Muchos diseñadores que se acercan por primera vez a GPT-Image-2 tienen una duda recurrente: cuando subo una foto y le pido que "cambie la ropa del personaje a azul", ¿está la IA retocando los píxeles con precisión como lo haría Photoshop, o está redibujando la imagen por completo en segundo plano? La respuesta a esta pregunta afecta directamente a cómo utilizamos las herramientas de edición de imágenes por IA y a cómo entendemos la predictibilidad de los resultados.
De hecho, este es un detalle técnico gravemente malinterpretado. En este artículo, partiremos de los principios de edición de imágenes por IA para analizar en profundidad el mecanismo de funcionamiento de los modelos de imagen autorregresivos de nueva generación, como GPT-Image-2 y Nano Banana, respondiendo a la pregunta clave de si se trata de una modificación local o de un redibujado, y revelando cómo mantienen una consistencia visual asombrosa a pesar de redibujar la imagen completa.
| Problema central | Respuesta intuitiva | Respuesta real |
|---|---|---|
| Método de edición | Cobertura local estilo PS | Redibujado de tokens de toda la imagen |
| Fuente de consistencia | Conservar píxeles no modificados | Anclaje de características mediante autoatención |
| Arquitectura principal | Difusión de eliminación de ruido | Transformer autorregresivo |
| Edición multironda | Acumulación fácil de artefactos | GPT-Image-2 sin deriva evidente |
Al comprender este principio, descubrirás que la forma de redactar la indicación, el uso de máscaras y las estrategias de entrada de la imagen de referencia tienen ahora una base teórica sólida. Recomendamos a los lectores que prueben la interfaz de GPT-Image-2 en la plataforma APIYI (apiyi.com) mientras leen, para llevar estos principios a resultados prácticos.
Principios de edición de imágenes por IA: no es una modificación local tipo PS, sino un redibujado inteligente
Muchos usuarios, basándose en la experiencia de interacción con la web de ChatGPT, asumen erróneamente que la edición de imágenes por IA es como la "modificación local" de Photoshop: el sistema identifica el área que deseas modificar, cubre algunos píxeles en la imagen original y deja el resto intacto. Este modelo mental es muy intuitivo, pero completamente incorrecto.
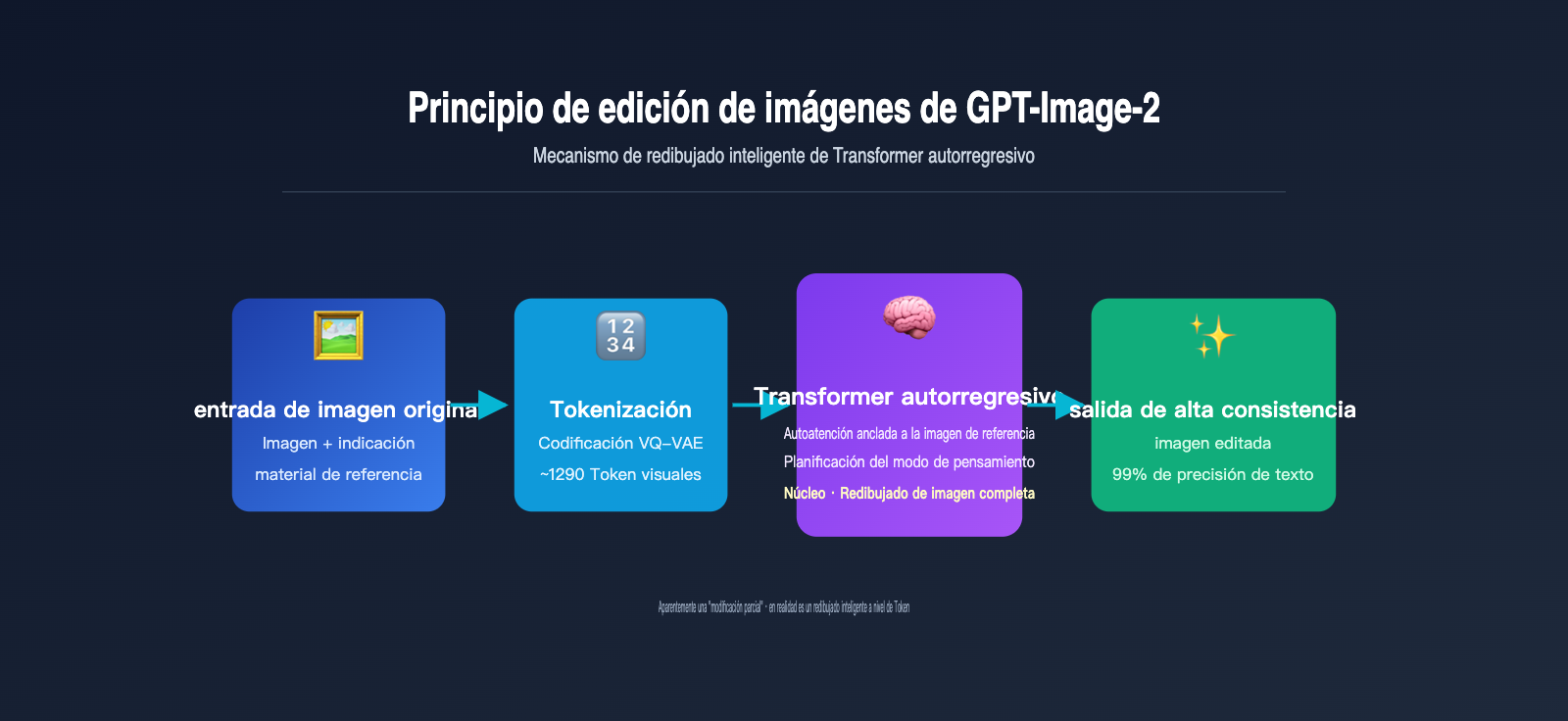
Todos los modelos de edición de imágenes por IA convencionales se basan esencialmente en la lógica de "redibujar". Ya sea GPT-Image-2, Nano Banana o la serie Stable Diffusion, todos necesitan codificar primero la imagen original en algún tipo de representación interna (tokens o latentes), para que luego el modelo "imagine" la representación interna completa de la nueva imagen y, finalmente, la decodifique de nuevo a píxeles. No existe ningún paso de "dibujar sobre la imagen original".
Es por eso que a veces, cuando le pides a la IA que cambie el color de un solo ojo, descubres que los mechones de pelo y las texturas del fondo también han sufrido cambios sutiles. El modelo no es perezoso; realmente está "redibujando" toda la imagen, solo que en la mayoría de las áreas dibuja de forma muy similar a la original.
Entonces surge la pregunta: si se redibuja, ¿por qué las imágenes editadas por GPT-Image-2 parecen tan consistentes con la original e incluso permiten múltiples rondas de edición sin "desviarse"? La respuesta reside en su arquitectura. Si deseas verificar este comportamiento de primera mano, puedes invocar el endpoint /v1/images/edits de gpt-image-2 en APIYI (apiyi.com), editar la misma imagen repetidamente con la misma indicación y observar los cambios en los detalles.
Diferencias esenciales entre la modificación local de PS y el redibujado de IA
| Dimensión de comparación | Modificación local de Photoshop | Redibujado inteligente de GPT-Image-2 |
|---|---|---|
| Unidad de operación | Píxel | Token visual (bloque de 8×8 o 16×16 píxeles) |
| Área no editada | Físicamente permanece igual | Tras codificación-decodificación, hay una reconstrucción teórica |
| Garantía de consistencia | 100% (copia directa de píxeles originales) | Garantizada por el mecanismo de atención del modelo |
| Comprensión semántica | Ninguna, solo valores de píxeles | Comprende la semántica de "ropa", "fondo", "iluminación", etc. |
| Transición de bordes | Requiere difuminado manual | Transición natural automática basada en la semántica |
PS es una "modificación mecánica" basada en píxeles, mientras que la IA es un "redibujado tras la comprensión" basada en la semántica. Es por eso que la IA puede completar ediciones globales como "cambiar el día por el atardecer", algo que PS nunca podría hacer: modifica la representación semántica de la imagen, no los valores RGB de los píxeles.
Principio de edición de gpt-image-2: cómo un Transformer autorregresivo "entiende" la imagen original
Para comprender realmente el principio de edición de gpt-image-2, es fundamental analizar una elección arquitectónica clave que OpenAI tomó cuando lanzó este modelo el 21 de abril de 2026: abandonar los modelos de difusión utilizados en la serie DALL-E y optar por un Transformer autorregresivo. Esta decisión se basa directamente en la arquitectura multimodal de GPT-4o.
La generación autorregresiva es, en esencia, el mismo mecanismo que utiliza ChatGPT para escribir artículos: predecir el siguiente token. La diferencia radica en que, aquí, el "token" no es texto, sino un token visual. El modelo realiza lo siguiente:
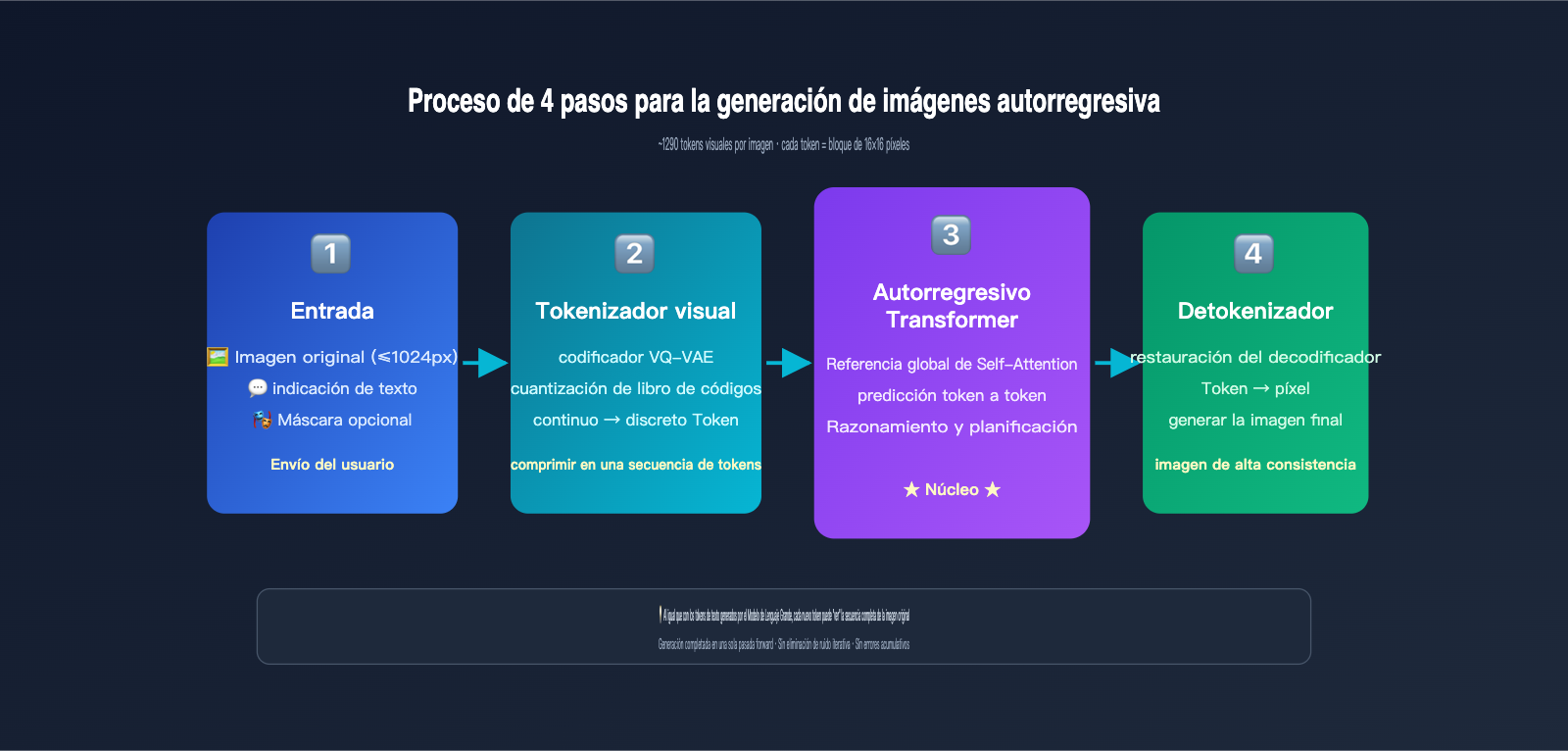
- Tokenización de la imagen: Mediante un mecanismo de discretización similar a VQ-VAE, divide una imagen en aproximadamente 1024-1290 tokens visuales, donde cada token corresponde aproximadamente a un bloque de 8×8 o 16×16 píxeles de la imagen original.
- Concatenación de secuencias: Combina los tokens de la indicación de texto del usuario con los tokens visuales de la imagen original en una secuencia larga, que se introduce en un Transformer unificado.
- Generación token a token: El modelo predice cada token visual de la imagen de salida uno por uno de izquierda a derecha (o siguiendo un orden de escaneo ráster). Cada vez que se genera un nuevo token, el modelo puede "ver" todas las entradas anteriores y el contenido ya generado.
- Decodificación a píxeles: Una vez generados todos los tokens visuales, el decodificador los convierte de nuevo en la imagen de píxeles final.
La clave aquí es: cuando GPT-Image-2 genera una nueva imagen, todos los tokens de la imagen original están dentro de su "campo de visión". Esto funciona exactamente igual que cuando conversas con ChatGPT y este puede ver todos los mensajes anteriores. El mecanismo de Self-Attention permite que cada nuevo token generado pueda "hacer referencia" a las características de cualquier parte de la imagen original.
OpenAI también introdujo un "modo de pensamiento" en GPT-Image-2, que permite al modelo realizar un razonamiento interno antes de comenzar a generar tokens visuales: qué quiere cambiar el usuario, qué partes deben conservarse y cómo organizar la disposición espacial. Esto ha mejorado aún más la precisión en la ejecución de instrucciones de edición complejas, alcanzando un 99% de precisión textual y una disposición precisa de múltiples objetos. Si necesitas probar estas capacidades en un entorno de producción, puedes acceder a gpt-image-2 a través de APIYI (apiyi.com), que ofrece especificaciones de interfaz consistentes con las oficiales y un cambio sencillo entre múltiples modelos.
Tokenizador visual: el equilibrio entre compresión y retención de información
El tokenizador visual es el cuello de botella clave de todo el sistema de generación de imágenes autorregresiva. Debe equilibrar dos objetivos:
- Alta tasa de compresión: cuantos menos tokens, más rápido procesa el Transformer y menor es el costo.
- Alta calidad de reconstrucción: los píxeles decodificados deben restaurar la imagen original tanto como sea posible, sin perder detalles.
El enfoque principal es VQ-VAE (Vector Quantized Variational Autoencoder): utiliza un codificador para comprimir las áreas de la imagen en un vector continuo y luego lo asigna a un "libro de códigos" limitado para encontrar el índice del código más cercano; este índice es el token. Las imágenes de 1024×1024 suelen comprimirse en unos 1024 tokens, con una densidad de información extremadamente alta.
Precisamente porque esta compresión es intrínsecamente con pérdida, ninguna herramienta de edición de IA puede "conservar al 100% los valores de píxeles de las áreas no modificadas de la imagen original". Esto nos lleva a la siguiente cuestión clave: la consistencia.
Mecanismos centrales de la consistencia de imágenes en IA: tokenización visual y anclaje de atención
Dado que GPT-Image-2 realiza un redibujado de toda la imagen, ¿cómo se logra realmente la consistencia de imágenes en IA? ¿Por qué al editar un retrato, tus rasgos faciales, tono de piel y peinado no se transforman en los de otra persona? La respuesta tiene cuatro niveles.
Primer nivel: la alta abstracción de los tokens visuales. Después de que un rostro pasa por el tokenizador, la secuencia de tokens generada ya ha codificado las características centrales de "esta persona": forma de la cara, proporciones de los rasgos y tono de piel. Mientras estos "tokens de identidad" se conserven básicamente al generar la nueva imagen, el personaje no cambiará.
Segundo nivel: referencia global mediante Self-Attention. Al generar cada nuevo token, el Transformer autorregresivo calcula sus pesos de atención con todos los tokens de entrada (incluidos los de la imagen original). Si el usuario no ha especificado cambios en el área correspondiente a un nuevo token, el modelo asigna un peso alto al token de la posición correspondiente en la imagen original, lo que en la práctica equivale a "copiar" la imagen original.
Tercer nivel: sesgo inductivo de los datos de entrenamiento. OpenAI utilizó una cantidad masiva de datos emparejados de "imagen original-imagen editada" para entrenar a GPT-Image-2. En este proceso, el modelo aprendió una regla implícita: a menos que la indicación lo exija explícitamente, intenta mantener las demás áreas sin cambios. Este sesgo se consolida en los pesos y entra en juego de forma natural durante la inferencia.
Cuarto nivel: planificación explícita mediante el modo Thinking. GPT-Image-2 realiza primero una fase de razonamiento interno para clasificar "qué áreas deben modificarse y cuáles deben conservarse" antes de generar la imagen, lo que equivale a crear una lista de elementos a preservar antes de empezar.
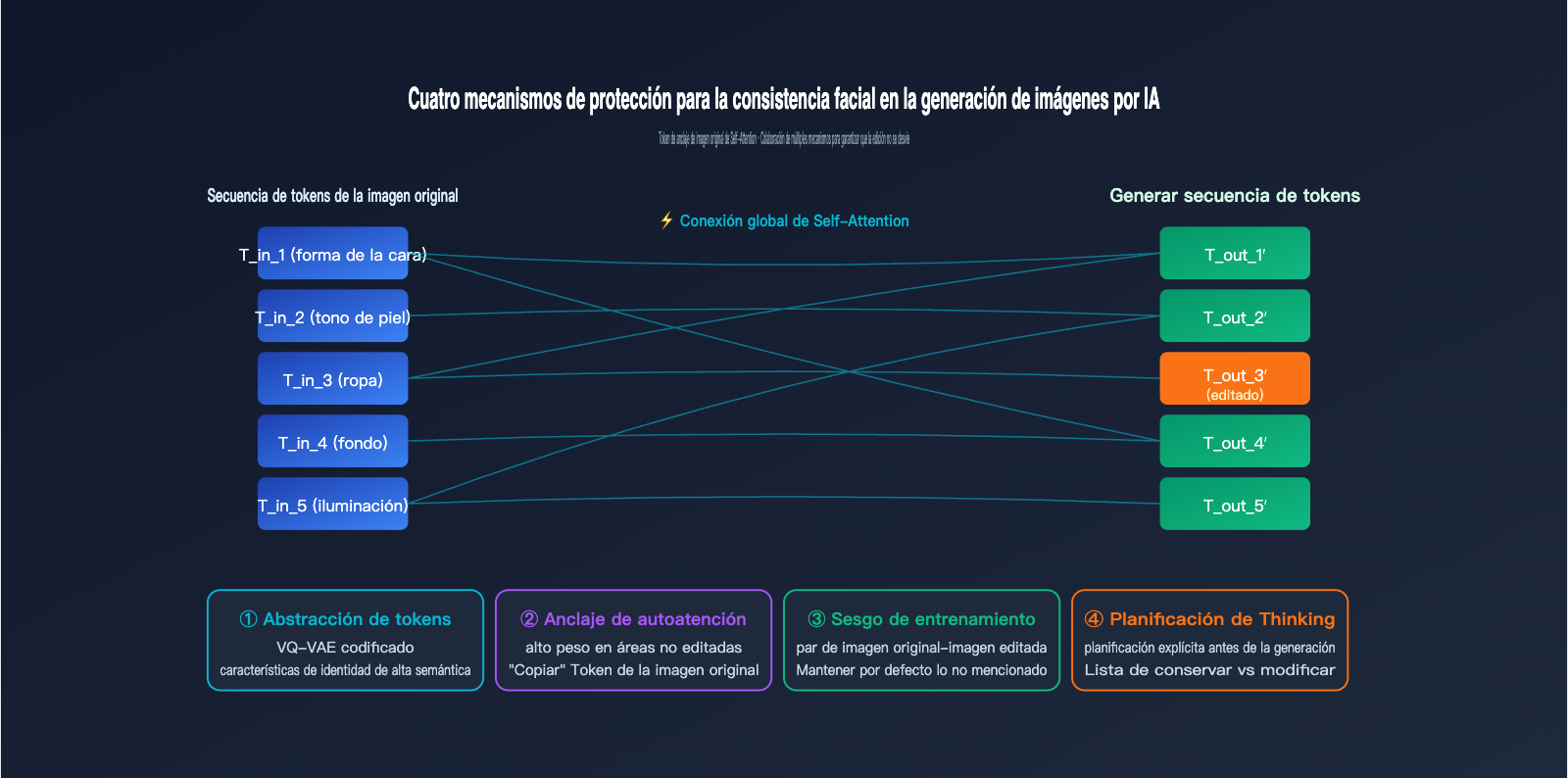
Comparativa de las cuatro capas de protección de consistencia
| Capa de mecanismo | Alcance de acción | Escenarios de fallo |
|---|---|---|
| Abstracción de tokens | Características de identidad global | Rostro demasiado lejano (pocos tokens) |
| Self-Attention | Anclaje de detalles locales | Conflicto semántico entre indicación y original |
| Sesgo de entrenamiento | Preservación por defecto | Indicación demasiado agresiva |
| Planificación Thinking | Instrucciones de edición complejas | Requiere múltiples ajustes y pruebas |
Al comprender estas cuatro capas de protección, podrás redactar indicaciones más precisas para evitar la "deriva". Por ejemplo, en lugar de decir "vuelve a dibujar la ropa de esta persona", es mejor decir "mantén la identidad del personaje sin cambios, cambia solo el color de la ropa de blanco a azul". Al probar GPT-Image-2 en APIYI (apiyi.com), descubrimos que añadir restricciones explícitas como "mantener los demás elementos sin cambios" permite que el modo Thinking sea mucho más efectivo.
Modo máscara: hacer que el redibujado "simule" una modificación local
Si el usuario busca una experiencia de "modificación local" más definida, GPT-Image-2 ofrece el parámetro mask en el endpoint /v1/images/edits. El usuario puede enviar una imagen de máscara binaria: las áreas blancas permiten que la IA genere contenido, mientras que las áreas negras deben conservar la imagen original.
Sin embargo, es importante destacar que el modo máscara no cambia la naturaleza del redibujado. Su función es añadir una restricción estricta al generar los tokens: los tokens correspondientes a las áreas negras deben ser exactamente iguales a los de la imagen original. Esto es una "generación restringida" dentro del marco autorregresivo, no una superposición de píxeles al estilo de Photoshop.
Modelos de difusión vs. Generación de imágenes autorregresiva: Comparativa de principios de implementación
Para comprender plenamente las ventajas de GPT-Image-2, es necesario realizar una comparación sistemática con los modelos de difusión de la generación anterior (Stable Diffusion, DALL-E 3, Midjourney). Ambos sistemas tienen diferencias fundamentales en sus principios de edición de imágenes por IA.
El flujo de trabajo de los modelos de difusión comienza con una imagen de ruido puro, que pasa por decenas de pasos de eliminación de ruido iterativa hasta que la imagen final emerge gradualmente. Al editar, primero se comprime la imagen original en un espacio latente, se añade ruido parcial a dicho espacio y luego se utiliza una indicación para guiar el proceso de eliminación de ruido, decodificando finalmente el resultado a píxeles. El modo de inpainting restablece el espacio latente fuera de la máscara al latente original en cada paso de eliminación de ruido, "bloqueando" así las áreas no editadas.
El flujo de trabajo de los modelos autorregresivos es completamente diferente: la imagen se codifica en tokens y luego se predice la salida token por token, tal como se redacta un artículo. No hay eliminación de ruido iterativa, no hay ruido latente; la generación se completa en una sola pasada.
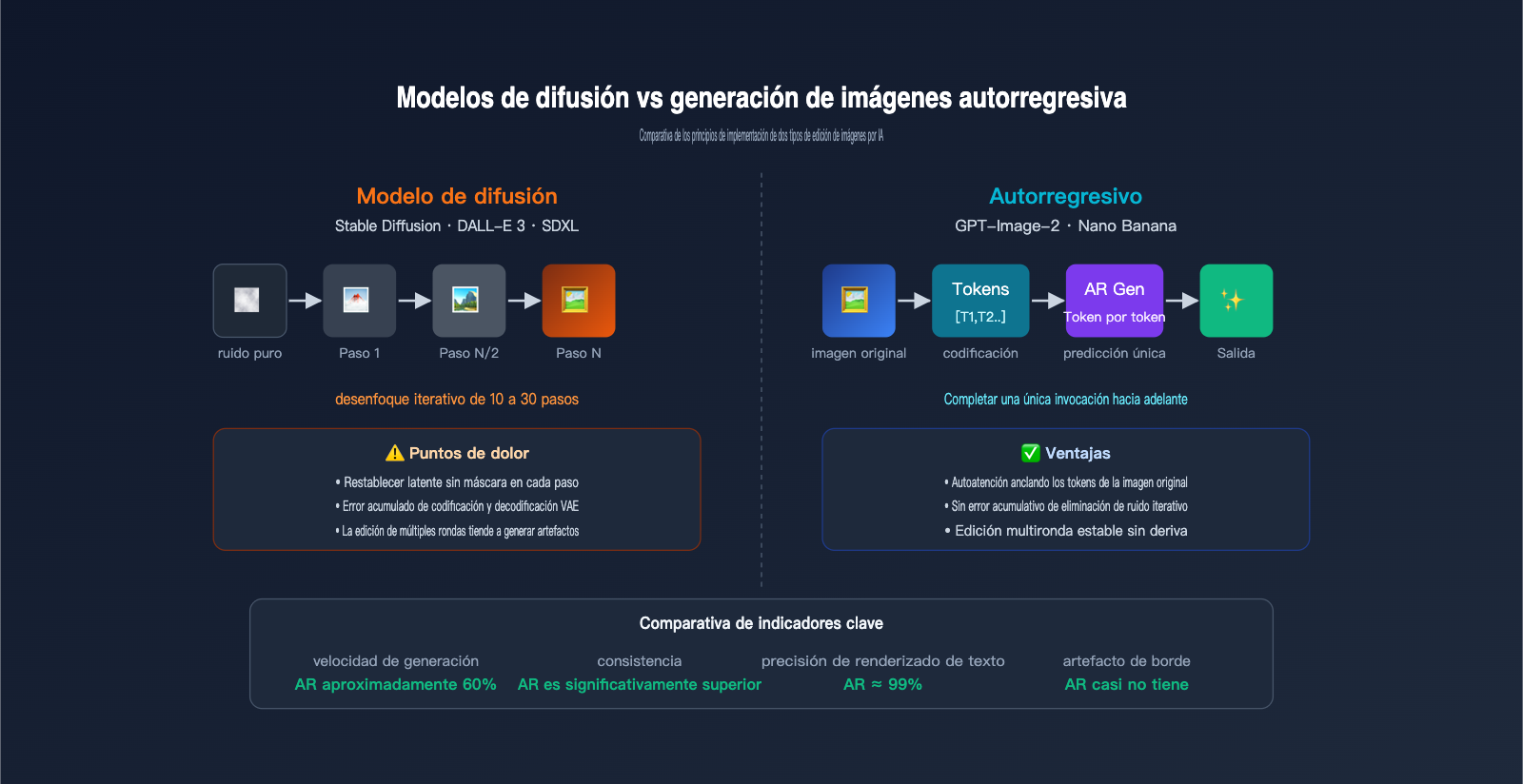
Las diferencias de rendimiento entre ambos paradigmas en escenarios de edición de imágenes son enormes; a continuación se detalla en la siguiente tabla:
| Comparativa | Modelos de difusión (SD/DALL-E 3) | Modelos autorregresivos (GPT-Image-2/Nano Banana) |
|---|---|---|
| Método de generación | Iteración de eliminación de ruido multietapa | Predicción de secuencia de tokens única |
| Implementación de máscara | Restablecimiento de latente no enmascarado por paso | Restricción estricta a nivel de token |
| Procesamiento de bordes | Propenso a artefactos de unión latente | Transición natural (a nivel semántico) |
| Renderizado de texto | Falla frecuentemente | Precisión de aprox. 99% |
| Edición multironda | Pérdida de recodificación acumulada | Casi sin deriva |
| Instrucciones complejas | Difícil de diseñar con precisión | Soporta diseño de más de 100 objetos |
| Velocidad | Generalmente 10-30 segundos | ~60% más rápido que la difusión |
| Renderizado de texto largo | Difícil | Cualquier idioma/script |
El principal punto débil de los modelos de difusión radica en la pérdida de recodificación de la codificación/decodificación VAE: incluso si teóricamente las áreas no enmascaradas están bloqueadas, la conversión de ida y vuelta entre el latente y los píxeles provoca ligeras diferencias de color. Tras varias ediciones, la pérdida se acumula en artefactos visibles. GPT-Image-2 evita este problema mediante una arquitectura autorregresiva, donde la decodificación de tokens solo ocurre una vez.
Sin embargo, el modelo autorregresivo no está exento de costes. Su coste de generación es mayor, principalmente porque la cantidad de tokens es grande y cada token requiere un forward completo del Transformer. Recomendamos utilizar GPT-Image-2 (accesible a través de APIYI, apiyi.com) para escenarios que busquen una consistencia y renderizado de texto extremos, mientras que los escenarios de alta concurrencia sensibles a los costes aún pueden mantener la serie Stable Diffusion como complemento.
Práctica de los principios de edición de gpt-image-2: Invocación de API y optimización de la consistencia
Una vez comprendidos los principios de edición de gpt-image-2, veamos cómo aplicar este mecanismo de manera efectiva. A continuación, presentamos un ejemplo mínimo ejecutable para invocar la interfaz de edición de GPT-Image-2 a través de los puntos de conexión compatibles con APIYI:
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
with open("portrait.png", "rb") as image_file:
response = client.images.edit(
model="gpt-image-2",
image=image_file,
prompt="Mantén la identidad de la persona y el fondo sin cambios, solo cambia el color de la camisa de blanco a azul oscuro",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Presta atención a cómo redactas la indicación: especifica claramente qué elementos deben conservarse y cuáles deben modificarse. Esto activa directamente el modo "Thinking" (pensamiento) de GPT-Image-2 para planificar la generación tal como esperas. Si deseas realizar una edición de área precisa, puedes añadir el parámetro mask:
response = client.images.edit(
model="gpt-image-2",
image=open("portrait.png", "rb"),
mask=open("mask.png", "rb"),
prompt="Cambia la ropa blanca por un traje azul oscuro",
size="1024x1024"
)
La máscara es un archivo PNG del mismo tamaño, donde las áreas blancas representan el rango permitido para modificaciones y las áreas negras fuerzan la conservación de los tokens de la imagen original.
5 consejos prácticos para la optimización de la consistencia
Para la depuración real de la consistencia de imágenes por IA, hemos resumido 5 experiencias obtenidas de pruebas reales:
- Sé explícito en la indicación sobre "qué conservar": No digas solo "cambia X", di "mantén Y sin cambios y cambia X".
- Usa una resolución de imagen de referencia moderada: OpenAI recomienda que el lado más largo de la imagen de referencia no supere los 1024px; un tamaño excesivo puede diluir la atención de los tokens.
- Usa la misma imagen base para ediciones multironda: No utilices el resultado de la edición anterior como entrada para la siguiente; basa cada edición en la imagen original y luego combina las indicaciones.
- Divide las instrucciones en escenas complejas: Si quieres "cambiar al personaje a un estilo japonés con fondo al atardecer", divídelo en dos pasos, modificando solo una variable en cada uno.
- Selecciona el parámetro de calidad "high": La baja calidad reduce el número de tokens, lo que debilita directamente la consistencia.
Equilibrio entre precio y consistencia en gpt-image-2
| Combinación de parámetros | Costo por imagen | Escenario de uso |
|---|---|---|
| 1024×1024 low | $0.006 | Bocetos creativos/previsualización rápida |
| 1024×1024 medium | $0.053 | Imágenes para redes sociales |
| 1024×1024 high | $0.211 | Edición de nivel comercial/iteraciones frecuentes |
| 4K high | $0.50+ | Impresión/visualización de alta resolución |
El costo y la consistencia están correlacionados positivamente: el modo de alta calidad asigna más tokens al modelo, lo que naturalmente permite retener más características de la imagen original. Recomendamos priorizar el modo "high" en entornos de producción y utilizar la Batch API de APIYI (apiyi.com) para reducir los costos hasta en un 50%.
Preguntas frecuentes sobre los principios de edición de imágenes por IA y tendencias futuras
P1: ¿GPT-Image-2 realiza modificaciones locales al estilo Photoshop o redibuja la imagen?
R: Redibuja. Todos los modelos de imagen autorregresivos necesitan codificar la imagen original en tokens, generar una secuencia completa de tokens de salida y finalmente decodificarla en una nueva imagen. Incluso al activar la máscara, solo se añaden restricciones durante el proceso de redibujado, no se trata de una superposición real de píxeles.
P2: Si es un redibujado, ¿por qué la imagen editada parece casi idéntica?
R: Depende de cuatro mecanismos de consistencia: la abstracción de características de los tokens visuales, la referencia global de la imagen original mediante Self-Attention, el sesgo inductivo de los datos de entrenamiento y la planificación explícita del modo "Thinking". Estos mecanismos permiten que la IA "elija activamente" conservar las áreas no mencionadas.
P3: ¿El inpainting de los modelos de difusión cuenta como una modificación local real?
R: No. El inpainting de Stable Diffusion también debe pasar las áreas no enmascaradas a través de la codificación/decodificación VAE, lo que genera una pequeña pérdida de re-codificación. Las ediciones multironda acumulan artefactos visibles, que es precisamente una de las motivaciones principales por las que GPT-Image-2 cambió a un modelo autorregresivo. Puedes usar APIYI (apiyi.com) para invocar ambos modelos simultáneamente y realizar una validación comparativa.
P4: ¿Por qué GPT-Image-2 puede realizar ediciones multironda sin desviarse?
R: Porque la arquitectura autorregresiva hace referencia a la secuencia completa de tokens de la imagen original en cada generación, sin errores acumulativos de eliminación de ruido iterativa. Combinado con la planificación explícita de conservación del modo "Thinking", la estabilidad de las ediciones multironda supera con creces a los modelos de difusión.
P5: ¿Debo usar máscara o solo edición mediante indicación?
R: Prioriza el uso de indicaciones con instrucciones de conservación claras, esto permite aprovechar la planificación automática del modo "Thinking". Solo añade una máscara para restricciones estrictas cuando los límites del área a modificar sean claros y deban ser precisos (como partes específicas del rostro).
P6: ¿Cómo evolucionará la edición de imágenes por IA en el futuro?
R: Tres tendencias: (1) Aumento continuo de la densidad de información del tokenizador, reduciendo el número de tokens y los costos; (2) Unificación multimodal, donde texto, imágenes y video comparten el mismo Transformer; (3) Mejora de las capacidades de razonamiento "Thinking", soportando cadenas de edición de múltiples pasos más largas. Recomendamos seguir de cerca las actualizaciones de nuevos modelos en APIYI (apiyi.com) para evaluar las rutas de actualización de inmediato.
Conclusión: Entender los principios para dominar la herramienta
Los modelos de imagen autorregresivos como GPT-Image-2 han cambiado nuestra intuición sobre la "edición de imágenes por IA". No son modificaciones locales al estilo Photoshop, sino un redibujado inteligente basado en la generación de imágenes autorregresiva. La consistencia proviene de la colaboración de cuatro mecanismos: la abstracción semántica de los tokens, el anclaje global de Self-Attention, el sesgo de entrenamiento y el modo "Thinking".
Al comprender estos principios, podrás escribir indicaciones que realmente activen la planificación del modo "Thinking", evitar las trampas de las ediciones multironda y encontrar el punto de equilibrio entre costo y calidad. Recomendamos realizar pruebas y comparaciones prácticas a través de la plataforma APIYI (apiyi.com), la cual admite la invocación mediante una interfaz unificada para diversos modelos principales como GPT-Image-2, Nano Banana y Stable Diffusion, facilitando la verificación rápida de todos los principios y técnicas de optimización mencionados en este artículo.
Este artículo fue redactado por el equipo de APIYI, basado en materiales oficiales de OpenAI, Google DeepMind y pruebas de campo. Si necesitas invocar gpt-image-2 en un entorno de producción, visita el sitio web oficial de APIYI: apiyi.com para obtener la documentación de acceso.