Récemment, j'ai reçu une question très classique : un utilisateur souhaite « distiller » des centaines de milliers de mots écrits par un expert en rédaction pour servir de base de style à un grand modèle de langage, mais il ne sait pas comment intégrer ses corpus Markdown de la manière la plus rentable. Les trois approches courantes sont : importer les fichiers un par un dans des outils de discussion comme Cherry Studio, utiliser MCP pour permettre au modèle d'accéder directement aux fichiers sur le disque dur, ou tout intégrer dans une base de connaissances pour faire du RAG. À première vue, toutes ces méthodes fonctionnent, mais dès que le volume dépasse les 300 000 mots, la facture de jetons (tokens) et la latence divergent rapidement, et un mauvais choix peut facilement multiplier votre budget par dix.
Cet article décortique quatre solutions majeures pour économiser des jetons lors de l'utilisation de corpus Markdown avec un grand modèle de langage : consommation réelle de jetons, coût par tâche, latence du premier jeton, contrôlabilité et choix optimal selon le volume du corpus. Enfin, je vous proposerai une feuille de route décisionnelle par étapes : quoi utiliser pour l'exploration initiale et vers quoi migrer une fois passé à l'échelle. Si vous travaillez sur la distillation de style, les questions-réponses sur base de connaissances ou le nettoyage de données avant un fine-tuning, cette lecture vous permettra de faire le bon choix opérationnel.
I. Le problème central de l'économie de jetons pour les corpus Markdown
Avant de décomposer les solutions, clarifions où se situe réellement le coût. Alimenter un grand modèle avec des centaines de milliers de mots en Markdown revient à arbitrer entre quatre types de coûts : les jetons d'entrée, les jetons de sortie, les coûts de recherche/indexation et les coûts de débogage humain.
Les jetons d'entrée sont souvent les plus sous-estimés. Si un article technique est au format HTML brut, le convertir en Markdown permet généralement d'économiser 70 % à 80 % des jetons, car les balises, les styles et les scripts intégrés sont supprimés. C'est pourquoi la première étape de toute chaîne de traitement de grands corpus consiste à uniformiser le contenu en Markdown ou en txt. Si vous réussissez cette étape, la base de coût de n'importe quelle méthode d'alimentation sera réduite d'un cran.
Les jetons de sortie semblent sans rapport, mais dans les tâches de « distillation », ils constituent en fait un goulot d'étranglement invisible. Claude Sonnet et Opus ont standardisé la tarification avec une fenêtre de contexte d'un million de jetons (3 $/M en entrée pour Sonnet, 5 $/M pour Opus). En théorie, vous pourriez tout injecter d'un coup, mais la sortie maximale par réponse reste limitée à quelques dizaines de milliers de jetons, ce qui signifie que vous ne pouvez pas effectuer une réécriture complète en un seul appel. La tâche doit être segmentée, ce qui rend les scripts de traitement par lots souvent plus adaptés aux scénarios à grande échelle que les conversations interactives.
🎯 Conseils de préparation avant le choix : Avant de choisir une solution, effectuez un nettoyage et une normalisation du format de tous vos fichiers Markdown. Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester d'abord sur de petits échantillons, confirmer la consommation réelle de jetons par millier de mots, puis décider si vous optez pour des outils de discussion ou des scripts de traitement par lots, afin d'éviter que les coûts ne deviennent incontrôlables par la suite.
2. Différences fondamentales et limites d'application des 4 approches
Chacune de ces quatre approches possède des limites claires en termes de capacités. Il est bien plus important de comprendre ces différences que de mémoriser des paramètres techniques.
2.1 Approche A : Téléchargement direct via des outils de chat comme Cherry Studio
C'est la méthode la plus accessible. Des outils comme Cherry Studio, Claude Desktop ou ChatGPT vous permettent de glisser-déposer plusieurs fichiers Markdown directement dans la fenêtre de discussion. Le modèle concatène alors tout le contenu pour en faire une longue invite. L'avantage est une ingénierie quasi nulle et un résultat immédiat. L'inconvénient est qu'à chaque nouvelle session, il faut tout recharger, ce qui entraîne une consommation excessive de jetons (tokens), sans compter que la quantité de fichiers est limitée par la fenêtre de contexte.
Pour des tâches sur de petits échantillons (moins de 25 000 mots), cette méthode est la plus efficace, car vous pouvez ajuster les résultats en langage naturel au fur et à mesure. Cependant, dès que le corpus dépasse 100 000 mots, vous rencontrerez fréquemment des troncatures de contexte, des latences importantes (le premier jeton peut prendre 20 à 30 secondes) et des coûts répétitifs.
2.2 Approche B : Connexion directe aux fichiers locaux via MCP
Le protocole MCP (Model Context Protocol) permet au modèle de lire les fichiers de votre disque dur comme s'il utilisait un outil. Cela semble élégant : le modèle pioche ce dont il a besoin sans tout charger. Mais en pratique, la consommation de jetons via MCP est souvent sous-estimée : même si un appel d'outil ne nécessite que 3 champs JSON, la structure complète est envoyée dans le contexte. Le mode de correspondance par mots-clés consomme environ 3 fois plus de jetons qu'une recherche vectorielle.
La véritable force du MCP réside dans les sources de données dynamiques, comme les journaux en temps réel, les données privées des utilisateurs ou les données financières qui doivent rester localement. Pour des scénarios classiques comme « des centaines de milliers de mots en Markdown statique », le MCP est un peu comme utiliser un marteau-pilon pour écraser une mouche, et il risque d'épuiser votre fenêtre de contexte lors d'appels multiples.
2.3 Approche C : Base de connaissances vectorisée / NotebookLM
Découper tous les fichiers, les intégrer (embedding) et les stocker pour les appeler via une recherche sémantique à la demande : c'est la voie du RAG. Un pipeline RAG bien conçu ne récupère que 5 à 20 segments (chunks) par requête, soit généralement 2 000 à 10 000 jetons, ce qui permet d'économiser 50 à 200 fois les jetons d'entrée par rapport à un chargement complet.
NotebookLM est une solution RAG clé en main proposée par Google. Il gère automatiquement l'intégration, la recherche et les citations, ce qui est idéal pour l'analyse de style, les revues de littérature ou les questions-réponses sur des notes. Sa limite est que les réponses se basent uniquement sur les fichiers sources et ne s'appuient pas sur les données d'entraînement du modèle. Si vous avez besoin de stratégies de recherche complexes ou d'un raisonnement en plusieurs étapes, construire votre propre base de connaissances vectorielle sera plus flexible.
🎯 Conseil pour l'approche C : La qualité de la recherche dans une base vectorielle détermine directement la qualité de la sortie. Le découpage des segments (chunking), le modèle d'embedding et le top-k de recherche doivent être optimisés en fonction de votre corpus. Nous vous recommandons d'effectuer d'abord un test à petite échelle avec Claude ou GPT sur la plateforme APIYI (apiyi.com) pour comparer la précision des réponses selon différents paramètres de recherche, avant de décider entre NotebookLM ou une solution faite maison.
2.4 Approche D : Scripts de traitement par lots (la solution optimale à grande échelle)
C'est l'approche la plus soulignée dans la réponse initiale : demandez à l'IA de vous écrire un script de traitement par lots. Utilisez d'abord le grand modèle de langage pour traiter 5 à 10 échantillons, identifiez manuellement ou automatiquement les modèles réutilisables (modèles de phrases, structures de paragraphes, distribution des mots-clés), puis intégrez ces règles dans le code. Laissez le code traiter les centaines de milliers de mots restants, le grand modèle de langage n'intervenant que sur les points critiques.
Il s'agit essentiellement d'une « descente de règles » : le grand modèle de langage sert à découvrir des motifs, et le code se charge de l'exécution en masse. Avec l'API Batch de Claude/GPT (réduction de 50 %), le coût global ne représente généralement que 5 % à 15 % de l'approche A. L'inconvénient est qu'elle nécessite 1 à 2 jours d'investissement technique, ce qui n'est pas adapté aux tâches ponctuelles.
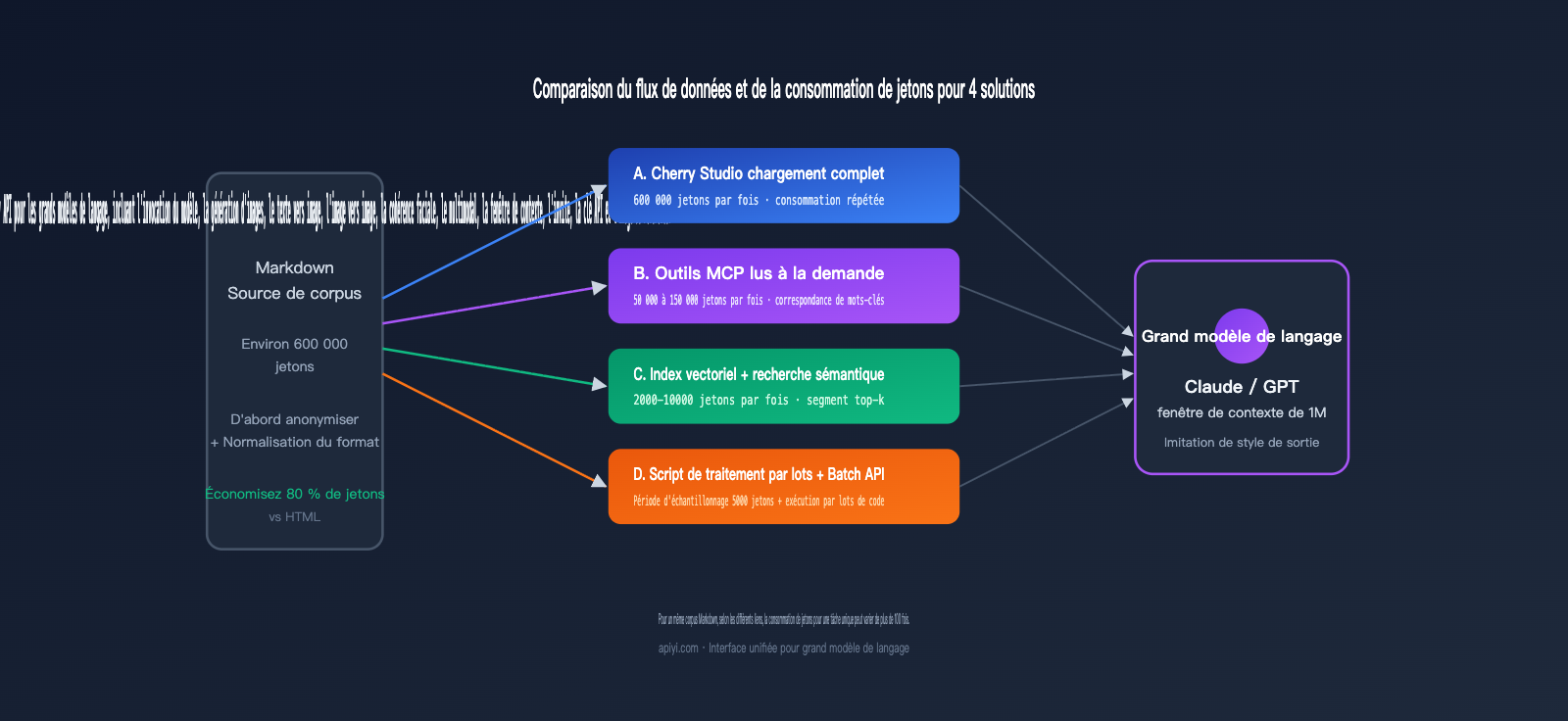
三、Comparaison de la consommation de jetons et des coûts pour 4 solutions
Pour vraiment calculer la rentabilité, il faut traduire les différences abstraites en chiffres. Le tableau suivant compare les solutions sur un scénario concret : un utilisateur souhaite distiller 300 000 mots de corpus Markdown (environ 600 000 jetons) pour générer 100 articles imitant un style spécifique (environ 2 000 mots chacun).
| Solution | Jetons d'entrée (par exécution) | Total jetons d'entrée | Total jetons de sortie | Coût estimé (Sonnet) | Latence (premier jeton) |
|---|---|---|---|---|---|
| A. Outil de chat direct | 600 000 | 60 millions (100 fois) | 6 millions | ≈ 270 $ | 20-30 s |
| B. Accès fichier MCP | 50-150 000 (par lots) | 15 millions | 6 millions | ≈ 135 $ | 8-15 s |
| C. Base de connaissances vectorielle | 5 000-10 000 | 1 million | 6 millions | ≈ 93 $ | 1-2 s |
| D. Script de traitement par lots + Batch API | 5 000 (échantillonnage) + traitement code | 1 million | 6 millions | ≈ 46 $ | Asynchrone |
On constate que le coût de la solution D ne représente qu'environ 17 % de celui de la solution A, avec une latence bien plus stable. Si l'on ajoute la réduction de 50 % offerte par la Batch API, le coût réel de la solution D peut encore être divisé par deux. Depuis que Claude a standardisé la tarification pour les contextes de 1M de jetons, la solution A n'est plus surtaxée, mais le gaspillage lié à la saisie répétée du même corpus demeure — c'est le défaut inhérent aux flux de travail conversationnels.
🎯 Conseil pour la vérification des coûts : Les coûts ci-dessus sont basés sur les tarifs publics. Les chiffres réels peuvent varier de 30 à 50 % selon la conception de votre invite, le taux de réussite de la mise en cache et l'activation du "prompt caching". Nous vous recommandons d'activer le suivi de la consommation sur la console APIYI (apiyi.com), de vérifier vos comptes quotidiennement pendant les 3 premiers jours pour transformer votre budget abstrait en courbes visualisables, avant de décider de migrer davantage de tâches vers la Batch API.
Le tableau suivant intègre la complexité technique des quatre solutions pour une comparaison transversale :
| Dimension | A. Chat direct | B. MCP | C. Base vectorielle | D. Script de traitement par lots |
|---|---|---|---|---|
| Investissement technique | Presque nul | Moyen | Moyen à élevé | Élevé (initial) |
| Temps de prise en main | 5 minutes | 1-2 heures | 0,5 à 1 jour | 1-2 jours |
| Reproductibilité | Faible (historique perdu) | Moyenne | Forte | Très forte |
| Échelle de corpus adaptée | < 50 000 mots | 50-300 000 mots (dynamique) | 100 000 – 10 M mots (statique) | > 300 000 mots |
| Contrôle de la sortie | Limité par la fenêtre de contexte | Limité par les appels d'outils | Limité par la qualité de recherche | Entièrement contrôlable |
四、Recommandations selon l'échelle du corpus
Appliquer ces solutions à des scénarios concrets rend les choses plus claires. Voici des recommandations selon trois échelles de volume.
4.1 Petit corpus (< 50 000 mots) : Phase d'exploration
L'objectif ici est de valider rapidement des idées, pas d'optimiser les coûts. La solution A (chat direct) est le choix le plus rationnel : glissez tous vos fichiers dans Cherry Studio ou Claude Desktop et discutez directement avec le modèle pour affiner votre invite. À ce stade, concentrez-vous sur : le modèle saisit-il vraiment les caractéristiques de style de l'auteur cible ? Quelles dimensions sont quantifiables (longueur des phrases, vocabulaire, structure) ? Lesquelles sont subjectives (ton, rythme) ? Le coût est dérisoire pour ces petits échantillons, quelques dollars suffisent.
4.2 Corpus moyen (50 000 – 300 000 mots) : Phase de recherche et analyse
Dans cette fourchette, les coûts de saisie répétée de la solution A vont exploser. La meilleure pratique consiste à passer à la solution C (base de connaissances vectorielle) ou à NotebookLM. Une fois les échantillons indexés, utilisez la recherche sémantique pour les appeler à la demande. Si vous faites simplement de l'analyse de contenu, de la synthèse de style ou de l'exploration par questions-réponses, NotebookLM ne demande quasiment aucun effort technique. Pour des raisonnements complexes en plusieurs étapes, construisez votre propre système RAG basé sur Claude ou GPT.
🎯 Conseil pour le choix de taille moyenne : NotebookLM est idéal pour la lecture et l'analyse pure, mais ne permet pas de personnaliser les stratégies de recherche ou les flux de travail complexes. Nous vous suggérons d'utiliser la plateforme APIYI (apiyi.com) pour connecter Claude Sonnet ou Opus avec une fenêtre de contexte de 1M de jetons pour votre RAG. Vous bénéficierez d'une tarification standard tout en contrôlant finement le nombre de segments (chunks) et le poids de la recherche, idéal pour les corpus à long terme.
4.3 Grand corpus (> 300 000 mots) : Phase de production
À l'échelle de plusieurs centaines de milliers, voire millions de mots, la solution D (script de traitement par lots) est pratiquement la seule option viable. Divisez votre flux de travail en trois étapes : « découverte des motifs dans les échantillons → traitement par lots via code → invocation du modèle uniquement pour les nœuds critiques ». En utilisant la Batch API de manière asynchrone, vous pouvez réduire le coût par mot à 5-15 % du coût initial. À ce stade, ce dont vous avez besoin n'est pas une invite plus intelligente, mais un pipeline plus robuste.
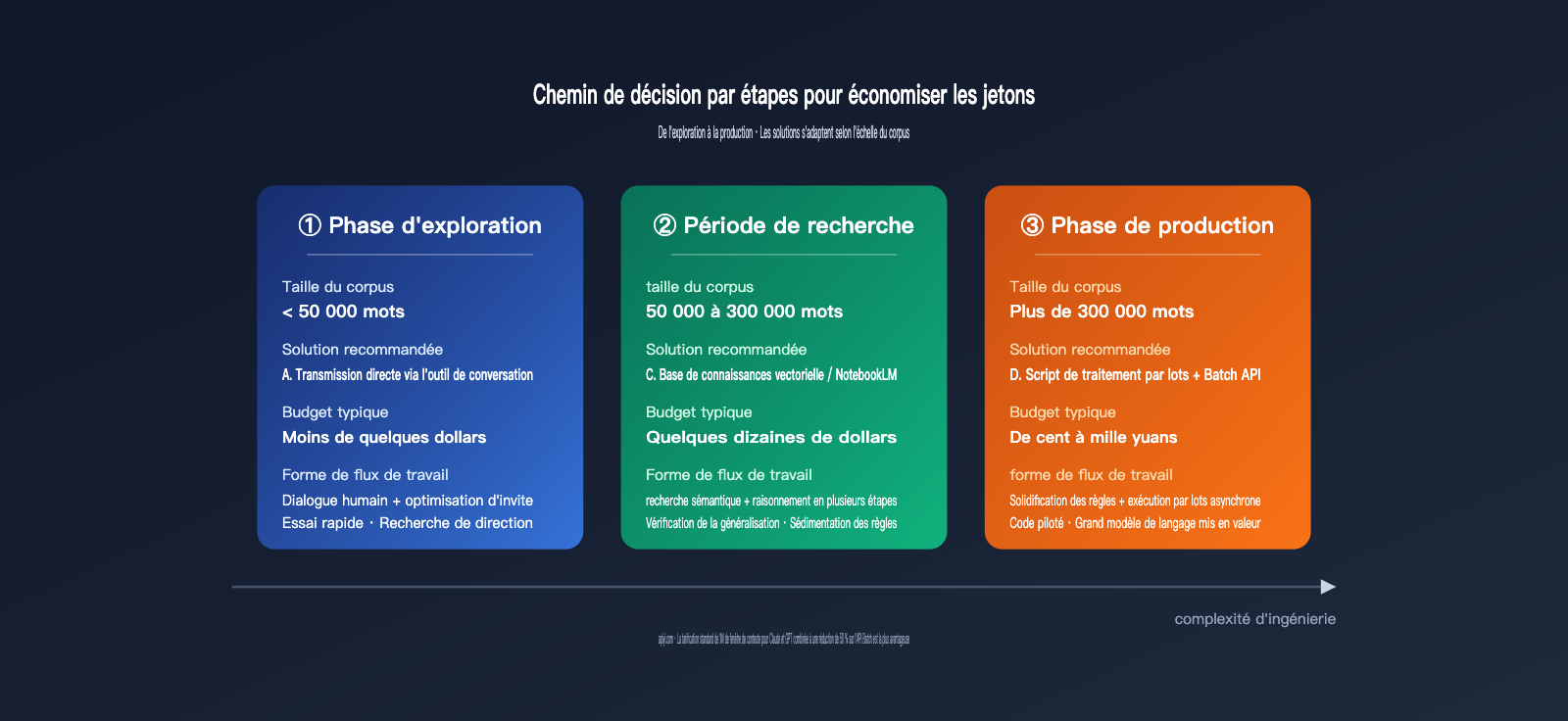
V. Conseils de décision pour économiser des jetons par étapes
Voici un tableau récapitulatif des stratégies à adopter, que vous pouvez suivre directement selon vos besoins :
| Conditions de déclenchement | Solution recommandée | Actions clés |
|---|---|---|
| Corpus < 50 000 mots / Exploration ponctuelle | Solution A : Dialogue direct | Glisser-déposer le fichier, ajuster l'invite, noter les invites efficaces |
| 50 000 – 300 000 mots / Corpus statique / Analyse de lecture | Solution C : Base de connaissances vectorielle | Choisir NotebookLM ou un RAG auto-hébergé, privilégier le réglage du chunk et du top-k |
| Plus de 300 000 mots / Tâches répétitives / Production de masse | Solution D : Script de traitement par lots + Batch API | Demander à l'IA d'écrire le script, validation humaine des modèles lors de la phase d'échantillonnage |
| Données dynamiques / Confidentialité locale requise | Solution B : MCP | Limiter les appels d'outils, utiliser la recherche par mots-clés avec prudence |
La combinaison la plus courante dans les projets réels est « Solution A au démarrage, Solution C au milieu, Solution D pour la finalisation ». La compréhension d'une tâche est un processus progressif : les petits échantillons de dialogue vous aident à clarifier vos objectifs et vos critères d'évaluation ; les échantillons moyens permettent de vérifier la qualité de la recherche et la capacité de généralisation ; la phase à grande échelle consiste à figer les processus matures dans le code.
Sauter les étapes intermédiaires pour passer directement aux scripts de traitement par lots est une erreur classique : vous découvrirez que le script est parfait, mais que les résultats ne sont pas à la hauteur, car l'invite initiale n'a pas été suffisamment optimisée. À l'inverse, rester trop longtemps au stade du dialogue gaspille des jetons ; une facture de plusieurs centaines de dollars peut ne produire que quelques dizaines d'échantillons utiles.
🎯 Signaux pour changer d'étape : Si vous constatez que vous utilisez des invites similaires pour traiter des fichiers analogues lors de 5 conversations consécutives, il est temps de passer à la base de connaissances vectorielle. Si vous devez répéter la même logique de recherche à chaque tâche, il est temps d'écrire un script. Nous vous recommandons d'activer la mise en cache des invites et le suivi de la consommation sur la plateforme APIYI (apiyi.com) pour basculer au bon moment, en vous basant sur des données plutôt que sur votre intuition.
VI. Exemple minimal fonctionnel d'un script de traitement par lots
Pour rendre la Solution D plus concrète, voici une structure de script simplifiée illustrant le processus clé : « Découverte d'échantillons → Figer les règles → Exécution par lots » :
import os, json
from anthropic import Anthropic
# Utilisation du service proxy API APIYI
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""Utilise un grand modèle de langage pour extraire des caractéristiques de style quantifiables d'un article."""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
Veuillez extraire les caractéristiques de style rédactionnel de l'article Markdown ci-dessous et générer un JSON contenant :
- avg_sentence_length : longueur moyenne des phrases
- paragraph_structure : modèle de structure des paragraphes
- key_phrases : top 10 des expressions fréquentes
- tone : étiquette de ton (ex: rigoureux/vulgarisé/incisif)
Contenu de l'article :
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# Phase d'échantillonnage : utiliser 10 articles pour découvrir les modèles
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# Figer les règles : enregistrer les caractéristiques fréquentes dans un fichier de configuration
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
Une fois la phase d'échantillonnage terminée, la phase de réécriture massive peut appliquer directement les règles du fichier style_profile.json via le code. Le grand modèle de langage n'intervient alors que pour la « retouche finale », ce qui permet de réduire la consommation de jetons de plusieurs centaines de milliers à quelques milliers.
🎯 Conseil pour l'intégration API : Le
base_urlci-dessus pointe vers le point de terminaison du service proxy API d'APIYI. Vous pouvez réutiliser le SDK officiel d'Anthropic sans modifier votre code. Nous vous conseillons d'ajouter une logique de nouvelle tentative (retry) et de suivi des coûts dans vos scripts. C'est le point critique lors de l'exécution de tâches à grande échelle pour éviter de dépasser votre budget.
VII. FAQ – Questions fréquentes
Q1 : Claude Sonnet et Opus disposent tous deux d'une fenêtre de contexte de 1 million de jetons, pourquoi ne pas tout y insérer directement ?
Techniquement, c'est faisable, mais cela entraîne deux coûts cachés. Premièrement, la latence du premier jeton peut atteindre 20 à 30 secondes, ce qui dégrade l'expérience utilisateur. Deuxièmement, comme le même corpus doit être réinjecté à chaque session, cela revient 50 à 200 fois plus cher que le RAG. Une fenêtre de 1M de jetons est idéale pour un raisonnement global ponctuel (comme "détecter des contradictions entre plusieurs documents"), mais n'est pas adaptée à un accès répété au même corpus. Nous recommandons d'utiliser Sonnet 1M sur APIYI (apiyi.com) pour les tâches de raisonnement global et Haiku pour les tâches de traitement par lots, afin d'obtenir le meilleur rapport coût-efficacité.
Q2 : Comment choisir entre NotebookLM et la création de sa propre base de données vectorielle ?
Si vous êtes un particulier ou une petite équipe effectuant de l'analyse de corpus statique, de la recherche de style ou des requêtes de questions-réponses, NotebookLM est la solution la plus rapide : il suffit de glisser-déposer vos fichiers. Si vous avez besoin de personnaliser la stratégie de découpage (chunking), de contrôler les poids de recherche, de vous connecter à des systèmes métier ou d'utiliser les modèles d'autres fournisseurs pour la génération, une base de données vectorielle auto-hébergée sera beaucoup plus flexible.
Q3 : Le MCP est-il vraiment inutile ?
Absolument pas. La force du MCP réside dans les scénarios où les données changent fréquemment ou ne peuvent pas quitter l'environnement local, comme la lecture de journaux en temps réel, l'interrogation de bases de données privées ou l'appel d'API internes. Pour un corpus Markdown statique, le RAG est supérieur sur presque tous les plans, c'est là que réside la nuance.
Q4 : L'API Batch permet-elle vraiment d'économiser 50 % ? La réponse est-elle lente ?
L'API Batch est asynchrone, les résultats sont généralement renvoyés sous 24 heures, et le prix est de 50 % par rapport à l'API standard. C'est parfait pour des tâches qui ne nécessitent pas de temps réel, comme "générer 100 articles en imitant un style d'écriture". En combinant cela avec la tarification standard pour 1M de jetons de contexte, le coût global peut être réduit à 30-40 % du coût initial. Nous vous conseillons de tester votre flux sur la plateforme APIYI (apiyi.com) avec l'API synchrone, puis de passer au mode Batch pour la production à grande échelle.
Q5 : Que faire si le corpus contient des images, des tableaux et des blocs de code ?
Le format Markdown préserve déjà très bien ces structures, mais attention : les longs blocs de code consomment énormément de jetons. Si vous analysez uniquement le style rédactionnel, vous pouvez utiliser un script pour extraire le code au préalable. Si les tableaux sont trop complexes, il est conseillé de les convertir en CSV et de les stocker séparément, en ne fournissant qu'un résumé au Grand modèle de langage, ce qui permet d'économiser plus de 30 % de jetons supplémentaires.
VIII. Conclusion
Pour revenir à la question initiale : quelle méthode utiliser pour alimenter un Grand modèle de langage avec des centaines de milliers de mots en Markdown ? La réponse n'est pas un choix unique, mais une combinaison par étapes. Pour la phase d'exploration sur petit échantillon, le transfert direct par chat est le plus rapide. Pour la phase de recherche à échelle moyenne, une base de connaissances vectorielle ou NotebookLM est le plus stable. Pour la phase de production à grande échelle, il faut impérativement passer à des scripts de traitement par lots combinés à l'API Batch, afin de faire passer le Grand modèle de langage du rôle d'« exécutant » à celui de « découvreur de modèles », le code étant alors la véritable force motrice du volume.
Une fois ce parcours compris, l'optimisation des jetons pour vos corpus Markdown ne consiste plus à choisir un outil, mais à déterminer quelle combinaison utiliser à chaque étape. Si vous êtes bloqué à une étape et hésitez à changer de méthode, commencez par effectuer une évaluation à petite échelle sur la plateforme APIYI (apiyi.com). Comparez trois indicateurs : le coût par millier de mots, la précision de la recherche et la latence du premier jeton. Votre décision sera beaucoup plus claire. Nous espérons que cette comparaison vous évitera quelques détours et vous permettra d'investir votre budget là où il génère réellement de la valeur.
— L'équipe APIYI (api.apiyi.com)