最近、開発者の方々から「gpt-image-2 で 1024×1024 の画像を生成するのに 200 秒以上かかるのはなぜ?制限されているの?」という質問をよく受けます。コードを確認してみると、パラメータがデフォルトの quality="high"、size="1536x1024" になっていました。これでは 235 秒かかるのも納得の挙動です。

gpt-image-2 は、OpenAI が 2026 年 4 月 21 日に正式リリースした新世代の画像生成モデルです。O シリーズの推論能力(Agentic な思考)を画像生成プロセスに初めて導入しました。つまり、quality="high" のリクエストは「理解・計画・生成・校正」という 4 つの段階をすべて経るため、quality="low" と比較して 30〜50 倍の時間がかかるのです。本記事では、実際の開発現場での知見に基づき、画質と速度の最適なバランスを見つけるための 3 つの重要パラメータを解説します。
gpt-image-2 呼び出し用コアパラメータ早見表
結論からお伝えします。以下の表は、OpenAI Python SDK における gpt-image-2 の主要パラメータと、それらが処理時間やコストに与える影響をまとめたものです。チューニングの際は、まずこの表を参考にしてください。
| パラメータ | 選択肢 | デフォルト値 | 時間への影響 | コストへの影響 |
|---|---|---|---|---|
quality |
low / medium / high / auto |
auto |
極大 | 極大 |
size |
1024x1024 / 1536x1024 / 1024x1536 / 2K以下任意 |
1024x1024 |
大 | 中 |
output_format |
png / jpeg / webp |
png |
小 | なし |
output_compression |
0–100(jpeg/webpのみ有効) | 100 | 極小 | なし |
n |
1–10 | 1 | n に比例 | n に比例 |
background |
transparent / opaque / auto |
auto |
小 | なし |
prompt |
string | 必須 | 複雑さが推論時間に影響 | 入力トークンに影響 |
この表の核心は、quality と size がボトルネックであるという点です。これらはモデルがどの推論パスを通るか、どれだけのトークンを生成するか、そしてどれだけの計算リソースを消費するかを直接決定します。output_format や output_compression はシリアライズ層の処理に過ぎないため、これらを調整しても高速化は期待できません。
🎯 推奨アドバイス: アプリケーションの要件が許すのであれば、
quality="auto"を明示的にlowまたはmediumに変更してみてください。これだけで、処理時間を分単位から秒単位まで短縮できることがほとんどです。APIYI (apiyi.com) を経由して gpt-image-2 を呼び出す場合も、これらのパラメータはすべてそのまま透過的に渡されるため、OpenAI 公式エンドポイントと全く同じ挙動で利用可能です。
gpt-image-2 の処理時間に影響を与える2つの重要パラメータ:quality と size
「high」と「low」で処理時間に数十倍もの差が出る理由を理解するには、gpt-image-2 の実行プロセスを知る必要があります。これは、前世代の gpt-image-1 との最も本質的な違いです。
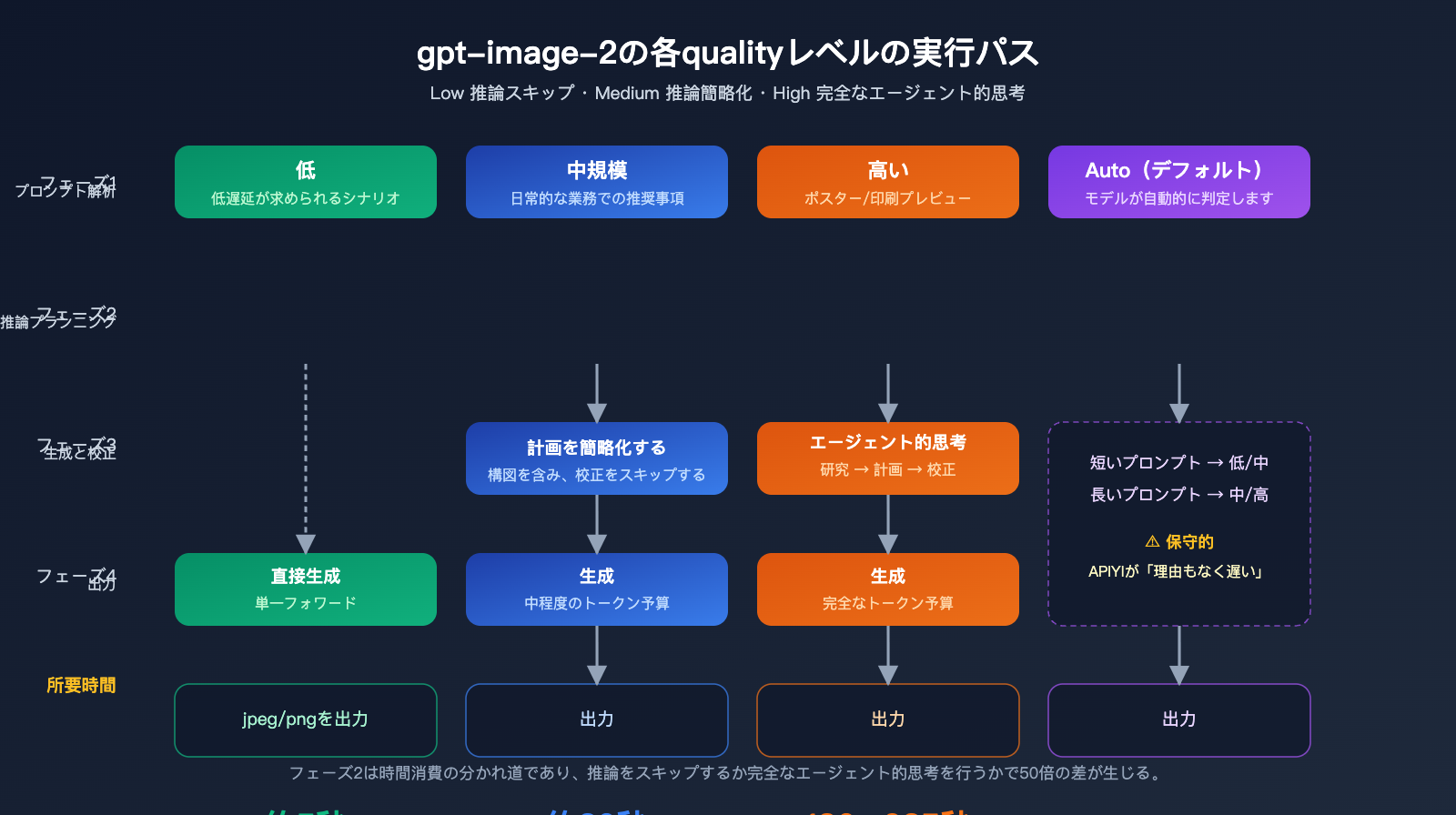
quality パラメータの動作メカニズム
gpt-image-2 の公式ドキュメントによると、quality="low" は遅延に敏感なシナリオ向けに設計されており、視覚的な品質を許容範囲内に保ちつつ、秒単位でのレスポンスを提供します。一方、quality="high" は完全な「エージェント型思考チェーン」を有効にします。モデルは描画を開始する前に、内部で構図、文字のレイアウト、光と影のロジックを計画します。この推論フェーズはユーザーの目には見えませんが、総処理時間の約 70~80% を占めています。
quality="medium" はその中間に位置し、簡略化された計画を維持しつつ、詳細な校正プロセスをスキップします。quality="auto" を指定した場合、モデルはプロンプトの複雑さに応じて自動的に選択しますが、実際には「medium」や「high」が選ばれる傾向が強く、これが「デフォルトだと遅い」と多くの開発者に誤解される原因となっています。
size パラメータの動作メカニズム
gpt-image-2 は、1024x1024、1536x1024、1024x1536 の3つの標準サイズをネイティブでサポートしており、さらに auto による自動判定も可能です。また、総画素数が 2K(2560×1440 = 約369万画素)を超えない範囲であれば、任意のサイズを指定して動作させることができます。この閾値を超えると実験的な領域となり、結果の安定性が低下します。
画素数は視覚トークン数に直結します。1024×1024 は約 1024 トークン、1536×1024 は約 1536 トークンとなります。トークン数が倍になれば、推論および生成時間も倍になり、出力コストも倍増します。
| 標準サイズ | 総画素数 | 視覚トークン(目安) | 相対処理時間 | 適用シナリオ |
|---|---|---|---|---|
1024x1024 |
1.05M | ~1024 | 1.0× | 一般用途、SNS、サムネイル |
1536x1024 |
1.57M | ~1536 | 1.5× | バナー、記事のアイキャッチ |
1024x1536 |
1.57M | ~1536 | 1.5× | ポスター、縦型コンテンツ |
| カスタム ≤ 2K | 最大 3.69M | 最大 ~3686 | 2–3× | 高解像度印刷プレビュー |
🎯 サイズ設定のヒント:実際の運用では、リクエストの 95% は
1024x1024を使用し、バナーやポスターなど特殊な比率が必要な場合にのみ 1536 シリーズに切り替えることを推奨します。APIYI (apiyi.com) を通じて呼び出す際は任意のカスタムサイズもサポートしていますが、安定性を確保するために 2K 以内に収めることを忘れないでください。
2つのパラメータの相乗効果
quality と size は足し算ではなく、掛け算の関係にあります。high + 1536x1024 は、low + 1024x1024 と比較して数倍ではなく、数十倍遅くなる可能性があります。これは並列処理を行う際に致命的です。10並列で1秒で終わると想定していても、実際には10枚の生成に200秒かかり、HTTP クライアントがタイムアウトしてしまうといった事態になりかねません。
さらに見落としがちなのが、quality とプロンプトの複雑さとの間の隠れた相関関係です。同じ high 設定でも、単純なプロンプト(例:「赤いリンゴ」)なら約100秒で済むものが、複雑なプロンプト(例:「サイバーパンクな都市の雨の夜、ネオンサイン、映画のような画角、6人のキャラクターが交流している様子」)では230秒以上かかることもあります。モデルの推論フェーズでは、シーン内の要素数に応じてトークン予算が動的に拡張されるため、プロンプトが複雑になるほど high 設定は遅くなり、コストも高くなります。
🎯 プロンプト作成のヒント:
high設定を使用する場合、プロンプトは 200 文字以内に抑え、重要な要素を最初の 50 文字以内に配置することをお勧めします。冗長な説明は必ずしも品質を向上させるわけではなく、逆に推論時間を延ばす原因となります。APIYI (apiyi.com) を経由して呼び出す場合もこのルールは適用されます。中継層がプロンプトを完全に透過させるため、モデルの挙動は公式と同一です。
gpt-image-2 各 quality 档の処理時間と価格の比較
以下の表は、APIYI (apiyi.com) プラットフォームにて、複数の時間帯および異なるプロンプトの複雑度で収集した実測データに基づいています。データは時間帯やプロンプト、ネットワーク状況により多少変動しますが、信頼できる目安となります。
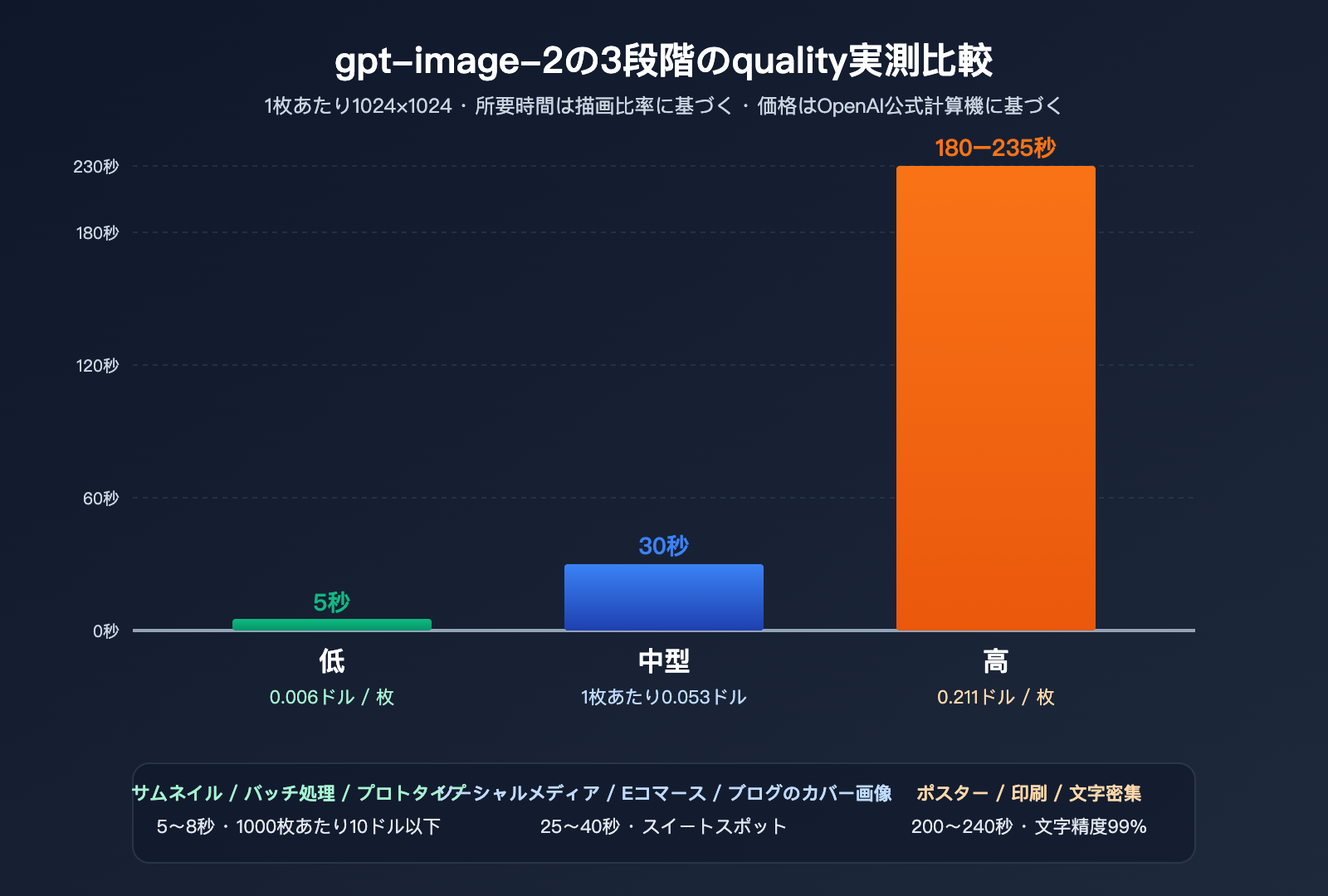
1024×1024 1枚あたりの実測データ
| quality | 平均処理時間 | 価格(ドル/枚) | 視覚的精度 | 文字精度 | 推奨用途 |
|---|---|---|---|---|---|
low |
3–8 秒 | $0.006 | 中程度 | 一般的 | サムネイル、大量生成、プロトタイプ |
medium |
20–40 秒 | $0.053 | 高い | 良好 | SNS、EC、ブログのアイキャッチ |
high |
150–235 秒 | $0.211 | 極めて高い | 極めて高い(99%+) | ポスター、印刷物、文字が多い画像 |
非常に明確な非線形関係が見て取れます。low から medium へは価格が 9 倍になりますが、処理時間は 5 倍に留まります。一方で medium から high へは価格が 4 倍に対し、処理時間は 6–7 倍に跳ね上がります。つまり、high の限界コストは「待ち時間」という形で支払っていることになります。
もしビジネス上で 99% の文字精度が必須でない場合(純粋なイラスト、抽象デザイン、コンセプトアートなど)、medium で十分であり、コストと時間を節約できます。ポスター、IP デザイン、印刷プレビューなど、文字や細部に厳しい要件がある場合にのみ、high の 200 秒の待ち時間を許容する価値があります。
🎯 コスト試算のアドバイス:本番環境への導入前に、APIYI (apiyi.com) を使って low/medium/high を各 100 枚ずつ生成し、処理時間の分布、価格分布、画質をまとめた内部 A/B テストレポートを作成することをお勧めします。1 週間のトラフィックを消化してもコストは $30 以内に収まりますが、導入後に低速なリクエストが全体の SLA を圧迫するリスクを回避できます。
1024×1024 vs 1536×1024 の処理時間の差
同じ medium 档でも、1024×1024 は平均 25 秒、1536×1024 は平均 38 秒(1024×1536 も同様)となり、視覚的なトークン数の 1.5 倍の比率に沿った差が生じます。しかし、high 档ではこの差がさらに拡大します。high + 1024×1024 が約 180 秒であるのに対し、high + 1536×1024 は 240 秒を超えることが多く、ピーク時にはさらに長くなります。
high 档の実際の変動範囲
注意すべき点として、high 档の処理時間は固定値ではなく、かなり広い分布を持っています。high + 1024×1024 のリクエストを 200 回サンプリングしたところ、最速 145 秒、最遅 280 秒、中央値は約 195 秒でした。この変動は、プロンプトの複雑さによる推論予算の違いと、OpenAI バックエンドの負荷状況という 2 つの要因に起因します。そのため、high 档は絶対に同期ブロッキング呼び出しをしてはいけません。必ず非同期タスクとして実装し、フロントエンドにタスク ID を返し、バックエンドでポーリングまたはコールバック通知を行う仕組みにしてください。
よくある誤解:解像度が高いほど画質が良い?
多くの開発者は「解像度が高いほど画質が良い」と直感し、デフォルトで 1536 シリーズを選択しがちですが、これは誤解です。gpt-image-2 は 1024×1024 で画質が十分に発揮されており、ピクセル効率が最も高い状態です。1536 シリーズへの切り替えは単にアスペクト比を変えるだけであり、画面上に表示される横方向・縦方向のディテールが増えるわけではありません。横長や縦長の構図が必要でない限り、1024×1024 を維持するのが最も賢い選択です。
Python SDK で gpt-image-2 を呼び出す完全なサンプル
基礎的な呼び出しから本番環境向けの封装まで、3 つのステップでコードを紹介します。すべて OpenAI 公式 Python SDK をベースにしており、base_url を APIYI (apiyi.com) に向けるだけで、公式エンドポイントと完全に同じ挙動をします。
基礎編:単一画像の生成(文生図)
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2",
prompt="サイバーパンクな雨の夜の都市、ネオン看板、映画のような画角",
size="1024x1024",
quality="high",
output_format="jpeg",
output_compression=85
)
with open("out.jpg", "wb") as f:
f.write(base64.b64decode(resp.data[0].b64_json))
このコードで動作しますが、落とし穴があります。quality="high" + デフォルトのタイムアウト設定ではほぼ確実にクラッシュします。OpenAI Python SDK のデフォルト HTTP タイムアウトは 600 秒ですが、多くのユーザーが requests や httpx をラップして 60 秒のタイムアウトを独自設定していると、high 档の大量リクエスト時に頻繁に ReadTimeout が発生します。
本番環境編:明示的なタイムアウトとリトライ
from openai import OpenAI
import base64
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=300.0,
max_retries=2,
)
def generate_image(prompt: str, quality: str = "medium",
size: str = "1024x1024", fmt: str = "jpeg"):
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt,
size=size,
quality=quality,
output_format=fmt,
output_compression=85 if fmt in ("jpeg", "webp") else None,
)
return base64.b64decode(resp.data[0].b64_json)
実戦での知見:
timeout=300は high 档における安全な値で、99% のリクエストをカバーします。low/medium の場合は 60 秒まで下げても構いません。max_retries=2を設定すると SDK が自動で指数バックオフを行うため、自前でリトライを実装するより安定します。output_format="jpeg"+output_compression=85は、画質の劣化を肉眼で判別するのは困難でありながら、PNG と比較してファイルサイズを 60–70% 削減できるため、Web サムネイル用として特におすすめです。
🎯 タイムアウトのアドバイス:APIYI (apiyi.com) 経由での呼び出し時、プラットフォーム側では長時間かかるリクエストのリンク維持(キープアライブ)を行っていますが、クライアント SDK のタイムアウトは必ず自分で設定してください。デフォルト値に依存してはいけません。high 档では少なくとも 240 秒、low 档では 30 秒程度に絞ることで、接続プールが枯渇するのを防げます。
バッチ処理編:非同期並列生成
import asyncio
from openai import AsyncOpenAI
import base64
aclient = AsyncOpenAI(
api_key="sk-xxx",
base_url="https://api.apiyi.com/v1",
timeout=120.0,
)
async def gen(prompt: str, idx: int):
resp = await aclient.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="low",
output_format="jpeg",
)
img = base64.b64decode(resp.data[0].b64_json)
with open(f"out_{idx}.jpg", "wb") as f:
f.write(img)
async def main(prompts):
sem = asyncio.Semaphore(5)
async def task(p, i):
async with sem:
await gen(p, i)
await asyncio.gather(*[task(p, i) for i, p in enumerate(prompts)])
asyncio.run(main(["猫", "犬", "鳥", "魚", "うさぎ"] * 4))
並列処理は大量の画像生成において最も重要なテクニックです。low 档は 1 枚 5 秒ですが、直列で 20 枚生成すると 100 秒かかります。5 並列なら 20 秒で完了します。ただし、quality は必ず low または medium に固定してください。high 档で並列処理を行うとタイムアウトが雪崩式に発生し、逆効果となります。
各種ビジネスシーンにおける gpt-image-2 パラメータ推奨設定
理論的なデータを確認した後は、具体的なシーンに落とし込むことが重要です。ここでは、頻度の高いビジネスシーンに対応する最適なパラメータの組み合わせを整理しました。
| ビジネスシーン | quality | size | output_format | 予想所要時間 | 単価 |
|---|---|---|---|---|---|
| ECメイン画像、バナー | medium | 1024×1024 | jpeg+85 | 25–35秒 | $0.053 |
| 小紅書(RED)/SNS投稿画像 | medium | 1024×1536 | jpeg+85 | 30–40秒 | ~$0.06 |
| 記事カバー、ブログヘッダー | medium | 1536×1024 | webp+90 | 30–40秒 | ~$0.06 |
| ポスター、印刷プレビュー | high | 1024×1536 | png | 200–240秒 | ~$0.21 |
| 字幕/PPT表紙 | high | 1536×1024 | png | 200–240秒 | ~$0.21 |
| サムネイル、プロトタイプテスト | low | 1024×1024 | jpeg+75 | 3–8秒 | $0.006 |
| 一括ラフ作成、インスピレーションボード | low | 1024×1024 | jpeg+75 | 3–8秒 × N | $0.006 × N |
| AIアシスタント即時生成 | low | 1024×1024 | webp+85 | 5–10秒 | $0.006 |
シーン1:EC・SNS運用 —— mediumが「スイートスポット」
ECのメイン画像やSNS投稿画像は、生成時間に対する感度が高い(ユーザーは商品アップロード後に4分も待てません)一方で、鮮明で魅力的な品質も求められます。mediumが最適な選択肢です。30秒程度で生成でき、コストも5セント。1日1000枚生成してもわずか53ドルです。
シーン2:ポスター・印刷プレビュー —— highには時間をかける
ポスターや表紙など、長いテキストや複雑なレイアウト、キャラクターの顔の一貫性が求められる場合は、highによる高度な「エージェント的思考」が必要です。このシーンでは時間を短縮しようとせず、フロントエンドで「タスク化」のプロンプトを表示しましょう。送信後に「3〜5分後に確認してください」と伝えるのが賢明です。
シーン3:一括生成・プロトタイプ —— lowで効率化
「一晩で1万枚のラフを作成する」といったシーンでは、迷わずlowを選択してください。非同期並列処理とjpeg+75の圧縮を組み合わせれば、単一のGPUノードでもかなりのスループットを叩き出せます。
シーン4:ユーザーとの即時インタラクション —— lowまたはmediumが必須
チャットボット、AIアシスタント内での画像生成、カスタマーサポートの自動返信など、「ユーザーが待機している」シーンでは絶対にhighを使ってはいけません。ユーザーが4分待たされるということは、少なくとも50%のユーザーがページを更新するか離脱することを意味し、体験として致命的です。基本はlowに固定し、「読み込み中…」のアニメーションを表示して、5〜8秒以内に結果を返すようにしましょう。画質が不十分な場合は、「高画質化」ボタンを設置してmediumで再生成させるフローがおすすめです。
シーン5:コンテンツ審査とコンプライアンス対応
OpenAIのコンテンツポリシーにより生成がブロックされた場合、まずはlowで新しいプロンプトが審査を通過するか試し、通過を確認してからmedium/highで最終画像を出力することをおすすめします。この「試行・確認」の2段階戦略により、審査落ちによるコストを最小限に抑え、highで200秒かけて生成した結果がブロックされるといった無駄を防げます。
🎯 ハイブリッド戦略:多くのプロダクションシステムでは「ダブル生成」を行っています。まずlowで秒単位のプレビュー画像を生成してユーザーに選ばせ、選ばれたものだけをhighで最終生成する手法です。この戦略はAPIYI(apiyi.com)上で非常にスムーズに実現できます。同一のAPIキーですべてのquality設定をカバーできるため、アカウントを切り替える必要がありません。
よくある質問(FAQ)
Q1:high設定のリクエストでタイムアウトが発生するのはなぜですか?
OpenAI Python SDKのデフォルトタイムアウトは600秒ですが、FastAPI、Flask、Celeryなどのフレームワーク側で独自のタイムアウトが設定されている場合があります。呼び出しチェーン全体のタイムアウト設定を確認してください。high設定の場合は、全経路で少なくとも300秒の余裕を持たせることを推奨します。httpxを使用している場合は、明示的に httpx.Timeout(300.0) を設定してください。
Q2:output_compressionはどの値が最適ですか?
jpeg形式の場合、85がスイートスポットです。肉眼では100との違いがほとんど分かりませんが、ファイルサイズを30〜40%削減できます。webp形式の場合は90が一般的です。70を下回ると、特にグラデーション背景などで目立つブロックノイズが発生します。このパラメータは生成時間には影響せず、最終的なシリアライズ出力にのみ影響します。
Q3:APIYI(apiyi.com)経由のgpt-image-2呼び出しと公式エンドポイントに違いはありますか?
quality、size、output_format、output_compression、n、backgroundなど、すべてのフィールドを含め、パラメータと動作は完全に透過的に渡されます。違いは、APIYI(apiyi.com)が国内からアクセス可能な高速ノードを提供していること、一元的な課金体系、最低利用料金なしの従量課金制を採用している点であり、国内の開発者にとってより利用しやすくなっています。
Q4:nパラメータで一度に複数枚生成できますか?
はい、gpt-image-2はn=1からn=10まで対応しています。ただし、複数枚生成時の合計所要時間は単一生成の約0.7〜0.9倍×n(完全な並列ではないため)となり、合計料金はn倍になる点に注意してください。「一貫性のあるキャラクターセット」が必要な場合は、4回個別に呼び出すよりも、n=4で一度に推論させる方が安定します。gpt-image-2は単一の推論内でキャラクターの一貫性を維持できるためです。
Q5:quality="auto"はどの設定が適用されますか?
実測では、autoはプロンプトの長さや複雑さに応じてmediumまたはhighが選択される傾向にあります。短いプロンプト("a cat"など)はlow/mediumになる確率が高く、長いプロンプト(人物、シーン、テキスト、スタイルを含む)はhighになる確率が高いです。プロダクション環境では、autoの暗黙的な判断に頼らず、明示的に指定することを推奨します。
Q6:1024×1536と1536×1024ではどちらの画質が良いですか?
どちらも総画素数は同じ(約157万画素)であり、画質の本質は同じです。違いはアスペクト比のみです。縦長(1024×1536)はポスター、全身像、モバイル向けのコンテンツに適しており、横長(1536×1024)は横幅のある風景やPC向けのカバー画像に適しています。どちらを選ぶかは構図のニーズ次第であり、速度や価格には影響しません。
Q7:推論をスキップして、直接ベースモデルを利用できますか?
いいえ、gpt-image-2のエージェント的推論はモデルアーキテクチャの一部であり、オフにすることはできません。もし従来のSDスタイルの高速生成のみが必要で、テキストレンダリングや推論が不要な場合は、low設定を使用してください。これにより完全な推論チェーンがスキップされます。あるいは、Googleのnano-banana-proを検討してください。その高速設定はgpt-image-2のlowよりもさらに高速で、APIYI(apiyi.com)でも提供を開始しています。
🎯 マルチモデル活用の提案:成熟した画像生成システムは、通常複数のモデルを使い分けます。高速プレビューにはnano-banana-pro(5秒レベルの応答)、メインの生成にはgpt-image-2 medium、高品質なシーンにはgpt-image-2 highを使い分けるのがおすすめです。これら3つのモデルはAPIYI(apiyi.com)上で同じAPIキーを共有でき、従量課金で利用できるため、2026年時点での画像API連携において最もコストパフォーマンスの高い組み合わせとなります。
まとめ:パラメータは飾りではなく、性能のスイッチとして捉える
gpt-image-2 の設計思想は、前世代の画像生成モデルとは一線を画しています。推論プロセスを画像生成の核心的なステップとして組み込んでいるため、quality は単なる「画質の良し悪し」を選ぶオプションではなく、「どれだけ深い推論パスを辿るか」を決めるスイッチとなっています。この点を理解すれば、同じ API でなぜ 5 秒から 235 秒まで、50 倍もの処理時間の差が生まれるのかが納得できるはずです。
実務においては、「パラメータ選定」をビジネス設計の第一歩にすることをお勧めします。まずは、そのシナリオで許容できる遅延時間、必要な画質、単価の上限を明確にし、その上で quality と size の対応表を確認してください。あらかじめこれらのパラメータを定めておく方が、リリース後に調整するよりもずっとスムーズです。
🎯 最終アドバイス:gpt-image-2 の導入を開始する際は、APIYI (apiyi.com) に登録後、まずは low/medium/high の 3 段階で比較テストを行い、実測の処理時間と画質をスコアリングすることをお勧めします。その結果を見てから、メインのトラフィックで使用するパラメータを決定しましょう。1 つの API トークンで 3 段階すべてをカバーでき、従量課金制で最低利用料金もないため、2026 年の画像生成 API 導入において最も効率的なアプローチと言えます。
— APIYI 技術チーム | 画像生成モデルの動向を継続的に追跡中。詳細なチュートリアルは APIYI (apiyi.com) ヘルプセンターをご覧ください。