Catatan Penulis: Claude Opus 4.8 dirilis pada 28 Mei, mencatatkan rekor peningkatan SWE-Bench Pro hingga 69,2%, serta menambahkan kemampuan sub-agen paralel Dynamic Workflows. Artikel ini mengulas secara mendalam 5 peningkatan utama dalam kemampuan pemrograman dan Agent.
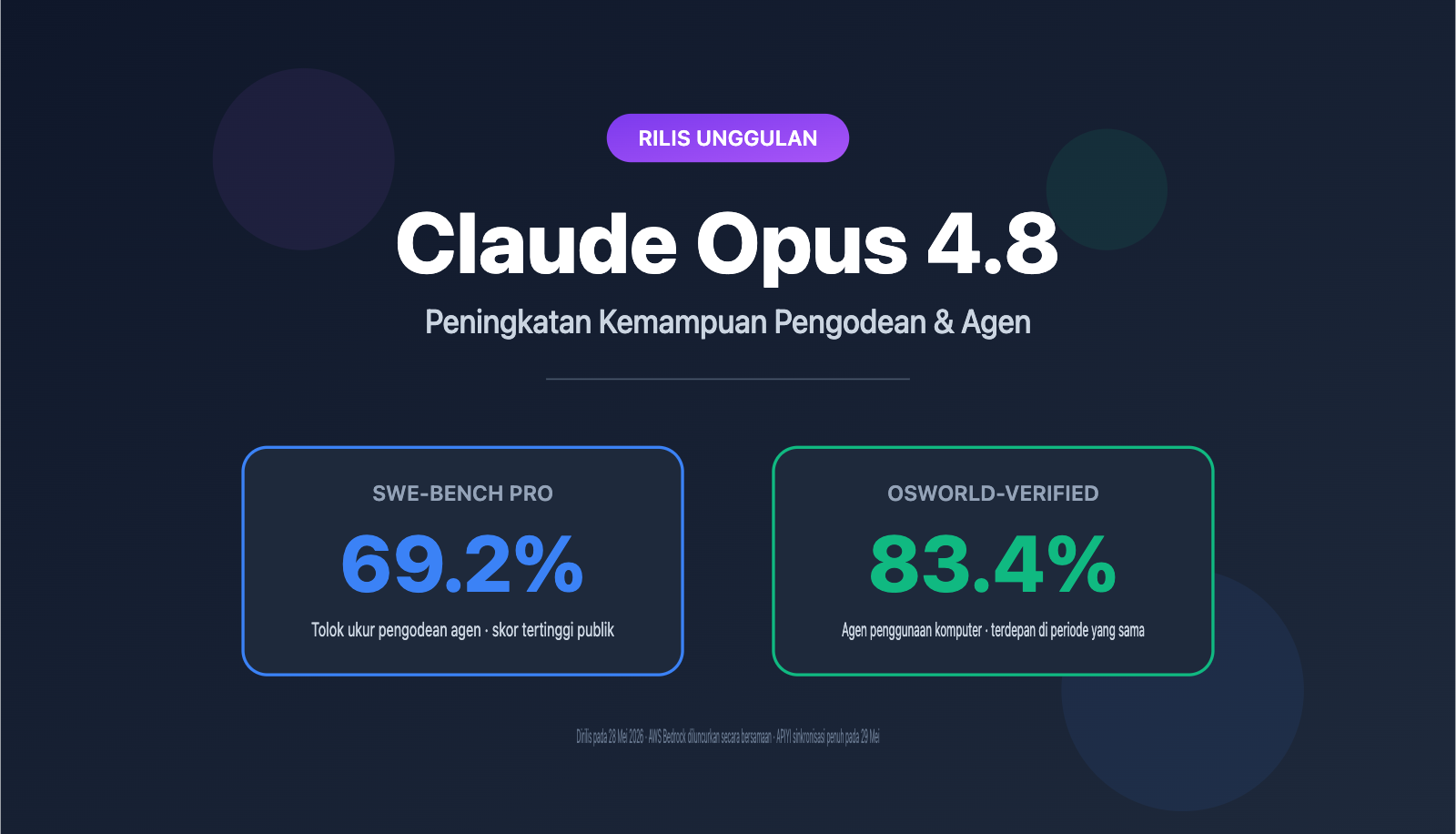
Anthropic secara resmi merilis Claude Opus 4.8 pada 28 Mei, yang juga tersedia di AWS Bedrock dan Claude Platform on AWS. Sinyal paling nyata dari pembaruan ini adalah skor SWE-Bench Pro yang melonjak dari 64,3% pada versi 4.7 menjadi 69,2%, memecahkan rekor semua model publik, sekaligus menambahkan kemampuan Dynamic Workflows yang dapat menjadwalkan ratusan sub-agen secara paralel.
Bagi pengembang, Opus 4.8 bukanlah iterasi nomor versi yang ringan, melainkan perombakan sistematis untuk "tugas otonom jangka panjang": model ini telah dioptimalkan secara mendasar dalam hal pemeriksaan mandiri kode, efisiensi pemanggilan alat, pemeliharaan jendela konteks, dan pemulihan kesalahan. Sebagai saluran sumber daya resmi AWS Claude, APIYI telah menyelesaikan sinkronisasi penuh pada 29 Mei. Pengembang dapat langsung melakukan pemanggilan claude-opus-4-8 melalui apiyi.com menggunakan protokol yang kompatibel dengan OpenAI, tanpa perlu mengganti SDK atau menulis ulang klien.
Artikel ini akan membahas tiga dimensi: "Apa yang sebenarnya berubah pada Opus 4.8", "Dalam skenario apa peningkatan kemampuan pemrograman terlihat", dan "5 terobosan kemampuan Agent", dilengkapi dengan data pengujian resmi Anthropic dan informasi peluncuran AWS, untuk membantu Anda memutuskan apakah perlu beralih ke versi ini di lingkungan produksi.
Apa Perubahan Inti Claude Opus 4.8
Claude Opus 4.8 adalah Model Bahasa Besar paling kuat dari Anthropic saat ini, yang diposisikan sebagai "agen otonom jangka panjang yang mampu memberikan hasil kerja produksi". Dibandingkan dengan 4.7, model ini dioptimalkan secara terpusat dalam tiga arah: agen pengodean, pekerjaan berbasis pengetahuan profesional, dan tugas otonom yang berjalan lama.
Deskripsi kemampuan dari Anthropic adalah: membaca basis kode seperti seorang insinyur, merencanakan sebelum mengedit, dan menjaga jendela konteks dalam sesi panjang di repositori nyata. Ketiga tindakan ini membentuk prototipe "Agent ala insinyur"—model tidak lagi hanya menghasilkan potongan kode baris demi baris, tetapi memahami struktur repositori, menyusun rencana modifikasi, dan menjaga konsistensi lintas sesi.
Opus 4.8 juga memiliki karakteristik yang ditekankan berulang kali oleh pihak resmi—"model paling jujur dari Anthropic hingga saat ini". Dalam pengujian internal, Opus 4.8 mengurangi kemungkinan cacat kode yang terlewatkan sekitar 4 kali lipat dibandingkan 4.7, dan secara signifikan menurunkan tingkat terjadinya "perilaku tidak selaras" (misaligned behavior). Ini sangat penting bagi Agent yang berjalan secara otonom dalam waktu lama: model lebih bersedia melaporkan ketidakpastian secara proaktif, daripada menutupi masalah dengan output yang tampak lancar.
🎯 Saran Pemilihan: Jika skenario aplikasi Anda melibatkan pemanggilan alat multi-putaran, orkestrasi Agent, atau tugas kode dengan jendela konteks panjang, kami sarankan untuk langsung meningkatkan model dasar ke
claude-opus-4-8. Anda dapat menyelesaikannya dengan cepat melalui platform APIYI apiyi.com, yang mendukung protokol kompatibel OpenAI, cukup dengan mengganti kolommodel.
Perbedaan Utama Claude Opus 4.8 dan 4.7
Tabel di bawah ini merangkum perbedaan inti yang diungkapkan secara resmi, agar Anda dapat melihat besarnya peningkatan dengan sekilas:
| Dimensi | Claude Opus 4.7 | Claude Opus 4.8 | Tingkat Peningkatan |
|---|---|---|---|
| SWE-Bench Pro (Pengodean Agen) | 64,3% | 69,2% | +4,9pp |
| Penalaran Multidisiplin (termasuk alat) | 54,7% | 57,9% | +3,2pp |
| OSWorld-Verified (Penggunaan Komputer) | 82,8% | 83,4% | +0,6pp |
| Skor Komprehensif Pekerjaan Pengetahuan | 1753 | 1890 | +7,8% |
| Agen Analisis Keuangan | 51,5% | 53,9% | +2,4pp |
| Harga Fast Mode | Harga dasar 6× | Harga dasar 3× | Diskon 50% |
| Tingkat Cacat Kode yang Terlewat | 1× | 0,25× | Turun 4 kali lipat |
Dapat dilihat bahwa peningkatan Opus 4.8 bukanlah terobosan satu titik, melainkan perbaikan di seluruh dimensi, di mana peningkatan 4,9 poin persentase pada SWE-Bench Pro merupakan kemajuan yang signifikan dalam tolok ukur pemrograman.
Analisis Peningkatan Kemampuan Pemrograman Claude Opus 4.8
Peningkatan kemampuan pemrograman pada Opus 4.8 berfokus pada tiga aspek: skor benchmark, migrasi repositori nyata, dan kredibilitas tinjauan kode. Ketiga aspek ini digabungkan untuk menjelaskan mengapa Anthropic berani memposisikannya sebagai "agen pengodean tingkat produksi".
Benchmark: Mencetak Rekor di SWE-Bench Pro
SWE-Bench Pro adalah salah satu benchmark pengodean agen yang paling ketat saat ini, yang mengharuskan model untuk menyelesaikan perbaikan kode dari awal hingga akhir pada issue repositori open-source nyata dan lulus pengujian. Opus 4.8 mencapai 69,2% dalam pengujian ini, dengan perbandingan data sebagai berikut:
| Model | Skor SWE-Bench Pro | Catatan |
|---|---|---|
| Claude Opus 4.8 | 69,2% | Skor publik tertinggi saat ini |
| Claude Opus 4.7 | 64,3% | Flagship generasi sebelumnya |
| GPT-5.5 | 58,6% | Pembanding dari OpenAI |
| Claude Opus 4.5 | Sekitar 60% | Dirilis setengah tahun lalu |
Perlu dicatat bahwa Anthropic juga merilis hasil benchmark Super-Agent—Opus 4.8 adalah satu-satunya model yang mampu menyelesaikan seluruh kasus uji dari awal hingga akhir, dan tetap unggul meskipun biayanya setara dengan GPT-5.5. Ini berarti dengan anggaran yang sama, Opus 4.8 bekerja lebih akurat dan lebih komprehensif.
Repositori Nyata: Mampu Menangani Migrasi Tingkat Basis Kode
Opus 4.8 yang dipadukan dengan Claude Code kini mampu menangani seluruh proses "migrasi basis kode ratusan ribu baris" mulai dari inisiasi hingga penggabungan (merge), dengan menggunakan rangkaian pengujian yang ada sebagai tolok ukur penerimaan. Kemampuan ini sebelumnya lebih banyak berada di skenario demonstrasi, namun versi 4.8 membawanya ke praktik rekayasa yang dapat diimplementasikan.
Performa spesifiknya meliputi:
- Memahami hubungan dependensi lintas banyak file, membuat rencana sebelum melakukan pengeditan
- Secara proaktif menambahkan kasus uji dalam PR, bukan hanya mengubah kode bisnis
- Secara otomatis menemukan titik regresi saat pengujian gagal, bukan sekadar melakukan rollback
- Mempertahankan memori tentang konteks dan kesepakatan tim dalam sesi yang panjang
Pemeriksaan Mandiri Kode: Penurunan 4 Kali Lipat pada Celah Cacat
Pengujian resmi menunjukkan bahwa Opus 4.8 mengurangi kemungkinan cacat kode yang tidak terdeteksi hingga 4 kali lipat dibandingkan versi 4.7. Bagi tim perusahaan, ini berarti setelah menulis kode, agen lebih mungkin untuk secara proaktif mengatakan "Di sini saya menggunakan implementasi placeholder" atau "Fungsi ini belum menangani kondisi batas", alih-alih memberikan kode yang tidak sempurna sebagai hasil yang "selesai".
🎯 Saran Produksi: Dalam alur CI/CD, kami merekomendasikan penggunaan Opus 4.8 sebagai model dasar untuk Code Review Agent, yang dapat secara signifikan mengurangi kesalahan penilaian dan kelalaian. Saat memanggil melalui platform APIYI apiyi.com, Anda dapat menggabungkannya dengan system prompt untuk secara eksplisit meminta model "menandai semua TODO dan poin yang tidak pasti" guna meningkatkan keandalan tinjauan.
5 Terobosan Kemampuan Agen Claude Opus 4.8
Jika peningkatan pemrograman adalah "peningkatan eksplisit" dari Opus 4.8, maka optimalisasi kemampuan agen adalah perbedaan yang sebenarnya. Anthropic merangkum arah pengembangannya dalam tiga hal: mencari jalur alternatif saat menemui hambatan alih-alih terjebak, pulih dari kesalahan sendiri, dan mengetahui kapan harus meminta bantuan serta kapan harus melanjutkan. Ketiga poin ini mencakup 5 peningkatan spesifik.
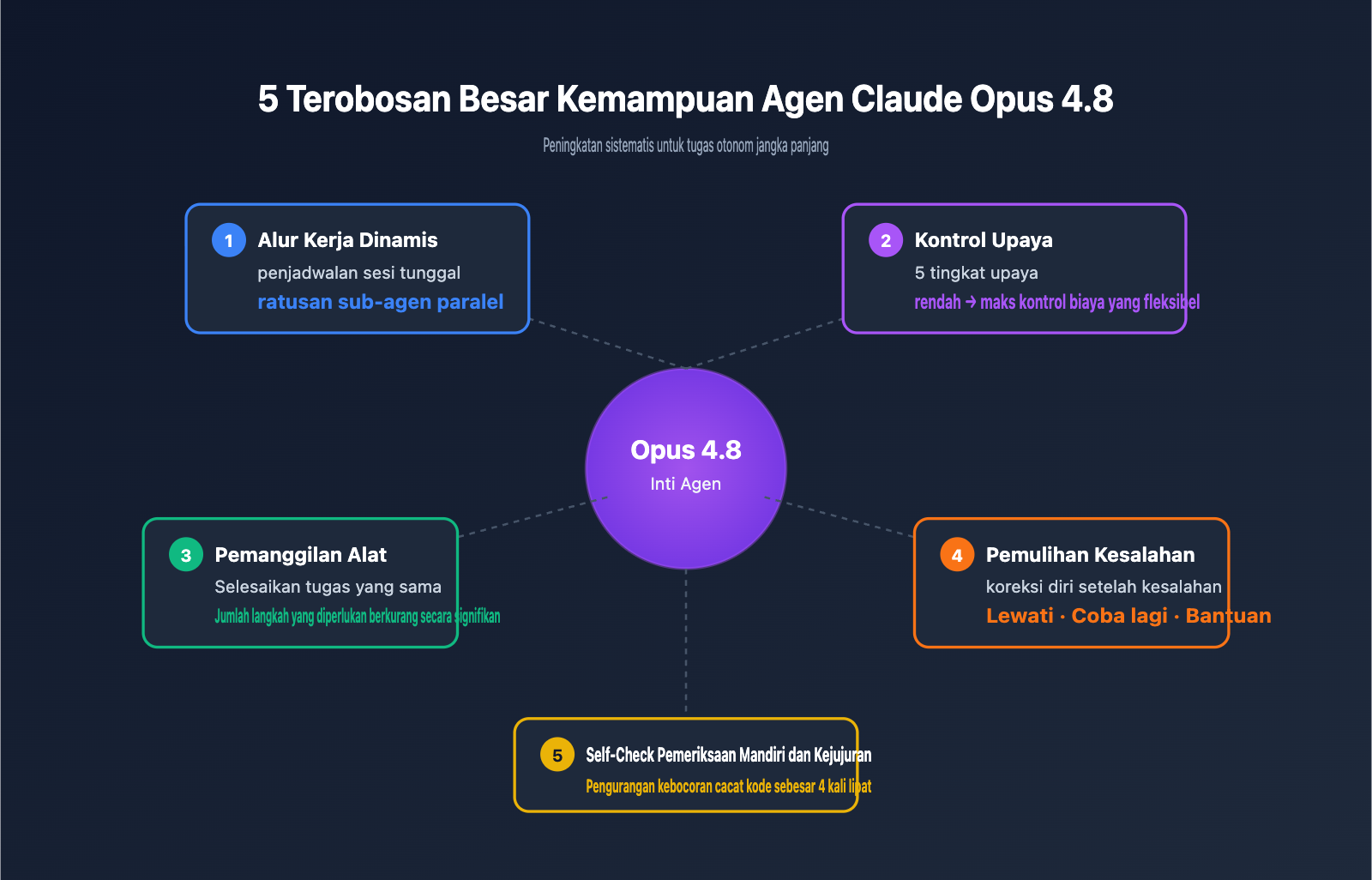
Terobosan 1: Alur Kerja Dinamis (Dynamic Workflows) dengan Sub-Agen Paralel
Ini adalah fitur baru Claude Code yang diluncurkan bersamaan dengan rilis Opus 4.8, saat ini tersedia sebagai pratinjau penelitian bagi pengguna paket Enterprise, Team, dan Max. Claude dapat merencanakan tugas, kemudian menjalankan ratusan sub-agen paralel dalam satu sesi, dan akhirnya memvalidasi serta merangkum output oleh agen utama.
Nilai inti dari Dynamic Workflows adalah mengubah "pemecahan tugas besar" dari penjadwalan manual menjadi penjadwalan mandiri oleh model. Pengembang hanya perlu mendeskripsikan tujuan, dan model secara otomatis memutuskan berapa banyak sub-tugas yang akan dipecah, berapa lama setiap sub-tugas berjalan, dan kapan harus menggabungkan hasilnya. Kemampuan ini, dipadukan dengan durasi runtime otonom Opus 4.8 yang lebih lama, membuat tugas-tugas seperti "refactoring seluruh repositori" atau "audit lintas modul" yang sebelumnya sulit diotomatisasi menjadi dapat dieksekusi.
Terobosan 2: Tingkat Upaya Terkendali (Effort Control)
Opus 4.8 memperkenalkan tingkat upaya extra dan max baru dalam Claude Code, di mana pengembang dapat secara eksplisit mengontrol berapa banyak token dan waktu berpikir yang diinvestasikan model dalam satu tugas. Secara default, tugas pengodean akan mengaktifkan upaya tinggi (high effort) untuk memastikan kualitas, dan dapat dialihkan secara manual ke max jika diperlukan akurasi yang lebih tinggi.
| Tingkat Upaya | Skenario Penggunaan | Konsumsi Token | Skenario yang Direkomendasikan |
|---|---|---|---|
| low | Tanya jawab sederhana, konversi format | Rendah | FAQ layanan pelanggan, penyuntingan teks |
| medium | Pembuatan kode umum, penulisan dokumen | Sedang | Pemanggilan API rutin |
| high | Pengodean agen, penalaran multi-langkah (default) | Tinggi | Pemrograman Claude Code |
| extra | Refactoring repositori kompleks | Lebih Tinggi | Migrasi lintas modul |
| max | Tugas yang sangat kompleks | Tertinggi | Audit seluruh repositori |
Mekanisme ini memungkinkan tim untuk mengalokasikan daya komputasi secara dinamis berdasarkan nilai tugas—tugas sederhana menghemat biaya, tugas penting mendapatkan hasil yang sepadan.
Terobosan 3: Peningkatan Efisiensi Pemanggilan Alat
Opus 4.8 menunjukkan efisiensi yang lebih tinggi dalam benchmark pemanggilan alat internal: jumlah langkah yang diperlukan untuk menyelesaikan tugas yang sama berkurang, dan lebih jarang terjadi "pemanggilan alat yang salah" atau "pemanggilan berulang". Untuk agen jangka panjang, latensi dan biaya setiap pemanggilan alat akan terakumulasi, dan optimalisasi 4.8 pada poin ini secara langsung mempersingkat durasi tugas dari awal hingga akhir.
Terobosan 4: Pemulihan Kesalahan dan Koreksi Mandiri
Versi baru ini telah dilatih secara khusus tentang "bagaimana cara melanjutkan setelah menemui kesalahan". Saat menghadapi kegagalan API, pengecualian pengembalian alat, atau ketidakkonsistenan status lingkungan, Opus 4.8 lebih cenderung untuk:
- Menganalisis akar penyebab kesalahan alih-alih mencoba ulang secara langsung
- Mencoba jalur alternatif untuk melewati hambatan
- Melaporkan dan meminta intervensi manusia jika memang tidak dapat dilanjutkan
- Menyimpan status perantara agar dapat dipulihkan di kemudian hari
Terobosan 5: Injeksi mid-task tingkat sistem baru pada Messages API
Peningkatan Messages API yang menyertai Opus 4.8 memungkinkan penyisipan entri tipe sistem ke dalam array messages, sehingga perintah sistem baru dapat dikirimkan di tengah eksekusi tugas tanpa merusak prompt caching. Ini adalah peningkatan penting untuk orkestrasi agen: sebelumnya, mengubah strategi di tengah jalan sering kali berarti cache tidak valid dan biaya melonjak, namun sekarang transisi dapat dilakukan dengan lancar.
🎯 Saran Akses: Jika Anda sedang membangun sistem orkestrasi multi-agen, kami merekomendasikan untuk memanggil Opus 4.8 melalui platform APIYI apiyi.com agar dapat menikmati fitur baru Messages API secara bersamaan. Platform ini telah menyelesaikan sinkronisasi sumber daya AWS resmi dan memiliki kemampuan yang sepenuhnya identik dengan versi resmi Anthropic.
Panorama Data Pengujian Claude Opus 4.8
Untuk memudahkan pembaca dalam menilai nilai peningkatan model ini, tabel berikut merangkum performa Opus 4.8 pada tolok ukur utama, dibandingkan dengan 4.7 dan GPT-5.5:
| Dimensi Tolok Ukur | Opus 4.8 | Opus 4.7 | GPT-5.5 | Penjelasan Evaluasi |
|---|---|---|---|---|
| SWE-Bench Pro | 69,2% | 64,3% | 58,6% | Perbaikan issue repositori open-source nyata |
| OSWorld-Verified | 83,4% | 82,3% (revisi) | Sekitar 80% | Penggunaan komputer lingkungan desktop |
| Online-Mind2Web | 84% | Belum diumumkan | Belum diumumkan | Agen browser end-to-end |
| Penalaran Multidisiplin (Alat) | 57,9% | 54,7% | Sekitar 56% | Gaya Tau-Bench |
| Pekerjaan Pengetahuan Komprehensif | 1890 | 1753 | Tidak dibandingkan langsung | Skor komprehensif internal Anthropic |
| Agen Analisis Keuangan | 53,9% | 51,5% | Sekitar 50% | Finance Agent v2 |
| Tolok Ukur Agen Hukum | >10% (all-pass) | <10% | <10% | Ambang batas kelulusan penuh pertama kali tembus 10% |
Perlu dicatat bahwa Anthropic kali ini memperbarui metode evaluasi OSWorld-Verified agar lebih mendekati skenario nyata, dan secara sinkron menghitung ulang skor revisi Opus 4.7 (82,3%). Oleh karena itu, angka 83,4% pada 4.8 merupakan peningkatan nyata di bawah metodologi yang sama, bukan hasil yang melambung karena perubahan standar evaluasi.
Fitur Baru Claude Opus 4.8: Dynamic Workflows dan Effort Control
Opus 4.8 bukan sekadar peningkatan bobot model, tetapi juga menghadirkan kemampuan rekayasa pendukung secara bersamaan. Dua fitur yang paling patut diperhatikan adalah: Dynamic Workflows dan penurunan harga Fast Mode.
Dynamic Workflows: Dari Agen Tunggal ke Klaster Agen
Masalah inti yang diselesaikan oleh Dynamic Workflows adalah "jendela konteks model tunggal tidak cukup untuk menampung tugas rekayasa yang lengkap". Pendekatan sebelumnya mengharuskan pemecahan tugas secara manual dan eksekusi serial, di mana efisiensi dibatasi oleh kemampuan pengaturan manusia. Opus 4.8 memungkinkan model itu sendiri memiliki kemampuan penjadwalan rantai penuh "perencanaan—distribusi—penggabungan—verifikasi", yang dapat memicu ratusan sub-agen paralel dalam satu sesi.
Skenario yang cocok untuk Dynamic Workflows meliputi:
- Migrasi kode seluruh repositori (seperti Vue 2 ke Vue 3)
- Pemilahan dokumen skala besar dan ekstraksi pengetahuan
- Verifikasi silang data multi-sumber dan pembuatan laporan
- Investigasi Bug lintas layanan dan pembuatan PR perbaikan
Fast Mode: Kecepatan dua kali lipat, harga justru turun setengahnya
Kecepatan pengujian Fast Mode pada Opus 4.8 sekitar 2,5 kali lebih cepat dari generasi sebelumnya, namun harganya turun dari 6 kali menjadi 3 kali lipat dari harga dasar. Ini berarti biaya per token berkurang 50% sambil tetap mempertahankan throughput yang tinggi. Hal ini sangat menguntungkan bagi skenario yang membutuhkan respons cepat namun tidak bisa mengorbankan kecerdasan tingkat Opus (seperti asisten pemrograman real-time, agen interaktif).
| Mode | Harga Input (per juta token) | Harga Output (per juta token) | Kecepatan |
|---|---|---|---|
| Opus 4.8 Standar | $5 | $25 | Dasar |
| Opus 4.8 Fast Mode | $10 | $50 | Sekitar 2,5× |
| Opus 4.7 Fast Mode (Historis) | $30 | $150 | Sekitar 2,5× |
Dapat dilihat bahwa harga Fast Mode 4.8 hanya sepertiga dari Fast Mode 4.7, yang merupakan penyesuaian struktur biaya paling signifikan sejak dirilis.
🎯 Saran Optimasi Biaya: Untuk skenario real-time dengan konkurensi tinggi, disarankan untuk memprioritaskan Fast Mode; untuk tugas batch offline, mode standar memiliki efektivitas biaya yang lebih baik. Kami merekomendasikan untuk melakukan pengujian aktual melalui platform APIYI apiyi.com, yang mendukung peralihan mode sesuai kebutuhan, sehingga memudahkan perbandingan biaya sebelum masuk ke tahap produksi.
Analisis Kelebihan dan Kekurangan Claude Opus 4.8
Setiap model memiliki batasan penerapannya, dan Opus 4.8 tidak terkecuali. Berdasarkan data resmi dan umpan balik awal dari pengembang, berikut adalah ringkasan kelebihan dan kekurangannya:
Kelebihan
- Rekor tolok ukur pemrograman: Mencapai 69,2% pada SWE-Bench Pro, angka tertinggi yang dipublikasikan saat ini.
- Kemampuan Agen jangka panjang yang menonjol: Penjadwalan ratusan sub-agen paralel yang matang.
- Peningkatan swa-uji kode yang signifikan: Penurunan tingkat kegagalan deteksi cacat hingga 4 kali lipat.
- Strategi harga yang ramah: Harga standar setara dengan 4.7, dengan penurunan harga 50% untuk Fast Mode.
- Dukungan penuh AWS: Tersedia secara bersamaan di Bedrock dan Platform Claude.
- Kompatibilitas API yang baik: Peningkatan mulus pada Messages API, prompt cache tetap berfungsi.
Keterbatasan
- Tekanan biaya untuk kecerdasan tingkat atas: Harga output $25/M token masih tergolong tinggi bagi tim kecil.
- Dynamic Workflows terbatas pada paket premium: Hanya tersedia untuk paket Enterprise/Team/Max.
- Hasil sangat sensitif terhadap kualitas petunjuk: Petunjuk yang kasar sulit mengeluarkan potensi maksimal model.
- Jendela konteks belum diperluas secara resmi: Tugas repositori besar masih bergantung pada pemecahan oleh sub-agen.
Skenario yang Direkomendasikan
| Skenario Penggunaan | Tingkat Rekomendasi | Alasan |
|---|---|---|
| Agen Peninjauan Kode | ⭐⭐⭐⭐⭐ | Kemampuan swa-uji meningkat 4 kali lipat |
| Migrasi kode seluruh repositori | ⭐⭐⭐⭐⭐ | Didukung oleh Dynamic Workflows |
| Orkestrasi Agen multi-langkah | ⭐⭐⭐⭐⭐ | Efisiensi pemanggilan alat dioptimalkan secara signifikan |
| Asisten pemrograman real-time | ⭐⭐⭐⭐ | Rasio harga-performa Fast Mode yang unggul |
| Pembuatan teks sederhana | ⭐⭐ | Lebih ekonomis menggunakan Haiku/Sonnet |
| Pembuatan gambar/video | — | Di luar cakupan kemampuan model ini |
Cara Memanggil Claude Opus 4.8 melalui APIYI
Sebagai saluran sumber daya AWS Claude resmi, APIYI telah menyelesaikan sinkronisasi Opus 4.8 pada tanggal 29 Mei. Pengembang tidak perlu mengajukan akun AWS atau mengonfigurasi izin IAM untuk dapat langsung memanggilnya melalui protokol yang kompatibel dengan OpenAI.
Contoh Pemanggilan Sederhana (Python)
from openai import OpenAI
client = OpenAI(
api_key="Kunci APIYI Anda",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-8",
messages=[
{"role": "user", "content": "Implementasikan quicksort dengan Python, dan jelaskan langkah-langkah kuncinya"}
]
)
print(response.choices[0].message.content)
Mengaktifkan Fast Mode
response = client.chat.completions.create(
model="claude-opus-4-8-fast", # Beralih ke Fast Mode
messages=[
{"role": "user", "content": "Jawab pertanyaan kode pengguna secara real-time"}
],
stream=True
)
Seluruh proses migrasi biasanya hanya memerlukan penggantian kolom model, kode SDK OpenAI yang sudah ada dapat langsung digunakan kembali tanpa perlu menulis ulang logika klien.
🎯 Saran Akses: Melalui platform APIYI apiyi.com, Anda dapat memanggil Claude Opus 4.8 untuk menikmati stabilitas sumber daya AWS resmi sekaligus menghemat biaya operasional akses AWS Bedrock mandiri. Platform ini telah menyelesaikan sinkronisasi untuk semua model, termasuk versi utama seperti Opus 4.8, Sonnet 4.6, dan Haiku 4.5.
FAQ Claude Opus 4.8
Apa perbedaan utama antara Opus 4.8 dan Opus 4.7?
Opus 4.8 mencatatkan peningkatan sebesar 4,9 poin persentase pada SWE-Bench Pro menjadi 69,2%, menambahkan kemampuan sub-agent paralel melalui Dynamic Workflows, menurunkan harga Fast Mode sebesar 50%, serta menekan tingkat false negative cacat kode hingga sekitar 4 kali lipat. Fokus keseluruhannya bergeser dari "model tujuan umum yang kuat" menjadi "agen otonom jangka panjang tingkat produksi".
Apakah harga Claude Opus 4.8 lebih mahal dibandingkan 4.7?
Harga untuk mode standar tetap sama dengan 4.7, yaitu $5/M token untuk input dan $25/M token untuk output. Sebaliknya, harga Fast Mode turun dari 6 kali harga dasar menjadi 3 kali, yang berarti biaya per unit turun sebesar 50%. Ini adalah langkah optimalisasi biaya paling signifikan dari Anthropic belakangan ini.
Bagaimana cara memanggil Opus 4.8 di AWS?
AWS menyediakan dua jalur resmi: Amazon Bedrock (termasuk Guardrails, Knowledge Bases, dan residensi data regional) serta Claude Platform on AWS (penagihan terpadu, kemampuan asli Anthropic). Jika Anda tidak ingin terhubung langsung dengan AWS, Anda dapat memanggilnya melalui platform APIYI (apiyi.com) yang telah menyinkronkan sumber daya resmi.
Apakah pengguna biasa bisa menggunakan Dynamic Workflows?
Saat ini, Dynamic Workflows masih dalam tahap pratinjau riset dan hanya dibuka untuk paket Enterprise, Team, dan Max di Claude Code. Saat memanggil Opus 4.8 di tingkat API, fitur ini tidak diwajibkan, sehingga pengembang biasa tetap dapat menggunakan semua kemampuan baru lainnya di tingkat model.
Apakah Opus 4.8 cocok menggantikan Sonnet untuk tugas sehari-hari?
Belum tentu. Untuk skenario seperti pembuatan teks sehari-hari, FAQ layanan pelanggan, atau output terformat, Sonnet 4.6 atau Haiku 4.5 menawarkan efisiensi biaya yang lebih baik. Nilai utama Opus 4.8 terletak pada skenario yang membutuhkan kecerdasan tingkat tinggi, seperti pengodean berbasis agen, tugas jangka panjang, dan pemanggilan alat yang kompleks.
Bagaimana cara menilai apakah layak beralih dari 4.7 ke 4.8?
Anda bisa menilainya dari tiga dimensi: apakah Anda melakukan pengodean berbasis agen (jika ya, sangat disarankan untuk beralih), apakah Anda membangun sistem multi-agen (jika ya, peningkatan ini memberikan bonus efisiensi pemanggilan alat), dan apakah Anda sensitif terhadap kualitas kode (jika ya, penurunan tingkat false negative sebesar 4 kali lipat sangat layak untuk beralih). Disarankan untuk mencoba di lingkungan pengujian menggunakan platform APIYI selama seminggu sebelum memutuskan untuk beralih sepenuhnya.
Berapa besar jendela konteks Opus 4.8?
Anthropic tidak merilis data jendela konteks secara terpisah dalam peluncuran 4.8, jadi Anda bisa menggunakan spesifikasi 4.7 sebagai garis dasar. Poin pertumbuhan utama Opus 4.8 adalah "bagaimana menjaga konsistensi konteks dengan lebih baik dalam jendela konteks yang sama", bukan perluasan ukuran jendela itu sendiri.
Apa yang harus dilakukan jika pemanggilan gagal?
Disarankan untuk memeriksa apakah kunci API Anda sudah benar dan apakah nama model ditulis sebagai claude-opus-4-8 (perhatikan penggunaan tanda hubung). Jika masih gagal, Anda dapat menghubungi layanan pelanggan APIYI atau merujuk pada dokumentasi pemecahan masalah di help.apiyi.com. Sebagian besar masalah terkait dengan pembatasan kecepatan (rate limit) atau ketersediaan regional.
Poin Utama Claude Opus 4.8
- Rekor SWE-Bench Pro: Skor 69,2% adalah yang tertinggi saat ini, meningkat 4,9 poin persentase dari 4.7.
- Peningkatan Pemeriksaan Kode 4x Lipat: Tingkat false negative cacat kode berkurang drastis, menjadikannya lebih cocok sebagai agen peninjau kode (Code Review Agent).
- Peluncuran Dynamic Workflows: Satu sesi dapat menjadwalkan ratusan sub-agent paralel untuk menangani tugas tingkat basis kode.
- Harga Fast Mode Dipangkas: Turun dari 6x harga dasar menjadi 3x, dengan kecepatan yang tetap terjaga di sekitar 2,5x.
- Dukungan Jalur Ganda AWS: Bedrock dan Claude Platform diluncurkan secara bersamaan, membuat akses perusahaan lebih fleksibel.
- Sinkronisasi APIYI: Sinkronisasi penuh selesai pada 29 Mei, mendukung pemanggilan langsung melalui protokol yang kompatibel dengan OpenAI.
- Peningkatan Tanpa Biaya Tambahan: Harga standar tetap sama dengan 4.7, peningkatan Messages API yang mulus, dan prompt cache tidak akan kedaluwarsa.
Ringkasan
Peluncuran Claude Opus 4.8 menandai kematangan penuh Anthropic dalam pengembangan "agen otonom jangka panjang". Skor 69,2% pada SWE-Bench Pro, penurunan tingkat kesalahan kode sebesar 4 kali lipat, Dynamic Workflows yang mampu menjadwalkan ratusan sub-agen, serta penurunan biaya sebesar 50% pada Fast Mode, secara kolektif membentuk solusi lengkap untuk skenario rekayasa produksi.
Bagi tim yang sudah menggunakan seri Opus, peningkatan ke versi 4.8 hampir tidak memerlukan biaya migrasi; Anda hanya perlu mengganti nama model untuk menikmati semua kemampuan baru tersebut. Bagi tim yang belum menggunakan Opus, peluncuran 4.8 adalah waktu yang tepat untuk melakukan evaluasi ulang, terutama untuk skenario bernilai tinggi seperti pengodean agen (agentic coding), orkestrasi agen, dan tinjauan kode (code review).
🎯 Saran Akhir: Kami merekomendasikan penggunaan Claude Opus 4.8 melalui platform APIYI (apiyi.com). Anda dapat menikmati stabilitas sumber daya AWS Claude yang dialihkan secara resmi, sekaligus menghemat biaya operasional karena tidak perlu membangun akses AWS Bedrock sendiri. Platform kami telah menyelesaikan sinkronisasi penuh pada tanggal 29 Mei, dan dengan protokol yang kompatibel dengan OpenAI, integrasi hanya memakan waktu beberapa menit.
Penulis: Tim Teknis APIYI | Untuk konten pengujian model AI lainnya, silakan kunjungi help.apiyi.com