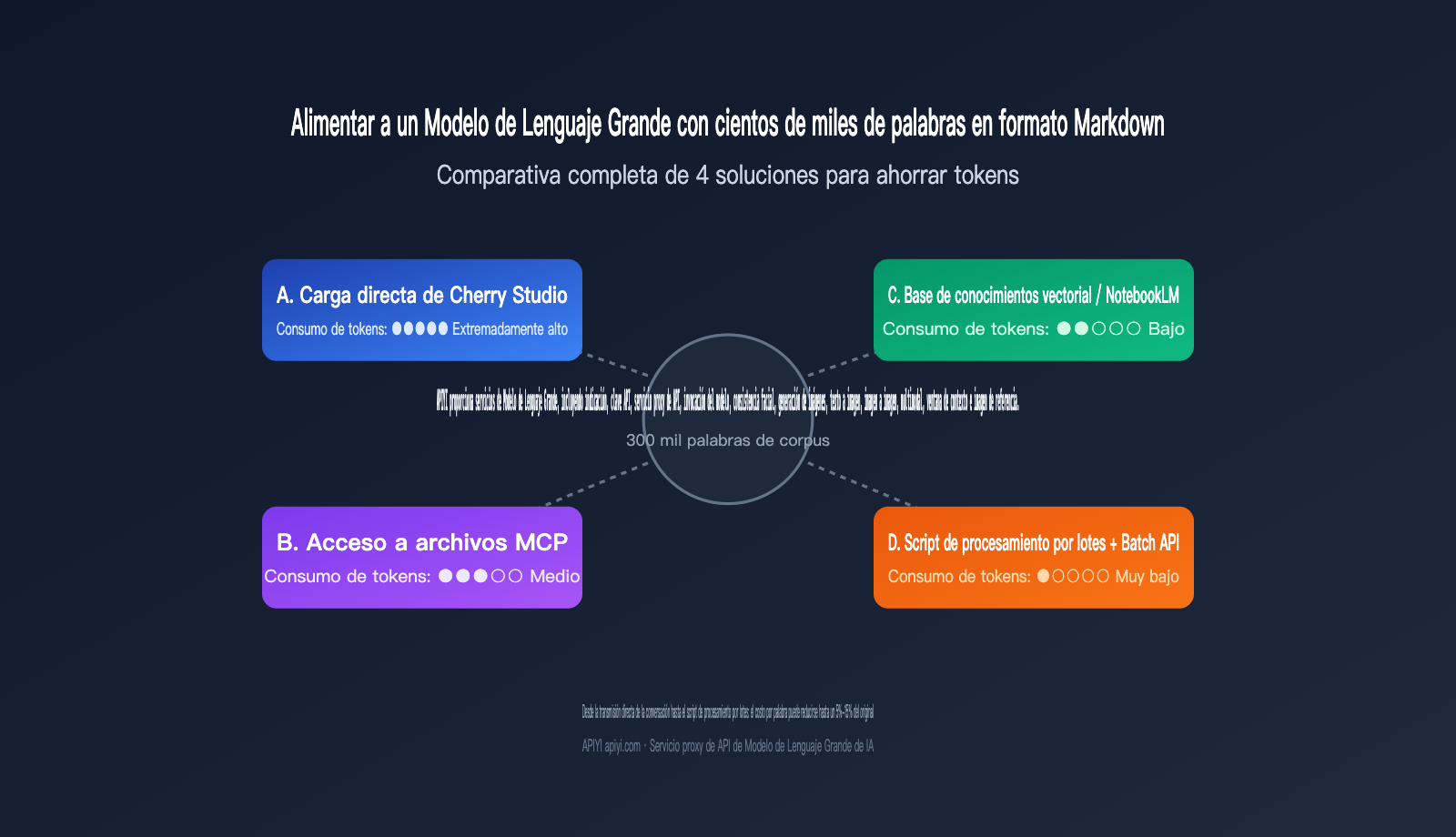
Recientemente recibí una consulta muy típica: un usuario quiere "destilar" cientos de miles de palabras de un escritor experto para que un Modelo de Lenguaje Grande adopte su estilo, pero no sabe cuál es la forma más rentable de introducir el corpus en Markdown. Las tres estrategias comunes son: subir los archivos uno a uno a herramientas de chat como Cherry Studio, usar MCP para que el modelo acceda directamente a los archivos en el disco duro, o volcarlo todo en una base de conocimientos para hacer RAG. A primera vista, todas parecen funcionar, pero cuando el volumen del corpus supera las 300,000 palabras, la factura de tokens y la latencia divergen rápidamente; elegir la opción incorrecta puede costar diez veces más de lo presupuestado.
Este artículo analiza y desglosa cuatro enfoques principales para optimizar el consumo de tokens al alimentar un Modelo de Lenguaje Grande con corpus en Markdown: consumo real de tokens, costo por tarea, latencia del primer token, controlabilidad y la mejor elección según el tamaño del corpus. Al final, ofreceré una ruta de decisión por etapas: qué usar para la exploración inicial y a qué cambiar una vez que se escale. Si estás trabajando en destilación de estilo, preguntas y respuestas sobre bases de conocimientos o limpieza de datos antes del ajuste fino (fine-tuning), tras leer esto deberías ser capaz de tomar una decisión directa.
I. El problema central de ahorrar tokens en corpus Markdown para Modelos de Lenguaje Grandes
Antes de desglosar las soluciones, aclaremos dónde reside realmente el costo. Alimentar a un Modelo de Lenguaje Grande con cientos de miles de palabras en Markdown implica, esencialmente, equilibrar cuatro tipos de costos: tokens de entrada, tokens de salida, costos de recuperación/indexación y costos de depuración humana.
Los tokens de entrada son los más subestimados. Si un blog técnico está en formato HTML original, convertirlo a Markdown suele ahorrar entre un 70% y un 80% de tokens, ya que se eliminan etiquetas, estilos y scripts incrustados. Esta es la razón por la cual el primer paso de cualquier flujo de trabajo que procese grandes corpus es unificar el contenido en Markdown o txt. Si haces esto bien, la línea base de costos de cualquier método de alimentación posterior bajará un escalón.
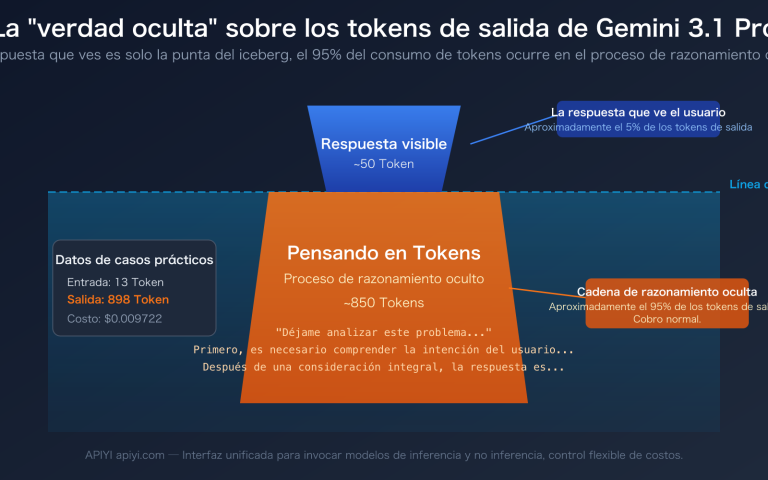
Los tokens de salida parecen irrelevantes, pero en tareas de "destilación" son un cuello de botella oculto. Claude Sonnet y Opus ya han estandarizado el precio de una ventana de contexto de 1 millón de tokens (Sonnet $3/M de entrada, Opus $5/M de entrada). Teóricamente, podrías volcar cientos de miles de palabras de una vez, pero la salida máxima de una sola respuesta sigue siendo de solo unas decenas de miles de tokens, lo que significa que no puedes completar una reescritura total con una sola invocación. La tarea debe fragmentarse, lo que determina directamente que los scripts de procesamiento por lotes suelen ser más adecuados para escenarios a escala que el chat interactivo.
🎯 Consejo de preparación antes de elegir: Antes de seleccionar una solución, realiza un proceso de desensibilización y normalización de formato en todos tus archivos Markdown. Recomendamos usar la plataforma APIYI (apiyi.com) para probar primero con muestras pequeñas, confirmar el consumo real de tokens por cada mil palabras y luego decidir si optar por herramientas de chat o scripts de procesamiento por lotes, evitando así que los costos se salgan de control más adelante.
II. Diferencias clave y límites de aplicación de las 4 soluciones
Cada una de las cuatro soluciones tiene límites de capacidad bien definidos. Entender estas diferencias es mucho más importante que memorizar parámetros técnicos.
2.1 Solución A: Carga directa en herramientas de chat (como Cherry Studio)
Esta es la opción con la barrera de entrada más baja. Herramientas como Cherry Studio, Claude Desktop o ChatGPT te permiten arrastrar varios archivos Markdown directamente al cuadro de diálogo, donde el modelo combina todo el contenido en una única indicación larga. La ventaja es que no requiere ingeniería y es un sistema "lo que ves es lo que obtienes". La desventaja es que, cada vez que inicias una sesión nueva, debes volver a cargar todo, lo que genera un consumo excesivo de tokens, además de que la cantidad de archivos que puedes incluir está limitada por la ventana de contexto.
Para tareas con muestras pequeñas de menos de 50 000 caracteres, este método es el más eficiente, ya que puedes ajustar el resultado sobre la marcha usando lenguaje natural. Sin embargo, una vez que el corpus supera los 200 000 caracteres, te enfrentarás constantemente a truncamientos de contexto, latencia en contextos largos (el primer token puede tardar entre 20 y 30 segundos) y cargos repetidos.
2.2 Solución B: MCP para conexión directa a archivos locales
El protocolo MCP (Model Context Protocol) permite que el modelo lea archivos de tu disco duro como si estuviera invocando una herramienta. Suena elegante: el modelo accede a lo que necesita sin cargar todo el conjunto. Pero, en la práctica, el consumo de tokens de MCP suele subestimarse; incluso si una llamada a la herramienta solo requiere 3 campos de un JSON, la estructura completa entra en el contexto. El modo de coincidencia de palabras clave consume aproximadamente 3 veces más tokens que la recuperación vectorial.
La verdadera fortaleza de MCP reside en las fuentes de datos que cambian dinámicamente, como registros en tiempo real, datos privados de usuarios o información financiera que debe permanecer local por seguridad. Para el escenario típico de "cientos de miles de caracteres en archivos Markdown estáticos", MCP es como usar un cañón para matar moscas, y es fácil agotar la ventana de contexto prematuramente en llamadas de múltiples pasos.
2.3 Solución C: Base de conocimientos vectorial / NotebookLM
Consiste en fragmentar todos los archivos, realizar embeddings y almacenarlos en una base de datos para recuperar fragmentos relevantes según sea necesario; esta es la ruta RAG. Un flujo de trabajo RAG bien diseñado solo recupera de 5 a 20 fragmentos por consulta, lo que suele sumar entre 2000 y 10 000 tokens, ahorrando entre 50 y 200 veces los tokens de entrada en comparación con una carga completa.
NotebookLM es el producto RAG "listo para usar" de Google; maneja automáticamente la incrustación, la recuperación y las citas, siendo ideal para tareas de lectura como análisis de estilo de escritura, revisiones bibliográficas o preguntas sobre notas. Su limitación es que las respuestas se basan únicamente en los archivos fuente y no asocia información de sus datos de entrenamiento, además de tener una personalización limitada. Si necesitas estrategias de recuperación complejas o razonamiento de varios pasos, construir tu propia base de conocimientos vectorial será mucho más flexible.
🎯 Consejo para la Solución C: La calidad de la recuperación en una base de conocimientos vectorial determina directamente la calidad de la salida. La segmentación (chunking), el modelo de embedding y el top-k de recuperación deben ajustarse según el corpus. Recomendamos realizar una evaluación a pequeña escala con Claude o GPT en la plataforma APIYI (apiyi.com) para comparar la precisión de las respuestas bajo diferentes parámetros de recuperación antes de decidir si usar NotebookLM o una solución propia.
2.4 Solución D: Scripts de procesamiento por lotes (la mejor opción para escalabilidad)
Esta es la solución más destacada en la respuesta original: dejar que la IA te ayude a escribir un script de procesamiento por lotes. Primero, usa el Modelo de Lenguaje Grande para procesar entre 5 y 10 muestras de datos, identifica manualmente o automáticamente patrones reutilizables (como plantillas de oraciones, estructuras de párrafos o distribución de palabras clave) y luego integra esas reglas en el código. Deja que el código procese los cientos de miles de caracteres restantes, reservando al Modelo de Lenguaje Grande solo para los puntos críticos.
Esto es, en esencia, "delegar reglas": el Modelo de Lenguaje Grande descubre los patrones y el código se encarga de la ejecución masiva. Al combinar esto con la API de procesamiento por lotes (Batch API) de Claude/GPT (con un 50% de descuento), el costo total suele ser solo del 5% al 15% de la Solución A. La desventaja es que requiere 1 o 2 días de trabajo de ingeniería inicial, por lo que no es ideal para tareas únicas.
三、Comparativa de consumo de tokens y costes de 4 soluciones
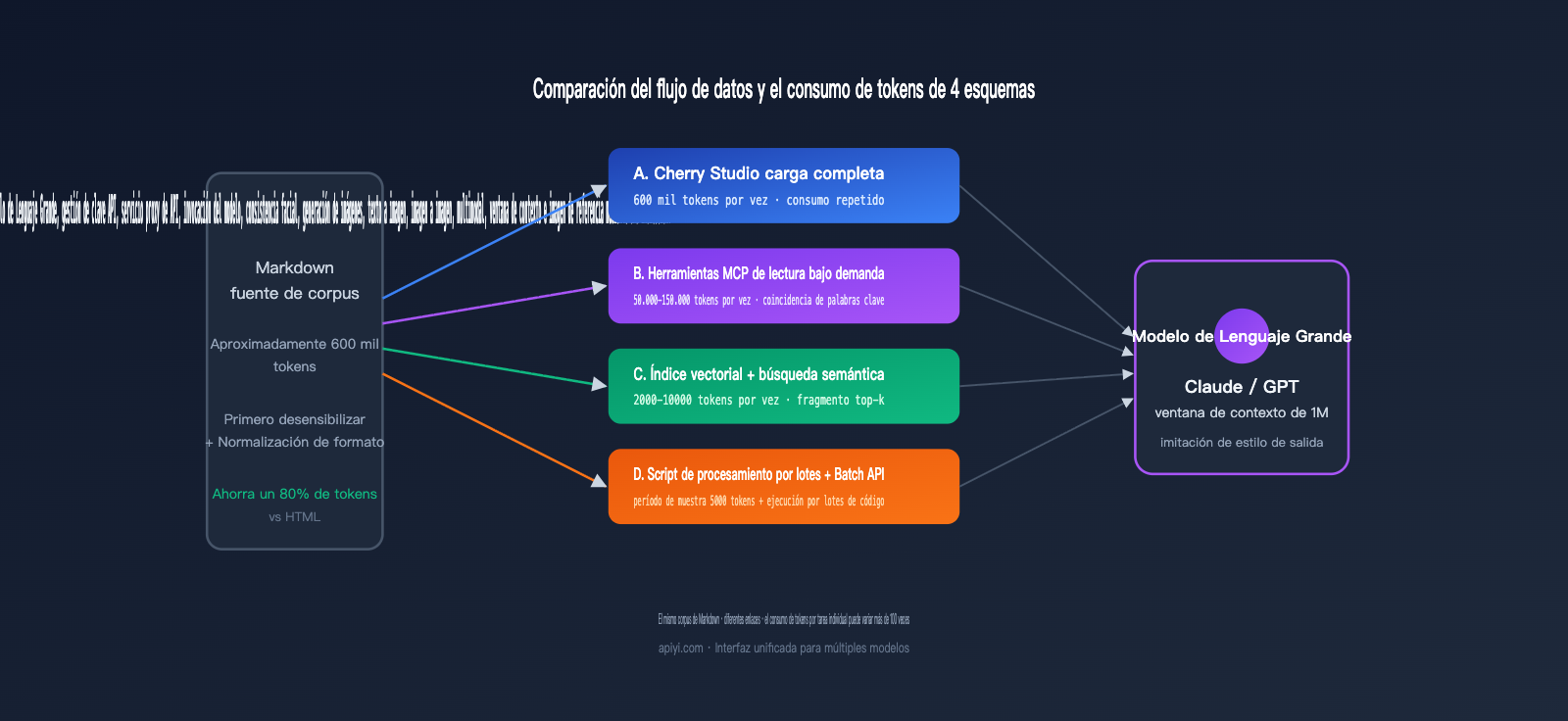
Para entender realmente las diferencias, hay que poner números sobre la mesa. La siguiente tabla compara un escenario concreto: un usuario que desea destilar 300.000 caracteres de material en Markdown (aprox. 600.000 tokens) para generar 100 artículos imitando un estilo específico (aprox. 2.000 palabras cada uno).
| Solución | Tokens de entrada (por vez) | Total tokens entrada | Total tokens salida | Coste estimado (Sonnet) | Latencia primer token |
|---|---|---|---|---|---|
| A. Chat directo | 600k | 60M (100 veces) | 6M | ≈ $270 | 20-30 s |
| B. Acceso a archivos MCP | 50k-150k (por partes) | 15M | 6M | ≈ $135 | 8-15 s |
| C. Base de conocimientos vectorial | 5k-10k | 1M | 6M | ≈ $93 | 1-2 s |
| D. Script de procesamiento + Batch API | 5k (muestreo) + proceso de código | 1M | 6M | ≈ $46 | Asíncrono |
Como se puede observar, la solución D cuesta solo un 17% de la solución A, además de ofrecer una latencia mucho más estable. Si además aplicamos el descuento del 50% de la Batch API, el coste real de la solución D se reduce a la mitad. Aunque el contexto de 1M de Claude ha estandarizado los precios, el desperdicio de reintroducir el mismo material sigue siendo un problema estructural inevitable en los flujos de trabajo basados en chat.
🎯 Consejo de validación de costes: Los costes anteriores son estimaciones basadas en precios públicos. Las cifras reales pueden variar entre un 30% y un 50% según el diseño de la indicación, la tasa de acierto de la caché y el uso de prompt caching. Recomendamos activar el monitoreo de uso en el panel de control de APIYI (apiyi.com), revisar los gastos diariamente durante los primeros 3 días para convertir el presupuesto abstracto en una curva visual antes de decidir migrar más tareas a la Batch API.
La siguiente tabla incluye la complejidad técnica de las cuatro soluciones para facilitar una visión comparativa:
| Dimensión | A. Chat directo | B. MCP | C. Base vectorial | D. Script batch |
|---|---|---|---|---|
| Esfuerzo de ingeniería | Casi nulo | Medio | Medio-alto | Alto (inicial) |
| Tiempo de aprendizaje | 5 min | 1-2 h | 0.5-1 día | 1-2 días |
| Reproducibilidad | Débil (historial volátil) | Media | Fuerte | Muy fuerte |
| Escala de datos ideal | < 50k caracteres | 50k-300k (dinámicos) | 100k – 10M (estáticos) | > 300k caracteres |
| Control de salida | Limitado por contexto | Limitado por llamadas | Limitado por recuperación | Control total |
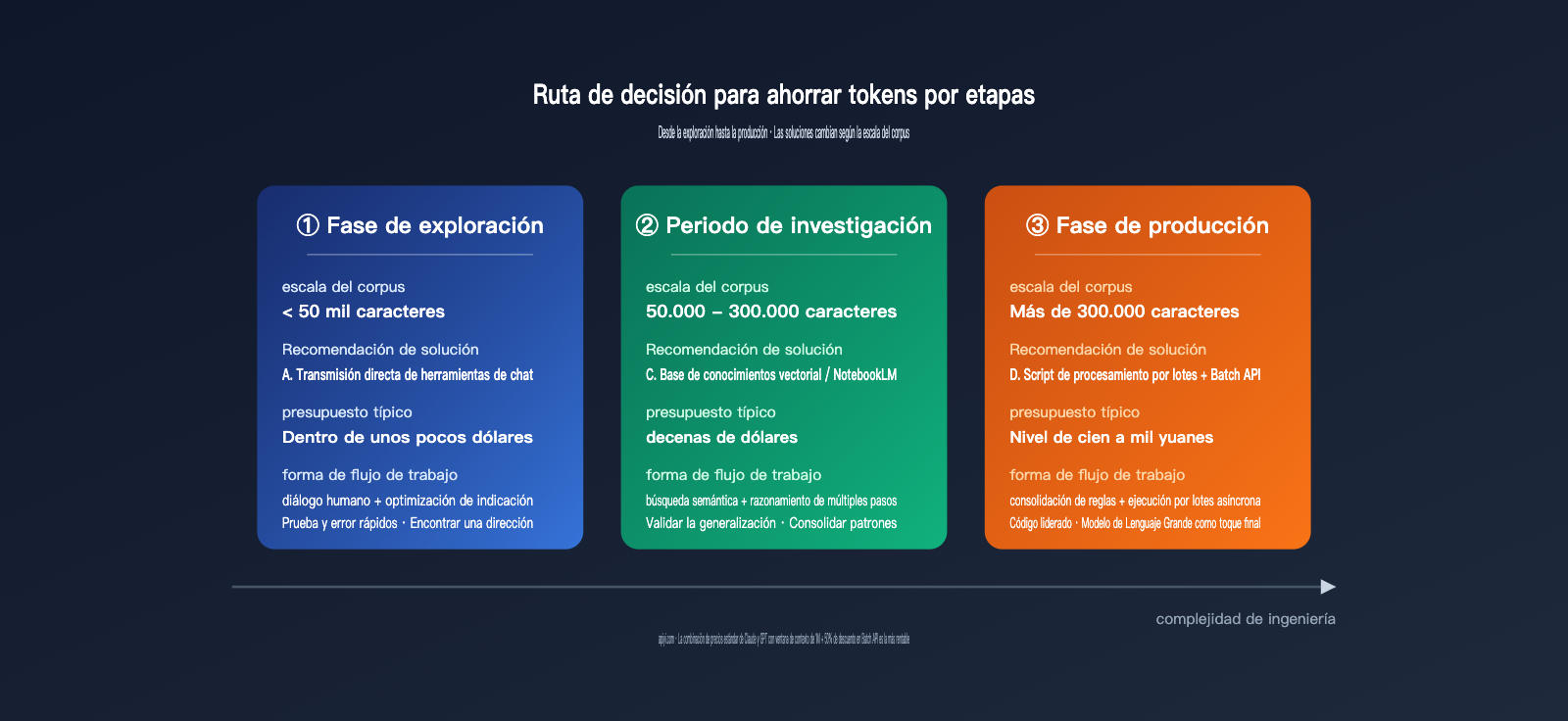
IV. Recomendaciones según el volumen de datos
Es más fácil entender estas soluciones aplicándolas a escenarios reales. A continuación, presentamos rutas recomendadas según tres escalas de volumen.
4.1 Pequeño volumen (< 50.000 caracteres): Fase de exploración
El objetivo principal aquí es validar ideas rápidamente, no optimizar costes. La solución A (chat directo) es la más razonable: arrastra todos los archivos a Cherry Studio o Claude Desktop y dialoga directamente con el modelo para ajustar la indicación. En esta fase, céntrate en: ¿el modelo captura realmente los rasgos de estilo del autor? ¿Qué dimensiones son cuantificables (longitud de frase, vocabulario, estructura)? ¿Cuáles son subjetivas (tono, ritmo)? Estas dudas se resuelven con un coste mínimo en muestras pequeñas.
4.2 Volumen medio (50.000 – 300.000 caracteres): Fase de investigación
Al entrar en este rango, el coste de reintroducir datos en la solución A se dispara. La mejor práctica es pasar a la solución C (base de conocimientos vectorial) o NotebookLM, almacenando las muestras en una base vectorial para consultarlas bajo demanda. Si solo necesitas análisis de contenido, resumen de estilo o exploración mediante preguntas, NotebookLM funciona casi sin esfuerzo técnico; si requieres razonamientos complejos de varios pasos, construye tu propio sistema RAG basado en Claude o GPT.
🎯 Consejo para escala media: NotebookLM es ideal para lectura y análisis, pero no permite estrategias de recuperación personalizadas ni flujos complejos. Recomendamos conectar Claude Sonnet o Opus con 1M de contexto en la plataforma APIYI (apiyi.com) para ejecutar RAG; disfrutarás de precios estándar y control total sobre el número de chunks y el peso de la recuperación, ideal para corpus de datos de larga duración.
4.3 Gran volumen (> 300.000 caracteres): Fase de producción
Al alcanzar cientos de miles o millones de caracteres, la solución D (scripts de procesamiento batch) es la única opción sostenible. Divide la tarea en un flujo de tres etapas: "descubrimiento de patrones en muestras → procesamiento masivo mediante código → el Modelo de Lenguaje Grande solo interviene en nodos críticos". Al combinar esto con la Batch API de forma asíncrona, puedes reducir el coste por carácter a un 5%-15% del original. En esta etapa, no necesitas una indicación más inteligente, sino una tubería de ingeniería más robusta.
V. Recomendaciones para la toma de decisiones por etapas para ahorrar Tokens
Hemos condensado el análisis anterior en una tabla de ruta práctica que puedes seguir directamente:
| Condición de activación | Solución recomendada | Acción clave |
|---|---|---|
| Corpus < 50k palabras / Exploración única | Solución A: Chat directo | Arrastrar archivos, ajustar la indicación, registrar indicaciones efectivas |
| 50k-300k palabras / Corpus estático / Análisis de lectura | Solución C: Base de conocimiento vectorial | Elegir NotebookLM o RAG propio, priorizar el ajuste de fragmentos (chunk) y top-k |
| > 300k palabras / Tareas repetitivas / Producción masiva | Solución D: Script de procesamiento por lotes + Batch API | Pedir a la IA que escriba el script, verificar patrones manualmente durante la fase de muestra |
| Datos dinámicos / Requisito de procesamiento local | Solución B: MCP | Limitar las llamadas a herramientas, usar la búsqueda por palabras clave con precaución |
La combinación más común en proyectos reales es "empezar con la Solución A, pasar a la C y finalizar con la D". Esto se debe a que la comprensión de la tarea es gradual: las conversaciones con muestras pequeñas te ayudan a aclarar qué hacer y cuáles son los criterios de éxito; las muestras medianas te ayudan a verificar la calidad de la recuperación y la capacidad de generalización; y la etapa a gran escala consiste en consolidar los procesos maduros en código.
Saltarse las etapas intermedias para ir directo a los scripts de procesamiento por lotes es un error común: descubrirás que el script está perfectamente escrito, pero los resultados no cumplen las expectativas porque la indicación inicial no se ajustó lo suficiente. Por el contrario, quedarse estancado en la etapa de chat desperdiciará Tokens; podrías terminar con una factura de cientos de dólares habiendo obtenido solo unas pocas docenas de muestras efectivas.
🎯 Señales para cambiar de etapa: Cuando notes que has usado una indicación similar para procesar archivos parecidos más de 5 veces, es hora de pasar a una base de conocimiento vectorial; cuando tengas que repetir la misma lógica de recuperación en cada tarea, es hora de escribir un script. Recomendamos activar el almacenamiento en caché de indicaciones y las estadísticas de uso en la plataforma APIYI (apiyi.com) para que el cambio de etapa se base en datos y no en intuiciones.
VI. Ejemplo mínimo ejecutable de un script de procesamiento por lotes
Para hacer que la Solución D sea más concreta, aquí tienes un esqueleto de script de procesamiento por lotes minimalista que demuestra el flujo central de "descubrimiento de muestras → consolidación de reglas → ejecución por lotes":
import os, json
from anthropic import Anthropic
# Usamos el servicio proxy de API para la invocación del modelo
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Usa un Modelo de Lenguaje Grande para extraer características de estilo cuantificables de un solo artículo."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Por favor, extrae las características del estilo de escritura del siguiente artículo en Markdown y genera un JSON que incluya:
- avg_sentence_length: longitud media de las oraciones
- paragraph_structure: patrón de estructura de párrafos
- key_phrases: las 10 frases más frecuentes
- tone: etiquetas de tono (ej. riguroso/coloquial/incisivo)
Contenido del artículo:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Fase de muestra: usar 10 artículos para descubrir patrones
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Consolidación de reglas: guardar las características frecuentes en un archivo de configuración para su uso posterior
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
Una vez terminada la fase de muestra, la etapa real de reescritura masiva puede aplicar las reglas de style_profile.json completamente mediante código. El Modelo de Lenguaje Grande solo interviene en el paso de "pulido final", lo que permite reducir el consumo de Tokens de cientos de miles a solo unos pocos miles.
🎯 Sugerencia de integración de API para procesamiento por lotes: El
base_urlanterior apunta al punto de conexión del servicio proxy de API de APIYI, por lo que puedes reutilizar el SDK oficial de Anthropic sin modificar el código. Recomendamos añadir lógica de reintento y seguimiento de costes en el script; detenerse automáticamente si se supera el presupuesto al ejecutar tareas largas es la mejor forma de evitar problemas comunes en el procesamiento por lotes a gran escala.
VII. Preguntas frecuentes (FAQ)
P1: Claude Sonnet y Opus ya tienen una ventana de contexto de 1 millón de tokens, ¿no es mejor simplemente meterlo todo ahí?
Técnicamente es posible, pero conlleva dos costes ocultos. Primero, la latencia del primer token puede extenderse a 20-30 segundos, lo que arruina la experiencia interactiva. Segundo, cada vez que envías el mismo corpus en una sesión nueva, los costes se disparan, siendo entre 50 y 200 veces más caro que usar RAG. Un contexto de 1M es ideal para razonamiento global puntual (como "encontrar contradicciones entre documentos"), pero no para consultar repetidamente el mismo material. Recomendamos usar Sonnet 1M en APIYI (apiyi.com) para tareas de razonamiento global y Haiku para tareas de procesamiento por lotes; esta combinación ofrece la mejor relación coste-beneficio.
P2: ¿Cómo elegir entre NotebookLM y montar mi propia base de datos vectorial?
Si eres un usuario individual o un equipo pequeño que necesita análisis de corpus estáticos, investigación de estilo o consultas de preguntas y respuestas, NotebookLM es lo más rápido: solo arrastras los archivos y listo. Si necesitas personalizar estrategias de chunking, controlar pesos de recuperación, integrarte con sistemas empresariales o usar modelos de otros proveedores para la generación, construir tu propia base de datos vectorial te dará mucha más flexibilidad.
P3: ¿Es realmente inútil el MCP?
Para nada. La fortaleza del MCP reside en escenarios donde los "datos cambian constantemente" o "no pueden salir del entorno local", como leer registros en tiempo real, consultar bases de datos privadas o invocar APIs internas. Para corpus estáticos en Markdown, RAG es superior en casi todas las dimensiones; esa es la conclusión.
P4: ¿La Batch API realmente ahorra un 50%? ¿Es muy lenta la respuesta?
La Batch API es asíncrona y suele devolver resultados en un plazo de 24 horas, con un precio del 50% respecto a la API estándar. Es perfecta para tareas que no requieren tiempo real, como "destilar un estilo de escritura para generar 100 artículos". Al combinarla con el precio estándar de 1M de contexto, el coste total puede reducirse al 30%-40% del original. Sugerimos probar el flujo en la plataforma APIYI (apiyi.com) con la API síncrona y, una vez validado, cambiar al modo Batch para la producción masiva.
P5: ¿Qué hago si mi corpus contiene imágenes, tablas y bloques de código?
Markdown ya preserva muy bien estas estructuras, pero ten cuidado: los bloques de código extensos consumen muchos tokens. Si solo buscas analizar el estilo del texto, puedes usar un script para eliminar el código. Si las tablas son muy complejas, te sugerimos convertirlas a CSV y almacenarlas por separado, enviando solo un resumen al Modelo de Lenguaje Grande; esto puede ahorrar más de un 30% adicional de tokens.
VIII. Conclusión
Volviendo a la pregunta inicial: ¿qué método usar para alimentar a un Modelo de Lenguaje Grande con cientos de miles de palabras en Markdown? La respuesta no es una opción única, sino una combinación por etapas. En la fase de exploración con muestras pequeñas, la carga directa en el chat es lo más rápido; en la fase de investigación de escala media, una base de conocimientos vectorial o NotebookLM es lo más estable; y en la fase de producción a gran escala, es obligatorio pasar a scripts de procesamiento por lotes junto con la Batch API. El objetivo es que el Modelo de Lenguaje Grande pase de ser un "ejecutor" a un "descubridor de patrones", dejando que el código sea el que realmente maneje el volumen.
Una vez que entiendes este camino, el ahorro de tokens en corpus Markdown para Modelos de Lenguaje Grandes deja de ser una cuestión de "qué herramienta elegir" y pasa a ser "qué combinación usar en cada etapa". Si estás atascado en alguna fase y no sabes si cambiar, puedes realizar una evaluación a pequeña escala en la plataforma APIYI (apiyi.com). Compara tres métricas: coste por cada mil palabras, precisión de recuperación y latencia del primer token; la decisión será mucho más clara. Esperamos que esta comparativa te ahorre rodeos y te ayude a invertir tu presupuesto en lo que realmente genera valor.
— Equipo de APIYI (api.apiyi.com)