最近、ある典型的なご相談をいただきました。それは、ある熟練ライターの数十万字に及ぶ文章を「蒸留」し、大規模言語モデルにスタイルとして学習させたいが、Markdown形式のコーパスをどのように入力するのが最もコスト効率が良いか分からない、というものです。よくあるアプローチとして、「Cherry Studioのような対話ツールにファイルを一つずつアップロードする」「MCP(Model Context Protocol)を使ってモデルにローカルファイルを直接読み込ませる」「すべてをナレッジベースに投入してRAG(検索拡張生成)を行う」といった3つの方法が挙げられます。一見どれも上手くいきそうですが、コーパスの規模が30万字を超えると、トークン料金と応答遅延に大きな差が生まれ、選択を誤ると予算が10倍以上跳ね上がることも珍しくありません。
本記事では、大規模言語モデルにおけるMarkdownコーパスのトークン節約に関する4つの主要な手法を徹底比較します。実際のトークン消費量、1回あたりのタスクコスト、初回トークン遅延、制御性、そしてコーパス規模ごとの最適な選択肢を解説します。最後に、段階的な意思決定パス(初期の探索段階で何を使うか、規模拡大後に何へ切り替えるべきか)を提示します。スタイル蒸留、ナレッジベースの構築、あるいは微調整(ファインチューニング)前のデータクレンジングを行っている方にとって、すぐに実践できる選定ガイドとなるはずです。
1. 大規模言語モデルにおけるMarkdownコーパスのトークン節約の核心
手法を分解する前に、この問題のコストがどこで発生しているのかを明確にしましょう。数十万字のMarkdownを大規模言語モデルに読み込ませることは、本質的に「入力トークン」「出力トークン」「検索・インデックスコスト」「人的デバッグコスト」という4つのコストのバランスを取る作業です。
入力トークンは最も過小評価されがちな項目です。技術ブログがHTML形式であれば、Markdownに変換するだけで通常70%〜80%のトークンを節約できます。これはタグ、スタイル、埋め込みスクリプトが削除されるためです。これが、大規模コーパスを扱うパイプラインの第一歩として、すべてのコンテンツをMarkdownやtxtに統一すべき理由です。ここを最適化できれば、その後の入力方式によるコストのベースラインを一段下げることができます。
出力トークンは一見無関係に見えますが、「蒸留」タスクにおいては隠れたボトルネックとなります。Claude SonnetやOpusは100万トークンのコンテキストウィンドウを標準価格(Sonnet入力 $3/M、Opus入力 $5/M)で提供しており、理論上は数十万字を一度に投入可能です。しかし、1回の応答あたりの最大出力トークン数は依然として数万トークンに制限されているため、1回の呼び出しで全量の書き換えを完了させることはできません。タスクを細分化する必要があり、この点が、対話型ツールよりもバッチ処理スクリプトの方が大規模なシナリオに適していると判断される直接的な理由となります。
🎯 選定前の準備アドバイス: 手法を選ぶ前に、すべてのMarkdownファイルに対して脱感作(機密情報の削除)とフォーマットの正規化を行ってください。APIYI (apiyi.com) プラットフォームを通じて、まずは小規模なサンプルでテストを行い、1000字あたりの実際のトークン消費量を確認してから、対話ツールを使うかバッチ処理スクリプトを使うかを決定することをお勧めします。これにより、後々のコスト超過を防ぐことができます。
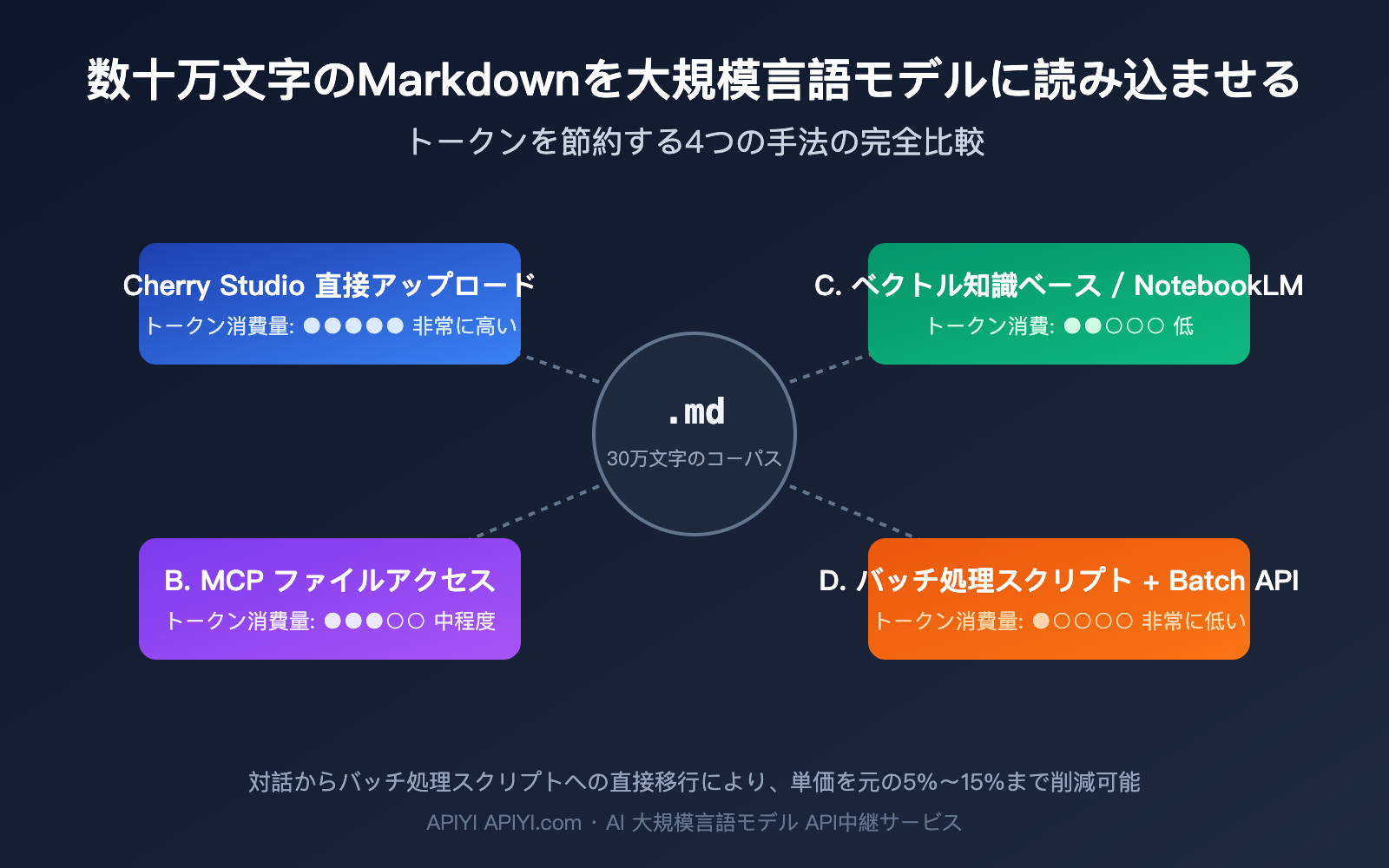
二、4 種類のソリューションの核心的な違いと適用範囲
4 つのソリューションにはそれぞれ明確な能力の境界線があります。パラメータを暗記するよりも、これらの違いを理解することが重要です。
2.1 ソリューション A:Cherry Studio などの対話ツールへの直接アップロード
これは最もハードルが低い方法です。Cherry Studio、Claude Desktop、ChatGPT などのツールでは、複数の Markdown ファイルを直接チャットボックスにドラッグ&ドロップでき、モデルがすべてのファイル内容を一つの長いプロンプトとして処理します。メリットは、エンジニアリング作業が不要で、見たままの結果が得られる点です。デメリットは、新しいセッションを開くたびにファイルを再読み込みする必要があり、トークンの無駄な消費が激しいこと、そして一度に投入できるファイル量がコンテキストウィンドウの制限に縛られることです。
5 万文字以内の小規模なタスクであれば、自然言語で対話しながら調整できるため、かえってこの方法が最も効率的です。しかし、コーパスが 20 万文字を超えると、コンテキストの切断、長いコンテキストによる遅延(最初のトークンが出るまでに 20〜30 秒かかることも)、そして重複するコストの問題に頻繁に直面することになります。
2.2 ソリューション B:MCP によるローカルファイルへの直接接続
MCP(Model Context Protocol)は、モデルがツールを呼び出すように、ハードディスク上のファイルを読み込めるようにするものです。一見非常にスマートで、モデルが必要に応じて読み込むため、全量をロードする必要がないように思えます。しかし、実際に試してみると、MCP のトークン消費量は過小評価されがちです。ツール呼び出しで返される JSON は、たとえ 3 つのフィールドしか必要なくても、構造全体がコンテキストに含まれてしまうため、キーワードマッチング方式はベクトル検索よりも約 3 倍多くのトークンを消費します。
MCP の真の強みは、リアルタイムのログ、ユーザーのプライベートデータ、あるいはローカル環境から外に出してはいけない財務データなど、動的に変化するデータソースにあります。「数十万文字の静的な Markdown」という典型的なシナリオにおいて、MCP は「鶏を割くに焉んぞ牛刀を用いん(大げさすぎる)」状態であり、複数回の呼び出しでコンテキストウィンドウを早期に使い果たしてしまうリスクがあります。
2.3 ソリューション C:ベクトル知識ベース / NotebookLM
すべてのファイルを分割(チャンク化)、埋め込み(エンベディング)してデータベースに格納し、セマンティック検索によって必要な断片を呼び出す。これが RAG(検索拡張生成)のルートです。適切に設計された RAG パイプラインであれば、1 回のクエリで 5〜20 個のチャンクのみを検索し、合計で 2,000〜10,000 トークン程度に収まるため、全量ロードと比較して入力トークンを 50〜200 倍節約できます。
NotebookLM は Google が提供するすぐに使える RAG 製品で、埋め込み、検索、引用を自動的に処理します。執筆スタイルの分析、文献レビュー、ノートの Q&A といった読み込み中心のタスクに適しています。その限界は、回答がソースファイルのみに基づいているため、学習データと積極的に関連付けたりすることができず、カスタマイズ性が限定的である点です。複雑な検索戦略や多段階の推論が必要な場合は、自前でベクトル知識ベースを構築する方が柔軟です。
🎯 ソリューション C 導入のアドバイス: ベクトル知識ベースの検索品質が、そのまま出力品質を決定します。チャンクの分割方法、埋め込みモデル、検索の top-k 設定などは、コーパスに合わせて調整が必要です。APIYI (apiyi.com) プラットフォームで、まずは Claude や GPT を使って小規模な評価を行い、異なる検索パラメータでの回答精度を比較してから、NotebookLM を使うか自作するかを決定することをお勧めします。
2.4 ソリューション D:AI によるバッチ処理スクリプトの作成(規模拡大における最適解)
これは元の回答で最も強調されていたソリューションです。AI にバッチ処理スクリプトを書かせ、まずは大規模言語モデルで 5〜10 個のサンプルデータを処理し、人間または自動化によって再利用可能なルール(文型テンプレート、段落構造、キーワード分布など)を特定します。その後、そのルールをコードに固定し、残りの数十万文字をコードで処理させ、大規模言語モデルは重要なポイントでのみ介入させるという方法です。
これは本質的に「ルールの沈み込み」です。大規模言語モデルはパターンを発見するために使い、コードがバッチ実行を担います。Claude/GPT の Batch API(50% 割引)と組み合わせれば、全体のコストは通常、ソリューション A の 5%〜15% に抑えられます。デメリットは、初期段階で 1〜2 日のエンジニアリング工数が必要になるため、単発のタスクには向いていない点です。
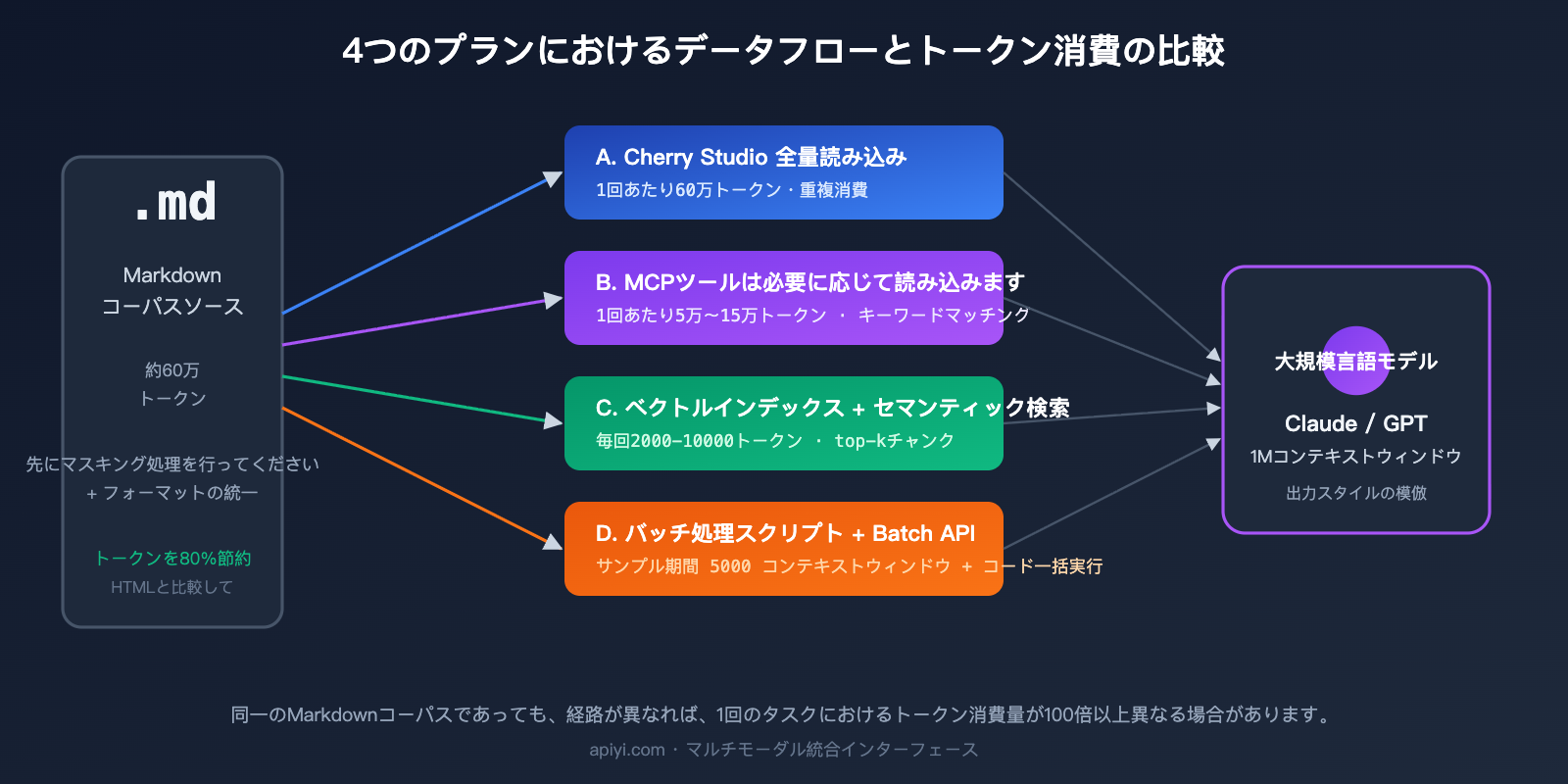
三、4 种方案的 Token 消耗与成本对比
抽象的差异只有落实到数字上,才能真正算出账。下表基于一个具体场景进行了对比:用户需要对 30 万字的 Markdown 语料(约 60 万 Token)进行提炼,并最终输出 100 篇风格仿写文章(每篇约 2000 字)。
| 方案 | 单次输入 Token | 总输入 Token | 总输出 Token | 估算成本(Sonnet) | 首 Token 延迟 |
|---|---|---|---|---|---|
| A. 对话工具直传 | 60 万 | 6000 万(100 次) | 600 万 | ≈ $270 | 20-30 秒 |
| B. MCP 文件访问 | 5-15 万(分次) | 1500 万 | 600 万 | ≈ $135 | 8-15 秒 |
| C. 向量知识库 | 5000-1 万 | 100 万 | 600 万 | ≈ $93 | 1-2 秒 |
| D. 批处理脚本 + Batch API | 5000(样本期)+ 代码处理 | 100 万 | 600 万 | ≈ $46 | 非同步 |
可以看出,方案 D 的成本仅为方案 A 的约 17%,且延迟最为稳定。如果再叠加 Batch API 的 50% 折扣,方案 D 的实际花费还能再降低一半。虽然 Claude 1M context 将超长上下文纳入标准定价后,方案 A 不再被加价 2 倍,但重复输入相同语料的浪费依然存在——这是对话式工作流难以规避的硬伤。
🎯 成本验证建议:上述成本是基于公开报价估算,实际数字会因プロンプト设计、缓存命中率、是否启用プロンプト缓存而有 30%-50% 的浮动。我们建议在 APIYI (apiyi.com) 控制台开启用量监控,前 3 天每天对账,将抽象的预算转化为可视化的曲线,再决定是否将更多任务迁移至 Batch API。
下表将四种方案的工程复杂度也纳入其中,方便进行横向对比:
| 维度 | 方案 A 对话直传 | 方案 B MCP | 方案 C 向量知识库 | 方案 D 批处理脚本 |
|---|---|---|---|---|
| 工程投入 | 几乎为零 | 中等 | 中等偏高 | 高(前期) |
| 上手时间 | 5 分钟 | 1-2 小时 | 半天到 1 天 | 1-2 天 |
| 可复现性 | 弱(对话历史易丢失) | 中 | 强 | 极强 |
| 适合语料规模 | < 5 万字 | 5-30 万字动态数据 | 10 万字 – 1000 万字静态 | 30 万字以上 |
| 输出可控性 | 受上下文长度限制 | 受工具调用次数限制 | 受检索质量限制 | 完全可控 |
四、不同语料规模下的场景推荐
将方案套入具体场景会更加直观。以下针对三种规模给出推荐路径。
4.1 小语料(< 5 万字)学习探索期
此时的核心目标是快速验证想法,而非追求成本最优。方案 A 对话直传是最合理的选择,将所有文件拖入 Cherry Studio 或 Claude Desktop,直接与模型对话并调试プロンプト。这一阶段应重点关注:模型是否真的能抓住目标作者的风格特征?哪些维度是可量化的(句长、用词、句式)?哪些是模糊的(语气、节奏)?这些问题在小样本下成本极低,仅需几美元即可完成测试。
4.2 中等语料(5-30 万字)研究分析期
进入此区间,方案 A 的重复输入开销会迅速膨胀。此时的最佳实践是切换至方案 C 向量知识库或 NotebookLM,将样本写入向量库后,通过语义检索按需调用。如果仅进行内容分析、风格归纳、问答式探索,NotebookLM 几乎零工程量即可运行;若需要更复杂的多步推理,则可自行搭建一套基于 Claude 或 GPT 的 RAG 系统。
🎯 中等规模选型提示:NotebookLM 适合纯读取分析,但不支持自定义检索策略和复杂工作流。我们建议在 APIYI (apiyi.com) 平台上对接 Claude Sonnet 或 Opus 1M context 来运行 RAG,既能享受标准定价,又能灵活控制 chunk 数和检索权重,适合需要长期运营的语料库。
4.3 大规模语料(30 万字以上)生产期
达到几十万字甚至上百万字的量级时,方案 D 批处理脚本几乎是唯一可持续的选择。将任务拆解为「样本发现规律 → 代码批量处理 → 大规模语言模型仅处理关键节点」的三段式工作流,配合 Batch API 异步执行,可将单字成本压低至原来的 5%-15%。这一阶段你需要的不再是更聪明的プロンプト,而是更工程化的流水线。

五、段階的なトークン節約のための意思決定ガイド
上記の分析を、そのまま実践できるアクションプラン表にまとめました。
| トリガー条件 | 推奨プラン | アクションの要点 |
|---|---|---|
| 5万字未満 / 一時的な探索 | プラン A:対話型直接入力 | ファイルをドラッグ&ドロップし、プロンプトを調整、有効なプロンプトを記録する |
| 5〜30万字 / 静的データ / 分析重視 | プラン C:ベクトル知識ベース | NotebookLM または自作 RAG を選択し、チャンクと top-k の調整を優先する |
| 30万字以上 / 反復タスク / 量産が必要 | プラン D:バッチ処理スクリプト + Batch API | AI にスクリプトを書かせ、サンプル期間中に手動でルールを検証する |
| 動的なデータ / ローカル環境必須 | プラン B:MCP | ツール呼び出し回数を制限し、キーワード検索は慎重に行う |
実際のプロジェクトでは「プラン A で開始し、プラン C で中盤をこなし、プラン D で仕上げる」という組み合わせが一般的です。タスクの理解は段階的に深まるものだからです。小規模な対話で「何をすべきか」「評価基準は何か」を明確にし、中規模サンプルで検索精度と汎用性を検証し、大規模フェーズで成熟したプロセスをコードに落とし込みます。
中間段階を飛ばして直接バッチ処理スクリプトを作成するのはよくある誤りです。スクリプト自体は完璧でも、最初のプロンプトが十分にチューニングされていないため、期待通りの結果が得られないことが多々あります。逆に、対話フェーズに留まりすぎるとトークンを浪費してしまい、数百ドルの請求に対して数十個の有効なサンプルしか得られないという事態になりかねません。
🎯 フェーズ移行の判断基準: 同じようなプロンプトで似たようなファイルを5回以上処理しているなら、ベクトル知識ベースへ移行すべきタイミングです。また、タスクのたびに同じ検索ロジックを入力しているなら、スクリプトを書くべきです。APIYI (apiyi.com) プラットフォームでプロンプトキャッシュと利用統計を有効にし、感覚ではなくデータに基づいて移行時期を判断することをお勧めします。
六、バッチ処理スクリプトの最小構成例
プラン D をより具体的に理解するために、バッチ処理スクリプトの最小構成例を紹介します。「サンプルの発見 → ルールの固定 → 一括実行」という核心的なプロセスをデモンストレーションします。
import os, json
from anthropic import Anthropic
# APIYIのAPI中継サービスを利用
client = Anthropic(base_url="https://vip.apiyi.com")
def extract_style_features(markdown_text: str) -> dict:
"""大規模言語モデルを使用して、単一の記事から定量化可能なスタイル特徴を抽出します。"""
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
messages=[{"role": "user", "content": f"""
以下のMarkdown記事からライティングスタイルの特徴を抽出し、JSON形式で出力してください。含める項目:
- avg_sentence_length: 平均文長
- paragraph_structure: 段落構造のパターン
- key_phrases: 高頻度フレーズ上位10個
- tone: トーンのタグ(例:厳格/平易/鋭い)
記事内容:
{markdown_text}
"""}],
)
return json.loads(resp.content[0].text)
# サンプル期間: 10本の記事を使ってルールを発見
samples = [open(f, encoding="utf-8").read() for f in os.listdir("samples")[:10]]
features = [extract_style_features(s) for s in samples]
# ルールの固定: 高頻度な特徴を設定ファイルに書き出し、以降はコードで適用
with open("style_profile.json", "w", encoding="utf-8") as f:
json.dump(features, f, ensure_ascii=False, indent=2)
サンプル期間が終われば、実際の大量書き換えフェーズでは style_profile.json にあるルールをコードで適用するだけで済みます。大規模言語モデルは「最終的な推敲」のステップでのみ介入するため、トークン消費量を数十万から数千レベルまで削減可能です。
🎯 バッチ処理スクリプトのAPI接続アドバイス: 上記の
base_urlは APIYI (apiyi.com) の中継エンドポイントを指しており、コードを変更することなく Anthropic 公式 SDK をそのまま再利用できます。スクリプト内にリトライ処理とコスト追跡ロジックを追加することを推奨します。長時間のタスク実行時に予算を超過した場合に自動停止させる仕組みは、大規模バッチ処理において最も重要かつトラブルが起きやすい部分です。
七、よくある質問(FAQ)
Q1: Claude Sonnet や Opus は 100 万トークンのコンテキストに対応していますが、すべてそのまま入力してはいけないのですか?
技術的には可能ですが、2 つの隠れたコストがあります。1 つ目は、最初のトークンが出力されるまでの遅延(Time to First Token)が 20〜30 秒に達し、インタラクティブな操作感が損なわれること。2 つ目は、同じ資料を会話のたびに入力し直すと、RAG を利用する場合に比べてコストが 50〜200 倍にも膨れ上がることです。1M コンテキストは「文書を横断して矛盾を探す」といった一度限りの全体的な推論には適していますが、同じ資料に繰り返しアクセスする用途には向きません。APIYI(apiyi.com)では、Sonnet 1M で全体的な推論タスクを行い、Haiku でバッチ処理や詳細なタスクをこなすといった組み合わせが、最もコストパフォーマンスに優れています。
Q2: NotebookLM と自作のベクトルデータベース、どちらを選ぶべきですか?
個人や小規模チームが静的な資料の分析、文体研究、Q&A 検索を行うだけであれば、ファイルをドラッグ&ドロップするだけで使える NotebookLM が最も手軽です。一方で、チャンク戦略のカスタマイズ、検索の重み付け、業務システムとの連携、あるいは他社のモデルを生成に利用したいといったニーズがある場合は、自作のベクトルデータベースの方が柔軟に対応できます。
Q3: MCP(Model Context Protocol)は本当に役に立たないのですか?
決してそんなことはありません。MCP の強みは「データが頻繁に変動する」場合や「ローカル環境から外に出せない」シナリオ(リアルタイムログの読み取り、プライベートデータベースの照会、内部 API の呼び出しなど)にあります。静的な Markdown 資料に対しては RAG の方がほぼすべての面で優れている、というのが今回の結論です。
Q4: Batch API は本当に 50% 節約できますか?レスポンスは遅くないですか?
Batch API は非同期処理のため、通常 24 時間以内に結果が返ってきます。価格は標準 API の 50% です。「文体を学習させて模倣記事を 100 本作成する」といった、リアルタイム性を求めないタスクには非常に適しています。1M コンテキストの標準価格と組み合わせれば、総合コストを元の 30〜40% まで抑えることが可能です。まずは APIYI(apiyi.com)プラットフォームで同期 API を使ってフローを確立し、その後 Batch モードに切り替えて大量生産することをお勧めします。
Q5: 資料の中に画像、表、コードブロックが含まれている場合はどうすればいいですか?
Markdown 自体がこれらの構造を保持するのに適していますが、注意点があります。長いコードブロックは大量のトークンを消費するため、文章のスタイル分析が目的であれば、スクリプトでコード部分を事前に取り除いておくと良いでしょう。表が複雑な場合は CSV に変換して別途保存し、要約だけを大規模言語モデルに渡すことで、トークンをさらに 30% 以上節約できます。
八、まとめ
冒頭の問いに戻りましょう。数十万字の Markdown をどのように大規模言語モデルに読み込ませるべきか?答えは単一の選択肢ではなく、段階に応じた組み合わせです。小規模な探索フェーズではチャットへの直接入力が最速であり、中規模の研究フェーズではベクトル知識ベースや NotebookLM が最も安定します。そして大規模な生産フェーズでは、必ずバッチ処理スクリプトと Batch API を組み合わせる必要があります。大規模言語モデルの役割を「実行者」から「法則の発見者」へと絞り込み、実際の大量処理はコードに任せるのが正解です。
このプロセスを理解すれば、「大規模言語モデルで Markdown 資料のトークンを節約する」という課題は、「どのツールを選ぶか」から「どの段階でどの組み合わせを使うか」という戦略に変わります。もし現在、どの段階で切り替えるべきか迷っているなら、まずは APIYI(apiyi.com)プラットフォームで小規模な評価を行い、「1,000 文字あたりのコスト」「検索精度」「最初のトークンの遅延」の 3 つのデータを比較してみてください。判断が非常に明確になるはずです。この比較記事が、無駄な遠回りを避け、予算を真に価値を生む部分に投資する一助となれば幸いです。
—— APIYI Team (api.apiyi.com)