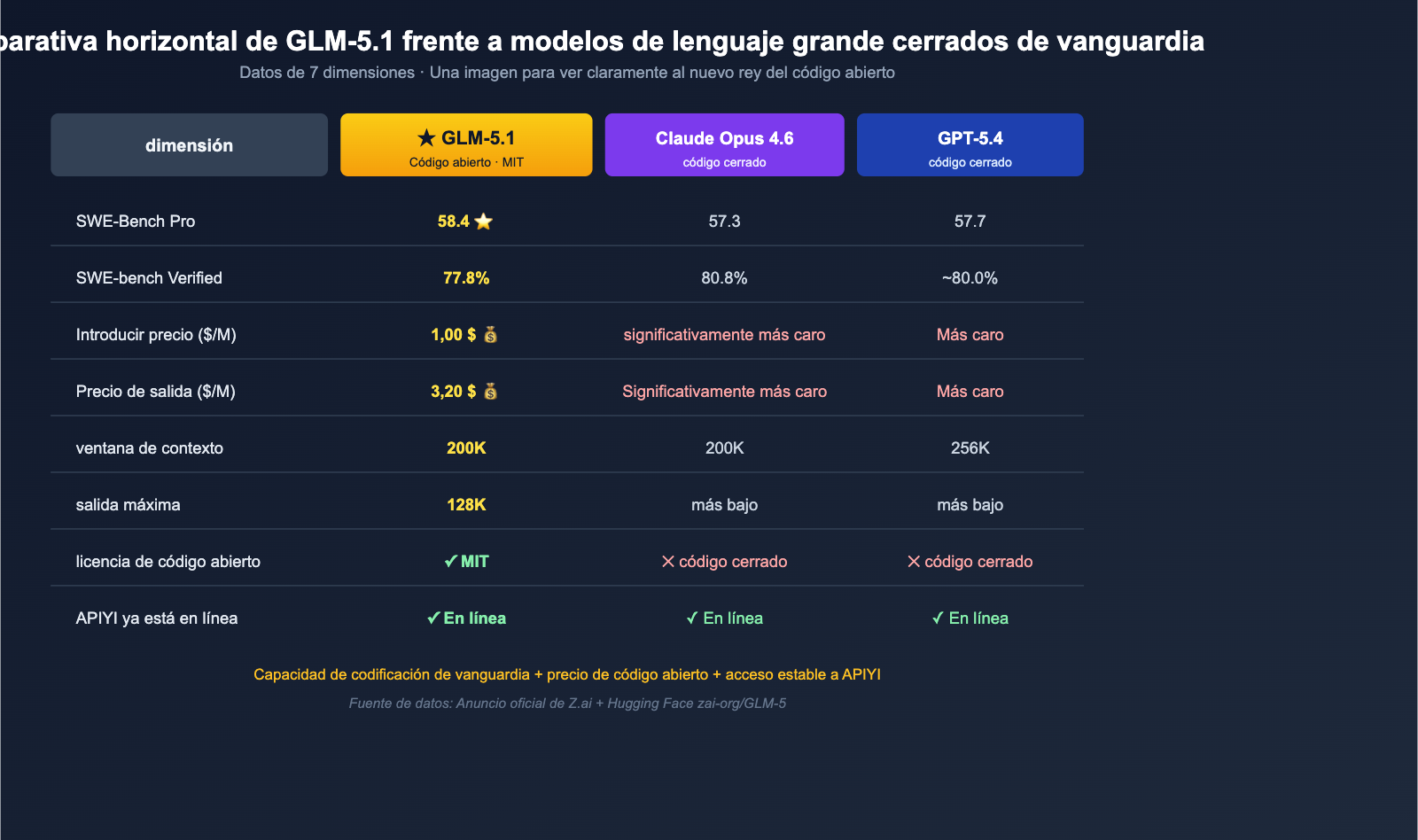
El 7 de abril de 2026, Z.ai (anteriormente Zhipu AI) lanzó oficialmente los pesos completos de GLM-5.1 bajo la licencia MIT en el repositorio de Hugging Face zai-org/GLM-5. Este lanzamiento causó un revuelo inmediato en la comunidad de IA de habla inglesa, no solo porque sea "otro Modelo de Lenguaje Grande de código abierto", sino porque alcanzó el primer puesto mundial en el benchmark de ingeniería de software SWE-Bench Pro con una puntuación de 58.4, superando directamente a GPT-5.4 (57.7), Claude Opus 4.6 (57.3) y Gemini 3.1 Pro (54.2). Es la primera vez que un modelo de código abierto supera a todos los modelos cerrados de vanguardia en un benchmark de "corrección de código real" ampliamente citado por la industria.
Lo que más interesa a los desarrolladores en China continental es que el ritmo de lanzamiento de la API de GLM-5.1 ha sido increíblemente rápido: APIYI (apiyi.com) ya ha completado la integración, por lo que ya no necesitas descargar los pesos de 754B de parámetros desde Hugging Face ni solicitar una cuenta oficial de Z.ai. Puedes invocarlo directamente usando el SDK de OpenAI existente simplemente cambiando la base_url. En este artículo, analizaremos el GLM-5.1 desde 7 dimensiones: arquitectura, benchmarks, hardware de entrenamiento, precios y métodos de acceso, además de proporcionar un ejemplo de código mínimo para invocar GLM-5.1 a través de APIYI.

Resumen de información clave de GLM-5.1 (Edición de abril de 2026)
Antes de entrar en detalles, resumamos todos los hechos clave sobre "GLM-5.1" en una sola tabla.
| Dimensión | Información conocida de GLM-5.1 |
|---|---|
| Fabricante | Z.ai (anteriormente Zhipu AI, cotiza en la bolsa de Hong Kong desde enero de 2026, valoración aprox. 31.3 mil millones de USD) |
| Fecha de lanzamiento | 7 de abril de 2026 |
| Licencia | MIT (permite uso comercial + modificaciones + derivados cerrados) |
| Repositorio | huggingface.co/zai-org/GLM-5 |
| Arquitectura | MoE (Mezcla de Expertos), 754B parámetros totales / 40B parámetros activos |
| Ventana de contexto | 200,000 tokens |
| Salida máxima | 128,000 tokens |
| Datos de entrenamiento | 28.5T tokens (aumento desde los 23T de GLM-5) |
| Hardware de entrenamiento | Uso exclusivo de Huawei Ascend 910B + framework MindSpore (sin Nvidia / AMD) |
| Framework de despliegue | vLLM / SGLang / KTransformers |
| Capacidad insignia | Codificación de agentes de largo alcance (trabajo continuo en una sola tarea durante aprox. 8 horas) |
| Precios (API directa) | Entrada $1.00 / millón de tokens, salida $3.20 / millón de tokens |
| Plan de codificación | GLM Coding Plan desde aprox. $3/mes |
| Acceso vía APIYI | ✅ Ya disponible, se puede invocar a través de https://api.apiyi.com/v1 |
| Herramientas compatibles | Claude Code / OpenClaw / Cline / Cualquier editor compatible con OpenAI |
🎯 Sugerencia de inicio rápido: GLM-5.1 ya está integrado en APIYI (apiyi.com). Solo necesitas cambiar la
base_urlde tu SDK de OpenAI existente ahttps://api.apiyi.com/v1y elmodelal nombre correspondiente de GLM-5.1, y podrás reemplazar inmediatamente tu modelo principal en tu flujo de trabajo de Agente / Cursor / Cline, sin necesidad de reescribir ningún código de negocio.
Por qué GLM-5.1 marca un "punto de inflexión" en el código abierto
Para entender por qué GLM-5.1 es considerado en la comunidad de IA angloparlante como un "punto de inflexión" para el código abierto, debemos analizar sus hechos clave en conjunto.
Primero: el modelo de código abierto que lidera SWE-Bench Pro
SWE-Bench Pro es actualmente uno de los puntos de referencia (benchmark) de reparación de código real más difíciles de la industria. Las tareas provienen íntegramente de repositorios de código de nivel industrial, y el modelo debe entender el contexto, localizar errores (bugs) y escribir una solución que pase las pruebas; esto no tiene nada que ver con "resolver un problema de LeetCode". Antes del lanzamiento de GLM-5.1, esta lista estaba dominada casi exclusivamente por las series GPT-5.x y Claude Opus, y ningún modelo de código abierto se había acercado realmente a los tres primeros puestos.
Sin embargo, esta vez, GLM-5.1 alcanzó la cima con una puntuación de 58.4:
| Modelo | Puntuación en SWE-Bench Pro | ¿Es código abierto? |
|---|---|---|
| GLM-5.1 | 58.4 ⭐ | ✅ MIT (Abierto) |
| GPT-5.4 | 57.7 | ❌ |
| Claude Opus 4.6 | 57.3 | ❌ |
| Gemini 3.1 Pro | 54.2 | ❌ |
No es una victoria por la mínima, sino que elimina por completo la brecha entre "código abierto vs. código cerrado" en el benchmark industrial más exigente. Incluso considerando la advertencia de que "el benchmark fue reportado por Z.ai y las evaluaciones independientes aún no han seguido", el significado industrial de este hecho es innegable: por primera vez, la comunidad de código abierto cuenta con un modelo gratuito capaz de competir cara a cara con los modelos cerrados de vanguardia en la "reparación de código real".
Segundo: una licencia MIT realmente comercializable
Otro hecho clave de GLM-5.1 es su licencia de código abierto: MIT. No es la habitual Apache 2.0, y mucho menos esas licencias restrictivas de "solo para investigación / no comercial". El significado de MIT es muy directo: cualquiera puede descargar, modificar, ajustar (fine-tune), implementar, comercializar, crear derivados cerrados y vender el modelo sin restricciones, siempre que se mantenga el aviso de derechos de autor.
Para los usuarios empresariales, esto significa que GLM-5.1 puede utilizarse sin preocupaciones en:
- Agentes de programación (Coding Agents) internos para productos de desarrollo propio;
- Módulos de generación/revisión de código en SaaS comerciales;
- Plugins de IDE para despliegue privado;
- Cualquier escenario de cumplimiento donde "los pesos del modelo no deban depender de la API de un proveedor específico".
En este momento, abril de 2026, GLM-5.1 es casi la única opción que cumple simultáneamente con "rendimiento de vanguardia + código abierto MIT + liderazgo en benchmarks industriales".

Arquitectura y entrenamiento de GLM-5.1: 754B MoE + Pila tecnológica completa de Huawei
El segundo hecho que hace que GLM-5.1 sea único es su pila de entrenamiento.
Arquitectura MoE: 754B de parámetros totales / 40B activados
GLM-5.1 emplea una arquitectura de Mezcla de Expertos (MoE) con 754B de parámetros totales, de los cuales solo se activan unos 40B en cada inferencia. Este diseño de "Modelo de Lenguaje Grande + activación dispersa" ha sido validado repetidamente por modelos de código abierto como DeepSeek, Qwen y Mixtral. Sus beneficios principales son:
- Gran capacidad del modelo durante el entrenamiento, capaz de absorber más conocimiento (28.5T tokens de datos de preentrenamiento);
- Solo se activa una pequeña parte de los expertos durante la inferencia, lo que hace que el uso de VRAM y la latencia sean similares a los de un modelo denso de 40B;
- Las tareas de diálogo y código pueden seguir rutas de expertos diferentes, mejorando la coherencia en tareas de largo alcance.
| Dimensión | GLM-5 (anterior) | GLM-5.1 (actual) |
|---|---|---|
| Parámetros totales | 355B | 754B |
| Parámetros activados | 32B | 40B |
| Datos de preentrenamiento | 23T tokens | 28.5T tokens |
| Ventana de contexto | Limitada | 200K |
| Salida máxima | Limitada | 128K |
| Especialización en código | Sí | ✅ Mejora significativa |
| Tareas de agente a largo plazo | Sí | ✅ ~8 horas por tarea |
Punto destacado de ingeniería: Agente de largo alcance de 8 horas
Z.ai enfatiza repetidamente en su anuncio la capacidad de "tarea única de 8 horas" de GLM-5.1. Esto significa que: puedes asignar una tarea de ingeniería real (como corregir un error entre archivos, migrar una biblioteca antigua o completar un conjunto de pruebas) a GLM-5.1, y este puede realizar continuamente planificación → ejecución → prueba → reparación → optimización secundaria sin intervención humana, hasta entregar un resultado listo para producción, un proceso que dura hasta 8 horas. Esta curva de capacidad de "agente de resistencia" solo había sido reproducida de forma estable en la industria por la serie Claude Opus; GLM-5.1 es el primer modelo del mundo del código abierto en alcanzar este nivel de rendimiento.
Hardware de entrenamiento: Pila completa de Huawei, sin chips estadounidenses
El tercer hecho que merece ser destacado es el hardware de entrenamiento de GLM-5.1: todo se realizó utilizando chips Huawei Ascend 910B + el framework MindSpore, sin utilizar ninguna GPU de Nvidia o AMD. Este hecho ha generado una gran discusión en la comunidad de IA angloparlante, ya que demuestra directamente que: en un entorno con restricciones de chips Hopper / Blackwell, los equipos de China continental ya son capaces de completar el preentrenamiento de modelos de la escala de 754B MoE utilizando hardware nacional. Esto no es solo una victoria técnica del modelo en sí, sino una demostración a nivel industrial de la infraestructura de entrenamiento de IA en China continental.
Informe completo de puntos de referencia de GLM-5.1
Para no pasar por alto ningún dato importante, hemos organizado los resultados de los puntos de referencia de GLM-5.1 publicados por Z.ai en la siguiente tabla.
| Punto de referencia | Puntuación GLM-5.1 | Significado |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | Reparación de código real, n.º 1 mundial (código abierto) |
| SWE-bench Verified | 77.8% | Reparación de código general, ~94.6% del nivel de Claude Opus 4.6 (80.8%) |
| CyberGym | 68.7 | Razonamiento de seguridad/CTF (ejecución única de 1507 tareas) |
| MCP-Atlas | 71.8 | Punto de referencia de invocación de herramientas MCP |
| T3-Bench | 70.6 | Uso de herramientas y tareas de Agente |
| Humanity's Last Exam | 31.0 / 52.3 | Razonamiento de alta complejidad (sin herramientas / con herramientas) |
| AIME 2026 | 95.3 | Nivel de olimpiada matemática de EE. UU. |
| GPQA-Diamond | 86.2 | Razonamiento científico de nivel experto |
Aquí tienes un resumen de los puntos clave:
- Nivel de código: Ha alcanzado la cima en SWE-Bench Pro y SWE-bench Verified llega al 94.6% del rendimiento de Claude Opus 4.6, lo que significa que, para la gran mayoría de las tareas de ingeniería diarias, la capacidad de codificación de GLM-5.1 está al mismo nivel que el modelo más potente de la actualidad, Claude Opus.
- Razonamiento matemático: Con 95.3 en AIME 2026 y 86.2 en GPQA-Diamond, se sitúa en un "nivel de vanguardia".
- Agentes y uso de herramientas: Los resultados de 71.8 en MCP-Atlas y 70.6 en T3-Bench confirman su capacidad para tareas de larga duración.
- Evaluación honesta: Estos datos provienen totalmente de los informes de Z.ai. Hasta la fecha de publicación, no existen pruebas independientes de terceros, por lo que deben tomarse como referencia y no como valores absolutos.
🎯 Consejo de validación: Ante los puntos de referencia autoinformados, la actitud más pragmática es probarlos con tareas reales de tu negocio. GLM-5.1 ya está disponible en APIYI apiyi.com; puedes ejecutar directamente 5-10 de los prompts de codificación más comunes de tu equipo en GLM-5.1, Claude Opus 4.6 y GPT-5.4, y verificar los resultados de SWE-Bench Pro con tus propios datos.
Estructura de precios de GLM-5.1: ¿Por qué es la "joya oculta" en relación calidad-precio?
Otra característica de GLM-5.1 que no se puede ignorar es su precio. Lo hemos comparado directamente con los principales modelos de vanguardia en la siguiente tabla.
Comparativa de precio por Token
| Modelo | Entrada ($/M) | Salida ($/M) | ¿Código abierto? |
|---|---|---|---|
| GLM-5.1 | $1.00 | $3.20 | ✅ MIT |
| Claude Opus 4.6 | Significativamente más caro | Significativamente más caro | ❌ |
| GPT-5.4 | Más caro | Más caro | ❌ |
| Gemini 3.1 Pro | Medio | Medio | ❌ |
La cifra de $1.00 / $3.20 se sitúa en el "precio base" dentro del rango de los modelos de codificación de vanguardia. En comparación con modelos de código cerrado como Claude Opus 4.6, el precio unitario real de GLM-5.1 es solo una fracción, mientras que Z.ai promociona como uno de sus puntos fuertes que ofrece el "94.6% del rendimiento de codificación de Claude Opus 4.6".
Plan de codificación GLM y opciones de paquetes
Además de la facturación por token, Z.ai ha lanzado el Plan de codificación GLM, un paquete fijo orientado a escenarios de "codificación intensiva" como Cursor, Cline o Claude Code, con un precio inicial de unos $3/mes, que incluye 120 prompts, muy por debajo de los paquetes de codificación de código cerrado similares. Estos planes suelen estar vinculados a varios niveles (Max / Pro / Lite), lo que permite, en flujos de trabajo de desarrollo diario donde las llamadas son frecuentes pero baratas, obtener "capacidad de codificación de nivel Opus a un coste casi gratuito".
🎯 Consejo de selección de precios: Para los equipos que desean "capacidad de codificación de nivel Claude Opus, pero sin el coste elevado de Opus", recomendamos llamar a GLM-5.1 directamente a través de APIYI apiyi.com: no solo disfrutarás de una interfaz unificada y facturación en moneda local, sino que también podrás alternar entre GPT-5.4 y Claude Opus 4.6 en el mismo código de negocio para realizar pruebas A/B y determinar, mediante datos de facturación reales, qué modelo ofrece la mejor relación calidad-precio.
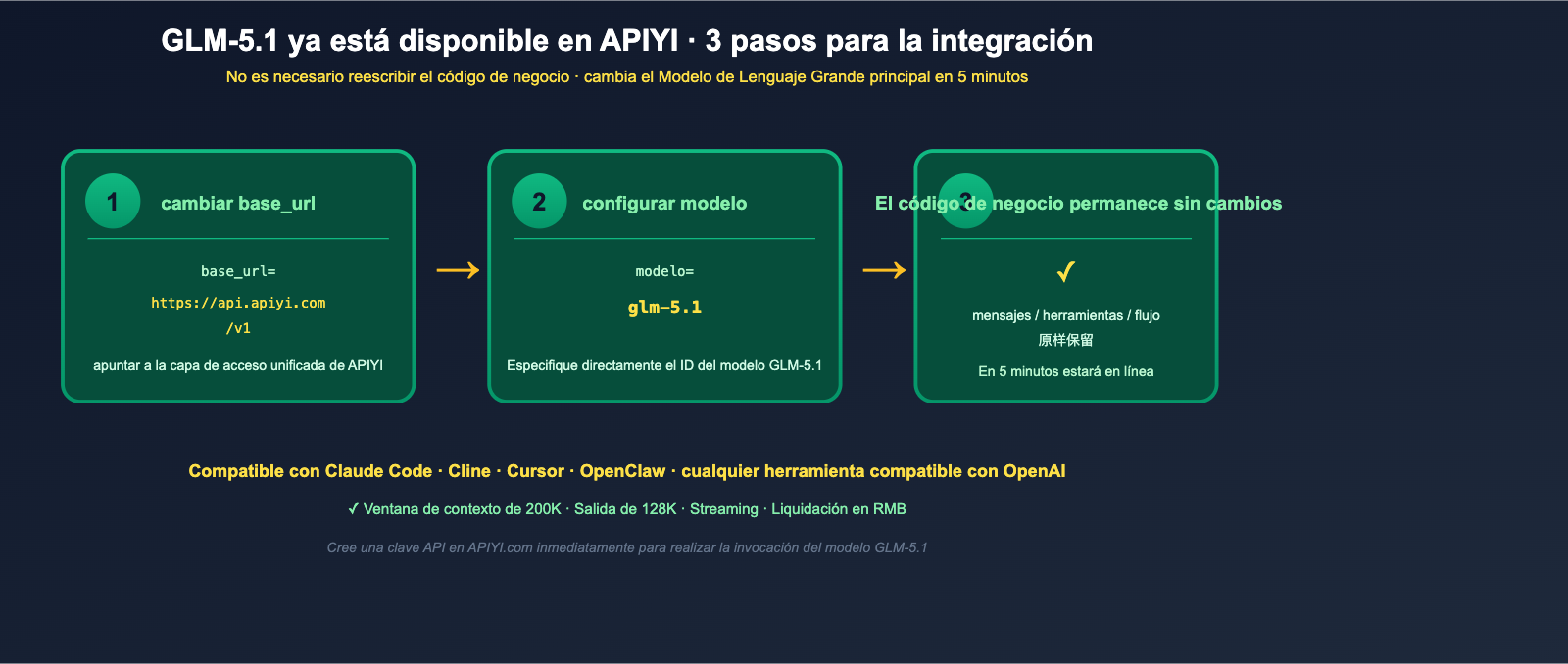
GLM-5.1 ya está disponible en APIYI: Ejemplo mínimo de invocación
Por último, y lo que más interesa a los desarrolladores de habla hispana: GLM-5.1 ya está disponible en APIYI (apiyi.com). Puedes invocarlo directamente a través del SDK de OpenAI compatible que ya utilizas, sin necesidad de desplegar por tu cuenta los pesos de 754B de parámetros en Hugging Face.
Ejemplo mínimo en Python
A continuación, presento un ejemplo mínimo de invocación en Python que muestra cómo utilizar el SDK oficial de OpenAI para llamar a GLM-5.1:
from openai import OpenAI
# Cambia base_url a APIYI y api_key por tu clave API de APIYI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="TU_CLAVE_API_APIYI"
)
resp = client.chat.completions.create(
model="glm-5.1", # Especifica directamente el ID del modelo GLM-5.1
messages=[
{"role": "system", "content": "Eres un ingeniero de software experto."},
{"role": "user", "content": "Escribe en Python una caché LRU con tiempo de expiración y límite de capacidad."}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
Tu código de negocio permanece intacto: la lógica que utilizabas para invocar a GPT-4, Claude o DeepSeek es exactamente la misma para GLM-5.1.
Integración con Cursor / Cline / Claude Code
Z.ai ha confirmado explícitamente que GLM-5.1 es compatible con todas las herramientas de programación que siguen el estándar de OpenAI, incluyendo Claude Code, OpenClaw y Cline. En estas herramientas, solo tienes que apuntar el endpoint compatible con OpenAI a https://api.apiyi.com/v1 y seleccionar el modelo GLM-5.1. De esta forma, podrás cambiar tu modelo de programación principal de Opus o GPT-5 a GLM-5.1 sin modificar tu flujo de trabajo. Para IDEs como Cursor, que también soportan un endpoint personalizado de OpenAI, el proceso es idéntico.
Ejemplo de invocación por streaming y ventana de contexto larga
GLM-5.1 en APIYI mantiene intacta su capacidad de 200K en la ventana de contexto y 128K de salida. Para tareas de agentes de larga duración, puedes activar el modo stream para obtener una menor latencia en el primer token:
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Revisa completamente este repositorio de Python de 5000 líneas, enumera los posibles errores y sugerencias de refactorización."}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 Sugerencia de integración: GLM-5.1 en APIYI (apiyi.com) ya es compatible con la interfaz de OpenAI, salida por streaming y una ventana de contexto completa de 200K. Te recomendamos que hoy mismo apuntes tus herramientas Cursor, Cline o Claude Code hacia APIYI y pruebes GLM-5.1 como tu nuevo modelo de programación principal durante una semana, validando con tareas reales si puede reemplazar al Opus o GPT-5 que utilizas actualmente.
¿Para quién es GLM-5.1 y para quién no?
Perfil recomendado
| Perfil | Razón |
|---|---|
| Usuarios intensivos de agentes de programación | Lidera en SWE-Bench Pro, capacidad para tareas de 8 horas |
| Equipos que buscan modelos de vanguardia con presupuesto limitado | Precio unitario de $1.00/$3.20, muy inferior a Opus / GPT-5 |
| Empresas que requieren despliegue comercial bajo licencia MIT | Sin restricciones, comercializable y con derivados de código cerrado |
| Usuarios de Cursor / Cline / Claude Code | Compatible nativamente con la interfaz de OpenAI, reemplazo con un clic |
| Investigadores interesados en la pila de entrenamiento de IA nacional | Entrenado totalmente con Huawei Ascend 910B + MindSpore |
| Escenarios de razonamiento matemático / científico | AIME 2026 95.3 / GPQA-Diamond 86.2 |
Perfil no recomendado
| Perfil | Razón |
|---|---|
| Usuarios que priorizan "benchmarks de terceros independientes" | Los datos actuales son reportados por Z.ai, requiere verificación propia |
| Tareas centradas en multimodal (imágenes/video) | GLM-5.1 se especializa en texto y código; lo multimodal no es su fuerte |
| Dependencia total del ecosistema de herramientas de Anthropic / OpenAI | Algunas características avanzadas siguen dependiendo de las interfaces originales |
Preguntas frecuentes (FAQ) sobre GLM-5.1
Q1: ¿GLM-5.1 es realmente de código abierto? ¿Se puede usar comercialmente?
Sí. GLM-5.1 fue publicado por Z.ai el 7 de abril de 2026 en Hugging Face (zai-org/GLM-5) bajo la licencia MIT, lo que significa que es de código abierto completo. Permite uso comercial, derivados de código cerrado y ajuste fino (fine-tuning) secundario; solo se requiere conservar el aviso de derechos de autor. Es una de las licencias de código abierto más permisivas que existen, lo que significa que puedes integrar GLM-5.1 directamente en tus productos comerciales, SaaS o despliegues privados sin pagar ninguna tarifa de licencia.
Q2: ¿Es GLM-5.1 realmente mejor que GPT-5.4 y Claude Opus 4.6?
En el benchmark SWE-Bench Pro, la puntuación publicada por Z.ai (58.4) supera efectivamente a GPT-5.4 (57.7) y Claude Opus 4.6 (57.3). Sin embargo, hay que tener en cuenta lo siguiente: estos datos son reportados por Z.ai y aún no han sido replicados completamente por laboratorios de evaluación independientes. Te sugerimos no tomar estas cifras como una "verdad absoluta", sino probarlo con las tareas reales de tu negocio; esto ya se puede hacer directamente con GLM-5.1 en APIYI apiyi.com, sin necesidad de realizar tu propio despliegue.
Q3: ¿La API de GLM-5.1 ya está disponible en APIYI? ¿Cómo se utiliza?
Ya está disponible. Solo necesitas cambiar el base_url del SDK oficial de OpenAI a https://api.apiyi.com/v1, reemplazar el api_key con tu clave API de APIYI y configurar el model con el ID correspondiente a GLM-5.1. Podrás realizar la invocación del modelo inmediatamente sin necesidad de reescribir tu código de negocio. En la sección de "Ejemplo mínimo de invocación" del artículo se muestra la versión en Python, la cual es igualmente aplicable para los SDK de Node, Go o Rust.
Q4: ¿Es GLM-5.1 mejor que otros modelos de código abierto nacionales como DeepSeek, Qwen o Kimi?
La mayor diferenciación de GLM-5.1 radica en su "codificación de agentes de largo alcance + liderazgo en SWE-Bench Pro", un terreno que ni DeepSeek, ni Qwen, ni Kimi habían conquistado frontalmente hasta ahora. Si tu negocio se basa en "conversación diaria + RAG", DeepSeek y Qwen siguen siendo muy competitivos; pero si tu negocio se centra en Agentes de Programación / Integración con IDE / Corrección de código, GLM-5.1 es la primera opción en el mundo del código abierto actualmente. En APIYI puedes poner a todos estos modelos en una misma prueba comparativa y formarte tu propia opinión en 15 minutos.
Q5: ¿Qué hardware se necesita para desplegar GLM-5.1 localmente?
GLM-5.1 tiene una arquitectura MoE con 754B de parámetros totales y 40B activados. El despliegue local requiere un clúster de GPU multinodo de nivel profesional, algo casi inviable para equipos comunes. Z.ai recomienda oficialmente utilizar vLLM / SGLang / KTransformers para despliegues de inferencia a gran escala. Si solo quieres usar GLM-5.1 y no investigarlo, la forma más eficiente es invocarlo directamente a través de APIYI apiyi.com: sin necesidad de GPU, sin mantenimiento y pagando solo por el uso.
Q6: ¿Es cierto que el entrenamiento de GLM-5.1 no utilizó GPUs de Nvidia?
Sí. Z.ai reveló públicamente que GLM-5.1 fue entrenado completamente en chips Huawei Ascend 910B con el framework MindSpore, sin utilizar ninguna GPU de Nvidia o AMD. Este es el primer caso en el campo de los modelos de lenguaje grandes de código abierto en 2026 que logra completar el entrenamiento de un "modelo MoE de 754B con hardware totalmente nacional", lo cual tiene un significado industrial considerable.
Conclusión: GLM-5.1 es un punto de inflexión para la IA de código abierto en 2026
Al conectar la arquitectura, los benchmarks, los precios, la pila de entrenamiento y la ruta de acceso a la API, la posición de GLM-5.1 en abril de 2026 queda muy clara: no es solo otra actualización común de un modelo de código abierto, sino un evento emblemático donde "el código abierto realmente puede superar a la vanguardia de código cerrado". El primer puesto mundial en SWE-Bench Pro con 58.4, la apertura total bajo licencia MIT, el precio extremadamente bajo de $1.00/$3.20, la ventana de contexto de 200K + 128K de salida, la capacidad de agente de largo alcance de 8 horas y la pila de entrenamiento completa sobre Huawei Ascend 910B; cualquiera de estos hechos por sí solo merecería un informe, pero al sumarlos, se convierten en un "punto de inflexión para el código abierto".
Para los desarrolladores en China continental, la mejor noticia es que la API de GLM-5.1 ya está disponible en APIYI: no necesitas desplegar tú mismo 754B de pesos, no necesitas tarjetas de crédito extranjeras ni esperar aprobaciones. Solo cambiando el base_url a https://api.apiyi.com/v1 y el model a GLM-5.1, hoy mismo puedes reemplazar tu modelo de codificación principal en Cursor / Cline / Claude Code por este nuevo rey del código abierto. Si todavía te preocupan las facturas de Opus / GPT-5, esta es una ventana de oportunidad que vale la pena probar durante una tarde.
🎯 Recomendación final: Si quieres experimentar de primera mano la "capacidad de codificación de vanguardia + precio de código abierto + acceso estable de APIYI" de GLM-5.1, te sugerimos crear hoy mismo una clave API en apiyi.com, cambiar el
base_urldel SDK de OpenAI que ya usas ahttps://api.apiyi.com/v1y elmodela GLM-5.1, y ejecutarlo durante una semana con las tareas de código más cotidianas de tu equipo. Independientemente de si decides cambiar tu modelo principal, esta prueba te dará una percepción de primera mano sobre el nivel real de la IA de código abierto en 2026.
Autor: Equipo de APIYI | Enfocados en la implementación de modelos de lenguaje grandes y el ecosistema de código abierto. Para más información sobre invocaciones prácticas y comparativas de GLM-5.1 / Claude / GPT-5, visita APIYI en apiyi.com.