMind 等官方資料與一線實測整理。如需在生產環境調用 gpt-image-2,可訪問 API易官網: apiyi.com 獲取接入文檔。