Banyak tim yang mengintegrasikan API Gemini untuk layanan pengenalan gambar sering kali mengalami kebingungan yang sama: saat mengirim gambar dan petunjuk yang sama di versi web gemini.google.com, model dapat mengenali detail dengan presisi dan memberikan jawaban terstruktur; namun saat beralih ke API gemini-3.5-flash untuk melakukan hal yang sama, hasilnya justru jauh lebih kasar, bahkan melewatkan informasi penting. Perbedaan "web kuat, API lemah" ini bukan berarti modelnya sengaja diperlemah, melainkan karena Anda baru saja melihat kesenjangan antara versi web dan API dari sisi teknis.
Artikel ini berfokus pada satu kesimpulan utama: Gemini versi web adalah sebuah Agent komprehensif yang secara otomatis melakukan optimasi petunjuk, penalaran multi-langkah, pemanggilan alat, dan verifikasi hasil; sementara pemanggilan API adalah model mentah, apa yang Anda berikan adalah apa yang Anda dapatkan. Setelah memahami kesenjangan ini, 6 teknik peningkatan API yang lebih dari sekadar "mengubah petunjuk" akan membuat hasil pengenalan gambar Anda stabil dan setara dengan pengalaman di situs resmi.

Mengapa hasil pengenalan gambar Gemini API tidak sebaik versi web: Kesenjangan antara Agent dan model mentah
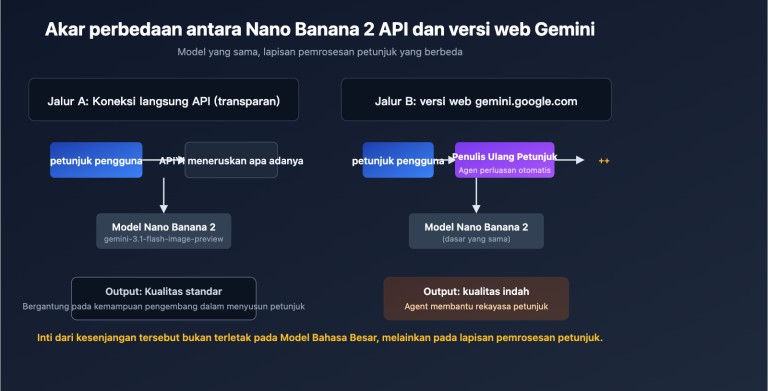
Untuk menjelaskan perbedaan ini, kita harus memahami berapa banyak hal yang dilakukan gemini.google.com untuk Anda sejak Anda mengirimkan gambar hingga mendapatkan jawaban akhir. Berdasarkan dokumentasi Agentic Vision yang dirilis Google dan pengamatan kami di APIYI (apiyi.com) mengenai perbedaan respons antara situs resmi dan API, versi web pada dasarnya adalah sebuah Agent tingkat produk yang dibangun di sekitar model dasar. Ia setidaknya menyelesaikan 5 hal untuk Anda yang tidak Anda minta secara eksplisit:
- Mengubah petunjuk Anda secara otomatis, melengkapinya menjadi instruksi lengkap dengan peran, tugas, dan format output.
- Memproses gambar secara internal dengan resolusi yang lebih tinggi untuk memastikan detail tidak terkompresi menjadi piksel yang kabur.
- Mengaktifkan anggaran penalaran intensitas tinggi secara default (mirip dengan
thinking_level=high), memberikan waktu bagi model untuk "berpikir". - Memanggil alat bawaan seperti eksekusi kode atau pencarian web saat diperlukan untuk melakukan verifikasi silang guna memastikan detail yang akurat dan tepercaya.
- Melakukan pemformatan dan penilaian "jawaban ulang" pada hasil output, jika menemukan jawaban yang ambigu, ia akan bertanya kembali kepada model.
Sementara saat Anda memanggil API secara langsung, 5 hal ini tidak akan terjadi secara otomatis. Dengan kata lain, Anda memanggil "model" dengan kemampuan penuh, tetapi kehilangan seluruh "perancah teknik". Tabel berikut merinci perbedaan antara kedua cara penggunaan ini pada jalur utama:
| Dimensi Perbandingan | Versi Web gemini.google.com | API gemini-3.5-flash |
|---|---|---|
| Pemrosesan Petunjuk | Penulisan ulang otomatis, melengkapi peran & format | Sepenuhnya mengikuti input pengguna |
| Resolusi Gambar | Tingkat tinggi default | Tingkat menengah default, perlu diatur manual |
| Anggaran Penalaran | Intensitas tinggi, tanpa batas eksplisit | Menengah default, bisa diatur via thinking_level |
| Pemanggilan Alat | Akses default ke pencarian, eksekusi kode | Nonaktif default, perlu diaktifkan eksplisit |
| Verifikasi Hasil | Verifikasi multi-langkah Agent | Penalaran tunggal, tanpa verifikasi |
| Transparansi Biaya | Tercakup dalam paket bulanan | Penagihan terpisah per Token |
Kami menyarankan untuk menjalankan gambar dan petunjuk yang sama di gerbang API terpadu seperti APIYI (apiyi.com), lalu membandingkan hasil pengenalan gambar dari API gemini-3.5-flash, Claude Opus, dan GPT-5.5. Dengan cara ini, Anda dapat dengan cepat menentukan apakah tugas saat ini terhambat oleh kemampuan model atau oleh jalur teknisnya.
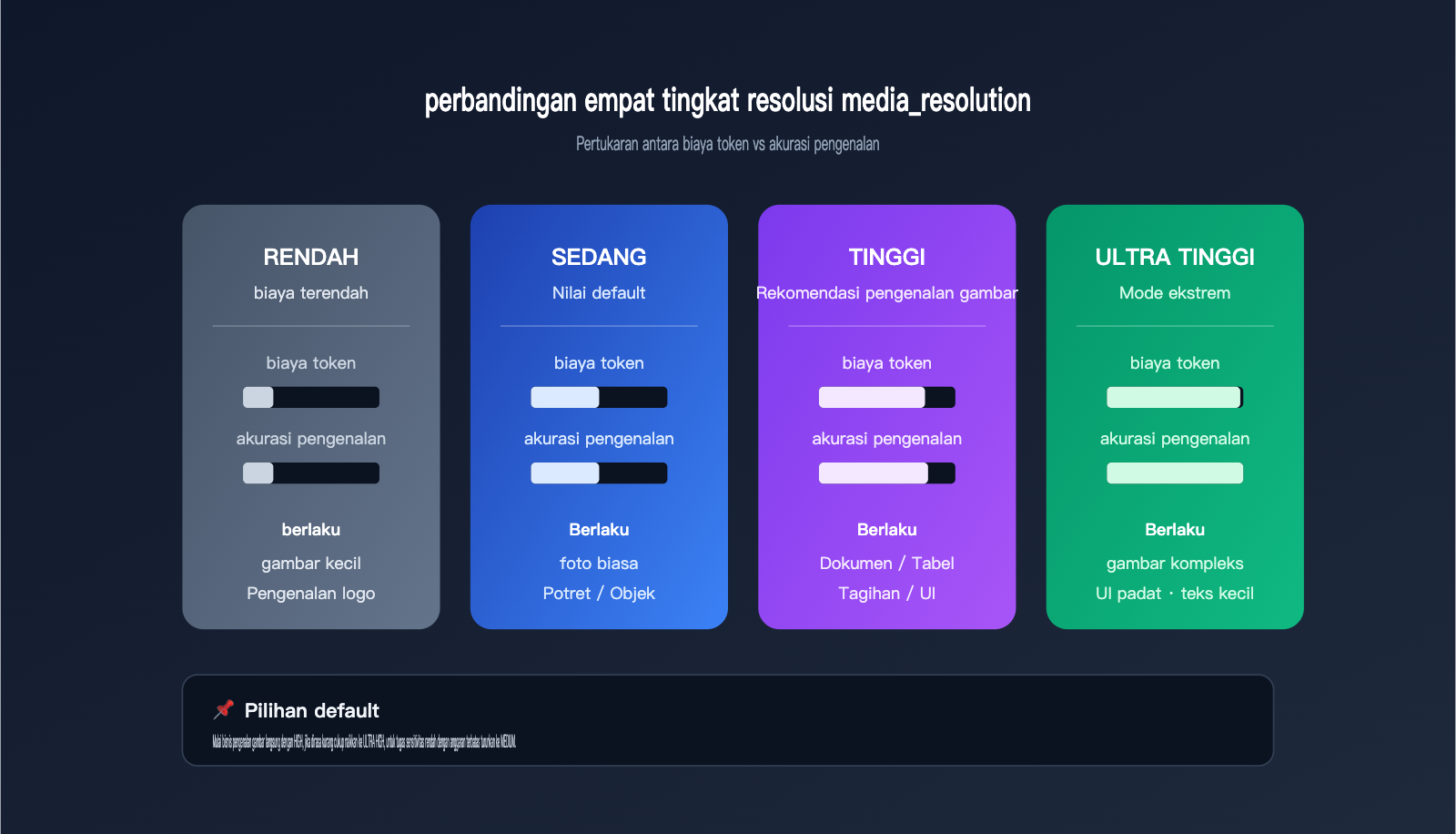
Tips Identifikasi Gambar Gemini API 1: Tingkatkan Parameter media_resolution
Seri Gemini 3 mulai memperkenalkan parameter media_resolution, yang secara langsung mengontrol berapa banyak Token yang dialokasikan API untuk "melihat" gambar. Parameter ini memiliki empat tingkat: low, medium, high, dan ultra high, dengan default biasanya di medium. Untuk gambar dengan detail padat seperti teks kecil, kuitansi, diagram sirkuit, atau tangkapan layar UI, pengaturan medium sering kali tidak cukup. Model akan mengompres gambar menjadi peta fitur yang kasar, sehingga menyebabkan hilangnya detail.
Tabel berikut menunjukkan perbedaan nyata dari keempat tingkat tersebut, agar Anda dapat memilih sesuai dengan jenis tugas:
| Tingkat Resolusi | Penggunaan Token | Skenario yang Cocok | Masalah Umum |
|---|---|---|---|
| low | Paling rendah | Thumbnail, identifikasi Logo | Teks kecil hampir hilang |
| medium (default) | Sedang | Foto biasa, potret | Detail kabur |
| high | Lebih tinggi | Dokumen, tabel, kuitansi | Informasi umumnya terbaca |
| ultra high | Paling tinggi | Diagram kompleks, UI padat | Mendekati hasil situs resmi |
Untuk tugas identifikasi gambar, mengubah parameter ini dari medium ke high biasanya dapat langsung meningkatkan akurasi identifikasi ke tingkat berikutnya. Jika anggaran Anda mencukupi dan tugas tersebut benar-benar melibatkan teks kecil atau tabel padat, memilih ultra high juga merupakan pilihan yang masuk akal.
# Memanggil gemini-3.5-flash melalui APIYI, secara eksplisit menentukan resolusi media high
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Ekstrak semua teks yang terlihat di gambar dan keluarkan dalam bentuk tabel"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
Saat melakukan panggilan melalui APIYI (apiyi.com), parameter diteruskan langsung ke lapisan bawah tanpa dikemas ulang oleh gateway, sehingga Anda dapat dengan aman mengirimkan nilai sesuai dokumentasi resmi.
Tips Identifikasi Gambar Gemini API 2: Aktifkan Secara Eksplisit thinking_level=high
Gemini 3.5 Flash memperkenalkan parameter thinking_level, yang mengontrol kedalaman penalaran internal model sebelum menghasilkan jawaban. Dalam tugas identifikasi gambar, "berpikir cukup lama" dan "berpikir cukup teliti" sering kali menjadi pembeda antara melihat detail dengan jelas atau salah melihat. Tingkat default API cenderung mengutamakan kecepatan daripada kualitas. Untuk tugas identifikasi gambar, disarankan untuk mengaturnya secara aktif ke high, agar model memiliki cukup waktu untuk melakukan penalaran spasial dan penghitungan seperti pada versi web.
| thinking_level | Skenario yang Disarankan | Perbedaan yang Terasa |
|---|---|---|
| low | Percakapan sederhana, penilaian gaya | Cepat, identifikasi kasar |
| medium | Tanya jawab umum | Tingkat rata-rata |
| high (disarankan) | Dokumen, kuitansi, penghitungan, penalaran spasial | Mendekati pengalaman situs resmi |
Dokumentasi resmi juga menekankan poin yang berlawanan dengan intuisi: setelah menggunakan thinking_level=high, Anda justru harus menulis petunjuk yang lebih langsung dan ringkas, hindari taktik chain-of-thought gaya lama seperti "tolong pikirkan langkah demi langkah, tolong pertimbangkan berbagai situasi". Taktik ini ditujukan untuk menambah kemampuan model lama, bagi seri Gemini 3, hal ini justru membuatnya "terlalu banyak menganalisis".
🎯 Saran Pemilihan Parameter: Jadikan
media_resolution=HIGHdanthinking_level=highsebagai kombinasi default untuk tugas identifikasi gambar, dan tuliskan ke dalam templat panggilan di sisi APIYI (apiyi.com). Selanjutnya, lakukan penyesuaian mikro ke arah ultra high atau low berdasarkan pengalaman bisnis, untuk menghindari pengujian parameter berulang kali di setiap permintaan.
Tips Gemini API untuk Pengenalan Gambar 3: Masukkan instruksi ke dalam system_instruction, bukan user prompt
Kesalahan umum lainnya saat menggunakan API adalah memasukkan segalanya ke dalam user prompt: pengaturan peran, penjelasan tugas, format output, dan pertanyaan pengguna semuanya dicampur dalam satu teks. Cara penulisan seperti ini membuat model harus membaca ulang seluruh konteks setiap saat, padahal "petunjuk sistem" di versi web sudah di-cache dan digunakan kembali.
Cara yang benar adalah dengan memasukkan "instruksi tetap Anda" ke dalam system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Anda adalah asisten analisis gambar yang teliti."
"Saat menjawab, hanya kutip detail yang terlihat jelas di dalam gambar, jangan membuat asumsi."
"Output harus berupa JSON terstruktur, dengan kolom tetap: entities/attributes/text."
)
)
Ada dua keuntungan dari cara ini: model menjawab dengan aturan yang konsisten sehingga hasilnya lebih stabil; dan setelah System Prompt Caching diaktifkan, biaya input bisa turun hingga 10 kali lipat, yang sangat berharga untuk bisnis pengenalan gambar yang berjalan dalam skala besar. Di dasbor APIYI (apiyi.com), Anda dapat melihat tingkat cache hit per ID model untuk memantau efektivitas optimasi dengan mudah.
Tips Gemini API untuk Pengenalan Gambar 4: Aktifkan eksekusi kode agar model bisa "memperbesar gambar"
Dalam pengumuman Agentic Vision untuk Gemini 3 Flash, Google memberikan data yang jelas: dengan mengaktifkan alat eksekusi kode pada model dasar, tugas pengenalan gambar rata-rata bisa mendapatkan peningkatan kualitas sebesar 5%~10%. Prinsipnya adalah model dapat menghasilkan kode Python secara internal untuk melakukan pemotongan (cropping), pembesaran (zooming), rotasi, atau pembacaan piksel pada gambar, lalu memberikan sub-gambar yang telah diproses tersebut kembali kepada dirinya sendiri untuk dianalisis. Inilah yang dilakukan secara default pada versi web.
API tidak mengaktifkan eksekusi kode secara default, jadi Anda perlu mendeklarasikannya secara eksplisit:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Hitung jumlah semua tombol merah di gambar dan sebutkan lokasinya"],
config=config
)
Untuk tugas-tugas seperti penghitungan, penalaran spasial, dan analisis UI padat yang secara resmi diakui sebagai "poin plus eksekusi kode", ini adalah optimasi dengan rasio harga-performa terbaik. Berdasarkan pengamatan kami di APIYI (apiyi.com), latensi keseluruhan akan sedikit meningkat setelah eksekusi kode diaktifkan. Oleh karena itu, disarankan untuk mengaktifkannya secara default pada proses asinkron, dan mengaktifkannya sesuai kebutuhan pada proses sinkron.
Tips Pengenalan Gambar Gemini API 5: Gunakan File API untuk Gambar Besar, Bukan Inline Base64
Untuk gambar dengan ukuran lebih dari beberapa MB, banyak tim langsung menyematkan gambar ke dalam badan permintaan menggunakan base64. Cara ini memang oke untuk gambar kecil, tetapi ketika total ukuran permintaan melebihi 20MB, batasan Gemini akan terpicu. Akibatnya, sebagian gambar akan dikompresi secara diam-diam, yang tentu saja menurunkan kualitas pengenalan.
Batas ketentuan yang diberikan secara resmi cukup jelas:
| Ukuran Gambar | Metode Transmisi yang Disarankan | Alasan |
|---|---|---|
| Kurang dari 5MB | Inline base64 | Permintaan ringan, pemanggilan mudah |
| 5~20MB | Unggah File API | Mencegah pembengkakan ukuran permintaan |
| Lebih dari 20MB | Wajib File API | Pengodean base64 akan merusak permintaan |
| Penggunaan berulang | Disarankan File API | Unggah sekali, referensi berkali-kali, hemat Token |
Keuntungan lain dari File API adalah gambar yang sama dapat digunakan kembali dalam beberapa permintaan, sehingga menghemat biaya unggah berulang. Setelah melewati gateway APIYI (apiyi.com), endpoint File API menggunakan kumpulan kredensial yang sama, sehingga Anda tidak perlu membuat akun Google Cloud terpisah hanya untuk mengunggah gambar.
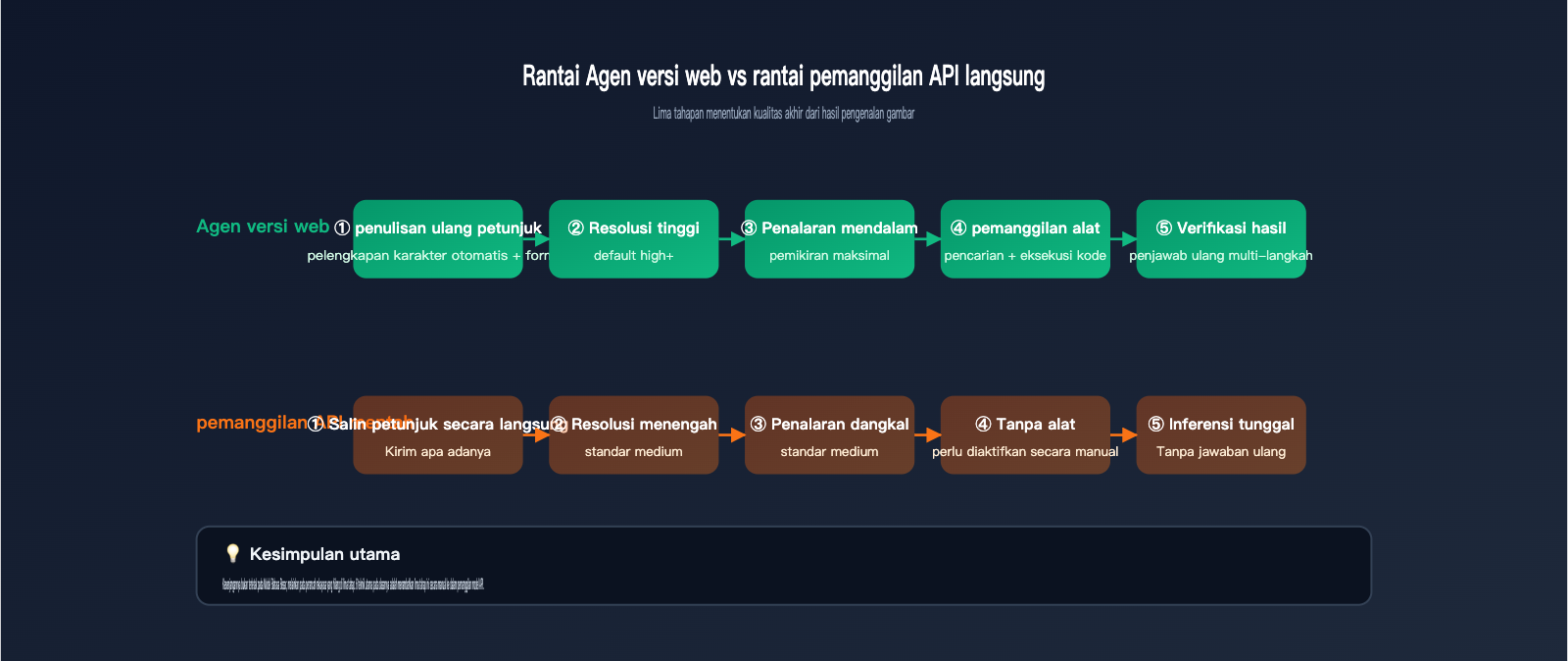
Tips Identifikasi Gambar Gemini API #6: Membangun Rantai Agen untuk Verifikasi Multi-Langkah
Setelah menyelesaikan 5 tips sebelumnya, pemanggilan API Anda sudah mendekati pengalaman penggunaan di situs web resmi. Namun, versi web memiliki satu senjata rahasia: verifikasi multi-langkah. Fitur ini melakukan verifikasi fakta kunci dengan penalaran kedua setelah jawaban dihasilkan, dan akan melakukan "penulisan ulang" jika menemukan jawaban yang tidak pasti. Kemampuan ini tidak tersedia secara instan di API, jadi Anda perlu membangun rantai Agen sederhana sendiri.
Rantai dua langkah minimal yang bisa digunakan adalah:
- Pemanggilan pertama: Minta
gemini-3.5-flashmenghasilkan hasil identifikasi terstruktur (output JSON). - Pemanggilan kedua: Masukkan hasil pertama bersama gambar asli, lalu tanya model, "Berdasarkan gambar ini, apakah setiap kesimpulan berikut benar?"
Jika pemanggilan kedua menemukan kolom yang "tidak benar", picu langkah ketiga untuk "menulis ulang". Rantai ini dapat langsung dijalankan di APIYI (apiyi.com) dengan menggunakan base_url dan kunci API yang sama tanpa memerlukan layanan tambahan. Untuk bisnis yang membutuhkan akurasi tinggi (identifikasi kontrak, anotasi bantuan pencitraan medis, tinjauan kepatuhan keamanan), verifikasi multi-langkah adalah langkah kunci untuk meningkatkan akurasi dari 90% menjadi 98%.
| Jenis Tugas | Rantai yang Disarankan | Parameter Langkah Tunggal |
|---|---|---|
| Tanya Jawab Identifikasi Umum | Langkah tunggal | high + thinking_high |
| Ekstraksi Dokumen | Langkah tunggal + validasi JSON | ultra high + thinking_high |
| Penghitungan Kompleks | Dua langkah + eksekusi kode | high + thinking_high + tools |
| Bisnis Akurasi Tinggi | Rantai tiga langkah (Identifikasi → Validasi → Ulang) | ultra high + thinking_high + tools |
Templat Parameter Praktis: Menggabungkan 6 Tips Menjadi Satu Pemanggilan yang Dapat Digunakan Kembali
Agar Anda dapat langsung menggunakannya, berikut adalah "templat default tugas identifikasi gambar" yang telah menggabungkan 6 tips sebelumnya, cocok sebagai titik awal untuk sebagian besar bisnis:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Anda adalah asisten analisis gambar yang teliti. Hanya kutip konten yang terlihat jelas dalam gambar, "
"jangan membuat kesimpulan tanpa dasar. Output harus berupa JSON ketat, dengan kolom entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Identifikasi gambar ini sesuai dengan persyaratan SYSTEM"],
config=config
)
print(resp.text)
Saat melakukan deployment, disarankan untuk mengekstrak templat menjadi lapisan pemanggilan SDK terpadu di sisi APIYI (apiyi.com). Pihak bisnis hanya perlu mengirimkan gambar dan pertanyaan, sementara parameter disuntikkan secara terpadu oleh gateway untuk menghindari kesalahan berulang di setiap unit bisnis.

FAQ: Menjawab Perbedaan Kemampuan Pengenalan Gambar Gemini API vs Versi Web
Q1: Apakah API masih akan kalah dari versi web setelah semua parameter ini diaktifkan?
Sebagian besar tugas bisnis bisa menyamai performa situs resmi, namun untuk beberapa tugas dengan tingkat kesulitan tinggi (teks sangat kecil, pencahayaan minim, atau gaya seni khusus), hasilnya mungkin masih sedikit berbeda. Hal ini karena versi web sering kali memanggil pipeline peningkatan internal yang tidak dipublikasikan. Untuk skenario seperti ini, Anda bisa melakukan perbandingan silang dengan model visual dari vendor lain di APIYI (apiyi.com) guna menemukan model kerja yang paling sesuai.
Q2: Apakah thinking_level=high akan melipatgandakan biaya?
Ini akan meningkatkan penggunaan token penalaran internal, namun hanya berdampak pada tahap output. Selain itu, dalam biaya keseluruhan tugas pengenalan gambar, token gambar biasanya memakan porsi yang lebih besar. Peningkatan akurasi yang didapat dari pengaturan thinking ke high jauh lebih berharga dibandingkan biaya tambahan yang dikeluarkan, terutama untuk bisnis yang bertujuan menggantikan proses verifikasi manual.
Q3: Bagaimana cara mengubah base_url? Saya menggunakan SDK resmi Google.
SDK google-genai mendukung pengalihan permintaan ke gateway APIYI (apiyi.com) melalui http_options={"base_url": "https://api.apiyi.com"}. Gunakan kunci API yang dibuat di dasbor APIYI, Anda tidak memerlukan proyek Google Cloud terpisah.
Q4: Apakah masalah bisa diselesaikan hanya dengan mengoptimalkan petunjuk?
Batas maksimal jika hanya mengandalkan petunjuk sangat jelas; cara ini tidak bisa mencakup kemampuan "di luar model" seperti resolusi, kedalaman penalaran, atau pemanggilan alat. Dari 6 tips dalam artikel ini, hanya poin ketiga yang berkaitan dengan petunjuk, sementara 5 poin lainnya adalah pengungkit di level teknis (engineering).
Q5: Bagaimana jika API sering melewatkan "tanda air teks" pada gambar yang bisa dikenali oleh versi web?
Detail seperti tanda air sering kali bergantung pada kombinasi resolusi tinggi dan eksekusi kode untuk pemotongan gambar. Atur media_resolution ke ultra high, aktifkan code execution, lalu gunakan alur verifikasi dua langkah; biasanya ini akan membuat pengenalan menjadi stabil.
Kesimpulan: Membawa Kemampuan Engineering Versi Web ke Pemanggilan API
Kembali ke pertanyaan awal: Mengapa hasil pengenalan gambar Gemini API tidak sebaik versi web? Jawabannya bukan karena modelnya melemah, melainkan karena versi web memiliki "perancah" teknis yang sangat tebal. Saat Anda memanggil API gemini-3.5-flash secara langsung, penulisan ulang petunjuk, tingkat resolusi, anggaran penalaran, pemanggilan alat, hingga validasi hasil harus Anda lengkapi secara eksplisit. Setelah memahami hal ini, inti dari 6 tips tersebut adalah "memindahkan apa yang dilakukan versi web untuk Anda ke dalam rantai pemanggilan API Anda sendiri".
Jalur praktisnya sangat jelas: pertama, maksimalkan media_resolution dan thinking_level, pindahkan instruksi ke system_instruction dan aktifkan caching, aktifkan code execution untuk tugas pengenalan gambar yang kompleks, gunakan File API untuk gambar berukuran besar, dan terakhir, gunakan alur Agent dua hingga tiga langkah untuk menjamin akurasi bisnis yang tinggi. Dengan menerapkan kombinasi ini dan kembali memeriksa tingkat keberhasilan serta latensi di dasbor APIYI (apiyi.com), sebagian besar tim dapat menekan kesenjangan antara "versi web vs API" hingga hampir tidak terlihat oleh mata.
📌 Penulis: Artikel ini disusun oleh tim teknis APIYI (apiyi.com). Untuk panduan praktis integrasi dan penyesuaian parameter model seri Gemini, Claude, dan GPT lainnya, silakan kunjungi Pusat Bantuan APIYI.