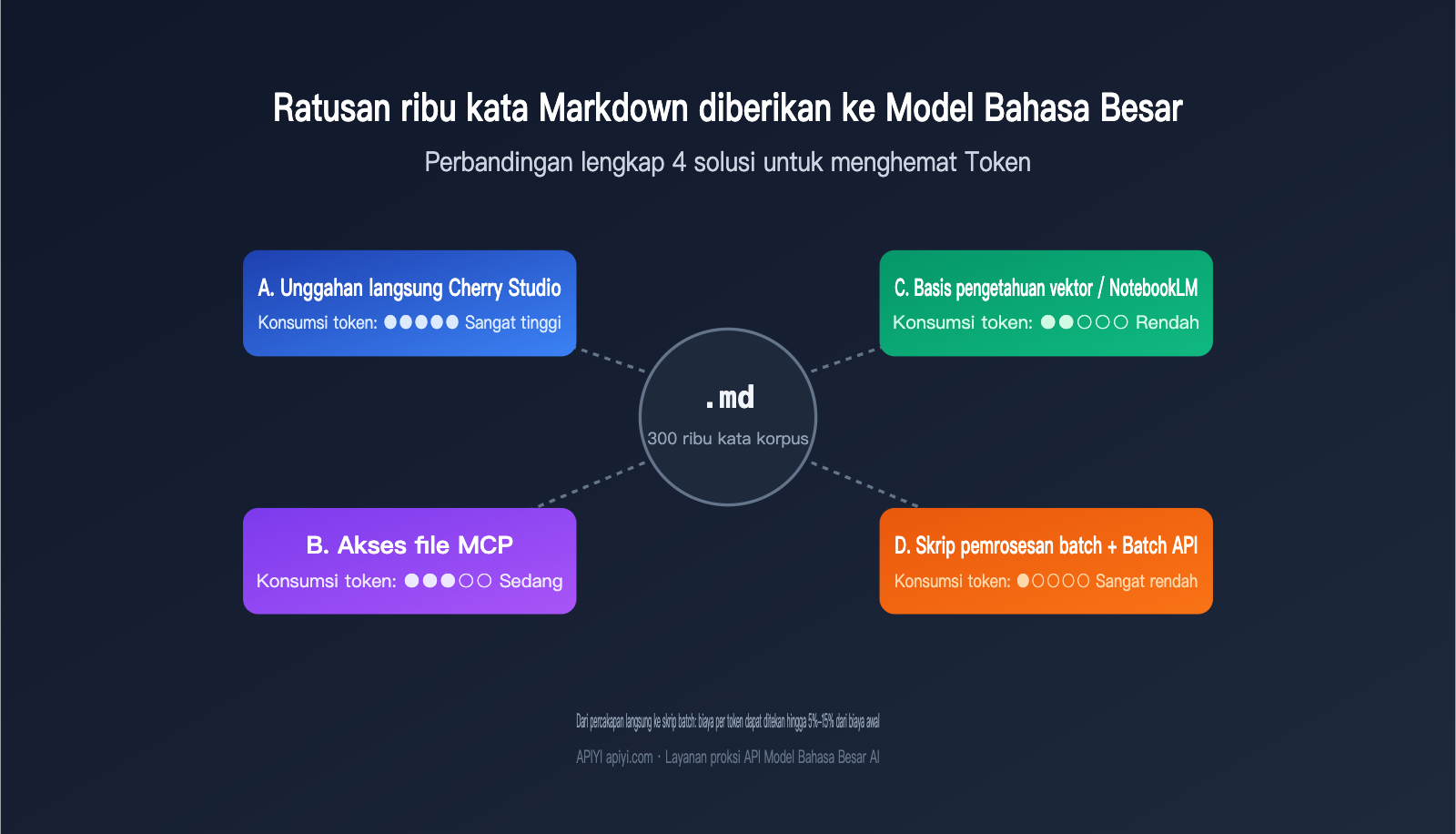
Baru-baru ini saya menerima pertanyaan yang sangat umum: seorang pengguna ingin "menyuling" ratusan ribu kata tulisan dari seorang penulis ahli ke dalam Model Bahasa Besar agar bisa meniru gaya penulisannya, tetapi ia bingung bagaimana cara memasukkan korpus Markdown tersebut dengan cara yang paling efisien. Tiga pendekatan yang umum dilakukan adalah: mengunggah file satu per satu ke alat percakapan seperti Cherry Studio, menggunakan MCP agar model dapat memanggil file langsung dari hard disk, atau memasukkan semuanya ke dalam basis pengetahuan (knowledge base) untuk RAG. Sekilas, semuanya tampak bisa berjalan, tetapi ketika volume korpus melebihi 300.000 kata, tagihan Token dan latensi akan segera berbeda drastis. Salah memilih metode bisa membuat anggaran membengkak hingga sepuluh kali lipat.
Artikel ini akan membedah empat skema utama untuk menghemat Token saat memberikan korpus Markdown ke Model Bahasa Besar: konsumsi Token aktual, biaya per tugas, latensi Token pertama, kontrol, dan pilihan terbaik untuk berbagai skala korpus. Terakhir, saya akan memberikan jalur pengambilan keputusan bertahap—apa yang digunakan untuk eksplorasi awal dan apa yang harus diganti setelah mencapai skala besar. Jika Anda sedang melakukan penyulingan gaya, tanya jawab basis pengetahuan, atau pembersihan data sebelum fine-tuning, setelah membaca ini Anda seharusnya bisa langsung menentukan pilihan.
I. Masalah Inti Penghematan Token pada Korpus Markdown Model Bahasa Besar
Sebelum membedah skema, mari kita perjelas di mana letak mahalnya masalah ini. Memberikan ratusan ribu kata Markdown ke Model Bahasa Besar pada dasarnya adalah menyeimbangkan empat jenis biaya: Token input, Token output, biaya pengambilan/pengindeksan, dan biaya debugging manusia.
Token input adalah hal yang paling sering diremehkan. Jika sebuah blog teknis dalam format HTML asli diubah menjadi Markdown, biasanya dapat menghemat 70%~80% Token karena tag, gaya, dan skrip yang disematkan akan dihapus. Inilah sebabnya mengapa langkah pertama dari semua alur kerja pemrosesan korpus besar adalah menyatukan konten ke dalam Markdown atau txt. Jika Anda melakukan ini dengan benar, biaya dasar dari metode input apa pun yang dipilih akan turun satu tingkat.
Token output mungkin tampak tidak relevan, tetapi dalam tugas "penyulingan", ini sebenarnya adalah hambatan tersembunyi. Claude Sonnet dan Opus telah menetapkan jendela konteks 1 juta Token sebagai harga standar (input Sonnet $3/M, input Opus $5/M). Secara teoritis, Anda bisa memasukkan ratusan ribu kata sekaligus, tetapi output maksimum untuk satu respons tetap hanya beberapa puluh ribu Token. Ini berarti Anda tidak bisa menyelesaikan penulisan ulang penuh hanya dengan satu pemanggilan. Tugas harus dipecah menjadi potongan-potongan, yang juga secara langsung menentukan bahwa skrip pemrosesan batch biasanya lebih cocok untuk skenario skala besar daripada percakapan interaktif.
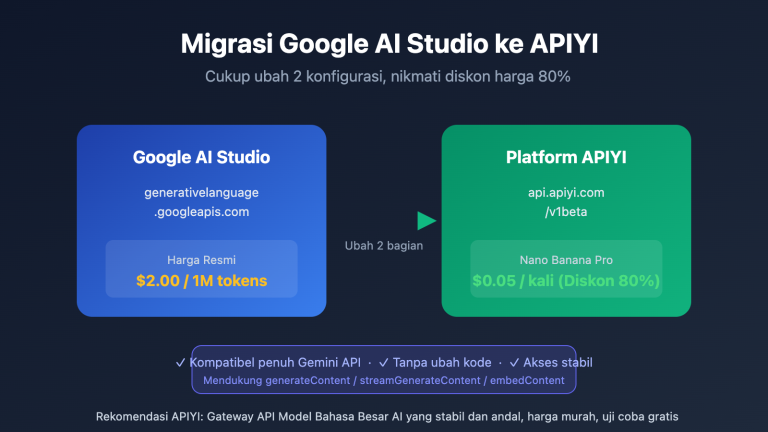
🎯 Saran persiapan sebelum pemilihan: Sebelum memilih skema, lakukan pembersihan data (de-sensitisasi) dan normalisasi format pada semua file Markdown. Kami menyarankan untuk mencoba sampel batch kecil melalui platform APIYI (apiyi.com) terlebih dahulu, konfirmasikan konsumsi Token aktual per seribu kata, baru kemudian putuskan apakah akan menggunakan alat percakapan atau skrip pemrosesan batch untuk menghindari biaya yang tidak terkendali di kemudian hari.
2. 4 Jenis Solusi: Perbedaan Inti dan Batasan Penerapan
Keempat solusi ini memiliki batasan kemampuan yang jelas. Memahami perbedaannya jauh lebih penting daripada sekadar menghafal parameter teknis.
2.1 Solusi A: Unggah Langsung via Alat Percakapan (seperti Cherry Studio)
Ini adalah cara dengan hambatan masuk terendah. Alat seperti Cherry Studio, Claude Desktop, atau ChatGPT memungkinkan Anda menyeret beberapa file Markdown langsung ke dalam kotak obrolan, di mana model akan menggabungkan semua konten file menjadi satu petunjuk panjang untuk diproses. Kelebihannya adalah nol beban rekayasa dan hasil yang langsung terlihat. Kekurangannya adalah setiap kali memulai sesi baru, Anda harus mengunggah ulang file, yang menyebabkan konsumsi Token berulang, serta jumlah file yang bisa dimasukkan dibatasi oleh jendela konteks.
Untuk tugas skala kecil di bawah 50.000 kata, cara ini justru paling efisien karena Anda bisa menyesuaikan hasil secara langsung dengan bahasa alami. Namun, begitu korpus melebihi 200.000 kata, Anda akan sering mengalami pemotongan konteks, latensi konteks panjang (Token pertama bisa memakan waktu 20-30 detik), dan biaya yang membengkak akibat pengulangan.
2.2 Solusi B: MCP (Model Context Protocol) untuk File Lokal
MCP memungkinkan model membaca file di hard drive Anda seolah-olah sedang memanggil alat. Terdengar elegan: model memanggil data sesuai kebutuhan tanpa harus memuat semuanya. Namun, dalam pengujian, konsumsi Token MCP sering kali diremehkan—bahkan jika pemanggilan alat hanya membutuhkan 3 kolom dari JSON, struktur lengkapnya tetap akan masuk ke dalam konteks. Mode pencocokan kata kunci mengonsumsi sekitar 3 kali lebih banyak Token dibandingkan pengambilan berbasis vektor.
Kekuatan utama MCP terletak pada sumber data yang berubah secara dinamis, seperti log waktu nyata, data pribadi pengguna, atau data keuangan yang harus tetap berada di penyimpanan lokal. Untuk skenario tipikal seperti "ratusan ribu kata Markdown statis", MCP terasa seperti menggunakan meriam untuk membunuh nyamuk, dan cenderung menghabiskan jendela konteks lebih cepat dalam pemanggilan multi-putaran.
2.3 Solusi C: Basis Pengetahuan Vektor / NotebookLM
Memotong semua file, melakukan embedding, menyimpannya ke database, dan memanggil potongan yang relevan melalui pencarian semantik adalah alur kerja RAG. Jalur RAG yang dirancang dengan baik hanya mengambil 5-20 potongan per kueri, biasanya total 2.000-10.000 Token, yang menghemat 50-200 kali lipat Token input dibandingkan pemuatan penuh.
NotebookLM adalah produk RAG siap pakai dari Google yang secara otomatis menangani embedding, pencarian, dan referensi. Ini cocok untuk tugas berbasis pembacaan seperti analisis gaya penulisan, tinjauan literatur, atau tanya jawab catatan. Keterbatasannya adalah jawaban hanya didasarkan pada file sumber dan tidak akan secara aktif mengaitkan data pelatihan, serta kustomisasi yang terbatas. Jika Anda memerlukan strategi pencarian yang kompleks atau penalaran multi-langkah, membangun basis pengetahuan vektor sendiri akan jauh lebih fleksibel.
🎯 Catatan Implementasi Solusi C: Kualitas pencarian basis pengetahuan vektor secara langsung menentukan kualitas output. Pemotongan chunk, model embedding, dan top-k pencarian harus disesuaikan berdasarkan korpus Anda. Kami menyarankan untuk melakukan pengujian skala kecil terlebih dahulu di platform APIYI (apiyi.com) menggunakan Claude atau GPT untuk membandingkan akurasi jawaban di bawah parameter pencarian yang berbeda sebelum memutuskan antara menggunakan NotebookLM atau membangun sistem sendiri.
2.4 Solusi D: Skrip Pemrosesan Batch AI (Solusi Optimal untuk Skala Besar)
Ini adalah solusi yang paling ditekankan dalam jawaban asli: biarkan AI membantu Anda menulis skrip pemrosesan batch. Gunakan Model Bahasa Besar untuk memproses 5-10 sampel data, identifikasi pola yang dapat digunakan kembali (seperti templat kalimat, struktur paragraf, distribusi kata kunci) secara manual atau otomatis, lalu tanamkan aturan tersebut ke dalam kode. Biarkan kode menangani ratusan ribu kata sisanya, sementara Model Bahasa Besar hanya dilibatkan pada titik-titik krusial.
Ini pada dasarnya adalah "penurunan aturan": Model Bahasa Besar digunakan untuk menemukan pola, sementara kode bertanggung jawab atas eksekusi massal. Jika dikombinasikan dengan Batch API Claude/GPT (diskon 50%), biaya keseluruhan biasanya hanya 5%-15% dari Solusi A. Kelemahannya adalah membutuhkan investasi rekayasa selama 1-2 hari di awal, sehingga tidak cocok untuk tugas sekali jalan.
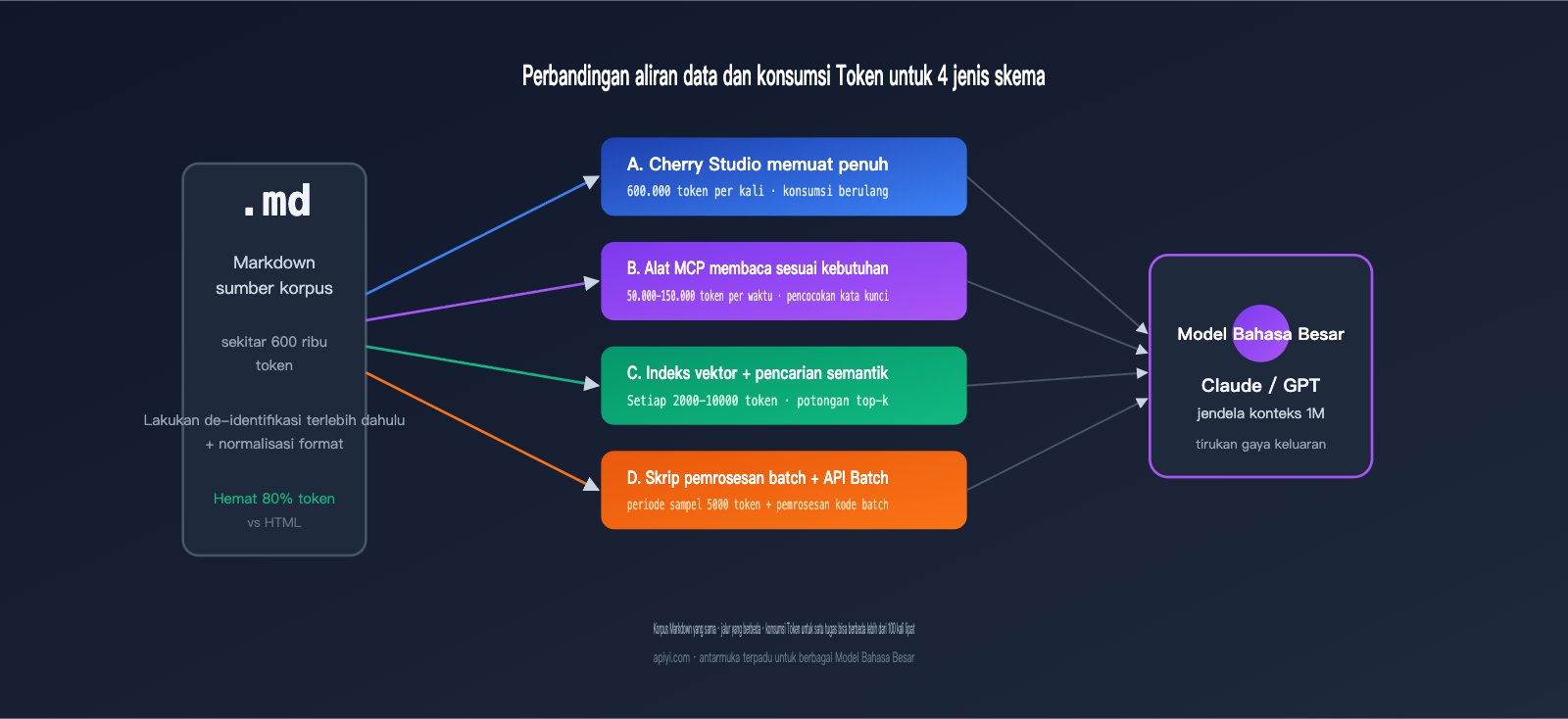
Tiga. Perbandingan Konsumsi Token dan Biaya untuk 4 Opsi
Perbedaan abstrak baru bisa dihitung nilainya jika dikonversi ke angka. Tabel di bawah ini membandingkan skenario nyata: pengguna ingin menyarikan 300.000 karakter korpus Markdown (sekitar 600.000 Token) untuk menghasilkan 100 artikel tiruan gaya (masing-masing sekitar 2.000 karakter).
| Opsi | Token Input per Sesi | Total Token Input | Total Token Output | Estimasi Biaya (Sonnet) | Latensi Token Pertama |
|---|---|---|---|---|---|
| A. Chat Langsung | 600.000 | 60 juta (100x) | 6 juta | ≈ $270 | 20-30 detik |
| B. Akses File MCP | 50-150 ribu (bertahap) | 15 juta | 6 juta | ≈ $135 | 8-15 detik |
| C. Basis Pengetahuan Vektor | 5.000-10.000 | 1 juta | 6 juta | ≈ $93 | 1-2 detik |
| D. Skrip Batch + Batch API | 5.000 (fase sampel) + pemrosesan kode | 1 juta | 6 juta | ≈ $46 | Asinkron |
Terlihat bahwa biaya Opsi D hanya sekitar 17% dari Opsi A, dengan latensi yang paling stabil. Jika ditambah diskon 50% dari Batch API, biaya aktual Opsi D bisa turun setengahnya lagi. Setelah Claude 1M context menetapkan harga standar untuk jendela konteks super panjang, Opsi A tidak lagi dikenakan biaya 2x lipat, namun pemborosan akibat input berulang pada korpus yang sama tetap ada—ini adalah kelemahan fatal yang tak terhindarkan dalam alur kerja berbasis percakapan.
🎯 Saran Verifikasi Biaya: Biaya di atas diestimasi berdasarkan harga publik. Angka aktual akan berfluktuasi 30%-50% tergantung desain petunjuk, rasio hit cache, dan apakah prompt caching diaktifkan. Kami menyarankan Anda mengaktifkan pemantauan penggunaan di konsol APIYI apiyi.com, lakukan rekonsiliasi harian selama 3 hari pertama, ubah anggaran abstrak menjadi kurva visual, lalu putuskan apakah akan memindahkan lebih banyak tugas ke Batch API.
Tabel berikut menyertakan kompleksitas teknis dari keempat opsi agar lebih mudah dilihat secara horizontal:
| Dimensi | Opsi A Chat Langsung | Opsi B MCP | Opsi C Basis Pengetahuan Vektor | Opsi D Skrip Batch |
|---|---|---|---|---|
| Investasi Teknis | Hampir nol | Sedang | Sedang ke Tinggi | Tinggi (di awal) |
| Waktu Belajar | 5 menit | 1-2 jam | Setengah hingga 1 hari | 1-2 hari |
| Reproduksibilitas | Lemah (riwayat chat mudah hilang) | Sedang | Kuat | Sangat Kuat |
| Skala Korpus yang Cocok | < 50 ribu karakter | 50-300 ribu karakter (dinamis) | 100 ribu – 10 juta karakter (statis) | > 300 ribu karakter |
| Kontrol Output | Terbatas panjang konteks | Terbatas jumlah pemanggilan alat | Terbatas kualitas pencarian | Sepenuhnya terkontrol |
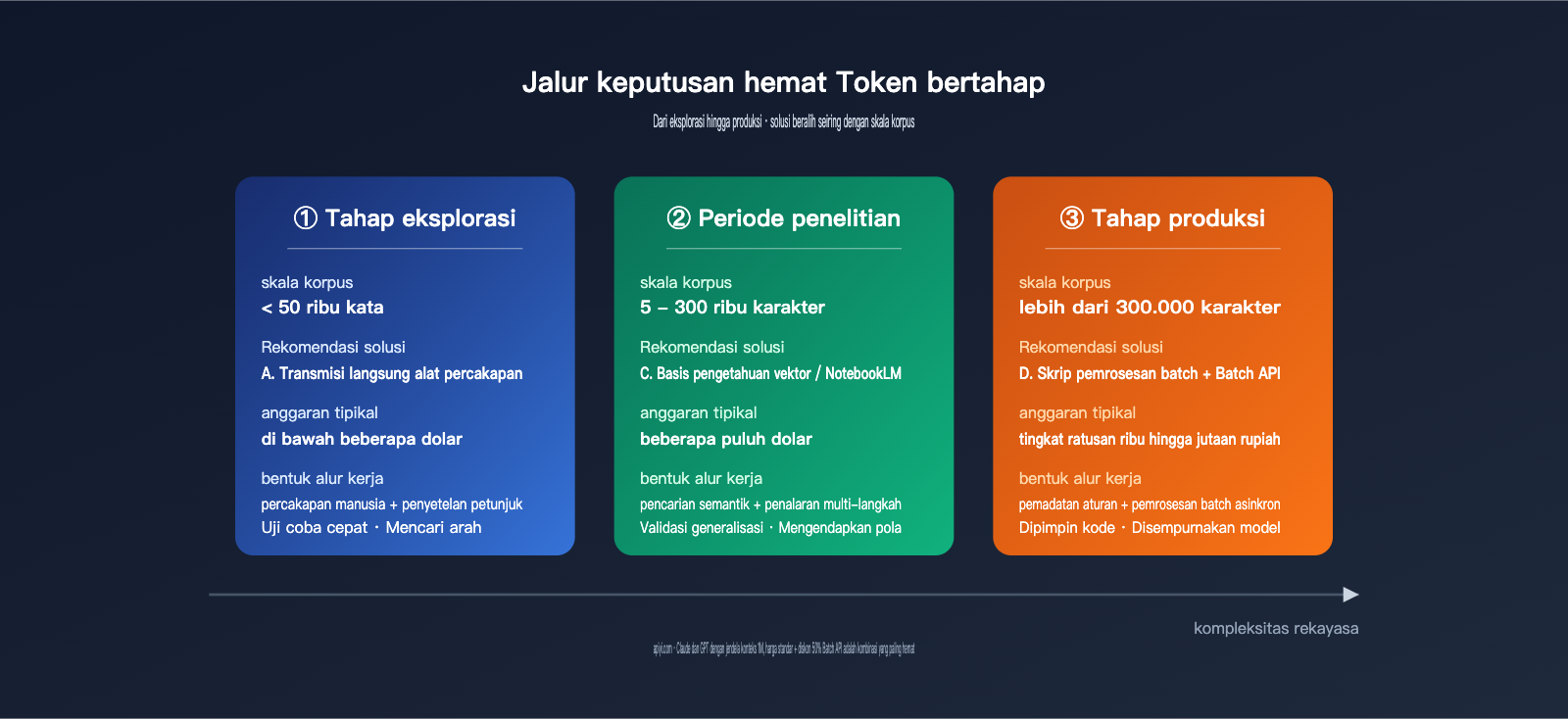
Empat. Rekomendasi Skenario Berdasarkan Skala Korpus
Menerapkan opsi ke dalam skenario nyata akan lebih intuitif. Berikut adalah jalur rekomendasi yang dibagi menjadi tiga skala.
4.1 Skala Kecil (< 50 ribu karakter): Fase Eksplorasi Pembelajaran
Tujuan utamanya adalah memvalidasi ide dengan cepat, bukan mengejar efisiensi biaya. Opsi A (Chat Langsung) adalah pilihan paling masuk akal. Seret semua file ke Cherry Studio atau Claude Desktop, lalu berdialog langsung dengan model untuk melakukan debug pada petunjuk. Pada tahap ini, fokuslah pada: apakah model benar-benar bisa menangkap karakteristik gaya penulis target? Dimensi mana yang bisa dikuantifikasi (panjang kalimat, pilihan kata, struktur kalimat)? Mana yang samar (nada, ritme)? Masalah ini berbiaya sangat rendah dalam sampel kecil, hanya butuh beberapa dolar untuk menyelesaikannya.
4.2 Skala Menengah (50-300 ribu karakter): Fase Analisis Penelitian
Memasuki rentang ini, biaya input berulang dari Opsi A akan membengkak dengan cepat. Praktik terbaik saat ini adalah beralih ke Opsi C (Basis Pengetahuan Vektor) atau NotebookLM. Setelah sampel dimasukkan ke dalam basis vektor, gunakan pencarian semantik untuk pemanggilan sesuai kebutuhan. Jika Anda hanya melakukan analisis konten, ringkasan gaya, atau eksplorasi tanya jawab, NotebookLM hampir tidak memerlukan usaha teknis. Jika memerlukan penalaran multi-langkah yang lebih kompleks, bangun sistem RAG sendiri berbasis Claude atau GPT.
🎯 Tips Pemilihan Skala Menengah: NotebookLM cocok untuk analisis bacaan murni, tetapi tidak mendukung strategi pencarian kustom dan alur kerja yang kompleks. Kami menyarankan untuk menghubungkan Claude Sonnet atau Opus 1M context di platform APIYI apiyi.com untuk menjalankan RAG. Anda bisa menikmati harga standar sekaligus mengontrol jumlah chunk dan bobot pencarian secara fleksibel, cocok untuk korpus yang perlu dioperasikan dalam jangka panjang.
4.3 Skala Besar (> 300 ribu karakter): Fase Produksi
Pada skala ratusan ribu hingga jutaan karakter, Opsi D (Skrip Batch) hampir menjadi satu-satunya pilihan yang berkelanjutan. Pecah tugas menjadi alur kerja tiga tahap: "penemuan pola sampel → pemrosesan batch kode → Model Bahasa Besar hanya menangani titik krusial", dikombinasikan dengan eksekusi asinkron Batch API, Anda dapat menekan biaya per karakter hingga 5%-15% dari biaya awal. Pada tahap ini, yang Anda butuhkan bukanlah petunjuk yang lebih cerdas, melainkan alur kerja yang lebih terstandarisasi secara teknis.
V. Saran Keputusan Penghematan Token Berdasarkan Tahapan
Berikut adalah ringkasan analisis di atas dalam bentuk tabel praktis yang bisa langsung Anda jadikan panduan:
| Kondisi Pemicu | Rekomendasi Solusi | Tindakan Utama |
|---|---|---|
| Korpus < 50 ribu kata / Eksplorasi sekali jalan | Solusi A: Dialog Langsung | Unggah file, sesuaikan petunjuk, simpan petunjuk yang efektif |
| 50-300 ribu kata / Korpus statis / Analisis bacaan | Solusi C: Basis Pengetahuan Vektor | Gunakan NotebookLM atau bangun RAG sendiri, prioritaskan pengaturan chunk dan top-k |
| > 300 ribu kata / Tugas berulang / Produksi massal | Solusi D: Skrip Batch + Batch API | Minta AI membuatkan skrip, validasi pola secara manual selama periode sampel |
| Data dinamis / Harus tetap di lokal (on-premise) | Solusi B: MCP | Batasi jumlah pemanggilan alat, gunakan pencarian kata kunci dengan hati-hati |
Kombinasi yang sering ditemui dalam proyek nyata adalah "Solusi A di awal, Solusi C di tengah, Solusi D di akhir". Hal ini karena pemahaman tugas bersifat progresif: dialog sampel kecil membantu Anda memahami apa yang harus dilakukan dan apa standar pengukurannya; sampel menengah membantu memvalidasi kualitas pengambilan data dan kemampuan generalisasi; sementara tahap skala besar adalah saat Anda mematenkan alur yang sudah matang ke dalam kode.
Melewati tahap menengah dan langsung menggunakan skrip batch adalah kesalahan umum—Anda akan mendapati skrip tertulis dengan sempurna, namun hasilnya tidak sesuai ekspektasi karena petunjuk awal belum dioptimalkan sepenuhnya. Sebaliknya, terlalu lama bertahan di tahap dialog juga akan membuang-buang Token; tagihan ratusan dolar mungkin hanya menghasilkan beberapa puluh sampel yang efektif.
🎯 Sinyal untuk berpindah tahap: Jika Anda merasa sudah menggunakan petunjuk yang serupa untuk memproses file yang mirip selama 5 kali berturut-turut, itu tandanya Anda harus beralih ke basis pengetahuan vektor; jika setiap tugas mengharuskan Anda mengulang logika pencarian yang sama, itu tandanya Anda harus menulis skrip. Kami menyarankan untuk mengaktifkan prompt caching dan statistik penggunaan di platform APIYI apiyi.com agar keputusan transisi didukung oleh data, bukan sekadar perasaan.
VI. Contoh Minimal Skrip Batch yang Dapat Dijalankan
Agar Solusi D lebih konkret, berikut adalah kerangka skrip batch versi minimalis yang mendemonstrasikan alur inti "Penemuan Sampel → Pematenan Aturan → Eksekusi Massal":
import os, json
from anthropic import Anthropic
# Menggunakan layanan proksi API dari APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Menggunakan Model Bahasa Besar untuk mengekstrak fitur gaya yang terukur dari satu artikel."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Tolong ekstrak fitur gaya penulisan dari artikel Markdown di bawah ini, keluarkan dalam format JSON, mencakup:
- avg_sentence_length: rata-rata panjang kalimat
- paragraph_structure: pola struktur paragraf
- key_phrases: 10 frasa yang paling sering muncul
- tone: label nada (misal: formal/santai/tajam)
Isi artikel:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Periode sampel: Gunakan 10 artikel untuk menemukan pola
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Pematenan aturan: Simpan fitur frekuensi tinggi ke file konfigurasi,
# selanjutnya kode akan langsung menerapkan aturan tersebut
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
Setelah periode sampel selesai, tahap penulisan ulang massal yang sebenarnya dapat sepenuhnya menggunakan aturan dalam style_profile.json melalui kode. Model Bahasa Besar hanya dilibatkan pada langkah "penyempurnaan akhir", sehingga konsumsi Token dapat ditekan dari ratusan ribu menjadi hanya beberapa ribu.
🎯 Saran integrasi API untuk skrip batch:
base_urldi atas mengarah ke titik akhir layanan proksi API APIYI apiyi.com. Anda dapat langsung menggunakan kembali SDK resmi Anthropic tanpa perlu mengubah kode. Kami menyarankan untuk menambahkan logika retry dan pelacakan biaya (cost tracking) di dalam skrip. Saat menjalankan tugas panjang, skrip akan otomatis berhenti jika melebihi anggaran; ini adalah hal yang paling sering menjadi kendala dalam pemrosesan batch skala besar.
VII. Pertanyaan Umum (FAQ)
Q1: Claude Sonnet dan Opus sudah memiliki jendela konteks 1 juta token, bukankah bisa langsung dimasukkan semuanya?
Secara teknis bisa, namun ada dua biaya tersembunyi. Pertama, latensi token pertama akan melambat hingga 20-30 detik, yang membuat pengalaman interaksi menjadi buruk. Kedua, korpus yang sama harus diinput ulang setiap kali sesi dimulai; setelah beberapa kali, biayanya bisa 50-200 kali lebih mahal daripada RAG. Konteks 1M cocok untuk penalaran global satu kali (misalnya, "mencari kontradiksi antar dokumen"), bukan untuk mengakses korpus yang sama berulang kali. Kami menyarankan penggunaan Sonnet 1M di APIYI (apiyi.com) untuk tugas penalaran global dan Haiku untuk tugas pemrosesan batch yang mendetail agar mendapatkan efisiensi biaya terbaik.
Q2: Bagaimana memilih antara NotebookLM dan membangun basis data vektor sendiri?
Jika Anda adalah individu atau tim kecil yang melakukan analisis korpus statis, riset gaya penulisan, atau kueri tanya jawab, NotebookLM adalah yang tercepat untuk digunakan—cukup tarik dan lepas file. Namun, jika Anda perlu menyesuaikan strategi chunking, mengontrol bobot pencarian, menghubungkan ke sistem bisnis, atau menggunakan model dari penyedia lain untuk pembuatan konten, membangun basis data vektor sendiri jauh lebih fleksibel.
Q3: Apakah MCP benar-benar tidak berguna?
Sama sekali tidak. Keunggulan MCP terletak pada skenario di mana "data sering berubah" atau "tidak boleh keluar dari jaringan lokal", seperti membaca log real-time, menanyakan basis data pribadi, atau memanggil API internal. Untuk korpus Markdown statis, RAG hampir lebih unggul di semua dimensi, itulah kesimpulannya.
Q4: Apakah Batch API benar-benar bisa menghemat 50%? Apakah responnya lambat?
Batch API bersifat asinkron, biasanya memberikan hasil dalam waktu 24 jam, dengan harga 50% dari API standar. Ini sangat cocok untuk tugas yang tidak memerlukan real-time, seperti "menyuling gaya penulisan untuk membuat 100 artikel tiruan". Jika digabungkan dengan harga standar konteks 1M, total biaya bisa ditekan hingga 30%-40% dari harga awal. Kami menyarankan untuk menjalankan alur kerja dengan API sinkron di platform APIYI (apiyi.com) terlebih dahulu, baru beralih ke mode Batch untuk produksi massal.
Q5: Bagaimana jika korpus berisi gambar, tabel, dan blok kode?
Markdown sendiri sudah menyimpan struktur ini dengan baik, namun perlu diingat: blok kode yang panjang akan memakan banyak token. Jika Anda hanya menganalisis gaya penulisan, Anda bisa menggunakan skrip untuk memisahkan kode terlebih dahulu. Jika tabel terlalu rumit, disarankan untuk mengubahnya menjadi CSV dan menyimpannya secara terpisah, lalu hanya memberikan ringkasannya kepada Model Bahasa Besar. Ini dapat menghemat lebih dari 30% token.
VIII. Kesimpulan
Kembali ke pertanyaan awal: cara mana yang harus digunakan untuk memberikan ratusan ribu kata Markdown ke Model Bahasa Besar? Jawabannya bukan pilihan tunggal, melainkan kombinasi bertahap. Gunakan unggahan langsung dalam percakapan untuk tahap eksplorasi sampel kecil, gunakan basis data pengetahuan vektor atau NotebookLM untuk tahap riset skala menengah, dan gunakan skrip pemrosesan batch yang dikombinasikan dengan Batch API untuk tahap produksi skala besar. Ubah peran Model Bahasa Besar dari "pelaksana" menjadi "penemu pola", karena kodenya lah yang sebenarnya bertanggung jawab menangani beban kerja besar.
Setelah memahami alur ini, efisiensi token untuk korpus Markdown pada Model Bahasa Besar bukan lagi tentang "memilih alat yang mana", melainkan "memilih kombinasi yang tepat untuk setiap tahap". Jika Anda saat ini terjebak di tahap tertentu dan ragu untuk beralih, Anda bisa menjalankan evaluasi skala kecil di platform APIYI (apiyi.com). Bandingkan tiga data: biaya per seribu kata, akurasi pencarian, dan latensi token pertama; keputusan Anda akan jauh lebih jelas. Semoga perbandingan ini membantu Anda menghindari jalan pintas yang salah dan mengalokasikan anggaran pada bagian yang benar-benar menghasilkan nilai.
—— Tim APIYI (api.apiyi.com)